
Junos® OS Subscriber-Aware and Application-Aware Traffic ...

A space-aware bytecode verifier for Java Cards
Cinzia Bernardeschi, Giuseppe Lettieri, Luca Martini, Paolo MasciDipartimento di Ingegneria dell’Informazione, Universita di Pisa,
Via Diotisalvi 2, 56100 Pisa, Italy
Abstract
The bytecode verification is a key point of the security chainof the Java Plat-form. However, it is an optional feature in many embedded devices since the mem-ory requirements of the verification process are too high. Inthis paper we proposea verification algorithm that drastically reduces the memory use by performing theverification during multiple specialized passes. The algorithm reduces the spacefor types encoding by operating onto different abstractions of the domain of types.Experimental results are presented showing that this bytecode verification is pos-sible directly onto small memory systems.
Keywords: Embedded systems, data-flow analysis, type correctness
1 Introduction
The Java programming language was born in the early 90s as a response to the needof a flexible and highly reliable way for programming smart electronic devices. It iscurrently being used in a growing number of areas and, in the last years, it is alsoadvancing in the embedded system world. Among the embedded devices, Java Cardsrepresent an interesting research challenge since they have limited resources but requirehigh security features. Actually, a Java Card is a Smart Cardrunning a Java VirtualMachine (VM), the Java Card Virtual Machine (JCVM), and it isgoing to be used as asecure token in fields like banking and public administration.
The JCVM is at the core of the Java Card: it is a software CPU with a stack-based architecture which creates an execution environmentbetween the device andthe programs (Java Card Applets). The JCVM guarantees hardware-independence andenforces the security constraints of the sandbox model. In particular, the Java bytecodeVerifier is one of the key components of the sandbox model: theJava Card Applets arecompiled in a standardized compact code, the Java Card bytecode, and the Verifier isresponsible of checking the correctness of the code before the execution on the JCVM.
The Java bytecode Verifier performs a data-flow analysis on the bytecode, to ensurethe type correctness of the code. For example, it ensures that the program does not forgepointers, e.g. by using integers as they were object references.
Bytecode verification enablespost issuancedownload of Java Card Applets, evenif they are taken from sources different from the card vendor. Bytecode verification canbe performed off-card or on-card. However, because of the strong memory constraints
1

of the Java Cards, the bytecode verification is unfeasible, in its standard form, directlyon-card.
To perform verification on-card, many approaches have been proposed in the litera-ture: they modify the standard verification process so that its implementation becomessuitable for memory constrained devices. We review these proposals in Section 3.1.
In this paper, we propose and evaluate an alternative approach. It is based on theidea of checking the bytecode correctness with a progressive analysis which requiresmuch less memory than the standard one.
2 Standard bytecode verification
The result of the compilation of a Java program is a set ofclass files: a class file isgenerated by the Java Compiler for each class definition of the program. A Java Cardapplet is obtained by transforming the class files intocap filesin order to perform nameresolution and initial address linking [3]. In the following, we will refer to the classfiles only, since cap files and class files contain conceptually the same information.
A class file is composed of the declaration of the class and of aJVM Language(JVML) bytecode for each method of the class. The JVML instructions are typed: forexample,iload loads an integer onto the stack, whileaload loads a reference.
The Verifier performs a data-flow analysis of the code by abstractly executing theinstructions over types instead of actual values. A Java bytecode verification algorithmis presented in [8]: almost all existing bytecode Verifiers implement that algorithm.The verification process is performed method per method: when verifying a method,the other methods are assumed to be correct. Figure 1 shows the JVML instructions.For simplicity, we assume subroutines have a unique return address. We use the fol-lowing notation for the types:
BasicType = {int ,float , . . .};ReferenceType = ReferenceObject | ReferenceArray ;AddressType = ReferenceType | ReturnAddress;β ∈ BasicType ;τ ∈ {AddressType ∪ BasicType};τ ∈ {ReferenceType ∪ BasicType};[τ ∈ ReferenceArray ;C ∈ ClassType .
The types form a domain, where⊤ is the top element and⊥ is the bottom element.In this domain⊤ represents either the undefined type or an incorrect type.
The class typesC are related as specified by the class hierarchy. Figure 2 shows anexample of class hierarchy:E, F andG are user defined classes, withF andG extendingE. Not all types are shown.
Each method is denoted by an expression of the formC.m(τ1, . . . , τn) : τr, whereC is the class which methodm belongs to,τ1, . . . , τn are the argument types andτr
is the type of the return value. Each method is compiled into a(finite) sequence of
2

βop :β′ Takes two operands of typeβ from the stack, and pushes the resultof op ∈ { add, mul, cmpg... } (of typeβ′) onto the stack
βconst d Loads a constantd of typeβ onto the stackτload x Loads the value of typeτ contained in registerx onto the stackτstore x Takes a value of typeτ from the stack and stores it into registerxifcond L Takes a value of typeint from the stack, and jumps toL
if the value satisfiescond ∈ { eq, ge, ...}.goto L Jumps toLnew C Creates an instance of classC and puts a reference to the created
instance on top of the stacknewarray τ Creates an instance of an array of classτ and puts a reference
to the instance on top of the stackβaload Takes an array reference and an integer index from the stack.
The array reference is of type[β. Loads on the stack the referenceof typeβ saved at the index position in the referenced array.
βastore Takes an array reference, an integer index and a reference from thestack. The array reference is of type[β, the reference of typeβ.The reference is saved into the referenced array at the indexposition.
aaload Takes an array reference and an integer index from the stack.The array reference is of type[C. Loads on the stack the referenceof typeC saved at the index position in the referenced array.
aastore Takes an array reference, an integer index and a reference from thestack. The array reference is of type[C, the reference of typeC.The reference is saved into the referenced array at the indexposition.
getfield C.f :τ Takes an object reference of classC from the stack; fetches fieldf(of typeτ ) of the object and loads the field on top of the stack
putfield C.f :τ Takes a value of typeτ and an object referenceof classC from the stack; saves the value in the fieldf of the object
invoke C.m(τ1, . . . , τn) :τr Takes the valuesv1, . . . , vn (of typesτ1, . . . , τn) and an objectreference of classC from the stack. Invokes methodC.m of the referenced object with actual parametersv1, · · · , vn;places the method return value (of typeτr) on top of the stack
τreturn Takes the value of typeτ from the stack and terminates the method.jsr L Places on the stack the address of the successor and jumps to Lret x Jumps to the address specified in registerx
Figure 1: Instruction set
3

T
int double ...
return_address
F
Object
E
G
null
[Object
[H
T
BasicType AddressType ReferenceType
Figure 2: Some types and the subtyping relation.
bytecode instructionsB. We useB[i] to denote thei-th instruction in the sequence,with B[0] being the entry point.
Figure 3 shows the rules of the standard verification algorithm. Each rule has aprecondition, containing a set of constraints, and a postcondition, containing the tran-sition from the before to the after state of an instruction. For example, aniload xinstruction requires a non-full stack and theint type associated to registerx, and itseffect is to pushint onto the stack. We have usedλ to denote the empty stack and, forsimplicity, the rules show only the constraints on types.
The goal of the verification is to assign to each instructioni a mappingM i fromthe registers to the types, and a mappingsi from the elements in the stack to the types.These mappings represent the stateSti = (M i, si) in which the instructioni is ex-ecuted. A stateSti is computed as the least upper bound of all the interpreter statesQi = 〈i, M, s〉 obtained while applying the rules. The rules are applied within astandard fixpoint iteration which uses a worklist algorithm. Until the worklist is notempty, an instructionB[i] is taken from the worklist and the states at the successorprogram points are computed. If the computed state for a successor program pointjchanges (either the state atj has been not yet computed or the already computed statediffers), B[j] is added to the worklist. The fixpoint is reached when the worklist be-comes empty. Initially, the worklist contains only the firstinstruction of the bytecode.The initial types of stack and registers represent the stateon method entrance: the stackis empty and the type of the registers are set as specified by the method signature (theregisters not associated with the method’s arguments hold the undefined type⊤).
As a consequence of the algorithm, the state at a program point of the instructionsrepresenting a merge point between control paths (i.e. having more than one prede-cessor in the control flow graph) is theleast upper boundof the after state of all thepredecessors. If, for example, registerx has typeint on a path and type⊤ on another
4

opB[i] = βop : β′, v1 ⊑ β, v2 ⊑ β〈i, M, v1v2s〉 −→ 〈i + 1, M, β′s〉
constB[i] = τconst d
〈i, M, s〉 −→ 〈i + 1, M, τs〉
loadB[i] = τload x, M(x) ⊑ τ
〈i, M, s〉 −→ 〈i + 1, M, M(x)s〉
storeB[i] = τstore x, v ⊑ τ
〈i, M, vs〉 −→ 〈i + 1, M [x/v], s〉
aloadB[i] = τaload, v1 = [v′, v′ ⊑ τ, v2 ⊑ int
〈i, M, v1v2s〉 −→ 〈i + 1, M, v′s〉
astoreB[i] = τastore, v1 = [v′, v′ ⊑ τ, v2 ⊑ int , v3 ⊑ τ
〈i, M, v1v2v3s〉 −→ 〈i + 1, M, s〉
if ttB[i] = ifcond L, v ⊑ int
〈i, M, vs〉 −→ 〈L, M, s〉
ifffB[i] = ifcond L, v ⊑ int
〈i, M, vs〉 −→ 〈i + 1, M, s〉
gotoB[i] = goto L
〈i, M, s〉 −→ 〈L, M, s〉
newB[i] = new C
〈i, M, s〉 −→ 〈i + 1, M, Cs〉
newarrayB[i] = newarray τ, v ⊑ int
〈i, M, vs〉 −→ 〈i + 1, M, [τs〉
getfieldB[i] = getfield C.f :τ, v ⊑ C〈i, M, vs〉 −→ 〈i + 1, M, τs〉
putfieldB[i] = putfield C.f :τ, v1 ⊑ τ, v2 ⊑ C
〈i, M, v1v2s〉 −→ 〈i + 1, M, s〉
invokeB[i] = invoke C.m(τ1, . . . , τn) :τr, vj ⊑ τj (1 ≤ j ≤ n), v ⊑ C
〈i, M, v1 · · · vnvs〉 −→ 〈i + 1, M, τr〉
returnB[i] = τreturn v ⊑ τ, v ⊑ τr
〈i, M, v〉 −→ 〈−1, M, λ〉
jsrB[i] = jsr L
〈i, M, s〉 −→ 〈L, M, ras〉
retB[i] = ret x, M(x) ⊑ ReturnAddress
〈i, M, s〉 −→ 〈ra, M, s〉
Figure 3: The rules of the standard interpreter
5

path, the type ofx at the merge point is⊤. The least upper bound of stacks and mem-ories is done pointwise. The pointwise least upper bound between stacks requires thatthe stacks have the same height (otherwise there is a type error).
3 On-card bytecode verification
The verification algorithm is expensive both in computationtime and memory spacesince a data-flow analysis of the code is performed. The before state of each instructionmust be recorded during the analysis. As an optimization, Sun’s bytecode Verifiermaintains the state of each program point that is either the target of a branch or theentry point of an exception handler [7]. The set of states saved during the data-flowanalysis is calleddictionary.
The on-card bytecode verification is formally identical to astandard verification.However, special optimizations must be used since cards have limited resources. Com-mercial 2004 Java Cards typically provide 1-4KB of RAM, 32-64KB of persistentwritable memory and 128-256KB of ROM. Only the RAM should be used to storetemporary data structures since persistent memory is too slow and allows a limitednumber of writing cycles.
3.1 Related work
Many approaches have been presented to develop an on-card Verifier.Rose and Rose [11] propose a solution based on a certificationsystem (inspired
by the PCC, ‘Proof Carrying Code’ work by Necula [10]). The verification process issplit in two phases: lightweight bytecode certification (LBC) and lightweight bytecodeverification (LBV). The LBC is performed off-card and produces a certificate that mustbe distributed with the bytecode. The LBV is performed on-card, and it is a linearverification process that uses the certificate to assure thatthe bytecode is safe. TheLBV is currently used in the KVM of Sun’s Java 2 Micro Edition.
Leroy, in [6], proposes to reduce memory requirements with an off-card trans-formation of the code, also known as ‘code normalization’. The transformed codecomplies with the following constraints: every register contains the same type for allmethod instructions and the stack is empty at the merge points. The verification of a‘normalized’ code is not expensive: only one global state isrequired since the type ofthe registers do never change.
Deville and Grimaud [4] propose to use the persistent memoryfor storing the datastructures needed for the verification process. Their strategy holds as long as possibleall data structures in RAM, and swaps them in persistent memory when RAM space ismissing. A particular type of encoding is proposed since persistent memory cells havea limited numbers of writing cycles.
In [2], a verification algorithm which reduces the dictionary size by dynamicallyallocating its entries has been presented. The algorithm assigns a life-time to the dic-tionary entries, splits the methods code into control regions [5] and analyzes the regionsone-by-one. Each region is analyzed by applying the standard verification algorithm:the dictionary size is reduced since unnecessary entries are never held in memory.
6

0: iload_0 1: getstatic AA.h I 4: if_icmpne 13 7: getstatic AA.c [I 10: iconst_0 11: iaload 12: istore_1 13: getstatic AA.c [I 16: iconst_1 17: iaload 18: istore_1 19: iconst_1 20: ireturn
static int debit ( int aC )
{ 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 } { 0 0 }
( ) ( 0 )
( 0 0 ) ( )
( 1 ) ( 0 1 ) ( 0 ) ( )
( 1 ) ( 0 1 ) ( 0 ) ( )
( 0 )
array of int (registers) (stack)
{ 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 0 } { 1 1 } { 1 1 }
( ) ( 1 )
( 1 1 ) ( )
( 0 ) ( 1 0 ) ( 1 ) ( )
( 0 ) ( 1 0 ) ( 1 ) ( )
( 1 )
int (registers) (stack)
MULTIPASS DFA
{ int T } { int T } { int T } { int T } { int T } { int T } { int T } { int T } { int T } { int T } { int T }
{ int int } { int int }
( ) ( int )
( int int ) ( )
( [int ) ( int [int )
( int ) ( )
( [int ) ( int [int )
( int ) ( )
( int )
STANDARD DFA
(registers) (stack)
Figure 4: An example of standard data-flow and multipass data-flow.
4 Our approach
In this paper we present a space-aware bytecode verificationalgorithm which reducesthe size of the dictionary by performing a progressive analysis on different abstractionsof the domain of types.
4.1 The multipass concept
The multipass verification algorithm is the standard algorithm performed in many spe-cialized passes. Each pass is dedicated to a type. The dictionary size is reduced since,during each pass, the abstract interpreter needs to know only if the type (saved in a reg-ister or in a stack location) iscompatiblewith the pass or not. The type compatibilityis given by the types hierarchy. Actually, only one bit is needed to specify the type ofthe data saved in registers and stack locations.
The analysis is performed on the whole bytecode for every pass. The number ofpasses depends on the instructions contained in the method:one pass is needed foreach type used by the instructions. Additional passes are also needed to check theinitialization of objects (this concept will be expounded upon later in Section 4.4).
The multipass verification is possible since the bytecode instructions are typed andthe number of types is limited: basic types (int, byte, ...),reference types (the oneslisted in the constant pool) and return address type.
An example of data-flow analysis (dfa) performed with the standard approach andwith the multipass approach is proposed in Figure 4. We can notice the different en-coding strategies for the two approaches: during the standard dfa the types are fullyspecified. On the other hand, during each pass of the multipass dfa, a one bit encodingof the types is used.
7

4.2 The rules
We first formalize the operations performed by the standard Verifier.
Definition 1 (transition system) A transition systemL is a triple (Q,→, Q0), whereQ is a set of states,Q0 ∈ Q is the initial state, and−→⊆ Q × Q is the transitionrelation.
We say that there is a transition fromQ to Q′ if (Q, Q′) ∈−→, and we writeQ −→ Q′. We denote with
∗
−→ the reflexive and transitive closure of−→. We say thata stateQ ∈ Q is a final state of the transition system if and only if noQ′ exists suchthatQ −→ Q′ (we writeQ 6−→).
Let D be the set of types,V the set of registers,A the set of bytecode addresses,I the set of bytecode instructions,M : V → D the set of memories (M associates atype to every register) andS the set of finite sequences of elements ofD (S associatesa type to every element in the stack locations). An interpreter state is defined as atriple 〈i, M, s〉, wherei ∈ A, M ∈ M ands ∈ S. Given a methodm, we defineBm : A → I as the instruction sequence of the method. We assume that a latticeL = (D,⊑) of types is defined (it is shown in Figure 2). The⊑ relation is extendedpointwise to the setsM, S. The rules shown in Figure 3 define a relation−→⊆ Q×Q.
Given a methodC.m(τ1, . . . , τn) : τr, which contains a bytecode sequenceB, wedefine the initial memoryM0 ∈ M such thatM0(0) = C, M0(i) = τi if 1 ≤ i ≤ nandM0(i) = ⊤ otherwise (M0 assigns types to the registers according to the methodparameters). We define by(Q,−→, 〈0, M0, λ〉) the transition system defined by therules in Figure 3, starting from the initial state〈0, M0, λ〉.
This transition system is an abstract interpretation of theexecution of the bytecode.The Verifier implicitly uses this abstract interpretation to associate a state with eachinstruction of the bytecode. During the data-flow analysis,the state associated to in-struction at offseti is Sti = (M i, si), where(M i, si) is the least upper bounds ofmemories and stacks of all the interpreter states〈i, M, s〉 that appear in the transitionsystem.
The standard Verifier gives an error if, starting from state〈0, M0, λ〉, produces astate〈i, M, s〉 where it can make no further transition, andi 6= −1. Formally, wewrite: 〈0, M0, λ〉 6
∗
−→We are now going to give a formal description of the multipassalgorithm.For each pass typep ∈ D, we define a latticeLp = (Dp,⊑p), whereDp =
{⊤p,⊥p} and⊥p ⊑p ⊤p. We define also the functionαp : D → Dp as:
αp(t) =
{⊥p if t ⊑ p⊤p otherwise
which means that the abstraction of a typet is ⊥p if and only if t is assignment com-patible with the typep of the pass.
For example, ift ∈ C, the abstraction function for class typeE (refer to the latticein Figure 2) is the following:
αE(t) =
{⊥E if t ∈ {F,G, null}⊤E otherwise
8

The functionαp is extended pointwise to the setsM andS. For each typep ∈ D,we define a transition system (Qp,−→p, 〈0, M0
p , λ〉), whereQp = 〈i, Mp, sp〉 ∈Qp, Mp ∈ Mp : V → Dp, sp ∈ Sp.
Each transition relation−→p of the multipass is obtained by the correspondingstandard transition relation (defined in Figure3) by simply applying theαp function tothe types and by changing each⊑ with ⊑p. The multipass rules are shown in Figure 5.In the following we are going to explain some of the rules.
Let us consider aβop : β′ instruction: iadd. In this caseβ = int andβ′ =int . The constraints to be checked arev1 ⊑p αp(int) and v2 ⊑p αp(int). No-tice that the constraints may fail only during theint pass, sinceαp(int) = ⊥int ifand only if p = int . If the top and next-to-top positions of the stack contain validtypes (i.e.⊥int ) then the rule is successfully applied and the transition isperformed:〈i, Mint , ⊥int⊥ints〉 −→int 〈i + 1, Mint , ⊥ints〉. For theiadd instruction, if thepass is different fromint, the αp function returns⊤int , thus the constraints are al-ways satisfied and the transition is performed consequently. Notice also that, when thepassp is different fromint, theiadd instruction always places⊤p on the stack, sinceαp(int) = ⊤p if p 6= int . Let us suppose now that there is a type error in the bytecode.Theiadd instruction, for example, may have found a type different from int on thestack top: the before state would have been〈i, Mint , ⊤int⊥ints〉. The multipass rulefinds the type error in the passp = int , since the constraintv1 ⊑p αp(int) is notsatisfied.
Let us consider aτloadx instruction:aload. In this caseτ = ReferenceType.As a consequence, the constraint in the rule isM(x) ⊑p αp(ReferenceType). Theconstraint may fail only during theReferenceType pass, sinceαp(ReferenceType) =⊥p if and only if ReferenceType ⊑ p. If the constraint fails then the abstraction of thetype found in registerx was not compatible with a reference type.
Notice that theaload and theastore instructions have asymmetric behaviorssince theaload does not work on theReturnAddresstype (different prefixes have beenused in the rules for this two instructions). Theβop, τconst, ifcond, newarray,τload and τstore instructions are always checked during one pass. The other in-structions may require operands of different types, thus their constraints are possiblychecked in more that one pass.
4.2.1 Theaaload instruction
Theaaload instruction needs some additional explanations. The instruction loadsonto the stack the elements contained in array of references: it takes from the stack anindex and an array reference, and pushes a reference to the array element on the stack.For instance if, during the verification process, the type ofthe array reference is[A,then the type placed on the stack by theaaload is A.
During the standard verification, the return type is inferred by examining the typeof the array reference on the stack; during the multipass verification, on the other hand,the type is inferred by the pass type. Since the type returnedby theaaload is dif-ferent from the one of the operands, the multipass Verifier checks the returned type ina different pass. In particular, the returned type of theaaload can be checked onlyduring theReferenceTypepass since the type is computed by inspecting the instruction
9

opp
B[i] = βop :β′, v1 ⊑p αp(β), v2 ⊑p αp(β)〈i, M, v1v2s〉 −→p 〈i + 1, M, αp(β
′)s〉
constpB[i] = τconst d
〈i, M, s〉 −→p 〈i + 1, M, τs〉
loadp
B[i] = τload x, M(x) ⊑p αp(τ)〈i, M, s〉 −→p 〈i + 1, M, M(x)s〉
storep
B[i] = τstore x, v ⊑p αp(τ)〈i, M, vs〉 −→p 〈i + 1, M [x/v], s〉
aloadp
B[i] = τaload, v1 ⊑p αp([τ), v2 ⊑p αp(int)〈i, M, v1v2s〉 −→p 〈i + 1, M, αp(τ)s〉
astorep
B[i] = τastore, v1 ⊑p αp([τ), v2 ⊑p αp(int), v3 ⊑p αp(τ)〈i, M, v1v2v3s〉 −→p 〈i + 1, M, s〉
ifptt
B[i] = ifcond L, v ⊑p αp(int)〈i, M, vs〉 −→p 〈L, M, s〉
ifpff
B[i] = ifcond L, v ⊑p αp(int)〈i, M, vs〉 −→p 〈i + 1, M, s〉
gotop
B[i] = goto L〈i, M, s〉 −→p 〈L, M, s〉
newp
B[i] = new C〈i, M, s〉 −→p 〈i + 1, M, αp(C)s〉
newarrayp
B[i] = newarray τ, v ⊑p αp(int)〈i, M, vs〉 −→p 〈i + 1, M, αp([τ)s〉
getfieldp
B[i] = getfield C.f :τ, v ⊑p αp(C)〈i, M, vs〉 −→p 〈i + 1, M, αp(τ)s〉
putfieldp
B[i] = putfield C.f :τ, v1 ⊑p αp(τ), v2 ⊑p αp(C)〈i, M, v1v2s〉 −→p 〈i + 1, M, s〉
invokep
B[i] = invoke C.m(τ1, . . . , τn) :τr , vj ⊑p αp(τj) (1 ≤ j ≤ n), v ⊑p αp(C)〈i, M, v1 · · · vnvs〉 −→p 〈i + 1, M, αp(τr)〉
return p
B[i] = τreturn, v ⊑p αp(τ), v ⊑p αp(τr)〈i, M, v〉 −→p 〈−1, M, λ〉
jsrp
B[i] = jsr L〈i, M, s〉 −→p 〈L, M, αp(M(x))s〉
retpB[i] = ret x, M(x) ⊑ αp(ReturnAddress)
〈i, M, s〉 −→p 〈ra, M, s〉
Figure 5: The rules of the multipass interpreter
10

prefix only: theaaload instruction embeds no detailed information about the classofthe array of references it is going to work with.
The rule of the standard Verifier places a value of typeC on the stack, the multipassinterpreter placesαp(ReferenceType). The standard interpreter can compute the classC since the array reference on the stack is of type[C. The correct type in the multipassshould have beenαp(C), but it cannot be computed with the types stored in the stackof the multipass.
This loss of precision possibly causes the refuse of type-correct bytecodes. Nev-ertheless, we can notice that arrays of references are actually never used in Java Cardapplets. Anyway, the loss of precision can be solved, for example, by specializing theanalysis for each array of reference type, and by using a two-bits type encoding in orderto analyze the array references and the array elements in thesame pass.
4.3 The correctness
We now prove that bytecodes rejected by the standard Verifierare also rejected by themultipass Verifier. We use the following definitions and lemmas.Givenp ∈ D, we define a binary relationsafep ∈ Q×Qp as:
Q safep Qp iff αp(Q) ⊑p Qp
which means thatQ is safely approximated byQp if and only if αp(Q) ⊑p Qp (i.e.αp(M) ⊑p Mp andαp(s) ⊑p sp). We naturally extend thesafep relation to transitionsystems.
The following Lemma states that∀p, αp is an homomorphism:
Lemma 1 (homomorphism) Given a stateQ = 〈i, M, s〉,
if Q −→ Q′ then ∀p ∈ D, ∃Q′
p such thatαp(Q) −→p Q′
p andαp(Q′) ⊑p Q′
p
Proof sketch. By cases on the rules of Figure 3
Notice that whenαp(Q′) <p Q′
p the abstraction loses precision [12].
Lemma 2 (monotonicity) Givenp ∈ D and two statesQ1
p = 〈i, M1
p , s1
p〉 and
Q2
p = 〈i, M1
p , s2
p〉 such thatQ1
p ⊑ Q2
p, if ( Q1
p −→p Q1′
p and Q2
p −→p Q2′
p ) then
Q1′
p ⊑ Q2′
p .
Proof sketch. By cases on the rules of Figure 5
The homomorphism and the monotonicity properties guarantee that the standard tran-sition system is safely approximated by the multipass transition system obtained withtheαp function [12].
Lemma 3 ∀p ∈ D, (Q,−→, 〈i, M0, λ〉) safep (Qp,−→p, 〈i, αp(M0), λ〉).
11

Proof sketch. By Lemma 1 and Lemma 2
The following Lemma defines a property of theαp function.
Lemma 4 Givenv1, v2 ∈ D, if v1 6⊑ v2 ⇒ ∃p : αp(v1) 6⊑p αp(v2).
Proof. Choosep = v2. It is αv2(v1) 6⊑ αv2
(v2) by definition ofαp since, ifv1 6⊑ v2,thenαv2
(v1) = ⊤v26⊑v2
⊥v2= αv2
(v2)
The following theorem states that if the standard Verifier gives an error, then∃psuch that−→p gets stuck.
Theorem 1 〈0, M0, λ〉 6∗
→⇒ ∃p : 〈0, αp(M0), λ〉 6
∗
−→p.
Proof sketch. Given that〈0, M0, λ〉 6∗
→, there exists a final stateQ = 〈i, M, s〉, withi 6= −1; from Lemma 3, we know that, for eachp, there existsQp = 〈i, Mp, sp〉such thatQ safepQp. Then, for each possible final stateQ, we have to show thatthere existsp such thatQp is also final. The proof proceeds by cases:B[i] must beone of the instructions enumerated in the rules of Figure 3. Only one rule (two if theinstruction is anif) could be applied to make a transition fromQ. SinceQ is final, thecorresponding rule cannot be applied : this means that either the preconditions are notmet, or the form of the before state in the transition does notmatchQ. The followingreasoning must be repeated for each rule. It is easy to show that, if Q does not matchthe before state of the transition, the form ofQp does not match in the correspondingmultipass rule, soQp is final (for everyp). If a precondition is not met, we note thatall the preconditions, in Figure 3, are of the formv 6⊑ v′, with v taken from the beforestate (in a register or on the stack) andv′ fixed by the instruction. The correspondingconstraint in Figure 5 becomesv 6⊑p αp(v
′), wherev is taken from the correspondingposition in the (abstract) before state. From the definitionof the safep relation, weknow that, for eachp, αp(v) 6⊑p v and, by Lemma 4, we know that∃p such thatv 6⊑ v′ ⇒ αp(v) 6⊑p αp(v
′). Thus, we must havev 6⊑p αp(v′). This implies that
stateQp does not meet a precondition in the (only) rule that could be used to make atransition, so it is a final state.
4.4 Checking objects initialization
The creation of a new object is a single statement in the Java programming language:the statement provides object allocation and initialization. In the bytecode, otherwise,the object initialization must be checked since the objectsare created during two dis-tinct phases. The first phase is the allocation of the space inthe heap, the second is theobject initialization. In particular, thenew instruction allocates the space, and the callto the appropriate constructor<init> performs the object initialization. The Verifierchecks that the objects are not initialized twice and that they are not used before theyhave been initialized [9].
Notice that references to multiple not-yet-initialized objects may be present in stacklocations and in registers: the constructor must know, whenit is called during theverification process, which references point to which object in order to initialize them
12

correctly. The standard verification algorithm uses aspecialtype to keep trace of theuninitialized objects [9]. The special type contains the bytecode position of thenewinstruction that creates the object instance.
The multipass analysis requires an additional pass for eachclass type: uninitializedobjects of a given class are traced within a pass. A data structure that holds infor-mation about the instance of uninitialized objects is also needed. It should be notedthat uninitialized objects must not be present in stack locations and in registers when abackwards branch is taken [9]. This last constraint simplifies the data structure neededduring the multipass: its size is constant and the object initialization can be resolvedwith a FIFO strategy.
5 Experimental Results
A prototype tools has been developed by using the open-source BCEL/JustIce package[1]. BCEL (ByteCode Engineering Library) is a set of APIs that provides an object-oriented view of binary class files. JustIce is a bytecode Verifier. The prototype is amodified version of JustIce: the main modifications have beenmade to specialize thedata-flow engine for the multipass process. It is available at http://www.ing.unipi.it/o1833499.
The prototype has been tested with a large number of methods.In the followingwe are presenting the statistics for five applications: 1) Azureus, an open-source peer-to-peer application: it contains a large number of network and identification methods;2) JGraphT, an open-source mathematical library; 3) Jasper, a class file disassembler;4) the Java Card Runtime Environment; 5) the Pacap prototype, an Electronic Purseapplication.
The statistics include the number of targets and the dictionary size for the standardand for the multipass verification. As expected, the dictionary size of the multipassverification is over than ten times smaller with respect to the dictionary size of thestandard verification. All the space gained is due to the encoding of the types: 1 bit forthe multipass, 3 bytes for the standard.
Figure 6 reports the dictionary size during the verificationprocess of methods be-longing to the examined packages (the space overhead for thedictionary indexing isnot taken into account). The dictionary size is computed asT × (H + N) × E, whereT is the number of targets,H andN are the maximum stack height and maximumregister number,E is the number of bytes needed to encode the types. As we can see,the standard verification of some methods requires more than2KB of RAM and, forcomplex methods, 4KB of RAM is not even enough. The multipassverification, on theother hand, comfortably fits in 1KB of RAM for all the examinedmethods. Moreover,it should be noted that the dictionary usually contains manyduplicated states when thenumber of targets is very large: the one bit encoding of the types reduces the numberof possible states thus, in some cases, the dictionary size can be optimized further byavoiding states duplication [2].
Some considerations on the time needed to perform a completemultipass verifica-tion can be made. We have analyzed the number of passes, needed for each method, toperform a complete multipass verification: it depends on theinstructions contained in
13
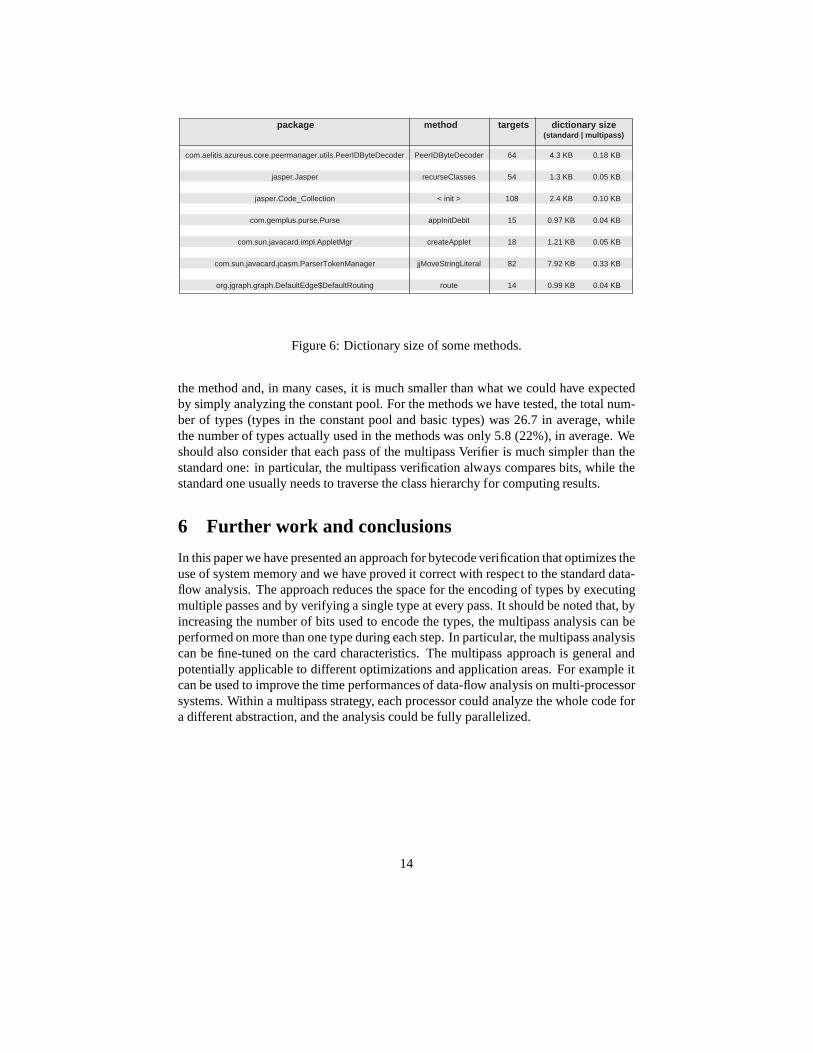
package method targets dictionary size (standard | multipass)
com.aelitis.azureus.core.peermanager.utils.PeerIDByteDecoder
jasper.Jasper
jasper.Code_Collection
com.gemplus.purse.Purse
com.sun.javacard.impl.AppletMgr
com.sun.javacard.jcasm.ParserTokenManager
org.jgraph.graph.DefaultEdge$DefaultRouting
PeerIDByteDecoder
recurseClasses
< init >
appInitDebit
createApplet
jjMoveStringLiteral
route
64
54
108
15
18
82
14
4.3 KB
1.3 KB
2.4 KB
0.97 KB
1.21 KB
7.92 KB
0.99 KB
0.18 KB
0.05 KB
0.10 KB
0.04 KB
0.05 KB
0.33 KB
0.04 KB
Figure 6: Dictionary size of some methods.
the method and, in many cases, it is much smaller than what we could have expectedby simply analyzing the constant pool. For the methods we have tested, the total num-ber of types (types in the constant pool and basic types) was 26.7 in average, whilethe number of types actually used in the methods was only 5.8 (22%), in average. Weshould also consider that each pass of the multipass Verifieris much simpler than thestandard one: in particular, the multipass verification always compares bits, while thestandard one usually needs to traverse the class hierarchy for computing results.
6 Further work and conclusions
In this paper we have presented an approach for bytecode verification that optimizes theuse of system memory and we have proved it correct with respect to the standard data-flow analysis. The approach reduces the space for the encoding of types by executingmultiple passes and by verifying a single type at every pass.It should be noted that, byincreasing the number of bits used to encode the types, the multipass analysis can beperformed on more than one type during each step. In particular, the multipass analysiscan be fine-tuned on the card characteristics. The multipassapproach is general andpotentially applicable to different optimizations and application areas. For example itcan be used to improve the time performances of data-flow analysis on multi-processorsystems. Within a multipass strategy, each processor couldanalyze the whole code fora different abstraction, and the analysis could be fully parallelized.
14

References
[1] Apache Foundation. ByteCode Engineering Library (BCEL) user manual,http://jakarta.apache.org/bcel/index.html, 2002.
[2] C. Bernardeschi, L. Martini, and P. Masci. Java bytecodeverification with dy-namic structures. In8th IASTED International Conference on Software Engi-neering and Applications (SEA), Cambridge, MA, USA, 2004.
[3] Zhiqun Chen. Java Card Technology for Smart Cards: Architecture and Pro-grammer’s Guide. Addison-Wesley Longman Publishing Co., Inc., 2000.
[4] D. Deville and G. Grimaud. Building an “impossible” verifier on a Java Card. In2nd USENIX Workshop on Industrial Experiences with SystemsSoftware, Boston,USA, 2002.
[5] R. Johnson, D. Pearson, and K. Pingali. The program structure tree: Computingcontrol regions in linear time. InSIGPLAN Conference on Programming Lan-guage Design and Implementation, pages 171–185, 1994.
[6] X. Leroy. Bytecode verification for java smart card.Software Practice & Experi-ence, 32:319–340, 2002.
[7] X. Leroy. Java bytecode verification: algorithms and formalizations.Journal onautomated reasoning, 30, 2003.
[8] T. Lindholm and F. Yellin. The Java Virtual Machine Specification. Addison-Wesley Publishing Company, Reading, Massachusetts, 1996.
[9] T. Lindholm and F. Yellin. Java Virtual Machine Specification, 2nd edition.Addison-Wesley Longman Publishing Co., Inc., 1999.
[10] G. C. Necula. Proof-carrying code. In24th Annual Symposium on Principles ofProgramming Languages Proceedings, pages 106–119, January 1997.
[11] E. Rose and K. Rose. Lightweight bytecode verification.In WFUJ 98 Proceed-ings, 1998.
[12] D. A. Schmidt. Abstract interpretation in the operational semantics hierarchy. InBasic Research in computer Science, 1997.
15
Copyright © 2022 FDOKUMEN




















