
Cryptanalysis Attacks on RSA
69
Cryptanalysis Attacks on RSA Chawanangwa Lupafya MSc Advanced Computer Science 2012/2013 ✬ ✫ ✩ ✪ The candidate confirms that the work submitted is their own and the appropriate credit has been given where reference has been made to the work of others. I understand that failure to attribute material which is obtained from another source may be considered as plagiarism. (Signature of student)
Transcript of Cryptanalysis Attacks on RSA

Cryptanalysis Attacks on RSAChawanangwa Lupafya
MSc Advanced Computer Science
2012/2013
'
&
$
%
The candidate confirms that the work submitted is their own and the appropriate credit has been given
where reference has been made to the work of others.
I understand that failure to attribute material which is obtained from another source may be considered
as plagiarism.
(Signature of student)

Summary
The RSA cryptosystem, named after Ron Rivest, Adi Shamir and Leonard Adleman, who first pub-
licly described it in 1978, is a cryptographic public-key system based on the presumed difficulty of
factoring integers. To receive an RSA-encrypted message a user selects two large prime numbers and
publishes the product, along with an auxiliary value, as public key. The prime factors must be kept
secret. Anyone can use this public key to encrypt a message. Someone knowing the prime factors can
feasibly decode the message. But there exist several approaches to break the cryptographic system
without this knowledge. In this project, we implement and study the efficiency and effectiveness of
three RSA attacks - Integer Factorisation, Guessing plaintext, and Guessing ϕ(N) attack. In order to
achieve this aim, we study the RSA algorithm and implement our version of the RSA algorithm. In
our study of the RSA algorithm, we look at various algorithms and number theory relevant for the
implementation of RSA.
i

Acknowledgements
First and foremost, I am grateful to my supervisor, and the assessor in their capacities. My supervisor,
Dr. Haiko Muller, your directional support, kept me calm throughout the whole process of completing
this project. To my assessor, Dr Natasha Shakhlevich, your feedback on both the interim report and at
the progress meeting was instrumental and valuable.
Secondly, my sincere thanks is to my sponsors, the Beit Trust and the University of Leeds for making
it possible for me to pursue my studies here at the University of Leeds. With them, I have managed to
realise a great portion of my life goals.
Thirdly, my lovely mother and the rest of the family: Chimwemwe, Brenda, Gomezgani, and Mercy
for your spiritual and moral support.
Finally, I thank my friends who have helped me celebrate my achievements and kept me going, no
matter how difficult it seemed to be.
ii

Contents
1 Introduction 11.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Aim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Minimum Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.5 Further Project Enhancements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.6 Relevance to Degree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.7 Project Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.8 Project Schedule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Background Research 52.1 Literature Review . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Public Key Cryptography . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.2 Outline of RSA Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 RSA Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.4 Cryptanalysis Attacks on RSA . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.5 Looking Forward: The Future of Cryptography . . . . . . . . . . . . . . . . 11
3 Preliminaries 123.1 Number Theory & RSA Relevant Algorithms . . . . . . . . . . . . . . . . . . . . . 12
3.1.1 Prime Numbers P . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1.1 Prime Number Generation Algorithms . . . . . . . . . . . . . . . 17
3.1.1.2 Sieve of Eratosthenes Algorithm . . . . . . . . . . . . . . . . . . 18
3.1.1.3 Implementation of Sieve of Eratosthenes Algorithm . . . . . . . . 20
3.1.2 Primality Test Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.2.1 Fermat Primality Test . . . . . . . . . . . . . . . . . . . . . . . . 22
3.1.2.2 Miller-Rabin Primality Test . . . . . . . . . . . . . . . . . . . . . 24
3.1.2.3 Fast Modular Exponentiation Algorithm . . . . . . . . . . . . . . 25
3.1.2.4 Miller-Rabin Primality Test Illustration . . . . . . . . . . . . . . . 26
3.1.3 Implementation of Prime Number Generator . . . . . . . . . . . . . . . . . 28
iii

4 RSA Algorithm 294.1 Derivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 RSA Signature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3 RSA Algorithm Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.1 RSA Algorithm Pseudo-code . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5 Integer Factorisation Attack 375.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.5 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6 Guessing Plaintext Attack 436.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
6.2 Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
6.3 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
6.3.1 Approach 1: Linear Search . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
6.3.2 Approach 2: Random Search . . . . . . . . . . . . . . . . . . . . . . . . . . 46
6.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
7 Guessing ϕ(N) Attack 487.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
7.2 Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
7.3 Solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7.4 Linear Search Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7.5 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7.6 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
7.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
8 Project evaluation 528.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
8.2 Evaluation: Comparison of the RSA attacks . . . . . . . . . . . . . . . . . . . . . . 52
8.3 Evaluation of the Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
8.4 Assessment of Project . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
8.4.1 Minimum Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
8.4.2 Further Project Enhancements . . . . . . . . . . . . . . . . . . . . . . . . . 55
8.5 Further Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
iv

Bibliography 56
A Personal Reflection 59
B INTERIM REPORT 61
C SAMPLE LIST OF PRIME NUMBERS GENERATED 62
v

Chapter 1
Introduction
1.1 Overview
In this project, we implement and study the efficiency and effectiveness of three RSA attacks - In-
teger Factorisation, Guessing plaintext, and Guessing ϕ(N) attack. In order to achieve this aim, we
study the RSA algorithm and implement our version of the RSA algorithm. In our study of the RSA
algorithm, we look at various algorithms and number theory relevant for the implementation of RSA.
Furthermore, we look at algorithms for generating prime numbers since prime numbers form the foun-
dation of the RSA. We then generate prime numbers and store them in a MySQL database. The prime
numbers are then accessed by RSA for the various experiments. The main programming language
used in this project is C++. However, there are some minor section where we have used the C pro-
gramming language. The evaluation of the attacks and other algorithm implemented is mainly based
on the size of the input in terms of bit-size and the running time of an algorithm.
1.2 Aim
The aim of this project is to gather some information on possible attacks on RSA, to implement some
of these RSA attacks and test their efficiency and effectiveness in practice by using relatively small
prime numbers.
1

1.3 Objectives
• To generate a list of prime numbers to be used by the RSA algorithm and store the prime
numbers in a database e.g. MySQL database.
• To find relevant C++ libraries that can handle large integers.
• To implement the RSA algorithm using C++.
• To develop a basic command line application that uses the RSA algorithm for encryption and
decryption.
• To research on programs and algorithms that can be used for integer factorisation.
• To implement some of the attacks in C++.
1.4 Minimum Requirements
• Implement the RSA algorithm.
• Implement Integer factorisation attack.
• Implement another attack which does not exploit the mathematical characteristics of the RSA
algorithm e.g. cipher text guessing
1.5 Further Project Enhancements
• Research on RSA digital signature
• Implemented Guessing ϕ(N) attack
• Researched on primality test algorithms and implemented Miller- Robin primality test and Fer-
mat primality test algorithms for generating any size of a prime numbers.
1.6 Relevance to Degree
This project builds on knowledge and skills obtained from modules taken during the taught phase of
this MSc in Advance Computer Science programme. The two main modules include Algorithm design
(COMP5900M), which provided foundation knowledge in the design, implementation and analysis
of algorithms and data structures. Advanced Distributed Systems (COMP5910M), which discussed
among other this, security in distributed system where cryptosystems such as RSA algorithm are
extremely vital for the protection of individual and business data.
2

1.7 Project Methodology
In this project, we follow the scrum methodology [20]. Scrum defines the systems development pro-
cess as a loose set of activities that combines known, workable tools and techniques with the best that
a development team can devise to build systems [20]. This is a sensible approach since this project
is divided into sub-components, where each component represents a specific milestone achieved. For
instance, generating prime numbers and creating a database of prime numbers, implementing the RSA
algorithm, and implementation of various attacks: all these and the other objectives represent mile-
stones of the project. The weakness of scrum is that this inherent looseness of the activities introduces
a risk in controlling the development process [20].
The project begins with a general background research on cryptography and cryptanalysis. Then the
we get specific into RSA algorithm. In order to gain a good understanding of the RSA algorithm,
we also explore some aspects of number theory. In particular, we focus on prime numbers, coprime
numbers, modular arithmetic and number theory algorithm relevant to RSA algorithm. After this, we
then discuss RSA.
We implement some of the RSA attacks using C++ and PARI/GP C library in the following order:
Integer Factorisation, Guessing plaintext, and Guessing ϕ(N) attack. PARI/GP is a computer algebra
system designed for fast computations in number theory i.e. integer factorizations, algebraic number
theory. After implementing each attack, we evaluate the effectiveness and efficiency of each individual
RSA attack based on the input in bit-size and the running time of the attack. This is a good evalu-
ation measure of the attacks since the security of RSA depends on the size of the modulus N in bits [6].
Finally, we provide an evaluation of the overall project. We compare the effectiveness and efficiency
of the three RSA attacks. Then, we discuss the overall implementations. We conclude by looking at
the achievement of the project and further work.
Through out the project writing up was on going activity. This achieved two goals: 1) To keep the
project well documented and 2) Help the author learn and get used to the LATEX document markup
language and document preparation system. The decision to use LATEX came later in the middle of the
project schedule following feedback on the interim report from the project assessor on the presentation
of the written work.
1.8 Project Schedule
Due to unexpected challenges, we were forced to change the project schedule. One of the major chal-
lenges that adversely affect the project schedule was the generation of prime numbers. The primes
numbers we had initially generated in a period of about 2 weeks proved to be too small for the inte-
3

ger factorisation attack. This meant that we could not generate enough sensible data for evaluation.
Therefore to overcome this challenge we had to study and generate prime numbers using primality
tests algorithms. Hence we also had to do literature search on primality test algorithms.
The other challenge that adversely affected the schedule were the issue to do with the C++ language.
The issues associated with the linking of C++ and the external libraries caused various problems such
that the implementation of the attacks using external libraries took extra work. Furthermore, time
required for some attacks to execute was initially under estimated since some of the attacks required
to run for days in order to generate enough data. This therefore limited the number of attacks we could
implement considering the time constraint.
Task Start Week Duration in Weeks1 Literature Review 8 142 Research on C++ Libraries 14 23 Prime Numbers Generation 15 44 RSA algorithm implementation 17 25 Implementing RSA attacks 20 46 RSA attack experiments and
evaluation of individual attacks21 5
7 Project evaluation:Evaluation of all the attacks bycomparing their efficiency andeffectiveness andEvaluation of implementationcarried on,assessment of minimum re-quirements and further enhance-ments achieved and further workrequired
26 2
9 Report Write-up 21 11
Table 1.1: Revised Project Schedule
On the evaluation of the project. In the first instance, we evaluate an individual attack on its own by
analysing the data it generates. Then during the project evaluation, we evaluate the attacks as a group
so as to establish which attack is the most efficient and effective.
4

Chapter 2
Background Research
2.1 Literature Review
2.1.1 Public Key Cryptography
In this section, we present the cryptography environment and introduce some of the terms and nota-
tions that are used through out the report. The use of the personal names: Alice, Bob, and Eve, is a
tradition in cryptography [2, 6, 22].
Let ∑ be the alphabet and let ∑∗ be the set of all possible message M from ∑.
Let M, plaintext, be the message .i.e. M ∈∑∗.
Given that we have two parties: Alice, who wishes to send a message M to Bob or vice versa. And
there is a third party, Eve, who is intends to break the privacy [4]. To protect the message from Eve,
Alice encrypts the message M using a function EA : ∑∗ → ∑
∗, which transforms the plaintext (M)
to ciphertext (C). This is the encryption process: C = EA(M). Alice then sends C to Bob hoping
Eve will not have the ability to decrypt C. When Bob receives C, he applies a decryption function:
DB : ∑∗→ ∑
∗ which transforms M = DB(C) = DB(EA(M)). .i.e. decryption. DB is the inverse of EA.
When Bob wishes to send a message to Alice, Bob uses EB(M) for encryption and sends the ciphertext
C to Alice. Alice decrypts C using DA(C).
From the above scenario, we see that the objective of a cryptosystem is to protect M such that Eve
cannot decrypt C if she intercepts C. A cryptosystem should be strong enough to ensure that the de-
cryption function is not be figured out [6]. The encryption and decryption algorithms might be freely
available to Eve, so keys are used to for security [1, 14].
To illustrate this, let the encryption and decryption keys for Bob be eB and dB respectively. Let Alice’s
5

keys be eA and dA. Hence the encryption and decryption for Alice becomes C = EA(M) = E(eA,M)
and M = DA(C) = D(dA,C) respectively. Where E stand for encryption algorithm and D for the de-
cryption algorithm. In public key cryptography, only the decryption key is kept secret the encryption
key and the algorithm are available to Eve [4, 6]. In private key cryptography, both keys are kept
secret, but the algorithm might be available to Eve [4, 6, 8]. In this setting, Eve is the cryptanalyst.
Cryptanalysis deals with the solution and reading of cryptic messages [8, 29].
In 1976 Whitfield Diffie and Martin Hellman published their article [4] which introduced public cryp-
tography. In the article, they suggested that public key cryptography was the solution to the then two
open problem in cryptography: 1) How to minimize the need for secure key distribution channels?
and 2) How to supply a digital signature that is equivalent to the physical signature that can be used
for authentication? Problem 1) arises in private key cryptography since all involved parties have to
exchange keys securely with each other. Niel Ferguson and Bruce Schneier in [6] illustrate that as the
number of parties gets larger, the number of keys grows quadratically. For instance with 100 parties,
4950 keys are required if all parties are communicating with one another [6]. According to [4], a
public key cryptosystem is defined as follows: Given a public key encryption algorithm which has
two keys for encryption(public) and decryption(private) key, the decryption key is kept secret and the
encryption key is available to anyone that wants to send you a message. Therefore, anyone can send
you a message and only you can decrypt the message with your decryption key. In this way we see
that public key cryptography solves the problem of minimization of key distribution by having the
public keys kept in a common shared database, for instance.
Digital signatures use the same public key algorithm [29, 19]. However, the use of a digital signature
is for authentication [29, 19, 22]. To create a signature SA, Alice decrypts a message, M1, using her
private key such that SA =DA(dA,M1). Then sends the message to Bob. When Bob receives the SA, the
digital signature for Alice, he then encrypts SA with Alice’s public key eA such that M2 = EA(eA,SA).
If M1 is equal to M2 then Bob knows that it is indeed Alice’s signature since EA is the inverse of DA.
No one else could create SA unless they have access to Alice’s private key.
In the same article [4], Whitfield Diffie and Martin Hellman, proposed a partial algorithm now called
Diffie-Hellman key exchange protocol that attempted to implement public key cryptosystem. How-
ever, it was in 1978 that Ronald Rivest, Adi Shamir, and Leonard Adleman first published a success-
fully workable public key algorithm [19]. This algorithm is now refered to as the RSA algorithm after
the initials from Rivest, Shamir and Adleman. The RSA algorithm solves both the problem of key
distribution minimization and digital signatures implementation [6, 19]. According to Dan Boneh,
these days RSA is deployed in many commercial systems [2] such online banking, online shopping
e.t.c.
6

The security of a public key algorithm depends on what is called a trapdoor function[2, 4, 6, 19].
Basically, a trapdoor function is a function that is easy to compute and whose inverse is hard to com-
pute if no privileged information is available [?]. The concept of a trapdoor function was suggested
in [4] as the foundation of public key cryptography but in [30], Andrew Yao claims that the question
“what is a trapdoor function?” has not been answered satisfactory. Therefore [30] attempts to provides
a definition of a trapdoor.
According to [4] and [30] the following properties should be achieved if a public key scheme is
to work properly. If we consider Alice for instance, her keys are dA and eA, private (decryption)
and public(encryption) key respectively. Given that the the encryption and decryption functions are
C = E(eA,M) and M = D(dA,C) respectively and M = D(dA,E(eA,M)) as already discussed; where
M,C ∈ ∑∗, then a trapdoor function should behave as follows:
1. Given eA implies that C = E(eA,M) is feasible to compute.
2. Without dA implies that M = D(M) is infeasible to compute.
3. Given C = E(eA,M) it should be feasible to find M given dA.
4. A random pair (eA,dA) should be easy to compute
Since C = E(eA,M) is easy to compute but hard to invert if dA is not given, it is called a trapdoor
function. dA is called the trapdoor since it is the information required to compute the inverse of the
trapdoor function [4, 30].
In public key cryptography, the strength of the cryptosystem is that it is infeasible to calculate the
decryption key even though the attacker has access to the algorithm and the encryption key [4]. The
security of RSA algorithm fundamentally depends on Integer Factorisation Problem (IFP) [29]. Taher
ElGamal in [5] presents a public cryptosystem that depends on the difficulty of computing discrete
logarithms [5].
The question of determining if a given problem, in terms of computing, is feasible (tractable) or in-
feasible (intractable) is a major area of research in computer science [29]. There exist some problems
where it is not known that the problem is either tractable or intractable. An example of such a problem
is the IFP [19, 15, 29, 16, 30]. No algorithm has been published that solves IFP in polynomial-time
hence the problem is assume to be intractable [15, 16, 29]. According to the Cook-Karp thesis [29],
it is believed that problems which can be solve in polynomial time are tractable and problems not
solvable in polynomial time are intractable. This thesis has not been proven mathematical though
practical evidence support the thesis [29].
7

Clearly, determining whether a problem is tractable or not has major implication for public key cryp-
tography. If an algorithm is invented that does integer factorisation in polynomial time, for instance,
then it will obvious imply the end of RSA algorithm [2, 6, 22, 29].
2.1.2 Outline of RSA Algorithm
Before we look at the literature on cryptanalysis of the RSA algorithm, let first look at the RSA al-
gorithm. An understanding of the algorithm helps us explore the strength and weakness of RSA and
how the various attacks aim to exploit these features.
The RSA algorithm [19, 11] is outlined below:
1. Choose large prime numbers p and q
2. Compute the product N = pq
3. Choose a number e < N which is coprime to ϕ(N) = (p−1)(q−1)
4. Find a number d such that ed ≡ 1(mod ϕ(N))
5. The public key is the pair (N,e)
6. The private key is the pair (N,d)
7. Encryption through C ≡Me(mod N)
8. Decryption through M ≡Cd(mod N)
Let us look at an example of the application of the RSA algorithm. Using small values will allow
us to workout the calculation using a calculator. The use of large values require the application of
specialized algorithms. These specific algorithms will be discussed in detail in Chapter 3. However,
we will point out the required algorithms where appropriate.
Definition 2.1.1 (Natural Number).The set N= {1,2,3,4,5,6, ...} is the set of natural numbers or positive integers.
Definition 2.1.2 (Prime Number P).If a natural number x is greater than 1 is divisible only by 1 and itself, then it is called a prime. P is
the set of prime numbers.
Definition 2.1.3 (coprime).Two integers are called coprime or relatively prime if their greatest common divisor is 1.
8

Example 2.1.1 (RSA Algorithm).
If we choose the prime numbers p = 17 and q = 23. Then N = p ∗ q = 391. Then we select e = 5
since 5 < (17−1)(23−1) = 352 and since clearly 5 and 352 are coprime. In RSA implementation,
Euclid’s greatest common divisor algorithm [13] is used to check if two number are coprime. To find
d, we have to solve ed ≡ 1(mod ϕ(N)) = 5d ≡ 1(mod 352). This equation is solved using Euclid’s
Extended algorithm [13]. In this case d = 141. Therefore the private key = (391,141) and the public
key = (391,5).
If we select M = 142, then to encrypt M we have to compute C≡Me(mod N) = 1425(mod 391)≡ 58.
Therefore the ciphertext: C = 58. The decryption process implies: M≡Cd(mod N)= 32141(mod 391)≡142. M = 142 as required.
2.1.3 RSA Implementation
Understanding of the RSA algorithm does not require complex mathematics, as can be seen from
the algorithm and example; most of the steps just require basic arithmetic [6]. However, efficient
implementation of the arithmetic operations require efficient algorithms as RSA involve computation
of large numbers [6, 21]. For instance [6] suggest the absolute minimum size of key N to be 2048
bits. [6] further recommends the value of N should tend to or equal to 4096 bits. The larger the N
the stronger the cryptosystem and the more computation power is required [6, 29, 22]. To calculate
the modulus N require the generation of large prime numbers p and q. But generating prime numbers
is not as straight forward. Don Zagier in [31], “The first 50 million prime numbers”, describe prime
numbers as follows:
“There are two facts about the distribution of prime numbers of which I hope to con-
vince you so overwhelmingly that they will be permanently engraved in your hearts. The
first is that, despite their simple definition and role as the building blocks of the natural
numbers, the prime numbers belong to the most arbitrary and ornery objects studied by
mathematicians: they grow like weeds among the natural numbers, seeming to obey no
other law than that of chance, and nobody can predict where the next one will sprout.
The second fact is even more astonishing, for it states just the opposite: that the prime
numbers exhibit stunning regularity, that there are laws governing their behavior, and that
they obey these laws with almost military precision.”
Using deterministic algorithms such as the The Sieve of Eratosthenes [7] is too slow for generating
large primes. However, usage of various techniques such as primality test and randomized proba-
bilistic algorithms [14], it is possible to create algorithms that generate large prime number more
efficiently [6, 7, 10, 22]. According to the prime number theory, the distribution of primes is relatively
dense [22]. This distribution of prime numbers allows for more efficient prime number generating
9

algorithms to be developed. Fermat test or Rabin-Miller test are some of the primality test which are
used to determine if some random number is probably prime[6, 10]. Using primality test to determine
if a number is prime is the most effective method as no knowledge of the prime factors of the number
is require [22]. If prime factors of a number were required for determining if a number is a prime,
primality test would have been equivalent to solving the IFP [22, 29].
Some of the algorithm being used in RSA were developed more than 2000 years ago [6, 13]. For
instance, to determine if two numbers are coprime, the greatest common divisor, Euclid’s algorithm
is used [6, 13]. The Extended Euclid’s algorithm is used to compute the private key d by solving the
equation ed ≡ 1(mod ϕ(N)) [13].
Finally, considering RSA encryption and decryption, the naive approach of calculating xy obviously
will not be effective. [6] states that computers have limited memory and computing power to cal-
culate xy when x and y are thousands of bits long. Such a calculation even for small values results
into a large number since it is exponential. But because this is modular arithmetic, effective and ef-
ficient algorithms exist for computing xy(mod N). Many public key cryptosystems use modular fast
exponentiation [6, 14, 21]. Daniel Gordon in [9] presents a survey of fast exponentiation methods
and provides some advice in choosing the appropriate method depending on computing resources
available and computing environment in use.
2.1.4 Cryptanalysis Attacks on RSA
[2] states that since RSA algorithm was published, researchers have analyzed RSA for vulnerabilities
and consequently invented various attacks but non of these attacks has proven to be catastrophic. [2]
further looks at some of the attacks that have been discovered twenty years since the publication of
RSA. [29] provides a comprehensive collection of all major known cryptanalytic attacks on RSA. All
the attacks implemented and evaluated in this project are found in [29]. Cryptanalytic attacks on RSA
algorithm either aim at exploiting the mathematical vulnerabilities of RSA or implementation vulner-
abilities [6, 2, 22, 29]. In “Practical cryptography” a discussion is presented on what to consider when
developing a cryptosystem [6]. The issues considered range from choice of implementation language
to the specific algorithm for various RSA computations. Sometimes to break a cryptographic system,
operating system bugs are exploited [6]. The computer system as a whole is complex; so even though
the cryptosystem as a component of the system might be secure, weak points might emerge from other
components of the system. For instance, the operation of swapping a file by the operating system be-
tween RAM and the hard disk might cause a security risk [17].
RSA encryption: C ≡Me(mod N) (2.1)
10

RSA decryption: M ≡Cd(mod N) (2.2)
Equation 2.1 and 2.2 show the encryption and decryption process of the RSA algorithm. Attacks on
RSA exploit any component of these equations to get information that can help in deciphering the
ciphertext. For example, the most direct attack is to determine the private key d. To find d, we have to
solve ed≡ 1(mod ϕ(N)). But ϕ(N)= (p−1)(q−1). Therefore a cryptanalyst has to factor N in order
to determine d. This require solving IFP [15, 16, 29]. Lenstra in [15, 16] details some algorithms for
IFP. The integer factoring algorithms can factor integers of only limited magnitude [14, 29]. Various
implementation of these factoring algorithm exist. For instance, some Linux operating system such as
Ubuntu includes a factoring program that implements the Pollard’s rho algorithm [24]. In addition,
there exists more efficient implementation of factoring algorithms in computer number theory system
such as in PARI/GP [26].
Other RSA attacks try to guess parameters of the RSA such as plaintext(M), private key(d) and the
Euler’s totient function(ϕ(N)) [2, 6, 29]. Due to computation requirement, some implementation of
RSA use small values of e and d. Therefore RSA attacks exists that attack cryptosystem with small
values of e and d [29].
2.1.5 Looking Forward: The Future of Cryptography
The One-time pad cryptosystem has been proven to be 100% secure [28]. Currently, even though
RSA is not 100% secure, it is still among the most popular public key algorithms. However, advances
in quantum computing pose a risk to RSA. Peter Shor developed a quantum algorithm that solves the
integer factorisation problem [27]. So if quantum computing is fully achieved, this will mean the end
of RSA. But research in quantum computing to implement cryptosystem such as one-time pad [3] is
in progress. In a classical setting, the one-time pad cryptosystem is not very feasible but in a quantum
computing setting one-time pad is feasible [3].
11

Chapter 3
Preliminaries
3.1 Number Theory & RSA Relevant Algorithms
Number theory is the study of numbers [10]. Among the areas of study in number theory are topics
such as prime numbers and integers factorisation. Some of the most useful algorithms that are used
in today’s cryptography were invented hundreds of year ago as a result of research in number theory
[13]. For instance, the Euclidean algorithm, denoted gcd(a,b), is used to finding the greatest common
divisor of two numbers, a and b [10, 13].
Theorem 3.1.1 (Euclidean algorithm).Let a and y be integers. Then there exist integers q1,q2,q3, ...,qk and a descending sequence of positive
integers, r1,r2,r3...,rk,rk+1 = 0, such that:
b = q1a+ r1
a = q2r1 + r2
r2 = q4r3 + r4
.
.
.
rk−2 = qk−1rk−1 + rk
rk−1 = qkrk + rk+1
Where rk+1 = 0 and, gcd(a,b) = rk [10, 13].
12

Algorithm 3.1.1 (Euclidean algorithm).Given two integers a and b, we compute the greatest common divisor c, i.e., the largest positive integer
which evenly divides both a and b [10, 13] .
NAME : Euclidean algorithmINPUT : Integers a and bOUTPUT : greatest common divisor
1: gcd(a,b)
2: if a = 0 then3: return a
4: else5: r← b−bb
aca6: return gcd(r,a)
7: end if
Example 3.1.1 (Euclidean algorithm).Find the greatest common divisor of 1001 and 1287.
SolutionLet a = 1001 and b = 1287
gcd(a,b) Equivalent Equationsgcd(1001,1287) 1287 = (1)1001+286gcd(286,1001) 1001 = (3)286+143gcd(143,286) 286 = (2)143+0
Table 3.1: Illustration of the step Euclidean algorithm performs to calculate gcd(1001,1287)
Therefore, the greatest common divisor of a and b is equal to 143 since rk+1 = 0.
In RSA implementation, Euclidean algorithm is used to determine if two numbers, a and b, are co-
prime. We defined coprime numbers in definition 2.1.3.
Extended Euclidean algorithmFurthermore, there is a extension to the Euclidean algorithm called the Extended Euclidean algorithm,
denote in this report as extend gcd(a,b). This algorithm in addition to finding the greatest common
divisor of two numbers, also solve the linear Diophantine equation that conforms to the Bezout’s iden-
tity [10].
The linear Diophantine equation is of the form: ax+ by = c. If c is the greatest common divisor of
a and b then, the equation is called a Bezout’s identity. Therefore, applying extend gcd(a,b) returns
13

(x,y,c). Where x and y are called the Bezout’s coefficients of a and b respectively and c = gcd(a,b).
The solution to the Bezout’s identity in the RSA algorithm include the private key [29].
Theorem 3.1.2 (Extended Euclidean algorithm).Suppose a and b are integers. Then, there exists integers x and y such that ax+by = c = gcd(a,b).
Algorithm 3.1.2 (Extended Euclidean algorithm).Given two integers a and b, we compute the greatest common divisor c and integers x and y, such that
ax+by = c [1, 13, 14].
NAME : Extended Euclidean algorithmINPUT : Integers a and bOUTPUT : Integers x,y and c such that ax+by = c where c = gcd(a,b)
1: extend gcd(a,b)
2: if a = 0 then3: return (b,0,1)
4: else5: r← b−bb
aca6: (c,x,y)← extend g(r,a)
7: s← y−bbacx
8: return (d,s,x)
9: end if
Example 3.1.2 (Extended Euclidean algorithm).Solve the following Diophantine equation: 1001x+1287y = c
SolutionLet a = 1001 and b = 1287. First we calculate the gcd(a,b), then combine the equivalent equations
in reverse order such that we express 1001x+1287y = c = gcd(a,b).
Step 1 Calculate gcd(a,b):
gcd(a,b) Equivalent Equationsgcd(1001,1287) 1287 = (1)1001+286gcd(286,1001) 1001 = (3)286+143gcd(143,286) 286 = (2)143+0
Table 3.2: Calculation of gcd(1001,1287) as first step of Extended Euclidean algorithm
14

Step 2 Calculate x and y by expressing 1001x+1287y = c = gcd(a,b):
143 = 1001− (3)286
143 = 1001− (3)(1287−1001)
143 = (−2)1001+(3)(1287)
Therefore x =−2, y = 3 and gcd(1001,1287) = 143.
Later in this report, we are going to see how both the Euclidean algorithms are used in implementing
RSA algorithms.
In chapter 4 of this report, where the RSA algorithm is presented, we explain how RSA generates
the private key consequently illustrating the use of the Extended Euclidean algorithm in solving the
Bezout’s identity.
Chapter OutlineThe rest of the chapter is as follows. In section 3.1.1 we present a brief introduction to prime numbers,
and further explore the elements of prime numbers that are relevant to the RSA algorithm. Then in
section 3.1.1.1, we discuss some of the techniques for generating prime numbers such as Sieve of Er-
atosthenes, Fermat primality test, and Miller-Rabin primality test. Sections 3.1.1.3, 3.1.2.1 and 3.1.2.2
presents details of these technique. Actually, the Fermat primality test and Miller-Rabin primality test
are enhancements to this project because they performed better than the initially considered Sieve of
Eratosthenes. Finally, section 3.1.3 we present the details of the implementation of prime numbers
generating algorithms and an empirical evaluation of their performance.
3.1.1 Prime Numbers P
Generating two large prime numbers is the first step of the RSA algorithm [19]. The calculation of
the private key is a function of the two prime numbers [19, 22, 29]. Definition 2.1.3 and 2.1.2 define
a prime number.
In the RSA algorithm we are mainly interested in the following question regarding prime numbers:
1) How to efficiently generate prime numbers 2) What is the distribution of the prime numbers in the
set of natural numbers N and 3) How hard is factoring a integer into its prime factors? The first two
question are closely related. Question 1), considers algorithms for generating prime numbers. The
performance of prime number generating algorithms depends on the distribution of prime numbers.
Definition 3.1.1 (Prime-counting function).Let π(N) be the number of primes that are less than or equal to N.
15

Theorem 3.1.3 (Prime Number Theorem (PNT)).
π(N)≈ NlnN
The prime number theorem help us calculate the probability of selecting a prime number randomly
given a range from 0 to N [31]. The probability of selecting a prime number between 0 and N can
further be increased by considering only odd numbers [31]. Two is the only prime number that is an
even number.
Example 3.1.3 (Application of prime number theory).Calculate the approximate number of prime numbers less than or equal to 1000?
Solution
π(1000)≈ 1000ln1000
= 144.764827301...≈ 145
So the approximate number of prime numbers less than or equal to 1000 is approximately 145. We
know that the actual number of prime numbers less than or equal to 1000 is 168.
Example 3.1.4 (Application of prime number theory).Calculate the approximate probability of uniformly randomly selecting a prime number between 1
and 1000?
SolutionFrom example 3.1.6 we calculated that:
π(1000)≈ 145 given N = 1000
But
Probability o f a prime number =Number o f prime numbersTotal Number o f Numbers
Probability o f a prime number ≈ π(N)
N=
NlnNN
=1
lnN
When N = 1000 the probability is:
Probability o f a prime number ≈ 1lnN
=1
ln1000≈ 0.145
So the probability is about 14.5%.
Example 3.1.5 (Application of prime number theory).What is the effect on the approximate probability of uniformly randomly selecting a prime number
between 1 and 1000 when even numbers are removed from the list of total numbers?
16

SolutionSince
Probability o f a prime number =Number o f prime numbersTotal Number o f Numbers
Removing even number from the list of total numbers(N) implies:
Total Number o f Numbers =N2
Therefore the approximate probability is now:
Probability o f a prime number ≈ π(N)N2
=
NlnNN2
=2
lnN
Probability o f a prime number ≈ 2lnN
=2
ln1000≈ 0.2895
So the probability has now increased to about 29%. Further improvement can be made by removing
multiples of more prime numbers such as 3 e.t.c. The examples demonstrate that it is possible to
generate prime numbers randomly as long as we have a means of determining if a number is prime.
Theorem 3.1.4 (Fundamental Theorem of Arithmetic).Every natural number greater than 1 is a product of primes.
Let n, i,a, p ∈ N
Let p ∈ P
∀n∃{pi} such that n = pa1
1 pa2
2 pa3
3 pa4
4 ...pak
k =k
∏i=1
pai
i
The fundamental theorem of arithmetic says that every number greater than 1 is a product of prime
numbers [10]. In the IFP, we try to decompose an integer into its respective prime factors.
3.1.1.1 Prime Number Generation Algorithms
In this section we look at the prime number generating algorithms that were used in the implementa-
tion of the RSA algorithm. These algorithms fall into two categories: deterministic and randomized
algorithm.
Definition 3.1.2 (Deterministic Algorithm).A deterministic algorithm when given a particular input will always produce the same output, with
the underlying machine always passing through the same sequence of states.
Definition 3.1.3 (Randomized Algorithm).A randomized algorithm employs a degree of randomness as part of its logic
There are two types of randomized algorithms: Monte-Carlo and Las Vegas.
17

Definition 3.1.4 (Monte-Carlo Algorithm).These have a good worst case time bound, but a nonzero probability of failure. Thus, they may give a
wrong answer, but the probability can be made as small as required by repeating the computation.
Definition 3.1.5 (Las Vegas Algorithm).These always give the right answer, but may have a bad worst case time bound.
The randomized algorithms that we looked at for generating prime numbers in this project are Monte-
Carlo Algorithms. We have used Las Vegas Algorithms in our implementation of the RSA during the
key generation phase in Chapter 4 and in the implementation of various RSA attacks.
3.1.1.2 Sieve of Eratosthenes Algorithm
The Sieve of Eratosthenes Algorithm is the prime number generating technique that we initially con-
sidered for generating relatively small prime number for this project. However, we should point out
from the start that this algorithm proved to be less efficient because 1) The prime numbers generated
were too small for the integer factorisation attack and 2) The algorithm proved to be is too slow.
The Sieve of Eratosthenes works by eliminating all composite numbers within a given range of num-
bers hence the remaining sequence of numbers is a set of all prime numbers within a the given range
[7]. The algorithms is as follows:
1. List all numbers within a particular range from 2 to n.
2. Take the first number, 2 in this case, and eliminate all its multiples from the list except itself.
3. Then take the next number and eliminate its multiples from the list except itself, again.
4. Continue by repeat step 3) up to b√
n+1c until all composite numbers are eliminated.
5. The remaining numbers of the list form a sequence of prime numbers within the range from 2
up to n.
18

NAME : The sieve of Eratosthenes AlgorithmINPUT : n upper bound of the rangeOUTPUT : L list of prime numbers between the range 2 and n inclusive
1: position← 0
2: L← list of all numbers from 2 up to n
3: prime← L[position]
4: while prime ≤√
n+1 do5: for (index← position+1; index≤ L.size(); index++) do6: if L[index] (mod prime) = 0 then7: remove L[index] from L
8: end if9: end for
10: position← position+1
11: prime← L[position]
12: end while13: return L
The algorithm only has to loop up to prime= b√
n+1c since (b√
n+1c)∗(b√
n+1c) =√
n+1c)2≥n, therefore all composite numbers will have been eliminated. Notice that b
√n+1c is the maximum
possible prime factor for numbers in the range 2 to n. Hence after prime = b√
n+1c all number in L
are guarantee to be prime numbers.
Example 3.1.6 (Application of sieve of Eratosthenes Algorithm).Generate prime numbers between 2 and 25 using the sieve of Eratosthenes algorithm?
Solution
Steps LGenerate the list in range 2 to 25 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25Eliminate multiples of 2 except 2 2, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25Eliminate multiples of 3 2, 3, 5, 7, 11, 13, 17, 19, 23, 25Eliminate multiples of 5 2, 3, 5, 7, 11, 13, 17, 19, 23Eliminate multiples of 7 But 7 ≥ b
√25+1c hence the algorithm terminates according
to step 4
Therefore the list of the sequence of prime numbers between 2 and 25 is L= {2,3,5,7,11,13,17,19,23}.
Possible optimizationNotice that the algorithm could have been easily improved if we already knew that 2 and 3 were prime
numbers for instance. This observation could have been used to eliminate multiples of 2 and 3 during
the initial generation of the list of all numbers. This has the following two benefits 1) Saves computer
19

memory utilization and 2) Reduces the number of steps of the algorithm as independent elimination
of multiples of 2 and 3 is no longer necessary hence increasing the efficiency of the algorithm.
Below, in the implementation section of the sieve of Eratosthenes prime number generator program,
we explain how we used the idea of pre-generating some small prime numbers in our prime number
generating program to help us save computer memory.
3.1.1.3 Implementation of Sieve of Eratosthenes Algorithm
We implemented the sieve of Eratosthenes algorithm into a program using the in C++. Since in this
project we are generally dealing with large integers as compared to the standard data types of the
C++ language [23], we had to use an external C++ library capable of handling large arbitrary integers
[23, 25]. We used the GMP library since it is designed for use cryptography [25]. According to the
GMP website, GMP is described as follows:
GMP is a free library for arbitrary precision arithmetic, operating on signed integers,
rational numbers, and floating point numbers.There is no practical limit to the precision
except the ones implied by the available memory in the machine GMP runs on. The main
target applications for GMP are cryptography applications and research, Internet security
applications, algebra systems, computational algebra research, etc.
The name of the sieve of Eratosthenes prime number generating program implemented is sieve.out.
Included with the program is a file called prime.db. The prime.db file contains pre-generated prime
numbers between 2 (two) and 1000,000 (one million) of which there are 664580 prime numbers. The
largest prime number in the range 2 to 100000 is 9999991. Since the largest pre-generated prime
number is 9999991, it means this list of pre-generated prime numbers can be used to eliminate all
composite numbers less than 99999912 = 99999820000081.
Implementation Results and EvaluationThe largest prime number that we generated using the sieve of Eratosthenes algorithm is 9103482433.
If we assume that each number is 4 bytes, this implies that the list of numbers from 2 to 9103482433
require almost 36413929732 bytes which translate to around 34 Gigabytes. The computer we used
during the project had only 4 Gigabyte of RAM hence implementing the program without the opti-
mization simply resulted in the computer freezing within a short period of time after starting running
the program due to the computer running out of RAM.
The output of the sieve.out program is a file of prime numbers called prime.out. The file prime.out
contains a prime number per line. After running the sieve.out program and generating prime.out, we
loaded the data in to a MySQL database. To generate the prime numbers, we left the sieve.out pro-
gram to run continuously for four days. At the end, the prime.out file contained 4.5 Gigabytes of
20

prime numbers. 415372674 prime numbers were generated with 9103482433 being the largest prime
number. Below is a table of the last 6 largest prime numbers generated.
Sample Prime Numbers910348243391034824319103482403910348237391034823479103482341
Table 3.3: The last 6 largest prime numbers generated using sieve.out program
These numbers are sorted in descending order. Notice that the bits required to represent each of these
prime numbers in binary are 34 bits. The number of bits required to represent an integer in binary is
equal to blog2(N)c+1 where N is an integer [10].
From the list of generated prime numbers, we see that the largest product of two prime number we can
get from the list is 67 bits. However, using Integer Factorisation Attack (IFA), we observed that such
a number is simply factored less that 5 seconds. In chapter 5 we present the results and evaluation
of IFA. This lead us to abandon the sieve of Eratosthenes as no larger primes could be generated in
reasonable time to be used in experiments to generate data for evaluation of the RSA attacks.
3.1.2 Primality Test Algorithms
We used the sieve of Eratosthenes as our initial choice algorithm for generating small prime numbers.
However, due to performance issue we had to find an alternative solution for generating prime num-
bers.
To overcome the challenges we decided to implement a randomized algorithm for generating prime
numbers. Randomized algorithm for generating prime numbers are known to be faster than determin-
istic algorithms [14]. The main challenge with a randomize algorithm for generating prime numbers
is that the possible prime generated is never guaranteed to be a prime number, it is just probably prime
[14, 22]. This is an example of a Monte-Carlo Algorithms. But the probability that an algorithm
generates a false prime can be reduce such that it tends to zero [14, 21, 22].
We considered two ways of checking if a number is probably prime. Checking whether a number is
probably prime is called primality test [14]. The two primality tests we considered for implementation
are Fermat Primality Test and Miller-Rabin Primality Test [1, 14, 10, 22]. We then used Miller-Rabin
primality test as an alternative algorithm to sieve of Eratosthenes for generating prime numbers. Using
21

the Miller-Rabin primality test we have further created a command line application that can generate
prime numbers of any bit size as a further enhancement to this project.
To implement a Monte-Carlo Algorithms using the primality test we simply had to implement a pro-
gram that takes its input as an integer. The program then decide if a integer is probably prime by
using the result of the primality test. To reduce the probability of a false prime, the program calls the
primality test on an integer repeatedly for a specif number of times.
Example 3.1.7 (An example of a Monte-Carlo Algorithms).Let A(n) be a Monte-Carlo algorithms that decides if a number is prime or not. Where n in an integer.
The algorithm A(n) is always correct when n is not prime. However when n is prime, A(n) has the
probability of 12 of determining if n is indeed prime.
IF n = prime THEN probability that A(n) is incorrect is 12
IF n ! = prime THEN probability that A(n) is correct is 1
The question is how can we decrease the probability that A(n) is incorrect? [14]
SolutionIf A(n) says that n is not prime, then we know that A(n) is correct since the probability is 1. However,
when A(n) say that n is prime then we know that n is probably prime, through we are not sure. To
ensure than n is indeed probably prime, we have to call A(n) i-times on n. Since each event of calling
A(n) is independent then the probability of an incorrect answer is a product of the probability of each
individual event.
If n is probably prime the we have:
P[A(n) = incorrect] =12i
P[A(n) = correct] = 1− 12i
Therefore we see that as i→ ∞ then P[A(n) = correct]→ 1. This shows that we can improve our
algorithm by repeating A(n) on n hence decreasing the probability that A(n) is incorrect [14].
We now look at the Fermat primality test and Miller-Rabin primality test algorithms and illustrate
how each of these algorithms work using examples.
3.1.2.1 Fermat Primality Test
Fermat primality test is based on Fermat’s little theorem on prime numbers.
22

Theorem 3.1.5 (Fermat’s Little Theorem ).If p is a prime, then xp−1 = 1(mod p)
Notice that this theorem just tells us if a number is not prime but it does not confirm if a number is
prime. However, if xp−1 6= 1(mod p), then p is not prime. Therefore when the theorem is correct
for a particular integer, p, we say that p is probably prime. Fermat primality test is correct with a
probability of about 12 [1, 14].
NAME : Fermat Primality TestINPUT : An integer pOUTPUT : Decision whether p is probably prime or not
1: fermat(p)
2: Choose x uniformly at random from {1, ..., p−1}3: if xp−1 6≡ 1(mod p) then4: return not prime
5: else6: return probably prime
7: end if
Example 3.1.8 (Fermat Primality Test).Use the Fermat Primality test to determine if 9 and 23 are prime numbers?
SolutionLet us consider p = 9
STEP 1: First we apply the Fermat primality test 9 .i.e fermat(9):
STEP 2: We choose x = 4, randomly from the set {1,2, ...,8}STEP 3: 48(mod 9) = 7 6≡ 1(mod p)
STEP 4: Since 48 6≡ 1(mod 9) then we return 9 is not prime
Let us consider p = 23
STEP 1: First we apply the Fermat primality test 23 .i.e fermat(23):
STEP 2: We choose x = 4, randomly from the set {1,2, ...,22}STEP 3: 422(mod 23) = 1 6≡ 1(mod 23)
STEP 6: Since 422 ≡ 1(mod p) then we return 23 is probably prime
Therefore, we see that Fermat primality test has successfully determined that 9 is not prime while 23
is probably prime.
The reason we discussed Fermat primality test prior to discussing Miller-Rabin primality test is that
the Fermat primality test forms the foundation for Miller-Rabin primality test. Miller-Rabin primal-
23

ity test is more robust than Fermat primality test because it is able to determine the primality of
Carmichael Numbers [14].
Definition 3.1.6 (Carmichael Number).A Carmichael number is a composite positive integer p which satisfies the Fermat Primality Test for
all values of the set {1, ..., p−1} with gcd(x, p) = 1.
If p is a Carmichael Numbers then xp−1≡ 1 (mod p) is true for all x∈{1, ..., p−1} with gcd(x, p)= 1.
The smallest Carmichael Number is 561 [14]. For Carmichael Numbers, Fermat primality test will
always return that 561 is probably prime when we choose gcd(x, p) = 1 even though 561 = 3*11*77
which is a composite number [14, 21].
3.1.2.2 Miller-Rabin Primality Test
NAME : Miller-Rabin Primality TestINPUT : An integer pOUTPUT : Decision whether p is probably prime or not
1: miller(p)
2: Determine the largest integer t such that 2t |(p−1), so p−1 = 2tm, with m odd
3: Choose x uniformly at random from {1, ..., p−1}4: Compute xm(mod p) by the exponentiation method
5: Then compute x2m,x4m, ...,x2t−1m,x2t m(mod p)
6: if x2t m = xp−1 6≡ 1 (mod p) then7: return not prime
8: else9: for i← 1 to t do
10: if x2im ≡ 1 (mod p), but x2i−1m 6≡ ±1 (mod p) then11: return not prime
12: end if13: end for14: return probably prime
15: end if
The Miller-Rabin Primality Test is able to determine that a Carmichael Number is composite. Notice
that STEP: 3 and STEP: 4 of the Miller-Rabin Primality Test is just the Fermat primality test. There-
fore these two steps have a probability of a 12 , according to Fermat primality test, of determining if a
number is not prime.
If p is a Carmichael Number then STEP: 9 to 12 attempts to determine if it is a composite number.
24

Let’s consider STEP: 10 in more detail since it is where primality test occurs:
Let c = x2i−1m
∴ c2 = x2i−1m ∗ x2i−1m = x2i−1m+2i−1m = x2im
Suppose we find c 6≡ ±1 (mod p)
such that c2 ≡ 1 (mod p)
∴ c2−1 = (c−1)(c+1)≡ 0 (mod p)
also, from our supposition that c 6≡ ±1 (mod p)⇒ (c−1) 6≡ 0 (mod p) and (c−1) 6≡ 0 (mod p)
Hence p can not be a prime if it is not a factor of either (c−1) or (c+1) but it is a factor of (c−1)(c+1)
Form the above explanation we see how STEP: 10 of Miller-Rabin Primality Test is able to determine
the primality of a number.
3.1.2.3 Fast Modular Exponentiation Algorithm
Before we illustrating that uses Miller-Rabin primality test, let us first looking at the Fast Modular
Exponentiation algorithm which we use for computing the value of m = xy (mod n). Through out the
project, this Fast Modular Exponentiation algorithm is used for such computations.
Algorithm 3.1.3 (Fast Modular Exponentiation Algorithm).Let x, y, n be integers. Calculates m = xy (mod n)
NAME : Fast Modular Exponentiation AlgorithmINPUT : Integer x,y,nOUTPUT : m where m = xy (mod n)
1: fast exp(x,y,n)
2: r← 1 r is the remainder
3: m← 1
4: while y != 0 do5: r← y (mod 2)
6: y← y/2
7: if r=1 then8: m← (m∗ x)( mod n)
9: end if10: x = (x∗ x)( mod n)
11: end while12: return m
25

3.1.2.4 Miller-Rabin Primality Test Illustration
Example 3.1.9 (Miller-Rabin Primality Test).Use Miller-Rabin primality test to determine if the number 1729 is a prime numbers? 1729 is the third
smallest Carmichael number.
SolutionSTEP 1: miller(1729)
STEP 2: Determine the largest integer t such that 2t |(p−1), so p−1 = 2tm, with m odd
t m =(1729−1)
2t
1 1728/2 = 8642 864/2 = 4323 432/2 = 2164 216/2 = 1085 108/2 = 546 54/2 = 27
Table 3.4: determine t = 6 and m = 27
Since m = 27 is odd, we stop dividing at t = 6. The largest integer t = 6 and m = 27 such the
1729−1 = 26 ∗27
STEP 3: Choose x uniformly at random from {1,2, ...,1728}Assume we select x = 5 uniformly random from {1,2, ...,1728}
STEP 4: Compute xm(mod p) by the exponentiation method
calculate 527(mod 1729) by the exponentiation method.
Since 527 = 516+8+2+1 = 524+23+21+20we get the table of values up to 24.
52k52k
( mod 1729)520
5521
25522
625523
1600524
1080
Table 3.5: Fast Exponentiation Method
But 527 ≡ 524(mod 1729) ∗ 523
(mod 1729) ∗ 521(mod 1729) ∗ 520
(mod 1729)≡ 1080 ∗ 1600 ∗ 25 ∗
26

5(mod 1729)≡ 1217(mod 1729)
Hence 527(mod 1729) = 1217(mod 1729)
STEP 5: Then compute x2m,x4m, ...,x2t−1m,x2t m(mod p)
x2t m x2t m( mod 1729)52027 121752127 106552227 152327 152427 152527 152627 1
Table 3.6: computation of x2m,x4m, ...,x2t−1m,x2t m(mod p)
STEP 6: x2t−1m = xp−1 6≡ 1 (mod p)
526−127 = 51729−1 6≡ 1 (mod 1729)⇒ false hence go to STEP 9
STEPS 10 - 13: IF x2im ≡ 1 (mod p), but x2i−1m 6≡ ±1 (mod p) THEN return not prime
i← 1
52127 ≡ 1065(mod 1729) and 52027 ≡ 1217(mod 1729)
i← 2
52227 ≡ 1(mod 1729) and 52127 ≡ 1065(mod 1729)
Therefore we have determined that 1729 is not prime since x2im≡ 1 (mod p), but x2i−1m 6≡ ±1 (mod p)
is true.
27

3.1.3 Implementation of Prime Number Generator
Below a 2048 bits prime number that we generated using the Miller-Rabin primality test. This prime
was generated in less than 30 seconds.
23571962325241536593960467483698095529751973889968927609297401326668848041472225185680139889479932923153775477415837144043662334875919228020609052311346297799418422015633927244494686617219957781472723810289278692170001520702559705900881871724963635604196792403202078931302187263276063992430688203169868818258282849678896306519465704524925114376228762851358711390850769302501083805182565139614168994028247650466478745556073024953194566415192828974272586275822736606625074781378726988479945096887748888508415442585823636860568265930926120711621578822968288585406032916361209741298869017669673610846969552796709279430983
To handle large integer, we used GMP C++ library the same used in sieve of Eratosthenes.
EvaluationFrom the prime number just shown above of a 2048 bits which was generated in less 30 seconds com-
pared to the sieve of Eratosthenes algorithm that generated the prime 9103482433 in 4 days, clearly,
the Miller-Rabin primality test is a more efficient algorithm for generating prime numbers. Further-
more, considering that 9103482433 is only 34 bits, this demonstrate that the sieve of Eratosthenes
algorithm is indeed too slow. This empirical evidence support our choice to use primality test for
generating primes as a replacement to the sieve of Eratosthenes algorithm.
28

Chapter 4
RSA Algorithm
In chapter 2 and chapter 3, we discussed the background of RSA and the relevant algorithms for
the implementation of RSA. In this chapter, we look at the RSA cryptosystem in detail. Section 4.1
presents the derivation of RSA algorithm. In Section 4.3, we present the implementation of RSA.
4.1 Derivation
We outlined the RSA algorithm in 2.1.2. Below is the RSA encryption and decryption.
Given two prime number p and q then N = pq
Encryption: C ≡Me(mod N) (4.1)
Decryption: M ≡Cd(mod N) (4.2)
ϕ(N) = (q−1)(p−1) (4.3)
ed = 1 ( mod ϕ(N)) (4.4)
where: e < Nand gcd(ϕ(N),e) = 1 i.e ϕ(N) and e in equation 4.4
and: C = CiphertextM = Plaintext(e,N) = Public key(d,N) = Private key
Equation 4.4 written as linear Diophantine is:
ed = 1+ϕ(N)k (4.5)
where: k is some constant.
To prove that RSA is correct we have to show that both 4.1 and 4.2 are true.
29

Chinese Remainder TheoremBefore we go in to the proof of the correctness of RSA algorithm as presented in [1, 19, 14, 29], let
us first look at the Chinese Remainder Theorem(CRT). [1, 14, 29] shows the correctness of the RSA
algorithm using CRT.
Theorem 4.1.1 (Chinese Remainder Theorem).
If n1,n2,n3, ...,nk are coprime, with N =k
∏j=1
n j, and a1,a2,a3, ...,ak are any integers, then the set of
recurrences:
x≡ a1(mod n1)
x≡ a2(mod n2)
.
.
.
x≡ ak(mod nk)
has a unique solution mod N.
Example 4.1.1 (Application of Chinese Remainder Theorem).Compute a number which leaves remainder 9 when divided by 13, 5 when divided by 9, and 9 when
divided by 23
SolutionLet n1 = 13,n2 = 9 and n3 = 23
Let a1 = 9,n2 = 5 and n3 = 9
∴ N = n1 ∗n2 ∗n3 = 13∗9∗23 = 2691
and N1 =Nn1
= 207, N2 =Nn2
= 299, N3 =Nn3
= 117
By using the Extended Euclidean Algorithm we solve the following linear Diophantine for equations
mk:
m1 ≡ 207−1 ≡−1≡ 12 (mod 13) since: 207m1 +13a = b
m2 ≡ 299−1 ≡−4≡ 5 (mod 9) since: 299m2 +9c = d
m3 ≡ 117−1 ≡−11≡ 12 (mod 23) since: 117m3 +23e = f
∴ x≡ 12∗9∗207+5∗5∗299+12∗9∗117≡ 42467≡ 2102 (mod 2691), hence the number is 2102.
Furthermore, the set of all numbers that satisfies the question are of the form 2012+ 2691i where
i ∈ {0,1,2,3,4, ...}.
Proof of the correctness of RSA
30

By using the CRT, theorem 4.3.1, n1 = p , n2 = q and N = pq. Combining equation 4.1 and 4.2. Then
substituting for ed.
First considering (mod p)
Cd ≡ (Me)d (mod p)≡ Med (mod p)≡ M1+ϕ(N)k (mod p)≡ M1+(p−1)(q−1)k (mod p)≡ MM(p−1)(q−1)k (mod p) using Fermat’s Little Theorem 3.1.5≡ M(1)(q−1)k (mod p)
Med ≡ M (mod p)
Second considering (mod q)
Cd ≡ (Me)d (mod q)≡ Med (mod q)≡ M1+ϕ(N)k (mod q)≡ M1+(p−1)(q−1)k (mod q)≡ MM(p−1)(q−1)k (mod q) using Fermat’s Little Theorem 3.1.5≡ M(1)(p−1)k (mod q)
Med ≡ M (mod q)
Therefore we have Med ≡ M (mod p) and Med ≡ M (mod q) . And since p and q are coprime and
N = pq, then by Chinese Remainder Theorem:
Med ≡ M (mod N)
Therefore we see that the encryption and decryption process of the RSA algorithm is indeed correct.
According to the [11], RFC2437, the maximum message M recommended is 1 < M < N. Using RSA
to loop through a message M > N to encode it in chunks in not recommended.
4.2 RSA Signature
The digital signature application of the RSA algorithm is just the use of the RSA in the opposite di-
rection [19]. If Bob encrypts a plaintext using his private key and send the ciphertext to Alice. Then
Alice decrypts the plaintext using the Bob’s public key. If the decrypted text by Alice match the plain-
text that Bob claims to have sent to Alice, then Alice knows that the message decrypted is indeed Bob
signature.
Given two prime number p and q then N = pq
Encryption: S≡Md(mod N) (4.6)
Decryption: M ≡ Se(mod N) (4.7)
31

where: S = SignatureM = Plaintext(e,N) = Public key(d,N) = Private key
4.3 RSA Algorithm Implementation
In 2.1.2 we gave an outline of the RSA algorithm. In this section we are going to present the pseudo-
code implementation of our version of the RSA algorithm. In Chapter 3 we introduced some algo-
rithms and number theory that are relevant for the implementation of the RSA and RSA attacks. In
this section, we are going to show how some of these algorithms discussed in Chapter 3 are used in
our implementation of the RSA algorithm.
We generate prime numbers p and q for RSA by accessing prime numbers from the MySQL database.
For security reasons, in the recommended implementation of RSA, once the public and private keys
are generated, the two prime numbers are discarded [14, 19]. However, for our implementation, we
have not implemented this measure. Instead, we have used a pre-generated list of prime numbers that
we have stored in a MySQL database.
We present our implementation of RSA as follows. Firstly, we present the RSA algorithm imple-
mented in pseudo-code. Then we show the correctness of our implemented algorithm. This demon-
strates the correctness of our implementation of the RSA algorithm in the project. Finally we give an
example of the RSA algorithm.
4.3.1 RSA Algorithm Pseudo-code
We present our version of the implementation of the RSA algorithm in three main components: Key
Generation, Encryption, and Decryption phases. The Key Generation phase generates the public key
(e,N) and the private key (d,N). The Encryption phase encrypts the plaintext(M) to the ciphertext(C).
The Decryption phase decrypts the ciphertext(C) to the original plaintext(C). Below is the pseudo-
code of our version of the implementation of the RSA algorithm.
32

Key Generation
NAME : RSA algorithm key generationINPUT : bit size of the prime numberOUTPUT : public key and private key
1: RSA GENERATE KEYS()
2: p← Choose a prime number uniformly at random from the database
3: q← Choose a prime number uniformly at random from the database
4: N← p∗q
5: ϕ(N)← (p−1)(q−1)
6: e =COMPUT E PUBLIC EXPONENT (ϕ(N),N)
7: PUBLIC KEY ← (N,e)
8: (d,k,gd)← extend gcd(e,ϕ(N))
9: if d < 0 then10: d← d +N
11: end if12: PRIVAT E KEY ← (N,d)
13: return (PUBLIC KEY,PRIVAT E KEY )
Compute Public Exponent(CPE) algorithm implements of STEP 6 of RSA algorithm key generation
above.
NAME : RSA algorithm Compute Public ExponentINPUT : ϕ(N) and NOUTPUT : Encryption exponent e
1: COMPUTE PUBLIC EXPONENT(ϕ(N), N)
2: while TRUE do3: r← generate a number uniformly at random
4: e← r (mod (N−2))+2
5: if gcd(e,ϕ(N)) = 1 then6: return e
7: end if8: end while
Correctness of Key Generation PhaseSTEP 1 to STEP 5 are clearly correct. STEP 2 which similar to STEP 3 though, complex in prac-
tice to implement since it requires connecting to and accessing a database, is correct since all numbers
in the database have been shown to be probably prime with a very higher probability in section 3.1.1.1.
STEP 6 computes the public exponent e. Since this STEP is complex, we decided to implement it
33

as a separate method called COMPUTE PUBLIC EXPONENT(ϕ(N),N). This is an example of a Las
Vegas algorithm we defined in section 3.1.5. This algorithm searches for a number e which is coprime
to ϕ(N) and is 2 < e < N. We require the lower bound 2 because we do not want to accept 0 or 1.
This algorithm uses the Euclidean algorithm, gcd(a,b), which we already know is correct. Therefore
STEP 6 is correct.
STEP 7 generates the public key(N,e). STEP 8 uses the Extended Euclidean algorithm to solve
ed = 1+ϕ(N)k for the private exponent d.We know that the Extended Euclidean algorithm,
extend gcd(e,ϕ(N)), is correct, therefore the result is correct. Because we want d to be positive,
STEP 9 TO 11 converts d to an equivalent positive value if d is negative. STEP 11 and STEP 13
generates the private key and return the keys respectively. Hence the overall key generating phase of
the RSA algorithm is correct.
Encryption
NAME : RSA algorithm EncryptionINPUT : Plaintext (M) and Public key(N,e)OUTPUT : Ciphertext (C)
1: RSA ENCRYPTION(M, PUBLIC KEY)
2: e← PUBLIC KEY.get public exponent()
3: N← PUBLIC KEY.get modulus()
4: C← f ast exp(M,e,N)
5: return C
Correctness of Key Encryption PhaseSTEP 1 just receives the input so it is correct. STEPS 2 and 3 retrieves the public exponent (e) and
the modulus (N) of the public key respectively hence both STEPS give the correct results. STEP 4
computes C=Me( mod N) using the fast modular exponentiation algorithm. But we know that fast
modular exponentiation is correct, hence the encryption phase of the RSA algorithm is correct.
Decryption
NAME : RSA algorithm DecryptionINPUT : Ciphertext (C) and Private key(N,d)OUTPUT : Plaintext (M)
1: RSA DECRYPTION(C, PRIVATE KEY)
2: d← PRIVAT E KEY.get private exponent()
3: N← PRIVAT E KEY.get modulus()
4: M← f ast exp(M,d,N)
5: return M
34

Correctness of Key Decryption PhaseSTEP 1 gets the input so it is correct. STEPS 2 and 3 retrieves the private exponent (d) and the mod-
ulus (N) of the public key respectively hence both STEPS give the correct results. STEP 4 computes
M=Cd( mod N) using the fast modular exponentiation algorithm. But we know that fast modular
exponentiation is correct, hence the decryption phase of the RSA algorithm is correct.
RSA Algorithm ExampleTo complete this chapter we give a complete example of operation of the RSA algorithm below. We
are going to demonstrate the operation of each STEP of our version of the RSA algorithm pseudo-code
as outline in the above section.
Example 4.3.1 (Application of RSA Algorithm).Use the following prime number: 13 and 19 to encrypt and then decrypt back the plaintext 119 using
the RSA algorithm.
SolutionTo illustrate this example we are going to go through each of the phases of the RSA algorithm in the
following order: key generation, encryption and finally decryption.
Key Generation
STEP 1: RSA GENERATE KEYS()STEP 2: p← Choose a prime number uniformly at random from the database
p← 13STEP 3: q← Choose a prime number uniformly at random from the database
p← 19STEP 4: Compute N← p∗q
N← 247← p∗qSTEP 5: Compute ϕ(N)← (p−1)∗ (q−1)
ϕ(N)← 216← (p−1)∗ (q−1)STEP 6: Compute e←COMPUT E PUBLIC EXPONENT (ϕ(N),N)
e← 197 //Assume the return value is e = 197STEP 7: Generate PUBLIC KEY ← (N,e)
PUBLIC KEY ← (247,197)STEP 8: Compute (d,k,gd)← extend gcd(e,ϕ(N))
(d,k,gd)← (−91,83,1)← extend gcd(e,ϕ(N))d←−91k← 83, gd← 1Notice that (83)216 - (91)197 = 1 hence indeed correct
STEP 9 to 11: Since d < 0 thend← 125← (−91+247)
STEP 12: Generate PRIVAT E KEY ← (N,d)PRIVAT E KEY ← (247,125)
35

STEP 13: return (PUBLIC KEY,PRIVAT E KEY )
We have generated the keys. Public key is (247,197) and the private key is (247,125)
EncryptionGiven that M = 119
STEP 1: RSA ENCRYPTION(M, PUBLIC KEY)STEP 2: e← 197← PUBLIC KEY.get public exponent()STEP 3: N← 247← PUBLIC KEY.get modulus()STEP 4: C← 175← f ast exp(M,e,N)STEP 5: return C
Therefore the ciphertext is C = 175.
DecryptionGiven that C = 175
STEP 1: RSA DECRYPTION(C, PRIVATE KEY)STEP 2: d← 125← PRIVAT E KEY.get public exponent()STEP 3: N← 247← PRIVAT E KEY.get modulus()STEP 4: M← 119← f ast exp(C,d,N)STEP 5: return M
Hence we have decrypted back M = 119 using RSA algorithm.
36

Chapter 5
Integer Factorisation Attack
5.1 Overview
In this chapter we study the Integer Factorisation Attack (IFA). In section 5.2 we define the IFA and
show how IFA results in an effective attack on RSA. Section 5.3 presents our implementation of
the IFA attack using PARI/GP library, C and C++. Then in 5.4 we present the result of IFA attack
and in section 5.5 we present an evaluation of IFA. Section 5.6 gives the conclusion. The IFA we
implemented is from [29].
5.2 Problem
Given that:
N = p∗q
The IFA attempts to find p and q given N. The crytanalyst has access to N through the public key -
(N,e).
If the cryptanalyst mananges to factor N then the private key can easly be computed by solving
ed = 1 ( mod ϕ(N))
Since ϕ(N) = (q− 1)(p− 1). Hence computing the private key - (N,d). With the private key, the
cryptanalyst can decrypt any ciphertext, C, encrypted by the public key - (N,e).
5.3 Implementation
For the implementation of IFA, we initially used the factoring, f actor, utility program found in most
linux computers. However, we observed that on the computer we were using, the size of integers that
this program was able to factor were relatively too small. This then restrict the data we could collect
37

for experimentation and evaluation of this project. As a result, we had to look for a better implemen-
tation of factoring that could help us meet the requirement of this project. In searching for a method
that implements factoring, we were also restricted by the programming language we were using. We
wanted a C++ Library that implements factoring.
After our research, we found that PARI/GP, a free library, has an implementation of factoring that is
suitable for our project. According to [26], PARI factoring can factor integer with 70 digits in minutes
and a few hours are needed for 80 digits. [26] also provides a comparison of PARI/GP with other free
implementation of factoring such as mpqs4linux and PPMQS-2.8.
The main challenge we encountered in using PARI/GP is that PARI is a C library though compati-
ble with C++. Linking PARI/GP and C++ proved challenging considering the time constraint on the
project. But we noticed that PARI implements a high level scripting language, GP, that is easier to
use. GP code can easly be converted to C code using a compiler called gp2c. The C code generated by
gp2c was then used in our C++ for factoring integers since C and C++ are compatible by just making
minor changes[26].
Using our database of pre-generated prime numbers, we randomly choose two prime numbers of a
specific bit size and multipled them to get N. Then using N as an input to factoring, we recorded the
time it took to factoring N back to its respective primes p and q, and the size of N in bits. For each
class of k-bits we collected 5 samples. The sampling is useful so that we use average values rather
than instantaneous values to get a more general picture during the evaluation. The choice of 5 was
just a calculated guess. We assumed that if in the worst case we have an N of k-bits that takes 15
minutes to factor, then 5 instances will require around 75 minutes. Though this seems like a lot of
time, it is reasonable considering that in some factoring challenges, a network of computer can be left
for months, a year or even more just to factor a single integer. For instance in factoring of a 768-bit
RSA modulus, they took half a year on 80 processors to just carryout 3% of the work involved [12].
5.4 Results
Below we present a sample of the data we collected for the IFA implementation. To save page space,
we just present sample data. The complete data is included as part of the software and data submission
for this project. The size in bits of prime number, p and q, used for IFA ranged from 10 bits to 133
bits. This gaves us N values in bits ranging from 20 to 266 bits.
38

time in ms p q bits of prime bits of N
44 1511969280449229209 1453565871750771509 61 121
80 2617954980469110773 2538982672195970107 62 123
84 5967435046885144187 8074283997402795079 63 126
76 13197165715209486053 16599754519836165133 64 128
124 28339492560213699583 32353759234428686917 65 130
172 58760095216376192417 68200217635689129343 66 132
116 121618895759685534877 110749351902607376113 67 134
128 222459516146686405159 187890264845069820883 68 135
172 446863138405796961799 416699769278484321731 69 138
Table 5.1: Sample data for IFA
The largest integer (N = p∗q) we managed to factor was 266 bits:
78099244341709058783109831272856339765970662450718439533984356961308504821849099
Where
p = 7453567484929947055748327257204221459931
q = 10478102532728739453507260842717211978129
It took 1040776 ms to factor. This is about 17 minutes.
The table below presents 5 instances of sample with prime numbers of 69 bits. Notice the variation in
time taken hence the need for averaging.
time in ms p q bits of prime bits of N
172 446863138405796961799 416699769278484321731 69 138
180 446863138405796961799 416699769278484321731 69 138
172 446863138405796961799 416699769278484321731 69 138
132 471863670058907684669 400047128601770180143 69 138
148 348228572866212381997 455538680544510328877 69 137
Table 5.2: Sample data where p and q are 69 bits
5.5 Evaluation
To investigate the relationship between the time taken for the IFA to factor the modulus N we plotted
a graph of time in seconds against the size in bits of N using Mathlab Software [18].
From figure 5.1 we observe that the relationship between factorisation time and size in bits of N seem
to be exponential in growth. After a certain size of N in bits, in this case around 200 bits, a further
39

0 50 100 150 200 250 3000
200
400
600
800
1000
1200
1400
N (bits)
Tim
e (s
econ
ds)
Relationship between the factorisation time and size of N in bits
Figure 5.1: Relationship between the factorisation time and the size of N in bits
small increase in bit size results in a large increase in time require to factor N.
To verify if indeed this relationship is exponential, we plot the natural log of time and bit size. If we
get a linear relationship, then this confirms that the relationship in figure 5.1 is probably exponential.
5 5.1 5.2 5.3 5.4 5.5 5.60
1
2
3
4
5
6
7
8
In(bits)
In(ti
me)
Natural log of the factorisation time against the natural log of size of N in bits
Figure 5.2: Relationship between natural log of time and natural log of N in bits
Observe that the data seems to be distribute in a linear pattern. Below we are going to use averaged
values of the data to plot similar graphs that are less scattered and then generate a model of the distri-
bution.
Rationale between the connection of exponential graph and linear graphHere we explain why we use a linear graph to verify an exponential relationship between factorisation
time and bit size of N.
40
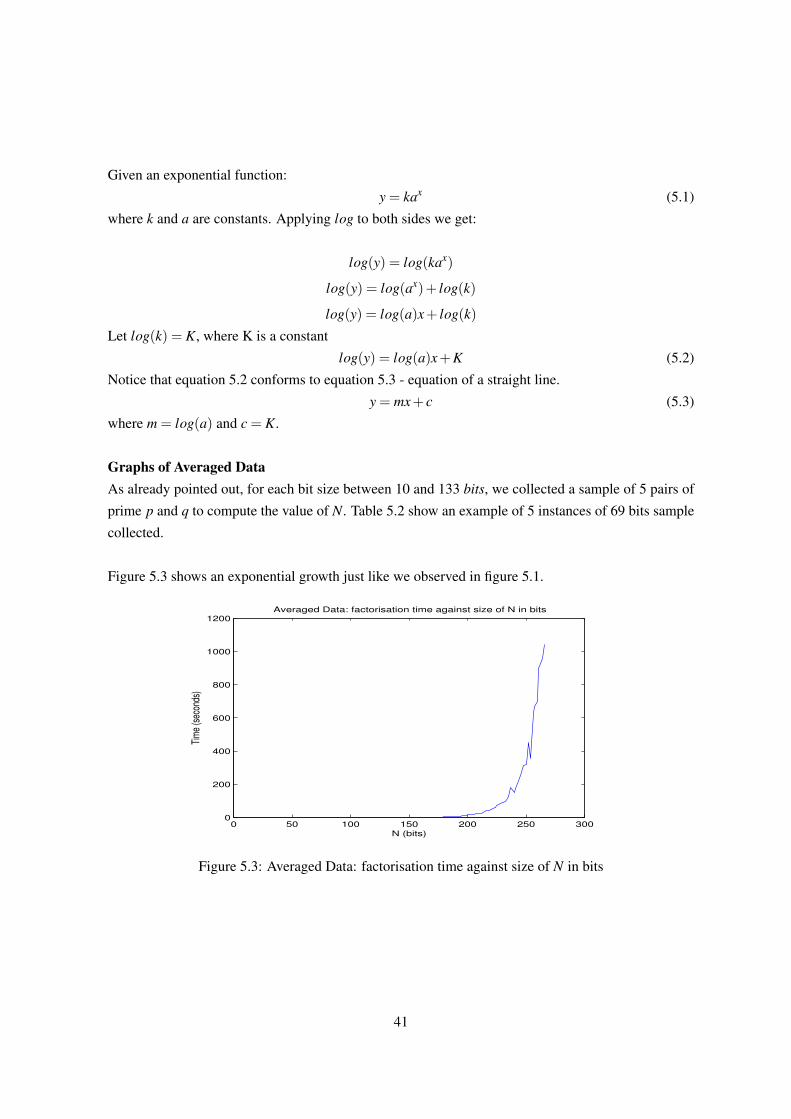
Given an exponential function:
y = kax (5.1)
where k and a are constants. Applying log to both sides we get:
log(y) = log(kax)
log(y) = log(ax)+ log(k)
log(y) = log(a)x+ log(k)
Let log(k) = K, where K is a constant
log(y) = log(a)x+K (5.2)
Notice that equation 5.2 conforms to equation 5.3 - equation of a straight line.
y = mx+ c (5.3)
where m = log(a) and c = K.
Graphs of Averaged DataAs already pointed out, for each bit size between 10 and 133 bits, we collected a sample of 5 pairs of
prime p and q to compute the value of N. Table 5.2 show an example of 5 instances of 69 bits sample
collected.
Figure 5.3 shows an exponential growth just like we observed in figure 5.1.
0 50 100 150 200 250 3000
200
400
600
800
1000
1200
N (bits)
Tim
e (s
econ
ds)
Averaged Data: factorisation time against size of N in bits
Figure 5.3: Averaged Data: factorisation time against size of N in bits
41

5 5.1 5.2 5.3 5.4 5.5 5.60
1
2
3
4
5
6
7
ln(bits)
ln(ti
me)
Average Data: Natural log of factorisation time against size of N in bits
averaged IFA data
linear model (y = 14x −71)
Figure 5.4: Averaged Data: Natural log of factorisation time against natural log of size of N in bits
Figure 5.3 shows the natural logarithm of the averaged values and the corresponding linear model.
We should point out that the parameters to the model are specific to the computer we were using since
they depend on the processor speed and memory. If we were using a different computer, the values
would have been different.
5.6 Conclusion
In this Chapter, we have seen that IFA has an exponential growth. Below a certain bit size of N, IFA
can be applied efficiently and effectively as IFA will successfully break RSA. Using the graphs we
generated, Figure 5.3 and 5.1, for this particular case, we observe that for up to N equal to 250 bits
IFA was efficient. However, after the threshold more time is require hence IFA becomes intractable as
the number of bits increase. Our observation support the recommendation that the large the number
of bits of N, the more secure is RSA [6, 29].
42

Chapter 6
Guessing Plaintext Attack
6.1 Overview
In this chapter we study the Guessing Plaintext Attack (GPA). In section 6.2 we define GPA and show
how GPA might results in an effective attack on RSA. Section 6.3 presents our implementation of
the GPA attack. In this section, we have implemented two approaches to GPA: a linear search and a
random search. Each approach is presented with its results and evaluation. Finally in section 6.4 we
present a general conclusion to GPA. The GPA we implement is from [29].
6.2 Problem
We know that RSA encryption is done by C ≡Me(mod N) where e and N form the public key. If a
cryptanalyst intercepts ciphertext C, they can use it for guessing the plaintext M as follows:
Let Mg be guessed plaintext
Let Cg ≡ (Mg)e(mod N) where Cg is ciphertext of the guessed plaintext Mg.
If Cg is equal to C then the guessed plaintext Mg is equal to M since RSA is a function such that for
every valid input M to RSA encryption, there is one and only one corresponding output C.
Hence we see that using the intercepted ciphertext C a cryptanalyst can verify if the guessed plaintext
Mg is correct hence successfully attacking RSA.
6.3 Implementation
The possible valid values for M are within the range 0 < Mg < N. Therefore the solution should guess
Mg from values within the range 0 < Mg < N until M is found. Verification of true M is done by
checking if C is equal to Cg. We implemented GPA using two approaches. 1) In the first approach we
43

attempt to search exhaustively for Mg in the range 0 < Mg < N using a linear search. In linear search
the possible values of Mg are checked progressive from 1 to N− 1. This approach is sensible when
the value of prime numbers are small as is the case in this project since N = p ∗ q hence the search
space 0 < Mg < N is reduced as well. 2) The second approach was to randomly guess Mg in the search
space 0 < Mg < N without repetition.
6.3.1 Approach 1: Linear Search
In addition to experimenting with the size of M in bits, since to verify if Mg is true, we compute
Cg ≡ (Mg)e(mod N), we also explored the effect of changing the size of e in bits and the time taken
to correctly guess the plaintext M.
Let Mset = {M1,M2,M3,M4...Mk} be a set of plaintext of specific bit size.
Let eset = {e1,e2,e3,e4...ek} be a set of public exponent of a specific bit size.
For each e ∈ eset we computed C ≡Me(mod N) for every M ∈Mset . Then attempt to guess M using
Cg ≡ (Mg)e(mod N) until we find Cg equal to C as outlined in section ??.
Approach 1: Results
The size of the value of e we used in bits ranged for 10 bits to 19 bits. The size of M in bits ranged
from 8 to 22 bits.
eset = {10, 11, 12, 13, 14, 15, 16, 17, 18, 19}
Mset = {8, 9, 10, 11, 12, 13, 15, 16, ... 21, 22}
We initially wanted to use larger values of M but after 22 bits it was infeasible to apply GPA using all
values in eset considering the time limitation and project schedule.
However, to at least get data for large value of M in bits we focused on e equal to 10 bits and then
used larger values of M.
44

Approach 1: Evaluation
8 10 12 14 16 18 20 220
5
10
15
20
25
M (bits)
time
(sec
onds
)
Relationship between time taken to Guess plaintext and size in bits of plain text
e = 10 bit
e = 11 bit
e = 12 bit
e = 13 bit
e = 14 bit
e = 15 bit
e = 16 bit
e = 17 bit
e = 18 bit
e = 19 bit
Figure 6.1: Each graph represents a constant e in bits
From figure 6.1 and 6.2 we observe that guessing plaintext has an exponential growth in time required
to successfully guess M. Figure 6.1 show the graphs showing the relationships among size of plaintext
M in bits, size of public exponent e and time required to guess the plaintext. From the graphs we
observe that as the size of e increases in bits the hard it is to use GPA. Notice that the graph with
e = 19 bits demands more time for GPA compared to when e = 10 bits.
2 2.5 3 3.5−8
−6
−4
−2
0
2
4
In(bits)
ln(t
ime)
The natural log of the plaintext guessing time against the natural log of size of M in bits
10 bit
11 bit
12 bit
13 bit
14 bit
15 bit
16 bit
17 bit
18 bit
19 bit
Figure 6.2: The natural log of the plaintext guessing time against the natural log of size of M in bits
Below, we explore GPA further for e = 10 and larger values of M in bits. In this case we have used bits
of M in the range from 8 to 34 and for each bit size we sampled 5 instances and average the values.
45

5 10 15 20 25 30 350
200
400
600
800
1000
1200
M (bits)
time
(min
utes
)
Relationship between time taken to guess plaintext and size in bits of M
e = 10 bit
Figure 6.3: Guessing plaintext M where e = 10 bits. M is in the range of even numbers between 8 to34 bits
From figure 6.3 we observe how the time required to guess plaintext increase exponentially for a
relatively small increase in bits of M size. Notice that the time in this case is in minutes as compare
to figure 6.1 where the time was in seconds. In fact to guess when M is 34 bits it took more than 18
hour.
6.3.2 Approach 2: Random Search
For this approach we used the random number generator to attempt to guess M by generating various
values of Mg between 0 < Mg < N as we stated in section ??. Figure 6.4 show the distribution of the
data we generated.
8 9 10 11 12 13 14 15 160
50
100
150
200
250
300
350
400
450
M (bits)
time
(min
utes
)
Relationship between time taken to randomly guess plaintextagainst the size in bits of M
e = 10 bit
Figure 6.4: Guessing plaintext M randomly where e = 10 bits. M is in the range of numbers between8 to 16 bits
46

6.4 Conclusion
Comparing figure 6.3 and 6.4 we see that approach 1, Linear Search, performed much better that ap-
proach 2, random search. Observe that from figure 6.3 in 400 seconds, an M of 30 bit is successfully
guessed as compare to figure 6.4 where only an M of 16 bit is successfully guessed in 400 seconds.
However, in both cases, we see the exponential growth in time required to guess RSA plaintext. In
both cases we also see that the larger the text the harder it is to successfully apply GPA. Therefore we
the that GPA is practically efficient for small values of plaintext M. For large values, the efficiency of
GPA decreases exponentially.
Another interesting observation is the effect of the magnitude of the public exponent e on the security
of RSA. From figure 6.1 we notice that the larger the value of e the harder it is apply GPA successfully.
Notice from figure 6.1 also that the time require to successfully guess M increases with the increase
in e progressively for the same value of M. With e = 10 being the least while e = 19 being the most
challenging to apply GPA successfully.
47

Chapter 7
Guessing ϕ(N) Attack
7.1 Overview
In this chapter we study the Guessing ϕ(N) Attack (Gϕ(N)A) on RSA. In section 7.2 we define
Gϕ(N)A and show how Gϕ(N)A might results in an effective attack on RSA. Then Section 7.3 out-
lines what the general approach the solution to Gϕ(N)A takes. Section 7.4 presents our implementa-
tion of the Gϕ(N)A attack. In this section, we have implemented a linear search of ϕ(N). Then in
7.5 we present the results Gϕ(N)A and in section 7.6 we present an evaluation of Gϕ(N)A. Finally in
section 7.7 we present a conclusion to Gϕ(N)A. The source of background information on Gϕ(N)A
we study is from [29].
7.2 Problem
In Chapter 4 we showed that to calculate the private exponent (d) we have to solve the following
equation 4.4: ed = 1 ( mod ϕ(N)). With d, we can now simply decrypt the ciphertext C using
M ≡Cd(mod N) where p and N form the private key. With the knowledge of N, a cryptanalyst can
attempt to guess ϕ(N) as follows as outline in [29]:
N = pq (7.1)
ϕ(N) = (p−1)(q−1) (7.2)
∴ pq− p−q+1−ϕ(N) = 0 (7.3)
substituting q = N/p into 7.3 we get
p2− (N−ϕ(N)+1)p+N = 0 (7.4)
Let A = N−ϕ(N)+1, then
(p,q) =A±√
A2−4N2
(7.5)
Equation 7.5 has only one unknown A since we can obtain N from the public key. If we successfully
guess A then we have the two RSA prime numbers p and q. With these primes we can compute ϕ(N).
48

7.3 Solution
From equation 7.5, we notice that√
A2−4N has to be a positive integer in order for us to get a valid
solution. Therefore A should have the following constraint: A≥d2√
Ne. Hence our solution considers
every integer greater that or equal to d2√
Ne as a potential candidate to the value of A.
Also we notice that since A = N−ϕ(N)+1, if we subtitute equations 7.1 and 7.2 we get:
A = p+q (7.6)
Equation 7.6 and constraint A≥ d2√
Ne tells that when the difference between p and q is small, then
Gϕ(N)A could effectively search for A. Also, equation 7.6 tells us that A is always an even number
since both p and q are odd numbers.
Example 7.3.1 (Guessing ϕ(N) Attack).Find A given N = 247. Assume that the primes p = 13 and q = 19 have not been given.
SolutionSince A≥ d2
√Ne therefore A≥ d2
√247e= 32
(19,13) =A±√
322−4∗2472
As expected.
7.4 Linear Search Implementation
Given N our solution first computes d2√
Ne. The check if d2√
Ne is a valid solution of A by substi-
tuting the values of d2√
Ne and N in to equation 7.5. If the value of p and q are prime and p∗q = N
then we know that A is correct. Since the prime factor of N are unique as state by the Fundamental
Theorem of Arithmetic - theorem 3.1.4. If A is not correct the we progressively increase d2√
Ne by
2 until we find a valid A. The increment by 2 is because we are searching for even numbers only.
Primality test is performed using Miller-Rabin primality test.
7.5 Results
We generated values of p and q from 4 bits to 35 bits. This gave us the values of N in the range of 8
bits to 70 bits. For each set of n bits size integers, we sample 5 instances of integers. For each integer
N we collected the prime number q and p, the time taken to successfully apply Gϕ(N)A, the bit size
of ϕ(N) and the bit size of N.
Below we present a sample of the data we collected for the Gϕ(N)A implementation. The complete
data is included as part of the software and data submission for this project.
49
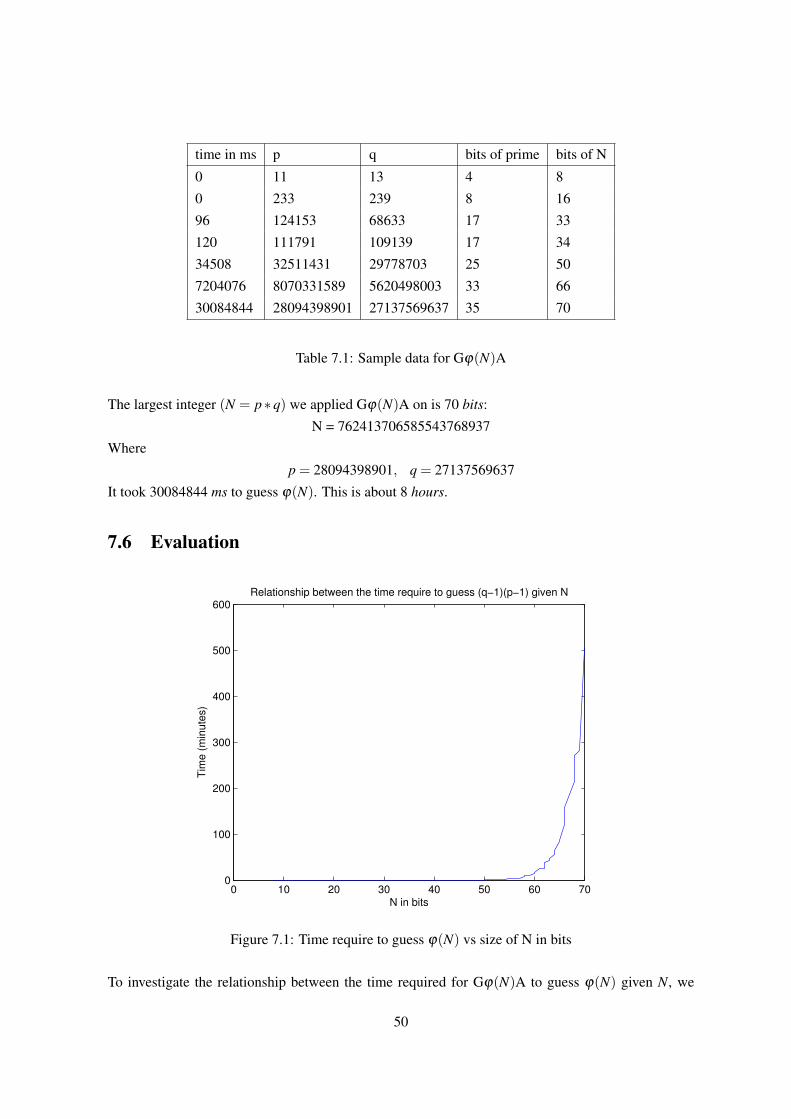
time in ms p q bits of prime bits of N
0 11 13 4 8
0 233 239 8 16
96 124153 68633 17 33
120 111791 109139 17 34
34508 32511431 29778703 25 50
7204076 8070331589 5620498003 33 66
30084844 28094398901 27137569637 35 70
Table 7.1: Sample data for Gϕ(N)A
The largest integer (N = p∗q) we applied Gϕ(N)A on is 70 bits:
N = 762413706585543768937
Where
p = 28094398901, q = 27137569637
It took 30084844 ms to guess ϕ(N). This is about 8 hours.
7.6 Evaluation
0 10 20 30 40 50 60 700
100
200
300
400
500
600
N in bits
Tim
e (
min
ute
s)
Relationship between the time require to guess (q−1)(p−1) given N
Figure 7.1: Time require to guess ϕ(N) vs size of N in bits
To investigate the relationship between the time required for Gϕ(N)A to guess ϕ(N) given N, we
50

plotted a graph of time in minutes against the size of N in bits. Figure 7.1 shows the graph.
From figure 7.1 we observe that the relationship between the time and the size of N seems to follow an
exponential growth. Figure 7.2 seems to support our observation since the logarithm of time against
bit size of N graph has a linear pattern (In Chapter 5, we showed the relationship between exponential
and linear graphs).
According to figure 7.1, when the size of N is below 60 bits, the time require to guess ϕ(N) is less
than approximately 10 minutes. However, just above 60 bits, the time starts increasing exponentially.
From 60 bits to 70 bits, the time required to guess ϕ(N) increases from approximately 10 minutes to
approximately 500 minutes.
Within the interval 60 bits to 70 bits, the change in bit size is only 10 bits. In contrasts, the changed in
time required to guess ϕ(N) within the same interval is approximately 450 minutes. This gives a rate
of change of approximately 45 minutes per bit within the interval 60 bits to 70 bits of N.
2 2.5 3 3.5 4 4.5−10
−8
−6
−4
−2
0
2
4
6
8
ln(t
ime
)
The natural log of time against the natural log of size of N in bits
ln(bits)
Figure 7.2: Each graph represents a constant e in bits
7.7 Conclusion
In this chapter we have seen that the time required to guess ϕ(N) increases exponentially as the
number of bits of N increases linearly. From this observation we can deduce that there is a certain
value of N below which Gϕ(N)A might be applied efficiently and effectively. But after the threshold,
the time grows exponentially hence making guessing ϕ(N) attack inefficient.
51

Chapter 8
Project evaluation
8.1 Overview
In this chapter, we present an overall evaluation of the project. Section 8.2, we evaluate the three
cryptanalysis attacks on RSA we implemented. We then establish among the three attacks which of
attacks is the most efficient and effective according to the experiments we carried out. In section 8.3,
we present an evaluation of the implementations made in this project. Then section 8.4 explains how
the aim, minimum requirement and further enhancement of the project were achieved. Finally in 8.5
we suggest further work that can be done in this project.
8.2 Evaluation: Comparison of the RSA attacks
Below we present graphs of three attacks that were generated in chapters 5, 6, and 7. From the graphs
we evaluate the three RSA attacks.
0 50 100 150 200 250 3000
200
400
600
800
1000
1200
1400
N (bits)
Tim
e (s
econ
ds)
Relationship between the factorisation time and size of N in bits
Figure 8.1: Relationship between the factorisation time and the size of N in bits
52

5 10 15 20 25 30 350
200
400
600
800
1000
1200
M (bits)
time
(min
utes
)
Relationship between time taken to guess plaintext and size in bits of M
e = 10 bit
Figure 8.2: Guessing plaintext M where e = 10 bits. M is in the range of even numbers between 8 to34 bits
0 10 20 30 40 50 60 700
100
200
300
400
500
600
N in bits
Tim
e (m
inut
es)
Relationship between the time require to guess (q−1)(p−1) given N
Figure 8.3: Time require to guess ϕ(N) vs size of N in bits
Figures 8.1, 8.2, 8.3 represent the integer factorisation attack (IFA), guessing plaintext attack and
geussing ϕ(N) respectively. In each case, we see that the time required to break RSA for each attack
grows exponentially. In chapter 5, 6 and 7, we demonstrated exponential growth in each case. How-
ever, for a given bit size of the input, we noticed that the IFA attack is the most effective and efficient
considering the above figures. With the second best attack being the guessing ϕ(N). Finally the worst
among the three is the guessing plaintext.
In all cases, we see that each of these attacks has a minimum threshold value within which it might be
effective and efficient. For instance IFA is very efficient when the size of N is below 250 bits.
53

8.3 Evaluation of the Implementation
We have managed to successfully implement all the algorithm that were relevant for the successful
completion of the project. Due to the requirement of the project, we had to implement some of the
algorithms in a non standard form. For instance, our implementation of the RSA algorithm was im-
plemented in a non standard format. According to the specification of RSA [11, 29, 6], the prime
numbers in RSA are supposed to be discarded once used. However, for our implementation in this
project, we had to use the database as a source of prime numbers due to the requirement of the project.
This proved to be a good approach as we did not find any major problem in accessing prime numbers.
Though the project, the programming language used was C++ with exceptional cases that required the
use of C. The reason we chose C++ it is one of the fastest and efficient computer language [23].
In the implementation, the main challenge we face was that some algorithm did not preform as ex-
pected. The Sieve of Eratosthenes algorithm we had considered initially for the generating of prime
numbers proved inefficient. Therefore we used primality test algorithms which proved to be efficient.
8.4 Assessment of Project
In this section we evaluate the aim and requirement of the project against what we have achieved. For
each section we are going to state if it has been achieved and how we have achieved it.
AimThe aim of this project is to gather some information on possible attacks on RSA, to implement some
of these RSA attacks and test their efficiency and effectiveness in practice by using relatively small
prime numbers.
STATUS: ACHIEVED
we have implement three RSA attacks and in chapter 5, 6, and 7 we study their effectiveness and
efficiency. In Chapter 8 section 8.2 we present an overall evaluation of these attack with respect to
each other.
8.4.1 Minimum Requirements
1. Implement the RSA algorithm.
2. Implement Integer factorisation attack (IFA).
3. Implement another attack which does not exploit the mathematical characteristics of the RSA
algorithm e.g. plaintext guessing
54

STATUS: ACHIEVED
We have successfully implemented the RSA algorithm. Chapter 4 gives the details of the implemen-
tation.
We have successfully implemented IFA. Chapter 5 describes the implementation and evaluation of
IFA. We have successfully implemented Guessing plaintext attack. Chapter 6 describes IFA and its
success implementation.
Therefore from the above we see that we have meet all the minimum requirements of the project.
8.4.2 Further Project Enhancements
1. Research on RSA digital signature
2. Implemented Guessing ϕ(N) attack
3. Researched on primality test algorithms and implemented Miller- Robin primality test and Fer-
mat primality test algorithms for generating any size of a prime numbers.
STATUS: ACHIEVED
We have achieved all the above further enhancements. In Chapter 3 we have presented RSA digital
signature. In fact due to time constraint but it was our wish to implement an attack on digital signature.
In chapter 7 we have successfully implemented guessing Guessing ϕ(N) attack. And finally, in chapter
3 we have discussed and implemented primality test algorithm.
8.5 Further Work
These are the potential ideas that would enhance the project.
1) Multi processor Integer factorisation attacks
It would be interest to compare integer factorisation that runs in a multi processor distributed system
environment
2)To improve the guessing ϕ(N) attacks by splitting the workload into threads running on different
processors.
3) Considering figure 8.1 and 8.3, it could be interesting to investigate the relationship between the
exponential growth and various processor speeds using experimental data.
55

Bibliography
[1] BEYERSDORFF, O. Algorithms Design. Lecture Notes, University of Leeds, 2013.
[2] BONEH, D., RIVEST, R., SHAMIR, A., AND ADLEMAN, L. Twenty years of attacks on the rsa
cryptosystem. Notices of the AMS 46, 2 (1999), 203–213.
[3] BOYKIN, P. O., AND ROYCHOWDHURY, V. Optimal encryption of quantum bits. Physical
review A 67, 4 (2003), 042317.
[4] DIFFIE, W., AND HELLMAN, M. New directions in cryptography. Information Theory, IEEE
Transactions on 22, 6 (1976), 644–654.
[5] ELGAMAL, T. A public key cryptosystem and a signature scheme based on discrete logarithms.
Information Theory, IEEE Transactions on 31, 4 (1985), 469–472.
[6] FERGUSON, N., AND SCHNEIER, B. Practical cryptography. Wiley, 10475 Crosspoint
Blvd.,Indianapolis, IN 46256, USA, 2003.
[7] FISHER, R. A. The sieve of eratosthenes. The Mathematical Gazette 14, 204 (1929), 564–566.
[8] GAINES, H. F. Cryptanalysis: a Study of Ciphers and their Solutions. Dover Publications, 180
Varick Street, New York, N.Y. 10014, 1956.
[9] GORDON, D. M. A survey of fast exponentiation methods. Journal of Algorithms 27 (1998),
129–146.
[10] HOUSTON, K. How to Think Like a Mathematician: A Companion to Undergraduate Mathe-
matics. Cambridge University Press, The Edinburgh Building, Cambridge CB2 8RU, UK, 2009.
[11] KALISKI, B., AND STADDON, J. Rsa cryptography specifications, 10 1998. RFC2437.
[12] KLEINJUNG, T., AOKI, K., FRANKE, J., LENSTRA, A. K., THOME, E., BOS, J. W., GAUDRY,
P., KRUPPA, A., MONTGOMERY, P. L., OSVIK, D. A., ET AL. Factorization of a 768-bit rsa
modulus. In Advances in Cryptology–CRYPTO 2010. Springer, 2010, pp. 333–350.
[13] KNUTH, D. E. The Art of Computer Programming, Volume1: Fundamental Algorithms, sec-
ond ed. Addison-Wesley, Massachusetts, USA, 1973.
56

[14] LEISERSON, C. E., RIVEST, R. L., STEIN, C., AND CORMEN, T. H. Introduction to algo-
rithms. The MIT press, 2001.
[15] LENSTRA, A. K. Integer factoring. In Towards a quarter-century of public key cryptography.
Springer, 2000, pp. 31–58.
[16] LENSTRA JR, H. W. Factoring integers with elliptic curves. Annals of mathematics (1987),
649–673.
[17] LINDQVIST, U., AND JONSSON, E. A map of security risks associated with using cots. Com-
puter 31, 6 (1998), 60–66.
[18] MATLAB. version 7.10.0 (R2010a). The MathWorks Inc., Natick, Massachusetts, 2010.
[19] RIVEST, R. L., SHAMIR, A., AND ADLEMAN, L. A method for obtaining digital signatures
and public-key cryptosystems. Communications of the ACM 21, 2 (1978), 120–126.
[20] SCHWABER, K. Scrum development process. In Business Object Design and Implementation.
Springer, 1997, pp. 117–134.
[21] SKIENA, S. S. The Algorithm Design Manual, second ed. Springer, 2008.
[22] STINSON, D. R. Cryptography Theory and Practice, third ed. Chapman Hall/CRC, 2006.
[23] STROUSTRUP, B. The C++ Programming Language, 3rd ed. Addison-Wesley Longman Pub-
lishing Co., Inc., Boston, MA, USA, 2000.
[24] TESKE, E. Speeding up Pollard’s rho method for computing discrete logarithms. Springer,
1998.
[25] THE GNU MULTIPLE PRECISION ARITHMETIC LIBRARY. GMP, version 5.4.2, 2013. avail-
able from http://gmplib.org/.
[26] THE PARI GROUP. PARI/GP, version 2.5.4. Bordeaux, 2013. available from http://pari.
math.u-bordeaux.fr/.
[27] VANDERSYPEN, L. M., STEFFEN, M., BREYTA, G., YANNONI, C. S., SHERWOOD, M. H.,
AND CHUANG, I. L. Experimental realization of shor’s quantum factoring algorithm using
nuclear magnetic resonance. Nature 414, 6866 (2001), 883–887.
[28] VERNAM, G. S. Cipher printing telegraph systems for secret wire and radio telegraphic commu-
nications. American Institute of Electrical Engineers, Transactions of the 45 (1926), 295–301.
[29] YAN, S. Cryptanalytic Attacks on RSA. Springer Science+Business Media, LLC, 233 Spring
Street, New York, NY 10013, USA, 2008.
57

[30] YAO, A. C. Theory and application of trapdoor functions. In Foundations of Computer Science,
1982. SFCS’08. 23rd Annual Symposium on (1982), IEEE, pp. 80–91.
[31] ZAGIER, D. The first 50 million prime numbers. The Mathematical Intelligencer 1 (1977),
7–19.
58

Appendix A
Personal Reflection
I think my project went on well even though I believe upon reflection that there are other things I
would have done better.
My reflection on this project is advice aimed at two categories of students. The first category is for
students in general, while the second category is of students that are pursuing a project similar to
mine. When I say a project similar to mine, I mean a project that requires a lot of programming in low
level language such as C++ and understanding of various algorithms.
REFLECTION FOCUSED TO THE STUDENTS IN GENERAL
When you come to study to an MSc program, you are already aware that as part of your MSc re-
quirement, you are supposed to undertake an MSc project. I remember, during our induction period
in the first, we were advised to start thinking early about our potential projects. Upon reflection, I
think if I had started planning my project as early as then, - just thinking in terms of the general areas
and the specific project I was interested in pursuing, or even consulting with the various lecturers and
professor, I would have utilized this project period much more better.
For instance, this project I pursued, I selected it from the MSc project list website. However, I think
that if I had earlier introduced myself to such an interesting area of computing through personal re-
search, I should have enjoyed the project more.
Furthermore, when you are doing your project, remember that you have a limited time. Therefore,
59

use your time effectively . When you are start working on your project, usually, at least in my case,
it seemed to me that 3 months was a lot of time. However, before you know it, you realize that
time is gone. Therefore, I would strongly advise that when you develop a schedule, you need to
try your best to to have the discipline to follow it. Also, remember to include enough contingency
plans since at some point, things are likely to go wrong in your project. For instance, in my case, I
spent about two weeks learning how to generate prime numbers as this was a completely new area to
me. And after implementing the prime number generating algorithm and generating primes. It took
about a week generate the prime numbers. However, upon using these prime numbers, I discovered
that the prime numbers used were too small in magnitude for my evaluation and that the algorithm
I used for generating primes was too slow. This meant that I had lost almost three weeks in my project.
On project write up, my advice is to start writing up as soon as possible. If you do plan to using
writing systems such as latex, I would recommend you do yourself a favor by using starting to use it
for other things such as writing Coursework.
REFLECTION FOCUSED TO THE STUDENTS DOING A PROJECT SIMILAR TO MINE
When you are working on a project like this one and you are using a low level language such a C++
and having to use external libraries, the chances that you will encounter issues that require an hour or
a day to fix, are extremely high. Therefore, when you meet a problem, it is better to check the forums
to see how others have fixed the issue. You might be keen on trying to figure it out on your own, that
is a good spirit it but it might cost you a lot of time. And the chances are that someone has already
worked out that solution, thus you need not to reinvent the wheel.
60

Appendix B
INTERIM REPORT
The following is the scanned copy of the Interim report of this project.
61

Appendix C
SAMPLE LIST OF PRIME NUMBERSGENERATED
62

prime number bit size
40077762712136337562434668539 96
101118533315874229869868194511 97
163218875836330030357164130979 98
317680799743506825233210052721 99
1002303185350557477458075237273 100
1352157481803950134705707130577 101
2689367285293152955344125877641 102
5394539498984229225519412675837 103
10508662514426939370420307932763 104
22725731577390302130566244640207 105
42411454038379358064633266776037 106
104897141259992423719523409386143 107
162550144317302532483250517285959 108
335176444940220272604880412250511 109
1067803375372609461108981758367323 110
1303841107305700891355763678131519 111
2662408284569009343753531755262193 112
10108621432540043054685477844006957 113
10718496942997584837810871243245491 114
21542275100620004140420677611267881 115
45831086284506641551136994822246641 116
105453620806463126518662729362106883 117
168586692559299486068737421968503437 118
335811318957351894961188689342924921 119
1012203142506900281933140472594741101 120
1476681869703431109180125690137107343 121
2764554378741345153462293492642522873 122
10103080073506177693183919284479764651 123
10662625990346458651607518798111386647 124
22314596644286846478170872312965616861 125
44164036538386113350811071772811043623 126
103301237149327264313236328542283085799 127
172059202025592718945131224501572328807 128
63


![Note sul territorio di Castiglion Fiorentino [RSA 1994-1]](https://static.fdokumen.com/doc/165x107/6318fa62e9c87e0c090fe96c/note-sul-territorio-di-castiglion-fiorentino-rsa-1994-1.jpg)

















