
Semi-automated Methods for the Annotation and Design of a Semantic Network Designed for Sentiment...
6
Semi-automated Methods for the Annotation and Design of a Semantic Network Designed for Sentiment Analysis of Social Web Content Donato Barbagallo, Leonardo Bruni, Chiara Francalanci, Paolo Giacomazzi, Francesco Merlo, Alessandro Poli Department of Electronics and Information Politecnico di Milano Via Ponzio 34/5, 20133 – Milan (Italy) {barbagallo,bruni,francala,giacomaz,merlo,poli}@elet.polimi.it Abstract— We have designed a new semantic network for the English language annotated with two types of domain knowledge: 1) general domain knowledge, represented as a sentiment polarity attached to relationships between words and 2) contextual knowledge, such as domain-specific proper names. In the context of social networks, such as Twitter, the evolution and maintenance of the network are particularly critical tasks for analysts not to incur in a quick obsolescence. We show how a set of semi-automated methodologies applied to our new semantic network show promising results on preliminary tests run using Twitter data. Keywords: semantic network, sentiment analysis, topic trend detection, categorization I. INTRODUCTION The literature concurs in considering natural language interpretation an open research issue, as it is still error prone [1]. Some authors claim that this error represents a fundamental obstacle to the success of many semantic Web applications, including sentiment analysis. However, in most contexts, the average precision of natural language interpretation is around. As a matter of fact this precision can be considered acceptable if an application does not involve additional sources of error. Our claim is that the error inherent to natural language interpretation is not the only reason why sentiment analysis is still considered a manual effort. A fundamental source of errors is related to the annotation of semantic networks for sentiment analysis. In traditional semantic networks, sentiment is usually associated with individual words (see, for instance, SentiWordnet [2]). However, the sentiment of a word can vary with the context of use. For example, the adjective long carries a positive sentiment if it is referred to the time duration of a battery, negative when referred to the lead time of a product. Starting from these observations, this paper presents the annotation of a semantic network which significantly differs from the state of the art and reports the results on precision gains in sentiment analysis. Twitter has been chosen as a test case for many reasons: (i) it is constantly growing, especially among mobile users, (ii) it provides general information on a variety of topics, and (iii) it is inherently difficult, since the structure of sentences is often difficult to understand. In our work, we take a data quality perspective (see Batini et al. [3]). Mitigating the consequence of data errors by taking a broader application process perspective is a typical problem of the data quality research. A strength of our approach is to build on a consolidated body of literature providing data quality methodologies and techniques. Our methodology assumes that sentiment is calculated with a tool that can interpret natural language, perform intelligent disambiguation, and evaluate whether the sentiment expressed by a sentence on a given subject of interest is either positive, negative, or neutral. In our research, we have built a prototype of this tool for the English language by assembling open source components [4]. The tool embeds an innovative disambiguation technique, described in [5], that can reach an average 67% precision. We consider this result as state of the art and, therefore, we use our tool to support the testing of the overall methodology described in this paper. The methodology has been developed as part of a two- year project in cooperation with the marketing office of the City Council of Milano with reference to the tourism domain. The project has been awarded the yearly innovation price of SMAU, Milano’s fair of electronics and computing. The tourism domain will be used as a reference scenario throughout the paper. The presentation is organized as follows. Section II describes the approach to the design of a new semantic network, its features and a methodology to drive its evolution and maintenance; Section III shows testing and performances that can be obtained on a set of tweets; Section IV discusses related works. Finally, Section V draws the conclusions. II. A NEW APPROACH TO THE ANNOTATION OF SEMANTIC NETWORK FOR SENTIMENT ANALYSIS Our approach on building a new semantic network is based on two main design principles:
Transcript of Semi-automated Methods for the Annotation and Design of a Semantic Network Designed for Sentiment...

Semi-automated Methods for the Annotation and Design of a Semantic Network Designed for Sentiment Analysis of Social Web Content
Donato Barbagallo, Leonardo Bruni, Chiara Francalanci, Paolo Giacomazzi, Francesco Merlo, Alessandro Poli Department of Electronics and Information
Politecnico di Milano Via Ponzio 34/5, 20133 – Milan (Italy)
{barbagallo,bruni,francala,giacomaz,merlo,poli}@elet.polimi.it
Abstract— We have designed a new semantic network for the English language annotated with two types of domain knowledge: 1) general domain knowledge, represented as a sentiment polarity attached to relationships between words and 2) contextual knowledge, such as domain-specific proper names. In the context of social networks, such as Twitter, the evolution and maintenance of the network are particularly critical tasks for analysts not to incur in a quick obsolescence. We show how a set of semi-automated methodologies applied to our new semantic network show promising results on preliminary tests run using Twitter data.
Keywords: semantic network, sentiment analysis, topic trend detection, categorization
I. INTRODUCTION The literature concurs in considering natural language
interpretation an open research issue, as it is still error prone [1]. Some authors claim that this error represents a fundamental obstacle to the success of many semantic Web applications, including sentiment analysis. However, in most contexts, the average precision of natural language interpretation is around. As a matter of fact this precision can be considered acceptable if an application does not involve additional sources of error. Our claim is that the error inherent to natural language interpretation is not the only reason why sentiment analysis is still considered a manual effort. A fundamental source of errors is related to the annotation of semantic networks for sentiment analysis. In traditional semantic networks, sentiment is usually associated with individual words (see, for instance, SentiWordnet [2]). However, the sentiment of a word can vary with the context of use. For example, the adjective long carries a positive sentiment if it is referred to the time duration of a battery, negative when referred to the lead time of a product. Starting from these observations, this paper presents the annotation of a semantic network which significantly differs from the state of the art and reports the results on precision gains in sentiment analysis. Twitter has been chosen as a test case for many reasons: (i) it is constantly growing, especially among mobile users, (ii) it
provides general information on a variety of topics, and (iii) it is inherently difficult, since the structure of sentences is often difficult to understand.
In our work, we take a data quality perspective (see Batini et al. [3]). Mitigating the consequence of data errors by taking a broader application process perspective is a typical problem of the data quality research. A strength of our approach is to build on a consolidated body of literature providing data quality methodologies and techniques. Our methodology assumes that sentiment is calculated with a tool that can interpret natural language, perform intelligent disambiguation, and evaluate whether the sentiment expressed by a sentence on a given subject of interest is either positive, negative, or neutral. In our research, we have built a prototype of this tool for the English language by assembling open source components [4]. The tool embeds an innovative disambiguation technique, described in [5], that can reach an average 67% precision. We consider this result as state of the art and, therefore, we use our tool to support the testing of the overall methodology described in this paper.
The methodology has been developed as part of a two-year project in cooperation with the marketing office of the City Council of Milano with reference to the tourism domain. The project has been awarded the yearly innovation price of SMAU, Milano’s fair of electronics and computing. The tourism domain will be used as a reference scenario throughout the paper.
The presentation is organized as follows. Section II describes the approach to the design of a new semantic network, its features and a methodology to drive its evolution and maintenance; Section III shows testing and performances that can be obtained on a set of tweets; Section IV discusses related works. Finally, Section V draws the conclusions.
II. A NEW APPROACH TO THE ANNOTATION OF SEMANTIC NETWORK FOR SENTIMENT ANALYSIS
Our approach on building a new semantic network is based on two main design principles:

• the network should support domain analyses, thus it must include domain-specific information;
• sentiment information should be embedded into the network and associated with relationships between concepts as opposed to individual words or synonym sets.
These two principles have driven the design of our network and represent the foundation of two architectural decisions: • The network is layered and contains domain information
in different logical layers. For example, the first layer contains nouns, verbs, and concepts; the second layers contains the description of the domain, i.e., grouping the first layer’s elements into interesting concepts for a given domain of analysis. In our project, the following categories are considered using the Anholt-GfK Roper Nations Brand Index [6]: Events & Sports, Food and Drink, Fashion & Shopping, Night & Music, Arts & Culture, Services and Transport, Fares and Tickets, Weather & Environmental, Life & Entertainment. A third layer, called the brand layer, contains all those words that are directly linked to a specific brand in the user domain. For example, Heathrow airport is represented in the second layer as domain knowledge and connected to London, which is a brand and is stored in the third layer.
• Network elements are connected through several types of links, which will be discussed in the next section. One of these links concerns opinions and connects each word carrying sentiment to the concepts to which that sentiment can be referred. The main difference between our network and state-of-the-art ones is that ours includes possible domain-related exceptions. For example, the adjective small can be associated with multiple nouns with a different sentiment value.
A. Structure of the Network As in any other semantic network, elements in our
network are connected by links. Such links can be viewed as a vector of pairs (type, verb). Type defines the relation between two elements, while verb specifies the action that can occur between the two elements. There are two main types: type 1 collects 17 different subtypes of relations among elements in the semantic network, while type 2 defines the sentiment that can be either positive, neutral, negative, or undefined. We report the main subtypes of type 1: “is subset of”, “has attribute”, “not has attribute”, “verb relation yes/no”, “has synonym”, “has contrary”, “categorizes as”, “is sub-brand of”, “has equivalent”.
The core of the semantic network is composed by three elements: (i) word, that is linked to stopwords, pronouns, and verbs, (ii) universe, and collects all names, objects and concepts in the network, and (iii) attribute, which defines all the adjectives that are classified according to their use (depending on whether they can be referred to weather, people, etc.) and according to their sentiment.
The domain knowledge of the tourism domain includes lists of foods, monuments, museums, street names, famous people, as well as all the adjectives that can be referred to
these categories of elements and their domain-specific sentiment. The creation of the semantic network has been mainly manual with the support of a massive import tool designed for long lists of names and related relations in the semantic network. Table I shows some descriptive data of our network.
TABLE I. DESCRIPTIVE STATISTICS OF THE SEMANTIC NETWORK.
Component Number elements > 100,000 links > 160,000 verbs 13960 verb clusters 312
B. Evolution of the Network The identification and correct classification of new
keywords is a fundamental maintenance objective of any semantic network. The addition of a new keyword into the network follows three steps: 1. the tool automatically analyzes new information and
provides a selection of keywords that are frequently repeated;
2. the tool provides an estimation of the most likely category for each keyword;
3. the tool provides additional functionalities to interpret keywords and make a categorization decision (semi-automatic).
These steps are described in the next three subsections. 1) Step 1: Finding Trending keywords
The first step is finding trending keywords. For this purpose, we have tested an approach that is based on the relative frequency of keywords. Our algorithm finds spikes of frequently mentioned keywords in a given time frame.
Similar to the approach followed by Dubinko [7], the first step is performed with a word burst detection algorithm that uses the keywords belonging to two different time-windows, tA and tB, such that tA < tB, as represented in Figure 1.
Figure 1. Time windows for finding trending keywords
Then, a relevance metric is calculated as follows:
€
RFB (T) =count(T,tA)
count(T,tB) + c,
where the function count(T, t) counts the occurrences of term T in the total posts published in time-window t, and c is a shrinking factor. 2) Step 2: Classifying Trending Topics
In order to classify trending topics, we have designed a metric that combines the use of a semantic network and techniques based on intentional learning. This metric is based on the use of n-grams and classifies keywords using

contextual information from each keyword’s posts. The metric is defined as follows:
€
M(c) =
cat(p,c)p∈P (g )∑
g∈G∑
log(count(c)) + count(c)c∈C∑
,
where G is the set of n-grams of keyword W, P(g) is the set of unigrams, bigrams, and (n-1)-grams extracted from n-gram g, the function cat(b, c) is equal to 1 if p is a keyword belonging to category c, 0 otherwise, count(c) is the total number of words in category c, which is used as shrinking factor. 3) Step 3: Mashing-up Web information
Understanding words coming from social network can be a very difficult task even for a human decision maker. For this reason, our approach is not limited to the use of the metrics introduced in the two previous sections, but it integrates them using different information sources in order to help interpretation.
Figure 2 shows a mockup version of our tool interface that mashes up different services: • trending keywords, identified with the algorithm shown
at step 1, grouped by tweet; • suggestion of categorization, identified with algorithm
shown at step 2 and value of the metric M(c) for each category;
• Twitter is used to show the full content of the top trending messages;
• Klout is mashed-up to embed knowledge on Twitter users and their influence.
• Google is included in order to exploit its general search functionalities and help interpretation.
III. TESTING AND RESULTS We have tested our approach on a dataset of posts
crawled from Twitter using Twitter’s APIs. The dataset is composed of 2023 subsequent tweets posted on December 1st, 2010 and containing the keyword “milan”. We have run two types of analyses in order to verify the benefits of the design features of our semantic network discussed in the previous sections. First, we have executed a categorization analysis, aimed at verifying whether the tool is able to classify tweets into categories describing a given topic of interest. Second, we have run a sentiment analysis on the same data set. Table II reports results in terms of precision and recall for both analyses and an overall score measuring the ability of the tool to provide results that are simultaneously correct on both categorization and sentiment. This latter indicator, called overall performance in Table II, is clearly the lowest.
In the literature, values of precision and recall above 80% are considered a minimum threshold to guarantee the dependability of analyses
Figure 2. Mockup version of the interface supporting analysts in the
network evolution phase.
Note that a 90% precision is close to the results of human evaluators [8]. Precision is defined as the ratio of correctly analyzed tweets to the total amount of analyzed tweets. Recall is defined as the ratio of correctly analyzed tweets to the total amount of tweets that should have been analyzed. The categories included in layer 2 of the semantic network are the following: weather and environment, services and transportation, tickets, fashion and shopping, food and drinks, arts and culture, events and sport, life and entertainment, night and music. These categories have been populated by creating over 5000 links with corresponding concepts in layer 1 of the semantic network. Brand “Milan” has been described with over 30000 sub-brands that include the complete set of streets, shops, pubs, restaurants, museums, and monuments of Milan city.
TABLE II. PERFORMANCE OF THE ANALYSIS ON A DATASET OF 2023 TWEETS.
categorization sentiment overall precision recall precision recall precision recall
84.8% 88.8% 92.3% 83.1% 84.8% 82.0% Table III reports the percentage of results that could not
be correctly classified without domain knowledge and the percentage of sentiment results that would not be correct without an association of sentiment to word pairs in the domain of interest. As an example, 18 tweets had a negative sentiment related to city transports in a day of snow. From Table III, it is clear how without a domain-dependent approach the values of precision would drop below 60% and recall below 40%, with also a combined effect on overall precision and recall below 60%. These low values clearly represent a threat to dependability in a decision-making context.
TABLE III. ESTIMATES OF PERFORMANCE GAINS FROM DOMAIN KNOWLEDGE AND SENTIMENT NETWORK DESIGN.
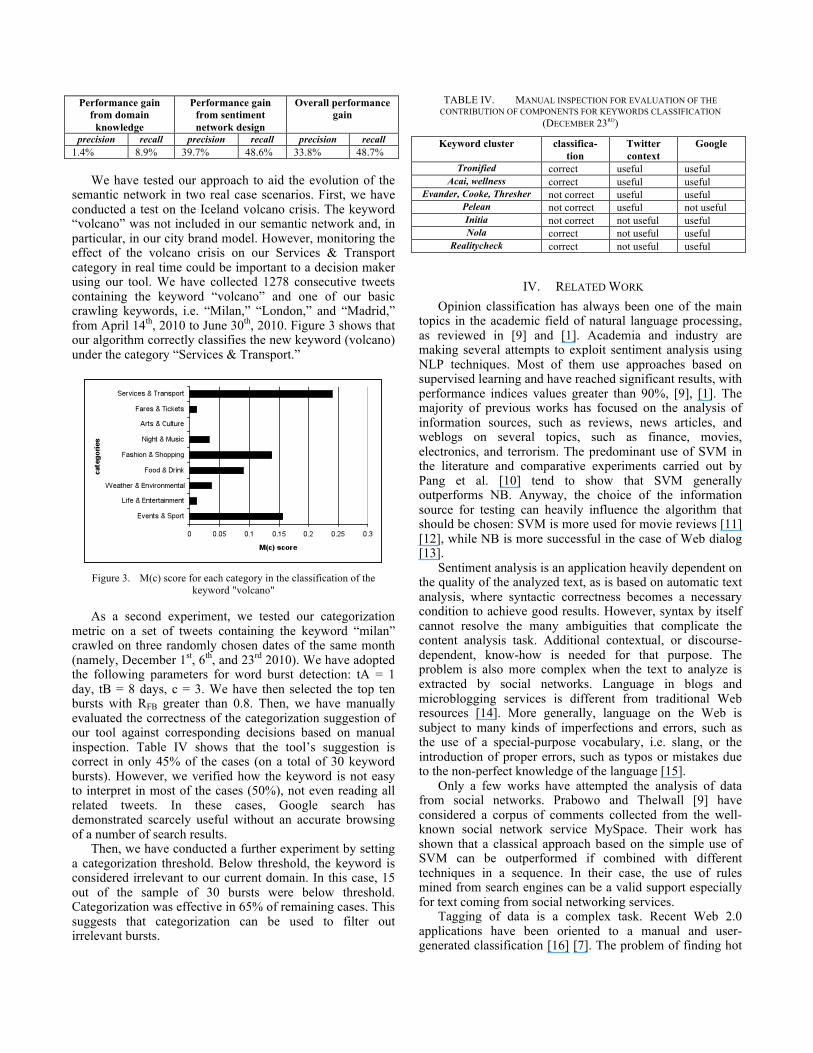
Performance gain from domain
knowledge
Performance gain from sentiment network design
Overall performance gain
precision recall precision recall precision recall 1.4% 8.9% 39.7% 48.6% 33.8% 48.7%
We have tested our approach to aid the evolution of the
semantic network in two real case scenarios. First, we have conducted a test on the Iceland volcano crisis. The keyword “volcano” was not included in our semantic network and, in particular, in our city brand model. However, monitoring the effect of the volcano crisis on our Services & Transport category in real time could be important to a decision maker using our tool. We have collected 1278 consecutive tweets containing the keyword “volcano” and one of our basic crawling keywords, i.e. “Milan,” “London,” and “Madrid,” from April 14th, 2010 to June 30th, 2010. Figure 3 shows that our algorithm correctly classifies the new keyword (volcano) under the category “Services & Transport.”
Figure 3. M(c) score for each category in the classification of the
keyword "volcano"
As a second experiment, we tested our categorization metric on a set of tweets containing the keyword “milan” crawled on three randomly chosen dates of the same month (namely, December 1st, 6th, and 23rd 2010). We have adopted the following parameters for word burst detection: tA = 1 day, tB = 8 days, c = 3. We have then selected the top ten bursts with RFB greater than 0.8. Then, we have manually evaluated the correctness of the categorization suggestion of our tool against corresponding decisions based on manual inspection. Table IV shows that the tool’s suggestion is correct in only 45% of the cases (on a total of 30 keyword bursts). However, we verified how the keyword is not easy to interpret in most of the cases (50%), not even reading all related tweets. In these cases, Google search has demonstrated scarcely useful without an accurate browsing of a number of search results.
Then, we have conducted a further experiment by setting a categorization threshold. Below threshold, the keyword is considered irrelevant to our current domain. In this case, 15 out of the sample of 30 bursts were below threshold. Categorization was effective in 65% of remaining cases. This suggests that categorization can be used to filter out irrelevant bursts.
TABLE IV. MANUAL INSPECTION FOR EVALUATION OF THE CONTRIBUTION OF COMPONENTS FOR KEYWORDS CLASSIFICATION
(DECEMBER 23RD)
Keyword cluster classifica-tion
Twitter context
Tronified correct useful useful Acai, wellness correct useful useful
Evander, Cooke, Thresher not correct useful useful Pelean not correct useful not useful Initia not correct not useful useful Nola correct not useful useful
Realitycheck correct not useful useful
IV. RELATED WORK Opinion classification has always been one of the main
topics in the academic field of natural language processing, as reviewed in [9] and [1]. Academia and industry are making several attempts to exploit sentiment analysis using NLP techniques. Most of them use approaches based on supervised learning and have reached significant results, with performance indices values greater than 90%, [9], [1]. The majority of previous works has focused on the analysis of information sources, such as reviews, news articles, and weblogs on several topics, such as finance, movies, electronics, and terrorism. The predominant use of SVM in the literature and comparative experiments carried out by Pang et al. [10] tend to show that SVM generally outperforms NB. Anyway, the choice of the information source for testing can heavily influence the algorithm that should be chosen: SVM is more used for movie reviews [11] [12], while NB is more successful in the case of Web dialog [13].
Sentiment analysis is an application heavily dependent on the quality of the analyzed text, as is based on automatic text analysis, where syntactic correctness becomes a necessary condition to achieve good results. However, syntax by itself cannot resolve the many ambiguities that complicate the content analysis task. Additional contextual, or discourse-dependent, know-how is needed for that purpose. The problem is also more complex when the text to analyze is extracted by social networks. Language in blogs and microblogging services is different from traditional Web resources [14]. More generally, language on the Web is subject to many kinds of imperfections and errors, such as the use of a special-purpose vocabulary, i.e. slang, or the introduction of proper errors, such as typos or mistakes due to the non-perfect knowledge of the language [15].
Only a few works have attempted the analysis of data from social networks. Prabowo and Thelwall [9] have considered a corpus of comments collected from the well-known social network service MySpace. Their work has shown that a classical approach based on the simple use of SVM can be outperformed if combined with different techniques in a sequence. In their case, the use of rules mined from search engines can be a valid support especially for text coming from social networking services.
Tagging of data is a complex task. Recent Web 2.0 applications have been oriented to a manual and user-generated classification [16] [7]. The problem of finding hot

topics (or hot trends) is often solved as word frequency burst. One of the most known approaches is proposed by Kleinberg [17] and is based on markovian models. Anyway, it presents the limitations of accepting only one input stream and of being based on features that are sometimes hard to estimate [18]. The work proposed by He and Stott Parker [18] presents an algorithm that uses several features for the burst detection, but it is also efficient and integrates semantics. Real-time detection of trending topics is a fundamental requirement for those applications that are based on the detection of critical situations and that need to get burst timely. Dubinko defines an interesting tag when it satisfies two properties [7]: (i) a tag is important in a given time interval if it more frequently appears in that interval and less frequently in other intervals and (ii) a tag, which is usually not frequent and becomes frequent in a given interval, is not necessarily interesting in that interval. A similar approach, that joins both frequency and timeliness, has been adopted by Kuo et al. [19].
Another problem discussed in this paper is the classification of documents under a set of given categories. Many studies have focused on (i) semi-supervised methods, mainly based on Naïve Bayes, Expectation Maximization algorithms [20][21], and Error Correction Output Coding, that reach accuracy values between 30% and 78%, and (ii) unsupervised methods, based on the definition of semantic groups of words directly connected to a category, that are used by a term-matching algorithm to define a training set of documents [22]. Manual labeling of documents can be supported using active learning, but a preliminary sample set of classified documents is always required, such as a taxonomy [23]. These kinds of approaches reach performance that, measured through F-measure, that span between 30% and 89%.
V. CONCLUSIONS This paper has shown a new approach to the design of a
semantic network oriented to sentiment analysis. It has also presented a set of algorithms to support analysts in the maintenance of the network. Preliminary results show that the combination of non-supervised algorithms for word burst detection and classification with Web information sources such as Google, and the use of the context derived from Twitter can represent a valid support.
ACKNOWLEDGMENT We would like to express our gratitude to the Directorate
of Tourism of Milan City and to Daniele Garbugli.
REFERENCES [1] B. Pang, and L. Lee, “Opinion mining and sentiment analysis”.
Found. Trends Inf. Retr. 2, 1-2 (Jan. 2008), 1–135. [2] A. Esuli, and F. Sebastiani, “SentiWordnet: A publicly available
lexical resource for opinion mining”. In Proc. of 5th Conf on Language Resources and Evaluation (LREC-06).
[3] C. Batini, C. Cappiello, C. Francalanci, and A. Maurino, “Methodologies for data quality assessment and improvement”. ACM Comput. Surv. 41, 3 (July 2009), 2009 pp. 1–52.
[4] D. Barbagallo, C. Cappiello, C. Francalanci, and M. Matera, “Semantic sentiment analyses based on the reputation of Web information sources”. In Applied Semantic Technologies: Using Semantics in Intelligent Information Processing. Taylor and Francis, 2011.
[5] D. Barbagallo, L. Bruni, and C. Francalanci, “Exploiting wordnet glosses to disambiguate nouns through verbs”. In Proc. of the Fourth Intl. Conf. on Advances in Semantic Processing (SEMAPRO 2010).
[6] S. Anholt, “Competitive Identity: The New Brand Management for Nations, Cities and Regions”. Palgrave Macmillan, Eds.
[7] M. Dubinko, R. Kumar, J. Magnani, J. Novak, P. Raghavan, and A. Tomkins, “Visualizing tags over time”. In Proc. of the 15th intl. conf. on World Wide Web (WWW '06). ACM, New York, NY, USA, 2006 pp. 193-202.
[8] S. Grimes, “Expert Analysis: Is Sentiment Analysis an 80% Solution?”. InformationWeek (March 2010). Available online at http://www.informationweek.com/news/software/bi/showArticle.jhtml?articleID=224200667 2010
[9] R. Prabowo, and M. Thelwall, “Sentiment analysis: A combined approach”. J. of Informetrics, 3, 2, 2009, pp. 143–157.
[10] B. Pang, L. Lee, and S. Vaithyanathan, “Thumbs up?: sentiment classification using machine learning techniques”. In EMNLP ’02: Proc. of the ACL-02 conf. on Empirical methods in NLP, 2002, pp. 79–86.
[11] S. Greene, and P. Resnik, “More than words: syntactic packaging and implicit sentiment”. In NAACL ’09: Proc. of Human Language Technologies: The 2009 Annual Conf. of the North American Chapter of ACL, 2009, pp. 503–511.
[12] A. Abbasi, H. Chen, and A. Salem, “Sentiment analysis in multiple languages: Feature selection for opinion classification in web forums”. ACM Trans. Inf. Syst., 26, 3, 2008.
[13] N. O’Hare, M. Davy, A. Bermingham, P. Ferguson, P. Sheridan, C. Gurrin, and A. F. Smeaton, “Topic-dependent sentiment analysis of financial blogs”. In TSA ’09: Proc. of the 1st Intl. CIKM workshop on Topic-sentiment analysis for mass opinion, New York, NY, USA, 2009, pp. 9–16.
[14] N. Savage, “New search challenges and opportunities”. Commun. ACM, 53, 1 pp. 27–28.
[15] C. Ringlstetter, K. U. Schulz, and S. Mihov, “Orthographic errors in web pages: Toward cleaner web corpora”. Comput. Linguist., 32, 3 (Sep. 2006), 2006, pp. 295–340.
[16] S. Sen, S. K. Lam, A. M. Rashid, D. Cosley, D. Frankowski, J. Osterhouse, F. Maxwell Harper, J. Riedl, “Tagging, communities, vocabulary, evolution”. In Proc. of the 2006 conf. on Computer supported cooperative work. (CSCW '06). ACM, New York, NY, USA, 2006, pp. 181-190.
[17] J. Kleinberg, “Bursty and hierarchical structure in streams”. In Proc. of the 8th ACM SIGKDD intl. conf. on Knowledge discovery and data mining, 2002, pp 91-101.
[18] D. He, and D. Stott Parker, “Topic dynamics: an alternative model of bursts in streams of topics”. In Proc. of the 16th ACM SIGKDD intl. conf. on Knowledge discovery and data mining (KDD '10), 2010, pp. 443-452.
[19] B.Y.L. Kuo, T. Hentrich, B. M. Good, and M.D. Wilkinson, “Tag clouds for summarizing Web search results”. Proc. of the 16th intl. conf. on World Wide Web, May 08-12 2006.
[20] C. Lanquillon, “Partially supervised text categorization: combining labeled and unlabeled documents using an EM-like scheme”. In Proc. of the 11th conf. on machine learning (ECML 2000), vol. 1810, 2000, pp. 229–237.
[21] K. Nigam, A. McCallum, S. Thrun, T. Mitchell, “Text Classification from Labeled and Unlabeled Documents using EM”, Machine Learning, v.39 n.2-3, 2000, pp.103-134.

[22] Y. Ko, J. Seo, “Text classification from unlabeled documents with bootstrapping and feature projection techniques”. Inf. Process. Manage. 45, 1 (Jan. 2009), 2009, pp. 70-83.
[23] G. Adami, P. Avesani, and D. Sona, “Bootstrapping for hierarchical document classification”. In Proc. of the twelfth intl. conf. on
Information and knowledge management (CIKM '03). ACM, New York, NY, USA, 2003, pp. 295-302.
.




















