
CONFERENCE Program
38
CONFERENCE Program Aug. 13-15, 2021 Online FAIML 2021 2021 International Conference on Frontiers of Artificial Intelligence and Machine Learning ECNLPIR 2021 2021 European Conference on Natural Language Processing and Information Retrieval
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of CONFERENCE Program

CONFERENCEProgramAug. 13-15, 2021Online
FAIML 20212021 International Conference onFrontiers of Artificial Intelligence andMachine Learning
ECNLPIR 20212021 European Conference onNatural Language Processing andInformation Retrieval

1
WelcomeDear Distinguished Participants,
Welcome to 2021 International Conference on Frontiers of Artificial Intelligence and Machine Learning(FAIML 2021) and 2021 European Conference on Natural Language Processing and Information Retrieval(ECNLPIR 2021).
Currently, the novel coronavirus COVID-19 is widely spreading in the world. Every countries are nowsparing no efforts to fight against the novel coronavirus pandemic and its impact. And we are definitelyconvinced that under the worldwide people's concerted efforts, the current serious situation will be relievedin the near future! After careful consideration and painstaking preparation, we would like to declare that theAugust conferences will be held online during Aug. 13-15, 2021.
First of all, we'd like to express our sincere gratitude for your participation, which is the vital note to makethe conference a great forum for the collision and fusion of ideas and knowledge. Besides, we'd like toexpress our sincere gratitude to our conference chair Dr. Issa Atoum who offered his kind help and greatefforts to us. Meanwhile, we'd like to say thanks to our keynote speakers Prof. Dr. Ajith Abraham, Prof. Dr.Henning Müller and invited speakers Prof. Jean Charles Lamirel, Prof.Rita Yi Man Li who will share theirnewest and outstanding research achievements in this online conference.
The aim as well as the objective of FAIML 2021 & ECNLPIR 2021 is to present the latest research andresults of Artificial Intelligence and Machine Learning, Natural Language Processing and InformationRetrieval. By providing opportunities for the delegates to exchange new ideas face-to-face, to establishbusiness or research relations as well as to find global partners for future collaborations, we do hope thatthe conference will intensify mutual improvement and facilitate academic exchange, as a result that leadingto significant contributions to the knowledge in these up-to-date scientific fields.
At the same time, we wish you enjoy a very splendid time in this online conference!
Thank you!
FAIML & ECNLPIR 2021 Committee

2
General Information
Time ScheduleAll time arrangement mentioned in this program are based on Greenwich Mean Time (GMT),GMT + 2
RemarksThe online conference is open to participants only. For more detailed information, please kindlyrefer to the guideline for online conference.
A Polite Request to All ParticipantsParticipants are requested to join this online conference in a timely fashion. Presenters arereminded that the time slots should be divided fairly and equally by the number of presentations,and that they should not overrun. The session chairs is asked to assume this timekeeping role andto summarize key issues in each topic.
Dress Code:Formal or national custom
Certificate
Certificate of AttendanceA certificate of presentation indicates a presenter's name, affiliation and the paper title that ispresented in the scheduled session, certifying the paper has been presented in this onlineconference.
Certificate of Best Presentation & Best Student PaperPresenters who presents a great oral presentation will be awarded as the Best Presentation andthe Best Student Paper. The session chair will announce a best awards in the award ceremony onAug. 14th , 2021.
Certificate DistributionAll presenters will receive the certificate (soft copy) of participation from conference committeethrough conference email, and the award winner's certificates (soft copy) will also be sent byconference committee through conference email.
Preparation for Oral PresentationsYou are expected to prepare your file in PowerPoint or PDF in advance. We recommend you tobring two copies of the file in case that one fails. You can share content during the online meeting.In the Participants panel, grab the ball and drop it next to your name. You become thepresenter. Select Share content and start sharing.
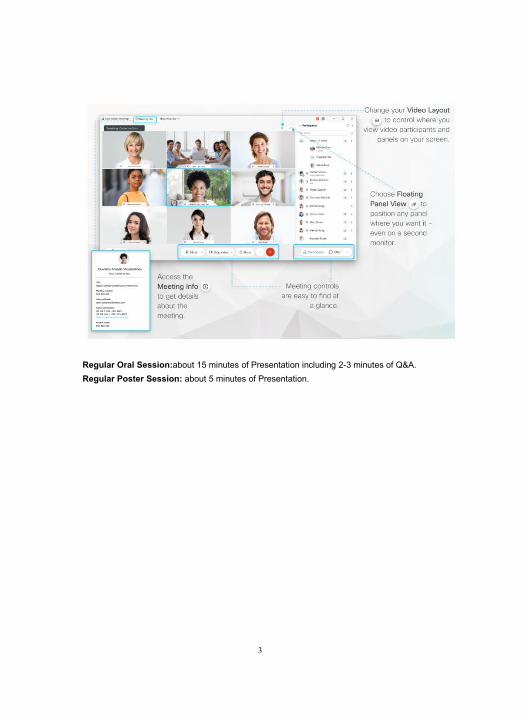
3
Regular Oral Session:about 15 minutes of Presentation including 2-3 minutes of Q&A.Regular Poster Session: about 5 minutes of Presentation.

4
Program (GMT + 2)
Day 1-Conference Program
Aug. 13, 2021---Friday
08:00-11:00 Technical Test16:00-18:00 Technical Test
Day 2-Conference Program
Aug. 14, 2021---Saturday
0900-0915 Opening Ceremony0915-0945 Invited Speech-Prof.Jean Charles Lamirel0945-1015 Invited Speech-Prof.Rita Yi Man Li1015-1200 Oral Session
IM1003---Sota TakagiIM1006---Song YuIM004---Thye Lye, Tan (Kelvin)EC1001---Rajeswaran ViswanathanIM1007---Geng ChenIM009---CHARLIE S. MARZANEC001---Marko Sahan (Student)
1200-1300 Break & Free Discussion1300-1345 Keynote Speech-Prof. Dr.Ajith Abraham1345-1545 Oral Session
IM2001-Dr. Vinod Kumar VermaEC004---Àlex BravoEC012---Óscar Barba Seara (Student)EC008---Ethan Cumberland and Tony DayIM1010---Fatima zohra Trabelsi (Student)IM006---René Arendt SørensenIM008---Teresa Paula Azevedo PerdicoúlisIM1009---Enes Uğuroğlu
1545-1600 Award Ceremony & Closing Ceremony

5
Day 3-Conference Program
Aug. 15, 2021---Sunday
0830-0845 Opening Ceremony0845-0930 Keynote Speech-Prof. Dr. Henning Müller0930-1000 Oral Session
W005-Takeshi Masumoto&Prof. Hiroshi KoideW001-Alexander Antonov(Student)
1000-1045 Keynote Speech-Prof. Steven Furnell1045-1115 Break & Free Discussion1115-1215 Oral Session
W009-Carmelo Ferrante
W1005-Assoc. Prof. Fabrizio d’ AmoreW012-Anusha VajhaW1001-Surafel Mehari
1215-1400 Break & Free Discussion1400-1445 Keynote Speech-Prof. Amir Herzberg1445-1530 Oral Presentation
NIS1001-Dr. Peter HillmannNIS1002-Prof. Carlos Manuel Moreno NegrinW011-Mohammed AAlsuwaie
1530-1600 Break & Free Discussion
1600-1645 Keynote Speech-Prof. Ramjee Prasad1645-1745 Oral Presentation
NIS1005-Kevin De Boeck(Student)NIS002-Ondřej Pospíšil
W007-Maryam Ramezanzadehmoghadam(Student)W010-Kavitha Venkatesh
1745-1800 Award & Closing Ceremony

6
Invited Session
Invited Speech-1
09:15-09:45 Saturday, Aug. 14th 2021 (GMT + 2)
Title: Feature maximization: a new generic approach with strongexplanatory capabilities for processing complex, multidimensional,multiview and dynamic textual data
Prof.Jean Charles LamirelEquipe Synalp, LORIAVandœuvre-lès-Nancy, FranceUniversité de StrasbourgWISELAB, Dalian University, China
AbstractWith the continuous growth of digital information of multiple natures available online, one of themajor challenges in information analysis is to exploit data analysis tools with high explanatorypower, capable of adapting to large volumes of heterogeneous, changing and often distributed datawith multiple views. In this talk, we thus propose to present new statistical methods that initially fitinto the context of textual data processing, but that can also extend their scope to the context of allstatic and dynamic numerical data.
The most commonly used measures in textual analysis are distributional measures, mainly basedon entropy or Chi-square metrics, or vector measures, such as Euclidean distances or correlationdistances. We have shown in different contexts, such as in the QUAERO project, that theseapproaches have strong limitations in the case of processing very unbalanced data and in the caseof processing very heterogeneous and multidimensional data, as it is very often the case with realtextual data. On the other hand, more complex methods, such as kernel-based methods and deeplearning-based methods work like black boxes, while not necessarily being more efficient for textualanalysis itself.
We have recently proposed an alternative metric based on feature maximization that does not havethese drawbacks. The principle of this metric is to define a trade-off measure between generalityand discrimination based on both the features extracted from the data specific to each group of apartition and those shared between the groups. One of the main advantages of this method is that itis operational on unsupervised approaches as well as on traditional categorization approaches.Moreover, it also presents, by its very principle, very strong explanatory capacities associated withlatent capacities of noise and complexity reduction by operating feature selection. Finally, thismethod has the decisive advantage of being parameter- free.
We were able to show that feature maximization can deal very efficiently with very complexproblems related to the unsupervised analysis of large volumes of textual and linguistic data, suchas the tracking of topics in data evolving over time, while adapting to traditional discriminantanalysis, widely exploited in linguistics, or to text categorization, with performances far superior toclassical methods.

7
In this talk, we will present the general principles of feature maximization and the associatedgraphical methods such as contrast graphs. We will show the additional advantages of itsintegration into a powerful and flexible multi-view analysis paradigm based on unsupervisedBayesian reasoning. To illustrate the overall functioning of the method, we will review one of itsrecent successful applications for the analysis of 40 years of science research in China andcompare its performance to that of LDA.
We will finally present the current perspectives of feature maximization through its adaptation tocommunity role detection in graphs. In particular, we will show that it is possible to exploit this newadaptation to build explanatory (and sparse) word embeddings using word communities extractedfrom co-occurrence graphs as embedding support. This will allow us to compare favorably theresults obtained, both in terms of explanatory and sparse performance, to those of usualembedding methods, such as Word2Vec, GloVe or SVD2vec.
Introduction to Prof.Jean Charles Lamirel
Invited Speech-2
09:45-10:15 Saturday, Aug. 14th 2021 (GMT + 2)
Title: Studying construction hazard awareness via artificialintelligence eye tracking: a tale of three groups of engineers
Prof. Rita Yi Man LiHong Kong Shue Yan University, Hong Kong
AbstractThe construction is a high-risk industry. The ability of construction workers to recognize hazardsand the speed of response affects the likelihood of accidents happens on sites or level of severity ofconstruction events. Eye tracking is a measure of people's situational awareness in response toenvironments. Although prior research attempted to do experiments by using eye trackingtechnology to analyze the hazard recognition ability and visual attention of tower crane operators,design and cost engineers construction industry practitioners, there are few studies using artificialintelligence eye tracking. There are even fewer eye tracking experiment for workers on constructionsite. This research attempts to analyze the online eye tracking data of three groups ofconstruction-related practitioners, including data such as heat map image, visual distribution,mouse clicks, opacity image, and facial expression changes. The analysis results show that visualdistribution and emotional changes of different construction workers are significantly different.Tower crane operators or conductor have a wider focus, and their emotional distribution issignificantly different from that of indoor and cost engineers, and is also significantly different fromgreen leaf engineers or site supervisors.
Introduction to Prof.Rita Yi Man Li

8
Oral Session
Saturday, Aug. 14th 2021 10:15-12: 00 ( GMT + 2) Webex
IM1003Sota Takagi
Tokyo Institute ofTechnology, Japan
15 min
Designing an Abnormal Posture Warning System using a PoseEstimation Model for Meal Assistance for Older AdultsSota Takagi, Honoka Hayashi, Yoji Morishita, Kohei Hamaya, TakumiOhashi and Miki Saijo
Background: The application of machine learning techniques to assistivetechnologies for older adults has attracted significant attention to resolve theserious shortage of manpower in care facilities. Many scholars haveproposed realtime posture estimation models with simple neural networkclassifiers for fall detection and have achieved high accuracy[1]. In the context of elderly care, pulmonary aspiration due to inability tomaintain posture during meals is a major problem. However, there is nodefinition of the threshold of abnormal posture or who needs to be notified ofthe detected posture in order to avoid serious accidents. Goal: We aimed toestablish a warning system that detects older adults’ abnormal postureduring meals and provides real-time feedback properly to the people aroundthem to avoid serious accidents in advance. To this end, we built aprototype system which detects the angle of posture and defined athreshold of abnormal posture angle during meals.Method: To build the warning system, we used RaspberryPi and PoseNet[2]. PoseNet is an ideal pose estimation model for the system as it does notrequire a GPU and runs fast even on edge devices. In addition to chin-tuck,which is closely related to swallowing [3], the warning system detects thepostures of leaning forward and to the left/right, as these are common inolder adults who are unable to maintain their posture. Abnormal posture isdetected by calculating the magnitude of the outer product for chin-tuck, thevector magnitude for forward-leaning posture, and the tilt from the verticalposture for left/right-leaning posture. The system notifies the subject andnearby people by voice, and the caregiver by text message/detected image.Caregivers can determine whether the subject needs assistance even iffalse detection occurs due to the surrounding situation (e.g., light, color ofperson’s clothing). We also conducted swallowing tests with 10 healthyadults (2 females, 8 males, age: 22.9± 1.9) to define abnormal posturewhile eating. The subjects were required to take four postures: forward-,left-, and right-leaning, and chin-tuck. The subjects sat in a chair, tiltedtheir posture in 10° increments, and ate jelly for people with swallowingdifficulties. The angle of difficulty in swallowing was evaluated by a 5-pointLikert scale (1: no problem; 2: slightly awkward; 3: awkward; 4: difficulty in

9
swallowing; 5: unable to swallow). Abnormal posture was defined as anyangle that scored 4 or more in the evaluation.Results: As a result of the swallowing tests, the threshold angles weredetermined as follows: forward-leaning of 48±8.7° , left-leaning of 48±4.0° , right-leaning of 47± 4.6° , and chin-tuck of 37.5± 4.3° . Therecorded videos of the experiment verified the functionality of our prototype.When postures were abnormal, the notification system was activatedcorrectly in 60% of forward-leaning, 50% of left-leaning, 60% ofright-leaning, and 70% of chin-tuck cases. It was found that our system maynot detect correctly due to the surrounding situation including colors of thesubject’s clothing and people/objects other than the subject.Conclusion: Our preliminary study successfully defined the angle ofabnormal posture during meals and demonstrated the notification functionof the system when it detected such postures. Future work shouldinvestigate abnormal postures for older adults as well as estimation modelsand algorithms that are resistant to noise from the external environment.Also, through iteratively conducting user tests in actual settings andre-examining the detection and warning system, we expect to build asystem that better meets the needs of care facilities.
IM1006Song Yu
Hitachi, Japan15min
Practical research on prediction accuracy improvement of DiseaseMigration Model based on GA_XGBoost_RF algorithmSong Yu and Matsumori Masaki
With the advent of the era of big data, machine learning theory is more andmore widely used in disease prediction. At the same time, the use ofdisease migration model (See Chapter 2 for details) to predict the chronicdisease prevalence rates and medical expenses of patients has beenrecognized in the industry. In this paper, on the basis of disease migrationmodel, In order to improve the prediction accuracy of the model. GAalgorithm is used to optimize the super parameters and prediction weightsof XGBoost and RF, and to construct GA_XGBoost_RF prediction model.Through experiments, the average prediction accuracy is 99.74% and theprediction variance is 1.7% on 1 million data sets, which is an extremelyeffective prediction method
IM004
Electromechanical Platform with removable overlay for exploring,tuning and evaluating search, machine learning and feedback controlalgorithmsThye Lye, Tan (Kelvin)Presented a physical electromechanical movable maze platform forevaluating reinforcement learning (RL) algorithms. The use of embeddedhall sensors in the platform for detecting the spherical magnetic ball

10
Thye Lye, Tan(Kelvin)
Effectual Devices15min
provides benefits over top mounted camera systems. The process ofadapting RL algorithms like Q-table, SARSA and Neural Network to functionwith the platform was discussed. A comparative evaluation of theperformance against baseline was presented. The electromechanicalplatform provides unique features, benefits, and challenges. The platformserves as a tool in RL algorithm tuning and validation. The platform alsoserves as a pedagogical tool, especially in providing learners a means tovisualize the RL algorithms in action.
EC1001RajeswaranViswanathan
Capgemini, India15min
Transformer models – Agree to disagreeRajeswaran Viswanathan and Sathya Priya. S
Word embeddings in different pre-trained transformer models are differentdue to the way they are trained and the input data used. Using unstructuredmedical data, the quality of embeddings for 12 different transformer modelsis analyzed by comparing it with two classic Bidirectional EncoderRepresentations from Transformers (BERT) models - bert.base.uncasedand bert.large.uncased. Meta-analysis was done to study the output.Analysis shows there is significant heterogeneity in the performance of themodels making automation tasks difficult. The observation is discussed withimplications of the downstream Natural Language Processing (NLP) taskslike search indexing and similarity identification.
IM1007Geng ChenHuazhongUniversity ofScience and
Technology, China15 min
New positional accuracy calibration method for an autonomous roboticinspection systemGeng Chen,Jianzhong Yang ,Hua Xiang
The existing automatic inspection system employed for the qualityassessment in the manufacturing of automotive parts, comprising industrialrobots and sensors, has a low absolute positioning accuracy. Therefore, anew method based on an optimally-pruned extreme learning machinealgorithm is proposed to compensate for the absolute positional errors. Thisalgorithm is applied to the positional error compensation of a robotend-effector by mapping the robot target position to the computed position.We selected sampling points in the robot motion space to establish an errorprediction model and used the trained model to predict the error at the testpoints. Experiments were carried out to verify the effectiveness of theproposed method in measuring the robot positional errors in the x, y, and zaxes and the total absolute accuracy. The maximum absolute positional errorreduced by 78.31% from 1.472 mm to 0.319 mm, and the average positionalerror reduced by 85.4% from 1.235 mm to 0.191 mm. A robot was made tomove along a predetermined trajectory at different speeds with improvedpositioning accuracy. A comparison experiment was performed to validate

11
the accuracy and superiority of the method. The experimental results showedthat the proposed method could significantly improve the positional accuracyof the robotic inspection system and that the method represents an effectiveand convenient technique for robot calibration in workshops.
IM009CHARLIE S.MARZAN
DON MARIANOMARCOSMEMORIALSTATE
UNIVERSITY15 min
Sign to Speech Convolutional Neural Network-Based Filipino SignLanguage Hand Gesture Recognition SystemMark Benedict D. Jarabese, Charlie S. Marzan, Jenelyn Q. Boado,Rushaine Rica Mae F. Lopez, Lady Grace B. Ofiana, Kenneth John P.Pilarca
Sign Language Recognition is a breakthrough for helping deaf-mute peopleand has been studied for many years. Unfortunately, every research has itsown limitation and are still unable to be used commercially. In this study, wedeveloped a real-time Filipino sign language hand gesture recognitionsystem based on Convolutional Neural Network. A manually gathereddataset consists of 237 video clips with 20 different gestures. This datasetunderwent data cleaning and augmentation using image pre-processingtechniques. The Inflated 3D convolutional neural network was used to trainthe Filipino sign language recognition model. The experiments consideredretraining the pretrained model with top layers and all layers. As a result, themodel retrained with all layers using imbalanced dataset was shown to bemore effective and achieving accuracy up to 95% over the model retrainedwith top layers to classify different signs or hand gestures. Using the RapidApplication Development model, the Filipino sign language recognitionapplication was developed and assessed its usability by the target users.With different parameters used in the evaluation, the application found to beeffective and efficient.
Active Learning For Text Classification and Fake News DetectionMarko Sahan, Václav Šmidl and Radek Mařik

12
EC001Marko Sahan(Student)
Dept. of ComputerScience, FEE, CTU
in Prague15 min
Supervised classification of texts relies on the availability of reliable classlabels for the training data. However, the process of collecting data labelscan be complex and costly. A standard procedure is to add labelssequentially by querying an annotator until reaching satisfactoryperformance. Active learning is a process of selecting unlabeled datarecords for which the knowledge of the label would bring the highestdiscriminability of the dataset. In this paper, we provide a comparative studyof various active learning strategies for different embeddings of the text onvarious datasets. We focus on Bayesian active learning methods that areused due to their ability to represent the uncertainty of the classificationprocedure. We compare three types of uncertainty representation: i) SGLD,ii) Dropout, and iii) deep ensembles. The latter two methods in cold- andwarm-start versions. The texts were embedded using Fast Text, LASER, andRoBERTa encoding techniques. The methods are tested on two types ofdatasets, text categorization (Kaggle News Category and TwitterSentiment140 dataset) and fake news detection (Kaggle Fake News andFake News Detection datasets). We show that the conventional dropoutMonte Carlo approach provides good results for the majority of the tasks.The ensemble methods provide more accurate representation of uncertaintythat allows to keep the pace of learning of a complicated problem for thegrowing number of requests, outperforming the dropout in the long run.However, for the majority of the datasets the active strategy using DropoutMC and Deep Ensembles achieved almost perfect performance even for avery low number of requests. The best results were obtained for the mostrecent embeddings RoBERTa
Break & Free Discussion
Saturday, Aug. 14th 2021 12:00-13:00 (GMT +2)

13
Keynote Session
Keynote Speech
13:00-13:45 Saturday, Aug. 14th 2021 (GMT + 2)
Title:
Prof. Dr. Ajith AbrahamEditor-in-Chief: Engineering Applications of Artificial Intelligence,ElsevierDirector - Machine Intelligence Research Labs (MIR Labs)Scientific Network for Innovation and Research Excellence, USA
Abstract
Introduction to Prof. Dr. Ajith Abraha
Dr. Abraham is the Director of Machine Intelligence Research Labs (MIR Labs), a Not-for-ProfitScientific Network for Innovation and Research Excellence connecting Industry and Academia. TheNetwork with HQ in Seattle, USA has currently more than 1,000 scientific members from over 100countries. As an Investigator / Co-Investigator, he has won research grants worth over 100+ MillionUS$ from Australia, USA, EU, Italy, Czech Republic, France, Malaysia and China. Dr. Abrahamworks in a multi-disciplinary environment involving machine intelligence, cyber-physical systems,Internet of things, network security, sensor networks, Web intelligence, Web services, data miningand applied to various real-world problems. In these areas he has authored / coauthored more than1,400+ research publications out of which there are 100+ books covering various aspects ofComputer Science. One of his books was translated to Japanese and few other articles weretranslated to Russian and Chinese. About 1,100+ publications are indexed by Scopus and over900+ are indexed by Thomson ISI Web of Science. Some of the articles are available in theScienceDirect Top 25 hottest articles. He has 1,100+ co-authors originating from 40+ countries. Dr.Abraham has more than 39,000+ academic citations (h-index of 95 as per google scholar). He hasgiven more than 100 plenary lectures and conference tutorials (in 20+ countries). For his research,he has won seven best paper awards at prestigious International conferences held in Belgium,Canada Bahrain, Czech Republic, China and India. Since 2008, Dr. Abraham is the Chair of IEEESystems Man and Cybernetics Society Technical Committee on Soft Computing (which has over200+ members) and served as a Distinguished Lecturer of IEEE Computer Society representingEurope (2011-2013). Currently Dr. Abraham is the editor-in-chief of Engineering Applications ofArtificial Intelligence (EAAI) and serves/served the editorial board of over 15 International Journalsindexed by Thomson ISI. He is actively involved in the organization of several academicconferences, and some of them are now annual events. Dr. Abraham received Ph.D. degree inComputer Science from Monash University, Melbourne, Australia (2001) and a Master of ScienceDegree from Nanyang Technological University, Singapore (1998).

14
Oral Session
Saturday, Aug. 14th 2021 13:45-15:45 (GMT+2) Webex
IM2001Dr. Vinod Kumar
VermaSant LongowalInstitute of
Engineering &Technology, India
15 min
Information Technology Advancements and Breakthrough in GlobalPandemic: COVID-19Dr. Vinod Kumar VermaTechnology based solutions to deal with the current state of affairs likeglobal pandemic: COVID-19, healthcare etc. are on the verge of researchnowadays. The foremost solutions to these areas of concern focus oninformation technology. Internet of things enabled applications allow theresearchers to cope with the current situations of healthcare and neurologyto a significant level. This results in the ease of doctors and scientists totreat the patients from the associated disease towards a more rigorousevaluation and assessment. Moreover, the treatments become easier andeliminate the load of adequate assessment of patients from the doctors.Eventually, results in the performance enhancement of the existingapplications. There is always a need to think in the direction of technologycompliant products and solutions for healthcare relateddomains including neurology. Recommendations have been suggestedto incorporate more technology based applications and products using theInternet of things.
EC004Àlex Bravo
Amaris Consulting,Spain15min
Accelerating the early identification of relevant studies in citationscreeningÀlex Bravo; Liga Bannetts and Petar AtanasovIn a systematic literature review (SLR), a large set of citations retrievedfrom multiple bibliographic databases must be screened to identify thoseeligible according to pre-specified criteria. Initially, records are screened forpotential eligibility by appraising titles and abstracts (TAs), which is atedious and time-consuming step. In a subsequent step, citations labelledas potentially relevant are thoroughly screened based on examination ofthe full texts (FT).In this study, we apply Natural Language Processing(NLP) and Machine Learning (ML) techniques to develop an automaticcitation prioritization system to assist the screening process and toaccelerate further steps of a SLR. First, we represent titles and abstractsusing bag-of-words (BoW) and TFIDF (term frequencyinverse documentfrequency) with a dimensional reduction. Then, we apply traditional MLalgorithms (such as Support Vector Machine, Stochastic Gradient Descentand Logistic Regression) to explore their performance in ranking therelevance of the remaining citations. Furthermore, the research sheds lighton the impact of class imbalance in SLR datasets on the performance of

15
each ML algorithm. In this context, oversampling techniques are explored toalleviate this inconvenience.In the evaluation, we use two SLRs carried out in our group (Dataset 1 andDataset 2) and analyze how our approach accelerates the earlyidentification of relevant citations by means of two figures of merit: the WorkSaved over Sampling (WSS) and the Relevant References Found (RRF).For Dataset 1, at only 10% of citations screened (RRF@10), the systemhad already identified 35% and 55% of all relevant citations in TA and FTscreenings, respectively. Also, 95% of relevant citations (WSS@95) werefound at 49% (in TA) and 37% (in TF) screened. For Dataset 2, at only 10%screening, the system found 35% (in TA screening) and 47% (in FTscreening) of relevant citations. Considering the initial randomly selectedsamples for training, the system significantly accelerates the earlyidentification of relevant citations . Despite a certain degree of noise andsimilar behavior at first, oversampling techniques may improveperformance in the final phase of the screening and avoid learningproblems caused by a small dataset or/and the imbalance class problem.Finally, our system is compared to a recent evaluation of two popularcitation screening systems (Abstrackr and EPPI-Reviewer), achieving acomparable performance.
EC012Óscar Barba Seara
(Student)University of Vigo,
NIU15min
Demographic market segmentation on short banking movementdeions applying Natural Language ProcessingSilvia García-Méndez, Francisco de Arriba-Pérez, Óscar Barba-Seara,Milagros Fernández-Gavilanes and Francisco Javier González-Castaño
Banking movement descriptions can be a valuable type of short texts forknowledge extraction with application in finance and social studies.Conventional research on text mining has mostly been applied tomedium-sized documents. Knowledge extraction from banking movementdescriptions is challenging due to the lack of meaningful textual data andtheir ad-hoc terminology. In this work we present a clustering analysis onshort banking movement descriptions based on Natural LanguageProcessing techniques. We exploit the knowledge in an experimental dataset composed of almost 20,000 real banking transactions that have beenanonymised as required by European data protection regulations. At theend, we were able to extract five distinctive user clusters with similardemographics. Our approach has potential applications in PersonalFinance Management.

16
EC008Ethan CumberlandCENTRIC, SheffieldHallam University
Tony DayCENTRIC, SheffieldHallam University
15 min
A Prescriptive Approach For Structured Information ExtractionFrom Web Forums And Social MediaEthan Cumberland and Tony Day
Banking movement descriptions can be a valuable type of short texts forknowledge extraction with application in finance and social studies.Conventional research on text mining has mostly been applied tomedium-sized documents. Knowledge extraction from banking movementdescriptions is challenging due to the lack of meaningful textual data andtheir ad-hoc terminology. In this work we present a clustering analysis onshort banking movement descriptions based on Natural LanguageProcessing techniques. We exploit the knowledge in an experimental dataset composed of almost 20,000 real banking transactions that have beenanonymised as required by European data protection regulations. At theend, we were able to extract five distinctive user clusters with similardemographics. Our approach has potential applications in PersonalFinance Management.
IM1010Fatima zohraTrabelsi(Student)
IMS Team, ADMIRLaboratory, RabatIT Center, ENSIAS,
Mohamed VUniversity15min
TOWARDS AN APPROACH OF RECOMMENDATION IN BUSINESSPROCESSES USING DECISION TREESTRABELSI Fatima zohra, KHTIRA Amal, EL ASRI Bouchra
A recommender system analyses users’ data in order to extract theirinterests and preferences and suggest them relevant items. Therecommendation systems have shown their applicability in many domains,especially in business processes (BP). Business processes are defined asa set of tasks that are performed by an organization to achieve a businessgoal. Using recommendation techniques in business processes consists ofproposing relevant tasks at a certain point, which helps managers makingthe right decisions. In this paper, we propose an approach ofrecommending in BPMN-based business processes. The recommendationtechnique that we considered in this approach is the decision trees.
Baggage Routing with Scheduled Departures using DeepReinforcement LearningRené Arendt Sørensen, Jens Rosenberg and Henrik KarstoftAs the number of travelers in airports increase, the load on the BaggageHandling Systems naturally gets higher. To accommodate this, airports caneither expand or optimize their Baggage Handling System. Therefore,

17
IM006René ArendtSørensen
Department ofElectrical andComputer
Engineering,Aarhus University
15min
capacity is a common parameter to evaluate Baggage Handling Systemson, and methods which can increase the capacity are highly valued withinthe airport industry. Previous work has shown that Deep ReinforcementLearning methods can be applied to increase the system capacity when ahigh load is constantly applied. It is, however, still not clear, how well suchDeep Reinforcement Learning agents perform, when the load of the systemcan change according to distributed flight schedules and realisticdistributions of incoming baggage. In this work, we apply DeepReinforcement Learning to a simulated Baggage Handling System withflight schedules and a distribution of incoming baggage generalized fromdata from a real airport. As opposed to previous work, we allow emptybaggage totes to be stored at the entry point until new baggage arrives. Thecentralized Deep Reinforcement Learning agent must learn to balance thenumber of baggage totes in the entry queue, while also learning optimalrouting strategies, ensuring that all bags meets their scheduled departuretimes. The performance is measured by the average number of deliveredbags and the average number of rush bags occurred in the exampleenvironment. We find that by using Deep Reinforcement Learning in thistype of congested system with scheduled departures, we can reduce thenumber of rush bags, compared to a dynamic shortest path method withdeadlock avoidance, resulting in a higher number of delivered bags in thesystem.
IM008Teresa PaulaAzevedo
PerdicoúlisUTAD &
ISR-Coimbra15min
Dark-matter Search OptimiserPaulo Alexandre Salgado & T-P Azevedo Perdicoúlis
A version of the Gravitational Search Algorithm that takes advantage of therepulsive forces of dark matter to explore the space is presented in thisarticle. The classification of matter into dark and gravitational particles isused to balance between exploration and exploitation of the feasible set ofsolutions, respectively. The idea is to overcome some problems of theGravitational Search Algorithm as the trapping into local optima and thechoice of parameters. We use three different problems to demonstrate thepotential of the algorithm when compared with the Particle SwarmOptimiser. In the future, we plan to do a thorough assessment of thealgorithm on benchmark problems as well as on some applications.

18
IM1009Enes UğuroğluIstanbul TechnicalUniversity, 34467Istanbul, Turkey
15min
Near-Real time quality prediction in a plastic injection moldingprocess using Apache SparkEnes Uğuroğlu
The automotive industry is undergoing wide scope transformation. Industry4.0 has both expanded the possibilities of digital transformation inautomotive, increased its importance to all mobility ecosystem and beingdriven by continued digitization of the entire value chain. Manufacturingdata which is unceasingly flow during serial production is one of the greatsources towards Industry 4.0 goal to fully automatizing complex humandependent processes. However, there are few challenges to consider suchas collecting and filtering various data from shop floor in given productioncycle time range and make them ready for real time analytics as well asconstructing efficient data pipeline to reach useful outcomes which isreliable enough to meet customer expectations. In this study, we will extractmeaningful relation between injection machine parameters from FarplasAutomotive Company’s shop floor and describe their effects on the productquality. We will train and test machine learning models with differenthyperparameters and test model performance to identify defected products.Finally, we will show implementation of streaming data pipeline using Kafkaand Spark to be able to analyze injection machine data and effectivelypredict plastic injection product’s OK-NOK condition real time even beforehuman operator reaches the product itself. Consequently, detectingdefected products will be independent from human attention which makesproduction areas one step closer to dark factory.
Award Ceremony & Closing Ceremony
Saturday, Aug. 14th 2021 15:45-16:00 (GMT+2) Webex

19
Day 3Keynote Session
Keynote Speech-1
08:45-09:30 Sunday, Aug. 15th 2021 (GMT + 2)
Title: Machine learning on multimodal histopathology data
Prof. Dr. Henning MüllerHES-SO ValaisTechno-Pôle 3, 3960 Sierre, Switzerland
AbstractHistopathology is in large part still analogue and images in the diagnostic process are manuallyinspected using a microscope. As many histopathology departments become digital for thediagnostic workflow it is important to find ways to manage these very large images(100'000x100'000 pixels with up to 20 images for a single tumor biopsy).This presentation willpresent how image data and associated text can be used together to extract knowledge from thecases and to help in the development of machine learning for decision support. The mainapplication will be on cancer grading/staging to help in decision support. Concrete examples fromthe EU project ExaMode will be given.
Introduction to Prof. Dr. Henning Müller
Henning Müller studied medical informatics at the University of Heidelberg, Germany, then workedat Daimler-Benz research in Portland, OR, USA. From 1998-2002 he worked on his PhD degree incomputer vision at the University of Geneva, Switzerland with a research stay at Monash University,Melbourne, Australia. Since 2002, Henning has been working for the medical informatics service atthe University Hospital of Geneva. Since 2007, he has been a full professor at the HES-SO Valaisand since 2011 he is responsible for the eHealth unit of the school. Since 2014, he is also professorat the medical faculty of the University of Geneva. In 2015/2016 he was on sabbatical at theMartinos Center, part of Harvard Medical School in Boston, MA, USA to focus on researchactivities. Henning is coordinator of the ExaMode EU project, was coordinator of the Khresmoi EUproject, scientific coordinator of the VISCERAL EU project. Since early 2020 he is also a member ofthe Swiss National Research Council.
Oral Session
Sunday, Aug. 15th 2021 09:30-10:00 (GMT +2) Webex

20
W005Prof. Hiroshi
KoideKyushu University,
Japan
Takeshi Masumoto(Student)
Kyushu UniversityFukuoka, Japan
15 min
MTD: Run-time System Call Mapping RandomizationTakeshi Masumoto, Wai Kyi Kyi Oo, Hiroshi KoidenThe purpose of our research is to provide defense against code injectionattacks on the system. Code injection attack is one of the most dangerousattacks to a system, which can even give an attacker a chance to fullycompromise the system by executing arbitrary code.Moving TargetDefense (MTD) can protect the system from attacks by dynamicallychanging the target area of attacks including vulnerability as well as reducethe reachability of attacks. System call randomization is an MTD techniquethat disables code injection attacks by randomizing the mapping betweensystem call numbers and the functions called by them. The purpose ofsystem call randomization is to limit the processing and resources that theinjected program can perform and access. As system calls are the only wayfor user applications to access system resources, randomizing system callscan give attackers more difficulty to achieve their goals, even if they caninject the program. Existing system call randomization techniques onceperformed randomization before loading the program, however, suchmethods only once in advance have no effect when information aboutrandomization is disclosed to attackers. In this paper, we propose a methodof re-randomizing multiple times at run-time to solve this problem. Weimplemented a script that directly edits the ELF executable format. In fact,as a result of running the script on a small program, we succeeded ingenerating a new executable file to which the method is applied. Ourexperiments show that run-time system call randomization is effectiveagainst code injection attacks, and this technique may also be applied toexisting compiled programs.
W001AlexanderAntonov(Student)
Department of Law,Tallinn University ofTechnology, Tallinn,
Estonia
Pitfalls of Machine Learning Methods in Smart Grids: A LegalPerspectiveAlexander Antonov, Tobias Häring, Tarmo Korõtko, Argo Rosin, TanelKerikmäe, Helmuth Biechl
The widespread implementation of smart meters (SM) and the deploymentof the advanced metering infrastructure (AMI) provide large amounts offine-grained data on prosumers. Machine learning (ML) algorithms are usedin different techniques, e.g. non-intrusive load monitoring (NILM), to extractuseful information from collected data. However, the use of ML algorithmsto gain insight on prosumer behavior and characteristics raises not onlynumerous technical but also legal concerns. This paper maps electricityprosumer concerns towards the AMI and its ML based analytical tools interms of data protection, privacy and cybersecurity and conducts a legalanalysis of the identified prosumer concerns within the context of the EU

21
15 min regulatory frameworks. By mapping the concerns referred to in thetechnical literature, the main aim of the paper is to provide a legalperspective on those concerns. The output of this paper is a visual tool inform of a table, meant to guide prosumers, utility, technology and energyservice providers. It shows the areas that need increased attention whendealing with specific prosumer concerns as identified in the technicalliterature.
Keynote Session
Keynote Speech-2
10:00-10:45 Sunday, Aug. 15th 2021 (GMT + 2)
Title: Biometrics: Succeeding, slowing or stalled?
Prof. Steven FurnellUniversity of Nottingham, UK
Abstract
For many years, biometrics were the long-promised solution to our authentication woes, and yetuntil relatively recently they remained something that most people had heard about rather thanactually used. However, this situation changed dramatically during the last decade, thanks in largepart to their use within mobile devices. As a result, many people have not only used biometrics,but do so regularly, many times a day, without necessarily even thinking about it. Nonetheless,biometrics are still far from being the ubiquitous solution that is needed to rid ourselves ofpasswords, causing some to question whether the revolution has stalled. This talk will take stockof the situation, examining the progress that has been made, and considering the potential forovercoming the barriers to wider adoption.
Introduction to Prof. Steven Furnell
Steven Furnell is a professor of cyber security at the University of Nottingham in the UnitedKingdom. He is also an Adjunct Professor with Edith Cowan University in Western Australia and anHonorary Professor with Nelson Mandela University in South Africa. His research interests includeusability of security and privacy, security management and culture, and technologies for userauthentication and intrusion detection. He has authored over 330 papers in refereed internationaljournals and conference proceedings, as well as books including Cybercrime: Vandalizing theInformation Society and Computer Insecurity: Risking the System. Prof. Furnell is the current Chairof Technical Committee 11 (security and privacy) within the International Federation for Information

22
Processing, and a member of related working groups on security management, security education,and human aspects of security. He is the editor-in-chief of Information and Computer Security, aswell as an associate editor for various other journals including Computers & Security and TheComputer Journal. His activities also include extensive contributions to international conferences inthe security field, including keynote talks, event chairing, and programme committee memberships.In terms of professional affiliations, Prof. Furnell is a senior member of the IEEE and the ACM, anda fellow of BCS, the Chartered Institute for IT. He is also a Fellow and board member of theChartered Institute of Information Security and chairs the academic partnership committee.
Break & Free Discussion
Sunday, Aug. 15th 2021 10:45-11:15 (GMT +2)
Oral Session
Sunday, Aug. 15th 2021 11:15-12:15 (GMT +2) Webex
W009Carmelo FerranteUniversity CollegeDublin Trento, Italy
15 min
Answering to 5W using digital forensics dataCarmelo Ferrante, Babak Habibnia, Pavel Gladyshev
In recent years the increasing capacity of storage devices, the advent of thecloud and the quantity of email, messages, chats, pictures and filesexchanged, led the data to be analyzed and correlated by the digitalinvestigators to be hundreds of times bigger than 15 years ago (DarrenQuick, K.K.R.C., 2014). To permit a fast visualization of the data, applicableto different types of data and understandable even to nonexpert people,we propose a proof of concept of a framework, defined Digital Forensics5W (DF5W), that create a visualization of the data as answers to the 5Wquestions: Who, What, When, Where and Why. In order to test this idea, wedeveloped a small prototype and tested it on two case studies: the ENRONdataset and a kidnap case. The results have revealed that answering to 5Wusing Digital Forensics Data is feasible and their use can display usefulinformation in a narrative way. It is allowing the quick identification ofpossible groups of data that could need to be analyzed in deep.

23
W1005Prof. Fabriziod’AmoreDIAG –
SAPIENZAUniversity of Rome -
Italy15 min
Authentication as a service based on Shamir Secret SharingAndrea Bissoli, Fabrizio d’ Amore
We consider a solution for securing the classical password-basedauthentication scheme, because in many cases this type of authenticationis given as a requirement. Our solution is based on the well-known (k,n)threshold scheme of Shamir for sharing a secret, where in our case thesecret is the password itself and (k,n) threshold scheme means that npassword-derived secrets (shares) are created and k ≤ n shares arenecessary and sufficient for reconstructing the password, while k −1 arenot sufficient. The scheme is information-theoretic secure. We improve theapproach so that the password is one-time. Since each of the n shares isstored on a different host (Shareholder), an attacker will need tocompromise k different Shareholders for obtaining an amount of datasufficient for reconstructing the secret. Furthermore, in order to be resistantto the compromising of the server (Dealer) coordinating the Shareholders,we define a variant of the classic Shamir, where the Shamir’s abscissasare unknown to Dealer and Shareholders, making the reconstructionimpossible even in the case of Dealer and Shareholders compromised. Inaddition, we apply the Pedersen method for allowing the verification ofshares. For the described scenario we have designed two protocolsallowing the communication between application, Dealer and Shareholders,so that the relevant players can participate in the phases of registration(users sign-up, to be carried out once), and of authentication (users login).We analyse several scenarios where Dealer and/or Shareholders arepartially/totally compromised and confirmthat none of them is enabling theattacker to break the authentication. Furthermore we focus on cases whereone or more byzantine servers are presented, analysing the impact on theauthentication and show the adopted mechanisms to be secure againstthese kinds of attacks. We have developed a prototype demonstrating thatour method works correctly, effectively and efficiently. It provides a firstfeasibility study that will provide a base for structured and engineeredcloud-based implementations aiming at providing what we call anauthentication-as-a-service.
W012
Detection of Ransomeware Attack Using Machine LearningAnusha Vajha

24
Anusha VajhaInstitute ofAeronautical
Engineering,India15 min
Ransomware is one of the most prevalent malicious software in 2021, itencodes the files in the victim's device, then demands money, i.e., ransom,for decrypting the files. The financial losses and global damage cost ofindividuals and organizations due to ransomware is increasing year byyear. As a result, combatting ransomware is a critical concern. In this paper,the proposed ransomware detection approach is based on machinelearning. The primary goal was to examine the visible changes with ahuman eye. The encrypted text files are then compared to unencrypted textfiles with the use of customized features and ML training, the program canidentify text files that had been attacked. Four different datasets are usedwhich contain thousands of text files. Each text file has 50% unencryptedtext and 50% text encrypted by 6 types of encryption techniques –
Atbash, Autokey, Caesar, Gronsfeld, Playfair, and RSA. Two differentmachine learning classifiers are trained – support vector machine andnear neighbor algorithm (KNN) – to train the model. From theexperimental results, the classification accuracies of 91% were achievedwith both classifiers.
W1001
Comparative Analysis of Intrusion Detection Attack Based on MachineLearning ClassifiersSurafel Mehari and Prof. Dr. Anuja Kumar Acharya

25
Surafel MehariSchool of ComputerEngineering, KIIT
University,Bhubaneswar, India
15 min
In current day information transmitted from one place to another by usingnetwork communication technology. Due to such transmission ofinformation, networking system required a high security environment. Themain strategy to secure this environment is to correctly identify the packetand detect if the packet contain a malicious and any illegal activityhappened in network environments. To accomplish this we use intrusiondetection system (IDS). Intrusion detection is a security technology thatdesign detects and automatically alert or notify to a responsible person.However, creating an efficient Intrusion Detection System face a number ofchallenges. These challenges are false detection and the data contain highnumber of features. Currently many researchers use machine learningtechniques to overcome the limitation of intrusion detection and increasethe efficiency of intrusion detection for correctly identify the packet eitherthe packet is normal or malicious. Many machine-learning techniques usein intrusion detection. However, the question is which machine learningclassifiers has been potentially to address intrusion detection issue innetwork security environment. Choosing the appropriate machine learningtechniques required to improve the accuracy of intrusion detection system.In this work, three machine learning classifier are analyzed. Support vectorMachine, Naïve Bayes Classifier and K-Nearest Neighbor classifiers. Thesealgorithms tested using NSL KDD dataset by using the combination of Chisquare and Extra Tree feature selection method and Python used toimplement, analyze and evaluate the classifiers. Experimental result showthat K-Nearest Neighbor classifiers outperform the method in categorizingthe packet either is normal or malicious.
Break & Free Discussion
Sunday, Aug. 15th 2021 12:15-14:00 (GMT +2)

26
Keynote Session
Keynote Speech-3
14:00-14:45 Sunday, Aug. 15th 2021 (GMT + 2)
Title: Biometrics: Succeeding, slowing or stalled?
Prof. Amir HerzbergUniversity of Connecticut, USA
Abstract
Public Key Infrastructure (PKI) provides an essential foundation to applications of public keycryptography, and crucial for security in open networks and systems. Since its introduction in 1988,the PKI landscape was dominated by the X.509 standard, widely deployed by many protocols andsystems, most notably TLS/SSL, used to secure connections between web server and browser.Unfortunately, the web-PKI deployment has inherent weaknesses, and over the years, we haveseen many failures of this trusted-CA approach. PKI failures allow attackers to issue fakecertificates, launch website spoofing and man-in-the-middle attacks, possibly leading to identitytheft, surveillance, compromises of personal and confidential information, and other serioussecurity breaches. These failures motivated efforts to develop and adopt next-generation,improved-security PKI schemes, i.e., PKI schemes that ensure security against corrupt CAs. Duringthe recent years, there have been extensive efforts toward this goal by researchers, developers andthe IETF. These efforts focus on additional security goals such as {\em transparency}, {\emnon-equivocation}, {\em privacy} and more.This talk will provide a concise review of this importantarea, and give the highlights of our research toward well-defined security goals for PKI schemes,and toward practical, efficient and yet provably-secure PKI schemes. Some parts of thepresentation would require basic understanding of applied crypto, mainly public-key cryptography,collision-resistant hashing, and Merkle trees.
Introduction to Prof. Amir Herzberg
Dr. Herzberg's is the Comcast professor for Cybersecurity Innovation in the department ofComputer Science and Engineering, University of Connecticut. His research areas include: networksecurity (esp. routing/DNS/transport, Denial-of-Service, Web), privacy and anonymity,appliedcryptography, usable security, security for cyber-physical systems, and social, economic and legalaspects of security.
Dr. Herzberg earned his Ph.D. in Computer Science in 1991 from the Technion in Israel. From 1991to 1995, he worked at the IBM T.J.Watson Research Center, where he was a research staff memberand the manager of the Network Security research group. From 1996 to 2000, Dr. Herzberg was theManager of E-Business and Security Technologies at the IBM Haifa Research Lab. From 2002 to2017, he was a professor in Bar Ilan University (Israel). Since 2017, he is professor at University of

27
Connecticut.Dr. Herzberg is the author of many papers in different areas of cybersecurity as well as24 patents, and is now writing a textbook on cybersecurity (draft available online). He has served innumerous program committees and delivered multiple keynote and plenary talks in conferences,and served as program chair for IEEE CNS’19, editor of PoPETS and ACM TISSEC/TOPS. Dr.Herzberg is recipient of the Internet Society's Applied Networking Research award, 2017.
Oral Session
Sunday, Aug. 15th 2021 14:45-15:30 (GMT +2) Webex
NIS1001Dr. Peter HillmannUniversität derBundeswehr
München, Germany15 min
Automated Enterprise Architecture Model MiningPeter Hillmann, Erik Heiland, and Andreas Karcher
Metadata are like the steam engine of the 21st century, driving businessesand offer multiple enhancements. Nevertheless, many companies areunaware that these data can be used efficiently to improve their ownoperation. This is where the Enterprise Architecture Framework comes in. Itempowers an organisation to get a clear view of their business, application,technical and physical layer. This modelling approach is an establishedmethod for organizations to take a deeper look into their structure andprocesses. The development of such models requires a great deal of effort,is carried out manually by interviewing stakeholders and requirescontinuous maintenance. Our new approach enables the automated miningof Enterprise Architecture models. The system uses common technologiesto collect the metadata based on network traffic, log files and otherinformation in an organisation. Based on this, the new approach generatesEA models with the desired views points. Furthermore, a rule andknowledge-based reasoning is used to obtain a holistic overview. Thisoffers a strategic decision support from business structure over processdesign up to planning the appropriate support technology. Therefore, itforms the base for organisations to act in an agile way. The modelling canbe performed in different modelling languages, including ArchiMate and theNato Architecture Framework (NAF). The designed approach is alreadyevaluated on a small company with multiple services and an infrastructurewith several nodes.

28
NIS1002Prof. Carlos
Manuel MorenoNegrin
Universidad Centralde Venezuela /
Central University ofVenezuela,Venezue
la15 min
Study of the Effect of Security on Quality of Service on a WebRTCframework for videocallsCarlos Moreno, Eduardo Crimaldi , Vinod Kumar, Mónica HuertaWeb Real-Time Communication (WebRTC) is a promising new standardand technology stack, providing full audio/video communications in asecured solution. Organizations implementing such technology deal withboth quality of service and security demands, therefore it is mandatory toinvestigate the impact of QoS parameters when applying securitymechanisms in multimedia services for the case of videocalls. This workpresents a study of quality of service indicators such as jitter, delaybetween RTP (Real Time Protocol) packets, establishment and releasetime for three levels of security, considering the effect over signaling andmedia planes of the videocall. Four scenarios were implemented in twogroups: the first one consisted of a LAN with a Laptop and a PC withWebRTC clients or between a Smartphone and a PC as well. The secondone consisted of a DSL WAN with a Laptop and a PC with WebRTC clientsor between a Smartphone and a PC as well. The three levels of security foreach scenario were implemented as follows: the first one without security,the second one with TLS in signaling, and the third with both TLS insignaling and DTLS in media traffic. Codecs employed were VP8 for videoand OPUS for audio on every testbed over WebRTC with EasyRTCframework. The results show, in general terms that QoS media indicatorswere on the recommended levels according to ITU and IETF. Establishingand liberation time were degraded. In some cases there was animprovement, as in the case of jitter due to the use of RTP (Real TimeTransport) protocol for audio. We recommend the use of machine learningalgorithm K-means for detecting clusters between different QoS indicatorfor the three levels of security just to detect with more accuracy the impactfor each level.
W011Mohammed AAlsuwaie
DFIRe Lab, School
Data Leakage Prevention Adoption Model & DLP Maturity LevelAssessmentMohammed A Alsuwaie, Babak Habibnia, Pavel GladyshevData is the most valuable resource organizations possess. Nowadays,intentional and unintentional data leakages to unauthorized entitieshavedramatically increased in the private and government sectors fordifferent reasons and purposes. Data leak poses a severe threat to the datasecurity of these organizations. In the private sector, such leakage candamage the reputation of a business and weaken its competitiveness, whilea leakage in the government sector can severely impact its public anddiplomatic relationships and even threaten national security. Therefore,

29
of ComputerScience, UniversityCollege Dublin,
Ireland15 min
private and government sectors have recently strived to adopt the DataLeakage Prevention (DLP) program to enhance data security and minimizedata leakage. However, some organizations limit their DLP programs toDLP technology implementation. DLP technology represents only a part ofthe whole process and does not include other essential elements such asplanning, policy, process, data ownership and classification, data accesscontrol, training, and awareness. A comprehensive adoption of theseelements might prevent data leakage. This research paper aims to providea model for DLP adoption and address the most critical elements of theDLP Adoption Model, which are correlated with the DLP Maturity LevelAssessment, the "DLP Maturity Level Grid," to measure the success of themodel.
Break & Free Discussion
Sunday, Aug. 15th 2021 15:30-16:00 (GMT +2)
Keynote Session
Keynote Speech-4
16:00-16:45 Sunday, Aug. 15th 2021 (GMT + 2)
Title: 6G SECURITY
Prof. Ramjee PrasadAalborg City Ambassador, Denmark&International CooperationAdvisor, ITU, San Jose, California, USA
Abstract
6G Security must be designed to offer security end-to-end in the 6G networks’ architecture andconsider the external agents that will interact with the network infrastructure from the physical layerto the application layer, including all potential threats. Consequently, 6G must be secure by design.The challenges of preventing and protecting networks, devices, and society against cyber terrorismare high priorities for the future wireless network.

30
Introduction to Prof. Ramjee Prasad
Dr. Ramjee Prasad, Fellow IEEE, IET, IETE, and WWRF, is a Professor of Future Technologies forBusiness Ecosystem Innovation (FT4BI) in the Department of Business Development andTechnology, Aarhus University, Herning, Denmark. He is the Founder President of the CTIF GlobalCapsule (CGC). He is also the Founder Chairman of the Global ICT Standardisation Forum forIndia, established in 2009. GISFI has the purpose of increasing of the collaboration betweenEuropean, Indian, Japanese, North-American and other worldwide standardization activities in thearea of Information and Communication Technology (ICT) and related application areas. He hasbeen honored by the University of Rome “Tor Vergata”, Italy as a Distinguished Professor of theDepartment of Clinical Sciences and Translational Medicine on March 15, 2016. He is HonoraryProfessor of University of Cape Town, South Africa, and University of KwaZulu-Natal, SouthAfrica.He has received Ridderkorset af Dannebrogordenen (Knight of the Dannebrog) in 2010 fromthe Danish Queen for the internationalization of top-class telecommunication research andeducation.He has received several international awards such as: IEEE Communications SocietyWireless Communications Technical Committee Recognition Award in 2003 for making contributionin the field of “Personal, Wireless and Mobile Systems and Networks”, Telenor's Research Award in2005 for impressive merits, both academic and organizational within the field of wireless andpersonal communication, 2014 IEEE AESS Outstanding Organizational Leadership Award for:“Organizational Leadership in developing and globalizing the CTIF (Center for TeleInFrastruktur)Research Network”, and so on. He has been Project Coordinator of several EC projects namely,MAGNET, MAGNET Beyond, eWALL and so on.He has published more than 50 books, 1000 plusjournal and conference publications, more than 15 patents, over 145 PhD Graduates and largernumber of Masters (over 250). Several of his students are today worldwide telecommunicationleaders themselves.
Oral Session
Sunday, Aug. 15th 2021 16:45-17:45 (GMT +2) Webex
NIS1005Kevin De Boeck
(Student)DistriNet KU
Leuven, Belgium
Dataset anonymization with purpose: a resource allocation use caseKevin De Boeck, Jenno Verdonck, Michiel Willocx, Jorn Lapon, VincentNaessens
Nowadays, companies are collecting huge amounts of data. Applying thecollected data to optimize the business activities can significantly improveprofit margins. In this context, companies often want to enhance theirmodels by enriching the data with data from external sources. Increasingly,companies are also considering selling data as an additional source ofincome. Governments are also willing to share citizen data with businesses.The GDPR regulation, introduced in May 2018 provides a framework for

31
15 min different parties (commercial, governmental, academic) to share and selldata provided that the data is anonymized. The effect of this anonymizationstep on the quality of the data (and the resulting business optimizationconclusions) are still unclear. Utility and quality metrics that exist are purelytheoretical, and do not grasp the purpose of the anonymized data, resultingin discrepancies between the expected and the actual utility of ananonymized dataset. This work studies the practical utility of anonymizeddatasets. It assesses the effect of applying the K-anonymity metric anddataset sampling on the utility of the data by conducting experiments on aresource allocation use case. Practical guidelines are presented foranonymizing datasets while maintaining a high degree of practical utility.
NIS002Ondřej PospíšilBrno University ofTechnology, Czech
Republic15 min
Active scanning in the industrial control systemsOndrej Pospisil, Petr Blazek, Radek Fujdiak, Jiri MisurecIndustrial control systems (ICS) networks have faced challenges in incidentdetection over the last few years. One of the issues harming ICS networksis the active scanning of such structures. Active scanning can be used intwo different key scenarios: either by an attacker causing network damageor by the network owner to explore network hosts and visualize networkarchitecture; in both cases, it can affect ICS network traffic. This paper aimsto demonstrate active scanning using two tools (Nmap, Zmap) from thepenetration tester's perspective. The penetration tester operation wasdescribed in the context of the impact on the failure or the delay ofcommunication in the network. As a part of this work, an industrial testbedwas created to analyse the impact of the scanning. While scanning with theZmap tool, there was a complete loss of communication between thedevice and the testbed network. On the other hand, the Nmap tooldisplayed a delay and an occasional network outage. The article thendescribed and visualized the delay and outage data. These results clearlyshow that it is not appropriate to use active scanners in industrial networks,as they can have a fatal impact on the entire network's communication.
W007Maryam
Ramezanzadehmo
A Personalized Learning Framework for Software VulnerabilityDetection and EducationMaryam Ramezanzadehmoghadam, Hongmei Chi
The software has become a necessity for many different societal industriesincluding, technology, health care, public safety, education, energy, andtransportation. Therefore, training our future software developers to writesecure source code is in high demand. With the advent of data-driventechniques, there is now a growing interest in leveraging machine learningand natural language processing (NLP) as a source code assurancemethod to build trustworthy systems. In this work, we propose a framework

32
ghadam(Student)Florida A&MUniversity
Department ofComputer & Info
SciencesTallahassee, FL32307, USA15 min
including learning modules and hands-on labs to guide future ITprofessionals towards developing secure programming habits andmitigating source code vulnerabilities at the early stages of the softwaredevelopment lifecycle following the concept of Secure SoftwareDevelopment Life Cycle (SSDLC). In this research, our goal is to prepare aset of hands-on labs that will introduce students to secure programminghabits using source code and log file analysis tools to predict, identify, andmitigate vulnerabilities. In summary, we develop a framework which will (1)improve students’ skills and awareness on source code vulnerabilities,detection tools and mitigation techniques (2) integrate concepts of sourcecode vulnerabilities from Function, API and library level to badprogramming habits and practices, (3) leverage deep learning, NLP andstatic analysis tools for log file analysis to introduce the root cause ofsource code vulnerabilities.
W010Kavitha VenkateshDFIRe Lab, School
of ComputerScience, UniversityCollege Dublin
15 min
Forensic analysis of Slack Instant Messenger Application on macOSand iOS deviceKavitha Venkatesh, Pavel Gladyshev, Babak HabibniaThe advent of the internet has removed the communication barriersbetween virtual teams within an organisation. Organisations can nowconduct business from any part of the world. Tools such as Emails andInstant Messengers (IM) enable teams to stay connected and accessible atall times. Instant Messengers are growing in popularity within organisationsas the chosen form of communication primarily because IM ’ s arelightweight; they can easily be installed on desktops or mobile devices andthey allow for a dialogue between 2 or more participants. Exchangingdocuments, multimedia files including audio, video and image files iseffortless. IM applications also provide the ability to make audio and videocalls. Since most of the day to day interactions between various teamswithin an organization happen on an IM, the forensic analysis of IM’ sprovides valuable evidence during corporate or criminal investigations.Thispaper attempts to identify the forensic artefacts left by one such businessapplication called Slack on devices running on macOS and iOS. Data wasgathered from the Slack folder on the macOS and parsed using SQLite andPlist Editor. The contents of each folder was then manually analysed. Forthe device running on iOS, data was acquired using iTunes backup and atool called ibackupBot was used to analyse data. It was found that the Slackapplication stores very little information on the macOS and insignificantamount of information on the iOS device. All the information is stored on theSlack servers which can be accessed using authentication token usingopen API calls.

33
Listener
Saturday, Aug. 14th 2021( GMT + 2) Webex
Prof. Poonam TanwarManav Rachna International Institute of Research & Studies, India
Prof.Chien-Chih WangDepartment of Industrial Engineering and Management, Ming ChiUniversity of Technology, Taiwan
Dr. Olarik SurintaMahasarakham University, Thailand
Dr.Issa AtoumThe World Islamic Sciences and Education, Jordan
Dr. Pascal LorenzDepartment of Computer ScienceUniversity of Haute Alsace, France
Dr. Tan Tse GuanUniversiti Malaysia Kelantan, MALAYSIA
Prof. Héctor F. Migallón GomisMiguel Hernández University, Spain
Pr. Smain FEMMAMUHA University France

34
Dr. Ankur Singh BistKIET, Ghaziabad, India
Prof. Dr. Loc NguyenIndependent Scholar
Dr. Bharat BhushanBirla Institute of Technology, India
Award Ceremony & Closing Ceremony
Sunday, Aug. 15th 2021 17:15-18:00 (GMT+2) Webex

35
Upcoming Conferences
www.cfeee.org
www.icstte.org
www.meamt.org

36
www.icbicc.org
www.icnaome.org
www.ccvpr.org

37
FLAT/RM A 9/F SILVERCORP INTERNATIONAL TOWER707-713 NATHAN ROAD MONGKOK, HONGKONG
TEL:+852-30696823Email: [email protected]








![International Conference: Traditional Architecture in the Western Mediterranean [final program]](https://static.fdokumen.com/doc/165x107/6328c62f2ad047623a033043/international-conference-traditional-architecture-in-the-western-mediterranean.jpg)











