
Fault tolerant solid state mass memory for space applications

Distributing an Itinerary Service
(Middleware approach)
Arian Hosseinzadeh, Faraz Falsafi
Fall 2012 - Spring 2013
McGill University
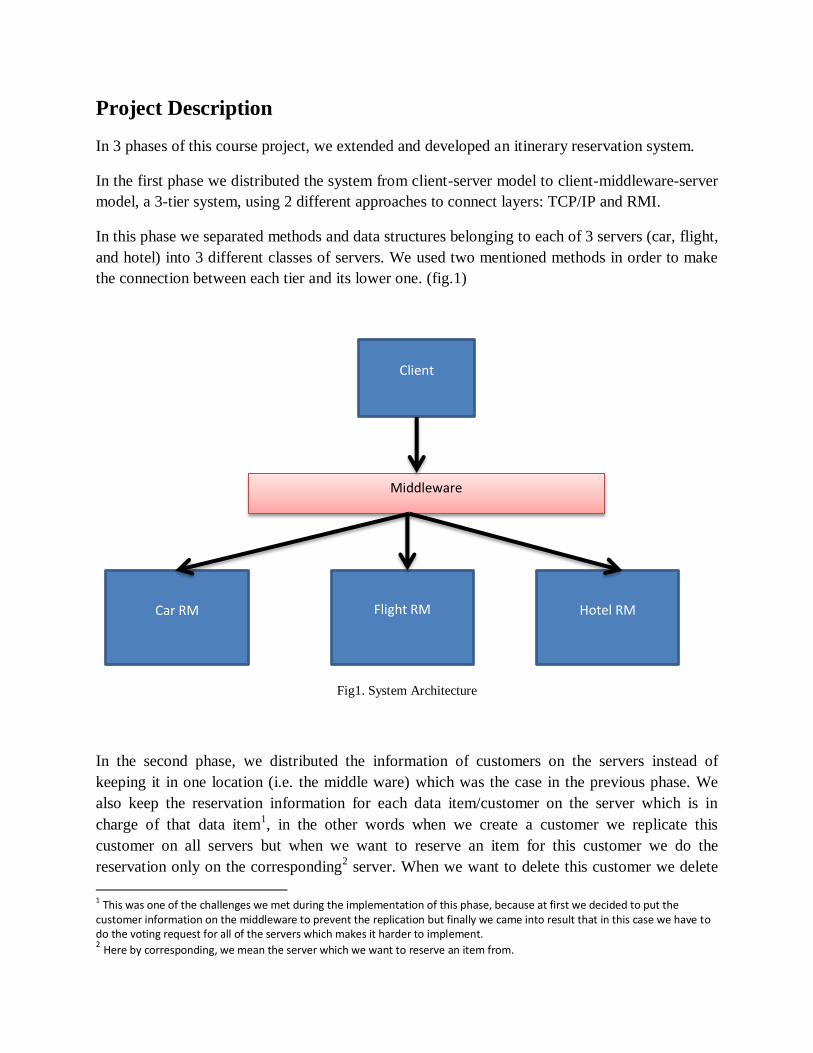
Project Description
In 3 phases of this course project, we extended and developed an itinerary reservation system.
In the first phase we distributed the system from client-server model to client-middleware-server
model, a 3-tier system, using 2 different approaches to connect layers: TCP/IP and RMI.
In this phase we separated methods and data structures belonging to each of 3 servers (car, flight,
and hotel) into 3 different classes of servers. We used two mentioned methods in order to make
the connection between each tier and its lower one. (fig.1)
Fig1. System Architecture
In the second phase, we distributed the information of customers on the servers instead of
keeping it in one location (i.e. the middle ware) which was the case in the previous phase. We
also keep the reservation information for each data item/customer on the server which is in
charge of that data item1, in the other words when we create a customer we replicate this
customer on all servers but when we want to reserve an item for this customer we do the
reservation only on the corresponding2 server. When we want to delete this customer we delete
1 This was one of the challenges we met during the implementation of this phase, because at first we decided to put the customer information on the middleware to prevent the replication but finally we came into result that in this case we have to do the voting request for all of the servers which makes it harder to implement. 2 Here by corresponding, we mean the server which we want to reserve an item from.
Client
Middleware
Car RM Flight RM Hotel RM

the customer on all servers and when we want to query customer information we request
information of the customer from all of the servers.
In this phase a lock manager was added to the system which provides the ISOLATION to the
system. We decided to keep this Lock Manager in the middleware so there would be no need for
detecting distributed deadlocks on the servers. A Transaction Manager was also added to the
middleware which keeps track of transactions & the servers (resource managers). To prevent
indefinite deadlocks, there’s a specific time out, i.e. each transaction waiting for a lock or not
doing an action (commanded by the client) would time out after this amount of time, so other
transactions may use the resources which are probably hold by these transactions.
We designed the lock manager as if a transaction request a lock on an object, it may acquire the
read lock if it already has a write lock on the same object and it gains a write lock if it already
has a read lock on that item and there’s no other transaction having a read lock request waiting,
in other cases it would wait until the lock is assigned to it. Object’s ID is defined as a string
referring to the server which the data item is stored on and name of the object, therefore its
unique.
The idea of ATOMICITY was also implemented in this phase by use of Transaction Manager
mentioned earlier. A set of operations in a transaction would change the data (stored in a
hashtable on each server) of the server3(s) after committing the transaction while aborting the
transaction causes no effect on the data. We implemented this part by taking a backup of the
original data, writing the changes to the data store4 of the server and replacing the data by the
backup version taken earlier in case of abort.
For the 3rd
phase of the project, we decided to change some implementations we had done so far,
and this was one the biggest challenges we faced during this phase. The reason for this decision
was that whenever we wanted to change part of the code in the one of the resource managers
(e.g. Flight Resource Manager) we had to make the change on all of the two other servers; so we
used similar resource managers for all resource managers, but the middleware accesses the
methods according to its role.
In this phase we implemented 2-phase commit (2PC) for the system. to implement this feature
we do the voting request in the middle ware from each server i.e. when the client requests a
transaction to commit, the middleware first sends VOTE REQUEST to the servers, the servers
first write their votes in a log and then send it to the middleware, if all votes are yes, middleware
send COMMIT to all of them and they would commit, otherwise it will send abort to those
servers which has sent YES vote.
3 As said earlier, Transaction Manager keeps track of accessed resource managers for each transaction. 4 As mentioned earlier, the datastore on each server was implemented as a hashtable and it contains information about
customers and the data related to each server (Flight , car , hotel)

We also extended the project to provide DURABILITY which means to be able to recover from
crashes.
First we had to simulate crashes. We implemented a method in middleware which can be called
by the client to decide in which step which server has to crash. This is done by setting a variable
indicating the step to crash in the target server, then we check this variable in different steps to
see if it’s the intended step to crash or not.
The crashes which are supported are the followings and they may happen in two layers:
middleware layer and server layer:
For transaction manager in middleware:
Crash before sending vote request
Crash after sending vote request and before receiving any replies
Crash after receiving some replies but not all
Crash after receiving all replies but before deciding
Crash after deciding but before sending decision
Crash after sending some but not all decisions
Crash after having sent all decisions
And for resource manager:
Crash after receive vote request but before sending answer
Crash after sending answer
Crash after receiving decision but before committing/aborting
Each resource manager creates three types of files: log file, recent file, data file. In the log file
the last status of transaction is stored. The most recent changes (add, delete and modify) on the
storage data items such as flight, car, room and customer info is kept in the recent file. And the
data file keeps the information of all items. During the process of a transaction, all files will be
stored as temporary files, if no crashes happen, the temporary files will be renamed to master
files. For restoring the lost information about the status of last transaction, these files will be
used.
We simulate the crash of the middleware with a long sleep time; actually in this case resource
manager transaction would be aborted. Crash and recovery for the resource managers is
implemented.
According to crashes there are different scenarios of recovery, but in all of them each server
must be able to connect back to the middleware (e.g. after the crash). This was again another
challenge. In the previous phase middleware connects to the server when it starts running. All 3
servers must be running before starting the middleware, but here change the architecture so the
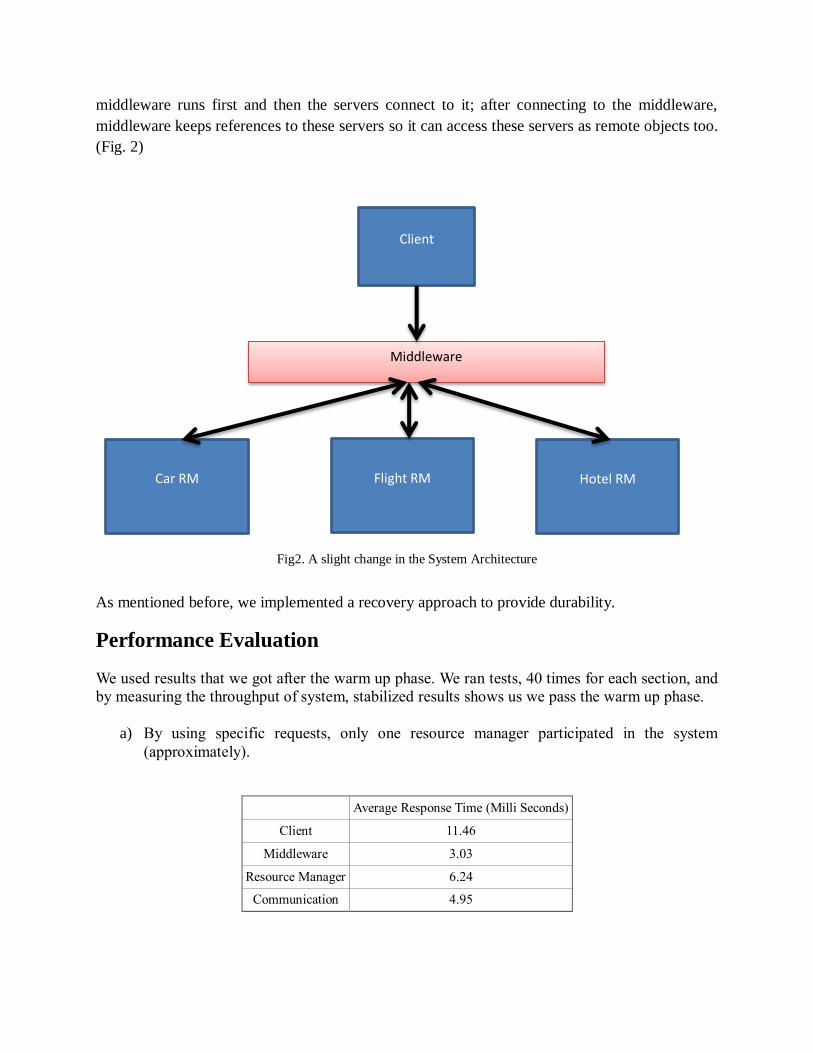
middleware runs first and then the servers connect to it; after connecting to the middleware,
middleware keeps references to these servers so it can access these servers as remote objects too.
(Fig. 2)
Fig2. A slight change in the System Architecture
As mentioned before, we implemented a recovery approach to provide durability.
Performance Evaluation
We used results that we got after the warm up phase. We ran tests, 40 times for each section, and
by measuring the throughput of system, stabilized results shows us we pass the warm up phase.
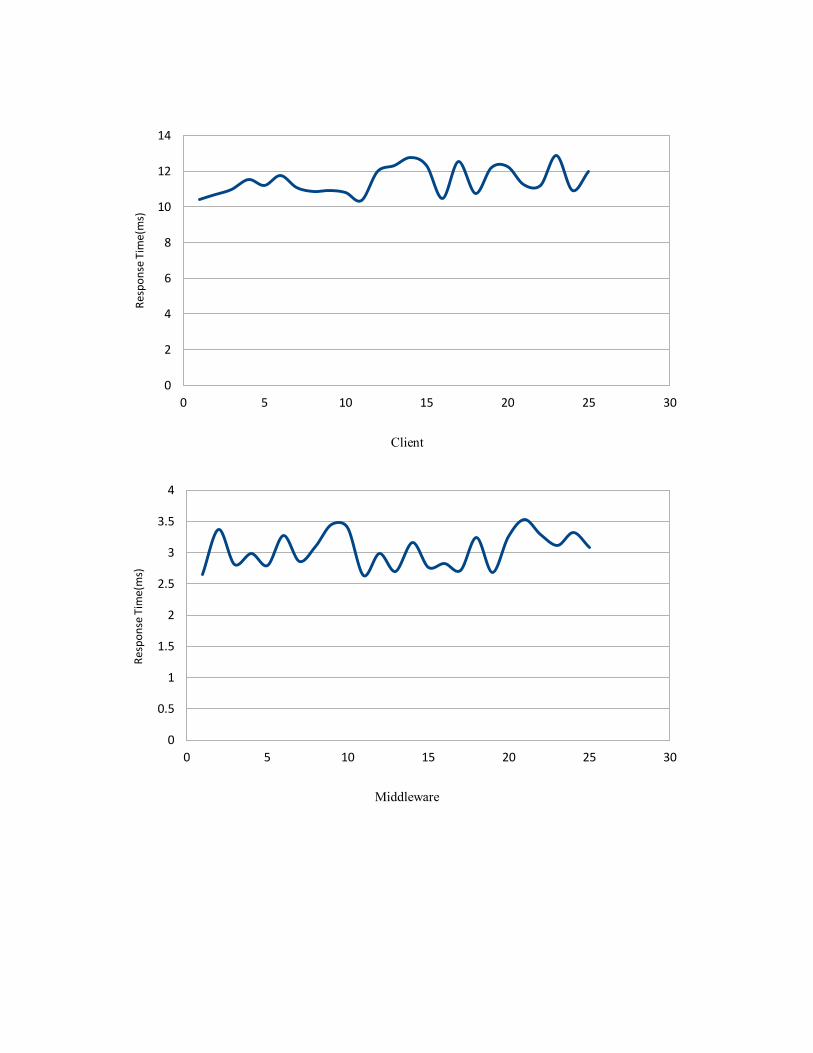
a) By using specific requests, only one resource manager participated in the system
(approximately).
Average Response Time (Milli Seconds)
Client 11.46
Middleware 3.03
Resource Manager 6.24
Communication 4.95
Client
Middleware
Car RM Flight RM Hotel RM
Client
Middleware
0 5 10 15 20 25 30
0
2
4
6
8
10
12
14R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
Res
po
nse
Tim
e(m
s)

Resource Manager
Communication
b)
0 5 10 15 20 25 30
0
1
2
3
4
5
6
7
8R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
1
2
3
4
5
6
Res
po
nse
Tim
e(m
s)
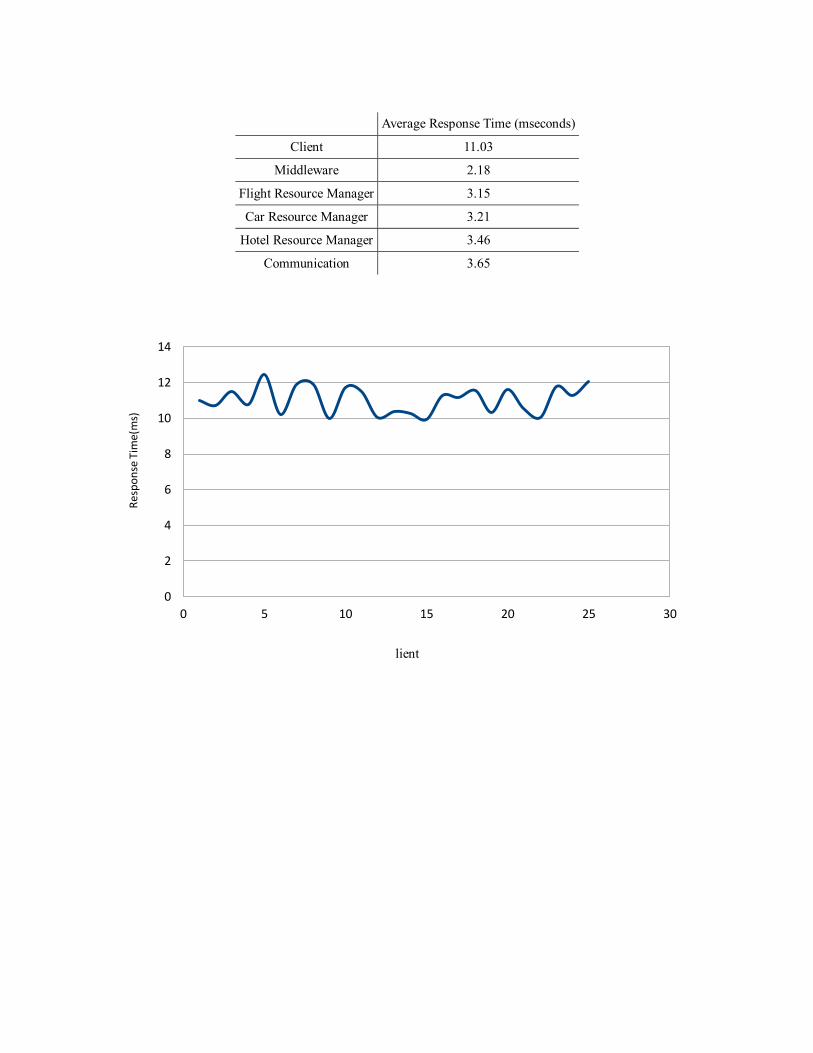
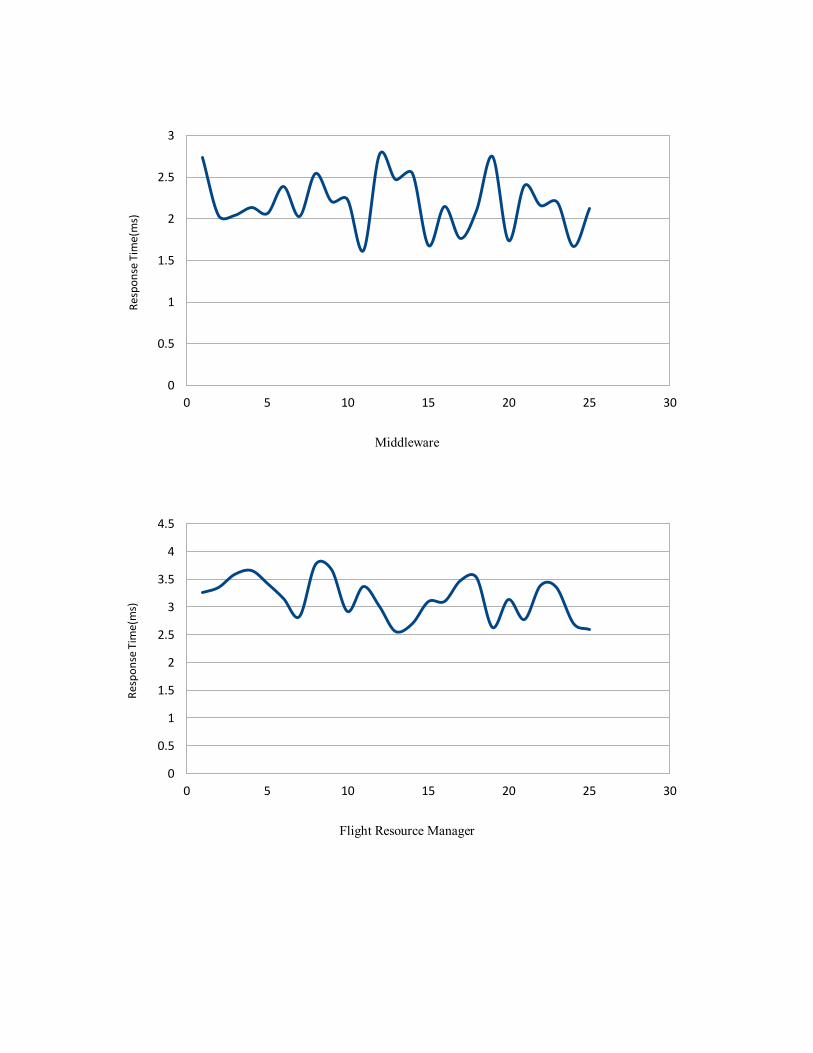
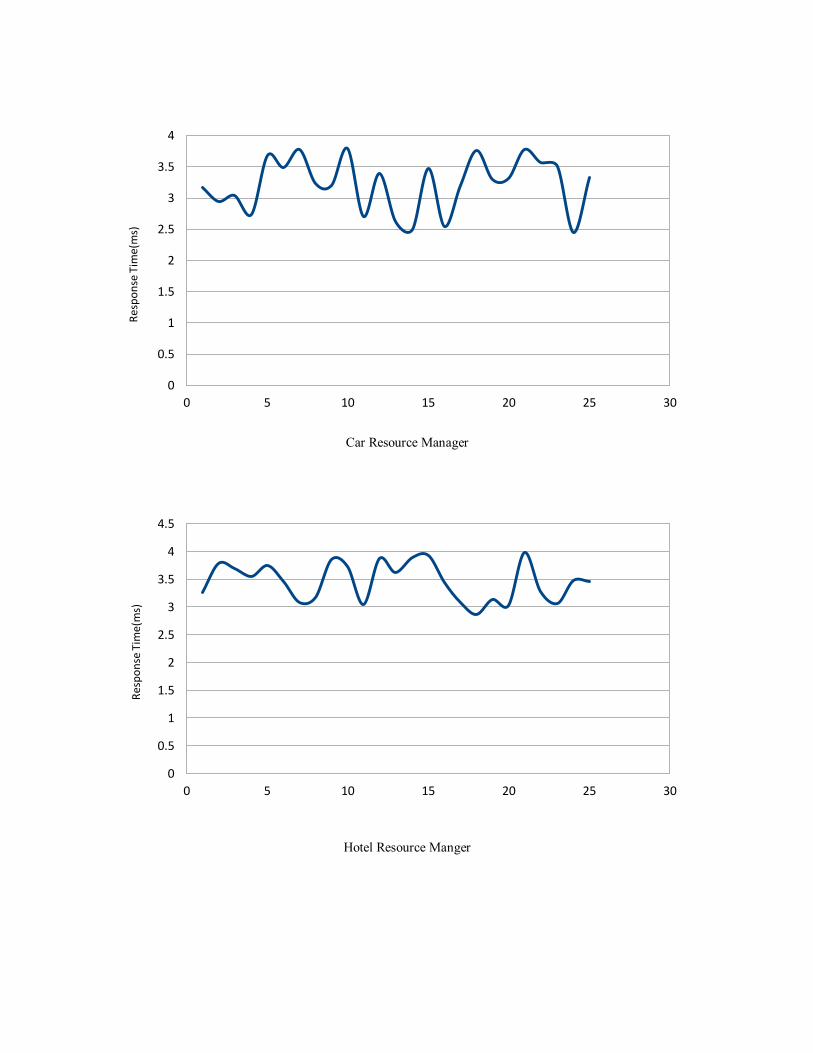
Average Response Time (mseconds)
Client 11.03
Middleware 2.18
Flight Resource Manager 3.15
Car Resource Manager 3.21
Hotel Resource Manager 3.46
Communication 3.65
lient
0 5 10 15 20 25 30
0
2
4
6
8
10
12
14
Res
po
nse
Tim
e(m
s)
Middleware
Flight Resource Manager
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Res
po
nse
Tim
e(m
s)
Car Resource Manager
Hotel Resource Manger
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Res
po
nse
Tim
e(m
s)
Communication
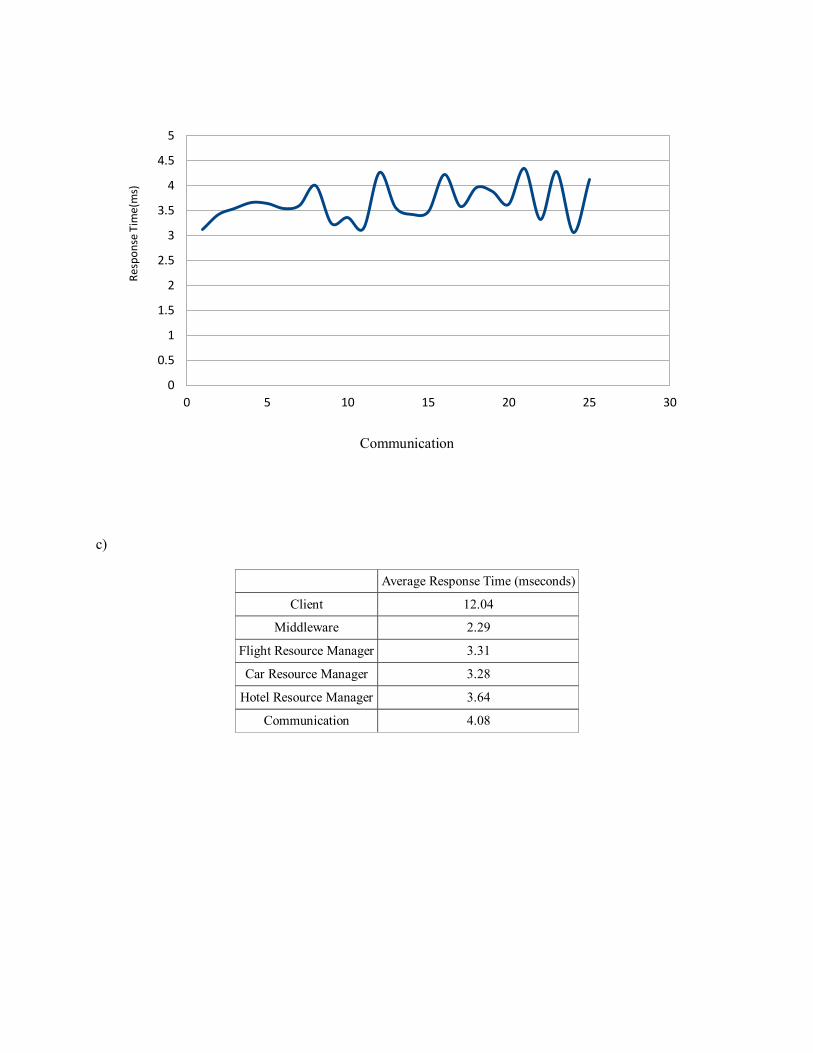
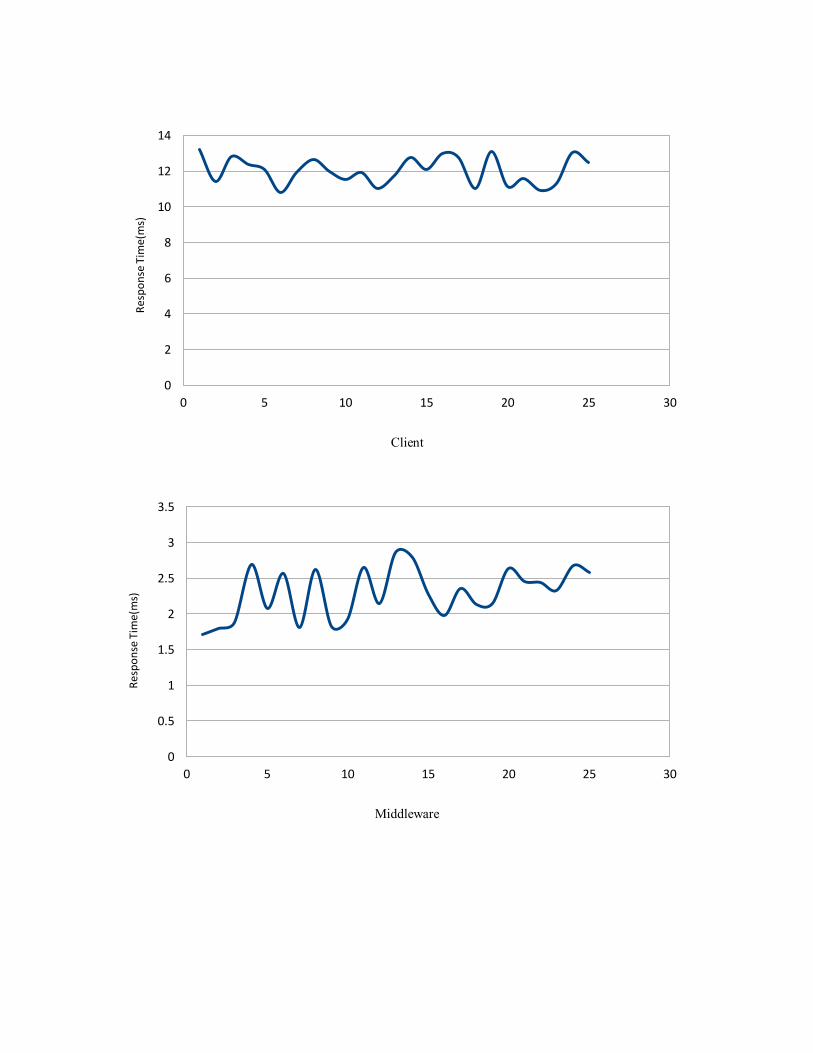
c)
Average Response Time (mseconds)
Client 12.04
Middleware 2.29
Flight Resource Manager 3.31
Car Resource Manager 3.28
Hotel Resource Manager 3.64
Communication 4.08
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5R
esp
on
se T
ime(
ms)
Client
Middleware
0 5 10 15 20 25 30
0
2
4
6
8
10
12
14R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
Res
po
nse
Tim
e(m
s)

Flight Resource Manager
Car Resource Manager
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Res
po
nse
Tim
e(m
s)
Hotel Resource Manager
Communication
d)
When the number of clients increases, response will increase too. Also when there is only one
resource manager, all requests are forwarded to one server which results lots of overhead.
0 5 10 15 20 25 30
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5R
esp
on
se T
ime(
ms)
0 5 10 15 20 25 30
0
1
2
3
4
5
6
Res
po
nse
Tim
e(m
s)

The charts illustrates that the Middleware response time is less than other parts such as clients,
resource managers and wasted time in communication.
Testing
Firstly it should be noted that for each phase of the project the features in that phase were tested
so when we tested the whole system we don’t focus very much on those features implemented in
previous phase(s).
The testing was done manually by entering commands in (a) client(s):
Phase 1:
For the first phase we started the whole system and by using one client we commanded the
middleware to create customers, to create items (flight, car, room) and then to do the
reservation and itinerary and we checked the results. We also deleted the customer and the
items to see the effects.
Phase 2:
In the second phase we did the same things as we did in the first phase but with use of two
clients entering commands at the same time. Besides, we checked the deadlocks and time-out
for conflicting commands and then we checked commit and abort to see if the effect of
transaction remains or not. We checked shutdown and also lock requesting to see if a
transaction holds an exclusive lock, what another transaction requesting a lock on the same
object would do.
Phase 3:
For the third phase of the project, we used 2 concurrent clients entering commands. In
addition to conflicting commands which were mentioned in the testing of the second phase
we tested those risky cases by use of crash command forcing the resource
manager/transaction manager to crash and then we started the resource manager to recover
from the files written on the disk to handle the last transaction and specify its status.
Copyright © 2022 FDOKUMEN




















