
USULAN PENELITIAN S1 - Fadly Rano Lado Revisi 1 (Dari Pak YOs)
51
USULAN PENELITIAN S1 IDENTIFIKASI SUARA MANUSIA MENGGUNAKAN MODULAR NEURAL NETWORK YANG DIMODIFIKASI UNTUK ABSENSI MAHASISWA Logo Undana (Diameter = 5,5, cm) Fadly Rano Lado 0706082987 JURUSAN ILMU KOMPUTER FAKULTAS SAINS DAN TEKNIK UNIVERSITAS NUSA CENDANA
-
Upload
melan-sixone -
Category
Documents
-
view
74 -
download
5
Transcript of USULAN PENELITIAN S1 - Fadly Rano Lado Revisi 1 (Dari Pak YOs)

USULAN PENELITIAN S1
IDENTIFIKASI SUARA MANUSIA MENGGUNAKAN MODULAR NEURAL NETWORK YANG DIMODIFIKASI UNTUK ABSENSI
MAHASISWA
Logo Undana
(Diameter = 5,5, cm)
Fadly Rano Lado
0706082987
JURUSAN ILMU KOMPUTER
FAKULTAS SAINS DAN TEKNIK
UNIVERSITAS NUSA CENDANA
KUPANG
2013

HALAMAN PERSETUJUAN
USULAN PENELITIAN S1
IDENTIFIKASI SUARA MENGGUNAKAN MNN YANG DIMODIFIKASI UNTUK ABSENSI MAHASISWA
Diusulkan oleh
Fadly rano lado
0706082987
Telah disetujui
Pada tanggal 12 november 2012
Pembimbing
Adriana Fanggidae
Pembimbing I
Apryanto Poli
Pembimbing II

DAFTAR ISI
ContentsDAFTAR ISI..........................................................................................................................3
BAB I...................................................................................................................................4
1.1. Latar Belakang....................................................................................................4
1.2. Rumusan Masalah..............................................................................................5
1.3. Batasan Masalah................................................................................................5
1.4. Tujuan.................................................................................................................6
1.5. Manfaat..............................................................................................................6
1.6. Tinjauan Pustaka................................................................................................6
1.7. Metodologi Penelitian........................................................................................8
1.8. Sistematika Penulisan.......................................................................................10
BAB II................................................................................................................................11
Transformasi Wavelet Diskrit........................................................................................11
Artficial Neural Network...............................................................................................11
Algoritma Training Backpropagation............................................................................11
Modular Neural Network.............................................................................................15
Particle Swarm Optimization........................................................................................27
BAB III...............................................................................................................................35
ANALISIS DAN PERANCANGAN SISTEM............................................................................35
DAFTAR PUSTAKA......................................................................................................36

BAB I
PENDAHULUAN
1.1. Latar Belakang
Absen merupakan sarana yang digunakan untuk mengetahui jumlah kehadiran anggota-anggotanya dalam suatu instansi. Dalam Universitas Nusa Cendana absen befungsi sebagai salah satu persyaratan penilaian apakah seorang mahasiswa layak lulus pada matakuliah yang ia programkan atau tidak. Absensi mahasiswa yang umumnya digunakan masih bersifat manual. Absensi ini mempunyai banyak kelemahan, diantaranya gampang dimanipulasi sehingga perlu adanya pengontrolan yang baik supaya tidak dimanipulasi. Salah satu metode yang dianggap baik untuk mengatasi masalah ini adalah dengan absensi menggunakan identifikasi suara.
Beberapa penelitian mengenai identifikasi suara menggunakan Artificial Neural Network (ANN) Multi Layer Percetron (MLP) dengan algoritma Backpropagation (BP) sebagai metode untuk training system (Agustini , 2006) (Yudho DN, et al., 2013). Akurasi yang didapat sudah mencapai 86% (Agustini ,2006).
MLP merupakan ANN yang mempunyai struktur jaringan monolithic. Hasil kerja jaringan ini baik pada ukuran input yang sangat kecil. Namun, kerumitan bertambah dan laju performa berkurang dengan bertambahnya dimensi input. Banyak ide memasukkan Modularity sebagai konsep dasarnya. Albrecht Schmidt dan Zuhair Bandar menggunakan pendekatan yang sama yaitu menggunakan Modular Neural Network (MNN). MNN merupakan ANN yang kompleks dan merupakan stuktur jaringan yang modular. Pada gambar 1.1 memperlihatkan perbandingan antara struktur jaringan monolithic dan struktur jaringan modular (Schmidt & Bandar, 1997).
Dari gambar 1.1 dapat dilihat bahwa performansi dari struktur jaringan modular dapat mengenali input yang memiliki noise lebih baik dari struktur jaringan monolithic. MNN ini menggunakan arsitektur MLP dengan algoritma BP untuk proses pembelajaran. BP memiliki kecepatan konvergen yang lambat, mudah masuk ke dalam nilai ekstrim parsial dan lemah kemampuannya dalam pencarian global (Misbahuddin, 2011). Salah satu pendekatan lain untu optimasi bobot adalah menggunakan algoritma evolusi Particle Swarm Optimization (PSO).

Gambar 1.1. Performansi dari input yang memiliki noise (Schmidt & Bandar,1997)
Misbahuddin (Misbahuddin, 2011) mengatakan bahwa untuk optimasi bobot pada ANN, PSO merupakan metode yang paling baik dibandingkan dengan Levenberg-Marquardt Back-Propagation (LMPROP), Resilient Back-Propagation (RPROP) dan Imperialist Competitive Algorithm (ICA).
Karena hal-hal tersebutlah penulis mencoba pendekatan lain untuk identifikasi suara dalam studi khasus absensi mahasiswa, yaitu dengan MNN yang dimodifikasi dengan algoritma evolusi PSO untuk training pada sistem.
1.2. Rumusan Masalah
1. Seberapa besar akurasi dari system barbasis MNN yang dimodifikasi dalam mengenali suara seseorang
2. Faktor-faktor apa saja yang mempengaruhi akurasi dari sistem ini3. Bagaimana cara terbaik pengambilan sample agar mendapatkan akurasi
yang baik
1.3. Batasan Masalah
Sample data untuk uji coba diambil dari sample suara mahasiswa-mahasiswa pada salah satu kelas mata kuliah di jurusan Ilmu Komputer Universitas Nusa Cendana.

1.4. Tujuan
1. Merancang dan membangun system identifikasi suara menggunakan MNN yang dimodifikasi untuk absen
2. Mengujicoba sistem yang dirancang untuk mengetahui sebarapa besar akurasinya
1.5. Manfaat
1. Mengetahui akurasi yang dapat dicapai oleh sistem2. Mendapatkan solusi pendekatan metode yang lain untuk identifikasi suara3. Mengetahui cara terbaik pengambilan sample untuk training sistem
1.6. Tinjauan Pustaka
Penelitian yang berhubungan dengan IDENTIFIKASI SUARA MANUSIA MENGGUNAKAN MODULAR NEURAL NETWORK YANG DIMODIFIKASI UNTUK ABSENSI MAHASISWA telah banyak dilakukan sebelumnya. Berikut ini merupakan table metode-metode yang sudah diteliti beserta metode yang diusulkan dalam penelitian ini.
Table 1.1. Tinjauan Pustaka
Metode ekstraksi
ciri
Metode pengenalan
pola
Arsitektur jaringan
Tipe struktur jaringan
Optimasi bobot
Citation
MFCC VFI5 - - - (Silvan & Muttaqien, 2011)
CWT, MFCC
ANN FF Monolithic BP (Al-Sawalmeh, et al., 2010)
DWT ANN MLP Monolithic BP (Yudho DN, et al., 2013)
DWT ANN MLP Monolithic BP (Agustini , 2006)DWT ANN FF Monolithic BP (Pawar & Badave,
2011)WT ANN MLP Modular BP (Shukla, et al., 2009)- ANN MLP Modular BP (Schmidt & Bandar,
1997)DWT ANN MLP Modular PSO USULAN

Dari table diatas dapat diulas dalam point-point dibawah ini :
Identifikasi suara yang dilakukan oleh Vicky Zilvan dan Furqon Hensan Muttaqien menggunakan metode algoritma Voting Feature Intervals (VFI) 5 dengan Mel Frequency Cepstrum Coefficients (MFCC) sebagai pengekstraksi ciri suara. Akurasi tertinggi yang didapat sebesar 97 % (data latih = 38, data uji = 20) untuk data suara tanpa noise. Sedangkan untuk suara bernoise dengan SNR sebesar 30 dB, akurasi tertinggi mencapai 81,5 % dan untuk suara bernoise dengan SNR sebersar 20 dB tingkat akurasi tertinggi mencapai 59 %. Dapat dilihat bahwa penggunaan metode diatas belum cukup handal untuk mengidentifikasi suara bernoise yang cukup tinggi (Silvan & Muttaqien,2011).
Penelitian yang dilakukan oleh Wael Al-Sawalmeh dan kawan-kawan menggunakan metode Feed Forward Backpropagation Neural Network (FFBPNN) dengan MFCC dan Continuous Wavelet Transform (CWT) untuk ekstraksi ciri. Penelitian ini menggunakan 1000 data sample dengan Akurasi tertinggi yang dicapai sebesar 99,7% pada SNR -6 dB (Al-Sawalmeh, et al.,2010).
Selanjutnya dalam penelitian yang dilakukan Theodorus Yudho D N dan kawan-kawan pada 10 orang responden mendapatkan tingkat akurasi tertinggi sebesar 97% (Yudho DN, et al., 2013). Sedangkan penelitian yang dilakukan Ketut Agustini dengan 100 data sample mendapatkan tingkat akurasi tertinggi sebesar 86 % (Agustini , 2006). Kedua penelitian ini sama-sama menggunakan metode ANN MLP dengan algoritma BP dan Diskret Wavelet Transform (DWT) untuk ekstraksi ciri.
Dalam penelitian yang dilakukan Pawar dan Badave, menggunakan metode FFBPNN dengan DWT mendapatkan tingkat akurasi tertinggi sebesar 98 % dengan 390 data sample (Pawar & Badave, 2011).
Penelitian yang dilakukan oleh Dr. Anupam Shukla dan kawan-kawan dengan 100 data sample mendapatkan akurasi tertinggi sebesar 97,5 %. Penelitian ini menggunakan MNN dan Wavelet Transform (WT) sebagai ekstraksi ciri (Shukla, et al., 2009).
Pada penelitian yang dilakukan Albrecht Schmidt dan Zuhair Bandar menjelaskan bahwa ANN MNN merupakan solusi dari masalah ruang input yang besar. Hasil dari penelitian ini memperlihatkan bahwa ANN MNN dapat mengenali input yang memiliki noise lebih baik daripada ANN yang memiliki struktur jaringan monolithic (Schmidt & Bandar, 1997).

Pendekatan yang dilakukan oleh penulis
Pada penelitian ini, penulis merancang system dengan pendekatan lain. Penulis mencoba alternative lain untuk identifikasi suara lebih khusunya untuk absensi mahasiswa dengan menggunakan metode Modular Neural Network yang dimodifikasi dengan algoritam PSO untuk training dan DWT sebagai ekstraksi cirinya.
1.7. Metodologi Penelitian
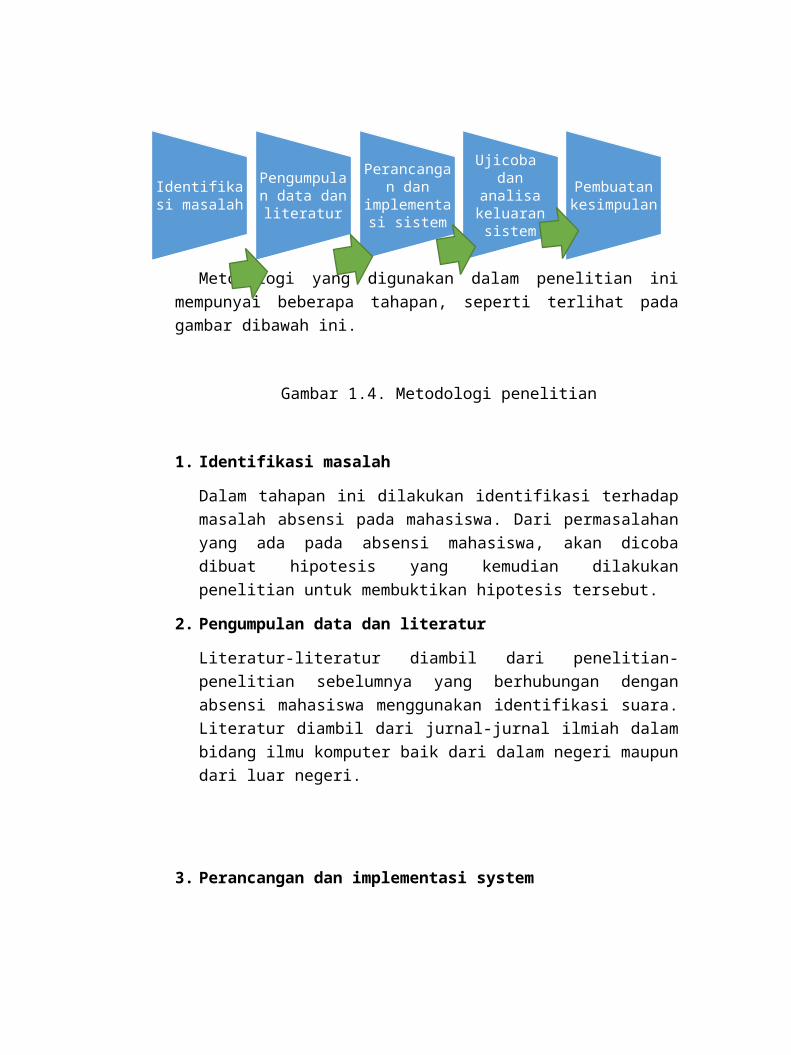
Metodologi yang digunakan dalam penelitian ini mempunyai beberapa tahapan, seperti terlihat pada gambar dibawah ini.
Gambar 1.4. Metodologi penelitian
1. Identifikasi masalah
Dalam tahapan ini dilakukan identifikasi terhadap masalah absensi pada mahasiswa. Dari permasalahan yang ada pada absensi mahasiswa, akan dicoba dibuat hipotesis yang kemudian dilakukan penelitian untuk membuktikan hipotesis tersebut.
2. Pengumpulan data dan literatur
Literatur-literatur diambil dari penelitian-penelitian sebelumnya yang berhubungan dengan absensi mahasiswa menggunakan identifikasi suara.
Identifikasi masalah
Pengumpulan data dan literatur
Perancangan dan
implementasi sistem
Ujicoba dan analisa
keluaran sistem
Pembuatan kesimpulan

Literatur diambil dari jurnal-jurnal ilmiah dalam bidang ilmu komputer baik dari dalam negeri maupun dari luar negeri.
3. Perancangan dan implementasi system
Hal-hal yang dilakukan meliputi perancangan bagan alir dari system dan perancangan antarmuka pemakai (user interface). Dalam perancangan bagan alir alir maupun antarmuka pemakai, dibagai menjadi dua tahapan.
Tahapan yang pertama adalah proses training yang terdiri dari 6 buah block. Block yang pertama adalah suara masukan, yaitu sinyal analog dari pembicara, block kedua sinyal analog dirubah dalam bentuk digital, block ketiga dilakukan proses blocking dan windowing yang bertujuan meminilmakan diskontinuitas sinyal pada bagian awal dan akhir sinyal suara, block keempat melakukan proses ektraksi ciri menggunakan metode DWT sehingga menghasilkan data yang berdimensi lebih kecil dengan tanpa merubah karakteristik sinyal suara tersebut, block kelima adalah proses training menggunakan metode MNN yang dimodifikasi dengan PSO, block terakhir merupakan output dari training yaitu suatu pola yang akan digunakan sebagai referensi untuk proses testing.
Tahapan yang kedua ialah proses testing yang terdiri dari 6 block juga. Block pertama sampai keempat sama dengan tahapan yang pertama. Block kelima merupakan proses maching data dengan pola, block terakhir adalah pemberian hasil dari proses matching.
4. Ujicoba dan analisa keluaran system
Ujicoba dilakukan pada salah satu kelas di jurusan Ilmu Komputer Universitas Nusa Cendana pada kurang lebih 25 orang mahasiswa. Ada empat cara pengambilan sample yang akan dilakukan untuk ujicoba. Yang pertama setiap mahasiswa mengucapkan sebuah kata (“SAYA”). Cara kedua setiap mahasiswa mengucapkan 2 kata (“ILMU KOMUTER”). Pada cara yang pertama dan kedua, pengambilan sample sebanyak 5 kali untuk suara yang tidak/sedikit memiliki noise dan 5 kali untuk suara yang memiliki banyak noise. Cara yang ketiga setiap mahasiswa mengucapkan kalimat yang panjang sebanyak 1 kali untuk suara yang tidak/sedikit memiliki noise dan 1 kali untuk suara yang memiliki banyak noise.

Kalimat panjang yang direkam akan dipotong dalam durasi tertentu sehingga menghasilkan beberapa sample data untuk setiap mahasiswa. cara yang terakhir mirip dengan cara ketiga, hanya perekaman dilakukan sebanyak 5 kali untuk suara yang tidak/sedikit memiliki noise dan 5 kali untuk yang memiliki banyak noise.
Sample data tersebut akan dianalisa keluaranya dari system yang akan dibuat sehingga bisa dibuat kesimpulan.
5. Evaluasi
Dari ujicoba dan anlisa keluaran yang dilakukan, akan dibuat kesimpulan seberapa efisienkah system yang dibuat dapat mengenali karakteristik suara seseorang dan berapa besar tingkat identifikasi yang dicapai.
1.8. Sistematika Penulisan
Sistematika penulisan pada penelitian ini adalah sebagai berikut :
BAB I : PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan, manfaat, keaslian penelitian, metodologi penelitian, tinjauan pustakan dan sistematika penulisan
BAB II : LANDASAN TEORI
Bab ini berisi dasar-dasar teori yang digunakan dalam penelitian
BAB III : ANALISIS DAN PERANCANGAN SISTEM
Dalam bab ini akan dianlisis permasalahan yang ada dan dibuat perancangan system berdasarkan analisis permasalahn
BAB IV : IMPLEMENTASI
Bab ini membahas implementasi dari system yang telah dibuat pada bab sebelumnya
BAB V : KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dari hasil penelitian yang telah dilakukan dan saran-saran untuk peneliti yang ingin meneliti masalah yang serupa

BAB II
LANDASAN TEORI
2.1. Transformasi Wavelet Diskrit
2.2. Artficial Neural Network
Artificial Neural Network (ANN) adalah salah satu metode penyelesaian masalah dalam kecerdasan tiruan yang memiliki karakteristik menyerupai jaringan syaraf biologis. Seperti halnya pada jaringan syaraf biologis, ANN tersusun dari sejumlah sel syaraf (neuron) yang saling dihubungkan dengan jalur koneksi (sinapsis). ANN menjanjikan dapat digunakan pada banyak aplikasi, terutama untuk menyelesaikan masalah rumit yang sangat tidak linier. Umumnya, ANN digunakan untuk pengenalan pola, pengolahan sinyal dan peramalan.
Terdapat berbagai jenis ANN yang masing-masing memiliki arsitektur, fungsi aktivasi dan perhitungan proses yang berbeda, seperti jaringan Hebbian, Perceptron, Adaline, Boltzman, Hopfield, Kohonen, Multi Layer Perceptron (MLP), Learning Vector Quatization (LVQ), dan lainnya. Dari seluruh jenis ANN, metode Multi Layer Perceptron (MLP) dengan algoritma Backpropagation merupakan metode yang paling populer digunakan karena terbukti mampu untuk menyelesaikan berbagai macam masalah.
X1
X2
Z1
Y
Z2
1 1
X3

2.2.1. Algoritma Training Backpropagation
Backpropagation merupakan algoritma pembelajaran yang terawasi dan biasanya digunakan oleh perceptron dengan banyak lapisan untuk mengubah bobot-bobot yang terhubung dengan neuron-neuron yang ada pada lapisan tersembunyinya. Algoritma backpropagation menggunakan error ouput untuk mengubah nilai bobot-bobotnya dalam arah mundur (backward). Untuk mendapatkan error ini, tahap perambatan maju (forward propagation) harus dikerjakan terlebih dahulu. Pada saat perambatan maju, neuron-neuron diaktifkan dengan menggunakan fungsi aktivasi yang dapat dideferensiasikan, seperti sigmoid.
Arsitektur jaringan backpropagation dapat dilihat pada gambar dibawah ini :
Algoritma backpropagation :
Inisialisasi bobot (ambil bobot awal dengan nilai random yang cukup kecil).
Tetapkan : Maksimum Epoh, Target Error, dan Learning Rate (a).
Inisialisasikan : Epoh = 0.
Kerjakan langkah-langkah berikut selama (Epoh < Maksimum Epoh) dan (MSE < Target Error) :
1. Epoh = Epoh + 1
2. Untuk tiap-tiap pasangan elemen yang akan dilakukan pembelajaran kerjakan :
Feedforward:
a. Tiap-tiap unit input ( X i i=1,2,3 , …,n ) menerima sinyal x i dan meneruskan sinyal tersebut ke semua unit pada lapisan yang ada di atasnya (lapisan tersembunyi).
b. Tiap-tiap unit pada suat lapisan tersembunyi ( Z i , j=1,2,3 ,…, p ) menjumlahkan sinyal-sinyal input terbobot:
z¿ j=b1 j+∑i=1
n
xi v ij
Gunakan fungsi aktivasi untuk menghitung sinyal outputnya:

z j=f ( z¿ j )
dan kirimkan sinyal tersebut ke semua unit di lapisan atasnya (unit-unit output).
c. Tiap-tiap unit output (Y k , k=1,2,3 ,…,m ) menjumlahkan sinyal-sinyal input terbobot.
y¿k=b 2k+∑i=1
p
zi w jk
Gunakan fungsi aktivasi untuk menghitung sinyal outputnya:
yk=f ( y¿k )
Dan kirimkan sinyal tersebut ke semua unit di lapisan atasnya (unit-unit ouput).
Catatan:
Langkah (b) dilakukan sebanyak jumlah lapisan tersembunyi.
Backpropagation
d. Tiap-tiap unit output (Y k , k=1,2,3 ,…,m ) menerima target pola yang berhubungan dengan pola input pembelajaran, hitung informasi errornya:
δ 2k=(t k− yk ) f ' ( y¿k )
φ 2 jk=dk z j
β 2k=dk
Kemudian hitung koreksi bobot (yang nantinya akan digunakan untuk memperbaiki nilai w jk).
∆ w jk=α φ jk
Hitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai b 2k):
∆ b 2k=α βk

Langkah (d) ini juga dilakukan sebanyak jumlah lapisan tersembunyi, yaitu menghitung informasi error dari suatu lapisan tersembunyi ke lapisan tersembunyi sebelumnya.
e. Tiap-tiap unit tersembunyi ( Z j , j=1,2,3 , …, p ) menjumlahkan delta inputnya (dari unit-unit yang berada pada lapisan di atasnya):
δ ¿ j=∑k=1
m
δ k w jk
Kalikan nilai ini dengan fungsi turunan dari fungsi aktivasinya untuk menghitung informasi error:
δ 1 j=δ ¿ j f ' ¿
φ 1ij=δ j x j
β 1 j=δ 1 j
Kemudian hitung koreksi bobot (yang nantinya akan digunakan untuk memperbaiki nilai v ij).
∆ v ij=α φ1ij
Hitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai b 1 j).
∆ b1 j=α φ 1 j
f. Tiap-tiap output (Y k , k=1,2,3 ,…,m ) memperbaiki bias dan
bobotnya ( j=0,1,2 , …, p ):
w jk (baru)=w jk ( lama )+∆ w jk
b 2k (baru )=b 2k ( lama )+∆ b2k
Tiap-tiap unit tersembunyi ( Z j , j=1,2,3 , …, p ) memperbaiki bias
dan bobotnya ( i=0,1,2 ,…, n ):
V ij ( baru)=V ij ( lama )+∆ V ij
b 1 j (baru )=b1 j ( lama )+∆ b 1 j
3. Hitung MSE.

Inisialisasi bobot awal secara random
Pemilihan bobot awal sangat mempengaruhi jaringan syaraf dalam mencapai minimum global (atau mungkin hanya local saja) terhadap nilai error, serta cepat tidaknya proses pelatihan menuju kekonvergenan. Apabila nilai bobot awal terlalu besar, maka input ke setiap lapisan tersembunyi atau lapisan output akan jatuh pada daerah dimana turunan fungsi sigmoid akan sangat kecil. Sebaiknya, apabila nilai bobot awal terlalu kecil, maka input ke setiap lapisan tersembunyi atau lapisan output akan sangat kecil, yang akan menyebabkan proses pelatihan akan berjalan sangat lambat. Biasanya bobot awal yang diinisialisasi secara random dengan nilai antara -0.5 samapai 0.5 (atau -1 sampai 1, atau interval yang lainnya).
2.2.2. Modular Neural Network
Arsitektur Jaringan
System jaringan yang diusulkan terdiri dari sebuah lapisan modul input dan sebuah tambahan decision modul. Semua sub jaringan adalah MLP, hanya jumlah input dan jumlah output dari modul yang ditentukan oleh system. Struktur intenal seperti jumlah hidden layer dan jumlah neuron dalam setiap hidden layer dapat ditentukan secara bebas dari keseluruhan arsitektur.
Setiap variable input terhubung hanya dengan satu modul input yang hubungannya dipilih secara acak. Output dari semua modul input dihubungkan ke jaringan decision. Dalam penelitian ini dimensi dari vector input dilambangkan dengan l dan jumlah kelas dilambangkan dengan k.
Untuk menentukan sebuah jaringan modular perlu untuk menetapkan baik jumlah input per modul input ataupun jumlah modul input. Parameter-parameter ini bergantung satu sama lain. Disini diasumsikan bahwa jumlah input per modul pada layer pertama dilambangkan dengan n; jumlah modul input dalam input
layer dapat dihitung dengan m=⌈ ln⌉.
Asumsi selanjutnya adalah bahwam=l ∙ n. Jika hal ini tidak terjadi, bagian sisa input dapat dihubungkan ke input yang tetap/konstan; Dalam implementasi pada model, semua input bebas dihubungkan ke nilai yang tetap ‘0’. Dengan alternative jika itu akan memungkinkan untuk mengubah ukuran satu modul atau sekelompok modul.

Setiap modul dalam layer input dapat mempunyai baik k ataupun ⌈ log2 k ⌉ output. Jaringan dengan k output lanjutan ditunjukkan sebagai perwakilan lanjutan yang besar. Itu hanya berguna jika jumlah kelas sangat kecil. Untuk masalah dengan jumlah kelas, perwakilan lanjutan yang kecil (⌈ log2 k ⌉) adalah lebih sesuai.
Dari sebuah sudut pandang teory informasi menunjukkan bahwa perwakilan lanjutan kecil akan cukup, Karen hanya jumlah neuron output yang diperlukan untuk mewakili semua kelas dalam sebuah code biner.
Jaringan decision mempunyai (m ∙k ) atau (m ∙ ⌈ log2 k ⌉ ) input, bergantung pada perwakilan lanjutan yang dipakai. Jumla output adalah k , satau neuron output untuk setiap kelas. Struktur dari jaringan modular dapat dilihat pada gambar 2.1. yang menggunakan sebuah perwakilan lanjutan yang kecil. Fungsi π : X → X memberikan sebuah permutasi dimana X={1…l }. Permutasi ini dipilih secara acak dan tetap/konstan untuk sebuah jaringan .
Definisi : Sebuah Modul
Sebuah modul adalah sebuah jaringan syaraf multi layer feedforward yang didefinisikan dengan 3-tuple :
M=( a ,b ,H )
Dimana :
a = jumlah input dari modul
b = jumlah node outputℋ = sebuah list berisi jumlah neuron dari setiap hidden layer
Contoh :
Sebuah modul multilayer Perceptron dengan 8 input, 12 neuron pada hidden layer pertama, dan 10 neuron pada hidden layer kedua, dan 4 output dapat digambarkan sebagai berikut : M=( 8 ,4 , [ 12, 10 ] ).
Definisi : sebuah Modular Neural Network

Sebuah MNN adalah satu set interkoneksi modul yang didefinikasikan dengan 7-tuple :
N= (l , k , m ,r , π , I , D )
Dimana :
l = jumlah input
k = jumlah kelas
m = jumlah modul dalam input layer
r = tipe perwakilan lanjutan (r ϵ {small , large } )
π = fungsi permutasi
I = input layer modul
D = decision modul
Contoh :
Sebuah jaringan modular dengan 210 input, 4 kelas, 15 modul input (masing-masing memiliki 14 input, 1 hidden layer dengan 6 neuron dan 2 output), sebuah perwakilan lanjutan kecil, sebuah fungsi permutasi p, dan sebuah jaringan decision (dengan 30 input, 1 hidden layer dengan 10 neuron dan 4 neuron output) dapat digambarkan sebagai berikut :
N= (210 , 4 , 15 , small , p ,(14 ,2 ,[6]) ,(30 , 4 , [10]))
Training Sistem
Training berlangsung dalm 2 tahap menggunakan algoritma Backpropagation.
Dalam fase yang pertama, semua sub jaringan dalam input layer akan ditraining. Training set individual untuk setiap sub jaringan dipilih dari traning set original dan terdiri dari komponen-komponen vector original dimana dihubungkan ke jaringan tertentu (sebagai sebuat vector input) bersama dengan perwakilan kelas output yang diinginkan dalam biner atau 1-out-of-k coding.

Dalam fase kedua decision jaringan akan ditraining. Untuk menghitung training set, setiap pola input original diterapkan ke layer input; menghasilkan vector bersama-sama dengan kelas output yang diinginkan (perwakilan dalam 1-out-of-k coding) membentuk pasangan training untuk decision modul.
Untuk mempermudah deskripsi/penjelasan pada training, sebuah perwakilan lanjutan kecil akan digunakan. Untuk selanjutkan diasumsikan bahwa fungsi permutasi adalah fungsi identitas ( x )=x .
Training set (TS) original adalah : (x1j , x2
j , …. , x lj , d j), dan dimana x i
j∈R adalah i
th komponen dari j th vector input, d j adalah nomor kelas, j = 1,….,t, dimana t adalah jumlah contoh data training.
Modul MLPi dihubungkan pada :
x i ∙n+ 1 , x i∙ n+2 , …, x ( i+1) ∙ n
Training set TSi untuk modul MLPi adalah :
( xi ∙ n+1j , x i ∙n+2
j , x i ∙n+3j , …, x (i+1 ) ∙n
j ;dBINj )
Untuk semua j=1 ,…, t , dimana d BINj adalah representasi kelas output dalam kode
biner.
The mapping performed by the input layer is denoted by :
Φ : Rn∗m→ Rm∗⌈ log2 k ⌉
Algoritma Training :
Tahap 1 Training Layer Input :1. Pilih training set TSi dari training set original TS, untuk semua
i=0 …m−1.2. Training semua modul MLPi pada TSi menggunakan algoritma
BP. Tahap 2 Training Decision Jaringan :
1. Hitung respon r pada layer pertama untuk setiap vector input j.
r j=Φ ( (x1j , x2
j , …, x lj ) )
2. Bangun training set untuk jaringan decision
TSd= {(r j ;dBITj )∨ j=1 ,…,t }
3. Training jaringan decision pada set TSd menggunakan algoritma BP.

Figure 2.1
Training set untuk jaringan decision :
(Φ ( (x1j , x2
j , …, x lj) );d BIT
j ) dan j=1 ,…, t . Dimana d BITj adalah representasi kelas
output dalam 1-our-of-k kode.
The mapping of the decision network is denoted by :
Ψ : Rm∗⌈ log2 k ⌉→ Rk
Algoritma training disimpulkan dalam Figure 2.1
Training pada setiap modul pada layer input adalah bebas untuk semua modul yang lain sehingga dapat diselesaikan parallel. Training akan berhenti baik ketika setiap modul telah mencapai eror yang cukup kecil atau menetapkan nilai nilai maximum epoh. Ini akan menjaga setiap modul bebas.
Alternative training dapat berhenti jika error dari keseluruhan modul sudah cukup kecil atau sudah mencapai nilai maximum epoh. Diasumsikan bahwa training berlangsung simultan langkah demi langkah dalam semua modul.
Perhitungan Output
Perhitungan output juga berlangsung dalam 2 tahap. Yang pertama sub-sub vector input untuk setiap modul dipilih dari vektor input yang digunakan berdasarkan fungsi permutasi dan intermediate output yang dihitung oleh semua modul. Dalam tahap yang kedua semua output dari layer input digunakan sebagai input pada jaringan decision; kemudian hasil akhir dihitung.
Diagram dari keseluruhan jaringan dapat ditunjukkan dengan :
Φ∘Ψ : R l→ Rk
Respon r untuk sebuah input tes (a1 , a2, …, al ) ditentukan oleh rumus berikut :
r=Ψ (Φ ( a1, a2 , …, al ))

Output dimensi k pada decision modul digunakan untuk menentukan nomor kelas dari input yang diberikan. Dalam percobaan neuron output dengan respon yang tinggi dipilih sebagai perhitungan kelas. Perbedaan antara neuron ini dan neuron level dibawahnya boleh dapat diambil sebagai ukuran akurasi.
Analisis dari Model Baru
Dalam bagian ini, beberapa aspek dari model dipertimbangkan. Analisis ini menampilkan beberapa latar belakang dari kelakuan jaringan, dan juga mengungkapkan pertanyaan : mengapa jaringan bekerja?, fokus pada aspek kecepatan, pembelajaran dan generalisasi/penyamarataan. Teori limitasi pada model juga dipertimbang.
Struktur jaringan yang diusulkan didasarkan pada modul dengan setiap input terkoneksi pada sebuah single modul. Fitur ini menghasilkan sebuah prosedur training yang lebih cepat dan memajukan performa generalisasi, tetapi juga memperkenalkan batas-batas tertentu. Jumlah koneksi dalam jaringan modular adalah signifikan lebih kecil dibandingkan dengan sebuah arsitektur monolithic. Perbandingan yang konkrit ditunjukkan dalam bab 7.
Kecepatan jaringan
Untuk analisis, dibawah ini dibuat sebuah asumsi :
Modul yang digunakan dalam MNN hanya mempunyai satu hidden layer dengan 4 neuron
Representasi lanjutan panjang digunakan pada system MNN ( untuk representasi yang pendek jumlah bobot bahkan bisa lebih kecil )
Fungsi v mengambil sebuah modul dan mengembalikan jumlah bobot-bobot koneksi. (contoh : v ( M )=i, dimana M=( a ,b , [h ] ) dan i=a ∙ h± h ∙b untuk
sebuah modul dengan satu hiden layer dan dimana M=(a , b , [h1 ,h2 ]) dan
i=a ∙ h1 ± h1 ∙ h2 ±h ∙b untuk sebuah jaringan dengan dua hidden layer) Fungsi τ mewakili waktu yang dibutuhkan dalam traning sebuah modul. Asumsi
analisis bahwa τ hanya bergantung pada jumlah bobot dan bertambah secara monoton i> j⟹ τ ( i )>τ ( j ). ini bearti waktu traning lebih lama jika ada bobot lebih dalam jaringan. Dalam sebuah system yang nyata, itu biasanya bergantung pada parameter lain dengan baik.

Training arsitektur jaringan yang baru lebih cepat dari training sebuah jaringan monolithic modular pada masalah yang sama untuk 3 alasan :
1. Jumlah koneksi dalam jaringan modular dan karenanya jumlah bobot lebih kecil dari pada sebuah MLP monolithic. Bobot yang lebih sedikit memimpin pada operasi yang sedikit selama training backpropagation. Hasilnya secara langsung dalam sebuah prosedur pembelajaran yang cepat.Mempertimbangkan sebuah jaringan modular dengan 10 modul input, masing-masing dengan n input, hm=4 neuron pada hidden layer, dan k output. Decision modul mempunyai (10 ∙ k ) input, hm=4 neruon pada hidden layer, dan
k output. Ini ditunjukkan dengan : M mod=(l , k ,10 , (n , k , [hm ]) , (10 , k , [hm ] )), dimana l=10 ∙ n.Sebuah jaringan monolithic dengan jumlah input yang sama dan output, dan dengan 2 hidden layer masing-masing dengan hs neuron dapat ditunjukan
dengan : BP=(l , k , [hs , hs ])Untuk jumlah neuron harus sama dalam dua jaringan :
10 ∙ ( hm+1 )+hm+k=2∗hs+k
⟹hs=11 hm+10
2=27
Jumlah bobot dalam setiap jaringan adalah :
v ( BP )=27 ∙+27 ∙ k+729
v ( M mod )=4 ∙ l+84 ∙ k
Jika input cukup besar, maka :
l>32+2.5 ∙ k
Kemudian
v ( BP )>v ( M mod )
Oleh karena itu
τ ( v ( BP ) )>τ (v ( M mod ))

Sejak τ bertambah secara monoton.
2. Modul dalam input layer adalah saling bebas, jadi training dapat dilakukan secara parallel. Waktu training pada implementasi semua parallel adalah waktu maksimum yang dibutuhkan untuk satu kali training dari modul input ditambah waktu untuk training decision modul. Oleh karena itu jumlah bobot yang dapat dianggap sebagai factor waktu dalam sebuah training parallel adalah hanya jumlah bobot dalam sebuah modul input ditambah jumlah bobot dalam decision modul. Asumsi M i adalah sebuah modul dalam layer input dan M d adalah decision modul, waktu training T dapat dihitung sebagai berikut :
T=τ (v ( M i ))+τ (v ( M d ))
Asumsi dari contoh (M moddanBP) diatas meningkat secara signifikan. Jumlah input per modul diasumsikan lebih besar dari delapan(n>8 ). Jumlah bobot untuk dipertimbangkan pada training dalam setiap jaringan adalah :
v ( BP )=27 ∙ l+27 ∙ k+729
v ( M mod )=2∙ ( 4 ∙l+4 ∙ k )
Rasio antara jumlah bobot untuk training (k=2 , n>8 , l=10 ∙ n ) :
v ( BP )v ( M mod )
=270∙ n+7838∙ n+16
> 270 ∙ n+78310 ∙ n
> 270 ∙ n10 ∙ n
=27
Jumlah bobot sebagai pertimbangan untuk waktu yang dibutuh pada training jaringan adalah kurang lebih 27 kali lebih kecil dalam sebuah monolithic MLP.
3. Membagi vector training ke dalam bagian-bagian sering membantu untuk focus pada atribut yang umum. Pertimbangkan contoh berikut :

Original Set Set MLP1 Set MLP1
x1 x2 x3 x4 x5 x6 y x1 x2 x3 y x4 x5 x6 y0 0 0 0 0 1 0 0 0 0 0 0 0 1 00 0 0 0 1 0 0 0 0 0 0 0 1 0 00 0 0 1 0 0 0 0 0 0 0 1 0 0 01 1 0 1 0 1 1 1 1 0 1 1 0 1 11 0 1 1 0 1 1 1 0 1 1 1 0 1 10 1 1 1 0 1 1 0 1 1 1 1 0 1 1
Kelas ‘0’ ditentukan oleh x1, x2, dan x3; dimana akan dipelajari dengan sangat cepat oleh MLP1, yang mana melihat tuple ini ‘0 0 0 : 0’ tiga kali selama satu putaran training.
Begitu juga kelas ‘1’ ditentukan oleh x4, x5, dan x6 yang mana akan dipelajari dengan cepat oleh MLP2.
Tidak mungkin bahwa data set pada dunia nyata mempunyai struktur yang sama sepeti pada contoh. Namun ini dapat menghasilkan perbaikan yang signifikan, terutama dengan input dimensi yang besar.
Masalah Pembelajaran
Membagi training set dalam sub bagian dapat juga membawa masalah. Jumlah vector input setara dengan nilai output yang berbeda kemungkinan dapat meningkat, secara khusus pada modul dengan jumlah sebuah variable input yang kecil. Mempertimbangkan kasus yang sangat buruk : masalah keseimbangan 4-Bit :
Original Set Set MLP1 Set MLP1
x1 x2 x3 x4 y x1 x2 y x3 x4 y0 0 0 0 0 0 0 0 0 0 00 0 0 1 1 0 0 1 0 1 10 0 1 0 1 0 0 1 1 0 10 0 1 1 0 0 0 0 1 1 00 1 0 0 1 0 1 1 0 0 10 1 0 1 0 0 1 0 0 1 00 1 1 0 0 0 1 0 1 0 00 1 1 1 1 0 1 1 1 1 11 0 0 0 1 1 0 1 0 0 1

1 0 0 1 0 1 0 0 0 1 01 0 1 0 0 1 0 0 1 0 01 0 1 1 1 1 0 1 1 1 11 1 0 0 0 1 1 0 0 0 01 1 0 1 1 1 1 1 0 1 11 1 1 0 1 1 1 1 1 0 11 1 1 1 0 1 1 0 1 1 0
Asumsi 2 modul input; MLP1 dihubungkan pada x1 dan x2, MLP2 dihubungkan pada x3 dan x4. Hasil training set untuk setiap 2 modul input mempunyai 162-Bit vector, masing-masing dari empat vektor yang berbeda muncul dua kali dengan output yang diinginkan ‘1’, dan dua kali dengan output yang diinginkan ‘0’. Hal ini tidak mungkin bagi modul individu untuk membedakan kasus ini, jadi setelah training respon modul akan menjadi ‘0.5’ untuk pola input apa saja. Semua informasi telah hilang dalam layer input, jadi tidak ada keputusan yang mungkin.
Untuk mendiskusikan masalah ini lebih jauh, dibutuhkan definisi berikut : P ( y=a ) adalah kemungkinan dari output variable y yang memiliki nilai a. Dan P ( y=a∨x=b ) adalah kemungkinan yang bergantung pada y=1jika x=b.
Definisi : set data pada variable-variabel statistic netral
Menimbang fungsi f (x1 , …, xn, …, xm)= y. sebuah subset input {x1 , …, xn } dengan n<m disebut statistic netral jika pengetahuan dari nilai variable ini tidak meningkatkan pengetahuan dari hasil y .
Secara formal : set variable input {x1 , …, xn } adalah statistic netral jika :
P ( y=a )=P ( y=a∨x1=b1∧…∧ xn=bn)
Jika keseluruhan set dari variable input dan semua kemungkinan subset untuk semua modul adalah statistic netral, jaringan tidak dapat mempelajari tugas. Jika hanya beberapa dari modul yang memenuhi sebuah statistic netral set pada input variable, jaringan dapat menunjukkan hasil yang memuaskan.
Dalam [ston95], itu menunjukkan bahwa jaringan monolithic multi layer feedforward dapat mempelajari masalah statistic netral, tetapi jaringan tidak dapat genaralisasi masalah tersebut. Keadaan ini terdengar sangat tidak sama pada kehidupan nyata dan harapannya dapat diteliti selama percobaan ini.

Secara khusus dalam tugas-tugas dengan ruang input yang besar, seperti pengenalan gambar, masalah ini dapat diabaikan. Dalam tugas-tugas dengan sebuah atribut dengan jumlah input yang kecil, satu cara untuk mengurangi kemungkinan mendapatkan statistic netral input set, adalah mengkodekan kembali data dalam code yang jarang.
Generalisasi
Kemampuan untuk generalisasi adalah sifat utama dari ANN. Hal ini adalah bagaimana ANN dapat menangani input yang belum dipelajari tetapi mirip dengan input yang terlihat selama fase training. Usulan arsitektur menggabungkan 2 metode generalisasi.
Metode yang pertama adalah membangun MLP. Setiap jaringan mempunyai kemampuan untuk menggeneralisasi data pada ruang input. Tipe generalisasi ini biasanya untuk koneksi sistem-sistem.

Metode generalisasi yang kedua adalah berhubungan dengan arsitektur dari jaringan yang diusulkan. Ini adalah satu cara generalisasi sesuai dengan kemiripan pola-pola input. Metode ini ditemukan dalam logical neural network [patt96, p127ff].
Untuk menjelaskan tingka laku secara lebih konkrit mempertimbangkan contoh sederhana berikut dari pengenalan sistem.
Diasumsi sebuah input retina 3x3 dengan arsitektur ditunjukkan dalam diagram 5.4. masing-masing sembilan input membaca sebuah nilai yang terus menerus antara 0 dan 1, sesuai dengan rekaman level keabuan (hitam =1; putih =0).
Jaringan perlu dilatih untuk mengenali huruf yang mudah ‘H’ dan ‘L’ menggunakan training set yang ditunjukkan dalam diagram 5.5(a). output yang diinginkan pada jaringan input adalah ‘0’ untuk huruf ‘H’ dan ‘1’ untuk huruf ‘L’.
Subset training untuk jaringan MLP0, MLP1, dan MLP2 adalah :
MLP0 MLP1 MLP2
(1,0,1;0) (1,1,1;0) (1,0,1;0)(1,0,0;1) (1,0,0;1) (1,1,1;1)
Setelah training di layer pertama pada jaringan, diasumsi bahwa perhitungan output adalah ekuivalen dengan output yang diinginkan. Hasil training set untuk decision network adalah :
(Φ (1,0,1,1,1,1,1,0,1 ) ;1,0 )=(0,0,0 ;1,0 )
(Φ (1,0,0,1,0,0,1,1,1 ) ;0,1 )=(1,1,1;0,1 )

Setelah training pada decision network, diasumsikan respon system pada training set sebagai berikut :
r H=Ψ (Φ (1,0,1,1,1,1,1,0,1 ) )=Ψ (0,0,0 )=(1,0 )
r L=Ψ ( Φ (1,0,0,1,0,0,1,1,1 ) )=Ψ (1,1,1 )= (0,1 )
Untuk menunjukkan perbedaan efek pada generalisasi tiga karakter yang terdistorsi, ditunjukkan dalam gambar 5.5(b) yang digunakan sebagai set tes.
Karakter pertama tes generalisasi dalam modul input, tes kedua generalisasi pada jumlah sub pola yang benar, dan karakter yang ketiga adalah kombinasi keduanya. (diagram dalam vector input adalah sesuai dengan level keabuan dalam pola ; output diambil dari neural network khusus/tersendiri).
r1=Ψ (Φ (0.9,0 .2,0.1,0 .7,0 .2,0 .1,0 .5,0.5,0 .5 ) )
¿Ψ (0.95,0 .86,0 .70 )=(0.04,0 .96 )⟹ ' L'
r2=Ψ (Φ (1.0,0.0,1 .0,1 .0,0.0,1 .0,1 .0,0.0,1 .0 ) )
¿Ψ (0,0.49,0 )=(0.91,0 .09 )⟹ ' H '
r3=Ψ ( Φ (0.9,0 .2,0.2,0 .9,0 .5,0 .2,0 .9,0 .2,0.9 ) )
¿Ψ (0.92,0 .65,0 .09 )=(0.15,0 .89 )⟹ ' L'

2.3. Bacterial Foraging Optimazation Algorithm (BFOA)
Pada tahun 2002, Passion mengusulkan sebuah algoritma untuk distribusi optimasi dan control. Algoritma tersebut adalah BFOA. BFOA adalah sebuah metode komputasi evolusi baru yang mana berdasarkan pada tingkah laku mencari makan dari bakteri Escherichia coli (E. coli) dalam usus manusia. Seleksi alami cenderung untuk mereduksi hewan-hewan dengan strategi mencari makan yang buruk dan mendukung perkembangbiakan gen-gen pada hewan yang mempunyai strategi mencari makan yang baik, ketika mereka yang diharapkan lebih untuk berhasil reproduksi. Setelah banyak generasi, strategi mencari makan yang buruk akan dieliminasi atau dibentuk menjadi yang berpotensi. Aktivitas mencari makan ini menyebabkan para peneliti menggunakannya sebagai proses optimasi. Bakteri E. coli yang hidup pada usus kita juga menjalani strategi mencari makan. System control pada E. coli yang menentukan bagaimana harus melanjutkan mencari makan.
2.4. Particle Swarm Optimization
Particle swarm optimization, disingkat sebagai PSO, didasarkan pada perilaku sebuah kawanan serangga, seperti semut, rayap, lebah atau burung. Algoritma PSO meniru perilaku sosial organisme ini. Perilaku sosial terdiri dari tindakan individu dan pengaruh dari individu-individu lain dalam suatu kelom-pok. Kata partikel menunjukkan, misalnya, seekor burung dalam kawanan bu-rung. Setiap individu atau partikel berperilaku secara terdistribusi dengan cara menggunakankecerdasannya (intelligence) sendiri dan juga dipengaruhi peri-laku kelompok kolektifnya. Dengan demikian, jika satu partikel atau seekor bu-rung menemukan jalan yang tepat atau pendek menuju ke sumber makanan, sisa kelompok yang lain juga akan dapat segera mengikuti jalan tersebut meskipun lokasi mereka jauh di kelompok tersebut.
Metode optimasi yang didasarkan pada swarm intelligence ini disebut algoritma behaviorally inspired sebagai alternatif dari algoritma genetika, yang sering disebut evolution-based procedures. Algoritma PSO ini awalnya diusulkan oleh James Kennedy dan Russell Eberhart. Dalam konteks optimasi multivariabel, kawanan diasumsikan mempun-yai ukuran tertentu atau tetap dengan setiap partikel posisi awalnya terletak di suatu lokasi yang acak dalam ruang multidimensi. Setiap partikel diasum-sikan memiliki dua karakteristik: posisi dan kecepatan. Setiap partikel bergerak dalam ruang/space tertentu dan mengingat

posisi terbaik yang pernah dilalui atau ditemukan terhadap sumber makanan atau nilai fungsi objektif. Setiap partikel menyampaikan informasi atau posisi bagusnya kepada partikel yang lain dan menyesuaikan posisi dan kecepatan masing-masing berdasarkan in-formasi yang diterima mengenai posisi yang bagus tersebut. Sebagai contoh, misalnya perilaku burung-burung dalam dalam kawanan burung. Meskipun se-tiap burung mempunyai keterbatasan dalam hal kecerdasan, biasanya ia akan mengikuti kebiasaan (rule) seperti berikut :
1. Seekor burung tidak berada terlalu dekat dengan burung yang lain2. Burung tersebut akan mengarahkan terbangnya ke arah rata-rata
keseluruhan burung3. Akan memposisikan diri dengan rata-rata posisi burung yang lain dengan
menjaga sehingga jarak antar burung dalam kawanan itu tidak terlalu jauh
Dengan demikian perilaku kawanan burung akan didasarkan pada kombinasi dari 3 faktor simpel berikut:
1. Kohesi - terbang bersama2. Separasi - jangan terlalu dekat3. Penyesuaian(alignment) - mengikuti arah bersama
Jadi PSO dikembangkan dengan berdasarkan pada model berikut:
1. Ketika seekor burung mendekati target atau makanan (atau bisa minimum atau maximum suatu fungsi tujuan) secara cepat mengirim informasi kepada burung-burung yang lain dalam kawanan tertentu
2. Burung yang lain akan mengikuti arah menuju ke makanan tetapi tidak secara langsung
3. Ada komponen yang tergantung pada pikiran setiap burung, yaitu memorinya tentang apa yang sudah dilewati pada waktu sebelumnya.
Model ini akan disimulasikan dalam ruang dengan dimensi tertentu dengan sejumlah iterasi sehingga di setiap iterasi posisi partikel akan semakin mengarah ke target yang dituju (minimasi atau maksimasi fungsi). Ini dilakukan hingga maksimum iterasi dicapai atau bisa juga digunakan kriteria penghentian yang lain.
2 Implementasi PSO
Misalkan kita mempunyai fungsi berikut
minf(x)(1) dimanaX(B)
≤X≤X(A)
2

dimanaX(B)
adalah batas bawah danX(A)
adalah batas atas dariX. Prosedur
PSO dapat dijabarkan dengan langkah-langkah sebagai berikut [2]:
1. Asumsikan bahwa ukuran kelompok atau kawanan (jumlah partikel) adalah
N. Untuk mengurangi jumlah evaluasi fungsi yang diperlukan untuk men-emukan solusi, sebaiknya ukuranNtidak terlalu besar, tetapi juga tidak
terlalu kecil,agar ada banyak kemungkinan posisi menuju solusi terbaik
atau optimal. Jika terlalu kecil, sedikit kemungkinan menemukan posisi
partikel yang baik. Terlalu besar juga akan membuat perhitungan jadi
panjang. Biasanya digunakan ukuran kawanan adalah 20 sampai 30 par-tikel.
2. Bangkitkan populasi awalXdengan rentangX(B)
danX(A)
secara ran-dom sehingga didapatX1,X2, ...,XN. Setelah itu, untuk mudahnya,partikel
j dan kecepatannya pada iterasii dinotasikan sebagaiX
(i)
j danV
(i)
j
Se-hingga partikel-partikel awal ini akan menjadiX1(0),X2(0), ...,XN(0).
VektorXj(0),(j=1,2, ...,N) disebut partikel atau vektor koordinat dari
partikel. (seperti kromosom dalam algoritma genetika). Evaluasi nilai
fungsi tujuan untuk setiap partikel dan nyatakan dengan
f[X1(0)],f[X2(0)], ..., f[XN(0)]
.
3. Hitung kecepatan dari semua partikel. Semua partikel bergerak menuju

titik optimal dengan suatu kecepatan. Awalnya semua kecepatan dari
partikel diasumsikan sama dengan nol. Set iterasii=1.
4. Pada iterasi ke-i, temukan 2 parameter penting untuk setiap partikelj
yaitu:
(a) Nilai terbaik sejauh ini dariXj(i) (koordinat partikeljpada iterasi
i) dan nyatakan sebagaiPbest,j, dengan nilai fungsi obyektif paling
rendah (kasus minimasi) ,f[Xj(i)] , yang ditemui sebuah partikelj
pada semua iterasi sebelumnya. Nilai terbaik untuk semua partikel
Xj(i) yang ditemukan sampai iterasi ke-i, Gbest,dengan nilai fungsi
tujuan paling kecil/minimum diantara semua partikel untuk semua
iterasi sebelumnya, f[Xj(i)].
3
(b) Hitung kecepatan partikelj pada iterasi kei dengan rumus sebagai
berikut:
Vj(i)=Vj(i−1) +c1r1[Pbest,j−xj(i−1)] + (2)
c2r2[Gbest−xj(i−1)],j=1,2, ...,N
dimanac1 danc2 masing-masing adalahlearning rates untuk ke-mampuan individu (cognitive) dan pengaruh sosial (group), danr1
danr2 bilangan random yang berdistribusi uniforml dalam inter-val 0 dan 1. Jadi parametersc1 danc2 dmenunjukkan bobot dari
memory (position) sebuah partikel terhadap memory (posisi) dari
kelompok(swarm). Nilai daric1 danc2 biasanya adalah 2 sehingga
perkalianc1r1 danc2r2 memastikan bahwa partikel-partikel akan
mendekati target sekitar setengah selisihnya.
(c) Hitung posisi atau koordinat partikeljpada iterasi ke-i dengan cara
Xj(i)=Xj(i−1) +Vj(i);j=1,2, ...,N (3)
Evaluasi nilai fungsi tujuan untuk setiap partikel dan nyatakan se-bagai

f[X1(i)],f[X2(i)], ..., f[XN(i)]
.
5. Cek apakah solusi yang sekarang sudah konvergen. Jika posisi semua
partikel menuju ke satu nilai yang sama, maka ini disebut konvergen.
Jika belum konvergen maka langkah 4 diulang dengan memperbarui it-erasii=i+ 1, dengan cara menghitung nilai baru dariPbest,j danGbest.
Proses iterasi ini dilanjutkan sampai semua partikel menuju ke satu titik
solusi yang sama. Biasanya akan ditentukan dengan kriteria penghentian
(stopping criteria), misalnya jumlah selisih solusi sekarang dengan solusi
sebelumnya sudah sangat kecil.
3Contoh
Misalkan kita mempunyai persoalan optimasi dengan satu variabel sebagai berikut
f(x) = (100−x)
2
(4)
dimana 60≤x≤120
4
1. Tentukan jumlah partikelN= 4 Tentukan populasi awal secara random,
misalkan didapat
x1(0) = 80,
x2(0) = 90,
x3(0) = 110,
x4(0) = 75.
2. Evaluasi nilai fungsi tujuan untuk setiap partikelxj(0) untukj=1,2,3,4.
dan nyatakan dengan
f1=f(80) = 400,

f2=f(90) = 100,
f3=f(110) = 100,
f4=f(75) = 625.
3. Tentukan kecepatan awalv1(0) =v2(0) =v3(0) =v4(0) = 0. Tentukan
iterasi i= 1; Lalu ke langkah nomer 4.
4. TemukanPbest,1=80,Pbest,2=90,Pbest,3= 110,Pbest,4=75,Gbest=90.
Hitungv(j) dengan c1 =c2 = 1. Misalkan nilai random yang didapat,
r1=0.4,r2=0.5, dengan rumusVj(i)=Vj(i−1) +c1r1[Pbest,j−xj(i−
1)] +c2r2[Gbest−xj(i−1)] diperoleh
v1(1) = 0 + 0.4(80−80) + 0.5(90−80) = 5
v2(1) = 0 + 0.4(90−90) + 0.5(90−90) = 0
v3(1) = 0 + 0.4(110−110) + 0.5(90−110) =−10
v4(1) = 0 + 0.4(75−75) + 0.5(90−75) = 7.5
Sedangkan untuk nilaixadalah
x1(1) = 80+ 5 = 85
x2(1) = 90+ 0 = 90
x3(1) = 110−10 = 100
x4(1) = 75+ 7.5= 82.5
5. Evaluasi nilai fungsi tujuan sekarang pada partikelxj(1),
f1(1) =f(85) = 225,
f2(1) =f(90) = 100,
f3(1) =f(100) = 0,
f4(1) =f(82.5) = 306.25.
Sedangkan pada iterasi sebelumnya kita dapatkan
5
f1(0) =f(80) = 400,

f2(0) =f(90) = 100,
f3(0) =f(110) = 100,
f4(0) =f(75) = 625.
Nilai darif dari iterasi sebelumnya tidak ada yang lebih baik sehingga
Pbest untuk masing-masing partikel sama dengan nilai x-nya.Gbest= 100
Cek apakah solusixsudah konvergen, dimana nilaixsaling dekat. Jika tidak,
tingkatkan ke iterasi berikutnyai= 2. Lanjutkan ke langkah 4.
1.Pbest,1=85,Pbest,2=90,Pbest,3= 100,Pbest,4=82.5,Gbest= 100
Hitung kecepatan baru denganr1=0.3danr=0.6 ( ini hanya sekedar
contoh untuk menjelaskan penghitungan, dalam implementasi angka ini
dibangkitkan secar arandom).
v1(2) = 5 + 0.3(85−85) + 0.6(100−85) = 14
v2(2) = 0 + 0.3(90−90) + 0.6(100−90) = 6.
v3(2) =−10+ 0.3(100−100) + 0.6(100−100) =−10
v4(2) = 7.5+ 0.3(82.5−82.5) + 0.6(100−82.5) = 18
Sedangkan untuk nilaixadalah
x1(2) = 85+ 14 = 99
x2(2) = 90+ 6 = 96
x3(2) = 100−10 = 90
x4(2) = 82.5+ 18 = 100.5
2. Evaluasi nilai fungsi tujuan sekarang pada partikelxj(2),
f1(2) =f(99) = 1,
f2(2) =f(96) = 16,
f3(2) =f(90) = 100
f4(2) =f(100.5) = 0.25.
Jika dibandingkan dengan nilaifdari iterasi sebelumnya, ada nilai yang

lebih baik dari nilai f sekarang yaitu f3(1) = 0, sehingga Pbest untuk
partikel 3 sama dengan 100, danGbest dicari dari min{1,16,0,0.25}=0
yang dicapai padax3(1) = 100. Sehingga untuk iterasi berikutnyaPbest=
(99,96,100,100.5) danGbest= 100.
Cek apakah solusi sudah konvergen, dimana nilaixsaling dekat. Jika tidak kon-vergen, seti= 3, masuk ke iterasi berikutnya. Lanjutkan ke langkah berikutnya
dengan menghitung kecepatanvdan ulangi langkah-langahs elanjunya sampai
mencapai konvergen.

BAB III
ANALISIS DAN PERANCANGAN SISTEM

DAFTAR PUSTAKA
Agustini , K., 2006. IDENTIFIKASI PEMBICARA DENGAN JARINGAN SYARAF TIRUAN DAN TRANSFORMASI WAVELET DISKRET SEBAGAI PRAPROSES. Seminar Nasional Sistem dan Informatika, 17 November.pp. 67-72.
Al-Sawalmeh, W., Daqrouq, K., Daoud, O. & Al-Qawasmi, A.-R., 2010. Speaker Identification System-based Mel Frequency and Wavelet Transform using Neural Network Classifier. European Journal of Scientific Research, 41(1), pp. 515-525.
Ariyadi, R., Purnomo, M. H., Ramadijanti, N. & Dewantara, B. S., 2013. PENGENALAN RASA LAPAR MELALUI SUARA TANGIS BAYI UMUR 0-9 BULAN DENGAN MENGGUNAKAN NEURAL NETWORK.
Hilal, T. A., Hilal, H. A., Shalabi, R. E. & Daqrouq, K., 2011. Speaker Verification System Using Discrete Wavelet Transform And Formants Extraction Based On The Correlation Coefficient. International MultiConference of Engineers and Computer Scientists (IMECS), 16-18 March.Volume II.
Misbahuddin, 2011. PELATIHAN JARINGAN SYARAF TIRUAN BERBASIS IMPERIALIST COMPETITIVE ALGORITHM. Majalah Ilmiah Al-Jibra, April.Volume 12.
Pawar, M. D. & Badave, S. M., 2011. Speaker Identification System Using Wavelet Transformation and Neural Network. International Journal of Computer Applications in Engineering Sciences, July, Volume I, pp. 228-232.
Putra, D., 2010. Pengolahan Citra Digital. Yogyakarta(DKI Yogyakarta): ANDI.
Rizal, A. & Suryani, V., 2006. Pengenalan Suara Jantung Menggunakan Dekomposisi Paket Wavelet dan Jaringan Syaraf Tiruan ART2 (Adaptive Resonance Theory 2). International Seminar on Electrical Power, Electronics Communication, Control, and Informatics, 16-17 Mei.
Schmidt, A. & Bandar, Z., 1997. A Modular Neural Network Architecture with Additional Generalization Abilities for High Dimensional Input Vectors. Norwich/England: Manchester Metropolitan University.
Silvan, V. & Muttaqien, F. H., 2011. Identifikasi Pembicara Menggunakan Algoritme VFI5 dengan MFCC sebagai Pengekstraksi Ciri. INKOM, Desember, Volume V, pp. 35-45.
Yudho DN, T., Hidayatno, A. & Isnanto, R., 2013. APLIKASI PENCIRIAN DENGAN TRANSFORMASI WAVELET UNTUK PENGENALAN PENGUCAP TEKS TAK BEBAS MENGGUNAKAN JARINGAN SARAF TIRUAN.





















