
Russian Learner Translator Corpus in translator training
19
Russian Learner Translator Corpus in translator training Maria Kunilovskaya Marina Kovyazina Tatyana Ilyushchenya Tyumen State University (Russia) 4th Using Corpora in Contrastive and Translation Studies conference (Lancaster, July 24th, 2014) http://www.rus-ltc.org/
Transcript of Russian Learner Translator Corpus in translator training

Russian Learner Translator Corpus in translator training
Maria Kunilovskaya Marina Kovyazina
Tatyana Ilyushchenya Tyumen State University (Russia)
4th Using Corpora in Contrastive and Translation Studies conference (Lancaster, July 24th, 2014)
http://www.rus-ltc.org/

1. Educational context: Where it is used
• the course of General Translation Practice (4 semesters, 2 class hours a week);
• advanced translation students;
• from English (L2) into Russian (L1) translations;
• STs: general press → economic press → professional texts;
• TTs: produced out of class;
come with a translation brief;
• no or moderate time limit.
Maria Kunilovskaya, UCCTS4, July 24, 2014

2. EN-RU error-tagged subcorpus: Description
• In use for 3 semesters;
• 265 annotated translations (for 33 sources);
• 6,471 error tags, including 236 for good solutions;
• online tag-editor: the server installation of the open-source text annotation programme called brat
http://brat.nlplab.org/index.html
• data storage: stand-off machine-readable txt files;
• all translations are anonymized before annotation;
• students have access to tagged translations and (visualized) statistics thru a link.
Maria Kunilovskaya, UCCTS4, July 24, 2014

An error-tagged translation with an expanded note
Maria Kunilovskaya, UCCTS4, June 8, 2014

Teacher’s end: BRAT-based online error tag editor
Maria Kunilovskaya, UCCTS4, June 8, 2014

Error typology
• reflects the practices used at our universities;
• emphases textual and pragmatic issues in translation;
• is descriptive (and TT-centered);
• is (mostly) based on evaluation of ST-TT relations
(a mistake is harm to the faithfulness of translation and its textual and linguistic quality);
• is aimed at formative rather than summative assessment;
• is manageable in the tag-editor. It is a tree-like hierarchy based on the opposition of
ST content transfer and TL expression errors
Maria Kunilovskaya, UCCTS4, July 24, 2014

Main RusLTC translation error typology
Maria Kunilovskaya, UCCTS4, July 24, 2014
ST content transfer
content_reference
omission
distortion
nonsense
inexact
unclear
content_cohesion
theme-rheme
logic
content_pragmatics
tenor
field
TT language quality language_lexical
choice-of-word combinability language_morphology wrong_wordform language_syntax incomplete ungrammatical word_order preposition language_spelling capitals typo language_punctuation Note Good_solution

Two extra tag sets
Technology (why the mistake)
• background_info
• SL
• TL
• too_literal
• too_free
• proper_name
• inconsistency
Maria Kunilovskaya, UCCTS4, July 24, 2014
Gravity of mistake • critical • major • minor
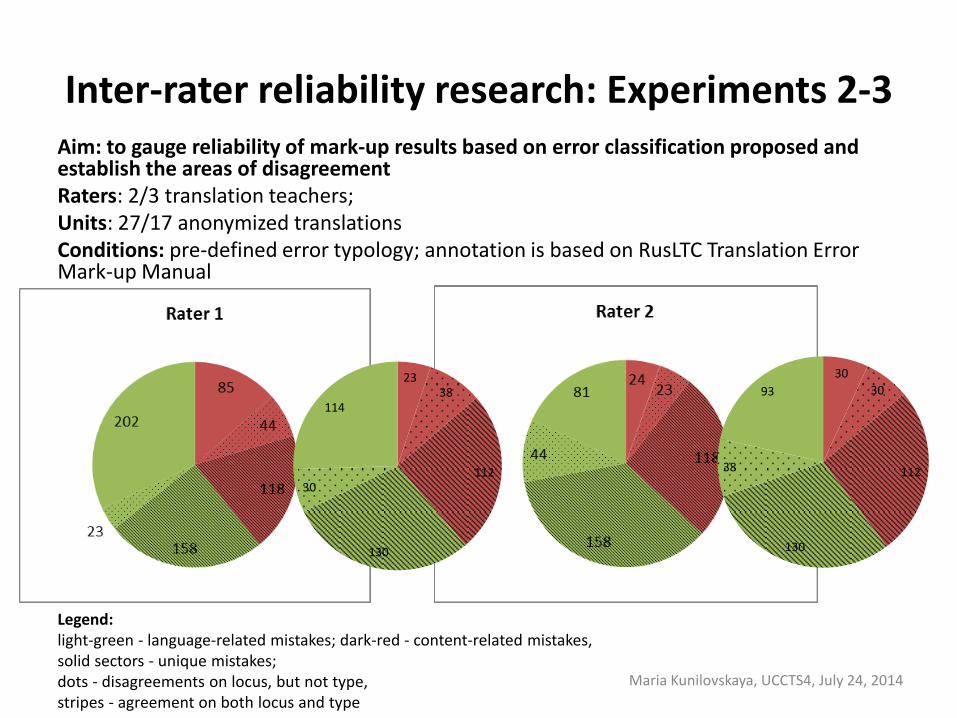
Inter-rater reliability research: Experiments 2-3 Aim: to gauge reliability of mark-up results based on error classification proposed and establish the areas of disagreement Raters: 2/3 translation teachers; Units: 27/17 anonymized translations Conditions: pre-defined error typology; annotation is based on RusLTC Translation Error Mark-up Manual
Legend: light-green - language-related mistakes; dark-red - content-related mistakes, solid sectors - unique mistakes; dots - disagreements on locus, but not type, stripes - agreement on both locus and type
Maria Kunilovskaya, UCCTS4, July 24, 2014
23 38
112
130
30
114
30
30
112
130
38
93

Inter-rater reliability research: Results
Agreement: 1) agreement on erroneous text spans: 2/3 of annotator decisions; 2) agreement on mistake type (in terms of upper-level categories): ˂ 80% of the above; 3) target language mistakes to content-related ones: 0.6; 4) more agreement on content errors than on less significant language errors; 5) more agreement on poor translations than on good ones; 6) error-based TQA shows greater degree of consensus between raters than
holistic evaluation (Krippendorff’s Alpha coefficient of α=0,734 versus α=0.569);
7) additional training for raters and improvements introduced into the classification between the consecutive experiments did increase the reliability of the error-tagging.
Disagreement: 1) the rigor of mistakes analysis (total number of mistakes); 2) nature and number of good translator solutions; 3) description in terms of lower-level categories, and 4) seriousness (gravity) of mistakes. See full paper at http://tc.utmn.ru/files/HowMuchDoWeAgree_TQA.pdf for more details
Maria Kunilovskaya, UCCTS4, July 24, 2014
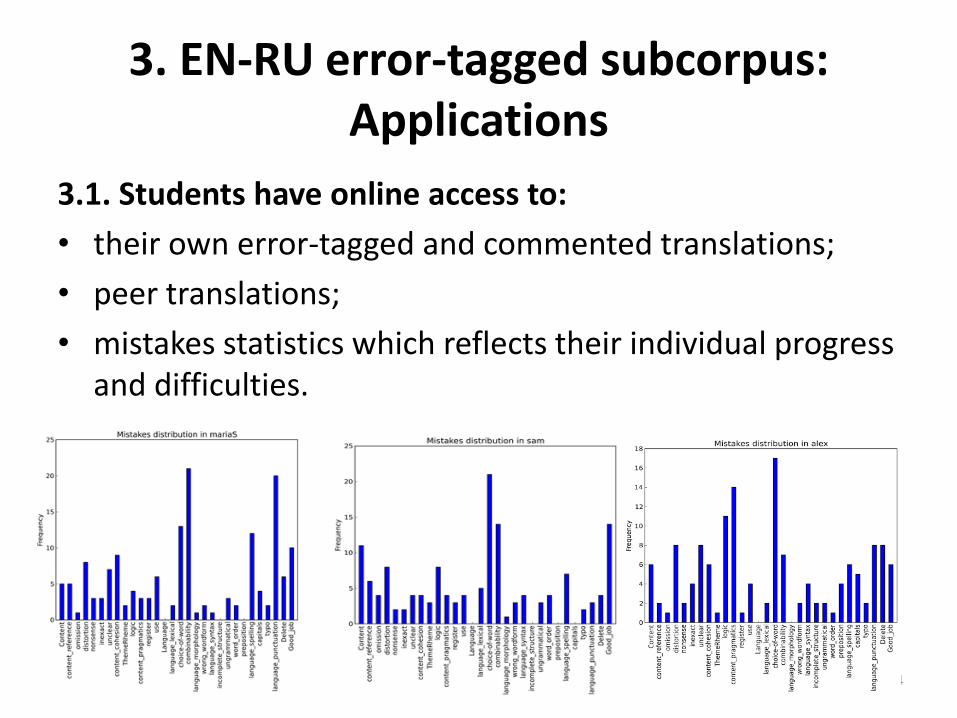
3. EN-RU error-tagged subcorpus: Applications
3.1. Students have online access to:
• their own error-tagged and commented translations;
• peer translations;
• mistakes statistics which reflects their individual progress and difficulties.
Maria Kunilovskaya, UCCTS4, July 24, 2014
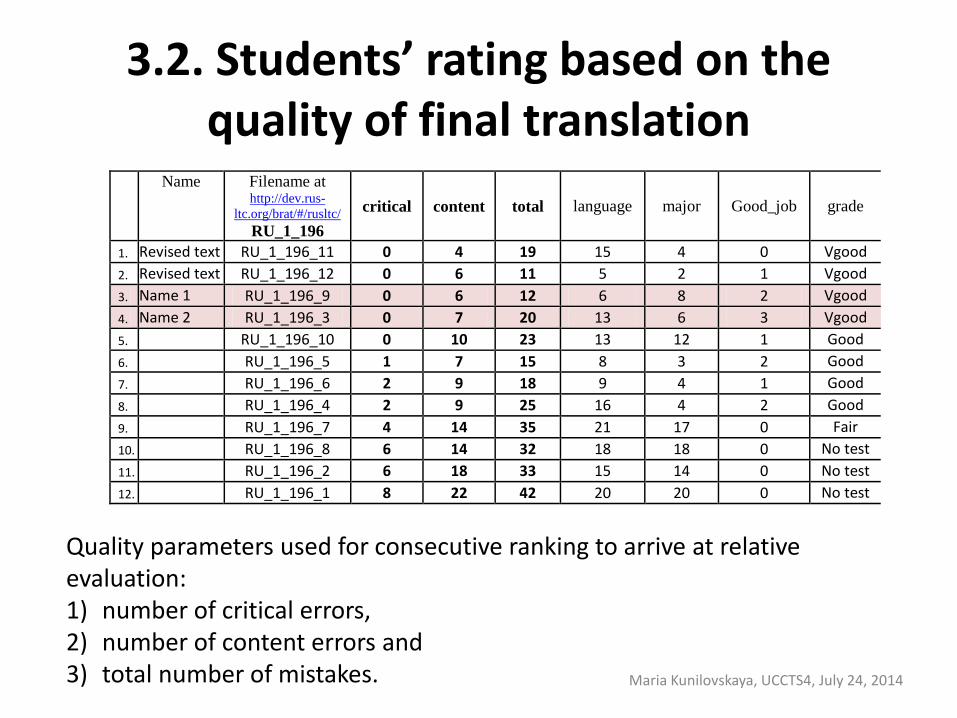
3.2. Students’ rating based on the quality of final translation
Maria Kunilovskaya, UCCTS4, July 24, 2014
Quality parameters used for consecutive ranking to arrive at relative evaluation: 1) number of critical errors, 2) number of content errors and 3) total number of mistakes.
Name Filename at http://dev.rus-
ltc.org/brat/#/rusltc/
RU_1_196
critical content total language major Good_job grade
1. Revised text RU_1_196_11 0 4 19 15 4 0 Vgood
2. Revised text RU_1_196_12 0 6 11 5 2 1 Vgood
3. Name 1 RU_1_196_9 0 6 12 6 8 2 Vgood
4. Name 2 RU_1_196_3 0 7 20 13 6 3 Vgood
5. RU_1_196_10 0 10 23 13 12 1 Good
6. RU_1_196_5 1 7 15 8 3 2 Good
7. RU_1_196_6 2 9 18 9 4 1 Good
8. RU_1_196_4 2 9 25 16 4 2 Good
9. RU_1_196_7 4 14 35 21 17 0 Fair
10. RU_1_196_8 6 14 32 18 18 0 No test
11. RU_1_196_2 6 18 33 15 14 0 No test
12. RU_1_196_1 8 22 42 20 20 0 No test

3.3. Error analysis results to apply in, and evaluate teaching practices
1) Follow students’ individual progress over the year (based on the total number of mistakes normalized by the text size)
Maria Kunilovskaya, UCCTS4, July 24, 2014
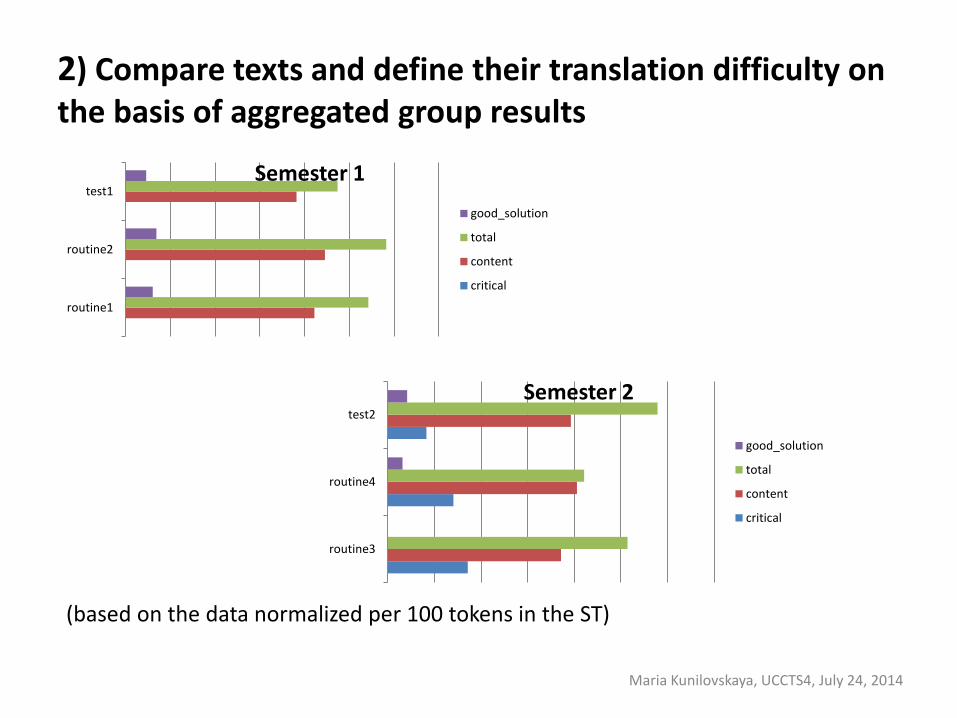
2) Сompare texts and define their translation difficulty on the basis of aggregated group results
Maria Kunilovskaya, UCCTS4, July 24, 2014
(based on the data normalized per 100 tokens in the ST)
routine1
routine2
test1Semester 1
good_solution
total
content
critical
routine3
routine4
test2
Semester 2
good_solution
total
content
critical
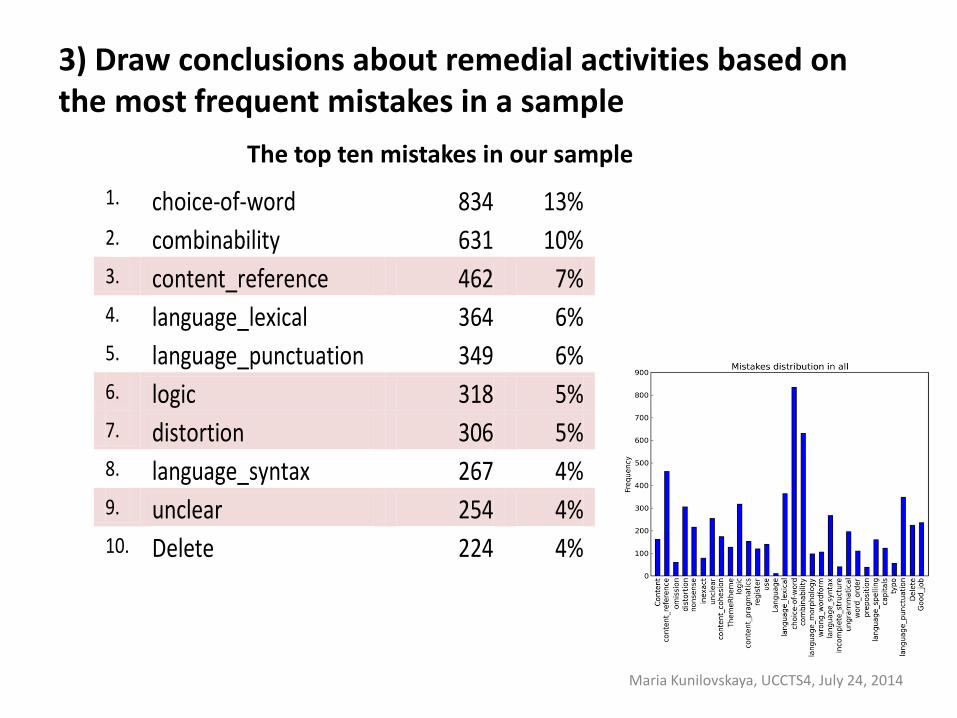
3) Draw conclusions about remedial activities based on the most frequent mistakes in a sample
Maria Kunilovskaya, UCCTS4, July 24, 2014
1. choice-of-word 834 13% 2. combinability 631 10% 3. content_reference 462 7% 4. language_lexical 364 6% 5. language_punctuation 349 6% 6. logic 318 5% 7. distortion 306 5% 8. language_syntax 267 4% 9. unclear 254 4% 10. Delete 224 4%
The top ten mistakes in our sample
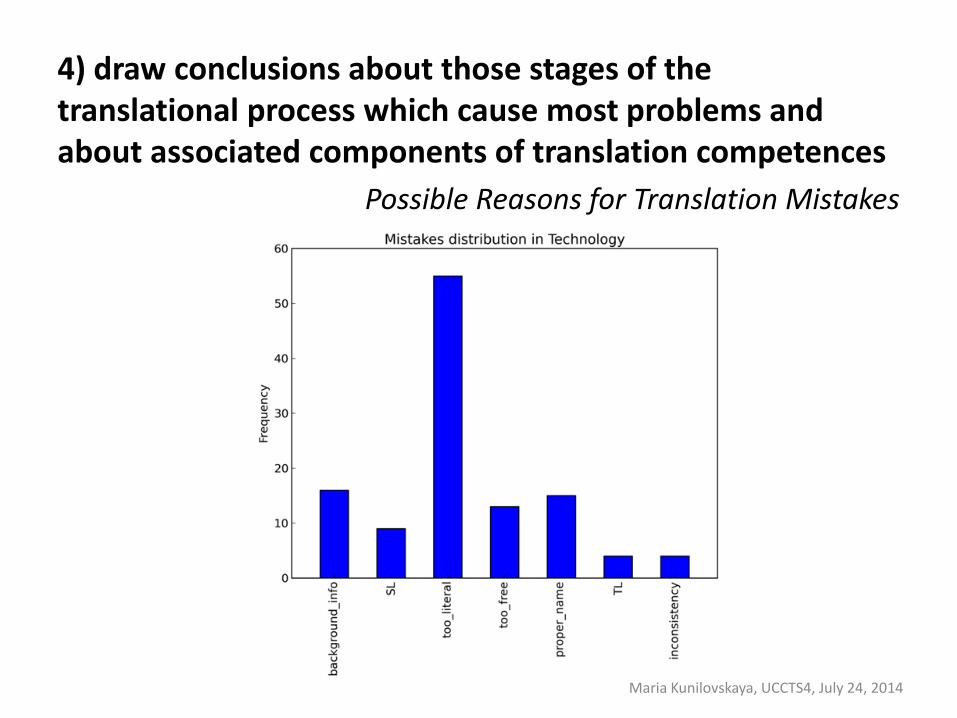
4) draw conclusions about those stages of the translational process which cause most problems and about associated components of translation competences
Possible Reasons for Translation Mistakes
Maria Kunilovskaya, UCCTS4, July 24, 2014

5) Use statistic analysis to check intuitions about students’ translation quality and TQA Hypothesis 1: The better one knows L1 the better she understands the source/the better the transfer skills, i.e. the less language errors, the less critical errors and the more good solutions. - no statistically significant correlation based on Pearson correlation
coefficient Hypothesis 2: Final year students make less mistakes than 4th year students (though their ST are assumed more difficult) - though normalized data does support this intuition, there is no statistically
significant difference between the two data-sets (based on 2-tailed Student's t-test for groups with unequal variance; the wanted P < 0.1)
Hypothesis 3: Test translations show better results than routine translations because students are more motivated to perform better - no significant difference between the two samples (based on the same t-
test) Hypothesis 4: The quantitative results of the error annotation depend on the order of translations in the set (“order effect”) - the median for the total number of mistakes in the “first” translations -
4.82, in the “last” ones - 3.63, paired t-test p= 0.12040056
Maria Kunilovskaya, UCCTS4, July 24, 2014

4. RusLTC in material design 1) Theory-based exercises utilizing multiple concordances
in the course of Translation Studies (3d year): - discussing translation strategies, identifying translation problems
and comparing/evaluating solutions - developing skills to overcome known transfer issues in English-
Russian translation which are due to interlingual typological differences
2) Corpus-driven exercises to prevent most common mistakes in the practical course of Text analysis for translators and in the
course Revision and Editing for Translators - developing L1 competence through building up corpus-querying
and documentary research skills; - extending the scope of world knowledge through information
search and developing text analysis and text comprehension aptitude.
We plan a pre-test/treatment/post-test experiment to establish efficacy and an e-learning course based on these exercises.
Maria Kunilovskaya, UCCTS4, July 24, 2014

Summary
1) Russian Learner Translator Corpus is an available and extensive source of data for translation studies and translator education research (http://www.rus-ltc.org/);
2) The error-tagged subcorpus (http://dev.rus-ltc.org/brat/#/rusltc/) is a method to provide students extensive feedback on their translations
3) and a means of accumulating research data on TQA;
4) RusLTC content is used in designing teaching materials.
Thank you!
Contact me: [email protected]
Maria Kunilovskaya, UCCTS4, July 24, 2014




















