
Improving English Pronunciation: An Automated Instructional Approach
10
Mitra, Tooley, Inamdar, Dixon Research Reports / Improving English Pronunciation 75 © 2003 The Massachusetts Institute of Technology Information Technologies and International Development Volume 1, Number 1, Fall 2003, 75–84 a. [email protected] Centre for Research in Cognitive Systems NIIT Limited Synergy Building IIT Campus New Delhi, India b. [email protected] University of Newcastle Newcastle Upon Tyne, England c. [email protected] Centre for Research in Cognitive Systems NIIT Limited Synergy Building IIT Campus New Delhi, India d. [email protected] University of Newcastle Newcastle Upon Tyne, England Improving English Pronunciation: An Automated Instructional Approach Sugata Mitra, a James Tooley, b Parimala Inamdar, c and Pauline Dixon d This paper describes an experiment in which groups of children attempted to improve their English pronunciation using an English-language learning software, some English ªlms, and a speech-to-text software engine. The experiment was designed to examine two hypotheses. The ªrst is that speech- to-text software, trained in an appropriate voice, can act as an evaluator of accent and clarity of speech as well as help learners acquire a standard way of speaking. The second is that groups of children can operate a computer and improve their pronunciation and clarity of speech, on their own, with no intervention from teachers. The results of the experiment are positive and point to a possible new pedagogy. It has been assumed that speech-to-text (STT) programs cannot distin- guish good pronunciation and have not been used for this purpose (Goodwin-Jones 2000). However, we propose that STT programs can be used instead of human listeners to evaluate the quality of pronunciation by comparing against a standard accent and pronunciation. The proposi- tion is based on a recent patent application (Mitra and Ghatak 2002). To investigate this hypothesis, we need to discover whether an STT program can judge pronunciation as well as a human can. If an STT pro- gram were demonstrated to be as good as a human judge of pronuncia- tion, it could be suggested that human speakers, particularly children, may be able to improve their pronunciation on their own, using such a program rather than requiring a human teacher. This hypothesis is inspired by, and uses ªndings of, previous research that shows that groups of chil- dren can learn to use computers to self-instruct without teachers (Mitra 1988, 2003; Mitra and Rana 2001). Popularly referred to as the “hole-in- the-wall,” a series of experiments showed that groups of children (8–13 years old) were able to self-instruct in using computers for playing games, surªng the Internet, painting, and other activities, irrespective of their so- cial, linguistic, or ethnic backgrounds. Working in groups and unsuper- vised, free access was important to the self-instructional process. This paper is made up of four parts. First, the reasons there is desirabil- ity for better pronunciation are examined. Second, the research method and results are described, setting out how, where, and when the data were collected. Third, the ªndings of the research are discussed, and ª- nally the paper closes with a conclusion and a vision for the way forward.
Transcript of Improving English Pronunciation: An Automated Instructional Approach

Mitra, Tooley, Inamdar, DixonResearch Reports / Improving English Pronunciation
75
© 2003 The Massachusetts Institute of TechnologyInformation Technologies and International Development
Volume 1, Number 1, Fall 2003, 75–84
[email protected] for Research inCognitive SystemsNIIT LimitedSynergy BuildingIIT CampusNew Delhi, India
[email protected] of NewcastleNewcastle Upon Tyne, England
[email protected] for Research inCognitive SystemsNIIT LimitedSynergy BuildingIIT CampusNew Delhi, India
[email protected] of NewcastleNewcastle Upon Tyne, England
Improving English Pronunciation:An Automated InstructionalApproach
Sugata Mitra,a James Tooley,b
Parimala Inamdar,c and Pauline Dixond
This paper describes an experiment in which groups of children attempted toimprove their English pronunciation using an English-language learningsoftware, some English ªlms, and a speech-to-text software engine. Theexperiment was designed to examine two hypotheses. The ªrst is that speech-to-text software, trained in an appropriate voice, can act as an evaluator ofaccent and clarity of speech as well as help learners acquire a standard way ofspeaking. The second is that groups of children can operate a computer andimprove their pronunciation and clarity of speech, on their own, with nointervention from teachers. The results of the experiment are positive andpoint to a possible new pedagogy.
It has been assumed that speech-to-text (STT) programs cannot distin-guish good pronunciation and have not been used for this purpose(Goodwin-Jones 2000). However, we propose that STT programs can beused instead of human listeners to evaluate the quality of pronunciationby comparing against a standard accent and pronunciation. The proposi-tion is based on a recent patent application (Mitra and Ghatak 2002).
To investigate this hypothesis, we need to discover whether an STTprogram can judge pronunciation as well as a human can. If an STT pro-gram were demonstrated to be as good as a human judge of pronuncia-tion, it could be suggested that human speakers, particularly children,may be able to improve their pronunciation on their own, using such aprogram rather than requiring a human teacher. This hypothesis is inspiredby, and uses ªndings of, previous research that shows that groups of chil-dren can learn to use computers to self-instruct without teachers (Mitra1988, 2003; Mitra and Rana 2001). Popularly referred to as the “hole-in-the-wall,” a series of experiments showed that groups of children (8–13years old) were able to self-instruct in using computers for playing games,surªng the Internet, painting, and other activities, irrespective of their so-cial, linguistic, or ethnic backgrounds. Working in groups and unsuper-vised, free access was important to the self-instructional process.
This paper is made up of four parts. First, the reasons there is desirabil-ity for better pronunciation are examined. Second, the research methodand results are described, setting out how, where, and when the datawere collected. Third, the ªndings of the research are discussed, and ª-nally the paper closes with a conclusion and a vision for the way forward.

Hyderabad is a large city in southern India and, likemany such cities in India, contains sprawling slumareas. These areas in Hyderabad contain a largenumber of small private schools, sometimes as manyas 10 in a square kilometre. These schools are ªlledto capacity with children whose parents pay sub-stantial amounts for education (in comparison totheir incomes) in spite of the fact that there are sev-eral free schools in the vicinity operated by the gov-ernment. The single most important reason the slumparents send their children to these private schoolsis the English language.
There are 17 languages recognized by the UnitedNations, and more than 700 dialects related to theselanguages, spoken in India. Hindi is the national lan-guage, and English is a common “bridging” lan-guage that is used everywhere.
As a consequence of its colonial past, peoplewho speak English are generally considered moresuitable for most jobs than people who do not. Al-though this may not be a happy situation, it is oneof the main reasons India scores over other South-east Asian nations in the software industry. India isthe second largest exporter of software in the worldafter the United States, and its success is often at-tributed to the ability of its industry and its peopleto deal with the English language.
The ability to speak in English can determine theliving standards and occupations of most Indians. Itis for this reason that the private schools in Hydera-bad prosper.
Although these schools teach English with a rea-sonable effectiveness, they suffer from a severemother-tongue inºuence (MTI). The products ofsuch schools, and, indeed, any school in India, canbe ºuent in English but would often speak the lan-guage with an accent that is incomprehensible any-where in the world. The reason for this is becauseteachers in such schools have a strong MTI them-selves, which their students copy, and the problemperpetuates itself. It is in this context that the exper-iment in this study was conducted.
People from all countries are now working and liv-ing in a globalized environment where communica-tion from and to almost anywhere in the world mayoccur practically instantaneously. Labor mobility and
the existence of international employment opportu-nities have heightened the need to communicateand to be understood. The most recent of such ser-vices are in the information technology (IT) enabledservices (ITES) area. These services use communica-tion technology to leverage the (often cheaper)work force of one country to service the require-ments of another. For example, the cost of takingorders on the telephone is cheaper in India than inthe United States because of lower salaries for tele-phone operators. As a result, many U.S. companieshave set up call centers in India, where telephoneoperators take orders for American goods fromAmerican customers, who are unaware that theconversation they are having is with an Indian lo-cated in India. English is generally regarded as thelanguage that can provide this communication uni-versality, so much so that parents know how impor-tant it is for their children to master the Englishlanguage for them to succeed. Moreover, in devel-oping countries it has been found that not only dothe elite and middle classes aspire for their childrento acquire and master English language skills butalso parents from poor slum areas now place greatimportance on their children attaining the ability toread, write, and speak in English. In the privateschools in the low-income areas of Hyderabad, In-dia, for instance, it is shown that the single mostimportant element for parents choosing a privateschool is that it teaches the entire curriculum in theEnglish vernacular (Tooley and Dixon Forthcoming).However, such ambitions are thwarted becausegood-quality teachers (and, in particular, native Eng-lish speakers) are not available to provide, inter alia,good English pronunciation language skills to theirstudents. As a result, even the best students fromthe system have a strong MTI on their English pro-nunciation and their speech is only barely under-standable. This, in turn, affects their employabilityand social status severely, leading to underemploy-ment and, sometimes, crime, poverty, and associ-ated urban social problems.
The need to be understood for cultural as well asITES purposes is the reason behind the undertakingof the experiment. We decided to conduct the ex-periment in an area of great educational need,where untrained teachers were catering to childrenwhose parents were illiterate and where English wasnot widely spoken although greatly desired. The ex-periment sets out to explore two hypotheses:
76 Information Technologies and International Development
Research Reports / Improving English Pronunciation

• Hypothesis 1: The objective measurement ofwords correctly recognized by an STT programclosely parallels subjective human judgments ofpronunciation.
• Hypothesis 2: Given suitable software andhardware, children, and in particular disadvan-taged children, can instruct themselves, with-out requiring a teacher, in the improvement oftheir English pronunciation.
The experiment took place in Hyderabad, India, be-tween September 2002 and January 2003. A com-puter was placed in a private, unaided school (PeaceHigh School, Edi Bazaar), which caters to very low-income families, situated in a slum area of the city.The school fees are between 75 rupees to 150 ru-pees per month (about US$1.50 to US$3 permonth). The school serves children of auto-rickshawdrivers, market traders, and service workers, withapproximate monthly income ranging from 1,000rupees to 3,000 rupees per month. Most familieshave more than one child; hence, the school feescan exceed 25% of the monthly incomes. A sampleof 16 children from different classes in the school,between 12 and 16 years old, were chosen at ran-dom to participate in the study. The school is anEnglish medium school; the entire curriculum istaught in English. The mother tongue of the chil-dren is either Urdu or Telegu. The children could al-ready read and speak English at variable standardsof competency.
The school was provided with a computer. Themulti-media computer was a Pentium P4, 1.8 GHz,256 Mb RAM, with microphone and speakers. Thespecialized software used was “Ellis Kids” and“Dragon Naturally Speaking,” using the WindowsXP operating system. The system was installed in aquiet part of the school. This ensured that thesounds received by the microphone were only thoseof the learners and not external noise. STT programsare often confused in noisy environments.
EllisEllis (www.planetellis.com) is one of the leadingEnglish language learning software programs in themarket, released in 1992. Ellis Kids is its specialized
children’s package. It teaches vocabulary, listening,grammar, and communication skills through multi-media inputs such as video, audio, and text.Learning is tested through multiple-choice ques-tions; the students are also able to test their pronun-ciation by recording a few words of their speechand comparing it with a standard English spokenvoice. Ellis is not equipped with any text-to-speechcapability and is not capable of providing the userwith any feedback on the quality of the learner’spronunciation. Indeed, there is no software at thistime that can do so. However, the focus of Ellis isthe whole of language learning, of which pronunci-ation is a small part.
DragonDragon Naturally Speaking (www.dragonsystems.com) is an STT engine. Dragon can be trained torecognize, interpret, and convert to text a particularuser’s speech. This is done by comparing the audioinput with a stored proªle. To create a proªle, a userhas to read several passages provided by the soft-ware into the computer’s microphone. These read-ings are then converted into a proªle for the user,about 3 Mb in size, which needs to be selected be-fore speech can be entered into the word processingprogram. Naturally, Dragon will best recognize thoseusers’ speech in whose voices it has been trained.This experiment used the Dragon STT programuniquely as a learning and testing tool for Englishpronunciation. Four proªles of speech were createdin Dragon: Pauline, English female, James, Englishmale, Sugata, Indian male, Parimala, Indian female.These were used as pronunciation standards againstwhich students practiced and were measured. Stu-dents read passages into Dragon using any one ofthese proªles. For the ªnal measurements, all malevoices were measured against the proªle Sugata,and all female voices were measured against theproªle Parimala.
FilmsFour ªlms were also installed in the computer as ad-ditional environmental inputs for spoken English.These were The Sound of Music, My Fair Lady, Gunsof Navarone, and The King and I. There are two rea-sons for introducing these ªlms into the experi-ments. First, the students have no reference to howthey should correctly pronounce an English word, al-though Dragon may tell them that their pronuncia-tion is incorrect. By watching 4 hours of ªlms, weexpected them to have heard most of the common
Volume 1, Number 1, Fall 2003 77
Mitra, Tooley, Inamdar, Dixon

English words as spoken by native English speakers.The second reason for selecting these ªlms was tobreak the monotony of practicing a few passagesfrom a school reader everyday. The ªlms were cho-sen because all, except Guns of Navarone, hadsomething to do with education and children oryoung people. Guns of Navarone was chosen be-cause it contains the kind of action that young peo-ple seem to enjoy.
Students, consisting of eight girls and eight boys,were randomly organized into four groups of fourand each group was instructed to spend a total of3 hours per week with the system (Figure 1). Atimetable was made out for this purpose and givento the students.
The students were then given a demonstration ofEllis and Dragon software and were told the namesand locations of the movies stored in the computer.They were given no instructions other than that they
should try to improve their English pronunciation byreading passages from their school English text-books into Dragon and to try to make Dragon rec-ognize as much of their readings as possible. Theywere told to use Ellis if they wished, or to watch anyªlm of their choice on the computer, if bored. It wassuggested to each group that they should help eachother and collectively organize what they would dowith the computer when it was their turn to use it.There was to be no organized adult intervention af-ter this point, except in case of any equipment fail-ure and related maintenance activity. We relied onthe earlier results (Mitra 1988, 2003; Mitra andRana 2001) that groups of children can instructthemselves without teachers if given adequate com-puting resources. In effect, the children were leftwith a clear objective (to alter their speech until un-derstood by the Dragon STT program) and a demon-stration of the resources available (i.e., computer,Dragon, Ellis, and movies). They were asked to orga-nize themselves to meet this objective and they
78 Information Technologies and International Development
Research Reports / Improving English Pronunciation
Figure 1. Children at Peace High School, Edi Bazaar, Hyderabad, India, working on their computer.

readily agreed to try. Indeed, they agreed with greatenthusiasm.
The experiment was started in September 2003.Each month, a researcher visited the school andasked all 16 children to read passages from a stan-dard English textbook into the Dragon STT program.From October, they took measurements of the stu-dents’ reading, comparing the resultant text pro-duced by Dragon with the correct text, andcalculated the percentage of correctly identiªedwords. Each passage was of approximately 100words. The text produced by Dragon was done us-ing girls’ readings compared against the Parimalaproªle, whereas the boys’ readings were comparedagainst the Sugata proªle. Dragon performs poorlywhen a female proªle is used to judge a male voiceand vice versa. This is because of obvious frequencydifferences in male and female voices. It is interest-ing to note that, for very young children of eithergender, a female proªle should be used for thesame reason.
Each month, starting in October, a new passagewas added to the one in the previous month; thatis, the children read one passage in September andOctober, two in November, and so on until January2003, when they read four passages. This was doneso that their pronunciation in the ªrst passage,which they read four times in the 4 months sinceOctober, could be compared with their pronuncia-tion in the fourth passage, which they read for theªrst time in January.
It should be mentioned that there were interrup-tions in the school calendar because of examinationsand holidays during the experiment, which reducedthe learners’ time spent at the computer. We esti-mate that each child spent between 10 and 15hours on the computer during this period. Mea-surements were taken at monthly intervals fromSeptember 2002 to January 2003; that is, ªve mea-surements in total. In the ªrst month, the studentsused Ellis only, and they began using Dragon in Oc-tober. This was unavoidable because the Dragonprogram was unavailable before October.
A video clip was made of each child reading eachpassage in each of these monthly sessions. Thevideo clips were recorded so that human judgeswould be able to watch and rank the pronunciationsof the children reading the passages. At this point it
is important to explain why we chose to record thereadings using video, and not just audio, as themedium.
The ªrst hypothesis, as described earlier, is to de-termine whether an STT program, such as Dragon,would score and rank the pronunciations of humanspeakers such that these scores and ranks are similarto those by human judges. That is, the judgment ofthe STT program and of human judges should showconcordance. Because Dragon is “judging” pronun-ciation only by “listening” to the speakers, it wouldseem natural that the judging process for humansshould also use only the audio from each speaker.After all, it is possible that a human judge wouldscore differently if he or she were to be looking at aspeaker or only listening to a recording of aspeaker’s voice during the judging process.
Some reºection shows that this reasoning is in-correct in the current context. First, we can ªnd noevidence that the human judgment of pronunciationis affected by whether the judge is only listening toa voice or looking at the speaker. Second, an STTprogram such as Dragon can neither “listen” nor“judge” in any manner that can be remotely com-parable to the process followed by humans. Humansprocess speech and vision in a way that is, as far ascurrent understanding goes, different from the waycomputers do (e.g., see Bhatnagar et al. 2002).Dragon does not listen; it receives a stream of bits(zeros and ones) and processes them mathematicallyagainst another stored array of bits—the “proªle.”It is therefore futile to try to give the humans and anSTT program the “same” input, in this case, audio.What is more relevant is that the STT programshould be shown to behave as an instrument thatcan measure pronunciation in a way such that itsmeasurements reºect the same values as those pro-duced by human, subjective judgment. A measuringinstrument does not necessarily have to measure thesame parameter as a human being to come to simi-lar conclusions. For example, an EEG machine candetect an epileptic attack by measuring electricalsignals from the patient’s brain, whereas a humanbeing can detect the same attack by other, subjec-tive audiovisual means.
In the present context, what we wish to study inthe children is their clarity and pronunciation in spo-ken English as judged by other humans. In society,such judgments are made more often in face-to-facesituations than otherwise. Indeed, in the present
Volume 1, Number 1, Fall 2003 79
Mitra, Tooley, Inamdar, Dixon

context of the children of Hyderabad, India, thejudgment of the effectiveness of their spoken Eng-lish will be almost entirely done by others who arein their presence. Although it is conceivable thatsuch a judgment may be made over telephone orsome other media where the speaker is not presentvisually, it is not considered an important or relevantfactor for the present experiment.
We have therefore presented the human judgeswith video clippings of the children reading, to beclosest to the social context in which their Englishwill be judged in real life. Dragon, on the otherhand, has been presented with audio bit streams ofthese readings (in the 44 KHz, mono .wav format),which is the only input it can accept.
Sometimes, some of the children were absent fora session and their data could not be collected. Al-though this is undesirable, it did not affect morethan 10% of the planned readings. The data at theend of the experiment consisted of 16 children’sreading of passages 1, 2, 3, and 4 over 5 months,for a total of 160 readings, 160 resultant text ªlesfrom Dragon, and 160 video clips.
Analysis of data was done at the end of the experi-ment. At this time, the children were ranked foreach of the readings in each of the months in orderof the percentage of words correctly identiªed byDragon, for each passage.
The video clips were labeled and randomized,and viewed by four human judges, who are the au-thors of this paper. Each judge, while viewing avideo clip, was unaware of when the recording hadbeen made. Because the process of scoring wasdone only once, at the end of the experiment, itwas important that the judges be unaware of thedate of each recording. The judges then scored eachvideo clip in terms of their subjective assessment, ona score of 1 to 10 (10 high), of how well each childperformed in English pronunciation, including clarityof speech and accent. Eventually, the scores ob-tained were used to rank the children according toeach judge.
It is important to establish ªrst that the humanjudges are, themselves, in agreement with eachother before proceeding to match their rankingswith that of Dragon. Kendall’s coefªcient of concor-dance (Siegel 1956) was calculated for the fourjudges for each of the 5 months for this purpose.
Kendall’s coefªcient, W, is considered more effectivefor smaller samples (less than 30) than Cohen’skappa for measuring concordance.
The same coefªcient (W) was also calculatedwith Dragon acting as a “ªfth judge”; that is, theranking obtained from the process using Dragonwas added to those obtained from the four humanjudges.
A control group is needed to verify the second hy-pothesis. However, it was difªcult to obtain a con-trol group at the beginning of the experiment. Anychild tested for pronunciation would want to be apart of the experimental “course,” as they perceivedit. Because the equipment would be left in chargeof the children and no adult control would be im-posed on them, it would be impossible to monitor ifany child from the control group was also joiningthe experimental group. Based on advice from theschool principal, we decided to not measure anychild other than those chosen for the experimentalgroup. These children were instructed not to letother children use the computer, an instruction theyfollowed meticulously. As a result, no control groupwas tested at the beginning of the experiment, andthis creates limitations to the generalizability of theresults. The following method was adopted to rec-tify this situation.
At the end of the experimental period (January2003), 16 children were selected at random fromthe same sections of the same school as those fromwhich the experimental groups had been selected.These children were aware of the fact that some oftheir peers were working on a computer, but theyhad no other information about what they were do-ing. Neither did this new group of children have anyexposure to computers or to any other teaching-learning method other than that used traditionallyby the school. Therefore, the only difference be-tween the new (control) group and our experimentalgroup was that the latter had worked on the com-puter as described earlier for 5 months. The controlgroup was asked to read out three passages from astandard English textbook, and a video clip was pro-duced for each reading session.
It was now necessary to establish whether thescores of the children using Dragon and Ellis for5 months were signiªcantly different from those ofthe children who had not. To do this, we decided to
80 Information Technologies and International Development
Research Reports / Improving English Pronunciation
use four new judges to remove any bias, becausethe previous judges were already familiar with theexperimental group, having visited the school manytimes. In this context, a judge has to be someonewhose English pronunciation is of an acceptablestandard. All judges chosen were such that theirown recognition rates in Dragon were 60% ormore. Incidentally, the best STT programs, includingDragon, generally show a recognition rate of 85%or less, even when used by the same person whohas trained it.
Four new judges were selected and presentedwith a collection of 48 video clips: 16 from the ex-perimental group’s readings of September 2002, 16from the experimental groups readings from January2003, and 16 from the control groups readings ofJanuary 2003. The clips were presented to thejudges in random order to ensure that they had noway of determining either the nature of the group(experimental or control) or the time of the video re-cording. Each reading was given a score from 1 to10 (10 high) for the same subjective parameters asused earlier by each judge. The average scores foreach group of 16 readings were calculated, thereadings were converted to ranks, and the Kendall’scoefªcient of concordance was calculated for thefour new judges.
Table 1 shows the results for the Kendall’s coefª-cient of concordance. This table reveals two interest-ing factors. First, the human judges, although judg-ing subjectively, were in very strong concordance,with W ranging from 0.79 in October to 0.94 inJanuary, with p � 0.001 in every case. Second, theaddition of the ªfth judge, Dragon, did drop the
coefªcient of concordance, but it remained at asigniªcant degree of concordance, ranging from0.69 in November to 0.81 in January, withp � 0.001 again.
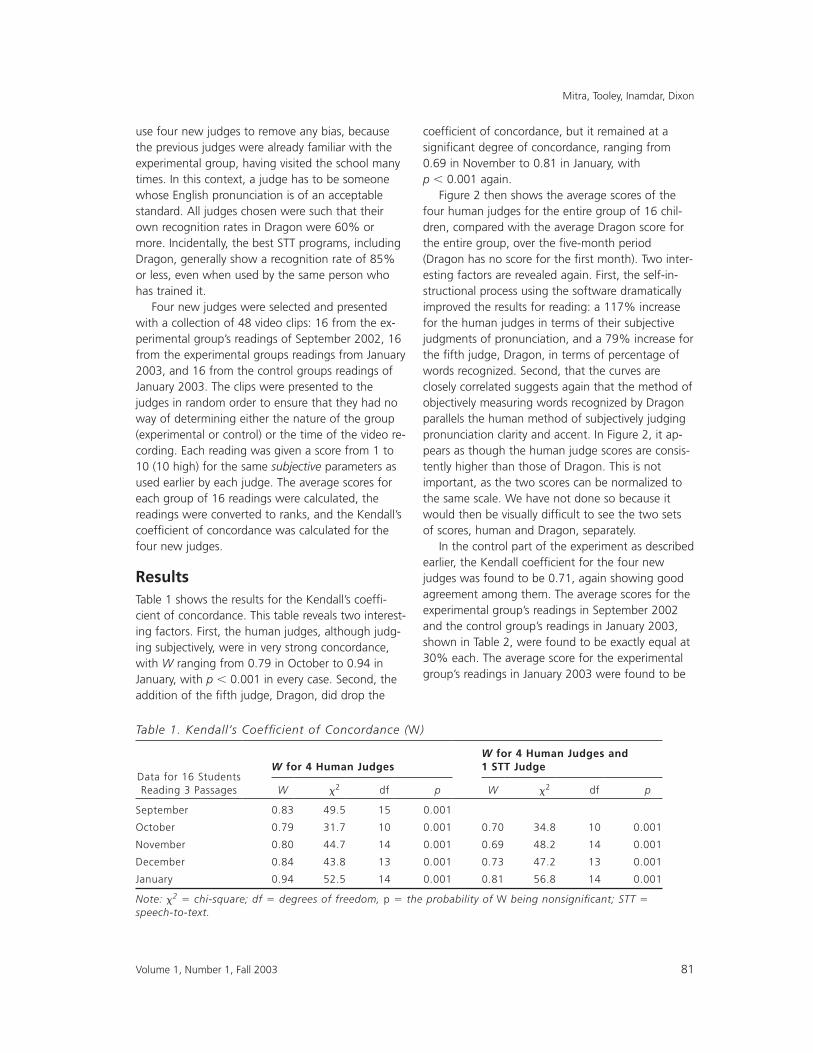
Figure 2 then shows the average scores of thefour human judges for the entire group of 16 chil-dren, compared with the average Dragon score forthe entire group, over the ªve-month period(Dragon has no score for the ªrst month). Two inter-esting factors are revealed again. First, the self-in-structional process using the software dramaticallyimproved the results for reading: a 117% increasefor the human judges in terms of their subjectivejudgments of pronunciation, and a 79% increase forthe ªfth judge, Dragon, in terms of percentage ofwords recognized. Second, that the curves areclosely correlated suggests again that the method ofobjectively measuring words recognized by Dragonparallels the human method of subjectively judgingpronunciation clarity and accent. In Figure 2, it ap-pears as though the human judge scores are consis-tently higher than those of Dragon. This is notimportant, as the two scores can be normalized tothe same scale. We have not done so because itwould then be visually difªcult to see the two setsof scores, human and Dragon, separately.
In the control part of the experiment as describedearlier, the Kendall coefªcient for the four newjudges was found to be 0.71, again showing goodagreement among them. The average scores for theexperimental group’s readings in September 2002and the control group’s readings in January 2003,shown in Table 2, were found to be exactly equal at30% each. The average score for the experimentalgroup’s readings in January 2003 were found to be
Volume 1, Number 1, Fall 2003 81
Mitra, Tooley, Inamdar, Dixon
Table 1. Kendall’s Coefªcient of Concordance (W)
Data for 16 StudentsReading 3 Passages W �2 df p W �2 df p
September 0.83 49.5 15 0.001
October 0.79 31.7 10 0.001 0.70 34.8 10 0.001
November 0.80 44.7 14 0.001 0.69 48.2 14 0.001
December 0.84 43.8 13 0.001 0.73 47.2 13 0.001
January 0.94 52.5 14 0.001 0.81 56.8 14 0.001
Note: �2 � chi-square; df � degrees of freedom, p � the probability of W being nonsigniªcant; STT �speech-to-text.
signiªcantly higher at 72%. This is shown in Fig-ure 3.
It may be noticed that STT (Dragon) scores werenot used in this part of the measurement. This is be-cause the purpose of these measurements was tocompare the results of the experimental and controlgroups alone. Therefore, correlating these with STTresults was not required in this part of themeasurement.
The results are interesting for both of the hypothe-ses. Regarding the ªrst, the high concordance valuesshown in Table 1 seem to indicate unequivocallythat the method of using the objective measure ofpercentage of words correctly recognized by Dragonclosely mimics the human process of subjectivelyjudging children’s pronunciation. This seems to be
an important result, with possibly signiªcantimplications for the automation of the judgment ofpronunciation. Another intriguing possibility is thatof automatically detecting speakers with a certainaccent.
The procedure followed with the control groupand four independent judges shows clearly that thecontrol group’s scores at the end of the experimentin January match the experimental group’s scores atthe beginning of the experiment in September. Inother words, the control group children, with no ex-posure to the experimental apparatus and proce-dure, continued to have pronunciations similar tothose of the experimental group children beforethey began their interaction with the computer andsoftware. The experimental group, on the otherhand, showed signiªcant improvement after the ex-perimental period.
82 Information Technologies and International Development
Research Reports / Improving English Pronunciation
Figure 2. Improvements in pronunciation as measured by human judges and by a speech-to-text program.
Table 2. Independent Comparison of Experimental and Control Group Scores
Description of Video Clips Average Percent Scores from 4 Judges
Experimental Group, September 2002 30
Experimental Group, January 2003 72
Control Group, January 2003 30

Ideally, we should have scored the control groupat the beginning of the experiment as well. How-ever, because this could not be done and because itis very unlikely that the control group’s scores at be-ginning of the experimental period could have beenhigher than at the end of the period, we propose onthe basis of Figure 3 that the improvements in pro-nunciation observed in the experimental group ofchildren were caused by the experimental proce-dure. The fact that this is supported by an inde-pendent, randomized judging process furthersupports this contention.
It seems highly unlikely that such improvementsin pronunciation could have been effected by otherthings in the school or slum environment. Theschool principal corroborated that he had noticedsigniªcant improvements in the language ability ofthese children but not others. Certainly, we can saythat when groups of children are given the appropri-ate resources, they can improve their pronunciationwith minimal intervention from adults. Further workis required to see to what extent their improvementwas based on which parts of the software packagesused (Ellis, Dragon, or, indeed, My Fair Lady!) andthe degree to which these improvements exceedthose that might be expected over time withoutsuch interventions.
Yet another possibility emerges from these re-sults. It appears that, using an STT system, childrencan acquire any kind of accent, because the accent
acquired is similar to the one in which the system istrained. ■
We would like to thank Mr. Wajid, principal of PeaceHigh School, Edi Bazaar, Hyderabad, India, for hissupport for this experiment. Detailed commentsfrom one of the referees were invaluable and re-sulted in a dramatic improvement in the paper.
Bhatnagar, G., S. Mehta, andS. Mitra, eds. 2002. Intro-duction to Multimedia Systems. San Diego,
Calif.: Academic Press.
Eastment, D. 1998. ELT and the New Technology:The Next Five Years. Retrieved fromwww.eastment.com.
Ehsani, F. and E. Knodt. 1998. “Speech Technologyin Computer-Aided Language Learning: Strengthsand Limitations of a New CALL Paradigm.” Lan-guage Learning & Technology 2:45–60.
Goodwin-Jones, B. 2000. “Emerging Technologies:Speech Technologies for Language Learning.”Language Learning & Technology 3:6–9.
Mitra, S. 1988. “A Computer-Assisted LearningStrategy for Computer Literacy Programmes.” Pa-per presented at the annual convention of the
Volume 1, Number 1, Fall 2003 83
Mitra, Tooley, Inamdar, Dixon
Figure 3. Scores of experimental and control groups in different months asmarked by four independent judges.

84 Information Technologies and International Development
Research Reports / Improving English Pronunciation
All-India Association for Educational Technology,Goa, India.
Mitra, S. 2003. “Minimally Invasive Education: AProgress Report on the ‘Hole-in-the-wall’ Experi-ments.” British Journal of Educational Technology34:367–371.
Mitra, S. and R. Ghatak. 2002. “An apparatus formeasuring clarity of spoken English,” Indian pat-ent application number 1159/DEL/2002, Novem-ber 18.
Mitra, S. and V. Rana. 2001. “Children and theInternet: Experiments with Minimally Invasive Ed-
ucation in India.” The British Journal of Educa-tional Technology 32:221–232.
Siegel, S. 1956. Nonparametric Statistics for the Be-havioural Sciences. New York: McGraw-Hill.
Stark, D. G. 1997. Hal’s Legacy: 2001’s Computer asDream and Reality. Cambridge, MA: MIT Press.
Tooley, J. and P. Dixon. Forthcoming. “Providing Edu-cation for the World’s Poor: A Case Study of thePrivate Sector in India,” in B. Davies and J. West-Burnham, eds., Handbook of Educational Leader-ship and Management. Victoria, Australia:Pearson Longman.




















