
UNIVERSITAS PENDIDIKAN GANESHA PASCASARJANA …pasca.undiksha.ac.id/download/1.-Uji-Asumsi.pdf ·...
46
UNIVERSITAS PENDIDIKAN GANESHA PASCASARJANA PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN 220 BAB IX UJI ASUMSI Uji statistik parametrik seperti uji-t, ANAVA, ANAKOVA, MANOVA, Analisis Regresi/Korelasi, Analisis Jalur dan seterusnya mempersyaratkan pemenuhan beberapa asumsi. Sebelum anaslsis statistik parametrik dilakukan, asumsi-asumsi tersebut harus dipenuhi terlebih dahulu. Pengujian asumsi dilakukan dengan analisis statistik yang umum dilakukan. Pada bab ini dibahas beberapa asumsi yang harus dipenuhi oleh uji statistik parametrik yang dibahas pada buku ini dan disertai pembahasan analisis statistik untuk menguji asumsi-asumsi tersebut. 9.1 Lima Asumsi Analisis Regresi Ada beberapa asumsi tentang distribusi variabel dalam model regresi populasi. Lima di antara asumsi dimaksud umum diformulasikan karena memiliki estimator yang cukup sederhana terhadap karakteristik yang dimiliki, serta dapat dihasilkan dari analisis statistik yang berlaku pada distribusi yang umum digunakan. Analisis regresi tidak dapat dilanjutkan apabila satu atau lebih dari kelima asumsi analisis regresi tidak terpenuhi atau terganggu. Oleh karena itu, perlu dilakukan pendeteksian atau pengujian apakah kelima asumsi regresi telah dipenuhi. Berikut adalah lima asumsi dalam regresi linier yang dibahas pada buku ini. Asumsi Pertama: variabel penelitian diasumsikan berdistribusi normal. Data penelitian dikumpulkan dari sampel dan sampel berasal dari populasi. Oleh karena itu, asumsi pertama sering diformulasikan menjadi: data berasal dari populasi yang berdistribusi normal. Jadi diperlukan uji normalitas sebaran data dari semua variabel yang terlibat dalam penelitian. Asumsi Kedua: model regresi diasumsikan linier dan arah regresi diasumsikan signifikan. Artinya, hubungan antara variabel bebas dan variabel terikat bersifat linier. Peningkatan harga pada variabel bebas akan diikuti oleh peningkatan harga pada variabel terikat. Sebaliknya, penurunan harga pada variabel bebas akan diikuti oleh penurunan harga pada variabel terikat. Apabila digambar grafik hubungan antara variabel bebas dengan variabel terikat, maka akan membentuk kurva linier. Asumsi Ketiga: tidak terdapat variabel bebas yang berkombinasi linier dengan variabel bebas yang lain. Apabila terdapat variabel bebas X 1, X 2, X 3, ...., X n, maka semua variabel bebas tersebut diasumsikan bebas linier (linearly independent) atau tidak berkombinasi linier. Apabila variabel bebas X 1, X 2, X 3, ...., X n, berelasi atau berkombinasi linier satu sama lain secara sempurna, maka variabel- variabel tersebut bergantung linier (linearly dependent). Kasus tersebut dinamakan multikolinieritas (multycolinearity). Pada kondisi ini, tidak ada estimasi dari koefisien regresi parsial yang bisa diperoleh karena sistem persamaan tidak dapat diselesaikan. Metode kuadrat terkecil akan terhenti, sehingga tidak ada estimasi yang dapat dihitung. Dalam praktek sehari-hari, jarang terjadi multikoloieritas karena peneliti sudah mempertimbangkan variabel-variabel yang berpeluang mengakibatkan terjadinya multikolieritas, sehingga dua atau lebih variabel bebas yang memiliki efek yang sama terhadap variabel terikat tidak disertakan dalam penelitian. Apabila secara kebetulan peneliti memilih dua atau variabel bebas yang berkombinasi linier, maka data yang diperoleh dari sampel belum tentu menunjukkan hubungan linier yang sempurna antara dua atau variabel bebas tersebut. Hal ini bisa terjadi karena beberapa bentuk kesalahan dalam pengambilan sampel.
Transcript of UNIVERSITAS PENDIDIKAN GANESHA PASCASARJANA …pasca.undiksha.ac.id/download/1.-Uji-Asumsi.pdf ·...

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
220
BAB IX
UJI ASUMSI
Uji statistik parametrik seperti uji-t, ANAVA, ANAKOVA, MANOVA, Analisis Regresi/Korelasi,
Analisis Jalur dan seterusnya mempersyaratkan pemenuhan beberapa asumsi. Sebelum anaslsis statistik
parametrik dilakukan, asumsi-asumsi tersebut harus dipenuhi terlebih dahulu. Pengujian asumsi
dilakukan dengan analisis statistik yang umum dilakukan. Pada bab ini dibahas beberapa asumsi yang
harus dipenuhi oleh uji statistik parametrik yang dibahas pada buku ini dan disertai pembahasan
analisis statistik untuk menguji asumsi-asumsi tersebut.
9.1 Lima Asumsi Analisis Regresi
Ada beberapa asumsi tentang distribusi variabel dalam model regresi populasi. Lima di antara asumsi
dimaksud umum diformulasikan karena memiliki estimator yang cukup sederhana terhadap
karakteristik yang dimiliki, serta dapat dihasilkan dari analisis statistik yang berlaku pada distribusi
yang umum digunakan. Analisis regresi tidak dapat dilanjutkan apabila satu atau lebih dari kelima
asumsi analisis regresi tidak terpenuhi atau terganggu. Oleh karena itu, perlu dilakukan pendeteksian
atau pengujian apakah kelima asumsi regresi telah dipenuhi. Berikut adalah lima asumsi dalam regresi
linier yang dibahas pada buku ini.
Asumsi Pertama: variabel penelitian diasumsikan berdistribusi normal. Data penelitian
dikumpulkan dari sampel dan sampel berasal dari populasi. Oleh karena itu, asumsi pertama sering
diformulasikan menjadi: data berasal dari populasi yang berdistribusi normal. Jadi diperlukan uji
normalitas sebaran data dari semua variabel yang terlibat dalam penelitian.
Asumsi Kedua: model regresi diasumsikan linier dan arah regresi diasumsikan signifikan. Artinya,
hubungan antara variabel bebas dan variabel terikat bersifat linier. Peningkatan harga pada variabel
bebas akan diikuti oleh peningkatan harga pada variabel terikat. Sebaliknya, penurunan harga pada
variabel bebas akan diikuti oleh penurunan harga pada variabel terikat. Apabila digambar grafik
hubungan antara variabel bebas dengan variabel terikat, maka akan membentuk kurva linier.
Asumsi Ketiga: tidak terdapat variabel bebas yang berkombinasi linier dengan variabel bebas yang
lain. Apabila terdapat variabel bebas X1, X2, X3, ...., Xn, maka semua variabel bebas tersebut
diasumsikan bebas linier (linearly independent) atau tidak berkombinasi linier. Apabila variabel bebas
X1, X2, X3, ...., Xn, berelasi atau berkombinasi linier satu sama lain secara sempurna, maka variabel-
variabel tersebut bergantung linier (linearly dependent). Kasus tersebut dinamakan multikolinieritas
(multycolinearity). Pada kondisi ini, tidak ada estimasi dari koefisien regresi parsial yang bisa
diperoleh karena sistem persamaan tidak dapat diselesaikan. Metode kuadrat terkecil akan terhenti,
sehingga tidak ada estimasi yang dapat dihitung. Dalam praktek sehari-hari, jarang terjadi
multikoloieritas karena peneliti sudah mempertimbangkan variabel-variabel yang berpeluang
mengakibatkan terjadinya multikolieritas, sehingga dua atau lebih variabel bebas yang memiliki efek
yang sama terhadap variabel terikat tidak disertakan dalam penelitian. Apabila secara kebetulan
peneliti memilih dua atau variabel bebas yang berkombinasi linier, maka data yang diperoleh dari
sampel belum tentu menunjukkan hubungan linier yang sempurna antara dua atau variabel bebas
tersebut. Hal ini bisa terjadi karena beberapa bentuk kesalahan dalam pengambilan sampel.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
221
Asumsi Keempat: setiap pasangan error еi dan еj secara statistik independen satu sama lain,
sehingga kovariannya sama dengan nol. Asumsi ini menyatakan bahwa error pada satu titik dari
populasi tidak berkorelasi secara sistematis dengan error pada titik yang lain dari populasi. Dengan
kata lain, besar atau tanda pada satu atau lebih error tidak dapat digunakan untuk mengestimasi besar
atau tanda error yang lain. Asumsi ini terganggu umumnya pada observasi atau pengambilan data yang
dilakukan secara periodik pada selang waktu tertentu. Apabila asumsi tersebut tertganggu, maka error
pada satu titik populasi akan berkorelasi dengan error pada titik populasi yang lain. Kejadian ini
dinamakan autokorelasi.
Asumsi Kelima: varian error diasumsikan konstan untuk setiap nilai dari variabel bebas X. Artinya,
penyebaran atau dispersi atau variabilitas titik dalam garis regresi populasi harus konstan. Varian dari
ei berdistribusi normal dengan standar deviasi yang sama. Tidak ada kurva normal yang lebih lancip
atau lebih datar daripada yang lain untuk setiap Xi. Gangguan terhadap asumsi ini sering terjadi pada
data yang bersifat cross-sectional), yakni data yang dikumpulkan pada waktu bersamaan padahal ada
variabel lain yeng memberi pengaruh yang berbeda. Data kualitas sarana pendidikan misalnya
terpengaruh oleh lokasi sekolah, yakni perkotaan, pinggiran kota, atau pedesaan. Varian error tidak
akan konstan, melainkan akan berbeda antara data di perkotaan, di pinggiran kota, dan di pedesaan.
Kondisi dimana varian error tidak konstan dinamakan heterokedastisitas.
9.2 Dua Asumsi Uji-t dan ANAVA
Ada dua asumsi yang harus dipenuhi sebelum uji-t dan ANAVA bisa dilakukan. ANAVA tidak dapat
dilakukan apabila salah satu atau kedua asumsi tersebut tidak terpenuhi. Berbeda halnya dengan
ANAVA, untuk uji-t asumsi yang wajib dipenuhi adalah asumsi tentang normalitas data. Apabila
asumsi tentang normalitas data tidak dipenuhi, maka ujit tidak dapat dilanjutkan. Di lain sisi, untuk
asumsi tentang homogenitas varian, uji-t relatif lebih fleksibel karena uji-t menyediakan formula yang
berbeda untuk kelompok yang memiliki varian homogen dan kelompok yang memiliki varian yang
tidak homogen. Jadi, dalam uji-t, apabila kelompok yang dibandingkan tidak memiliki varian yang
homogen, maka uji-t masih dapat dilanjutkan dengan menggunakan formula yang berbeda. Hal ini
sudah dibahas pada bab iv tentang uji hipotesis di bagian uji-t (uji beda dua rerata).
Asumsi Pertama: variabel terikat dari semua kelompok yang dibandingkan diasumsikan berdistribusi
normal. Sama halnya dengan regresi, data penelitian dikumpulkan dari sampel dan sampel berasal dari
populasi. Oleh karena itu, asumsi pertama sering diformulasikan menjadi: data berasal dari populasi
yang berdistribusi normal. Jadi diperlukan uji normalitas sebaran data variabel terikat dari semua
kelompok yang dibandingkan.
Asumsi Kedua: variabel terikat dari semua kelompok yang dibandingkan diasumsikan memiilki
varians yang sama atau homogen. Analisis varian dapat mengungkap apakah perubahan varian antar-
sumber lebih besar dari yang dinyatakan pada hipotesis nol. Analisis varian sepenuhnya menggunakan
varian, bukan perbedaan dan standar error aktual. Varian yang muncul akibat variabel-variabel
eksperimen (variabel bebas) dibandingkan dengan varian kesalahan yang muncul dari dalam sampel
akibat pengacakan. Dengan kata lain, varian antar-kelompok dibandingkan dengan varian dalam
kelompok. Varian dalam kelompok dihitung secara terpisah, kemudian dihitung rata-ratanya. Oleh
karena itu varian dalam kelompok tidak terpengaruh oleh varian antar-kelompok. Jika tidak ada hal lain
yang menyebabkan sekor-sekor itu bervariasi, maka varian dalam kelompok dianggap sebagai
fluktuasi kebetulan. Jika hal itu yang terjadi, maka varian antar-kelompok dapat dibandingkan dengan

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
222
varian dalam kelompok. Dengan demikian, varian data dari semua kelompok yang dibandingkan
diasumsikan homogen. Jadi diperlukan uji homogenitas varian dari semua kelompok yang dibandingkan.
9.3 Teknik Analisis untuk Uji Asumsi Untuk mengetahui apakah asumsi yang dipersyaratkan oleh uji statistik yang digunakan sudah
terpenuhi atau tidak, perlu dilakukan pendeteksian atau pengujian. Pendeteksian atau pengujian asumsi
tersebut sering disebut uji asumsi. Berikut dibahas teknik statistik untuk mengujia semua asumsi yang
sudah diuraikan.
9.3.1 Pengujian Normalitas Sebaran Data
Analisis regresi/korelasi, ANAVA, dan uji-t dapat dilakukan apabila variabel yang terlibat di dalamnya
berdistribusi normal. Ungkapan lain yang sering digunakan adalah data berasal dari populasi yang
berdistribusi normal. Ada beberapa teknik analisis statistik yang umum digunakan untuk menguji
normalitas sebaran data, yaitu teknik Chi Kuadrat, Teknik Lilliefors, dan teknik Komogorov Smirnov.
9.3.1.1 Pengujian Normalitas Data dengan Teknik Chi Kuadrat
Teknik analisis statistik chi kuadrat digunakan untuk menguji perbedaan dua kelompok atau lebih,
yang mana datanya berupa frekuensi. Dalam uji normalitas sebaran data dibandingkan frekuensi
sebaran data hasil penelitian atau observasi dengan frekuensi sebaran data lain yang sudah
berdistribusi normal. Data yang dibandingkan berupa fekuensi, sehingga teknik analisis statistik yang
digunakan adalah teknik chi kuadrat. Hipotesis nol yang diuji menyatakan tidak terdapat perbedaan
frekuensi sebaran data hasil observasi dengan frekuensi sebaran data lain yang berdistribusi normal
melawan hipotesis alternatif yang menyatakan bahwa terdapat perbedaan frekuensi sebaran data hasil
observasi dengan frekuensi sebaran data lain yang berdistribusi normal.
Apabila hipotesis nol ditolak atau hipotesis alternatif diterima, yang berarti frekuensi sebaran data hasil
observasi berbeda secara signifikan dengan dengan frekuensi sebaran data lain yang sudah
berdistribusi normal, maka dapat disimpulkan bahwa sebaran data hasil observasi tidak berdistribusi
normal. Sebaliknya, apabila hipotesis nol diterima, yang berarti frekuensi sebaran data hasil observasi
tidak berbeda secara signifikan dengan frekuensi sebaran data lain yang sudah berdistribusi normal,
maka dapat disimpulkan bahwa sebaran data hasil observasi berdistribusi normal.
Formula chi kuadrat yang digunakan adalah sebagai berikut.
k
i i
ii
E
EO
1
2
2 )(
Yang mana: 2 = koefisien chi kuadrat,
Oi = frekuensi observasi(frekuensi data yang diperoleh dari observasi),
Ei = frekuensi harapan (frekuensi data yang berdistribusi normal),
K = banyak kelompok atau kelas.
Kriteria penerimaan atau penolakan hipotesis adalah sebagai berikut. Jika harga chi kuadrat hitung
lebih kecil dari harga chi kuadrat tabel pada taraf signifikansi tertentu, maka hipotesis nol diterima dan
hipotesis alternatif ditolak. Artinya, frekuensi sebaran data hasil observasi tidak berbeda secara

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
223
signifikan dengan dengan frekuensi sebaran data lain yang sudah berdistribusi normal. Oleh karena itu,
dapat disimpulkan bahwa sebaran data hasil observasi berdistribusi normal. Sebaliknya, jika harga chi
kuadrat hitung lebih besar dari harga chi kuadrat tabel pada taraf signifikansi tertentu, maka hipotesis nol
ditolak dan hipotesis alternatif diterima. Artinya, frekuensi sebaran data hasil observasi berbeda secara
signifikan dengan frekuensi sebaran data lain yang sudah berdistribusi normal. Oleh karena itu, dapat
disimpulkan bahwa sebaran data hasil observasi tidak berdistribusi normal.
Harga chi kuadrat tabel dapat diambil dari tabel distribusi chi kuadrat dengan derajat kebebasan (dk) =
k-1, yang mana k adalah banyak kelompok. Pada uji normalitas sebaran data k adalah banyak interval
kelas karena perbandingan frekuensi dilakukan per-interval kelas. Selanjutnya, taraf signifikansi
ditentukan oleh peneliti. Umumnya, dalam penelitian sosial atau penelitian behavioral, termasuk pula
di dalamnya penelitian pendidikan, taraf signifikansi 0,05 sudah dipandang cukup memadai. Apalagi
kalau taraf signifikansi 0,01 bisa tercapai, maka hasil penelitian tentu akan lebih akurat.
Secara ringkas, langkah-langkah pengujian normalitas sebarab data dengan teknik chi kuadrat adalah
sebagai berikut.
a. Data disusun secara berkelompok dalam daftar distribusi frekuensi.
b. Tentukan batas kelas interval.
c. Hitung nilai z dari masing-masing batas kelas interval.
d. Hitung besar peluang untuk tiap-tiap nilai z berupa luas daerah di bawah kurva normal yang
diperoleh dari tabel kurva normal.
e. Hitung besar peluang untuk masing-masing kelas interval sebagai selisih luas daerah batas interval.
f. Hitung frekuensi harapan (fe) untuk tiap-tiap kelas interval sebagai hasilkali peluang tiap-tiap kelas
(d) dengan besar sampel (n).
g. Hitung chi-kuadrat dengan rumus:
k
i i
ii
E
EO
1
2
2 )(
h. Apabila χ2
hitung < χ2
tabel, maka sampel berasal dari populasi yang berdistribusi normal.
Sebagai contoh penerapan uji normalitas dengan teknik statistik chi kuadrat, berikut ini akan diuji
normalitas data fiktif berupa hasil ujian komputer dari 50 orang siswa, seperti tercantum pada tabel di
bawah ini.
Nilai Ujian Frekuensi
61 – 66 1
54 – 60 3
47 – 53 4
40 – 46 12
33 – 39 15
26 – 32 6
19 – 25 4
12 - 18 3
5 - 11 2

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
224
Apabila dari data di atas dihitung rerata atau mean ( X ) dan standar deviasi (SD), maka diperoleh
X =39,86 dan SD=12,85. Selanjutnya dapat dibuat tabel kerja perhitungan chi-kuadrat ( 2 ) seperti
berikut. Perlu diingat lagi bahwa Z=(X- X )/SD.
Batas
Kelas
(X)
Z
Batas
Kelas
Luas
Batas
Kelas
Luas
Interval
(d)
Frekuensi
Harapan
(Ei=dxn)
Frekuensi
Observasi
(Oi)
i
ii
E
EO2
67.5 2,15 0,9842 0,0379 1,8950 1 0,4227
60.5 1,61 0,9463 0,0909 4,5450 3 0,5252
53.5 1,06 0,8554 0,1569 7,8450 4 1,8845
46.5 0,52 0,6985 0,2105 10,5250 12 0,2067
39.5 -0,03 0,4880 0,2039 10,1950 15 2,2646
32.5 -0,57 0,2841 0,1527 7,6350 6 0,3501
25.5 -1,12 0,1314 0,0829 4,1450 4 0,0051
18.5 -1,66 0,0485 0,0349 1,7450 3 0,9026
11.5 -2,21 0,0136 0,0106 0,5300 2 4,0772
4.5 -2,75 0,0030
Total 10,6387
Diperoleh
k
i i
ii
E
EO
1
2
2 )( =10,6387.
Dari daftar distribusi frekuensi dapat dilihat bahwa banyak kelas = 10, sehingga derajat kebebasan (dk)
untuk distribusi chi-kuadrat besarnya sama dengan 10-1=9. Selanjutnya dari daftar nilai persentil
untuk distribusi 2
pada taraf signifikansi 0,05 dan dk=9 diperoleh 2 0,05 (9)= 16,919. Ternyata nilai
2
yang diperoleh dari perhitungan lebih kecil dari 2 yang diperoleh dari tabel. Jadi hipotesis nol
diterima. Artinya, tidak terdapat perbedaan frekuensi sebaran data hasil observasi dengan frekuensi
sebaran data yang sudah berdistribusi normal. Dapat disimpulkan bahwa data berasal dari populasi
yang berdistribusi normal.
9.3.1.2 Pengujian Normalitas Sebaran Data dengan Teknik Lilliefors
Pengujian normalitas data dengan teknik chi-kuadrat dilakukan setelah data tersusun pada tabel
distribusi kelompok. Pengujian normalitas data menggunakan teknik Lilliefors dilakukan langsung
pada tabel distribusi frekuensi tunggal. Artinya, data tidak perlu disajikan dengan tabel distribusi
kelompok. Prinsip yang digunakan juga hampir sama. Pada pengujian normalitas data dengan teknik
chi-kuadrat, frekuensi sebaran data hasil observasi dibandingkan dengan frekuensi sebaran data yang
sudah berdistribusi normal. Pada pengujian normalitas data dengan teknik Lilliefors, dicari selisih
frekuensi sebaran data dengan frekuensi kumulatif sampai batas tiap-tiap data. Apabila nilai selisih
yang terbesar masih lebih kecil dari kriteria nilai Lilliefors, maka disimpulkan bahwa sebaran data
berdistribusi normal.
Secara ringkas, mekanisme pengujian normalitas sebaran data dengan teknik Lilliefors adalah sebagai
berikut.
a. Menampilkan data dengan urutan dari data yang terkecil sampai dengan data yang terbesar.
b. Menghitung frekuensi data.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
225
c. Menghitung nilai Z untuk tiap-tiap data, yang mana Z= .SD
XX
d. Menghitung frekuensi data pada kurva normal dengan batas Z yang dinyatakan dengan F(Z) yakni
luas daerah di bawah kurva normal pada jarak Z.
e. Menghitung frekuensi kumulatif data (FK).
f. Menghitung probabilitas frekuensi kumulatif yang dinyatakan dengan S(Z) yakni hasil bagi
frekuensi kumulatif dengan banyak data (FK/N).
g. Menghitung harga mutlak selisih antara F(Z) dengan S(Z) yang dinyatakan dengan |F(Z)-S(Z)|.
h. Mencari nilai |F(Z)-S(Z)| yang terbesar yang selanjutnya ditetapkan sebagai nilai Lhitung.
i. Nilai Lhitung dibandingkan dengan nilai Ltabel yang diperoleh dari tabel Lilliefors.
j. Apabila Nilai Lhitung lebih kecil dari nilai Ltabel, maka hipotesis nol yang menyatakan bahwa data
berasal dari populasi yang berdistribusi normal dapat diterima.
Mari kita lihat contoh di bawah ini.
Sebuah penelitian ingin mengkaji efektivitas program klinik pembelajaran matematika. Sebanyak 30
orang siswa yang mengalami kesulitan belajar matematika diikutkan dalam program tersebut sebagai
sampel. Setelah limit waktu yang ditetapkan dilakukan pengukuran hasil belajar matematika dengan
tes. Tabel berikut menunjukkan skor tes sebagai data hasil belajar matematika siswa yang dilibatkan
dalam program. Selanjutnya, ingin diuji apakah data hasil penelitian tersebut berdistribusi normal,
dengan menggunakan uji Lilliefors.
Data (X) Frekuensi (F)
3 1
4 1
5 4
6 4
8 5
9 5
10 4
11 3
14 2
15 1
N=30
Selanjutnya, mengikuti mekanisme kerja uji normalitas data dengan teknik Lilliefors dapat dibuat tabel
kerja seperti berikut ini.
X F Z F(Z) FK S(Z) |F(Z)-S(Z)|
3 1 -1,81 0,0351 1 0,0333 0,0018
4 1 -1,48 0,0694 2 0,0667 0,0027
5 4 -1,14 0,1271 6 0,2000 0,0729

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
226
6 4 -0,81 0,2090 10 0,3333 0,1243
8 5 -0,13 0,4483 15 0,5000 0,0517
9 5 0,20 0,5793 20 0,6667 0,0874
10 4 0,54 0,7054 24 0,8000 0,0946
11 3 0,87 0,8078 27 0,9000 0,0922
14 2 1,88 0,9699 29 0,9667 0,0032
15 1 2,21 0,9864 30 1,0000 0,0136
Pada tabel di atas X adalah data skor tes, F adalah frekuensi responden yang memperoleh skor
tersebut. S(Z) adalah probabilitas frekuensi kumulatif, yang diperoleh dari hasilbagi frekuensi
kumulatif dengan banyak data (FK/N). Misal sampai data 4 FK=2, sehingga S(Z)=2/30=0,0667. Z
adalah harga Z (skor baku) untuk tiap skor. F(Z) adalah frekuensi data atau sering disebut luas daerah
di bawah kurva normal dengan batas Z yang diperoleh dari dari tabel kurva normal (tabel Z). Nilai
Lhitung adalah nilai |F(Zi)-S(Zi)| yang terbesar. Jadi Lhitung = 0,1243. Selanjutnya, dengan n=30 dan
taraf signifikansi =0,05 dari daftar harga kritis L untuk uji Lillifors didapat Ltabel=0,136. Jadi Lhitung
(0,1214 lebih kecil dari Ltabel (0,136), sehingga hipotesis nol diterima. Jadi dapat disimpulkan bahwa
data hasil penelitian di atas berasal dari populasi yang berdistribusi normal.
9.3.1.3 Pengujian Normalitas dengan Teknik Kolmogorov-Smirnov Pengujian normalitas sebaran data menggunakan teknik Kolmogorov-Smirnov sama dengan pengujian
normalitas data menggunakan teknik Lilliefors, yakni dilakukan langsung pada tabel distribusi
frekuensi tunggal. Artinya, data tidak perlu disajikan dengan tabel distribusi kelompok. Prinsip yang
digunakan juga hampir sama. Pada pengujian normalitas data dengan teknik Pada pengujian normalitas
data dengan teknik Lilliefors, dicari selisih frekuensi sebaran data dengan frekuensi kumulatif sampai
batas tiap-tiap data. Apabila nilai selisih yang terbesar masih lebih kecil dari kriteria nilai Lilliefors,
maka disimpulkan bahwa sebaran data berdistribusi normal. Pada pengujian normalitas data dengan
teknik Kolmogorov-Smirnov, dicari selisih maksimum dari proporsi kumulatif dengan frekuensi
sebaran data pada batas bawah dan batas atas. Apabila nilai maksimum selisih yang terbesar masih
lebih kecil dari kriteria nilai Kolmogorov-Smirnov, maka disimpulkan bahwa sebaran data
berdistribusi normal.
Secara ringkas, mekanisme pengujian normalitas sebaran data dengan teknik Kolmogorov-Smirnov
adalah sebagai berikut.
a. Menampilkan data dengan urutan dari data yang terkecil sampai dengan data yang terbesar.
b. Menghitung frekuensi data.
c. Menghitung nilai Z untuk tiap-tiap data, yang mana Z= .SD
XX
d. Menghitung frekuensi data pada kurva normal dengan batas Z yang dinyatakan dengan F(Z) yakni
luas daerah di bawah kurva normal pada jarak Z.
e. Menghitung frekuensi kumulatif data (FK).
f. Menghitung probabilitas frekuensi kumulatif yang dinyatakan dengan PK yakni hasil bagi
frekuensi kumulatif dengan banyak data (FK/N).
g. Menghitung harga mutlak selisih antara F(Z) dengan PK di bawahnya yang dinyatakan dengan D-
1=| F(Z)-PKi-1|.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
227
h. Menghitung harga mutlak selisih antara F(Z) dengan PK yang dinyatakan dengan D0=|1=| F(Z)-
PKi|.
i. Menghitung nilai maksimum dari D-1 dan D0 yang dinyatakan dengan D=Mak(D-1, D0).
j. Mencari nilai D yang terbesar dan ditetapkan sebagai nilai Dhitung.
k. Nilai Dhitung dibandingkan dengan nilai Dtabel yang diperoleh dari tabel Kolmogorov-Smirnov.
l. Apabila Nilai Dhitung lebih kecil dari nilai Dtabel, maka hipotesis nol yang menyatakan bahwa data
berasal dari populasi yang berdistribusi normal dapat diterima.
Sebagai contoh, mari kita lihat kembali data yang sudah diuji normalitasnya dengan teknik Lilliefors di
bawah ini. Data tersebut merupakan data hasil penelitian yang melibatkan 30 orang responden sebagai
sampel. Sekarang kita uji normalitas sebaran data tersebut menggunakan teknik Kolmogorov-Smirnov.
Bila data tersebut diuji dengan teknik Kolmogorov-Smirnov dengan mengikuti mekanisme yang sudah
diuraikan di atas, maka diperoleh tabel kerja sebagai berikut.
X F FK PK Z F(Z) D-1 D0 Mak(D-1, D0)
3 1 1 0,0333 -1,8100 0,0351 0,0351 0,0018 0,0351
4 1 2 0,0667 -1,4800 0,0694 0,0361 0,0027 0,0361
5 4 6 0,2000 -1,1400 0,1271 0,0604 0,0729 0,0729
6 4 10 0,3333 -0,8100 0,2090 0,0090 0,1243 0,1243
8 5 15 0,5000 -0,1300 0,4483 0,1150 0,0517 0,1150
9 5 20 0,6667 0,2000 0,5793 0,0793 0,0874 0,0874
10 4 24 0,8000 0,5400 0,7054 0,0387 0,0946 0,0946
11 3 27 0,9000 0,8700 0,8078 0,0078 0,0922 0,0922
14 2 29 0,9667 1,8800 0,9699 0,0699 0,0032 0,0699
15 1 30 1,0000 2,2100 0,9864 0,0197 0,0136 0,0197
Pada tabel di atas X adalah data skor tes, F adalah frekuensi responden yang memperoleh skor
tersebut. FK adalah frekuensi kumulatif. PK adalah probabilitas frekuensi kumulatif, yang diperoleh
dari hasilbagi frekuensi kumulatif dengan banyak data (KF/N). Z adalah harga Z (skor baku) untuk tiap
skor. F(Z) adalah frekuensi data atau luas wilayah di bawah kurva normal dengan batas Z yang
diperoleh dari tabel kurva normal (tabel Z). D-1 adalah selisih antara F(Z) dengan PK di bawahnya, dan
D0 adalah selisih antara F(Z) dengan PK..D adalah nilai maksimum antara D-1 dan D0.
Nilai D terbesar (maksimum) yang disebut Dhitung dibandingkan dengan nilai Dtabel yang diperoleh dari
harga kritik Kosmogorov-Smirnov satu sampel pada taraf signifikansi yang ditentukan. Apabila nilai
Dhitung lebih kecil daripada nilai Dtabel, maka hipotesis nol yang menyatakan bahwa data berasal dari
populasi yang berdistribusi normal dapat diterima. Berdasarkan perhitungan pada tabel kerja diperoleh
Dhitung= 0,1243, sedangkan Dtabel dengan N=30 dan taraf signifikansi 0,05 adalah 0,24. Ternyata Dhitung
lebih kecil dari Dtabel. Jadi hipotesis nol diterima, berarti data skor tes di atas berasal dari populasi yang
berdidtribusi normal.
9.3.1.4 Pengujian Normalitas Sebaran Data dengan SPSS
Pengujian normalitas sebaran data dengan SPSS dilakukan dengan menerapkan teknik Kolmogorov-
Smirnov. Pada kesempatan ini akan digunakan SPSS untuk mencoba menganalisis normalitas data
yang sudah dianalisis secara manual menggunakan teknik Kolmogorov-Smirnov. Pengujian
normalitas sebaran data dengan SPSS dilakukan dengan mengikuti mekanisme kerja berikut ini.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
228
1. Entry data atau buka file data yang akan dianalisis
Lembar kerja entry data akan tampak seperti bagan di bawah ini.
2. Lakukan analisis dengan memilih menu berikut ini.
Analyze
Descriptives Statistics
Explore
Menu SPSS akan tampak seperti gambar berikut.
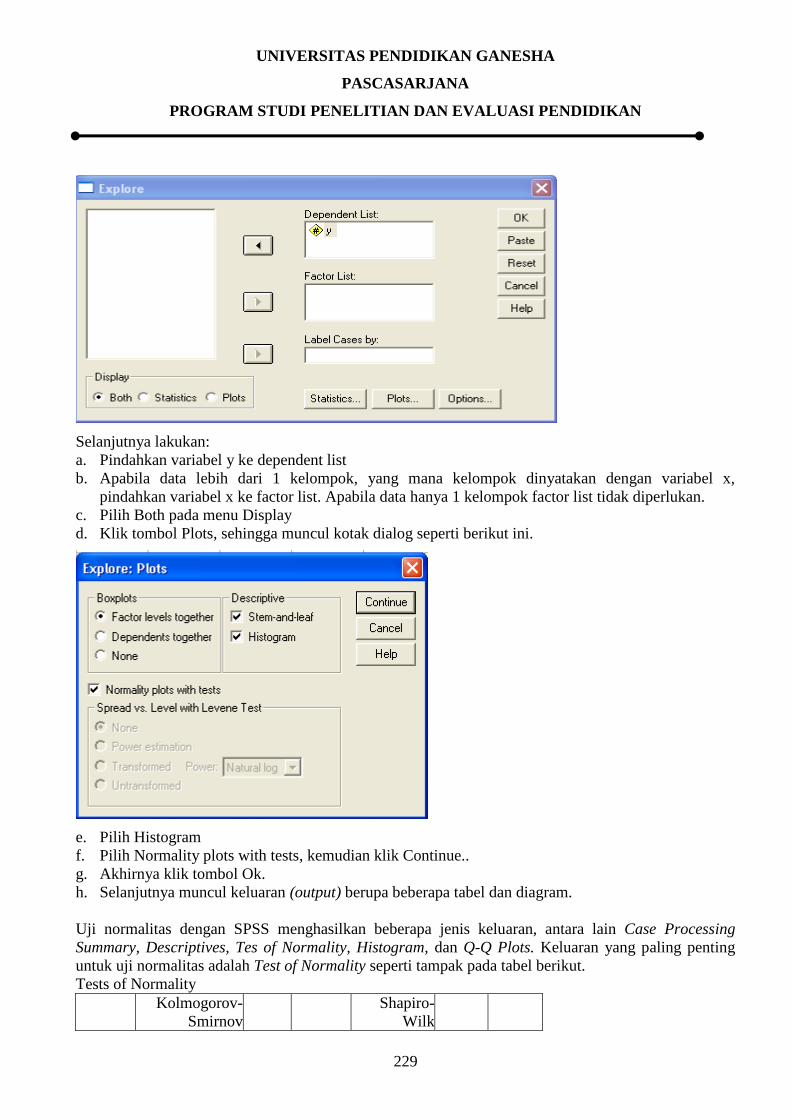
Setelah menu di atas dipilih akan tampak kotak dialog uji normalitas, seperti gambar di bawah ini.
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
229
Selanjutnya lakukan:
a. Pindahkan variabel y ke dependent list
b. Apabila data lebih dari 1 kelompok, yang mana kelompok dinyatakan dengan variabel x,
pindahkan variabel x ke factor list. Apabila data hanya 1 kelompok factor list tidak diperlukan.
c. Pilih Both pada menu Display
d. Klik tombol Plots, sehingga muncul kotak dialog seperti berikut ini.
e. Pilih Histogram
f. Pilih Normality plots with tests, kemudian klik Continue..
g. Akhirnya klik tombol Ok.
h. Selanjutnya muncul keluaran (output) berupa beberapa tabel dan diagram.
Uji normalitas dengan SPSS menghasilkan beberapa jenis keluaran, antara lain Case Processing
Summary, Descriptives, Tes of Normality, Histogram, dan Q-Q Plots. Keluaran yang paling penting
untuk uji normalitas adalah Test of Normality seperti tampak pada tabel berikut.
Tests of Normality
Kolmogorov-
Smirnov
Shapiro-
Wilk

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
230
Statistic df Sig. Statistic df Sig.
Y ,123 30 ,200 ,956 30 ,343
* This is a lower bound of the true significance.
a Lilliefors Significance Correction
3. Menafsirkan Hasil Uji Normalitas
Keluaran pada tabel di atas menunjukkan uji normalitas data y, yang sudah diuji sebelumnya secara
manual menggunakn teknik Lilliefors dan teknik Kolmogorov-Smirnov. Pengujian dengan SPSS
berdasarkan pada teknik Kolmogorov–Smirnov dan Shapiro-Wilk. Pilih salah satu teknik saja,
misalnya Kolmogorov–Smirnov. Hipotesis yang diuji adalah:
H0 : data sampel berasal dari populasi berdistribusi normal
H1 : data sampel tidak berasal dari populasi berdistribusi normal
Dengan demikian, normalitas data terpenuhi jika hipotesis nol diterima dan sebaliknya normalitas data
tidak terpenuhi jika hipotesis nol ditolak untuk taraf signifikasi ( ) yang ditetapkan. Pedoman
penerimaan atau penolakan hipotesis nol adalah sebagai berikut.
a. Perhatikan bilangan statistik (statistic) dan signifikansi (sig.) pada kolom Kolmogorov-Smirnov
atau Shapiro Wilk. Misalnya pada contoh pengujian di sini kita gunakan Kolmogorov-Smirnov.
b. Tetapkan taraf signifikansi yang digunakan. Untuk penelitian sosial atau penelitian pendidikan
biasanya =0.05 atau =0.01.
c. Apabila bilangan signifikansi (sig.) lebih besar daripada taraf signifikansi yang ditetapkan,
maka bilangan statistik yang diperoleh tidak signifikan, sehingga hipotesis nol diterima. Artinya,
data sampel berasal dari populasi yang berdistribusi normal. Sebaliknya, apabila bilangan
signifikansi (sig.) lebih kecil daripada taraf signifikansi yang ditetapkan, maka bilangan statistik
yang diperoleh signifikan, sehingga hipotesis nol ditolak. Artinya, data sampel tidak berasal dari
populasi yang berdistribusi normal.
Pada tabel hasil pengujian di atas bilangan statistik untuk teknik Kolmogorov-Sirnov besarnya 0,123
(berbeda sangat sedikit dengan hasil perhitungan manual) dengan bilangan signifikansi besarnya
0,200. Apabila ditetapkan taraf signifikansi =0,05, maka bilangan signifikansi (sig) lebih besar
daripada . Artinya, bilangan statistik yang diperoleh tidak signifikan, sehingga hipotesis nol
diterima. Jadi data hasil penelitian berasal dari populasi yang berdistribusi normal.
9.3.2 Pengujian Linieritas Data dan Keberartian Arah Regresi
9.3.2.1 Pengujian Linieritas Data dan Keberartian Arah Regresi
Secara Manual
Asumsi kedua dari analisis regresi menyatakan bahwa model regresi diasumsikan linier dan arah
regresi diasumsikan signifikan. Artinya, hubungan antara variabel bebas dan variabel terikat bersifat
linier. Peningkatan harga pada variabel bebas akan diikuti oleh peningkatan harga pada variabel
terikat. Sebaliknya, penurunan harga pada variabel bebas akan diikuti oleh penurunan harga pada
variabel terikat. Apabila digambar grafik hubungan antara variabel bebas dengan variabel terikat, maka
akan membentuk kurva linier. Selain bentuk regresi linier, koefisien arah regresi juga signifikan atau
berarti.
Asumsi tersebut harus diuji. Pengjian asumsi di atas sering disebut dengan uji keberartian arah regresi
dan uji linieritas regresi. Mekanisme pengujian yang dilakukan adalah sebagai berikut. Seperti sudah
dibahas sebelumnya, regresi linier antara variabel bebas X dengan variabel terikat Y menghasilkan

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
231
persamaan regresi Ŷ = b2X + b1. Persamaan regresi tersebut digunakan untuk menduga persamaan
regresi populasi Y = β2X + β1. Apabila persamaan sudah diperoleh, maka harus diuji: 1) apakah b1
signifikan untuk menaksir β2; dan 2) apakah rgresi benar-benar memiliki model linier atau memiliki
model yang lain. Pengujian linieritas regresi umumnya dilakukan sekaligus dengan pengujian
keberartian arah regresi. Hal ini dilakukan demi efisiensi, karena pengujian linieritas regresi dan
pengujian keberartia arah regresi banyak melibatkan perhitungan yang sama. Uji statistik yang
diterapkan untuk kedua pengujian tersebut adalah uji statistik F.
1. Pengujian Keberartian Arah Regresi
Pada pengujian keberartian arah regresi, hipotesis nol (H0) yang diuji menyatakan bahwa koefisien
regresi (yaitu koefisien b2) sama dengan nol (tidak berarti) melawan hipotesis hipotesis alternatif (H1),
yang menyatakan bahwa koefisien arah regresi berarti (tidak sama dengan nol). Pengujian hipotesis
nol dilakukan dengan uji statistik F. Nilai F dihitung dengan menggunakan rumus:
F-reg = RJK(D)
RJK(Reg)
Sebagai kontrol dari nilai F-reg yang diperoleh dari perhitungan digunakan distribusi F dengan dk
pembilang sama dengan dk regresi atau dk(Reg) dan dk penyebut sama dengan dk dalam atau dk(D)
pada taraf signifikansi α. Apabila harga F yang diperoleh dari perhitungan lebih besar daripada harga F
yang diperoleh dari tabel, maka hipotesis nol ditolak. Artinya, koefisien regresi b2 signifikan atau
berarti atau tidak sama dengan nol.
Pada rumus F-reg di atas, RJK(Reg) adalah rerata jumlah kuadrat regresi yang dihitung dengan
memakai rumus di bawah ini.
)(Re
)(Re)(Re
gdk
gJKgRJK
JK(Reg) adalah jumlah kuadrat regresi dan dk(Reg) adalah derajat kebebasan regresi. Derajat
kebebasan regresi atau dk(Reg)=1 karena dalam regresi ini hanya ada satu variabel bebas. JK(Reg)
dihitung dengan rumus:
JK(Reg) =
n
YXXYb
RJK(D) adalah rerata jumlah kuadrat dalam yang dihitung dengan memakai rumus di bawah ini.
)(
)()(
Ddk
DJKDRJK
JK(D) adalah jumlah kuadrat dalam dan dk(D) adalah derajat kebebasan dalam. Derajat kebebasan
dalam atau dk(D)=n-k. JK(D) dihitung dengan rumus:

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
232
JK(D) =
Xi ni
YY
2
2
2. Pengujian Linieritas Regresi
Pengujian linieritas regresi dilakukan melalui pengujian hipotesis nol (H0), yang menyatakan bahwa
regresi linier melawan hipotesi tandingan atau hipotesis alternatif (H1), yang menyatakan regresi non-
linier. Pengujian linieritas regresi dilakukan dengan uji F. Rumus F yang digunakan adalah sebagi
berikut.
F-TC = RJK(D)
RJK(TC)
Sebagai kontrol dari nilai F-reg yang diperoleh dari perhitungan digunakan distribusi F dengan dk
pembilang sama dengan dk tuna cocok atau dk(TC) dan dk penyebut sama dengan dk dalam atau
dk(D) pada taraf signifikansi α. Apabila harga F yang diperoleh dari perhitungan lebih besar daripada
harga F yang diperoleh dari tabel, maka hipotesis nol ditolak. Artinya, koefisien regresi b2 signifikan
atau berarti atau tidak sama dengan nol.
Pada rumus F-TC di atas, RJK(TC) adalah rerata jumlah kuadrat tuna cocok (TC) yang dihitung
dengan memakai rumus:
)(
)()(
TCdk
TCJKTCRJK
JK(TC) adalah jumlah kuadrat tuna cocok dan dk(TC) adalah derajat kebebasan tuna cocok. Derajat
kebebasan tuna cock atau dk(TC)=k-2. JK(TC) dihitung dengan rumus:
JK(TC) = JK(S) - JK(D), yang mana JK(D) menyatakan jumlah kuadrat dalam yang sudah dihitung
pada uji keberatian arah regresi dengan uji F. Demikian pula RJK(D) adalah rerata jumlah kuadrat
dalam yang rumusnya sudah dicantumkan pada pengujian keberartian arah regresi.
Apabila semua perhitungan pada uji F untuk pengujian keberartian arah regresi dan perhitungan uji F
untuk pengujian linieritas regresi, maka akan diperoleh tabel ringkasan uji F untuk menguji keberartian
arah regresi dan untuk menguji linieritas regresi seperti berikut.
Sumber Variasi DK JK RJK F
Regresi (Reg)
1
JK(Reg)
1
)(Re gJK
)(
)(Re
DRJK
gRJK
Tuna Cocok (TC)
k-2
JK(TC)

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
233
Dalam (D)
n-k
JK(D)
2
)(
k
TCJK
kn
DJK
)(
)(
)(
DRJK
TCRJK
T o t a l N Y2
3. Contoh Penerapan
Mari kita lihat lagi contoh penelitian yang mengkaji hubungan antara motivasi belajar (X) dan hasil
belajar (Y) yang sudah dibahas pada analisis regresi linier. Data yang diperoleh untuk menguji
hipotesis penelitian tersebut dari 15 orang responden adalah sebagai berikut.
No. Motivasi
Belajar
(X)
Hasil Belajar
(Y)
No. Motivasi
Belajar
(X)
Hasil Belajar
(Y)
1 52 62 9 68 76
2 52 65 10 70 82
3 54 68 11 70 78
4 58 64 12 70 80
5 62 68 13 72 84
6 62 64 14 73 84
7 68 80 15 76 85
8 68 70
Penelitian tersebut sudah menghasilkan persamaan regresi: Ŷ = 0,963 X + 11,413. Harga b2
sebenarnya sama dengan 0,962877 tetapi dibulatkan menjadi 0,963. Sekarang kita uji: 1) apakah
koefisien regresi b2=0,963 signifikan atau tidak dan 2) apakah regresi memiliki model linier atau tidak.
Untuk tujuan tersebut harus dibuat tabel kerja regresi yang dilengkapi dengan pengelompokan nilai
variabel Y berdasarkan nilai variabel X, seperti di bawah ini.
NO. X Y X2 Y
2 XY
1 52 k1 62 2704 3844 3224
2 52 65 2704 4225 3380
3 54 k2 68 2916 4624 3672
4 58 k3 64 3364 4096 3712
5 62 k4 68 3844 4624 4216
6 62 64 3844 4096 3968
7 68 80 4624 6400 5440
8 68 k5 70 4624 4900 4760
9 68 76 4624 5776 5168
10 70 82 4900 6724 5740
11 70 k6 78 4900 6084 5460

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
234
12 70 80 4900 6400 5600
13 72 k7 84 5184 7056 6048
14 73 k8 84 5329 7056 6132
15 76 k9 85 5776 7225 6460
Total 975 1110 64237 83130 72980
Tampak pada tabel di atas ada 15 data (n=15) dan 9 kelompok data Y menurut kelompok (kesamaan)
data X (k=9). Berdasarkan tabel kerja di atas dapat dilakukan perhitungan-perhitungan seperti berikut.
JK(T) = 2Y = 83130
JK(koef) =
8214015
1232100
15
111022
n
Y
JK(Reg) =
n
YXXYb
JK(Reg) = .15
1110975729800,962877
x
= .1879,799830 x 92877,0
Harga b2 dimasukkan 0,962877 (sebelum pembulatan) untuk mengurangi bias perhitungan.
JK(S) = JK(T) - JK(koef) - JK(Reg)
= 83130 – 82140 – 799,1879
= 190,8121
JK(D) =
Xi ni
YY
2
2
=
1
6464
1
6868
2
)6562(6562
22
22
222

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
235
3
)767080(767080
2
)6468(6468
2222
222
1
8484
1
8484
3
)807882(807882
22
22
2222
1
8585
22
= 4,5 + 0 + 0 + 8,0 + 50,6667 +8,0 + 0 + 0 + 0 = 71,1667.
JK(TC) = JK(S) - JK(D)
= 190,8121 - 71,1667
= 119,6454
Banyak data (n) sama dengan 15 dan banyak kelomok (k) sama dengan 9. Oleh karena itu, dk(Reg)=1;
dk(S)=n-2=15-2=13; dk(TC)=k-2=9-2=7; dk(D)=n-k=15-9=6.
Selanjutnya, rata-rata jumlah kuadrat (RJK) dapat dihitung sebagai berikut.
RJK(Reg)= 1829,7991
1829,799
1
)(Re
gJK
RJK(TC)= 0922,177
6454,119
)(
)(
TCdk
TCJK
RJK(D)= 8611,116
1667,71
)(
)(
Ddk
DJK
Akhirnya dapat dhitung harga F-regresi seperti berikut.
F-reg = 3788,678611,11
1829,799
RJK(D)
RJK(Reg)
F-TC = .441,18611,11
0922,17
RJK(D)
RJK(TC)
Hasil perhitungan di atas dapat diringkas seperti tampak pada tabel di bawah ini.
Sumber Variasi DK JK RJK F
Regresi (Reg) 1 799,1829 799,1829 67,3788

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
236
Tuna Cocok
Galat
7
6
119,6454
71,1667
17,0922
11,8611
1,441
Total 15 83130
Kesimpulan yang diperoleh dari perhitungan-perhitungan di atas adalah sebagai berikut.
Keberartian Arah Regresi
Jika diambil taraf nyata 0,05 maka untuk menguji hipotesis nol tentang keberartian regresi, dari daftar
distribusi F dengan dk pembilang 1 dan dk penyebut 6 diperoleh F=5,99. Ternyata F dari hasil
penelitian (67,3788) lebih besar dari F tabel (5,99). Ini berarti hipotesis nol ditolak dan hipotesis
alternatif diterima, sehingga koefisien arah regresi bersifat nyata (signifikan). Jadi regresi yang kita
peroleh berarti.
Linieritas Regresi
Jika diambil taraf nyata 0,05 maka untuk menguji hipotesis nol tentang kelinieran regresi, dari daftar
distribusi F dengan dk pembilang 7 dan dk penyebut 6 diperoleh F=4,21. Ternyata F dari hasil
penelitian (1,441) lebih kecil dari F tabel (4,21). Ini berarti hipotesis nol diterima. Jadi pernyataan
bahwa bentuk regresi linier diterima.
9.3.2.2 Pengujian Linieritas dan Keberartian Arah Regresi
dengan SPSS.
Pengujian keberartian arah regresi dan linieritas regresi dengan SPSS dilakukan dengan mengikuti
mekanisme kerja di bawah ini.
1. Entry Data
Data dimasukkan ke lembar kerja SPSS dengan menggunakan nama variabel x dan y. Lembar kerja
entry data akan tampak seperti bagan di bawah ini.
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
237
2. Analisis
Analisis dilakukan dengan mekanisme pemilihan menu sebagai berikut.
Analyze
Compare Means
Means
Sehingga menu SPSS akan tampak seperti bagan berikut.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
238
Setelah menu di atas dipilih akan tampak kotak dialog uji linieritas, seperti gambar di bawah ini.
a. Pindahkan variabel y ke Dependent list
b. Pindahkan variabel x ke Independent list
c. Klik tombol Options, sehingga muncul kotak dialog seperti berikut.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
239
d. Pilih menu Anova table and eta dan menu Test for linearity.
e. Klik Continue dan kemudian klik Ok.
f. Selanjutnya akan muncul output atau keluaran uji keberartian arah regresi dan linieritas regresi
yang terdiri dari beberapa tabel, antara lain: Case Processing Summary, Report, ANOVA Table,
dan Measures of Association.
Keluaran yang paling penting adalah ANOVA Table seperti tampak pada tabel di bawah ini.
ANOVA Table
Sum of
Squares
df Mean
Square
F Sig.
Y * X Between
Groups
(Combine
d)
918,833 8 114,854 9,683 ,006
Linearity 799,188 1 799,188 67,379 ,000
Deviation
from
Linearity
119,645 7 17,092 1,441 ,336
Within
Groups
71,167 6 11,861
Total 990,000 14
Bagian yang harus diperhatikan untuk uji keberartian arah regresi adalah Linearity, sedangkan untuk
uji linieritas regresi bagian yang harus diperhatikan adalah Deviation from Linearity. Deviation from
Linearity merupakan uji pembandingan linieritas regresi data hasil penelitian dengan linieritas regresi
dari data yang memang sudah linier. Apabila tidak ada perbedaan, maka berarti bentuk regresi yang
sedang diuji adalah linier. Pengambilan keputusan untuk uji keberartian arah regresi dan linieritas
regresi dilakukan sebagai berikut.
Pengujian Keberartian Arah Regresi

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
240
Pengujian keberartian arah regresi dilakukan dengan menguji hipotesis nol (H0) yang menyatakan bahwa
koefisien arah regresi tidak berarti, melawan hipotesis alternatih (H1) yang menyatakan bahwa
koefisien arah regresi berarti atau signifikan. Penerimaan atau penolakan hipotesis nol dilakukan
dengan memperhatikan nilai F Linearity dan nilai signifikansinya (sig). Apabila nilai sig. dari F
Linearity. Apabila nilai sig. dari F Linearity lebih kecil dari taraf signifikansi α yang ditetapkan, maka
hipotesis nol yang menyatakan bahwa koefisien arah regresi tidak berarti ditolak dan hipotesis
alternatif yang menyatakan bahwa koefisien arah regresi berarti atau signifikan diterima. Pada tabel
hasil analisis di atas nilai F Linearity besarnya 67,379 dengan nilai signifikansi (sig.) sebesar 0,000.
Jika ditetapkan taraf signifikansi α=0,05, maka nilai sig. jauh lebih kecil daripada α. Dengan demikian,
hipotesis nol ditolak dan hipotesis alternatif diterima. Artinya, koefisien arah regresi berarti atau
signifikan.
Pengujian Linieritas Regresi
Pengujian linieritas regresi dilakukan dengan menguji hipotesis nol (H0) yang menyatakan bahwa
bentuk regresi linier, melawan hipotesis alternatif (H1) yang menyatakan bentuk regresi tidak linier.
Penerimaan atau penolakan hipotesis nol dilakukan dengan memperhatikan nilai F Deviation From
Linearity dan nilai signifikansinya (sig). Apabila nilai sig. dari F Deviation From Linearity lebih besar
dari taraf signifikansi α yang ditetapkan, maka hipotesis nol yang menyatakan bahwa bentuk regresi
linier diterima dan hipotesis alternatif yang menyatakan bahwa bentuk regresi tidak linier ditolak. Pada
tabel hasil analisis di atas nilai F Deviation from Linearity besarnya 1,441 dengan nilai signifikansi
(sig.) sebesar 0,336. Jika ditetapkan taraf signifikansi α=0,05, maka nilai sig. jauh lebih besar daripada
α. Dengan demikian, hipotesis nol diterima dan hipotesis alternatif ditolak. Artinya, bentuk regresi
memang benar linier.
9.3.3 Pengujian Multikolinieritas
9.3.3.1 Pengujian Multikolinieritas Secara Manual
Uji Multikolieritas dimaksudkan untuk mengetahui ada tidaknya hubungan (korelasi) yang signifikan
antar variabel bebas. Jika terdapat hubungan yang cukup tinggi (signifikan), berarti ada aspek yang
sama diukur pada variabel bebas. Hal ini tidak layak digunakan untuk menentukan kontribusi secara
bersama-sama variabel bebas terhadap variabel terikat. Jadi uji multikolinieritas diperlukan hanya pada
regresi ganda karena pada regresi ganda terdapat lebih dari satu variabel bebas. Regresi sederhana
tidak memerlukan uji multikoliniertas karena regresi sederhana hanya memiliki satu variabel bebas.
Dalam regresi ganda x1, x2, x3, … xn terhadap y, apabila x1, x2, x3, … xn saling berkombinasi linier atau
berhubungan linier secara sempurna satu sama lain maka mereka saling tergantung (dependen). Dalam
kasus ini, koefisien regresi parsial tidak dipeoleh karena persamaan normal tidak terselesaikan karena
estimasi kuadrat terkecil tidak dapat dihitung. Saling tergantung secara sempurna jarang terjadi dalam
penelitian. Akan tetapi masalah khusus, yang disebut dengan multikolinier bisa terjadi.
Multikolinieritas terjadi apabila dua atau lebih variabel bebas saling berkorelasi kuat satu sama lain.
Bila terjadi multikolinieritas, estimasi kuadrat terkecil dapat dihitung tetapi terjadi kesulitan untuk
menginterpretasikan efek dari tiap-tiap variabel.
Multikolinieritas dapat dideteksi dengan menghitung koefisien korelasi ganda dan membandingkannya
dengan koefisien korelasi antar variabel bebas. Sebagai contoh, diambil kasus regresi x1, x2, x3, x4
terhadap y. Pertama dihitung Ry, x1x2x3x4. Setelah itu, dihitung korelasi antar enam pasang variabel
bebas, yaitu rx1x2, rx1x3, rx1x4, rx2x3, rx2x4, dan rx3x4. Apabila salah satu dari koefisien korelasi itu sangat
kuat, maka dilanjutkan dengan menghitung koefisien korelasi ganda dari masing-masing variabel

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
241
bebas dengan 3 variabel bebas lainnya, yaitu Rx1, x2x3x4; Rx2, x1x3x4; Rx3, x1x2x4; dan Rx4, x1x2x3. Apabila di
antara beberapa koefisien korelasi ganda tersebut ada yang mendekati Ry, x1x2x3x4, maka dikatakan
terjadi multikolinieritas.
Sebagai contoh, kita lihat penelitian yang mengkaji korelasi ganda antara motivasi belajar (X1) dan
kebiasaan belajar (X2) dengan hasil belajar (Y) yang sudah dibahas pada pembahasan regresi ganda.
Agar lebih menampakkan permasalahan multikolinieritas, pada kesempatan ini ditambahkan satu
variabel bebas lagi, yakni kreativitas (X3). Dengan demikian, penelitian ini mengkaji hubungan
(korelasi) antara motivasi belajar (X1), kebiasaan belajar (X2), dan kreativitas dengan hasil belajar
(Y). Data yang diperoleh dari 15 responden adalah seperti tercantum pada tabel di bawah ini. Ingin
diuji, apakah pada kasus korelasi ganda tersebut terjadi multikolinieritas.
No. X1 X2 X3 Y
1 72,00 60,00 60,00 84,00
2 68,00 65,00 72,00 80,00
3 70,00 75,00 80,00 82,00
4 70,00 72,00 75,00 78,00
5 73,00 78,00 85,00 84,00
6 62,00 68,00 72,00 68,00
7 58,00 55,00 58,00 64,00
8 52,00 55,00 59,00 62,00
9 70,00 72,00 70,00 80,00
10 76,00 80,00 83,00 85,00
11 68,00 64,00 70,00 70,00
12 52,00 54,00 58,00 65,00
13 54,00 56,00 60,00 68,00
14 62,00 66,00 62,00 64,00
15 68,00 70,00 70,00 76,00
Perhitungan koefisien korelasi ganda memberikan hasil Ry,x1x2x3=0,909. Perhitungan koefisien korelasi
sederhana antara variabel-variabel bebas (X1, X2, dan X3) memberikan hasil seperti tercantum pada
tabel di bawah.
X1 X2 X3
X1 1,000 ,841 ,777
X2 ,841 1,000 ,939
X3 ,777 ,939 1,000 .
Tampak pada tabel di atas rx1x2=0,841; rx1x3=0,777; dan rx2x3=0,939. Ternyata rx1x2=0,841 melebihi 0,8.
Oleh karena itu dapat diduga bahwa terjadi multikolinieritas antara X1 dan X2. Selain itu, rx2x3=0,939
juga melebihi 0,8. Oleh karena itu, dapat diduga pula bahwa terjadi multikolinieritas antara x2 dan x3.
Untuk itu, lebih lanjut harus dihitung koefisien korelasi ganda antara variabel-variabel bebas.
Berdasarkan perhitungan korelasi ganda diperoleh Rx1..x2x3=0,841; Rx2..x1x3=0,955; dan Rx3.x1x2=0,939.
Tampak dari hasil perhitungan bahwa koefisien korelasi ganda yang terbesar adalah koefisien korelasi
ganda antara X2 dengan X1 dan X3. Artinya, variabel X2 memiliki keterikatan paling besar dengan

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
242
variabe-variabel bebas lainnya. Dengan demikian, apabila peneliti mau menggugurkan variabel yang
mengalami multikolinieritas, maka variabel yang harus digugurkan adalah X2.
9.3.3.2 Pengujian Multikolinieritas dengan SPSS
Pengujian multikolonieritas menggunakan bantuan program SPSS dapat dilakukan dengan mengikuti
mekanisme pengujian multikolinieritas secara manual tahap demi tahap seperti di atas. Akan tetapi,
selama ini, apabila pengujian multikolinieritas dilakukan dengan bantuan program SPSS, maka
pedoman yang digunakan adalah variance inflation factor (VIF) atau toleransi (tolerance). Nilai VIF
merupakan kebalikan dari nilai tolerance, sehingga dapat dinyatakan bahwa VIF=1/tolerance. Hasil
pengujian multikolinieritas dengan SPSS akan sekaligus menampilkan nilai VIF dan nilai tolerance.
Apabila variabel bebas memiliki nilai VIF melebihi 10, maka dikatakan bahwa variabel bebas tersebut
mengalami multikolinieritas, sehingga harus digugurkan. Dengan kata lain, apabila variabel bebas
memiliki nilai tolerance kurang dari 0,1 maka dikatakan bahwa variabel bebas tersebut mengalami
multikolinieritas, sehingga harus digugurkan.
Sebagai contoh, kita lihat kembali data hasil penelitian yang mengkaji korelasi ganda antara motivasi
belajar (X1), kebiasaan belajar (X2), dan kreativitas (X3) dengan hasil belajar (Y), yang telah diuji
multikolinieritasnya secara manual. Sekarang kita uji menggunakan SPSS, apakah pada kasus korelasi
ganda tersebut terjadi multikolinieritas.
Mekanisme pengujian multikolinieritas dengan SPSS adalah sebagai berikut.
1. Entry Data
Masukkan data ke dalam form SPSS, yakni data motivasi belajar (X1), minat belajar (X2), dan
kreativitas (X3) dengan hasil belajar (Y), seperti tampak pada bagan di bawah ini.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
243
2. Analisis Data
Apabila data sudah dimasukkan, maka selanjutnya dapat dilakukan analisis untuk menguji
multikolinieritas. Pengujian multikolinieritas dengan SPSS ada pada modul regresi dengan memilih
menu dan sub-menu seperti berikut.
Analyze
Regression
Linier …
Apabila menu tersebut sudah dipilih, maka akan muncul kotak dialog seperti berikut.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
244
Pindahkan variabel Y ke dependent list dan variabel X1, X2, dan X3 ke independent list. Setelah itu
pilih boks statistics, dan pilih colliniearity diagnostics, sehingga tampak kotak dialog seperti berikut.
Selanjutnya pilih continue, lalu OK.
Apabila semua proses di atas sudah dilakukan maka akan muncul output hasil analisis. Output terdiri
dari beberapa bagian. Bagian yang paling penting adalah tabel Collinearity Statistics seperti tampak di
bawah ini.
Coefficients
Unstanda
rdized
Standardize
d
t Sig. Collinearity
Statistics

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
245
Coefficie
nts
Coefficients
Model B Std. Error Beta Tolerance VIF
1 (Constant) 10,394 9,007 1,154 ,273
X1 1,017 ,250 ,949 4,076 ,002 ,292 3,424
X2 -,410 ,414 -,421 -,991 ,343 ,088 11,371
X3 ,357 ,334 ,390 1,067 ,309 ,119 8,426
a Dependent Variable: Y
Pada tabel di atas tampak nilai tolerance dan VIF dari masing-masing variabel bebas. Nilai VIF dari
variabel X1 besarnya 3,424, sehingga tolerance 0,292. Nilai VIF dari variabel X2 besarnya 11,371,
sehingga tolerance 0,088. Nilai VIF dari variabel X3 besarnya 8,426, sehingga tolerance 0,119.
Ternyata, nilai VIF dari variabel X2 melebihi 10. Jadi variabel X2 mengalami multikolinieritas. Bila
dilihat nilai tolerance, untuk variabel X2 nilai tolerance kurang dari 0,1. Jadi variabel X2 mengalami
multikolinieritas. Hasil pengujian multikolinieritas secara manual sama dengan hasil pengujian
multikolinieritas dengan SPSS.
9.3.4 Pengujian Autokorelasi
9.3.4.1 Pengujian Autokorelasi Secara Manual
Autokorelasi terjadi dalam regresi apabila dua error εt-1 dan εt tidak independent atau C(εt-1, εt) ≠ 0.
Autokorelasi biasanya terjadi apabila pengukuran variabel dilakukan dalam intereval watu tertentu.
Hubungan antara εt dengan εt-1 dapat dinyatakan seperti berikut.
εt = ρ εt-1 + vt
Pada persamaan di atas ρ menyatakan koefisien autokorelasi populasi. Apabila ρ=0, maka autokorelasi
tidak terjadi. Apabila autokorelasi terjadi, maka ρ akan mendekati +1 atau -1. Menduga terjadi
tidaknya autokorelasi dengan diagram antara grafik antara εt dengan εt-1 sangat sulit. Deteksi
autokorelasi umumnya dilakukan dengan uji statistik Durbin-Watson, yang ditemukan oleh dua orang
pakar asal Inggris, yakni Durbin dan Watson. Koefisien uji statistik Durbin-Watson dinyatakan dengan
d yang dihitung dengan menggunakan formula sebagai berikut.
n
t
t
n
t
tt
e
ee
d
1
2
2
2
1)(
Nilai d berkisar antara 0 dan 4 (0≤d≤4). Untuk mencapai kesimpulan, nilai d yang diperoleh dari
perhitungan dikoreksi dengan nilai d yang diperoleh dari tabel distribusi d atau tabel nilai Durbin-
Watson. Tabel nilai Durbin-Watson memuat dua nilai, yakni dL (d-Lower) dan dU (d-Upper). Hipotesis
nol yang diuji dalam uji statistik Durbin-Watson adalah: H0: ρ=0: tidak terjadi autokorelasi. Pengujian
hipotesis pada uji statistik Durbin-Watson sedikit berbeda dengan uji hipotesis pada uji statistik yang
lain. Umumnya uji hipotesis pada uji statistik hanya memiliki dua alternatif, yaitu terima hipotesis nol
dan tolak hipotesis alternatif atau terima hipotesis nol dan tolak hipotesis alternatif. Uji hipotesis pada
uji statistik Durbin-Watson memiliki lima alternatif seperti berikut.
1) Jika d<dL, maka terjadi autokorelasi positif yang serius, sehingga wajib dilakukan koreksi.
2) Jika dL<d<dU, maka terjadi autokorelasi positif yang lemah, sehingga bisa tidak dilakukan koreksi.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
246
3) Jika dU<d<4-dU, maka tidak terjadi autokorelasi.
4) Jika 4-dU<d<4-dL, maka terjadi autokorelasi negatif yang lemah, sehingga bisa tidak dilakukan
koreksi.
5) Jika 4-dL<d, maka terjadi autokorelasi negatif yang serius, sehingga wajib dilakukan koreksi.
Berikut ini disajikan contoh uji autokorelasi menggunakan uji statistik Durbin-Watson. Mari kita lihat
lagi contoh penelitian yang mengkaji hubungan antara motivasi belajar (X) dan hasil belajar (Y) yang
sudah dibahas pada analisis regresi linier. Data penelitian dikumpulkan dari 15 orang responden
sebagai berikut.
No. Motivasi Belajar
(X)
Hasil Belajar
(Y)
1 72 84
2 68 80
3 70 82
4 70 78
5 73 84
6 62 68
7 58 64
8 52 62
9 70 80
10 76 85
11 68 70
12 52 65
13 54 68
14 62 64
15 68 76
Contoh penelitian tersebut sudah dibahas sebagai contoh pada analisis regresi linier sederhana dan
sudah menghasilkan persamaan regresi: Ŷ = 0,963 X + 11,413. Pada kesempatan ini dikaji apakah
pada regresi tersebut terjadi persoalan autokorelasi. Hipotesis nol yang diuji adalah: H0: ρ=0: tidak
terjadi autokorelasi. Pengujian dilakukan dengan memakai uji statistik Durbin-Watson. Untuk itu,
terlebih dahulu harus dibuat tabel kerja seperti berikut.
X Y Ŷ et=Y- Ŷ 2
te
1 tt ee 2
1)( tt ee
72 84 80,749 3,251 10,569
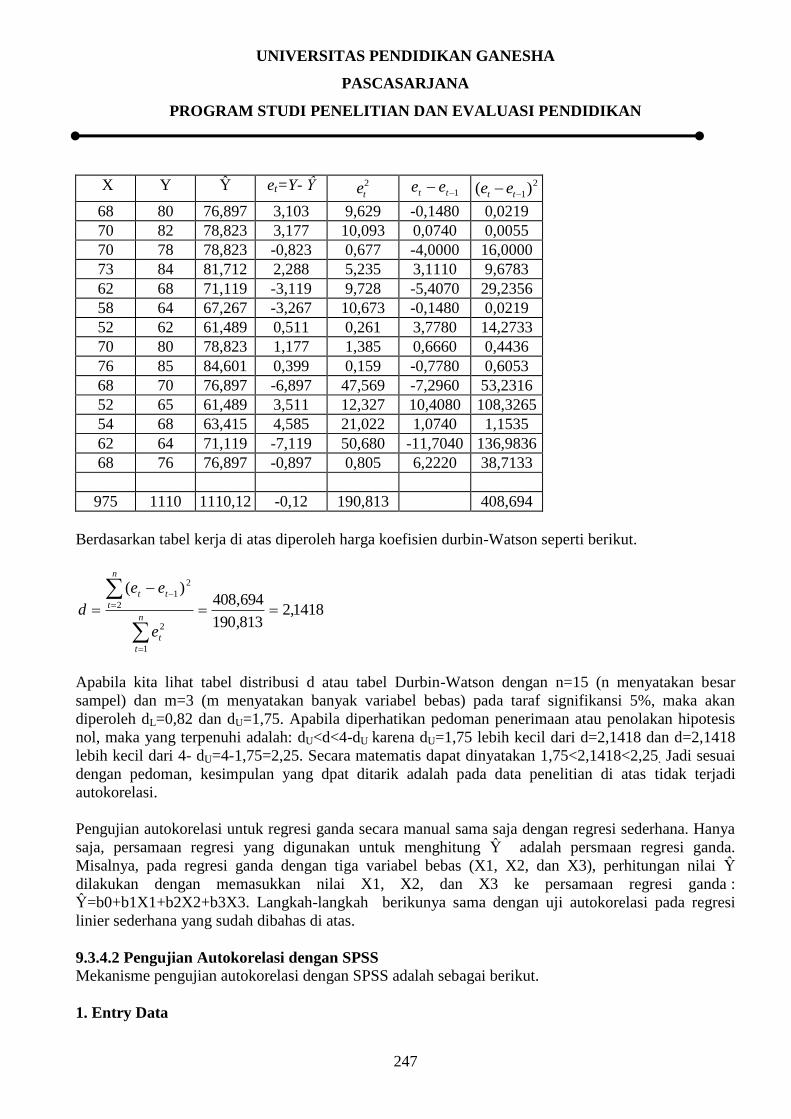
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
247
X Y Ŷ et=Y- Ŷ 2
te
1 tt ee 2
1)( tt ee
68 80 76,897 3,103 9,629 -0,1480 0,0219
70 82 78,823 3,177 10,093 0,0740 0,0055
70 78 78,823 -0,823 0,677 -4,0000 16,0000
73 84 81,712 2,288 5,235 3,1110 9,6783
62 68 71,119 -3,119 9,728 -5,4070 29,2356
58 64 67,267 -3,267 10,673 -0,1480 0,0219
52 62 61,489 0,511 0,261 3,7780 14,2733
70 80 78,823 1,177 1,385 0,6660 0,4436
76 85 84,601 0,399 0,159 -0,7780 0,6053
68 70 76,897 -6,897 47,569 -7,2960 53,2316
52 65 61,489 3,511 12,327 10,4080 108,3265
54 68 63,415 4,585 21,022 1,0740 1,1535
62 64 71,119 -7,119 50,680 -11,7040 136,9836
68 76 76,897 -0,897 0,805 6,2220 38,7133
975 1110 1110,12 -0,12 190,813 408,694
Berdasarkan tabel kerja di atas diperoleh harga koefisien durbin-Watson seperti berikut.
1418,2813,190
694,408)(
1
2
2
2
1
n
t
t
n
t
tt
e
ee
d
Apabila kita lihat tabel distribusi d atau tabel Durbin-Watson dengan n=15 (n menyatakan besar
sampel) dan m=3 (m menyatakan banyak variabel bebas) pada taraf signifikansi 5%, maka akan
diperoleh dL=0,82 dan dU=1,75. Apabila diperhatikan pedoman penerimaan atau penolakan hipotesis
nol, maka yang terpenuhi adalah: dU<d<4-dU karena dU=1,75 lebih kecil dari d=2,1418 dan d=2,1418
lebih kecil dari 4- dU=4-1,75=2,25. Secara matematis dapat dinyatakan 1,75<2,1418<2,25. Jadi sesuai
dengan pedoman, kesimpulan yang dpat ditarik adalah pada data penelitian di atas tidak terjadi
autokorelasi.
Pengujian autokorelasi untuk regresi ganda secara manual sama saja dengan regresi sederhana. Hanya
saja, persamaan regresi yang digunakan untuk menghitung Ŷ adalah persmaan regresi ganda.
Misalnya, pada regresi ganda dengan tiga variabel bebas (X1, X2, dan X3), perhitungan nilai Ŷ
dilakukan dengan memasukkan nilai X1, X2, dan X3 ke persamaan regresi ganda :
Ŷ=b0+b1X1+b2X2+b3X3. Langkah-langkah berikunya sama dengan uji autokorelasi pada regresi
linier sederhana yang sudah dibahas di atas.
9.3.4.2 Pengujian Autokorelasi dengan SPSS
Mekanisme pengujian autokorelasi dengan SPSS adalah sebagai berikut.
1. Entry Data

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
248
Masukkan data ke dalam form SPSS, yakni data motivasi belajar (X1) dengan hasil belajar (Y),
seperti tampak pada bagan di bawah ini.
2. Analisis Data
Menu Autokorelasi ada pada menu Regression dengan langkah-langkah seperti berikut.
Analyze
Regression
Linier
Menu akan tampak seperti bagan di bawah ini.
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
249
Apabila menu tersebut sudah dipilih, maka akan tampak kotak dialog seperti di bawah ini.
Pindahkan y ke dependent variabel, x ke independent(s) variable. Pemindahan dilakukan dengan
meng-klik variabel tersebut dan kemudian meng-klik tanda panah di sebelahnya. Stelah langkah-
langkah itu dilakukan, akan tampak posisi dari variabel bebas (x) dan variabel terikat y pada posisi
masing-masing, seperti tampak pada bagan di bawah ini. Apabila keliru memindahkan variabel, maka
pengembalian dapat dilakukan dengan meng-klik kembali variabel tersebut kemudia
mengembalikannya dengan meng-klik tanda panah yang berlawanan arah.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
250
Pindahkan variabel Y ke dependent list dan variabel X ke independent list. Setelah itu pilih boks
statistics, sehingga tampak kotak dialog seperti di bawah ini. Selanjutnya, pilih Durbin-Watson,
kemudian pilih continue, dan akhirnya klik OK.
Apabila semua proses di atas sudah dilakukan maka akan muncul output hasil analisis. Output terdiri
dari beberapa bagian, termasuk hasil analisis autokorelasi. Bagian yang paling penting adalah tabel
Model Summary seperti tampak di bawah ini.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
251
Model Summary
R R
Square
Adjusted
R Square
Std. Error
of the
Estimate
Change
Statistic
s
Durbin-
Watson
Model R
Square
Change
F
Change
df1 df2 Sig. F
Change
1 ,898 ,807 ,792 3,8312 ,807 54,449 1 13 ,000 2,142
a Predictors: (Constant), X1
b Dependent Variable: Y
Apabila kita lihat tabel distribusi d atau tabel Durbin-Watson dengan n=15 (n menyatakan besar
sampel) dan m=3 (m menyatakan banyak variabel bebas) pada taraf signifikansi 5%, maka akan
diperoleh dL=0,82 dan dU=1,75. Apabila diperhatikan pedoman penerimaan atau penolakan hipotesis
nol, maka yang terpenuhi adalah: dU<d<4-dU karena dU=1,75 lebih kecil dari d=2,142 dan d=2,1418
lebih kecil dari 4- dU=4-1,75=2,25. Secara matematis dapat dinyatakan 1,75<2,142<2,25. Jadi sesuai
dengan pedoman, kesimpulan yang dpat ditarik adalah pada data penelitian di atas tidak terjadi
autokorelasi.
Pengujian autokorelasi untuk regresi ganda dengan menggunakan SPSS sama saja dengan regresi
sederhana. Hanya saja, variabel bebas yang dimasukkan tentunya lebih dari satu. Misalnya, pada
regresi ganda dengan tiga variabel bebas (X1, X2, dan X3) uji autokorelasi dengan SPSS akan
memasukkan tiga variabel bebas tersebut.
9.3.5 Pengujian Heterokedastisitas
9.3.5.1 Pengujian Heterokedastisitas Secara Manual
Heterokedastisitas artinya varian ei tidak konstan melainkan berubah-ubah. Padahal regresi
mempersyaratkan varian ei konstan. Pengujian heterokedastistas dilakukan dengan membuat diagram
pencar antara e dengan Ŷ. Apabila sebaran diagram membentuk pola yang berubah-ubah, maka dapat
dikatakan bahwa pada regresi tersebut sudah terjadi masalah heterokedastisitas. Apabila sebaran
diagram terkonsentrasi pada satu wilayah, maka dapat dikatakan bahwa pada regresi tersebut tidak
terjadi masalah heterokedastisitas.
Gambar A, B, dan C di atas
menunjukkan diagram
pencar antara e dan Ŷ atau
(e, Ŷ ). Pada Gambar A
varian nilai e meningkat,
sedangkan pada Gambar B
Gambar A Gambar B Gambar C

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
252
varian e berubah. Artinya, pada regresi yang dilukiskan oleh Gambar A dan Gambar B terjadi masalah
heterokedastisitas. Sementara itu varian e pada Gambar C konstan. Jadi pada regresi yang dilukiskan
pada Gambar C tidak terjadi masalah heterokedastisitas.
Berikut ini disajikan contoh pengujian heterokedastisitas. Kita lihat kembali contoh penelitian yang
mengkaji hubungan antara motivasi belajar (X) dan hasil belajar (Y) yang sudah dibahas pada analisis
regresi linier. Persamaan regresinya adalah: Ŷ = 0,963 X + 11,413. Pada kesempatan ini dikaji apakah
pada regresi tersebut terjadi persoalan heterokedastisitas. Pengujian dilakukan dengan membuat
diagram pencar (e,Ŷ). Untuk itu, kita lihat kembali sebagian tabel kerja yang sudah dibuat pada
pengujian autokorelasi seperti berikut.
X Y Ŷ et=Y- Ŷ
72 84 80,749 3,251
68 80 76,897 3,103
70 82 78,823 3,177
70 78 78,823 -0,823
73 84 81,712 2,288
62 68 71,119 -3,119
58 64 67,267 -3,267
52 62 61,489 0,511
70 80 78,823 1,177
76 85 84,601 0,399
68 70 76,897 -6,897
52 65 61,489 3,511
54 68 63,415 4,585
62 64 71,119 -7,119
68 76 76,897 -0,897
975 1110 1110,12 -0,12
Berdasarkan tabel kerja di atas dibuat diagram pencar (e,Ŷ) seperti di bawah ini.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
253
Diagram pencar (e,Ŷ) pada gambar di atas menunjukkan bahwa nilai e menyebar secara merata dan
berimbang di atas dan di bawah nol. Di bawah nol titik terjauh berada pada posisi sekitar -7 dan di atas
nol titik terjauh berada pada posisi sekitar 5. Artinya, varian e relatif konstan. Jadi pada regresi di atas
tidak terjadi masalah heterokedastisitas.
9.3.5.2 Pengujian Heterokedastisitas dengan SPSS
Kita akan uji kembali masalah heterokedastisitas pada regresi antara motivasi belajar dengan hasil
belajar yang telah diuji secara manual di atas. Pengujian heterokedastisitas dengan bantuan SPSS
dilakukan dengan mengikuti langkah kerja seperti di bawah ini.
1. Entry Data
Masukkan data ke dalam form SPSS, yakni data motivasi belajar (X1) dengan hasil belajar (Y), seperti
tampak pada bagan di bawah ini.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
254
2. Analisis Data
Menu Autokorelasi ada pada menu Regression dengan langkah-langkah seperti berikut.
Analyze
Regression
Linier
Menu akan tampak seperti bagan di bawah ini.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
255
Apabila menu tersebut sudah dipilih, maka akan tampak kotak dialog seperti di bawah ini. Pindahkan y
ke dependent variabel, x ke independent(s) variable. Pemindahan dilakukan dengan meng-klik
variabel tersebut dan kemudian meng-klik tanda panah di sebelahnya. Stelah langkah-langkah itu
dilakukan, akan tampak posisi dari variabel bebas (x) dan variabel terikat y pada posisi masing-
masing, seperti tampak pada bagan di bawah ini. Apabila keliru memindahkan variabel, maka
pengembalian dapat dilakukan dengan meng-klik kembali variabel tersebut kemudia
mengembalikannya dengan meng-klik tanda panah yang berlawanan arah.
Pindahkan variabel Y ke dependent list dan variabel X ke independent list. Setelah itu pilih kotak
plots, sehingga muncul kotak dialog seperti di bawah ini. Selanjutnya, masukkan *SRESID ke Y dan
*ZPRED ke X. Pada bagian akhir dipilih continue, kemudian OK

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
256
Setelah itu, akan tampak hasil analisis seperti di bawah ini (ditampilkan hanya sebagian).
Scatterplot
Dependent Variable: Y
Regression Standardized Predicted Value
1,51,0,50,0-,5-1,0-1,5-2,0
Reg
ress
ion
Stu
dent
ized
Res
idua
l
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
-2,0
Pada diagram pencar di atas titik-titik menyebar secara merata dan berimbang, baik di atas dan di
bawah sumbu X maupun di atas dan di bawah sumbu Y. Titik-titik menyebar merata tidak membentuk
pola tertentu. Oleh karena itu, dapat disimpulkan bahwa pada regresi di atas tidak terjadi masalah
heterokedastisitas.
9.3.6 Pengujian Homogenitas Varian
9.3.6.1 Pengujian Homogenitas Varian Secara Manual
Analisis varians (ANAVA), analisis kovarians atau analyses of covarians (ANACOVA), analisis
varians ganda atau analyses of multiple varians (MANOVA), dan uji-t (t-test) mempersyaratkan atau
mengasumsikan adanya homogenitas varians antar-kelompok. Dengan kata lain, varians antar-
kelompok harus homogen. Apabila varians antar-kelompok tidak homogen, maka perbedaan nilai
antar-kelompok dapat terjadi akibat perbedaan nilai yang terjadi dalam kelompok. Kondisi seperti ini
dapat mengakibatkan kekeliruan dalam pengujian hipotesis, khususnya hipotesis tentang perbedaan.
Oleh karena itu, apabila varians antar-kelompok tidak homogeny, maka ANAVA, ANACOVA,
MANOVA, atau uji-t tidak dapat dilanjutkan. Khusus untuk uji-t, ada formula yang dapat digunakan

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
257
apabila varians antar-kelompok tidak homogeny. Uji homogenitas dimaksudkan untuk memperlihatkan
bahwa dua atau lebih kelompok data sampel berasal dari populasi yang memiliki variansi yang sama.
Hipotesis statistic yang diuji adalah:
H0 : 12 = 2
2 = 3
2 = …. = k
2
H1 : Paling tidak dua varians tidak sama.
H1 : Salah satu tanda = pada H0 tidak berlaku.
9.3.6.1.1 Uji Homogenitas Varians dengan Uji Bartlet
Uji Bartlet dilakukan dengan menghitung 2. Harga
2 yang diperoleh dari perhitungan (
2–hitung)
selanjutnya dibandingkan dengan nilai 2 dari tabel distribusi
2 (tabel distribusi Chi Kuadrat) pada
taraf signifikansi yang ditentukan dengan derajat kebebasan (dk)=k-1, yang mana k menyatakan
banyak kelompok. Bila 2–hitung lebih kecil daripada
2–tabel, maka hipotesis nol diterima. Artinya,
varians data pada setiap kelompok homogen atau sering disebut bahwa kelompok data berasal dari
populasi yang homogen. Langkah-langkah perhitungan 2 adalah sebagai berikut. Pertama dibuat table
kerja seperti di bawah ini.
Sampel dk 1/dk s12 log s1
2 dk * s1
2 Dk * log s1
2
Total
Selanjutnya dihitung varians gabungan (s2) dengan rumus:
s2 =
dk
sdk )(2
1
Bila harga varians gabungan (s2) sudah diperoleh, maka selanjutnya dihitung nilai B dengan rumus:
B = ( dk ) log s2
Setelah ditemukan nilai B, dilakukan perhitungan untuk mendapatkan nilai 2 dengan menggunakan
rumus:
2 = (ln 10) { B - (dk log s
2 )}
Akhirnya, nilai 2 yang diperoleh dari perhitungan dibandingkan dengan nilai
2 yang diperoleh dari
table distribusi 2 (table distribusi Chi-kuadrat). Apabila
2-hitung lebih kecil daripada
2-tabel),
maka hipotesis nol ditolak, Jadi kelompok data memiliki varians yang homogen.
Berikut ini disajikan sebuah contoh penerapan uji Bartlet.
Sebuah penelitian ingin membandingkan tingkat kemandirian anak (Y) berdasarkan kelompok daerah,
yaitu pedesaan (Y1), pinggiran kota (Y2), dan perkotaan (Y3). Data yang diperoleh adalah seperti
berikut.
NO. Y1 Y2 Y3 NO. Y1 Y2 Y3

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
258
NO. Y1 Y2 Y3 NO. Y1 Y2 Y3
1 61 80 73 11 88 55 33
2 75 42 51 12 69 75 64
3 70 67 65 13 58 61 33
4 57 54 47 14 48 57 68
5 78 73 64 15 47 85 45
6 52 25 56 16 45 70 72
7 53 65 87 17 64 62 25
8 86 27 36 18 36 47 63
9 48 77 67 19 52 86 53
10 85 61 76 20 32 60 43
Apabila dihitung varian (s2) dari masing-masing kelompok data di atas, maka diperoleh:
s12 = 266,48
s22 = 284,16
s32 = 276,47
Hipotesis Statistik yang diuji:
H0 : 12 = 2
2 = 3
2
H1 : Paling tidak dua varians tidak sama.
H1 : Salah satu tanda = pada H0 tidak berlaku
Selanjutnya dibuat tabel kerja seperti berikut.
Sampel dk 1/dk s12 log s1
2 dk * s1
2 dk * log s1
2
1 19 0,053 266,48 2,43 5063,12 46,09
2 19 0,053 284,16 2,45 5399,04 46,62
3 19 0,053 276,47 2,44 5252,93 46,39
Total 57 0,1579 827,11 7,32 15715,09 139,10
Hitung varians gabungan:
s2 = 70,275
57
15715,09)(2
1
dk
sdk
log s2
= log 275,70 = 2,44
Hitung nilai B:
B = ( dk ) log s2 = 57 (2,44) = 139,08

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
259
Hitung 2
2 = (ln 10) { B - (dk log s
2 )}
= (2,303) {139,08 – 139,10}
= - 0,046
Dari perhitungan didapat 2 = -0,046, sedangkan dari table nilai distribusi
2 dengan dk=3-1=2 pada
taraf signifikansi 0,05 diperoleh nilai 2-tabel=5,99. Ternyata
2-hitung lebih kecil daripada
2-tabel,
sehingga H0 diterima. Jadi data berasal dari populasi yang homogen.
9.3.6.1.2 Uji Homogenitas Varians dengan Uji Levene
Uji Levene dilakukan dengan menghitung nilai W.dengan rumus:
k
i
n
j
iij
k
i
ii
ddk
ddnkN
W
1 1
2
1
2
)()1(
)()(
Yang mana:
N=banyak data keseluruhan
n=banyak data tiap-tiap kelompok
k=banyak kelompok
dij=|Yij- iY |.
Yij=data sampel ke-j pada kelompok ke-i
iY =rerata kelompok sampel ke-i
id =rerata dij untuk kelompok sampel ke-i
d = rerata seluruh dij.
Pengambilan keputusan dilakukan dengan membandingkan nilai W yang diperoleh dari perhitungan dengan nilai F yang diperoleh dari tabel distribusi F dengan dk pembilang (k-1) dan dk penyebut (N-k) pada taraf signifikansi yang ditetapkan. Apabila nilai W lebih kecil daripada nilai F-tabel, maka hipotesis nol diterima. Artinya, kelompok-kelompok data yang dibandingkan memiliki varian yang homogen. Sebagai contoh penerapan, berikut ini kita uji kembali homogenitas varians data penelitian yang membandingkan tingkat kemandirian anak (Y) berdasarkan kelompok daerah. , yaitu pedesaan (Y1), pinggiran kota (Y2), dan perkotaan (Y3). Sebelumnya homogenitas varians data penelitian sudah diuji dengan uji Bartlet. Sekarang, homogenitas varians data penelitian diuji dengan uji Levene. Untuk itu, mula-mula harus dibuat tabel kerja seperti di bawah ini.
Y1 Y2 Y3 d1 d2 d3 2
1d 2
2d 2
3d
61 80 73 0,80 18,55 16,95 159,26 26,32 12,46
75 42 51 14,80 19,45 5,05 1,90 36,36 70,06
70 67 65 9,80 5,55 8,95 13,10 61,94 19,98
57 54 47 3,20 7,45 9,05 104,45 35,64 19,10
78 73 64 17,80 11,55 7,95 19,18 3,50 29,92

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
260
52 25 56 8,20 36,45 0,05 27,25 530,38 178,76
53 65 87 7,20 3,55 30,95 38,69 97,42 307,30
86 27 36 25,80 34,45 20,05 153,26 442,26 43,96
48 77 67 12,20 15,55 10,95 1,49 4,54 6,10
85 61 76 24,80 0,45 19,95 129,50 168,22 42,64
88 55 33 27,80 6,45 23,05 206,78 48,58 92,74
69 75 64 8,80 13,55 7,95 21,34 0,02 29,92
58 61 33 2,20 0,45 23,05 125,89 168,22 92,74
48 57 68 12,20 4,45 11,95 1,49 80,46 2,16
47 85 45 13,20 23,55 11,05 0,05 102,62 5,62
45 70 72 15,20 8,55 15,95 3,17 23,72 6,40
64 62 25 3,80 0,55 31,05 92,54 165,64 310,82
36 47 63 24,20 14,45 6,95 116,21 1,06 41,86
52 86 53 8,20 24,55 3,05 27,25 123,88 107,54
32 60 43 28,20 1,45 13,05 218,45 143,28 0,14
2
1d
1461,27
2
2d
2264,04
2
3d
1420,20
1Y
60,20
2Y
61,45
3Y
56,05
1d
13,42
2d
12,55
3d
13,85
Berdasarkan tabel kerja di atas, diperoleh nilai d seperti di bawah ini.
.2733,13
3
85,1355,1242,131
k
d
d
k
i
i
Setelah itu dibuat tabel kerja yang kedua sebagai berikut.
id dd i 2ddn ii
13,4200 0,1467 0,4302
12,5500 0,7233 10,4642
13,8500 0,5767 6,6509
k
i
ii ddn1
2
17,5453
5145,5081420,202264,041461,27 )(1 1
2
k
i
n
j
iij dd

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
261
Dengan demikian W dapat dihitung seperti berikut.
k
i
n
j
iij
k
i
ii
ddk
ddnkN
W
1 1
2
1
2
)()1(
)()(
09718,010291,016
0821,1000
)508,5145()13(
)5453,17()360(
x
xW
Apabila dilihat nilai F pada tabel distribusi F dengan dk pembilang=3-1=2 dan dk penyebut=60-3=57
pada taraf signifikansi 0,05, maka diperoleh nilai F-tabel=5,06. Terjnyata nilai W (0,09718) jauh lebih
kecil daripada nila F-tabel (5,06). Dengan demikian hipotesis nol diterima. Jadi semua kelompok data
memiliki varians yang homogen.
9.3.6.2 Uji Homogenitas Varians dengan SPSS
Pengujian hogenitas varians dengan SPSS dilakukan dengan langkah-langkah: 1) entry data, 2) analisis
data, dan 3) menginterpretasikan hasil analisis. Sebagai contoh penerapan kita uji kembali
homogenitas varioans data penelitian yang membandingkan tingkat kemandirian anak (Y) berdasarkan
kelompok daerah, yaitu pedesaan (Y1), pinggiran kota (Y2), dan perkotaan (Y3). Sebelumnya
homogenitas varians data sudah diuji secara manual, baik dengan uji Bartlet maupun dengan uji
Levene. Sekarang kita uji lagi homogenitas varians data dengan SPSS.
1. Entry Data
Uji homogenitas varians dapat dilakukan sekaligus dengan uji ANAVA karena pada uji ANAVA ada
menu untuk melakukan uji homogenitas varians. Oleh karena itu, entry data untuk uji homogenitas
varians sama dengan uji ANAVA yakni disambung. Entry data untuk uji homogenitas data
kemandirian anak berdasarkan kelompok daerah, yaitu pedesaan (Y1), pinggiran kota (Y2), dan
perkotaan (Y3) adalah seperti bagan di bawah ini. Tampak pada bagan di bawah bahwa data Y1, data
Y2, dan data Y3 disambung ke bawah dan diberi nama variabel mandiri (singkatan dari kemadirian).
Kemudian, untuk mengenali data Y1, data Y2, dan data Y3 dibuat dua variabel baru yang diberi nama
grup. Grup boleh dibuat bertipe numerik atau bilangan (misalnya 1, 2, dan 3 karena ada 3 kelompok)
dan boleh juga dibuat bertipe string (misalnya g1, g2, dan g3).
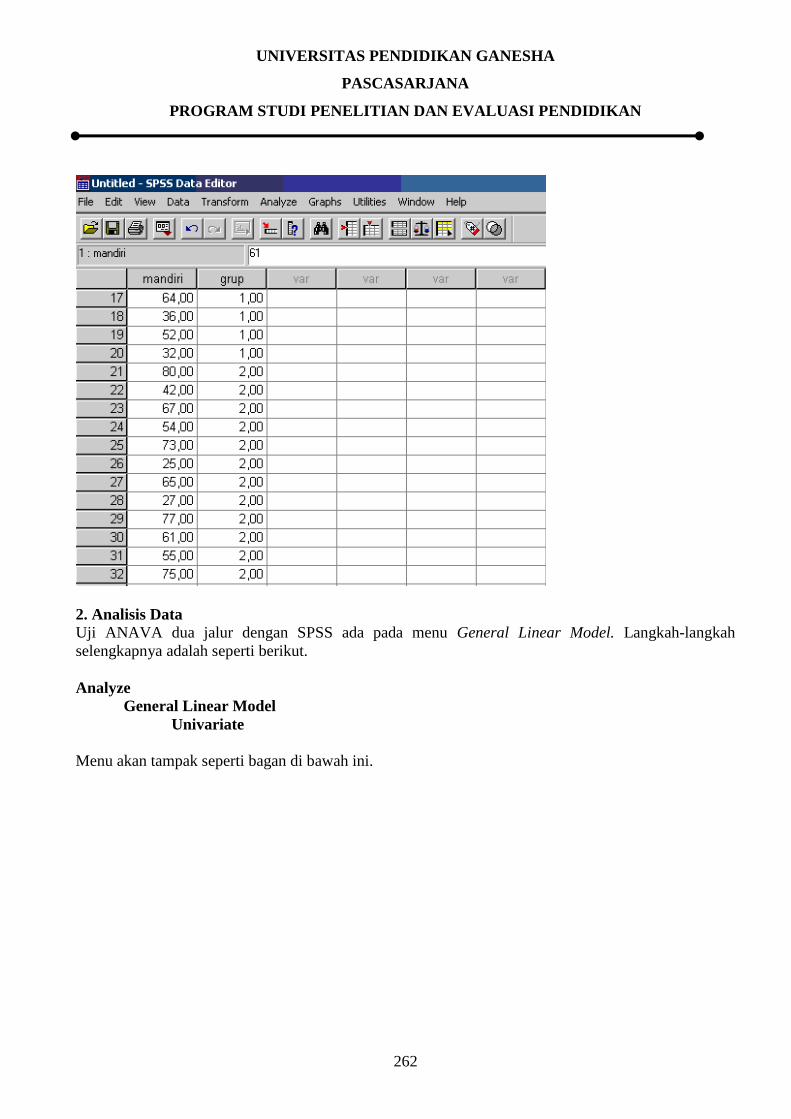
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
262
2. Analisis Data
Uji ANAVA dua jalur dengan SPSS ada pada menu General Linear Model. Langkah-langkah
selengkapnya adalah seperti berikut.
Analyze
General Linear Model
Univariate
Menu akan tampak seperti bagan di bawah ini.
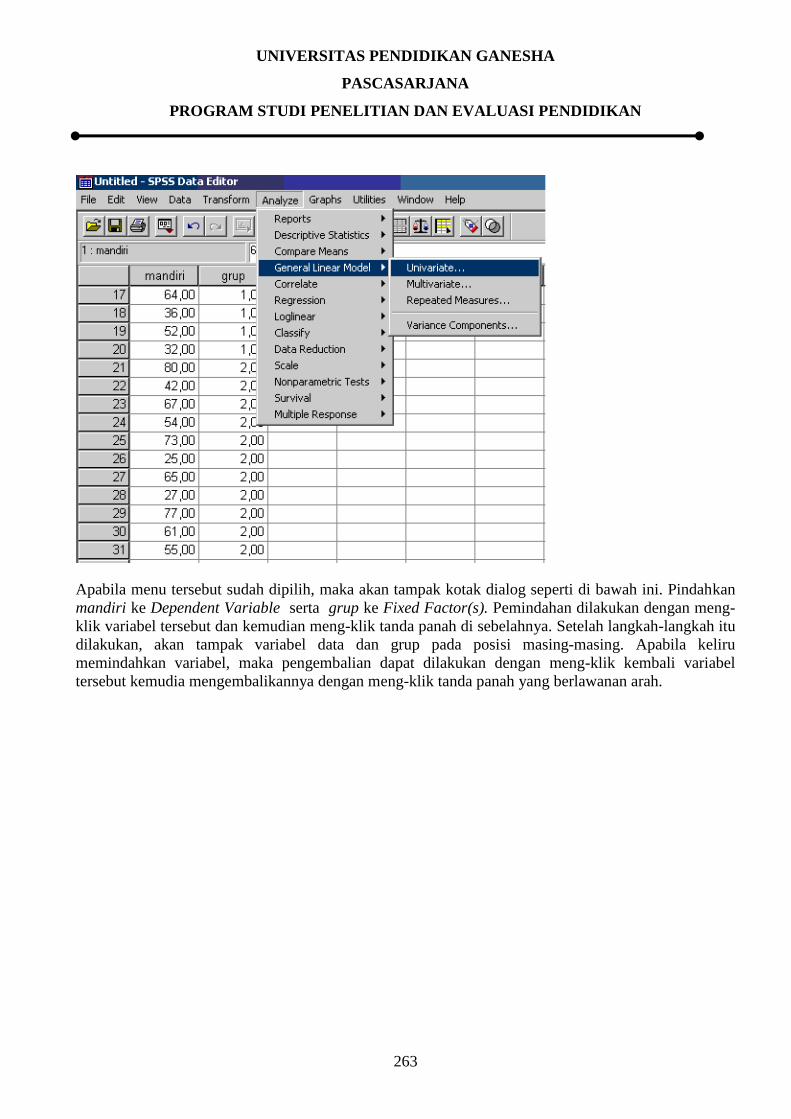
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
263
Apabila menu tersebut sudah dipilih, maka akan tampak kotak dialog seperti di bawah ini. Pindahkan
mandiri ke Dependent Variable serta grup ke Fixed Factor(s). Pemindahan dilakukan dengan meng-
klik variabel tersebut dan kemudian meng-klik tanda panah di sebelahnya. Setelah langkah-langkah itu
dilakukan, akan tampak variabel data dan grup pada posisi masing-masing. Apabila keliru
memindahkan variabel, maka pengembalian dapat dilakukan dengan meng-klik kembali variabel
tersebut kemudia mengembalikannya dengan meng-klik tanda panah yang berlawanan arah.
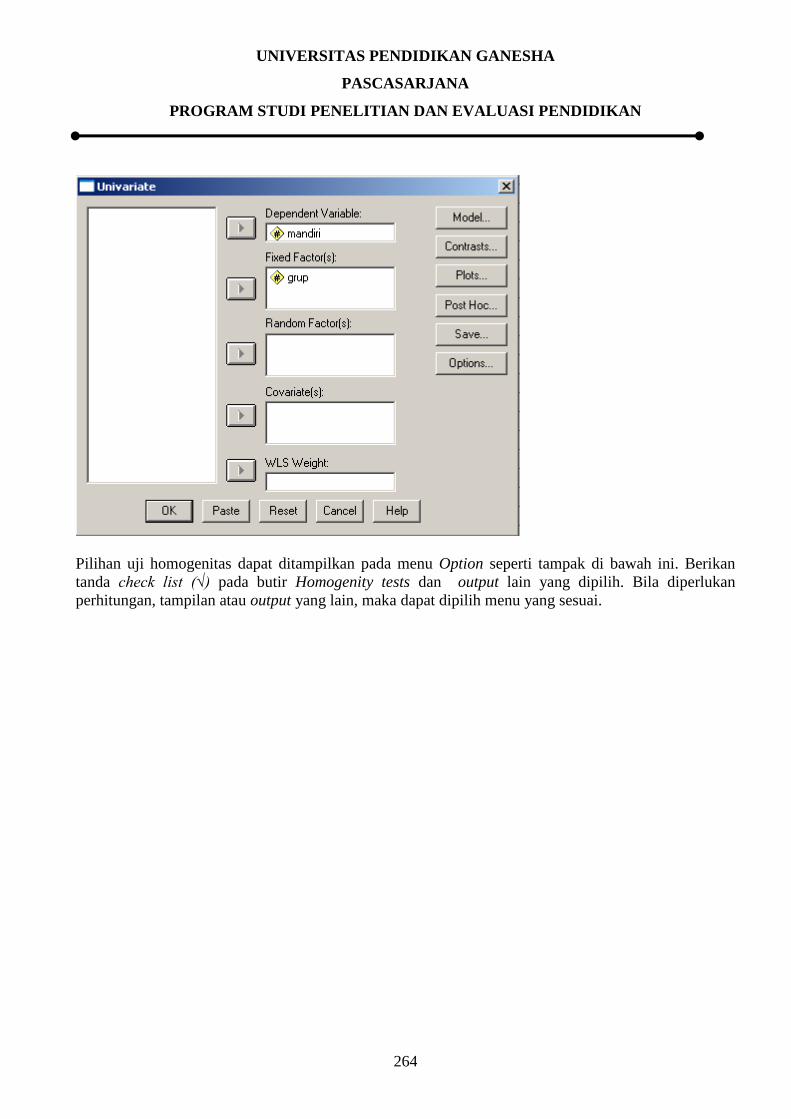
UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
264
Pilihan uji homogenitas dapat ditampilkan pada menu Option seperti tampak di bawah ini. Berikan
tanda check list (√) pada butir Homogenity tests dan output lain yang dipilih. Bila diperlukan
perhitungan, tampilan atau output yang lain, maka dapat dipilih menu yang sesuai.

UNIVERSITAS PENDIDIKAN GANESHA
PASCASARJANA
PROGRAM STUDI PENELITIAN DAN EVALUASI PENDIDIKAN
265
Bila semua perhitungan, tampilan, dan output yang diinginkan sudah dipilih, maka dilanjutkan dengan
memilih Ok. Dengan demikian akan muncul output yang diinginkan. Output berupa beberapa tabel
(sesuai permintaan). Tabel yang penting adalah tabel Levene's Test of Equality of Error Variances
yang memuat hasil uji homogenitas varians dengan uji Levene seperti di bawah ini.
Levene's Test of Equality of Error Variances
Dependent Variable: MANDIRI
F df1 df2 Sig.
,098 2 57 ,907
Tests the null hypothesis that the error variance of the dependent variable is equal across groups.
a Design: Intercept+GRUP
3. Menafsirkan Hasil Uji Homogenitas Varians
Tabel Levene's Test of Equality of Error Variances menunjukkan nilai F=0,98 dengan dk pembilang 2
dan dan dk penyebut 57 dan nilai signifikansi (sig.) sama dengan 0,907. Apabila dittapkan taraf
signifikansi α=0,05, maka nilai sig. jauh lebih besar daripada nilai α. Dengan demikian hipotesis nol
diterima. Artinya, semua kelompok data memiliki varians yang homogen.




















