
Synthetic Generation of Social Network Data with Endorsements

1
A Reversible Watermarking Technique for SocialNetworks Datasets for Enabling Data Trust in
Cyber, Physical and Social ComputingSaman Iftikhar, M. Kamran, Ehsan Ullah Munir, Member IEEE, and Samee U. Khan, Senior Member IEEE
Abstract—Social networks data is being mined for extracting interesting patterns. Such data is collected by different researchers andorganizations and is usually also shared via different channels. This data usually has huge volume because there are millions of socialnetworks users throughout the world. In this context, ownership protection of such datasets with huge volume becomes relevant. Digitalwatermarking is more demanding solution than any other technique for ensuring rights protection and integrity of the original datasets.The objective of this paper is to devise a reversible watermarking technique for the social networks data to prove ownership rightsand also provide a mechanism for data recovery. Robustness of the proposed technique is evaluated through attack analysis usingexperimental study. In this paper, Z notation based formal specification is also provided to show the working of the proposed reversiblewatermarking technique for social networks datasets for enabling data trust in Cyber, Physical and Social Computing (CPSCom).
Index Terms—Digital Watermarking, Reversible Watermarking, Robust, Data Mining, Social Network Data.
F
1 INTRODUCTION
The use of social networks is increasing day by day. Arecent statistics show that there were above 32 millionsocial networks users worldwide [1]. The recent trendsof the people all over the world indicates that thisnumber would keep on increasing. The social networks’users perform different actions such as: sharing theiractivities, news about their events, sharing news, sharingtheir personal data, discussing various topics and soon. Consequently, they are generating “Big Data” forsocial network computing – an essential component ofCyber, Physical and Social Computing (CPSCom). Toextract and analyze useful information from this data,data mining and other knowledge extraction algorithmsare applied [2], [3], [4], [5]. This work is usually done incollaboration and demands data sharing among differ-ent stakeholders; consequently, ownership protection ofsuch data becomes relevant.
Nowadays social networks data is used excessivelyfor statistical and data mining purposes. Reality Com-mons is an ongoing project in MIT Human Dynamics
• Saman Iftikhar is with the Department of Computer Science, GovernmentCollege University Faisalabad and previously with the Department ofComputing, School of Electrical Engineering and Computer Sciences,National University of Sciences and Technology, Islamabad, Pakistan.E-mail: [email protected]
• M. Kamran is with the Department of Computer Science, COMSATSInstitute of Information Technology, Wah Cantt, Pakistan.E-mail: [email protected]
• E. U. Munir is with the Department of Computer Science, COMSATSInstitute of Information Technology, Wah Cantt, Pakistan.E-mail: [email protected]
• S. U. Khan is with the Department of Electrical and Computer Engineer-ing, North Dakota State University, Fargo, ND 58108–6050, USA.E-mail: [email protected]
Lab [6] containing datasets about social communitiessuch as: (1) Badge dataset; (2) Friends and Family; (3)Reality Mining; and (4) Social Evolution. These datasetswere assembled as a result of two projects namely: anopen-source sensing platform for Android phones andsociometric badges for sensing organizational behavior[7]. The digital ownership protection of such datasets isinevitable and highly demanding because an intruder– Mallory1 – may claim the false ownership of thedata after acquiring access to the data and performingsome modifications (malicious attacks) on the data. Thisprovides us the motivation for the work reported in thispaper.
For ownership protection of digital data, approacheslike fingerprinting, data hashing, serial codes, and wa-termarking techniques are usually used. Fingerprints (ortransactional watermarks) are used to monitor and iden-tify the digital ownership by watermarking all copies ofthe same contents with different watermark for differentrecipients. The main purpose of such technique is toidentify the source of leakage of data [8]. On the otherhand, watermarking provides the ownership protectionover the digital content by watermarking the data withone watermark and then proving the ownership of dig-ital content after successful detection of the embeddedwatermark. This watermark can either be perceptible orimperceptible based on the requirements. A perceptiblewatermark is visible to the human user while an im-perceptible watermark is not visible. A watermarkingscheme should be robust and imperceptible. Further-more, the watermark should be such that it can be
1. In information theory, Mallory is considered as an intruder thathas some evil intentions

2
detected using some secret parameters like secret key etc.A good watermarking technique is also blind, that is, itdoes not require the original data or watermark to detectthe watermark from the altered data. The embeddedwatermark should only be detectable by the data owner.The watermark should not deteriorate the original dataand data usability should be ensured during the processof watermark insertion.
Usually, watermarking techniques for the ownershipprotection introduce modifications into the original data;therefore, information loss occurs [9], [10], [11]. To caterto this situation, reversible watermarking can be usedthat enables original data recovery after watermark de-coding. Accordingly, this paper proposes a reversiblewatermarking technique for social networks datasets2.
To generalize the application of a watermarking tech-nique on different datasets, a formal specification modelmay be used to depict its effectiveness. To support thisargument, authors of [12], [13], [14] insist that a sys-tem (in our case, watermarking technique) specificationshould be written in some structured format [12], [13],[14], using formal methods [15], [16]. Such type of struc-tured and formal specification is more demanding forsecure systems. In formal methods, formal specificationlanguages prove the accuracy, reliability and correctnessof the system under study [17]. Therefore, a formalspecification model has been designed for the proposedreversible watermarking technique through a formalspecification language - Z. It is a formal specificationlanguage amalgamation of typed set theory, predicatecalculus, and schema calculus. Z notations can be usedmathematically to describe and specify the functionalrequirements of a system and its behavior.
The major contributions of our work are: (1) a re-versible watermarking technique for social networksdata that ensures data recovery; (2) a robust watermarkdecoding mechanism; and (3) a formal specificationmodel using a formal method - Z language. The pro-posed technique detects the watermark accurately andrecovers the original data effectively as shown by theformal model and the experimental study on one of thesocial network datasets.
The subsequent sections of the paper are structuredas follows. In the Section 2, related work is discussedand a motivational scenario is presented. The Section 3provides the detail about the threat model. In the Section4, the proposed technique is explained with a detaileddescription of each step. In the Section 5, a formalspecification model is designed for the proposed system.The Section 6 contains the discussion on experimentsand results with the example of a Badge dataset. Finally,the paper is concluded in the Section 7.
2. In this paper, unless otherwise specified, the terms data anddatasets have been used interchangeably
2 RELATED WORK AND MOTIVATION
This discussion presents the related work and the moti-vation behind this work.
2.1 Related Work
To the best of our knowledge, no work has been donefor watermarking of social networks datasets yet. How-ever, some closely relevant techniques include relationaldatabase watermarking techniques but they are eitherrobust or reversible but not both. On the other hand, theproposed technique is both the robust and reversible.
The watermarking of relational databases primarilydeals with the watermarking of numeric features, subjectto the usability constraints. In this context, techniques,such as [18] and [19] require the presence of a primarykey attribute to enforce ownership over the shared data.Primary keys are used in some watermarking techniquesfor various types of data. Its use is not dependent on anytype of data and not required for every watermarkingtechnique. In our context, social networks datasets donot need to have a primary key as the focus is not toidentify each instance distinctly.
A number of recent techniques, such as [20], [21],[22], [23], [24] extend the work reported in [18] and em-bed a multi-bit watermark in selected Least SignificantBits (LSBs). The focus of all of the above mentionedtechniques is towards the watermarking of relationaldatabases and almost all of the techniques require aprimary key for watermarking. However, often (if notalways) there is no primary key or any other uniquefeature in social network datasets. Consequently, weconsider our work to be novel.
2.2 Motivation
A scenario is demonstrated in Fig. 1 for the motivationof this work. A number of users are accessing datafrom the Reality Commons - a social network. Thepurpose is to perform data mining and other statisticalmeasures over the provided datasets for useful analysis.It is possible that Mallory (or any of the user) mayclaim fake ownership over the dataset. Therefore, theownership protection of all the given datasets in thesocial network is required. Digital watermarking andmore specifically reversible watermarking is one goodsolution for ownership protection and data recovery incase of malicious intentions of the users.
3 THREAT MODEL
This section systematically presents the facts regardingthe system and adversary capabilities; thus, encompassesall the possible scenarios with the perspective of anattacker.

3
Fig. 1. Motivational Scenario
3.1 System Model
The owners of the social network datasets demand own-ership protection for their shared data. Therefore, theproposed system is not allowed to modify the data inany way; otherwise, its meaning would be lost and itwould become useless. The owners should be able torecover watermark and the original data. They do notneed to keep a copy of the original data for two reasons:(1) watermark is embedded in the original data withoutchanging values; and (2) watermark decoding does notrequire the original data and the original watermark forwatermark decoding (or recovery). They should input:(1) numeric and non-numeric features; (2) a seed valuefor watermark string generation; (3) a secret key ofnumber of characters and symbols for computing digrammatrix; and, (4) a secret number of rounds (defined bythe owner) for introducing randomness in the permuta-tion matrix. There is no need to store digram and permu-tation matrix as these can be trivially regenerated whilerestoring watermark and the original data. They shoulddefine an integer value and a percent for watermarkencoding and decoding. We assume that all the secretparameters and keys are not compromised and attackerscannot reproduce some or all of them. They will notshare these secret parameters and keys with anyone.
3.2 Adversary Model
The intention of the adversary, Mallory, is to corrupt(or remove) the watermark from the marked dataset. Itis assumed that in various types of malicious attacks,Mallory tries to destroy watermark W. These attacksconsist of insertion, deletion, alteration, additive andcounterfeiting attacks, as shown in Figure 2. The pro-posed technique of reversible watermarking should berobust against these attacks and the encoded watermarkmust be successfully extracted from the attacked dataset.
Fig. 2. Un-Authorized Use of Social Network Data.(a)(b)(c) Mallory inserts, deletes and alters some tuplesin the social networks datasets and intents to destroythe encoded watermark. (d) Mallory tries to embed herown watermark in the datasets and claim her ownership.(e) Mallory forges the original data and makes a copyof the original watermark to claim her ownership in anunauthorized manner.
4 PROPOSED TECHNIQUE
This section discusses the reversible watermarking ofsocial network datasets. The main architecture of theproposed technique is presented in the Fig. 3. It includesthe following four major phases: (1) preprocessing, (2)watermark encoding, (3) watermark decoding, and (4)data recovery.
For a quick reference, Table 1 lists the notations usedin this paper.
4.1 PreprocessingThe preprocessing phase comprises three steps: (1) dataselection; (2) feature selection; and (3) watermark cre-ation. First, the dataset to be watermarked is selected.Next, the numeric or non-numeric feature is selectedfor watermarking. Then, a watermark is created throughpseudo-random sequence generator to encode the se-lected feature of the selected dataset.
4.2 Watermark EncodingAfter selecting the feature from the dataset, two furthersteps are performed for each type of selected featurebefore encoding watermark. In the first step, an evo-lutionary algorithm – Genetic Algorithm (GA) [25] – isused to create an optimum value to be embedded in thenumeric type of dataset for ensuring robust watermarkdetection. In the second step, hashing and permutationsare generated for non-numeric type of dataset to ensurereversible watermarking. After calculating a seeded wa-termark in step (3), watermark is embedded in each typeof data in step (4) as shown in the Fig. 3.
4.3 Watermark DecodingFor watermark detection from the watermarked data;first, the preprocessing steps – hashing and permutation

4
Fig. 3. Main Architecture of Proposed Technique
TABLE 1Notations Used in the Paper
Symbol Description Symbol DescriptionD The original dataset R All tuples in a datasetDWr The watermarked dataset Dr Recovered DataS[ω] A Seed vector for Pseudo-Random Sequence Generator F A feature selected for watermarkingβ Determines character at a specified index γ Index of a specified character in permuted matrixk A key based on number of characters used in digram matrix κ Secret number of rounds for permutations defined by the ownerΣ All accepted characters 4Σ Matrix of all possible digrams` Length of input data string `4Σ
Length of the matrix of all possible digramsρ Index of the character in digram matrix P[N] Permutation vector for introducing randomness N timesω Watermark length b Watermark bitsζ Owner defined an integer change τ Owner defined percentage change∆D Change in the original value ∆DW Change in the watermarked value∆Diff Difference in ∆D and ∆DWξW Substituted digram for encoding ξD Decoded data from Substituted digram
are performed again for selected type of feature. Next,majority voting scheme is used to detect the watermarkfrom the marked dataset on the basis of number of ’1s’and ’0s’. Finally, the watermark is extracted from thewhole dataset to prove ownership.
4.4 Data RecoveryIn this phase, GA, hashing and permutation steps areperformed again for selected type of feature. Data isrecovered from the marked data of the selected featuretype through employing GA, hashing and permutationafter detecting the embedded watermark.
5 FORMAL SPECIFICATION MODELFormal specification model includes schemas to describethe static and dynamic aspects of the proposed system.Schemas define states, invariants, operations and rela-tionships between inputs and outputs. Metadata aboutdifferent states and operations of the system are definedseparately for each schema. Data owner requirementsare defined in the form of properties and propositionusing conjunction, disjunction, implication, equivalenceand negation. Quantifiers used are: (1) for all ∀; and,(2) existential quantifier ∃. Mathematical notations forschema inclusion, used in this paper are ∆ and Ξ.
The formal specification model comprises System-Info, FeatureSelection, EvolutionaryAlgorithm, Hashing-Permutation, WatermarkCreation, WatermarkEncoding,WatermarkDecoding, and DataRecovery schemas.
5.1 The Proposed System
It is a system that provides ownership protection ofnumeric relational data and restores the original datawithout distortions. The proposed technique allows anysocial network data owners to watermark their datasetsby giving some secret parameters. The system specifica-tion is provided in this schema by defining SETS forOWNER-ID, NAME, WATERMARK-ID, PASSWORD,DATA, WATERMARK-DATA, De-WATERMARK-DATA,FEATURES, STRING, λ, and β. The metadata of theproposed system is defined in Table 2, and its schemais given below. All the variables of the proposed systemare declared in the SystemInfo schema.
TABLE 2Metadata of the SystemInfo Schema
Types DescriptionDATA Set of Original DatasetsWATERMARK-DATA Set of Data that is WatermarkedDe-WATERMARK-DATA Set of Data that is DecodedFEATURES Set of features of DatasetsSTRING Set of messages that are shown in the systemS[ω] Set of Seed vectors for PseudoRandom
Sequence Generatorλ Set of usability constraints defined by OWNERκ Set of secret number of rounds for
permutations defined by the ownerβ Set of Optimized values to Watermark the Data
[DATA, WATERMARK-DATA, De-WATERMARK-DATA, FEATURES, STRING, S[ω], κ, λ, β]

5
5.2 Feature SelectionSchema of the Feature Selection step of preprocessingphase is defined below. In the schema F represents thenumeric or non-numeric feature.
FeatureSelection
ΞSystemInfo
Display! : STRING
Display! = Select Features to set in your Data
Display! = Feature Selection Completed
5.3 Evolutionary AlgorithmSchema of the Evolutionary Algorithm sub-step of pre-processing phase is defined below: [!htpb]
EvolutionaryAlgorithm
ΞSystemInfo
ΞFeatureSelection
GA? : Algorithm for creating an optimum value
β? : Optimum Value to Watermark the Data
Display1! : STRING
β = β′
Data = Data′ ∪ Data′
Operations = Operations′ ∪ Operations
DATA = DATA′
Display! = Step Completed
5.4 Hashing and Permutation
Schema of the Hashing and Permutation sub-step ofpreprocessing phase is defined below. In the schemaP[N] represents a 1 × 10 vector and P[4Σ] representsall possible permutations.
HashingPermutation
ΞSystemInfo
ΞFeatureSelection
Σ′? : Σ //Set of all specified characters
k′? : k //keyspace
Display! : STRINGMESSAGE
Display! = Select special characters for matrix creation
β(i) = Σ(i), β(j) = Σ(j)
4Σ(i ∗ k′ + j) = β(i) || β(j)
Where i, j = 0, 1, 2..., k′
Display! = hashing generated
Display! = Select number of rounds for permutations
Loop of Counter :
4Σ((i ∗ k′ + P[j] ∗ κ′) mod `4Σ)
4Σ(((`4Σ− i) + P[j + 1] ∗ κ′) mod `4Σ
)
Where i = `4Σand j = P[N].length
Display! = Permutations generated
5.5 Watermark CreationSchema of the Watermark Creation step of preprocessingphase is defined below:
WatermarkCreation
ΞSystemInfo
ΞFeatureSelection
ΞEvolutionaryAlgorithm
ΞHashingPermutation
PRSG? : Pseudo− random sequence generator
S[ω]? : Seed Value
Display1! : STRING
S[ω] : S[ω]′
Operations = Operations′ ∪ Operations
Display! = Step Completed
5.6 Watermark Encoding
Schema of the Watermark Encoding phase is definedbelow:
WatermarkEncoding
ΞSystemInfo
ΞFeatureSelection
ΞEvolutionaryAlgorithm
ΞHashingPermutation
ΞWatermarkCreation
EA? : EncodingAlgorithm
Counter = WATERMARK→ Length
Display1! : STRING
Loop of Counter :
Status1
Status2
Step1
CASE 1 : THEN ηr = Dr + β ∗ ζ
& DWr = Dr + β
ELSE ηr = Dr− β ∗ ζ
& DWi = Dr − β
WATERMARK − DATA′ =
WATERMARK − DATA′ ∪ ∇
Step2
CASE 1 : THEN ξW = 4Σ(γ(Di) ∗ k + γ(Di+1) + ζ)
& ∆D = (γ(Di) ∗ k + γ(Di+1) + ζ) ∗ τ
ELSE ξW = 4Σ(γ(Di) ∗ k + γ(Di+1)− ζ)
& ∆D = (γ(Di) ∗ k + γ(Di+1)− ζ) ∗ τ
WATERMARK − DATA′ =
WATERMARK − DATA′ ∪ ξW
Display! = Step Completed
5.7 Watermark Decoding
Schema of the Watermark Decoding phase is definedbelow:

6
WatermarkDecoding
Ξ SystemInfo
Ξ FeatureSelection
∆ EvolutionaryAlgorithm
∆ HashingPermutation
∆ WatermarkEncoding
DA? : DecodingAlgorithm
Change? : Variable of type ∆
Counter = WATERMARK→ Length
Display1! : STRING
Loop of Counter :
Step1
ηDr = D′Wr + β ∗ ζ
η∆r = ηDr − ηr
CASE η∆r ≤ 0 : THEN w→ 1
ELSE CASE η∆r > 0 ∧ η∆r ≤ 1 THEN w→ 0
Step2
∆DW = (γ(DW(i)) ∗ k + γ(DW(i+1)) + ζ) ∗ τ
∆Diff = ∆DW −∆D
CASE ∆Diff ≤ 0 : THEN w→ 1
ELSE CASE ∆Diff > 0 ∧ ∆Diff ≤ 1 THEN w→ 0
WATERMARK − DATA′ =
De−WATERMARK − DATA
Display! = Step Completed
5.8 Data RecoverySchema of the Data Recovery phase is defined below:
DataRecovery
Ξ SystemInfo
Ξ FeatureSelection
∆ EvolutionaryAlgorithm
∆ HashingPermutation
∆WatermarkEncoding
DRA? : DataRecoveryAlgorithm
Display1! : STRING
Loop of Counter :
Step1
CASE 0 : THEN Dr = D′Wr − βr
ELSE Dr = D′Wr + βr
Step2
CASE 0 : THEN ξD = 4Σ(γ(DW(i))∗
k + γ(DW(i+1))− ζ)
ELSE ξD = 4Σ(γ(DW(i)) ∗ k + γ(DW(i+1)) + ζ)
Data = Data′
De−WATERMARK DATA = DATA
Display! = Step Completed
6 RESULTS AND DISCUSSION
In this section, the proposed technique has been eval-uated for providing: (1) reversible watermarking; and(2) robustness against malicious attacks. For brevity,experiments have been reported with a Badge datasetcontaining performance and dynamics of a real worldorganization. A relatively small watermark that consists
of 8-bits is used in the analysis. The dataset consists offour features including: (1) BID (badges identified byunique numbers assigned to the employees), (2)(3) x andy (locations of employees’ cubicles and anchor nodes);and (4) roles of employees. The dataset has been shownin Table 3 with only three records for brevity.
TABLE 3Badge Dataset
BID x y Role266 5895.2 3075.8 Pricing276 6512 3105.8 Configuration291 6792.8 3105.8 Coordinator... ... ...
The proposed technique handles big data in a system-atic way with logical grouping. For instance, for non-numeric data encoding, similar records for the sameemployees get hashed to same values and make logicalgroups; so, the data size do not increase. Moreover, thedata owner has more interest in acquiring ownershiprights and data recovery. She gets her data watermarkedonly once and watermarking is usually done offline, thatis to say: it is done on the machine of the data ownerand data is delivered to recipient only after completingthe embedding process; so, she can afford large com-putation time for providing ownership rights and datarecovery. For datasets involving large number of featuresor large number of rows “Big Data”, data owner mayuse a separate machine, with high computation power,for watermarking the datasets. This might incur somecost but gain the owner more security (false claim ofownership can be tackled by watermark encoding anddecoding).
The computational time of the proposed techniqueis (ω ∗ R ∗ F) where ω is the watermark length, R isthe total number of tuples in the dataset and F is thefeature selected for watermarking. The number of tuplesare usually much larger as compared to the number offeatures in databases and the watermark length ω; so,F << R and ω << R. Therefore, for large databases,(R termed as n) the time complexity of the proposedtechnique for watermark encoding and decoding is O(n)(it is worth mentioning here that the time for computingthe GA based optimal value is not included in thiscalculation because it is part of pre-processing.
6.1 Reversible WatermarkingThe preprocessing phase, watermark creation, water-mark encoding, decoding and data recovery are demon-strated, to give an insight of how the proposed techniqueworks.
6.1.1 Preprocessing PhaseIn this phase, a dataset (Badge Dataset) and a numericand non-numeric feature was selected for watermarking.A watermark string of 8-bits was generated with seededpseudo-random sequence generator to encode all the

7
tuples of the selected features. An optimum value ofβ = 1 is calculated by using an optimization scheme.This value might be different for different datasets.Sufficient experiments were performed to find out themost reliable set of parameters for GA. The detailed setof GA parameters found reliable are given in Table 4.The value of ζ = 0.1 for both feature types.
TABLE 4GA Parameters Setting
GA Parameter ValueNo. of Generations 50Population Size 10Chromosome Length 8Selection Mechanism Tournament Selection
Tournament Size = 5Crossover Type: Single Point
Fraction: 0.7Mutation Type: Uniform
Rate: 0.1Elitism Count 2
All the possible digrams 4Σ for the selected datasetwere computed with all the possible pair combinationsand hashing of the selected feature and permutationmatrix P[4Σ] was generated from the digram matrix4Σ.Permutations are performed to substitute the originalcharacters with permuted characters [26]. The permu-tation matrix P[4Σ] was then computed algorithmicallyby using previously calculated matrix of digrams 4Σ.Thereafter, permutations are performed. A 1× 10 vectorP[N] is initialized randomly that introduces randomnessin the resultant permutation matrix P[4Σ] by manipulat-ing P[j] and P[j + 1] values from P[N] alternatively. Thepermutations were computed for a pre-specified numberof times according to a secret number - κ, specified by thedata owner. This step is performed to bring randomnessin the initial digrams matrix 4Σ.
6.1.2 Watermark Encoding
In this phase, Badge dataset was taken under consider-ation, with only 3 tuples of the selected feature: BID asa numeric feature and role as a non-numeric feature toshow the whole procedure of watermark encoding. Thewatermark encoding process has been explained throughTables 5 and 6. Numeric values were marked witha novel proposed reversible watermarking techniquewhere the original data recovered fully without modifi-cations. For non-numeric data, a digram Pr from pricing –the value of the first tuple was encoded with watermarkbits. Watermark bits have been represented with b oflength 8. For every watermark bit the watermarked dataDWr and percentage change ηr in the original valueswere computed. Similarly, for permuted digrams ξW andchanges in data values ∆D were computed for digramPr. The same procedure was repeated for the rest of thetuples for the selected features.
The watermarked dataset after watermark encodinghas been shown in Table 7.
TABLE 5Watermark Encoding (Numeric Data)
BID b 1 0 1 1 1 1 0 0
266 ηr 26.7 26.6 26.7 26.8 26.9 27.0 26.9 26.8DWr 267 266 267 268 269 270 269 268
276 ηr 27.7 27.6 27.7 27.8 27.9 28.0 27.9 27.8DWr 277 276 277 278 279 280 279 278
291 ηr 29.2 29.1 29.2 29.3 29.4 29.5 29.4 29.3DWr 292 291 292 293 294 295 294 293
TABLE 6Watermark Encoding (Non-Numeric Data)
Role b 1 0 1 1 1 1 0 0
Pr ξW MS UU MS MS MS MS UU UU∆D 42.4 42.0 42.4 42.4 42.4 42.4 42.0 42.0
Co ξW Q OP Q Q Q Q OP OP∆D 7.0 6.6 7.0 7.0 7.0 7.0 6.6 6.6
Co ξW BI QD BI BI BI BI QD QD∆D 7.0 6.6 7.0 7.0 7.0 7.0 6.6 6.6
TABLE 7Badge Dataset (Watermarked Dataset)
BID x y Role266 5895.2 3075.8 Pricing276 6512 3105.8 Configuration291 6792.8 3105.8 Coordinator... ... ...
6.1.3 Watermark Decoding
To show the intuition to how the decoding algorithmworks, the same 3 tuples of the selected features wereconsidered. The steps of watermark decoding have beenshown in Tables 8 and 9. The changes in the original datavalues ∆D computed during the encoding phase wereused in the decoding phase. The changes in the encodeddata values ∆DW were computed while decoding thewatermark from the watermarked data. The difference inchange in the original data values and the encoded datavalues ∆Diff was computed as given in schemas above.On the basis of these computed differences, watermarkbits b were extracted as it is for numeric data and inreverse order for non-numeric data.
TABLE 8Watermark Decoding (Numeric Data)
BID
266
∆D 26.7 26.6 26.7 26.8 26.9 27.0 26.9 26.8∆DW 26.7 26.8 26.7 26.8 26.9 27.0 27.1 26.9∆Diff 0 0.2 0 0 0 0 0.2 0.2b 1 0 1 1 1 1 0 0Dr 267 266 267 268 269 270 269 268
276
∆D 27.7 27.6 27.7 27.8 27.9 28.0 27.9 27.8∆DW 27.7 27.8 27.7 27.8 27.9 28.0 28.1 28.0∆Diff 0 0.2 0 0 0 0 0.2 0.2b 1 0 1 1 1 1 0 0Dr 277 276 277 278 279 280 279 278
291
∆D 29.2 29.1 29.2 29.3 29.4 29.5 29.4 29.3∆DW 29.2 29.3 29.2 29.3 29.4 29.5 29.6 29.5∆Diff 0 0.2 0 0 0 0 0.2 0.2b 1 0 1 1 1 1 0 0Dr 292 291 292 293 294 295 294 293

8
TABLE 9Watermark Decoding (Non-Numeric Data)
Role
Pr
∆D 42.0 42.0 42.4 42.4 42.4 42.4 42.0 42.4∆DW 42.4 42.4 42.4 42.4 42.4 42.4 42.4 42.4∆Diff 0.4 0.4 0 0 0 0 0.4 0b 0 0 1 1 1 1 0 1ξD UU UU MS MS MS MS UU MS
Co
∆D 6.6 6.6 7.0 7.0 7.0 7.0 6.6 7.0∆DW 7.0 7.0 7.0 7.0 7.0 7.0 7.0 7.0∆Diff 0.4 0.4 0 0 0 0 0.4 0b 0 0 1 1 1 1 0 1ξD OP OP Q Q Q Q OP Q
Co
∆D 6.6 6.6 7.0 7.0 7.0 7.0 6.6 7.0∆DW 7.0 7.0 7.0 7.0 7.0 7.0 7.0 7.0∆Diff 0.4 0.4 0 0 0 0 0.4 0b 0 0 1 1 1 1 0 1ξD QD QD BI BI BI BI QD BI
6.1.4 Data RecoveryAfter detecting watermark string, post processing stepswere carried out for error correction and data recovery.The optimized value of β computed through GA is usedfor regeneration of numeric data. The original data Drand the permuted digrams ξD for the digram Pr, Co weredecoded accordingly. Finally, the original data valuepricing was computed from permuted digrams. The sameprocedure was repeated for the rest of the tuples for theselected features as shown in Tables 8 and 9. The originaldataset has been recovered fully and same as shown inthe Table 3
6.2 Robustness AnalysisRobustness analysis of the proposed technique is startedwith a supposition that the ownership protection of thesocial networks’ datasets is inevitable against the threatmodel (presented in Section 3). The datasets are sharedin the social networks. Mallory has malicious intentionsand she make several attempts to corrupt the data andthe watermark encoded in the data.
Robustness of the proposed technique was examinedthrough an extensive attack analysis. Our results showedhigh accuracy for the watermark detection with inser-tion, alteration and deletion attacks. We believe that thisis due to the fact that the optimum GA parameters madesure that the maximum decoding accuracy is achievedby introducing sufficient randomness during watermarkembedding. The GA do not guarantee the optimumresult; however, due to their evolutionary nature, thetend to find a better solution for the given problem.
In the robustness study, we examined our techniqueagainst tuple insertion, deletion and insertion attacks.Mallory tries to insert, alter or delete 10%, 20%, 30%,40%, 50%, ..., 90% of data. After such attacks, theproposed technique recovered 100%, tuples in all thecases. In case of tuple insertion and deletion attacks,the decoding accuracy is higher because Mallory isnot quite “affecting” the watermarked tuples becausethe watermark embedding takes into account all theoriginal tuples and hence insertion of new tuples ordeletion of some tuples do not affect the watermark in
the un-attacked tuples. On the other hand, in case oftuple alteration attacks, the robustness may suffer withthe attacks that target large number of tuples becausethe embedded watermark is directly dependent on thevalues of the tuples. Moreover, the combination of tupleinsertion, deletion and alteration attacks will also affectthe accuracy of the proposed technique.
6.2.1 Insertion AttacksIn this type of attack, Mallory inserts new tuples tocorrupt the watermark embedded in the data. Insertionof new tuples do not destroy the data integrity andthe embedded watermark but may affect the watermarkdetection rate. The proposed technique was observed tobe highly resilient against these types of attacks andrecovered the watermark with 100% accuracy even ifMallory inserts 100% new and fake tuples. Data recoveryhas been shown in Fig. 4 for the proposed technique. Thewatermark decoding success rate was demonstrated inFig. 5.
0 10 20 30 40 50 60 70 80 90 1000
20
40
60
80
100
Inserted Tuples (%)
Dat
a R
eco
very
(%
)
Fig. 4. Data Recovery after Insertion Attack
0 10 20 30 40 50 60 70 80 90 1000
20
40
60
80
100
Inserted Tuples (%)
Acc
ura
cy (
%)
Fig. 5. Watermark Decoding Accuracy of the proposedtechnique with Insertion Attack
6.2.2 Deletion AttacksIn such attacks, Mallory deletes a subset of watermarkedtuples from the datasets to corrupt the watermark. Thewatermark was encoded in the permuted digrams ofn tuple, so the watermark was extracted even from apermuted digram of a single tuple. Mallory is unableto detect watermark as she is not aware of permuteddigrams; therefore, she has the only choice to deletetuples with the concern of preserving the data usefulnessof the remaining tuples. Experiments were performed toshow the data recovery and the watermark detection.If she can delete n − 1 tuples, watermark would berestored from the remaining 1 tuple of the dataset. In
9
experiments, upto 90% of the data was deleted, so thewatermark was recovered with 100% accuracy as shownin Fig. 7. Data recovery was also observed with varioussuccess rates under various ranges of deletion attacks asshown in Fig. 6.
0 10 20 30 40 50 60 70 80 90 1000
102030405060708090
100
Deleted Tuples (%)
Dat
a R
eco
very
(%
)
Fig. 6. Data Recovery after Deletion Attack
10 20 30 40 50 60 70 80 900
20
40
60
80
100
Deleted Tuples (%)
Acc
ura
cy (
%)
Fig. 7. Watermark Decoding Accuracy of the proposedtechnique with Deletion Attack
6.2.3 Alteration Attacks
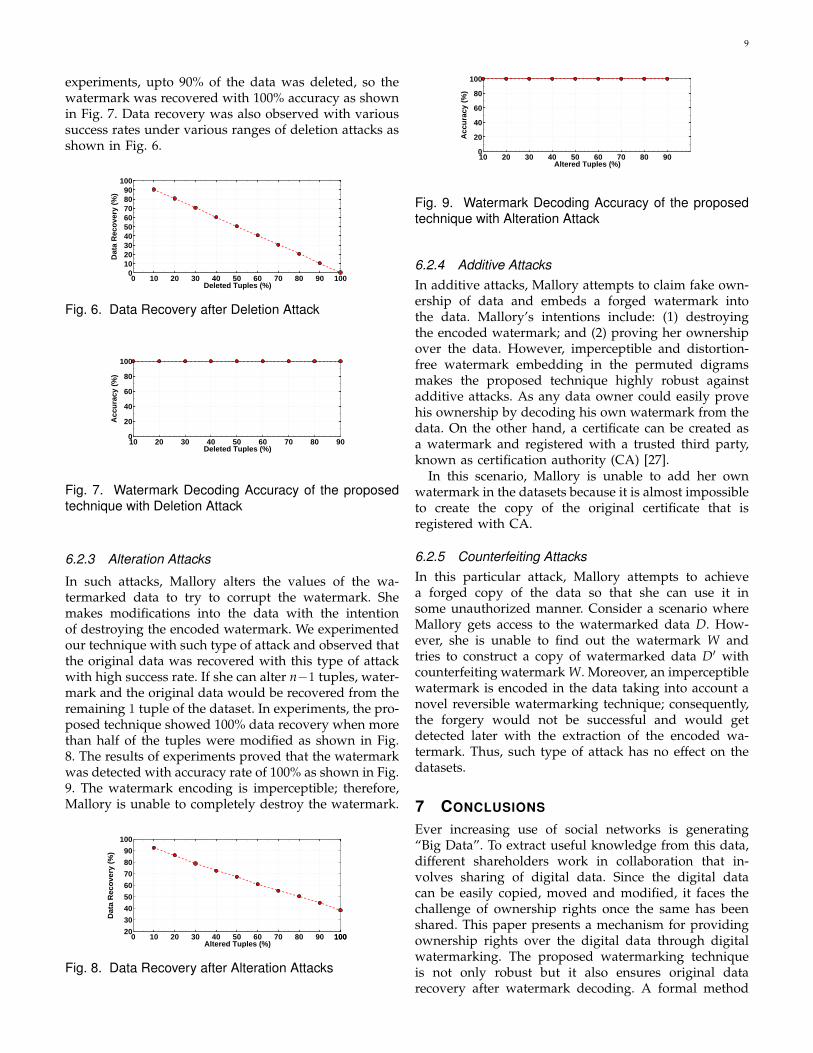
In such attacks, Mallory alters the values of the wa-termarked data to try to corrupt the watermark. Shemakes modifications into the data with the intentionof destroying the encoded watermark. We experimentedour technique with such type of attack and observed thatthe original data was recovered with this type of attackwith high success rate. If she can alter n−1 tuples, water-mark and the original data would be recovered from theremaining 1 tuple of the dataset. In experiments, the pro-posed technique showed 100% data recovery when morethan half of the tuples were modified as shown in Fig.8. The results of experiments proved that the watermarkwas detected with accuracy rate of 100% as shown in Fig.9. The watermark encoding is imperceptible; therefore,Mallory is unable to completely destroy the watermark.
0 10 20 30 40 50 60 70 80 90 10010020
30
40
50
60
70
80
90
100
Altered Tuples (%)
Dat
a R
eco
very
(%
)
Fig. 8. Data Recovery after Alteration Attacks
10 20 30 40 50 60 70 80 900
20
40
60
80
100
Altered Tuples (%)
Acc
ura
cy (
%)
Fig. 9. Watermark Decoding Accuracy of the proposedtechnique with Alteration Attack
6.2.4 Additive AttacksIn additive attacks, Mallory attempts to claim fake own-ership of data and embeds a forged watermark intothe data. Mallory’s intentions include: (1) destroyingthe encoded watermark; and (2) proving her ownershipover the data. However, imperceptible and distortion-free watermark embedding in the permuted digramsmakes the proposed technique highly robust againstadditive attacks. As any data owner could easily provehis ownership by decoding his own watermark from thedata. On the other hand, a certificate can be created asa watermark and registered with a trusted third party,known as certification authority (CA) [27].
In this scenario, Mallory is unable to add her ownwatermark in the datasets because it is almost impossibleto create the copy of the original certificate that isregistered with CA.
6.2.5 Counterfeiting AttacksIn this particular attack, Mallory attempts to achievea forged copy of the data so that she can use it insome unauthorized manner. Consider a scenario whereMallory gets access to the watermarked data D. How-ever, she is unable to find out the watermark W andtries to construct a copy of watermarked data D′ withcounterfeiting watermark W. Moreover, an imperceptiblewatermark is encoded in the data taking into account anovel reversible watermarking technique; consequently,the forgery would not be successful and would getdetected later with the extraction of the encoded wa-termark. Thus, such type of attack has no effect on thedatasets.
7 CONCLUSIONS
Ever increasing use of social networks is generating“Big Data”. To extract useful knowledge from this data,different shareholders work in collaboration that in-volves sharing of digital data. Since the digital datacan be easily copied, moved and modified, it faces thechallenge of ownership rights once the same has beenshared. This paper presents a mechanism for providingownership rights over the digital data through digitalwatermarking. The proposed watermarking techniqueis not only robust but it also ensures original datarecovery after watermark decoding. A formal method

10
has been used to prove the effectiveness of the system.Experimental study is performed for evaluation of theproposed watermarking technique against the definedthreat model.
REFERENCES
[1] “Global social networks ranked by number of users2014,” http://www.statista.com/statistics/278414/number-of-worldwide-social-network-users/, last accessed: July, 182014.
[2] A. Stefanidis, A. Crooks, and J. Radzikowski, “Harvesting ambi-ent geospatial information from social media feeds,” GeoJournal,vol. 78, no. 2, pp. 319–338, 2013.
[3] D. Jensen and J. Neville, “Data mining in social networks,” inDynamic Social Network Modeling and Analysis: workshop summaryand papers. National Academies Press, 2003, pp. 287–302.
[4] M. Thelwall, D. Wilkinson, and S. Uppal, “Data mining emotion insocial network communication: Gender differences in myspace,”Journal of the American Society for Information Science and Technology,vol. 61, no. 1, pp. 190–199, 2010.
[5] C. C. Aggarwal, An introduction to social network data analytics.Springer, 2011.
[6] “Reality commons,” http://realitycommons.media.mit.edu/index.html,last accessed: January, 20 2014.
[7] “sociometric badges for sensing organizational behavior,”http://sociometricsolutions.com, last accessed: January, 30 2014.
[8] M. B. Thompson, J. M. Tangen, and D. J. McCarthy, “Expertise infingerprint identification,” Journal of forensic sciences, vol. 58, no. 6,pp. 1519–1530, 2013.
[9] G. Coatrieux, E. Chazard, R. Beuscart, and C. Roux, “Losslesswatermarking of categorical attributes for verifying medical database integrity,” in IEEE Annual International Conference of theEngineering in Medicine and Biology Society, EMBC, 2011. IEEE,2011, pp. 8195–8198.
[10] G. Gupta and J. Pieprzyk, “Reversible and blind database wa-termarking using difference expansion,” in Proceedings of the 1stinternational conference on Forensic applications and techniques intelecommunications, information, and multimedia and workshop. ICST(Institute for Computer Sciences, Social-Informatics and Telecom-munications Engineering), 2008, p. 24.
[11] E. Aimeur, S. Gambs, and A. Ho, “Towards a privacy-enhancedsocial networking site,” in Availability, Reliability, and Security,2010. ARES’10 International Conference on. IEEE, 2010, pp. 172–179.
[12] J. P. Bowen and M. G. Hinchey, High-integrity system specificationand design. Springer Heidelberg, 1999.
[13] T. DeMarco, Structured analysis and system specification. YourdonPress, 1979.
[14] E. Yourdon and L. L. Constantine, “Structured design: Funda-mentals of a discipline of computer program and systems design.1979.”
[15] I. Toyn, “Innovations in the notation of standard z,” in ZUM 98:The Z Formal Specification Notation. Springer, 1998, pp. 193–213.
[16] J. Bicarregui, J. Dick, B. Matthews, and E. Woods, “Makingthe most of formal specification through animation, testing andproof,” Science of computer programming, vol. 29, no. 1, pp. 53–78,1997.
[17] J. M. Spivey, “An introduction to z and formal specifications,”Software Engineering Journal, vol. 4, no. 1, pp. 40–50, 1989.
[18] R. Agrawal and J. Kiernan, “Watermarking relational databases,”in 28th International Conference on Very Large Data Bases. MorganKaufmann Pub, 2002, pp. 155–166.
[19] R. Sion, M. Atallah, and S. Prabhakar, “Rights protection forrelational data,” Knowledge and Data Engineering, IEEE Transactionson, vol. 16, no. 12, pp. 1509–1525, 2004.
[20] V. Khanduja and O. Verma, “Identification and proof of owner-ship by watermarking relational databases,” International Journalof Information and Electronics Engineering, vol. 2, no. 2, pp. 274–277,2012.
[21] L. Zhang, W. Gao, N. Jiang, L. Zhang, and Y. Zhang, “Rela-tional databases watermarking for textual and numerical data,”in Mechatronic Science, Electric Engineering and Computer (MEC),2011 International Conference on. IEEE, 2011, pp. 1633–1636.
[22] U. P. Rao, D. R. Patel, and P. M. Vikani, “Relational database wa-termarking for ownership protection,” in International Conferenceon Communication, Computing & Security, 2012, pp. 988–995.
[23] S. Iqbal, A. Rauf, S. Mahfooz, S. Khusro, and S. H. Shah, “Self-constructing fragile watermark algorithm for relational databaseintegrity proof,” World Applied Sciences Journal, vol. 19, no. 9, pp.1273–1277, 2012.
[24] W. Yanmin and G. Yuxi, “The digital watermarking algorithm ofthe relational database based on the effective bits of numericalfield,” in World Automation Congress (WAC), 2012. IEEE, 2012,pp. 1–4.
[25] J. Holland, “Genetic algorithms,” Scientific American, vol. 267,no. 1, pp. 66–72, 1992.
[26] P. Flajolet and R. Sedgewick, Analytic combinatorics. cambridgeUniversity press, 2009.
[27] L. Zhou, F. B. Schneider, and R. Van Renesse, “Coca: A securedistributed online certification authority,” ACM Transactions onComputer Systems (TOCS), vol. 20, no. 4, pp. 329–368, 2002.
Saman Iftikhar received her M.S and Ph.D.degrees in Information Technology in 2008 and2014, respectively, from National University ofSciences and Technology (NUST), Islamabad,Pakistan. She has worked as Research Assis-tant in an Information and Communication Tech-nology Research and Development (ICT R&D)project from 2008 to 2011 in NUST. Currently,she is working as Assistant Professor in theDepartment of Computer Science, GovernmentCollege University Faisalabad. Her research in-
terests include information security, distributed computing, semanticweb and cloud computing.
M. Kamran received the M.S. and Ph.D. degreesin computer science, in 2008 and 2012, re-spectively, from National University of Computerand Emerging Sciences (NUCES), Islamabad,Pakistan. Currently he is working as AssistantProfessor in Computer Science Department ofCOMSATS Institute of Information Technology,Wah Cantt, Pakistan. His research interests in-clude machine learning, evolutionary computa-tions techniques, data security, health informat-ics, big data analytics and decision support sys-
tems.
Ehsan Ullah Munir received his Ph.D. degreein Computer Software & Theory from HarbinInstitute of technology Harbin, China in 2008.He completed his Masters in Computer Sciencefrom Barani Institute of Information Technology,Pakistan in 2001. He is currently an AssociateProfessor and Head in the department of Com-puter Science at COMSATS Institute of Informa-tion Technology, Pakistan. His research interestsinclude heterogeneous parallel and distributedcomputing, wired and wireless networks and
information retrieval.
Samee U. Khan received a BS degree fromGhulam Ishaq Khan Institute of EngineeringSciences and Technology, Topi, Pakistan, anda PhD from the University of Texas, Arlington,TX, USA. Currently, he is Assistant Professorof Electrical and Computer Engineering at theNorth Dakota State University, Fargo, ND, USA.Prof. Khans research interests include optimiza-tion, robustness, and security of: cloud, grid,cluster and big data computing, social networks,wired and wireless networks, power systems,
smart grids, and optical networks. His work has appeared in over250 publications. He is a Fellow of the Institution of Engineering andTechnology (IET, formerly IEE), and a Fellow of the British ComputerSociety (BCS).
Copyright © 2022 FDOKUMEN




















