
Boundary effects in Polish English - implications for similarity in L2 phonology (with Grzegorz...
38
1 Boundary effects in Polish English – implications for ‘similarity’ in L2 phonology 1 Geoffrey Schwartz 1 , Grzegorz Aperliński, Anna Balas 1 , Arkadiusz Rojczyk 2 1-Faculty of English, Adam Mickiewicz University in Poznań; 2- Institute of English, University of Silesia 0 – Abstract Experimental phonetic studies examine the extent to which Polish learners of English acquire phonological processes occurring at word boundaries in the target language. In particular, we look at linking of vowel-initial words and the suppression of stop release in word-final stops. Our results suggest that glottalization of vowels, which blocks linking of initial vowels, and coda stop release production, both constitute L1 phonological interference that learners must overcome. The phonology of these seemingly unrelated effects may be unified in the Onset Prominence framework, in which parametric representational mechanisms govern the extent of phonetic cohesion between segments and the formation of prosodic boundaries. Implications for the oft-invoked notion of cross-language phonological similarity are also discussed. 1 - Introduction For a significant percentage, if not a majority, of studies on second language (L2) phonology, it is segmental contrasts that constitute the linguistic focus of experimental work. Researchers have investigated the effects of cross-language differences both in segmental inventories, as well as the realization of phonological categories. For example, many studies are devoted to the acquisition of new L2 vowel contrasts by speakers whose L1 lacks the opposition in question; Escudero & Boersma’s (2004) oft-cited study examines Spanish L1 speakers’ perception of the English /iː/-/ɪ/ contrast. Another area that has received a lot of attention is the implementation of laryngeal contrasts, measured in terms of the phonetic parameter of voice onset time (VOT). Studies typically compare VOTs of stops in the speech of bilinguals whose two languages differ in this parameter, such as French and English (e.g. Flege 1987) or Greek and English (e.g. Antoniou et al. 2010). Research into the perception and production of L2 segments has been instrumental in the formation of two of the more influential theoretical models of L2 speech acquisition. Flege’s Speech Learning Model (SLM; Flege 1995) and Best’s Perceptual Assimilation Model (PAM; Best 1995, Best & Tyler 2007) facilitate the formulation of important predictions concerning learners’ success or lack of success in the acquisition of second language segments and contrasts. When examining the research spawned by current models of L2 speech, one encounters a crucial concept that constitutes the foundation of both the SLM and the PAM: the notion of similarity. Difficulties in acquisition of L2 segments and contrasts are predicted on the basis of how similar they are to those found in L1. Interestingly, similarity has been seen as both a help (Best 1995) and a hindrance (Flege 1995) in L2 phonological acquisition. A question that is not so frequently asked, however, is how similarity is to be defined. Flege (1995: 264) notes this problem, stating that “an obstacle to testing hypotheses . . . is the lack of an objective means for gauging degree of perceived cross-language phonetic distance”. Nevertheless, while there is awareness of the issue, there remain unresolved issues with regard to assumptions of cross-language phonetic distance (see e.g. Major 2008: 71). In essence, the question of similarity is one of phonological representation. In what follows, we 1 This research was supported by a grant from the Polish National Science Centre (Narodowe Centrum Nauki). Project number 2012/05/B/HS2/04036.
Transcript of Boundary effects in Polish English - implications for similarity in L2 phonology (with Grzegorz...

1
Boundary effects in Polish English – implications for ‘similarity’ in L2 phonology1
Geoffrey Schwartz1, Grzegorz Aperliński, Anna Balas
1, Arkadiusz Rojczyk
2
1-Faculty of English, Adam Mickiewicz University in Poznań; 2- Institute of English, University of Silesia
0 – Abstract
Experimental phonetic studies examine the extent to which Polish learners of English acquire
phonological processes occurring at word boundaries in the target language. In particular, we
look at linking of vowel-initial words and the suppression of stop release in word-final stops.
Our results suggest that glottalization of vowels, which blocks linking of initial vowels, and
coda stop release production, both constitute L1 phonological interference that learners must
overcome. The phonology of these seemingly unrelated effects may be unified in the Onset
Prominence framework, in which parametric representational mechanisms govern the extent
of phonetic cohesion between segments and the formation of prosodic boundaries.
Implications for the oft-invoked notion of cross-language phonological similarity are also
discussed.
1 - Introduction
For a significant percentage, if not a majority, of studies on second language (L2) phonology,
it is segmental contrasts that constitute the linguistic focus of experimental work. Researchers
have investigated the effects of cross-language differences both in segmental inventories, as
well as the realization of phonological categories. For example, many studies are devoted to
the acquisition of new L2 vowel contrasts by speakers whose L1 lacks the opposition in
question; Escudero & Boersma’s (2004) oft-cited study examines Spanish L1 speakers’
perception of the English /iː/-/ɪ/ contrast. Another area that has received a lot of attention is
the implementation of laryngeal contrasts, measured in terms of the phonetic parameter of
voice onset time (VOT). Studies typically compare VOTs of stops in the speech of bilinguals
whose two languages differ in this parameter, such as French and English (e.g. Flege 1987) or
Greek and English (e.g. Antoniou et al. 2010). Research into the perception and production of
L2 segments has been instrumental in the formation of two of the more influential theoretical
models of L2 speech acquisition. Flege’s Speech Learning Model (SLM; Flege 1995) and
Best’s Perceptual Assimilation Model (PAM; Best 1995, Best & Tyler 2007) facilitate the
formulation of important predictions concerning learners’ success or lack of success in the
acquisition of second language segments and contrasts.
When examining the research spawned by current models of L2 speech, one
encounters a crucial concept that constitutes the foundation of both the SLM and the PAM:
the notion of similarity. Difficulties in acquisition of L2 segments and contrasts are predicted
on the basis of how similar they are to those found in L1. Interestingly, similarity has been
seen as both a help (Best 1995) and a hindrance (Flege 1995) in L2 phonological acquisition.
A question that is not so frequently asked, however, is how similarity is to be defined. Flege
(1995: 264) notes this problem, stating that “an obstacle to testing hypotheses . . . is the lack
of an objective means for gauging degree of perceived cross-language phonetic distance”.
Nevertheless, while there is awareness of the issue, there remain unresolved issues with
regard to assumptions of cross-language phonetic distance (see e.g. Major 2008: 71). In
essence, the question of similarity is one of phonological representation. In what follows, we
1 This research was supported by a grant from the Polish National Science Centre (Narodowe Centrum Nauki).
Project number 2012/05/B/HS2/04036.

2
will offer enhanced representational tools that allow for a new perspective on the question of
cross-language phonetic distance. In particular, we consider the relationship between the
representation of segmental units and that of prosodic constituents and their boundaries.
Although traditional phonetic and phonological descriptions provide largely viable
options for defining segmental similarity between L1 and L2, the effects of external sandhi,
phonological processes observable at word boundaries, have been largely neglected in L2
speech research. For example, at the two previous New Sounds conferences, in Poznań,
Poland and Montreal, fewer than five out of well over 100 presentations could be claimed to
be related to boundary effects. Most of these studies addressed the well-known processes of
liaison and enchaînement in L2 French (e.g. Howard 2006, 2008; Shoemaker 2010; Sturm
2013), beyond which the acquisition of L2 sandhi remains almost entirely unexplored. Zsiga
(2011) provides a literature review that is helpful in assessing the current state of research.
She discusses just a few studies dealing with a small number of L1-L2 pairings (Catalan-
English, Cebrian 2000; English-Russian, Zsiga 2003; Spanish-German, Lleo&Vogel 2004;
Korean-English, Zsiga 2011). In sum, there is a clear need for more research on cross-
language boundary effects, which have clear implications for communicative success in the
target language.
The placement of prosodic boundaries may at first glance appear to be an
unpredictable aspect of the phonology of a given language. However, cross-language
comparisons suggest that languages may differ systematically in their boundary formation
mechanisms. Consider the sequence of /t#j/ in English got you as opposed to Polish kot jest
‘the cat is’. The English example is frequently produced without any boundary at all – the
stop and the glide are joined into an affricate and the form is pronounced gotcha. The /t/
undergoes a sandhi process of palatalization. Conversely, in Polish, such stop-glide
sequences are produced asynchronously (Święciński 2012) – the /t/ is not subject to the same
type of mutating processes that may within words. The /t/ appears to be ‘final’ in the Polish
example, while in English it is resyllabified and assimilates to the /j/. Although /t#j/ is a
‘similar’ sequence in segmental terms, there is a seemingly systematic difference in its
realization in Polish and English. In Polish /t#j/ there is a boundary, while in English there is
not. The question that remains is if there is any way to predict this state of affairs.
We suggest that the appearance of prosodic boundaries between segments has
phonological origins that may be derived within the Onset Prominence representational
environment (OP; Schwartz 2010a, 2010b, 2012, 2013a). The OP framework is a new theory
of phonological representation that encodes manner of articulation as a structural property
(cf. Aperture Theory, Steriade 1993), yielding representations in which segments and
syllables are constructed from the same materials, rather than being linked to a skeleton by
means of association lines. Prosodic boundaries arise when two adjacent segmental structures
may not be joined according to the basic constituent-forming mechanisms of the framework.
With regard to the /t#j/ example discussed above, sandhi palatalization in Polish is blocked
by a process of promotion, a kind of fortition that raises the glide to the highest level of the
OP hierarchy normally occupied by stop closure. A similar mechanism governs the
realization of word-initial vowels in Polish, which show a tendency for glottal marking that
blocks sandhi processes linking C#V and V#V sequences. By contrast, English is
characterized by a recursive submersion process, which is responsible for linking processes
that wipe out boundaries before vowel-initial words (find out ~ fine doubt; see [ʲ]everything).
The process of submersion in English also governs the realization of word-final stop
consonants, which are frequently produced without an audible release.
This paper will present phonetic data from Polish learners of English investigating
two types of boundary phenomena, which at first glance appear to be unrelated. In Section 2,
we will examine the relations between glottalization and linking of word-initial vowels in

3
both C#V and V#V contexts. Our results suggest that vowel glottalization is a form of L2
interference that hinders the acquisition of sandhi linking processes in English. The C#V
data are supplemented by additional measures of consonant voicing to explore the connection
between sandhi linking and the acquisition of ‘final’ voiced obstruents, a well-known
problem for L1 Polish learners. The V#V data include the results of an accent rating test in
which L1 English listeners judged glottalized and non-glottalized hiatus tokens on a scale of
foreign accentedness. In Section 3 we look at the production of stop release of the word-final
consonant in VC#C sequences. Our data indicate that the acquisition of target language
unreleased stops is connected with the acquisition of robust VC formant transitions
suggestive of greater articulatory coordination between the vowel and consonant. Thus, in
both of these empirical areas, native-like production in English entails a tendency for greater
phonetic cohesion between segments. These patterns are predicted by the representational
mechanisms of the OP framework, which we review in Section 4. Finally, in Section 5 we
discuss implications for the oft-invoked notion of cross-language phonological similarity.
2 Vowel-initial words in Polish English
This section will summarize data related to Polish learners’ acquisition of linking processes
involving vowel-initial words in English. In 2.1 we review previous work to provide a
comparison of the patterns of initial vowel realization in L1 English and Polish. An acoustic
study of C#V sequences is described in 2.2. In 2.3 we present a related study of V#V
sequences. Section 2.4 describes an accent rating study in which L1 English listeners judged
linked and glottalized V#V sequences.
2.1 Previous work on vowel-initial words in English and Polish
Our study is based on a claim that Polish and English are characterized by differences in the
representation of word-initial vowels. We return to the phonological underpinnings of this
claim in Section 4. For now, we suggest that word-initial vowels in Polish are inherently
more prominent prosodic entities than their counterparts in English. This claim is compatible
with previous findings that word-initial syllables in Polish are marked by some degree of
phonetic prominence (Dogil 1999; Crosswhite 2003; Newlin-Łukowicz 2012). The
consequence for Polish word boundaries is the blockage of the type of sandhi linking
processes that are common in English. A corollary of our claim is a hypothesis that Polish
initial vowels, as more prominent entities, should be more likely to be produced with
glottalization. That is, glottalization in Polish may be the fortification of a prominent prosodic
position, whereas in English it serves merely to mark the boundaries of larger prosodic
constituents. Consequently, we should expect glottalization in Polish to be more prevalent.
The difference between Polish and English with regard to linking processes involving
word-initial vowels is reflected in traditional textbook descriptions, as well as phonological
studies. With regard to English, process linking initial vowels with the preceding segment are
described. For example, McCarthy (1993) offers a phonological analysis of a process of
hiatus glide insertion in American English (see Ed [sijed], new image [nuwɪmədʒ];
McCarthy, 1993), while Uffmann (2007) discusses linking or intrusive /r/ in non-rhotic
dialects (Uffmann, 2007). For C#V contexts, Cook (2000) as well as Cruttenden describe
processes of liaison or linking (find out ~ fine doubt).2 Flapping of /t/ at C#V word
boundaries is also frequently described (e.g. Harris 1994). In the presence of such linking
2 The terms liaison and linking are used interchangeably in this paper.

4
processes, phrase-medial vowel glottalization is uncommon in English (Dilley et al. 1996).
By contrast, descriptions of Polish phonology make no mention of any linking processes.
Rubach & Booij (1990) note that C#V sequences in Polish are not resyllabified. Meanwhile,
Dukiewicz & Sawicka (1995), as well as Gussmann (2007), suggest that glottal stops are the
norm for word-initial vowels, and may even appear word-internally.
Our claim is also reflected in English pronunciation textbooks with regard to
glottalization in English. Cruttenden (2001) states that the use of glottal stops in English is
not as common as in some other languages, e.g. German, and is limited to emphatic
utterances. Lecumberri & Maidment (2000: 64) see utterance-initial glottal stop insertion in
emphatic speech as a universal phenomenon. Wells (2008: 345) claims that glottalization is
optionally used to add emphasis to syllable-initial vowels or to avoid hiatus in neighboring
syllables (V#V).
In recent years, some experimental studies have suggested that traditional English
linking processes may be in decline. Britain & Fox found that traditional hiatus fillers [j w r]
have been replaced by glottalization in culturally and linguistically diverse areas in the South
of England (cf. Britain & Fox 2008). Meanwhile, Davidson & Erker (2014) present evidence
against ‘glide insertion’ by English speakers in New York City (see 4.2 for additional
discussion of the Davidson & Erker study). Glottalization of hiatus was often observed when
the word-initial vowel is stressed. In other cases, they found that VV and V#V sequences
differ systematically from VjV and V#jV sequences.
Experimental phonetic studies also suggest that glottalization is more prevalent in
Polish than in English. Dilley et al. (1996) found a phrase-medial glottalization rate of around
17% in a corpus American English radio speech. By contrast, Malisz et al. (2013) found a
phrase–medial glottalization rate of just under 35%, about twice that of the rate found by
Dilley et al. (1996) in American English. Schwartz (2013b) found an even higher rate for
phrase-medial V#V tokens in a sentence reading task. The Schwartz (2013b) study also
examined spectral balance of hiatus in V#V contexts. Hiatus tokens without visible
glottalization were compared with initial-syllable CV tokens. The results revealed that the
hiatus vowels were produced with a higher spectral balance. This was true both overall and
across the V2 contexts. Raised spectral balance has been identified as a cue to word stress in
a number of languages (e.g. Sluijter & van Heuven 1996; Crosswhite 2003; Plag et al. 2011),
so this finding points to the prosodic prominence of Polish word-initial vowels even when no
glottalization is visible on waveform and spectrogram displays. In American English,
Garellek (2012) has found no spectral balance effect in phrase-medial postion; it was limited
to phrase-initial position. In sum, the common thread running through textbook descriptions
and phonetic studies is that Polish initial vowels are susceptible to glottalization, which
blocks the application of other linking processes characterized by modal voice quality.
Transferring these patterns to the domain of SLA allows for the formulation of a
hypothesis that glottalization of initial vowels in the speech of Polish learners of English may
be a manifestation of L1 phonological interference that hinders the acquisition of target
language sandhi processes. In what follows we shall present acoustic phonetic studies
investigating this possibility.
2.2 Production of C#V sequences by Polish learners of English
This section presents an acoustic study of C#V sequences produced by Polish learners of
English (for a related study, see Schwartz et al. 2014). The aim is to measure the degree of
acquisition of sandhi linking processes. In addition, we present acoustic measures of voicing
of the word-final obstruent in these sequences. Since word-final devoicing is a typical feature

5
of Polish-accented English, and linking results in a loss of ‘final’ status, we should expect to
find a relationship between the acquisition of final voicing and sandhi linking.
2.2.1 Participants
Our analysis is based on recordings of twelve Polish students majoring in English studies at
the University of Silesia (Uniwersytet Śląski; UŚ), Sosnowiec and Adam Mickiewicz
University (Uniwersytet im. Adama Mickiewicza; UAM), Poznań. Six of the twelve subjects
were first year students, while the other eight were in higher years. In the first year of English
studies in Polish universities, students receive intensive pronunciation instruction (2*90
minutes/week). In the second year, this instruction is reduced to one meeting a week, while
students in the third year and above no longer receive explicit instruction in pronunciation.
The division into first/higher years was intended to group the students according to whether
or not they had completed the intensive first year instruction. The first year group had
completed one semester of instruction at the time of the recordings. The higher years group
had completed 3 or 4 semesters.3 None of the participants had spent significant time in an
English-speaking country. All of the participants had received passing grades in their English
pronunciation courses.
2.2.2 Materials and procedure
Data were elicited from a sentence list containing 35 English C#V sequences (see Appendix
1) in which the consonant was a voiced obstruent. The list also contained fillers, as well as
tokens used in a separate experiment. The recordings were made in soundproof recording
studios in the English departments at each of the two universities.4 The studios were
equipped with a computer monitor upon which the stimulus data were presented. First,
subjects were instructed to read the sentence presented on a slide in a Power Point
presentation. Afterwards, the presentation of the slide was accompanied by an audio
recording of one of five native speakers of English producing the stimulus with a linked C#V
production. Students were instructed to imitate the model voice. The acoustic analysis was
made on the tokens produced in the imitation task. A total of 420 tokens were collected for
analysis, of which 3 were excluded for technical reasons.
The imitation task had two primary goals. The first goal was to exert control over the
analyzed data. Glottal marking in L1 English is frequently dependent on prosodic position
(Dilley et al. 1996), which is difficult to control for in the elicitation of L2 speech. By
repeating after L1 speakers, the participants’ task was to embed the vowel-initial word in the
same prosodic context. By the same token, the task also allows us to factor out other possible
influences on glottalization, such as word frequency or the function/content word distinction.
Secondly, imitation tasks have been found to elicit phonetic convergence (Goldinger 1997;
Shockley et al. 2004; Pardo et al. 2012; for L2 studies see Rojczyk 2012, 2013; and Rojczyk
et al. 2013), by which speakers approximate non-contrastive phonetic details. As such, we
might expect the task to neutralize proficiency-based differences in non-contrastive features
3 Polish dialect background was not taken into account in our analysis. Eight of the twelve students were raised
in either the Upper Silesia or Great Poland provinces, which have been described as regions that feature a sandhi
voicing process before word-initial vowels and sonorants (see e.g. Dejna 1973). According to our auditory
impressions of these subjects’ Polish, sandhi voicing was largely absent. If, for our subjects, sandhi voicing was
indeed a factor, the effect would be to produce more voicing in final obstruents. The results to be presented
presently suggest that this is unlikely. 4 The recording studio at UAM is equipped with an Edirol UA-25 USB audio interface, while the UŚ studio
features a Sound Devices USBPre2 interface. Both devices allow for high-quality recordings directly onto a
laptop computer. At both univsities, recordings were made at a sampling rate of 48 kHz, 24-bit quantization.

6
such as vowel glottalization. That is, we might expect both groups of students to produce
similar non-glottalized tokens after the model voice. By contrast, if advanced learners
produce less glottalization in the imitation task, we might safely attribute glottalization to L1
phonological interference. In other words, proficiency-based differences that survive the
imitation task may be claimed to reflect the level of phonological acquisition.
2.2.3 Acoustic analysis
Acoustic analysis was performed manually with the help of the Praat program (Boersma &
Weenink 2011). The analysis focused on voicing parameters associated with the final
consonant, as well as the realization of the vowel. With respect to voicing, the following
measurements were made.
Duration of the preceding vowel (in milliseconds). The vowel duration measurements
included all post-vocalic sonorant consonants in which robust formant structure could
be identified.
Duration of final obstruent (in milliseconds); These measurements included both stop
closure and burst noise in the case of plosives and affricates, and frication noise in the
case of fricatives and affricates. In other words, a single measure of consonant
duration combined all aspects of obstruent articulation.
Duration of periodicity (vocal fold vibration) during the obstruent articulation (in
milliseconds).
From these measurements, voicing of the consonant was quantified according to two
calculated variables.
V/C ratio: duration of the preceding vowel divided by duration of the consonant. V/C
ratios are higher when the consonant is voiced. This effect is greater in English than in
other languages (Chen 1970), and is crucial for L1 perception. (Port & Dalby 1982)
%Voiced: the duration of the voiced period of the consonant divided by the total
consonant duration multiplied by 100. This measure allows us to describe how much
of a given consonant was in fact voiced.
With regard to the realization of the vowel in the C#V sequences, the goal of the
acoustic examination was to determine the presence or absence of glottalization. When no
glottalization or pause was visible on the vowel, the tokens were coded as Linked or Liaised.
An example of an L-annotated token is given in Figure 1, which contains a token of the
sequence showed everyone. The closure period of the stop, which is fully voiced, is selected
in the display.

7
Figure 1 – Example of token coded as Liaison; showed everyone
With regard to the glottalized tokens, we observed variable realization of glottal events (cf.
Redi & Shattuck-Hufnagel 2001). In Figure 2 we see a full glottal stop on the word-initial
vowel in showed everyone. Figure 3 shows non-modal phonation over the first 40-50 ms
after the release of the stop on the initial vowel of the name Alice, taken from the sentence,
I’m afraid Alice will be late.
Figure 2 – Glottalized with full glottal stop; showed everyone

8
Figure 3 – Glottalized token without full glottal stop; afraid Alice
Three of the four authors of the present paper were involved in annotating the acoustic
data. With regard to the calculated voicing parameters, a one way ANOVA revealed no
significant differences in either V/C ratio (F[2,315] = 0.98; p=.379) or %Voiced (F[2, 315]
=2.17; p=.120) in the measures of the three annotators. Some inter-annotator differences were
found in the durational measures from which the voicing parameters were calculated,
including vowel duration (F[2, 315]=4.93; p=.009) and voicing duration (F[2,315] = 5.72;
p=.005), but not consonant duration (F[2,315] = 0.81; p=.449). In particular, one annotator’s
vowel duration and voicing duration measures were shorter than those of the other annotators.
Post-hoc Bonferroni tests revealed that one of three pairwise differences was significant for
vowel duration, and two of three were significant for voicing duration. Nevertheless, these
differences were not reflected in the calculated voicing parameters.
With regard to the coding of the initial vowels, the calibration analyses revealed a
high level of agreement in the case of tokens coded as liaised (unanimous agreement in
88.5% of cases; Fleiss’ Kappa = 0.72 for two categories, liaised vs. glottalized). In some
cases glottalization was visible on the vowel, but not immediately. These tokens appeared to
contain an intrusive vowel, in which a short vocoid is visible between the final consonant and
the glottal event. We interpret intrusive vowels as an attempt to produce a voiced obstruent
before a glottalized vowel (see Schwartz et al 2014). For the present analysis, all of these
were coded simply as ‘glottalized’ to avoid annotation discrepancies.
2.2.4 Results
The first set of results we will present shows glottalization/linking rates as a function of
learner group. The first year group produced glottalized vowels in just under 60% of the
tokens, and linked C#V sequences in just over 40% of the tokens. The advanced group
showed the opposite pattern, producing less glottalization (37.7%) and more linked C#V
sequences (62.3%). A binary logistic regression analysis with linking as the dependent
variable and learner group (Advanced) as a predictor variable showed a significant effect of
learner group (B=.889; p<.001). The linking/glottalization results are summarized graphically
in Figure 4.

9
Figure 4 – C#V context glottalization rates by learner group
The results for the voicing parameters as a function of learner group are shown in Figures 5
and 6. Figure 5 shows the mean values for %Voiced (47.7 for First Year, 81.0 for Advnced).
A one-way ANOVA revealed that this difference was significant (F[1,415]=149, p<.001).
Figure 5 - %voiced measure by learner group. Error bars denote 95% confidence interval
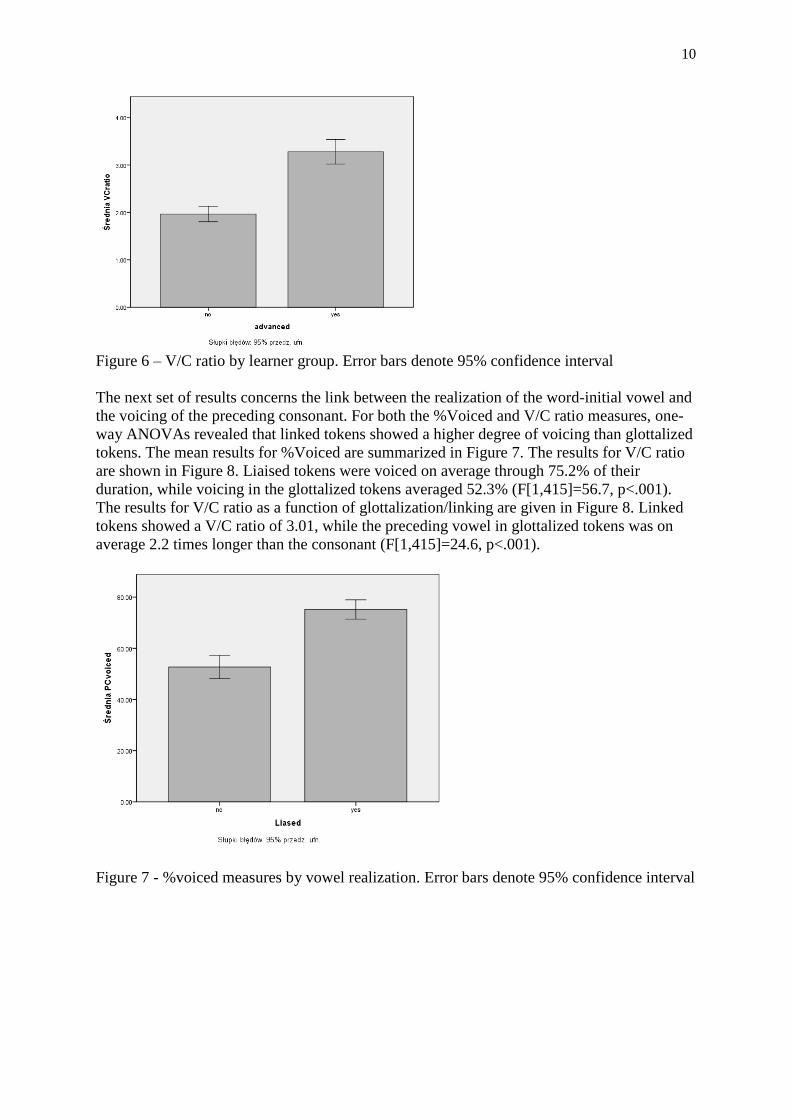
In Figure 6 we see the mean values for V/C duration as a function of learner group. The First
Year group had an average V/C ratio of 1.96, compared to 3.28 for the Advanced group
(F[1,415]=72.6, p<.001)
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
First Year Advanced
Linked C#V
Glottalized
10
Figure 6 – V/C ratio by learner group. Error bars denote 95% confidence interval
The next set of results concerns the link between the realization of the word-initial vowel and
the voicing of the preceding consonant. For both the %Voiced and V/C ratio measures, one-
way ANOVAs revealed that linked tokens showed a higher degree of voicing than glottalized
tokens. The mean results for %Voiced are summarized in Figure 7. The results for V/C ratio
are shown in Figure 8. Liaised tokens were voiced on average through 75.2% of their
duration, while voicing in the glottalized tokens averaged 52.3% (F[1,415]=56.7, p<.001).
The results for V/C ratio as a function of glottalization/linking are given in Figure 8. Linked
tokens showed a V/C ratio of 3.01, while the preceding vowel in glottalized tokens was on
average 2.2 times longer than the consonant (F[1,415]=24.6, p<.001).
Figure 7 - %voiced measures by vowel realization. Error bars denote 95% confidence interval

11
Figure 8 – V/C ration as a function of linking. Error bars denote 95% confidence interval.
Finally, we checked the extent to which Linking was correlated with voicing in the
productions of the individual participants. Spearman’s rho was calculated between the
percentage of linked items produced by each individual and each speaker’s mean values for
the voicing parameters. In both cases, the correlation coefficient was significant (ρ=.627,
p=.029 for V/C ratio; ρ=.666, p=.018 for %voiced).
2.2.5. Discussion
Our findings may be summarized as follows. In the production of both linking and final
obstruent voicing, Advanced learners produced more native-like tokens than the First Year
group. In an imitation task in which some degree of phonetic convergence is to be expected,
remaining differences between learner groups may be attributed to phonological factors.
Since both linking and final voicing revealed differences between groups, we suggest that
glottalization, which blocks linking, must be a form of phonological interference. We will
return to the phonological discussion in Sections 4 and 5.
A phonological interpretation is also suggested by the robust relationship between
linking and final voicing. The devoicing of final obstruents is a phonetically motivated
process. Linking in L1 English serves to alter the prosodic position of the voiced obstruent to
facilitate voicing. Since final devoicing is a notorious problem for Polish learners, we suggest
that learners who receive explicit instruction in C#V linking will be better equipped to
overcome problems with final voiced obstruents. A classroom-based study is underway to
test this prediction.
2.3. V#V production study
A related study was carried out with learners productions of V#V sequence. The participants
and data-gathering procedure were the same as in the C#V study described above, while the
stimulus materials are given in the appendix. The stimuli included 26 V#V sequences (see
Appendix 2). A total of 312 tokens were collected for analysis. As in the C#V study, an
imitation task was employed with an eye to controlling for effects of prosodic position and
other factors.
2.3.1. Acoustic analysis

12
In the vowel hiatus study, tokens were toked as either Modally voiced, suggesting linking of
the two vowels, or Glottalized. Again, we did not distinguish between full glottal stops and
glottalized tokens (see Schwartz et al. 2013 for a more detailed look at the realization of
glottalized tokens). Again, 3 of 4 authors were involved in the annotation of glottalization.
Calibration analyses revealed a high level of inter-annotator agreement (90.5%, Fleiss’ Kappa
= 0.78 for two categories, Modal vs. Glottalized).
2.3.2. Results
As with the C#V study, the first year group showed more glottalization than the advanced
group. A binary logistic regression analysis with Modal voice as the dependent variable and
Learner Group as the predictor variable revealed a significant effect of Learner Group on the
likelihood of linking; the Advanced group was more likely to produce linked tokens with a
modal voice quality (B=.784, p=.003). These results are shown graphically in Figure 9. The
advanced group produced linked vowels in 81% of the tokens, while the first year group
linked only 66% of the V#V tokens.
Figure 9 – V#V glottalization rates
2.3.3. Discussion
As in the case of the C#V study, the imitation task performed by the students did not
neutralize learner group differences in hiatus linking. More advanced students produced
more linking and less glottalization. One potentially significant observation, however, is that
the hiatus context appeared to be more conducive to linking than the C#V context. Overall,
74% of the hiatus tokens were produced without glottalization, while 51% of the C#V tokens
were linked. This may be attributable to the presence of word-internal vowel hiatus in Polish,
which is typically produced without glottalization. In addition, it is worth noting one aspect
of the differences between the C#V and V#V studies. In particular, the C#V data revealed a
close link between linking and the suppression of L1 final devoicing, which is an
‘established’ feature of a Polish accent in English. In the case of vowel hiatus, there is no
such connection with other segmental phenomena. Thus, the hiatus data raise questions about
the degree to which the failure to suppress glottalization in V#V sequences might contribute
to the perception of a foreign accent by L1 English listeners. At this point we take up this
question.
2.4. Hiatus linking and glottalization in foreign accent ratings
20
30
40
50
60
70
80
90
first year advanced
%Modal

13
The aim of this experiment was to assess the effect of vowel hiatus realization on the
perceived accentedness of non-native speech (cf. Derwing & Munro, 1997; Munro, 2008).
To explore the relationship between these variables, an on-line listening test was carried out.
2.4.1 Participants and stimuli
Forty-two native speakers of English participated in the foreign accent rating study. The
experimental stimuli were taken from recordings obtained in the production study. Each
stimulus consisted of utterances of between three and seven words. The total number of
tokens used was 36. Out of these, 12 pairs (i.e. 24 tokens) contained non-native utterances
with vowel hiatuses. That is, each member of the pair was the same utterance, but one was
produced with a modal realization of the hiatus, while the other had a glottalized realization. The tokens were checked by two professional pronunciation teachers for additional
segmental errors. Four glottalized tokens were judged to contain additional pronunciation
errors, while three tokens with modal realization were found to exhibit additional errors.
Appendix 3 provides a summary of the utterance pairs and errors identified. Aside from the
12 pairs, the stimuli contained six additional tokens of native English utterances taken from
target recordings used for the repetition task in the production study. Finally, six other non-
native tokens without vowel hiatus were used as distractors.
2.4.2 Procedure
The survey was built using Google Forms software and were additionally customized by
hand to include audio files and additional data validation. The surveys were made available
online and distributed using their URL addresses. Cooke et al. (2013) discuss the merits and
drawbacks associated with web-based speech perception studies. We feel that the merits
outweigh the drawbacks. One advantage is the highly voluntary nature of the participants.
Another advantage is the feasibility of recruiting a large number of L1 English listeners in a
non-English speaking country, particularly those who do not have everyday experience with
Polish-accented English. Nevertheless, we are in the process of attempting to replicate this
study in an on-site experiment. The survey consisted of two parts. The first part was comprised of a short linguistic
background questionnaire that was followed by the second part that included perception
tasks. Each perception task contained a recording and a question to answer, i.e. ‘Which of the
descriptions below best describes the speaker's pronunciation?’. The task was to answer the
question by choosing one of the five available options. Listeners rated the degree of non-
native accent in the utterances (5 – clearly native; 1 – clearly foreign). All descriptions and
instructions in both surveys were delivered in English. While completing the surveys listeners could not compare two recordings to each
other. Only one question could be viewed at a time and the participants could not continue to
the next question without first answering the current one. It was also impossible to return to a
previously answered question. The participants could only rely on their own impressions
when making perception judgments. In addition, each survey attempt was unique in the sense
that the order of all perception tasks was randomized when the survey was accessed. This
helped limit the effect of question order on the responses.
As mentioned above, the experiment was conducted via the internet. Consequently,
the participants completed the tasks remotely on their own computers. The survey was
distributed among the participants using the following URL address: http://goo.gl/Hsypq7

14
Participants were instructed to complete the survey only once and to use headphones to listen
to the stimuli in order to ensure sound fidelity. All participants were unaware of the purpose
of the experiment. When participants accessed the surveys they were first asked to provide information
about their linguistic background and then they moved on to the experiment proper that
consisted of 36 perception tasks. No indication of this division was given to the participants. When completing the surveys, the participants were presented with only one question at a
time. In each question, the participants were instructed to do the following: Click on a play button and listen to a short recording of an utterance. The recordings
could be replayed if needed.
Answer the question by choosing one of the five available options numbered 1–5. The
participants could not proceed without first answering the current question. No
feedback was presented for answering a question. Click on ‘next’ to continue to the next question.
The participants continued until they answered all the questions. At this point, the ‘submit’
button became active and the listeners could click on it to send their responses. A
confirmation screen concluded the experiment.
2.4.3 Data Analysis
A total of 1512 responses were obtained in the experiment (36 tokens * 42 listeners = 1512).
The responses to filler tokens without vowel hiatuses were excluded from the analysis. The
remaining responses were used to calculate the mean values of comprehensibility and
accentedness ratings for each participant. The means were then analyzed by taking into
account the following factors: Realization (whether the hiatuses in the utterance tokens were produced with a non-
native glottal or modal realization or were produced by a native speaker, i.e. had a
native modal realization)
Other errors (whether the stimuli contained other errors identified by pronunciation
teachers that could have influences the rating) The mean comprehensibility and accentedness rating values for all stimuli types (glottal vs.
modal vs. native) were calculated and compared using a repeated measures ANOVA to
determine the effect vowel of hiatus realization (glottalized vs. modal vs. native) on
perceived accentedness of L2 English speech. In addition, the same means and statistical
analyses were obtained for tokens with and without other pronunciation errors in order to
evaluate the effects of these errors on the listeners’ judgments.
2.4.4 Results
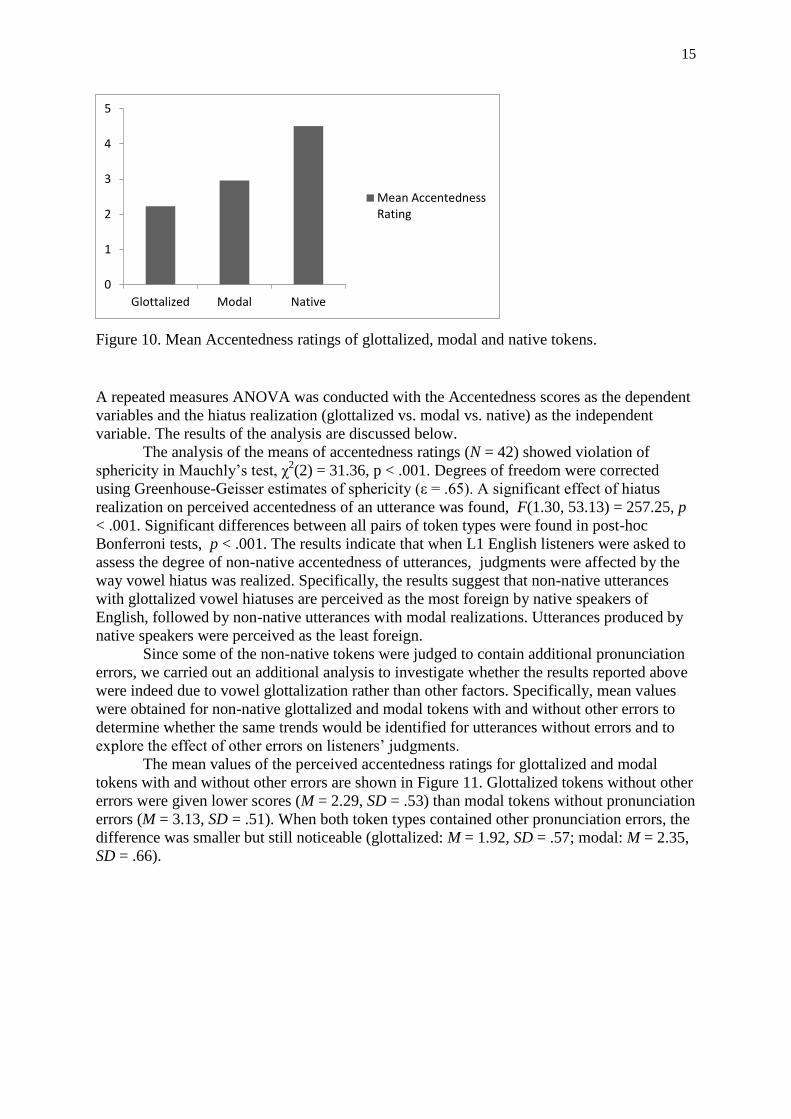
The mean values of the accentedness ratings for all three stimuli types are presented in Figure
10. For the mean values of the accentedness rating, the lowest score was found for
glottalized tokens (M = 2.23, SD = .47), followed by modal tokens (M = 2.96, SD = .52).
Tokens produced by native speakers obtained the highest scores for accentedness (M = 4.51,
SD = .56).
15
Figure 10. Mean Accentedness ratings of glottalized, modal and native tokens.
A repeated measures ANOVA was conducted with the Accentedness scores as the dependent
variables and the hiatus realization (glottalized vs. modal vs. native) as the independent
variable. The results of the analysis are discussed below.
The analysis of the means of accentedness ratings (N = 42) showed violation of
sphericity in Mauchly’s test, χ2(2) = 31.36, p < .001. Degrees of freedom were corrected
using Greenhouse-Geisser estimates of sphericity (ε = .65). A significant effect of hiatus
realization on perceived accentedness of an utterance was found, F(1.30, 53.13) = 257.25, p
< .001. Significant differences between all pairs of token types were found in post-hoc
Bonferroni tests, p < .001. The results indicate that when L1 English listeners were asked to
assess the degree of non-native accentedness of utterances, judgments were affected by the
way vowel hiatus was realized. Specifically, the results suggest that non-native utterances
with glottalized vowel hiatuses are perceived as the most foreign by native speakers of
English, followed by non-native utterances with modal realizations. Utterances produced by
native speakers were perceived as the least foreign. Since some of the non-native tokens were judged to contain additional pronunciation
errors, we carried out an additional analysis to investigate whether the results reported above
were indeed due to vowel glottalization rather than other factors. Specifically, mean values
were obtained for non-native glottalized and modal tokens with and without other errors to
determine whether the same trends would be identified for utterances without errors and to
explore the effect of other errors on listeners’ judgments. The mean values of the perceived accentedness ratings for glottalized and modal
tokens with and without other errors are shown in Figure 11. Glottalized tokens without other
errors were given lower scores (M = 2.29, SD = .53) than modal tokens without pronunciation
errors (M = 3.13, SD = .51). When both token types contained other pronunciation errors, the
difference was smaller but still noticeable (glottalized: M = 1.92, SD = .57; modal: M = 2.35,
SD = .66).
0
1
2
3
4
5
Glottalized Modal Native
Mean AccentednessRating

16
Figure 11.Mean ratings of accentedness for tokens with and without other segmental errors
The statistical analysis involved a paired-samples T-Test carried out for accentedness
with a number of within-subject conditions. The values for tokens without other
pronunciation errors were compared in order to confirm whether the same tendencies could
be attested as for all analyzed tokens. Significant differences between glottalized (M = 2.29,
SD = .53) and modal tokens (M = 3.13, SD = .50) were found, t(41) = 13.07, p < .001. These
results match the ones reported above, confirming that glottalized utterances were perceived
as more foreign accented by native speakers even when there were no other pronunciation
errors involved.The same analyses were conducted for tokens with other pronunciation
errors. Significant differences were found between glottalized (M = 1.92, SD = .57) and
modal tokens (M =2.35, SD = .66), t(41) = 4.00, p < .001. This implies that vowel
glottalization continued to play a crucial part in in increasing the foreign accentedness of
even in comparison to modal tokens containing other foreign accent features.
The effect of the glottalization of vowel hiatus on foreign accent perception is further
evidenced when the scores for tokens without other errors and for tokens with other
pronunciation errors are compared. A paired samples T-Test demonstrated that the difference
between mean accentedness scores for glottalized tokens without other errors (M = 2.29, SD
= .53) and modal tokens with errors (M =2.35, SD = .66) was non-significant, t(41) = -.62, p
> .05. These results indicate that the glottalization of vowel hiatus, even alone, was just as
indicative of a foreign accent as the segmental errors in modal tokens.
2.4.5 Discussion
With regard to accentedness ratings, our results point to a direct effect of hiatus glottalization.
Overall glottalized tokens were rated lower than modal tokens (2.23 vs 2.96). These
differences held in tokens both with and without other segmental errors. Interestingly, the
magnitude of this difference was greater in the case of the tokens without additional errors.
Such tokens may be claimed to have isolated the effects of the glottalized hiatus realization.
Finally, in the accentedness ratings, modal tokens with other errors were judged the same or
even slightly more native-like (2.35) than glottalized tokens without other errors (2.29). This
finding suggests that L1 English listeners are particularly sensitive to target-like boundary
realization in making accentedness judgments, and that boundary effects such as hiatus
linking are indeed an aspect of L1 English phonology.
2.5. Final remarks on word-initial vowels
0
0.5
1
1.5
2
2.5
3
3.5
with other errors without other errors
Glottalized
Modal

17
The results of the production studies and the accent rating test suggest that for Polish learners
of English, the suppression of glottalization in word-initial vowels represents an important
stage of phonological acquisition, facilitating the learning of target language sandhi linking
processes. In Section 4, we shall show how these facts fall out from aspects of phonological
representations within the Onset Prominence framework. Before proceeding to the
phonological discussion, however, we now turn to data from a seemingly unrelated
phenomenon: the realization of word-final stop consonants in C#C contexts.
3 Stop release and vowel quality in VC#C sequences
This section will summarize data from VC#C sequences in the speech of Polish learners of
English (for a related study, see Schwartz et al. 2014). In particular, we look at the link
between the production of plosive release and the production of the preceding vowel. The
basic hypothesis is that Polish learners learn to suppress release bursts in L2 English, a
process that goes hand in hand with the acquisition of robust VC formant transitions
suggestive phonetic cohesion.
3.1. Stop release in cross-language phonology
Although coda stop release is not a contrastive property, certain cross-language patterns
suggest that it is more than just a phonetic detail. Stated briefly, languages seem to adopt one
of three systems. Stop release may be (1) obligatory, (2) optional, or (3) always absent. Polish
exemplifies the first pattern (with the exception of homorganic CC sequences), English
follows the second pattern, while in Korean coda stops are always unreleased. Such
systematic differences suggest that coda stop release is phonological and subject to
parametric variation. Due to its non-contrastive status however, there has been only a small
amount of work on stop release in the literature on cross-language phonological interaction.
One important study is by Kang (2003), who looked at English loanword into Korean.
She showed that the probability of epenthetic vowels following English coda stops in
loanwords into Korean is strongly correlated with the probability of stop release in the speech
of L1 speakers. When the source language stops are more likely to be released, such as when
the stop is voiced, the Korean adaptations tended to appear with an epenthetic vowel and an
additional syllable (pad /pæ.tɨ/). By contrast, the adaptations of English words with a
voiceless stops, which are more likely to be unreleased, matched with the native Korean
pattern of suppressed stop release (pack /p k /). Clearly Korean listeners hear released
stops as containing a full ‘syllable’. In the context of L1 Polish speakers learning English,
previous studies by Bergier (2010) and Rojczyk et al. (2013) have studied the production of
L2 English unreleased stops. To our knowledge, only the Schwartz et al. (2014) study has
investigated the link between the suppression of stop release and the quality of the preceding
vowel.
3.2 Participants, procedure, and materials
Data were collected from 12 Polish learners of English, divided into two groups of six along
similar criteria to the initial vowel studies described in Section 2. Data were elicited by
presenting stimulus tokens on a Power Point slide. However, this study did not involve an
imitation task – participants read what was on the slide without audio input. The students had
one ‘practice’ round before they produced the tokens used in the analysis. The linguistic
material was made up of 18 VC#C sequences with equal distribution of the primary place of

18
articulation (labial, coronal, dorsal) in the first consonant. Care was taken to eliminate
homorganic consonant sequences, which constitute the only context in which stop release in
Polish may be suppressed (Dukiewicz & Sawicka 1995). The vowel in 12 of the tokens was
/æ/, while it was /ɪ/ in the other 6 tokens. A total of 216 tokens (12 speakers * 18 examples)
was collected for analysis.
3.3. Acoustic analysis
Acoustic analysis was performed by hand with the help of the Praat program (Boersma &
Weenink 2011) and focused on both the release of the post-vocalic stop consonant and the
VC formant transitions. With regard to stop release, tokens were tagged as either Yes or No,
on the basis of whether there was both a visual spike in the waveform as well as an audible
burst. With regard to the vowels in the VC sequences, the following acoustic measurements
were made.
Overall vowel duration (including pre-vocalic /r/ and /l/) in milliseconds
Duration of VC transition in milliseconds, from the end of the steady-portion of the vowel
to the onset of stop closure.
From these measurements, one additional measure of VC formant transitions was calculated,
%VC, defined as the transition duration divided by the vowel duration multiplied by 100.
That is, the measure defines the percentage of the vowel occupied by the VC transition.
3.4. Results
The first set of results shows the rate of stop release as a function of learner group. First year
students produced an audible release burst in 90.7% of the tokens, while the advanced
produced release bursts at a rate of 63.4%.
The next set of results looked at %VC as a function of stop release across learner
groups. A one way ANOVA revealed that the VC transition occupied on average 34.5% of
the vowel duration in unreleased tokens, while in the released tokens the mean %VC was
27.3% (p<.001). This is shown in Figure 12. Another one way ANOVA revealed that the
advanced group produced a slightly higher mean value for %VC (30.2%) than the first year
group (27.8%). This difference was significant (p=.027), and is illustrated in Figure 13.

19
Figure 12 - %VC as a function of stop release. Error bars denote 95% confidence interval
Figure 13 - %VC by learner group. Error bars denote 95% confidence interval.
To evaluate the role of learner group and %VC in determining the likelihood of stop release
production, a binary logistic regression analysis was performed with release as the dependent
variable and %VC and Learner Group as predictor variables. Both predictor variables turned
out to be significant (p<.001).
3.5 Discussion
The results of the stop release study may be summed up as follows. The likelihood of stop
release in VC#C sequences is linked to the %VC parameter, the percentage of the preceding
vowel occupied by the VC transitions. If more of the vowel taken up by the transition, the
the chances that the stop may be produced without a release burst. This pattern may be
understood in the context of Lindblom’s (1990) H&H theory of speech production, which

20
posits that speaker behavior is governed by a principle of ‘sufficient discriminability’. In
other words, speakers spend the minimal effort possible to produce a comprehensible
utterance. With more more robust VC transitions, listeners may identify the final stop without
a release burst, so speakers can spare the effort required to produce the burst. The acoustic
patterns associated with the %VC parameter suggest that in unreleased tokens, there is greater
phonetic coordination between the word-final consonant and the preceding vowel. Thus, the
fact that the Advanced group produced more unreleased stops, as well as more higher %VC
measures, suggests that the acquisition process involves the learning of this phonetic
coordination. In what follows, we shall investigate the phonological considerations that
underlie the empirical patterns we have observed.
4. Boundary formation in the Onset Prominence representational environment
In this section we will review the representations and mechanisms of the OP framework, in
order to derive the boundary effects we have observed in the speech of Polish learners of
English. We shall see that OP representations offer a perspective from which the formation of
prosodic boundaries may be linked to other segmental features such as vowel glottalization
and the behavior of coda stops. A mechanism of submersion in English allows for a unified
account of the seemingly unrelated phonetic properties we have examined, as well as the
acquisition patterns on the part of Polish learners.
4.1. Preliminaries
The Onset Prominence framework is a theory of phonological representation in which
segments and prosodic constituents (such as ‘syllables’) are constructed from the same
building block, a hierarchy of phonetic events shown in (1).
(1) The Onset Prominence representational hierarchy
Each node of the structure is derived from a phonetic event associated with a stop-vowel
sequence. The highest level node is associated with stop closure (Closure), this is followed by
burst/frication/aspiration noise after the stop release (Noise). The Noise node is followed by
the Vocalic Onset (VO) node, which derives from the initial portion of vowels in a CV
sequence. VO is followed by the Vocalic Target (VT) level. The tree in (1) represents a
unversal CV ‘syllable’ in which the C is a stop. The representational split between VO and
VT encodes the built-in ambiguity of CV transitions with regard to the consonant-vowel
distinction. While phonetically vocalic, the initial portion of vowels typically carries acoustic
information crucial for the identification of the preceding consonant. Thus, the VO node may
be contained in either consonant or vowel representations (see 4.2., and Schwartz 2013a).

21
The representations of individual segments are extracted from the hierarchy in (1). A
sample of these is given in (2). The segmental symbols act as shorthand for place and
laryngeal specifications, which are for the most part beyond the scope of this paper. Manner
of articulation is represented in the structural levels contained in a given segmental tree,
creating a partial scale of sonority and consonantal strength. Binary nodes are active in a
given segment’s representation, while unary nodes act as placeholders that define hierarchical
levels. Stops contain Closure, Noise, and parametrically VO. Nasals lack an aperiodic noise
element, so the Noise node is not active in /m/. Fricatives lack complete closure, so the
Closure node is not active in /f/. Approximants such as /w/ contain the Vocalic Onset node
(VO), but are missing the top two nodes associated with obstruents. Vowels are specified
under the Vocalic Target (VT) node. One item that should be noted at this time is that
terminal nodes of the structures that are not shown with melodic specifications are not
necessarily ‘empty’. Thus, in the structure of /p/, a labial specification that is assigned at the
Closure level, ‘trickles’ down the structure to occupy the Noise and VO nodes (see Schwartz
2014).
(2) Manner distinctions in the OP environment
By considering the relationship between the building block in (1) and the individual
segmental trees in (2), we can establish motivation for representational adjustments that
produce well-formed prosodic constituents. This may be thought of as follows. The tree in (1)
is a well-formed CV ‘syllable’ against which the well-formedness of individual segmental
structures in (2) is measured. In (3) we see a string of segmental structures /t/ and /a/. Neither
of these segments contain the entire four layer hierarchy, motivating a process of absorption,
by which the lower-level /a/ is merged with the higher level /t/ to its left, resulting in a well-
formed constituent /ta/.5 The /t/ lacks an active VT node, while the /a/ lacks the higher level
nodes. By absorbing the /a/ into the /t/, well-formed CV is produced.
(3) Absorption in a /ta/ sequence
5 Reversing the order of these segments would require either the submersion or promotion mechanisms that will
be discussed in due course.

22
The structures in (3) suggest a minimality requirement for well-formed structures, given in
(4).
(4) MINIMAL CONSTITUENT (MC) – A minimal prosodic constituent contains active (binary)
nodes both above and below the VT level
The MC requirement eliminates the need for constraints such as ONSET, PEAK, and *CODA
that impose requirements or restrictions on the segmental content of ‘syllables’. The
empirical generalizations that such constraints are intended to describe may be read directly
from OP representations. Additionally, the sharing of representational materials provides a
perspective from which a theory of boundary formation and representation may be
formulated. Prosodic domains are built from combinations of segmental trees, and boundaries
fall out naturally from the mechanisms involved. Parameters associated with these
mechanisms allow us to make predictions about where boundaries will arise.
4.2 Submersion in English yields sandhi linking and optional stop release
A single parametric mechanism, submersion, active in English and absent in Polish, may
account for the apparently diverse data observed in this paper. We shall start by illustrating
the most basic form of submersion involving ‘coda’ consonants, after which we shall
motivate submersion in vowel-initial words.
In (5), we see a string of segmental structures for the English word click. By
absorption, the vowel and the lateral /l/ are joined with the initial /k/ into a single structure.
Due to its high position in the representational hierarchy, the final /k/ may not undergo
absorption into the preceding constituent. In words of this shape, English licenses a process
of submersion, which places the final /k/ underneath the constituent built down from the
initial /k/, as is shown in the right-most structure.6
(5) Submersion of final /k/ in English click
Submersion of post-vocalic consonants is parametric. It is absent in Polish. In (14) we see
Polish klik ‘click’ on the left, alongside the English click with a submerged coda.
(6) Polish klik (left) and English click
6 For an analogous proposal by which coda consonants may reflect syllabic recursion, see van der Hulst (2010).

23
On the right, the final stop in English click is submerged under the preceding constituent. On
the left the final /k/ in Polish klik is not submerged, but is joined with preceding segments at a
higher level of structure that is not shown. From the representations in (6), it is predicted that
coda stops in Polish and English should behave differently, since they are structurally
distinct. The English coda is in a lower prosodic position in the OP hierarchy. Associating
lower hierarchical levels with prosodic weakness, we should expect the English coda to be
subject to lenition processes such as the repression of stop release. In addition, since the
submerged coda stops are joined into the same constituent structure as the preceding vowel in
English, the representations capture phonetic interaction between the vowel and consonant in
VC sequences. This was seen in our phonetic data in the %VC measure. The submersion
parameter has other implications for English and Polish phonology that are largely beyond
the scope of this paper. Submerged structures are associated with prosodic weight (absent in
Polish) and lenition in VCV contexts (absent in Polish). For discussion see Schwartz
(submitted). Now, we turn to the issue of linking of vowel-initial words.
Submersion is a mechanism that repairs structures that do not satisfy the MC
requirement by joining them with the preceding structure. In this connection, a key question
in determining sandhi application in English as opposed to Polish concerns the prosodic
status of word-initial vowels. That is, do word-initial vowels satisfy MC? We claim that this
another parametric decision. Word-initial vowels in Polish contain the VO node and satisfy
MC, word-initial vowels in English do not (see Schwartz 2013a). These parameters are
shown in (7). The tree on the left representing the Polish vowel, is a well-formed structure.
The tree on the right, representing the English vowel, is not. The result of these parameters is
that vowel-initial words in English are subject to sandhi linking processes while in Polish
they are not.
(7) VO parameters for vowels
Sandhi linking with initial vowels in English is due to submersion. Consider the English
phrase keep out. The /p/ is typically linked to the following vowel. This is represented by the

24
submersion of the structure for out, shown in (8). Since out does not contain active nodes
above the VT level, it does not meet the MC requirement. The sub-minimal out is therefore
submerged below the structure of keep, producing a well-formed constituent that we see on
the right. Analogous structures in Polish contain VO and are not subject to submersion.
(8) Submersion in keep out
Notice that the /p/ in keep has already undergone submersion, and is housed under the VT
level. If it had not, the /p/ would be built down from the Closure level, and the context for
absorption would be created. Absorption would mean that the final /p/ would become initial.
This, however, cannot be the case for English, since the /p/ in keep out is not aspirated – keep
out is clearly distinct from key pout. The linking that occurs in English is not the same
process as enchaînement or liaison that is found in French, which we would represent with
absorption. Thus, the /p/ in keep must already be submerged.
We have seen that submersion, a process absent in Polish, is responsible for sandhi-
linking in vowel-initial words in English. At this point we must consider more closely the
links between the OP representations and the phonetic data that we and others have observed.
The first issue to be discussed concerns the status and frequency of vowel glottalization, after
which we shall turn to the issue of linking in V#V sequences.
Although we have observed a tendency for more frequent and robust vowel
glottalization in Polish than in English, we should not expect an absolute opposition between
the two languages. That is, not all Polish initial vowels are glottalized, and some English
initial vowels are. In OP structures, glottalization may be represented as the activation of the
closure node, and the addition of some kind of specification denoting properties of non-modal
phonation. This is shown in (9). The tree on the left is a glottalized vowel of the type in
Polish containing VO, while on the right we see the a glottalized vowel without VO. Note
that both of these structures satisfy MC – they are both well-formed constituents. The
difference is that in Polish, glottalization fortifies a structure that is already well-formed. In
English, Closure activation repairs an ill-formed structure to denote higher-level constituent
edges. Thus, glottalization in the two languages has a different status that contributes to the
observed tendencies. In English it is a phrase-level phenomenon, while in Polish it may reach
further down into the realm of segmental representation. However, these differences do not
imply that the opposition between the two languages is absolute.
(9) Glottalization in VO-specified Polish vowel (left) and English vowel (right)

25
In the case of word-boundary vowel hiatus in English, OP representations offer a
useful perspective from which linking glides are distinct from lexical glides (cf. Levi 2008).
This is shown in (10). The two left-most structures show a sequence of two vowels in which
the second is subject to submersion. The second structure from the right contains the vowel
sequence, which may have produced the percept of a glide in previous descriptions. The
right-most structure contains a ‘lexical’ glide. English pronunciation textbooks have noted a
distinction between lexical and linking glides. Here that distinction is captured.
(10) Submersion in /ua/ sequence, as well as lexical /w/
Capturing the contrast between linking and lexical glides can aid phonological interpretation
of boundary phenomena. Consider Davidson & Erker (2014), who provide evidence against
‘glide insertion’ at hiatus sequences, showing that hiatus glides are distinct from lexical
glides. As an alternative, they suggest that glottalization is the preferred hiatus filler in
American English, as suggested by a relatively high glottalization rate (45%) in their data.
However, their glottalization rate may have been skewed by the fact that 18 of 24 of their
stimulus items contained stressed word-initial vowels. With the representations advocated
here, we do not need glottalization as an alternative to ‘glide insertion’. Non-glottalized
hiatus is captured, and is distinct from lexical glides. That is, we can argue against glide
insertion, as Davidson & Erker successfully do, without making the controversial claim that
glottalization is the preferred hiatus filler.
5 OP and similarity in L2 phonology
In our discussion so far, we have seen how the representations of the OP environment may
offer tools for predicting cross-language differences in boundary effects. At this point we turn
to the wider implications of the OP representational environment for the study of second

26
language speech. Our ultimate goal is to offer new perspectives on the oft-invoked principle
of similarity in L2 speech learning. As an introduction to this discussion, it is worth
considering the OP perspective on what is to our knowledge the only serious proposal
regarding interlanguage boundary effects: Cebrian’s (2000) Word Intergrity constraint.
5.1 Word Integrity vs. L1 interference.
Our studies have noted a significant degree of glottalization of word-initial vowels in the
speech Polish learners of English. We suggested that OP representational parameters may
account for these patterns. As an alternative to our representational hypothesis, the observed
glottalization in the speech of Polish learners of English may be claimed as evidence for a
more general Word Integrity constraint in the speech of L2 learners (Cebrian 2000). To
address this question, we will look at two previous studies of L2 learners by Cebrian (2000)
and Lleo & Vogel (2004). In both cases, there is evidence that learners suppress L1 processes
that weaken prosodic boundaries. However, it is not obvious that these results support the
proposed WI constraint. In the first case there is a simpler alternative explanation. In the
second case, learners’ failure to acquire a target language boundary strengthening process
casts doubt on the WI hypothesis (see Zsiga 2011 for additional doubts about the WI
proposal).
Cebrian’s proposal of Word Integrity was borne out of a discrepancy in the transfer of
L1 Catalan phonological processes into L2 English. Catalan is characterized by two processes
that neutralize laryngeal contrasts: final obstruent devoicing and voicing assimilation at word
boundaries. Examples are given in (11).
(11) Word-final devoicing and voicing assimilation in Catalan (Cebrian 2000)
vas ‘glass’
vazos ‘glasses’
vas petit ‘small glass’
vaz gran ‘big glass’
Final devoicing is a domain-internal process. Voicing assimilation is a sandhi process that
spans prosodic constituents. In the speech of Catalan learners of English, Cebrian found that
devoicing is widespread, but the assimilation process is not. It thus appears as though the
sandhi process is not a candidate for L1 interference, leading Cebrian (2000: 19) to claim the
existence of “an interlanguage prosodic constraint that treats every word as a separate unit
and prevents the synchronization of sounds belonging to different words”. On the face of it,
this would appear to be quite a strong claim. However, there is an alternative explanation for
Cebrian’s data.
The relatively low rates of transfer for voicing assimilation might reflect learners’
successful acquisition of short-lag VOT in the target language /b d g/, and the suppression of
the pre-voicing that is found in the L1 realizations of these stops. In other words, pre-voicing
facilitates regressive voicing assimilation, so the absence of this process suggests that
learners may have acquired the laryngeal qualities of the L2 stops, instead of transferring
their pre-voiced L1 stops. The final devoicing process remains however, since the acquisition
of VOT associated with the initial stops does not necessarily imply the acquisition of distinct
cues relevant for final stops. This is particularly true for English, in which final voiced
obstruents are often partially devoiced, yet remain distinct from the underlying voiceless
obstruents due to their duration relative to the preceding vowel (e.g. Port & Dalby 1982). In
short, the apparent discrepancy in transfer between L1 final devoicing and L1 voicing

27
assimilation may be attributable to the realization of laryngeal contrasts, and does not
necessitate any universal claims of Word Integrity.
In a study with more direct bearing on our work on initial glottalization, LLeo &
Vogel (2004) investigated the acquisition of L2 German by Spanish L1 speakers. Their
results were somewhat ambiguous with regard to the Word Integrity proposal. The focus of
their analysis included two phonological processes with implications for WI. One of these
was a sandhi spirantization process in L1 Spanish, by which word-initial voiced stops are
realized as fricatives between vowels. Another process they looked at was harter Einsatz or
‘glottal stop insertion’ on initial vowels in L2 German (e.g. Wiese 1996). Suppression of
spirantization accompanied by the acquisition of glottalization, both resulting in stronger
word-initial segments, would provide strong support for the WI hypothesis. Lleo & Vogel’s
analysis revealed conflicting results. The learners in their study managed for the most part to
suppress the spirantization process (around 80%), yet their acquisition of harter Einsatz was
less successful (under 50%). A universal WI constraint would predict that Spanish learners
should have little trouble acquiring harter Einsatz, which serves to enhance Word Integrity.
In accordance with the representational perspective advocated here, we postulate that
Word Integrity cannot be a uniform constraint that exerts equal force across all L1
backgrounds. Rather, we should expect differing degrees of Word Integrity as a function of
L1. The relative frequency of vowel glottalization in various L1s may therefore act as a
predictor of greater Word Integrity. To investigate this, we are engaged in a comparison of
L1 German and English speakers learning Polish as an L2. If English and German speakers
produce L2 Polish initial vowels with comparable rates of glottalization, we may conclude
that an L2 WI constraint may override the L1 English tendency for linking at word
boundaries.
In the present study, we looked at the vowel glottalization by Polish learners in L2
English, exploring the hypothesis that it is a form of L1 interference. Since the glottalization
of vowels has received only limited attention in the literature on L2 speech, it is worth
considering the phenomenon from the perspective of current models of second language
phonology. In this connection, we must consider the concept of cross-language similarity.
5.2 Vowel glottalization and cross-linguistic similarity
A comparison of the acquisition of harter Einsatz and the suppression of spirantization in
Lleo & Vogel’s study of Spanish learners of German may serve as an illustration of the
problematic concept of ‘similarity’ that is employed by current models of L2 speech. With
regard to both phonological and phonetic parameters, it is not obvious if either of these L2
phenomena is more similar to the corresponding structure in L1. Characterizing harter
Einsatz as ‘glottal stop insertion’, the appearance of a new segment, implies that this process
in L2 should be less similar to L1 than the suppression of spirantization. Under this view, the
former process produces a new segment [ʔ], while the latter simply adjusts the manner
specification of an existing segment. If [ʔu] is taken as a postional allophone of /u/, then the
two processes would have similar phonological status - both the glottalized vowel and the
unspirantized stop are variants of L1 phonemes appearing in a new prosodic context.
Alternatively, the relative infrequency of phonemic glottal stops across languages suggests
that the glottalized vowel should be more similar, since it involves the addition of a feature
that is non-contrastive in most languages. Thus, phonologically, one might argue for any of
three different interpretations with regard to the cross-language similarity of the two
processes.
In phonetic terms, it is equally difficult to gauge the relative similarity of the two
processes. Assuming equivalence in F1-F2 vowel space, a glottalized and non-glottalized

28
vowel should have similar formant frequencies, so they might be classified as similar. Yet the
voice source characteristics that distinguish them contribute to differences in perceived
loudness and have been identified as a cue to prominence in many languages (Sluijter & van
Heuven 1996; Kreimann & Gerratt 2010) and may be assumed to be perceptually robust.
Spirantization eliminates stop closure, an important acoustic landmark in the speech signal
(see Stevens 2002), yet stops produced with incomplete closure (e.g. Crystal & House 1988)
are typically perceived as stops, suggesting that listeners reconstruct the closure (cf. Ohala
1981). Thus, from the phonetic point of view, one could argue that either of the two target
language phenomena are more similar. In sum, defining similarity often requires weighing
the effects of conflicting phonetic and phonological parameters.
From the perspective afforded by the Onset Prominence framework, we gain new
tools for comparing segmental and prosodic representations across languages, and explicit
new parameters for the definition of similarity. Consider the trees in (12), which shows OP
representations for the German stop and glottalized vowel (first and third trees from the left),
alongside L1 Spanish representations of the spirantized stop (2nd
from the left) and the
unglottalized vowel (far right). The glottalized vowel (2nd
tree from the right) is represented
as a VO-specified vocalic structure with additional glottal specification an active Closure
node. The spirantized stop (2nd
tree from the left) is characterized by a deactivated (unary)
Closure node.
(12) German stop (left) vs Spanish spiranatized stop; German initial vowel vs. Spanish vowel
The structures in (12) suggest that harter Einsatz is less similar to the corresponding
L1 structure than the supression of spirantization. The dissimilarity is based on structural
differences among the pairs of corresponding sounds. For L1 speakers of Spanish, vowel
glottalization represents a more dramatic prosodic change, with two additional active layers
of structure, than the suppression of spirantization. Moreover, the structural change is
enhanced by an additional glottal specification on the VO node. By contrast, the structural
change involved in the repression of spirantization is less dramatic, involving only the
activation of the Closure node without any alteration to the underlying levels of the hierarchy.
Thus, the glottalized vowel is further from the L1 structure since its representational changes
entails both greater structural displacement and an additional melodic specification.
One of the hypotheses of Flege’s Speech Learning Model predicts that sounds that are
similar across languages may be subject to equivalence classification that prevents the
formation of a new perceptual category by L2 learners. Flege (1987) observed compromise
values in the speech of English-French bilinguals both in both vowel quality and VOT
parameters, which he attributed to equivalence classification. If harter Einsatz produces a
sound that is less similar to the corresponding L1 structure than the suppression of

29
spirantization, Lleo & Vogel’s results for Spanish learners of German would appear to be at
odds with the SLM. Our representations suggest that equivalence classification should be
more likely in the case of the non-spirantized stop, which is more similar to the L1 structure.
Consequently, the SLM might predict that L1 Spanish learners of German should have less
success in the suppression of spirantization. This is, of course, in opposition to Lleo &
Vogel’s findings.
An examination of the features that have been found to undergo equivalence
classification may point to a possible reconciliation of these apparently conflicting
predictions. Vowel quality, VOT, and the contrast between /l/ and /r/ constitute the phonetic
focus of a majority of the documented cases of equivalence classification. In the OP
environment, these properties differ crucially from spirantization and vowel glottalization
shown in (11) in that they are based solely on melodic specifications rather than structural
properties. Thus, we propose a modification to the SLM hypothesis by which equivalence
classification should impede the acquisition of melodically similar, rather than structurally
similar sounds. We suggest that parameters such as formant frequencies and VOT are by
nature more gradient than those associated with manner, and should be more likely to show
compromise values predicted by equivalence classification.7
5.3 Coda behavior and interlanguage epenthesis
In Section 3 we presented data on stop release in Polish English to suggest that the
acquisition of unreleased coda stops, as represented by submersion, is an integral part of the
learning process. The representations discussed in Section 4 provide a perspective from
which ‘coda’ consonants come in two varieties: submerged and non-submerged. Unreleased
coda stops are associated with submerged structures. Unsubmerged structures are always
released. These differences are represented prosodically in the OP environment, yet concern
the behavior of individual segments. That is, OP representations can describe the relationship
between segmental and prosodic representation in a way that traditional structures cannot. In
what follows, we shall examine the implications of this perspective, with particular attention
to Korean speakers’ treatment of coda consonants both in their L1 and in L2 English. First,
we shall consider perceptual epenthesis, by which Korean listeners hear vowels after English
coda stops (De Jong & Park 2012). We shall then consider Korean phonotactic constraints
with respect to contrast neutralization.
De Jong & Park (2012) studied perceptual epenthesis by Korean learners of English.
Their stated goal was to test the predictions of two explanations for epenthesis. According to
the first, which attributes epenthesis to ‘functional reparsing’, the process is motivated by the
need to license consonant manner and laryngeal contrasts in a new prosodic position.8 That is,
it serves to ease the task of identifying the consonant in question. In the other model, under
the heading of ‘perceptual misanalysis’, epenthesis is the reinterpretation of consonant release
as the ‘onset’ to an additional syllable, whose ‘nucleus’ is filled by an epenthetic vowel. De
7 Recent research has provided evidence that bidirectional phonetic drift attributable to equivalence
classification may be due to language context (Grosjean 1998). Antoniou et al. conducted two studies in which
they examined VOT values for early bilingual speakers of Greek and Australian English. The first experiment
(Antoniou et al 2010) was conducted in monolingual mode in the two languages, and monolingual-like
realization was observed in both. In a second experiment (Antoniou et al 2011), phonetic code switching was
induced by manipulating the alphabet used in the eliciting the stimulus, and L1 interference on L2 was observed,
but L1 was largely unaffected.
8 Since Korean features unreleased stops in which place is encoded in coda positions, it might be expected that
Korean listeners should be quite accurate at identifying the place of articulation of coda consonants.

30
Jong and Park note that authors who have argued for these models often claim that segment-
based and syllable-based explanations for epenthesis are incompatible. To test the two models De Jong & Park (2012) carried out a perceptual experiment in
which L1 Korean listeners engaged in two tasks with stimuli from American English: a
syllable counting task and a segment identification task. Their predictions with regard to the
aforementioned models were as follows. A negative relationship between segment
identification and syllable counting would provide support for the contrast-based model. That
is, more accurate segment identification comes at the cost of less accurate prosodic parsing,
since the additional syllable is claimed to aid in identification of the newly reparsed
consonant. No correlation between the two tasks would support the syllable-based model.
Finally, they posit that a positive relationship between the two tasks would support an
alternative model in which segmental identification and prosodic parsing are two aspects of
the same perceptual process. Their findings showed a positive correlation between syllable
counting and segmental features across individual subjects. Learners who were more accurate
in the syllable counting task (i.e. less likely to hear epenthetic vowels) tended to be more
accurate in identifying segmental features. Thus, it appears that neither of the two tested
models was supported. Rather, as they point out, ‘the present results suggest an overall model
. . . wherein listeners jointly interpret the details of segments and the syllabic position from an
integrated percept (De Jong & Park, 2012: 150)’.
The integrated percept proposed by De Jong & Park is captured in the Onset
Prominence representational environment, in which segmental and syllabic structures are
constructed from the same hierarchy. Crucially, manner of articulation is a prosodic
specification as well as a segmental feature. Instead of a segmental specification attaching to
prosodic structure by means of association lines, manner is prosodic structure. Thus, any
percept of manner is inevitably integrated with prosody, as De Jong & Park propose. It is also
worth noting that manner accuracy showed the most robust correlation with syllable counting
accuracy in De Jong & Park’s experiment (2012: 145, Figure 4).
Epenthesis in the adaptation of English codas into Korean has been classified as a case
of ‘unnecessary repair’ (Kang 2011), since L1 Korean does allow coda stops. However,
Korean codas are restricted in two important ways. First, the suppression of stop release is
obligatory. In addition, manner and laryngeal contrasts are neutralized. To provide some
perspective on Korean coda restrictions constraints, OP representations for the three Korean
labial stops are proposed in (9). Crucially, the framework allows for the possibility that
different melodic specifications may be housed at different levels of the OP hierarchy in
accordance with their phonetic realization. Place is specified as a [labial] annotation on the
Closure node. This is to be expected since it is the location of the closure that defines stop
place of articulation. By contrast, laryngeal features, whose phonetic realization may be
impeded by stop closure, may be assigned at lower levels. This is shown in (13). Aspiration,
which is of course associated with aperiodic noise, is shown as a [spread glottis] specification
on the Noise node. Tenseness is represented as a [constricted glottis] ([cg]) annotation on the
VO node. This feature is associated with a stiffer voice quality on the onset of the following
vowel (e.g. Ladefoged & Maddieson 1996), so the VO node is a natural structural position for
[cg] specifications. With these representations in mind, we may turn to the representation of
codas in Korean, which are characterized by the presence of place contrasts, but neutralized
manner and laryngeal contrasts.
(13) Proposed representations of Korean /p/, /pʰ/, and /p*/

31
In the OP environment, Korean codas may be attributed to submersion, producing the
structure in (14).
(14) Korean CVC sequence
To explain the fact that Korean maintains place contrasts in coda stops, but
neutralizes laryngeal constrasts, we need only propose a constraint against multiple layers of
submerged structure. That is, Korean, like many other languages, appears to restrict the size
of syllable rimes. The claim would be that Korean only allows a single node under the VT
level. The laryngeal specification loses its structural housing and is not realized in this
position. This is shown in (14) as the crossed-out labels of the lower Noise and VO nodes.
Thus, the apparent mismatch in Korean between a licensed place contrast and neutralized
laryngeal contrast may be explained as a single constraint on the size of prosodic
constituents.9 With the submerged Noise and VO nodes eliminated in (14), it also falls out
naturally that coda stops in Korean are always produced without an audible release. The only
remaining part of the stop is Closure; the lower nodes associated with stop release have been
eliminated.
Kang (2003) provides evidence that the presence of epenthesis in English loanwords
in Korean is closely related to the probability that the English coda stops are produced with
an audible release. Epenthesis is expected when the target language coda is more likely to
contain a release burst, which in Korean only occurs in syllable onsets. Thus, released stops
are adapted with an additional prosodic constituent whose prominence is enhanced by the
epenthetic vowel. In other words, when Korean listeners hear a release burst, the attribute it
to a non-submerged structure. Thus, from this perspective epenthesis is not at all an
‘unnecessary’, but is required to repair released consonants that are not followed by a vowel.
9 This restriction may capture the fact that coda fricatives are also realized as unreleased stops. Space
restrictions prevent us from explaining this in detail.

32
Polish requires stop release in codas, and as such does not submerge its codas. Thus,
epenthesis after coda stops is standard in the speech of Korean learners of Polish
(Dziubalska-Kołaczyk, p.c.). It is not subject to the same variability found in Korean English.
Kang attributes the link between epenthesis in Korean English and target language
stop release to ‘perceptual similarity’, arguing for the importance of a non-contrastive
phonetic detail, stop release, in the mechanism of loanword adaptation. From the OP
perspective, stop release, though non-contrastive, is not merely a phonetic detail. It is
predictable on the basis of phonological parameters. The lack of release is surely a systemic
element of Korean phonology; it should be representable in phonological terms. The OP
environment offers phonological tools for the representation of such non-contrastive
phenomena.
5 Conclusion
This paper has presented data on vowel-initial words and final stop consonants in the speech
of Polish learners of English. Although at first glance these phenomena seem to be unrelated,
the representations of the OP framework offer a unified explanation for the observed patterns.
In both areas, L2 acquisition involves learning submersion, a mechanism that facilitates the
phonetic coordination of neighboring segments, and allows for predictions with regard to
boundary formation in Polish and English.

33
References
Antoniou, M.,Best,C.T.,Tyler,M.D.,&Kroos,C. (2010). Language context elicits native-like
stop voicing in early bilinguals’ productions in both L1 and L2. Journal of Phonetics,
38, 640-653.
Antoniou, M.,Best,C.T.,Tyler,M.D.,&Kroos,C. (2011). Inter-language interference in VOT
production by L2-dominant bilinguals. Journal of Phonetics, 39, 558-570.
Best, C. T. (1995). A direct realist perspective on cross-language speech perception. In W.
Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language
research (pp. 171-204). Timonium, MD: York Press.
Best, C. T., & Tyler, M. D. (2007). Nonnative and second-language speech perception:
Commonalities and complementarities. In M. J. Munro & O.-S. Bohn (Eds), Second
language speech learning – the role of language experience in speech perception and
production (pp. 13-34). Amsterdam: John Benjamins.
Bissiri, M. P., Lecumberri, M. L., Cooke, M., & Volín, J. (2011). The role of word-initial
glottal stops in recognizing English words. Proceedings of Interspeech 2011. Florence,
Italy.
Boersma, P. & Weenink, D. (2011). Praat: doing phonetics by computer. [Computer
program].Version 5.2.18.
Britain, D. & S. Fox. (2008). Vernacular universals and the regularisation of hiatus
resolution. Essex Research Reports in Linguistics, 57, 1-42.
Cebrian, J. (2000). Transferability and productivity of L1 rules in Catalan-English
interlanguage. Studies in Second Language Acquisition, 22, 1-26.
Chen, M. (1970). Vowel length variation as a function of the voicing of the consonant
environment. Phonetica, 22, 129-159.
Cook, A. (2000). American Accent Training. Hauppauge, NY: Barron’s.
Crosswhite, K. (2003). Spectral tilt as a cue to word stress in Macedonian, Polish, and
Bulgarian. In Sole, M.J., D. Recasens & J. Romero (eds.). Proceedings of XVth
International Congress of Phonetic Sciences, Barcelona, 767-770.
Cruttenden, A. 2001. Gimson’s Pronunciation of English (6th
ed.). London: Arnold.
Crystal, T. & A.S. House. (1988). The duration of American English stop consonants: an
overview. Journal of Phonetics, 16, 285-294.
Davidson, Lisa & Daniel Erker (2014). Hiatus resolution in American English: the case
against glide insertion. Language 90 (2). 482-514.
Dejna, K. (1973). Dialekty Polskie [Polish dialects]. Krakow: Ossolineum.
Dogil, G. (1999). The phonetic manifestation of word stress in Polish, Lithuanian, Spanish,
and German. In H. van der Hulst (ed.), Word Prosodic Systems in the Languages of
Europe (pp. 273-311). New York: Mouton de Gruyter.
Downing, Laura. 1998. On the prosodic misalignment of onsetless syllables. Natural
Language & Linguistic Theory, 16, 1-52.
De Jong, K. & H. Park. (2012). Vowel epenthesis and segmental identity in Korean learners
of English. Studies in Second Language Acquisition, 34, 127-155.
Dilley, L., S. Shattuck-Hufnagel & M. Ostendorf. (1996). Glottalization of word-initial
vowels as a function of prosodic structure. Journal of Phonetics, 24, 423-444.
Dukiewicz, L. & I. Sawicka. (1995). Gramatyka współczesnego języka polskiego – fonetyka i
fonologia [Grammar of modern Polish – phonetics and phonology]. Krakow:
Wydawnictwo Instytutu Języka Polskiego PAN.
Escudero, P. & Boersma, P. (2004). Bridging the gap between L2 speech perception research
and phonological theory. Studies in Second Language Acquisition, 26, 551-585.

34
Flege, J.E. (1987). The production of ‘new’ and ‘similar’ phones in a foreign language:
evidence for the effect of equivalence classification. Journal of Phonetics, 15, 47-65.
Flege, J.E.(1995). Second language speech learning: Theory, findings, and problems. In
W.Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language
research (pp. 233–277). Baltimore: York Press.
Garellek, M. (2012). Word-initial glottalization and voice quality strengthening.
UCLA Working Papers in Phonetics, 111, 92-122.
Goldinger, S. (1997). Perception and production in an episodic lexicon. In Johnson, K.
Mullennix, J. W. (eds.). Talker Varioability in Speech Processing (pp. 33-66). San
Diego: Academic Press.
Goldinger, S. (1998). Echoes of echoes? An episodic theory of lexical access. Psychological
Review, 105 (2), 251-279.
Gussmann, E. (2007). The phonology of Polish. Oxford: Oxford University Press.
Hall, N. (2006). Cross-linguistic patterns of vowel intrusion. Phonology, 23, 387-429.
Harris, J. (1994). English Sound Structure. Oxford: Blackwell.
Howard, M. (2006). Variation in advanced French interlanguage: A comparison of three
(socio) linguistic variables. The Canadian Modern Language Review/La revue
canadienne des langues vivantes, 62 (3), 379-400.
Howard, M. (2008). 'On the role of naturalistic and classroom exposure in the acquisition of
socio-phonological variation: A longitudinal study of French liaison'. Journal of
Applied Linguistics, 5 (2), 159-179.
Johnson, K. (1997). Speech perception without speaker normalization: an exemplar model. In
K. Johnson & J. Mullennix, (Eds.). Talker variability in speech processing (pp. 145-
166). San Diego: Academic Press.
Kang, Y. (2003). Perceptual similarity in loanword adaptation: English post-vocalic word-
final stops to Korean. Phonology 20 (2): 219-273.
Kang, Y. (2011) Loanword phonology. In van Oostendorp, Marc, Colin Ewen, Elizabeth
Hume, and Keren Rice, eds., Companion to Phonology. Wiley-Blackwell.
Kreimann, J. & B. Gerratt. (2010). Perceptual sensitivity to first harmonic amplitude in the
voice source. Journal of the Acoustical Society of America, 128 (4), 2085-2089.
Lecumberri, M. & J. Maidment (2000). English transcription course. Oxford: Routledge.
Levi, S. (2008). Phonemic vs. derived glides. Lingua, 118,1956-1978.
Lindblom, B. 1990. Explaining phonetic variation: a sketch of the H&H theory. In W. J.
Hardcastle and A. Marchal (eds.) Speech Production and Speech Modelling. The
Netherlands: Kluwer Academic. 403-439.
LLeo, C. & I. Vogel. (2004). Learning new segments and reducing domains in German
L2 phonology: The role of the Prosodic Hierarchy. International Journal of
Bilingualism, 8, 79-104.
McCarthy, J. 1993. A case of surface constraint violation. Canadian Journal of Linguistics,
38.169-95.
Malisz, Z, M. Żygis & B. Pompino-Marschall. (2013). Rhythmic structure effects on
glottalisation: a study of different speech styles in Polish and German. Laboratory
Phonology, 4, 119-158.
Major, R. (2008). Transfer in second language phonology: a review. In: Hansen Edwards, J.
& M. Zampini. Phonology and Second Language Acquisition (pp. 63-94). Amsterdam:
John Benjamins.
Marlett, S. & J. Stemberger. (1983). Empty consonants in Seri. Linguistic Inquiry, 14, 617-
639.
Nespor, M. and I. Vogel (1986). Prosodic Phonology. Dordrecht: Foris.

35
Newlin-Łukowicz, L. (2012). Polish Stress: looking for phonetic evidence of a bidirectional
system. Phonology, 29(2), 271-329.
Ohala, J. (1981). The listener as a source of sound change. In: C. S. Masek, R. A. Hendrick,
& M. F. Miller (eds.), Papers from the Parasession on Language and Behavior
(pp.178-203). Chicago: Chicago Linguistic Society.
Pardo, J. S., Gibbons, R., Suppes, A. & Krauss, R. M. (2012). Phonetic convergence in
college roommates. Journal of Phonetics, 40, 190-197.
Plag, I., G. Kunter, & M. Schramm. (2011). Acoustic correlates of primary and secondary
stress in North American English. Journal of Phonetics,39, 362-374.
Port, R. & J. Dalby. (1982). C/V ratio as a cue for voicing in English. Journal of the
Acoustical Society of America, 69, 262-274.
Redi, L. & S. Shattuck-Hufnagel. (2001). Variation in the realization of glottalization in
normal speakers. Journal of Phonetics, 29, 407-429.
Rojczyk, A. (2012). Phonetic and phonological mode in second-language speech. VOT
imitation. Paper presented at EUROSLA 2012, Poznań, Poland, September 5-8 2012.
Rojczyk, A. (2013). Phonetic imitation of L2 vowels in a rapid shadowing task. In Lewis, J &
LeVelle, K. (eds). Proceedings of the 4th Pronunciation in Second Language Learning
and Teaching Conference (pp. 66-76). Ames, IA: Iowa State University.
Rojczyk, A., Porzuczek, A. & Bergier, M. (2013). Immediate and distracted imitation in
second-language speech: Unreleased plosives in English. Research in Language, 11, 3-
18.
Rubach, J. & G. Booij (1990b). Syllable structure assignment in Polish. Phonology 7. 121-
158.
Scheer, T. (2008). Why the Prosodic Hierarchy is a diacritic and why the Interface must be
Direct. In Hartmann, Jutta, Veronika Hegedus & Henk van Riemsdijk, (eds.). Sounds of
Silence: Empty Elements in Syntax and Phonology (pp. 145-192). Amsterdam: Elsevier.
Schwartz, G. (2010a). Auditory representations and the structures of GP 2.0. Acta Linguistica
Hungarica, 57, 381-397.
Schwartz, G. (2010b). Phonology in the signal – unifying cue and prosodic licensing. Poznań
Studies in Contemporary Linguistics, 46(4), 499-518.
Schwartz, G. (2012a). Glides and initial vowels within the Onset Prominence representational
environment. Poznań Studies in Contemporary Linguistics, 48 (4), 661-685.
Schwartz, G. (2012b). Initial glottalization and final devoicing in Polish English. Research in
Language, 10, 159-171.
Schwartz, G. (2013a). A representational parameter for onsetless syllables. Journal of
Linguistics, 49 (3), 613-646. DOI: http://dx.doi.org/10.1017/S0022226712000436.
Schwartz, G. (2013b). Vowel hiatus at Polish word boundaries – phonetic realization and
phonological implications. Poznań Studies in Contemporary Linguistics, 49 (4), 557-
585.
Schwartz, Geoffrey & Grzegorz Aperliński (2014). The phonology of CV transitions. In
Eugeniusz Cyran & Jolanta Szpyra-Kozłowska (eds.) Crossing phonetics-phonology
lines. Newcastle: Cambridge Scholars Publishing. 277-298.
Schwartz, Geoffrey, Anna Balas & Arkadiusz Rojczyk (2014a). Stop release in Polish
English – implications for prosodic constituency. Research in Language 12(2). 131-
144.
Schwartz, Geoffrey, Anna Balas & Arkadiusz Rojczyk (2014b). External sandhi in L2
segmental phonetics – final (de)voicing in Polish English. Concordia Working Papers
in Applied Linguistics 5. 637-649.
Shockley, K., Sabadini, L. & Fowler, C. A. (2004). Imitation in shadowing words. Perception
and Psychophysics, 66, 422-429.

36
Shoemaker, E. (2010). Nativelike Attainment in L2 Listening: The segmentation of spoken
French. In Dziubalska-Kołaczyk, K., M. Wrember & M. Kul (eds.) Proceedings of the
6th international symposium on second language speech, New Sounds 2010, Poznań,
Poland 1-3 May 2010. 433-438.
Sluijter, Agaath M.C. & Vincent J. van Heuven. 1996. Spectral balance as an acoustic
correlate of linguistic stress. Journal of the Acoustical Society of America, 100, 2471-
2485.
Steriade, Donca. 1993. Closure, release, and nasal contours. In M. K. Huffman and R. A.
Krakow (Eds.). Nasals, nasalization, and the velum (pp. 401−470). San Diego:
Academic Press.
Strycharczuk, P. (2012). Phonetics-phonology interactions in pre-sonorant voicing. Ph.D.
dissertation. University of Manchester.
Sturm, J. (2013). Liaison in L2 French: The effects of instruction. In. J. Levis & K. LeVelle
(Eds.). Proceedings of the 4th
Pronunciation in Second Language Learning and
Teaching Conference, Aug. 2013 (pp. 157-166). Ames, IA: Iowa State University.
Święciński, R. (2012). Acoustic aspects of palatalization in Polish and English – a study in
laboratory phonology. Ph.D. dissertation. Marie Curie-Skłodowska University, Lublin.
Uffmann, C. 2007. Intrusive [r] and optimal epenthetic consonants. Language Sciences, 29.
451-76.
Umeda, N. (1978). Occurrence of glottal stops in fluent speech. Journal of the Acoustical
Society of America, 64, 81-94.
Wells, J.C. (2008). Longman Pronunciation Dictionary (3rd
ed.). Harlow: Pearson Education
Limited Wiese, R. (1996). The phonology of German. Oxford: Clarendon Press.
Wright, R., S. Frisch & D. Pisoni. (1997). Speech Perception. Research on Spoken Language
Processing, Progress Report No. 21. Ms., Indiana University.
Wright, R. (2004). Perceptual cue robustness and phonotactic constraints. In Hayes, B., R.
Kirchner and D. Steriade (eds). Phonetically Based Phonology. Cambridge: Cambridge
University Press, 34-57.
Zsiga, E. (2003). Relearning consonant timing. Studies in Second Language Acquisition, 25,
399-432.
Zsiga, E. (2011). External sandhi in a second language: The phonetics and phonology of
obstruent nasalization in Korean and Korean-accented English. Language 87. 289 -
345.

37
Appendix 1 – Stimuli for C#V production experiment
They had evenings free
The child had red ears
They made everyone stay quiet.
There is a big dark cloud overhead.
I found out too late about the party.
The band bowed after playing the song.
Frank showed everyone his new pad.
Hard apples are my favorite.
The kids made excellent cookies.
Bill stayed after class to talk to the teacher.
I’m afraid Alice will be late.
The band played easy songs to dance to.
We paid everyone about two pounds.
I tried everything but I couldn’t make it work.
Brad even forgot the car keys
They should arrive around eight.
The judge ordered us to pay the fine
I’ve had easier tests than this one.
We stayed out all night
I tried out the new computer
She was all tired out after work
They earned equal amounts of money
Her friend Eve is very nice
I tried eel for the first time in a Japanese restaurant
Ted's apples are hard and sour
Rob avoids Alice’s uncle
Mary's earrings are made of aluminium
I bought five extra pounds of apricots
Peg's other sister likes to ride every day
George often sings after school
Fred's aunt is 80 years old
Jazz always was Adam’s favorite music
Today's express train was over three hours late
Fred always fills up his tank
Appendix 2 – stimuli for V#V production experiment
1-stay out 2-try out
3-see all 4-way out 5-go out 6-know everything
7-saw everything 8-be unable
9-know Alex 10-how interesting

38
11-know after 12-grow excellent 13-try each 14-they always 15-go every day
16-they actually 17-car always 18-your idea 19-the other 20-the end
21-they asked 22-be afraid
23-tell me all 24-I often 25-sure I 26-holiday activities
Appendix 3 – Stimuli for V#V listening test, with additional segmental errors identified by
pronunciation teachers
Utterance Errors in glottal token Errors in modal token
and they asked me – –
I go every day – –
his car always breaks
down – short VOT in /k/,
devoiced /z/ in his
and always
I’ll know after the exam vowel quality in
know –
I’m sure I heard a
telephone ringing – ng in ringing
I often imagine things vowel quality, ng –
I saw everything – –
see all the pictures unaspirated /p/ vowel quality in all
why did you stay out all
night – –
they actually like quality of /æ/ in
actually
–
they always have
something prepared – –
we’ll be unable to send – –




















