
Impoliteness in CMC: Differences in trolling of men’s rights activists vs. trolling of feminists
20
Rheinische FriedrichWilhelmsUniversität Bonn Institut für Anglistik, Amerikanistik und Keltologie Impoliteness in CMC: Differences in trolling of men’s rights activists vs. trolling of feminists Hausarbeit für Corpora and Pragmatics (Nr.: 506022101) Wintersemester 2012/13 Prof. Dr. Klaus Peter Schneider & M.A. Susanne StrubelBurgdorf Felix Metzger Matrikelnummer: 1587146 Ellerstr. 103, 53119 Bonn [email protected] Abgabedatum: 20130315 1
Transcript of Impoliteness in CMC: Differences in trolling of men’s rights activists vs. trolling of feminists

Rheinische FriedrichWilhelmsUniversität Bonn
Institut für Anglistik, Amerikanistik und Keltologie
Impoliteness in CMC: Differences in trolling of men’s rights activists
vs. trolling of feminists
Hausarbeit für
Corpora and Pragmatics (Nr.: 506022101)
Wintersemester 2012/13
Prof. Dr. Klaus Peter Schneider & M.A. Susanne StrubelBurgdorf
Felix Metzger
Matrikelnummer: 1587146
Ellerstr. 103, 53119 Bonn
Abgabedatum: 20130315
1

1. Introduction 3
2. Literature Review Toward a working definition of trolling4
3. Method 5
3.1 Corpus Design 6
3.2 Coding 8
4. Results 9
4.1 Why the quantitative approach failed 9
4.2 SRSC 10
4.3 MRC 13
5. Comparison 15
6. Conclusion 16
7. Works Cited 17
7.1 Primary Sources 17
7.2 Secondary Sources 17
7.3 Software used 18
8. Appendix 19
2

Disclaimer:
I am intentionally breaking a few conventions from the term paper guidelines in hope to make my
text better and more readable. For example, I vehemently disagree that academic English has to feature
relatively complex sentence structures, and avoid high frequency vocabulary this is an antiquated concept
that produces overly dense, hardtoread text. Instead, sentences will only be as complex as they have to be
to communicate my ideas clearly. They also will be as explicit and straightforward as possible which is
something that short sentences do better than long ones anyway.
Additionally, I will employ the active voice and the personal pronoun ‘I’ wherever the passive voice or
other impersonal constructions would complicate the sentence structure too much. I will also structure the
bibliography into subchapters, because presorting for datatype enables quicker access as long as there is
not too much data (then alphabetical would be better).
Lastly, I will break citation guidelines, because it is actually crucial for my paper. Since Reddit’s
structure is different from other online forums, and also allows for richtext formatting, it is important to
retain as much digital authenticity as possible. I want my quotations to stay as close to their original form as
possible, because the fewer layers of remediation there are, the better. My approach is closely influenced
by Twitter’s tweetembedding guidelines (cf. Twitter Staff 2013). I’ll insert quotations as screenshots, with
their original responsive formatting design intact, and their metadata shown.
1. Introduction
Computermediated communication is an active area of research that provides ample
opportunities for freshfaced students to find an interesting niche to make their own. Along
with its many advantages in comparison to older forms of communication, it also has a few
disadvantages that contribute to the emergence of new pragmatic phenomenons. As a
frequent participant in internet forums, I have found trolling to be the most interesting of the
bunch. Linguistically, trolling belongs into the area of impoliteness research. It is also
notoriously hard to define and quantify, but after finding Claire Hardaker’s article (2010) on
the topic, I felt confident to use her methodology as a blueprint for my paper.
With its recent resurgence in publicity in the media and online, and with our study
3

program’s focus on similar cultural issues, feminism was an obvious choice as a target of
this methodology. To spruce things up a bit, because the idea of struggle is deeply
embedded in many definitions of culture, and to avoid a lopsided approach, a comparison
with a counterideology seemed beneficial. The obvious counterideology to feminism is
the men’s rights movement. Reddit one of the leading internet forum platforms features
subforums (subreddits, in Reddit jargon) for feminists and for men’s rights activists, so I
chose to compare r/ShitRedditSays (feminists) with r/MensRights. For that purpose, I
created two corpora with about 1.7 million words each.
Consequently, this paper is a contrastive study in the field of intracultural
variational pragmatics. After a short literature review, considerable focus will be given to
methodology and corpus design, since a lot of dangers were averted there. Also, the initial
research proposal called for quantitative and qualitative analysis, but the quantitative part
proved impractical. The reason why will be explained in a separate chapter of the results
section. After that, the trolling cultures of r/ShitRedditSays and r/MensRights will be
analysed individually. These results will be compared in the subsequent chapter and finally,
the conclusion will provide an outlook on possible related future research projects.
Fair warning: This paper is rather light on pragmatic theory. Instead, the focus is
shifted toward practical concerns like corpus design and the cultural particularities of the
examined subreddits.
2. Literature Review Toward a working definition of trolling
The one complaint commonly found in all research on trolling is that there is not a lot of
research on trolling. Most commonly cited is Judith Donath’s 1999 article “Identity and
deception in the virtual community,” Unsuprisingly, it focuses on questions of identity and
anonymity, how trolls take on specific roles to deceive others. While her observations are of
merit, they are in dire need of updating, because newsgroups are basically dead today,
and have been for almost a decade. Even Hardaker in her 2010 article bases her research
on a newsgroup corpus. The reason behind this is most likely that newsgroups are easier
to index than other forms of internet forums, but with the recent APIrevolution, new fields for
research should open up soon. See the conclusion, for a more detailed explanation.
4

Apart from the use of antiquated corpora, it is equally striking that there is a lot of
nonscientific online articles on trolling, but little academic research. Existing academic
research mostly deals with trolling as a sidenote. Maybe it is because of that lack of
academic groundwork, that even Hardaker who has “trolling” in the title of her article has
to spend ten pages on the particularities of linking impoliteness theory to CMC, before she
can turn to trolling. Her literature review consists of a single page where she, too, presents
the lack of academic research.
Research on trolling is still in the phase of agreeing on a definition. Donath gave the
first definition: “Trolling is a game about identity deception, albeit one that is played without
the consent of most of the players” (1999: 14). Next to Donath, there is Susan Herring et
al’s definition: “Trolling entails luring others into pointless and time consuming
discussions.” (2002: 372) These are both useful definitions, but fail to encompass the
modern turn trolling has taken. They are both stepping stones to Hardaker’s fourpart
definition (2010:22f), which incorporates them and adds the useful methodological
categorization I will use to analyze my corpora. Quoted in full:
A troller is a CMC user who constructs the identity of sincerely wishing to be part of the group in question, including profess ing, or conveying pseudosincere intentions, but whose real intention(s) is/are to cause disruption and/or to trigger or exacerbate conflict for the purposes of their own amusement. Just like malicious impoliteness, troll ing can (1) be frustrated if users correctly interpret an intent to troll, but are not provoked into responding (cf. example 35), (2) be thwarted, if users correctly interpret an intent to troll, but counter in such a way as to curtail or neutralize the success of the troller (cf. examples 4446), (3) fail, if users do not correctly interpret an intent to troll and are not provoked by the troller, or, (4) succeed, if users are deceived into believing the troller’s pseudointention(s), and are provoked into responding sincerely (cf. example 39).
It’s striking that this part reads like a further condensed version of Hardaker’s
literature review. I looked for other academic articles on trolling, but did not find any
(academic) ones she had not mentioned. Consequently, my literature review is closely
based on hers, but I added some metainformation to justify its existence.
3. Method
5

The methodology of this paper is closely based on Claire Hardaker’s four types of trolling
that she defines in her 2010 article. They are: deception, aggression, disruption, and
success. These categories will be used to code any instance of “troll*” in two selfmade
corpora: one based on the subreddit “ShitRedditSays” (SRS), which is an activist feminist
forum. The other is based on the subreddit “MensRights” (MR) which is the counterpart to
SRS.
The original plan was to do a qualitative and quantitative approach. However, it
became apparent during coding that the quantitative part just was not going to work. I’ll
explain the reasons for this in chapter 4. Instead, the focus will be on the qualitative
approach. I’ll provide a few representative examples of the two subreddits and compare in
which ways their trolling cultures differ from each other.
Another methodological disclaimer has to taken into account: according to
Hardaker, one central methodological disadvantage of research on trolling is that “no
search is currently able to retrieve offrecord references to trolling.” (2010:11) This applies
to her study and to mine. I will give a perspective on how to do it better in the conclusion,
but for practical reasons this paper is restricted to her simplified methodology.
3.1 Corpus Design
Since there were no corpora of r/MensRights and r/ShitRedditSays, I had to create them.
Thankfully, Reddit makes it easy to see the most popular threads of any given subreddit:
you just have to add “top” to the URL. This is also exposed at the top of the page, next to
the title. It is possible to further restrict top threads from specific time periods like “last
week” or “last year,” but “all time” promised the broadest results.
Another possible option would have been to filter not for most popular posts, but for
the most controversial ones. However in contrast to the “top” category the algorithm used
to determine how controversial a thread is, is not immediately apparent, nor explained on
the site. Also, r/MensRights choses not to expose the link to controversial posts in the UI.
Even though it is still accessible via appending “controversial” to the URL, it is less likely to
be place with significant trolling activity because the moderators and users of the
subreddit apparently do not care for it. The most controversial threads were also much
6

shorter than the most popular ones. Since trolls need to maximize their chances of luring in
gullible prey, searching for them in the bigger and more exposed most popular threads
seemed the smarter way.
Having found a target, I took the 50 most popular threads of r/MensRights and saved
them as individual full webpages on my PC, using Google Chrome. Textonly saving was
not an option, because the comment hierarchy would have been lost. Not being able to
ascertain which commenter replied to which post would have made proper coding
impossible. I also had to pay 3.99$ for a onemonth “Reddit Gold” subscription, because
nonpaying users can only access 500 comments from a given thread, while subscribers
can view up to 1500. Since some of the most popular threads had over 1000 comments,
this was a nobrainer. This procedure netted 1702567 words for the r/MensRights Corpus
(MRC), before cleanup. For the r/ShitRedditSays Corpus (SRSC), 50 threads were not
sufficient to produce a comparable number of words. Since the female group has less
traffic than its male equivalent (for reasons I’ll explain in the discussion), my initial approach
to make a literal 50/50 comparison did not work. So I bumped up the number of threads for
the SRSC to 74, which netted 1679166 words after cleanup a close enough
approximation.
I’ve mentioned cleanup twice now, without further explanation. The procedure used
was twofold:
First, I loaded all htmlfiles into Textwrangler, and batchremoved lines 5169 from every
single file by globally finding them and replacing them with “ ”. That got rid of most of the
sidebar, including the FAQ which would have otherwise been included in every thread.
Sadly, it did not vanquish the whole sidebar the list of moderators and worse, the list of
recently viewed threads still remained.
Due to my limited knowledge of HTML I wasn’t able to batchremove these parts
because they were encoded in long and complicated tag strings. So, I asked a friend of
mine who is a web developer for help. He showed me how to find the code responsible for
the rest of the sidebar with the Firebug extension for the Firefox webbrowser. To painlessly
remove the unneeded code, he wrote a PHPscript to remove it. This script worked similar
to my manual Textwrangler method: it removed the code by finding and subsequently
deleting it. It had to be more sophisticated than Textwrangler, though: While the blocks
deleted with Textwrangler were static, the blocks the script needed to delete contained
7

dynamic parts. By using regular expressions basically a much more powerful and
customizable version of variables like “*” or “?” we succeded in deleting these dynamic
parts and completely removing the sidebar. The script is reprinted in the appendix.
Lastly, to facilitate easier linguistic coding, it was necessary to improve the legibility
of the corpus:
The Chrome plugin “Reddit Enhancement Suite” (RES) colorcodes comment
hierarchy and enables collapsing unnecessary comment subthreads. It also allows
disabling custom CSSstyles, which was important for SRSC, because r/ShitRedditSays
has a particular subreddit CSS style, which allows users to only downvote its links, hence
its nickname ‘the downvote brigade’. These downvotes are actually upvotes, though,
intentionally obfuscating readability. Thankfully, it is possible to turn off the custom CSS by
unticking the ‘use subreddit style’ checkbox provided by RES. For maximum compatibility
with MRC, the normal style had to be used.
According to AntConc, each of the resulting corpora is roughly 1.7 million words big. A
Textwrangler multifile search for “permalink” (a reasonably uncommon word that is
included in every individual post by the system) nets about 19235 (MRC) and 20853
(SRSC) hits. Random sampling of a few threads indicates that this searchmethod is not
onehundred percent precise, but the margin of error is in the low singledigits. Therefore, it
is a sufficient approximation for the number of individual posts in the corpora.
3.2 Coding
One of the amenities of Reddit’s comment threads is the way they are visually structured.
Instead of the multiline headers and footers frequently found in other internet forums that
artificially blow up the size of each post, Reddit restricts the metainformation and
actionable elements to one single line above the content, and one single line below it.
These lines are even further deemphasized because they use a smaller font size than the
content of the post. Replies to a post are indented, which is the simplest way to visually
show the comment hierarchy.
Thanks to these measures, Reddit is supremely readable for humans but not for
AntConc. The file view is completely unusable, because the comment hierarchy is lost, as
8

Reddit only links post visually and not by textual clues like “in reply to R’s post.” Therefore, I
could use AntConc only for general wordcountery; for the actual coding process, I needed a
different tool. Since I had saved the threads as individual HTML files, the sensible choice
was to use Google Chrome again to manually search each file for the string “troll*”. Each hit
was coded by giving it one or more attributes from the following matrix:
deception The troller seems to need something explained to him, but it is unclear whether his intentions are honest or whether he is trying to deceive.
aggression The troller is blatantly attacking other posters. This is closely related to flaming.
disruption The troller tries to disrupt the group, for example by stalling and going on argumentative tangents which have nothing to do with the issue at hand.
success A successful attempt at trolling where the troller succeeded by getting a victim to take his trolling seriously.
+success A successful trolling attempt that is identified and applauded by other posters. For example, if it was particularly funny.
success A failed trolling attempt that is identified and negated, often by countertrolling or even deletion through a moderator.
meta (Meta)Talk about trolling or trollers.
0 Anything that does not fit into the other categories and that also does not come up repeatedly to warrant a new category.
4. Results
I will start this chapter off with a rather elaborate explanation why the quantitative approach
failed, which offers its own crucial insights into the limitations of Corpus research in CMC.
After that, I will present my qualitative findings from the SRSC and the MRC.
4.1 Why the quantitative approach failed
The first result that presented itself during coding is actually a negative one: It became clear
9

that the quantitative approach did not work with this methodology. Hardaker’s categories
are not clearly delineated enough, and blend into each other frequently. While she had
mentioned blurring between aggression and disruption in her article (cf. Hardaker 2010:
233), my coding revealed other deficiencies that made the a quantitative analysis highly
impractical:
Reddit is a very modern internet forum, that is substantially more advanced than its
newsgroup ancestors which Hardaker analysed. Redditors are in general very aware of
trolls, and frequently discuss trolling even though no direct troll has taken place in the
immediate thread. This led me to add the meta category to the coding scheme, which
quickly became the most prevalent category by a very large margin. The meta and success
categories like Hardaker’s aggression and disruption categories blurred significantly,
which led me to open up the coding scheme to allow double tagging: instead of being only
allowed to belong into either the meta or the success category, a post could also belong
into to both. This complicated the coding considerably.
Another methodological pitfall I encountered was the prevalence of countertrolling.
For every successful or insuccessful trolling attempt, there were often multiple countertrolls,
which quickly became too overwhelming to count properly. I had to limit myself to only allow
up to three degrees of separation from the “troll*”hit. That is to say, if I saw another troll or
countertroll that was not part of the subthread which included the “troll*”hit, I ignored it. And
even if it was part of the thread, if it was more than three replies removed from the hit, I still
did not count it. A higher search depth would have been better, but was simply not
manageable for the scope of this paper.
The final nail in the quantitative approach’s coffin was a mixture of both
aforementioned problems. One of HTML’s defining features is the ability to include
hyperlinks to external webpages. This means, that it is possible to not only troll or
countertroll internally, i.e. in the subthread, the thread or the whole subreddit, but also to
troll externally, in other subreddits, other internet forums or even in online newspaper
articles and interviews. To sufficiently capture those kind of trolls, it would have been
necessary to add external and internal to the metacategories of my coding scheme and
consequently triple tag every trolling instance. Additionally, the search depth would have
had to be increased by a whole new dimension, which would have also multiplied the
results the effort needed to obtain them.
10

With the blurred category definitions and the large breadth of deliberately overlooked
trolling instances, I am not confident in the quantitative accuracy of my numbers. Therefore,
the quantitative approach must be scrapped. Instead, as has been said in chapter 3, the
focus now lies on the qualitative analysis of the trolling cultures of r/ShitRedditSays and
r/MensRights in the following subchapters, and on the comparison between them in chapter
5.
4.2 SRSC
(GoatPostman 2012)
SRS is a very specific group, that has evolved some interesting new ways of trolling. Let’s
start with an ordinary troll:
11

In this case, noitulove is a classical deception troll, who tried to start a pointless discussion
in the (notpictured) original post. Instead of indulging him however, he is
tripledisruptioncountertrolled by a nowdeleted user. Behavior like this that falls into the
successcategory was very common. Due to SRS’s tendency to identify and countertroll,
normal trolls are rarely seen there.
Instead, thanks to the troll positive culture of the group, there were an unusual
number +success trolls like this one:
Trolling is rarely described as a positive feature of a group. It is remarkable that SRS
employs positive trolling as a communitybuilding device. They have even evolved a new
kind of trolling: the circlejerk
12
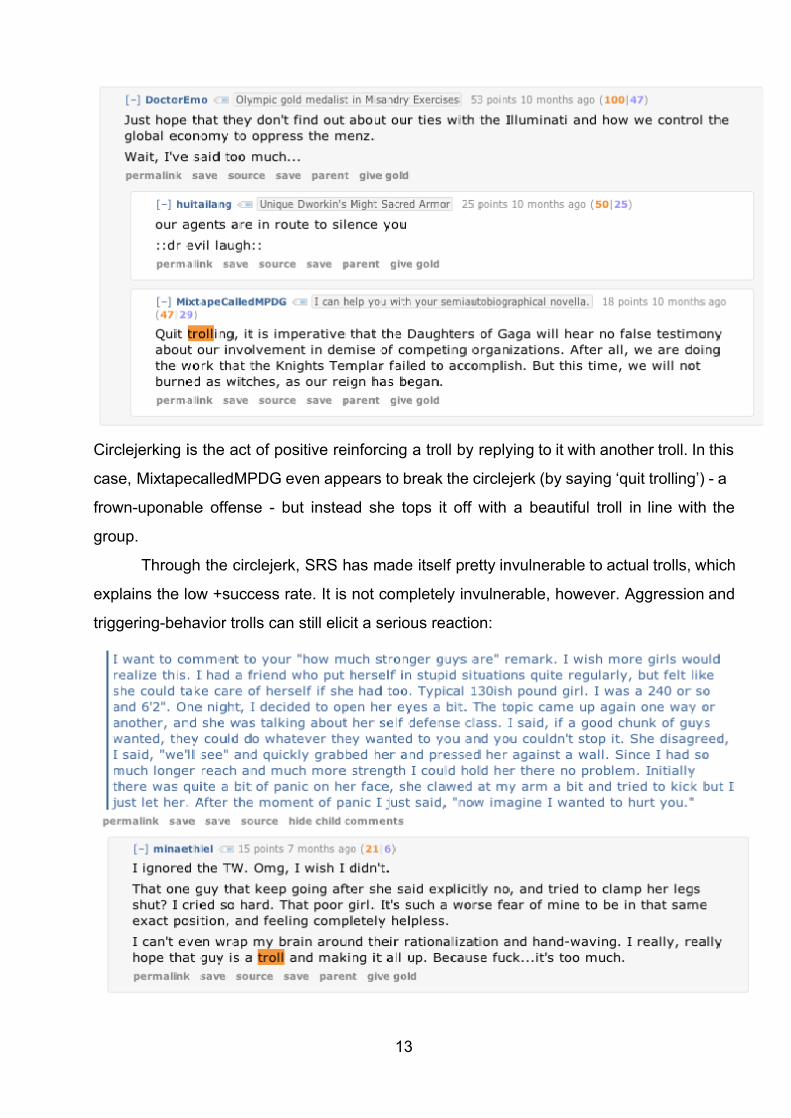
Circlejerking is the act of positive reinforcing a troll by replying to it with another troll. In this
case, MixtapecalledMPDG even appears to break the circlejerk (by saying ‘quit trolling’) a
frownuponable offense but instead she tops it off with a beautiful troll in line with the
group.
Through the circlejerk, SRS has made itself pretty invulnerable to actual trolls, which
explains the low +success rate. It is not completely invulnerable, however. Aggression and
triggeringbehavior trolls can still elicit a serious reaction:
13

Since SRS also functions as a support group for women, blatant abuse is still effective.
This is an external troll, however. If somebody had posted this in SRS, the moderators
would have deleted the comment and banned him.
Incorporating external trolls are another typical feature of SRS. They quote misogyny
from other subreddits and mock it internally, while some even venture into the external
subreddit and downvote the offending post. Downvoting has the effect of decreasing the
relevance of a post. The score of an individual post is calculated by subtracting the number
of downvotes from the number of upvotes. If the result is below 4, Reddit even
automatically hides that post.
To recap, SRS is a community of trolls which is rarely get trolled themselves, but often
venture outside of their own subreddit to troll others. According to themselves, they are very
successful at that. The most prevalent category I found was the metacategory, by a large
margin. Considering my above findings, this was not surprising. To segue into
r/MensRights, here is somebody from SRS detailing her experience with them, which also
neatly sums up SRS once more:
4.3 MRC
r/MensRights is a conventional subreddit. Here, disenfranchised men or boys (Reddit’s
dominant clientele are male white teenagers) can share stories of how they are being
mistreated. Like this one:
14

Except, not quite like this one. Dog_This_is_Colby is most likely a deception troll. He is
promptly identified by a deleted user and agggressioncountertrolled. Aggression is a
recurring theme in r/MensRights. Many reactions to trolls employ violent language.
Apart from that, the other main way of dealing with trolls is to starve them by simply
ignoring them:
r/MensRights seems to be more concerned with reasonable debate. However, it is
questionable how selfaware they are. On the one hand, jacKofKats in the next example
writes in a calm manner:
15

On the other hand, he is completely oblivious to himself being trolled. He tries to save face
by implying GamblingDementor is a troll. It is left for us to judge whether this worked.
There is really not much more to say about trolling In r/Mensrights. Because of the general
sentiment that SRS are trying to infiltrate them, they are very trollaware. The occasional
troll is either ignored or aggressively attacked. The most interesting thing about this is that
due to the ignoring, it is also very likely that my search for “troll*” did not catch many trolls,
because they are not called out for it.
5. Comparison
SRS and MR have a lot in common, but also significant differences. Both subreddits
are very trollaware. Both are very versed in trolling and can usually recognize bad trolls.
Even more sophisticated forms like concern trolling are usually ineffective.
The most prominent difference between the two subreddits is that SRS has the
circlejerk. It is a much more positive feature that stimulates runontrolling and even
contributes to community building among members. It seems that circlejerking is a more
productive method of dealing with trolls than aggression or ignoring. It is also much nicer,
because it encourages mocking of trolls instead of violently attacking them. This confirms
to gender stereotypes, and also shines a friendler light on the countertroller, which in turn is
positively constructive for the group dynamic.
Another difference is the larger volume of content per thread in r/MensRights
16

compared to SRS. This seems to be the case because MR is an ordinary subreddit, not a
specific troll subreddit like SRS. The number of upvotes for each thread is also higher by a
factor of two to three for MR. Since Reddit has more male users than female ones, this
seems only logical.
MR also does not seem to venture outside of its own subreddit as much as SRS.
MR often specifically implied that the people trolling their subreddit are coming from SRS.
In turn, SRS never implied they were trolled by somebody from MR. In fact, the opposite
was the case, they were actively trolling in MR under fake, throwaway accounts.
SRS is also more likely to moderate content than MR. Contrary to Hardakers Usenet
corpus, Reddit has a reporting function for offensive posts, and subreddit moderators who
will investigate those reports. This means that all too blatant repeated aggression is
dangerous, because trolls do not have to be killfiled individually by every reader, but can
instead be banned globally by a moderator.
6. Conclusion
Despite being a community of trolls, SRS seemed more positive and more sophisticated in
their methods than MR. However, my analysis of r/MensRights could not go as deep,
because there simply were fewer trolls due to the ignoringdoctrine. This is a
methodological problem:
Searching for “troll*” is really only the most basic way to find trolls, and not the best
one at that. For a more sophisticated algorithm, advanced programming knowledge would
be required. Reddit is actually a great resource for algorithmfueled research, because it
offers a public API that can be accessed by everybody. Also, Reddit’s inherent voting
system is a great advantage for further research on trolling. Every redditor up and
downvotes tons of threads and comments during his time on the site. This is
crowdsourced metatagging that other corpora cannot emulate, because the hordes of
redditors who do this ‘work’ for fun and for free must be hard to come by in scientific
tagging circles. Additionally, one could even try to persuade the moderator community to
be given privileged APIaccess to scrape the data collected about which posts were
reported for abuse. There is great research potential if one were to conflate voting data and
17

abuse data with with a sophisticated linguistic coding algorithm. Suffice it to say, this was
beyond the scope of this paper. For such an advanced approach, interdisciplinary
collaboration with information studies students would be necessary.
7. Works Cited
7.1 Primary Sources
Metzger, Felix. (2013) “Corpus of first 74 threads from
http://www.reddit.com/r/ShitRedditSays/top/ with comments: 1679166 words, extracted on
20130309. 2012present.” Available online at
https://www.dropbox.com/sh/gd819hsp7dobe69/qIZm6JAEBP.
Metzger, Felix. (2013) “Corpus of first 50 threads from
http://www.reddit.com/r/Mensrights/top/ with comments: 1702567 words, extracted on
20130309. 2012present.” Available online at
https://www.dropbox.com/sh/dbvdt8fjxp1480a/fij63S9eKC.
7.2 Secondary Sources
Donath, Judith S. (1999). “Identity and deception in the virtual community.” In Marc A. Smith
and Peter Kollock (eds.), Communities in Cyberspace, 2959. London: Routledge.
GoatPostman (2012). No title. Web. extracted 20130315.
http://www.reddit.com/r/communism/comments/12cb8i/could_someone_please_explain_w
hat_brd_srs_and_mra/c6u8ufb
Hardaker, C. (2010). “Trolling in Asynchronous Computermediated Communication: From
User Discussions to Academic Definitions.” Journal of Politeness Research. Language,
Behaviour, Culture 6.2, 215–242.
18

Herring, S. C., JobSluder, K., Scheckler, R., & Barab, S. (2002). “Searching for safety
online: Managing "trolling" in a feminist forum.” The Information Society, 18.5, 371383.
Krappitz, S. (2012). “Troll Culture” Unpublished Master Thesis. Merz Akademie, Stuttgart.
Morrissey, L. (2010). “Trolling is a art: Towards a schematic classification of intention in
internet trolling.” Griffith Working Papers in Pragmatics and Intercultural
Communications, 3.2, 7582.
Twitter Staff (2013). Embedded Tweets. Web. extracted 20130315.https://dev.twitter.com/docs/embeddedtweets
7.3 Software used
Anthony, L. (2011). “AntConc” (Version 3.3.5m). Tokyo, Japan: Waseda University.
Available from http://www.antlab.sci.waseda.ac.jp/
Bare Bones Software (2013). “Textwrangler” (Version 4.5). North Chelmsford, MA.
Available from http://www.barebones.com/products/textwrangler/download.html
The PHP Group (2012). “PHP” (Version 5.3.10).
Available from http://php.net/downloads.php
Sobel, Steve (2013). “Reddit Enhancement Suite” (Version 4.1.2). Chicago, IL. Available
From http://redditenhancementsuite.com/downloadchrome.html
Google Inc. (2013). “Google Chrome for Mac” (Version 27.0.1438.7 dev). Mountain View,
CA. Available from
https://sites.google.com/a/chromium.org/dev/gettinginvolved/devchannel
Mozilla Foundation (2013). “Firefox for Mac” (Version 10.0). Mountain View, CA. Available
from http://www.mozilla.org/enUS/firefox/features/
19

Joe Hewitt et al. (2013). “Firebug Extension for Firefox” (Version 1.11.2).
Available from https://addons.mozilla.org/de/firefox/addon/firebug/
8. Appendix
PHP Script used for Corpus Cleanup:
<?php
$files = glob('*.html');
foreach($files AS $file)
echo "Mache Seitenleiste weg von " . $file . "\n";
$content = file_get_contents($file);
$content = preg_replace('@<div id="header" role="banner">.*</div>\s*(<a
name="content">)@imsU', '<!-- PARSE: seitenleiste raus-->\1', $content);
$content = preg_replace('@<div class="footer-parent">.*(<p class="bottommenu
debuginfo">)@imsU', '<!-- PARSE: footer raus-->\1', $content);
$content = preg_replace('@<form id="form\-["]*" class="usertext cloneable"
onsubmit="return post_form\(this, \'comment\'\)" action="["]*">.*</form>@imsU', '<!--
PARSE: commentbox raus -->', $content);
$fp = fopen($file, 'wb');
fwrite($fp, $content);
fclose($fp);
echo "Done.\n";
20




















