PRAKTIKUM 1 PENGENALAN SPSS - …suparti.blog.undip.ac.id/files/MODUL-PRAKTIKUM-SPSS-PWK.pdf ·...
20
PRAKTIKUM 1 PENGENALAN SPSS 1. MEMULAI SPSS Jika anda akan memulai SPSS 10.0 for Windows, langkah yang harus anda lakukan adalah : a. Klik menu START, kemudian pilih All Programs. Gambar 1. Menu memulai SPSS b. Pilih item SPSS for Window, kemudian klik SPSS 10.0 for Windows, maka akan muncul gambar 2 berikut ini : Gambar 2. Jendela data editor dan jendela menu pilihan lain Dalam tampilan tersebut ada dua buah jendela atau window. Yang pertama adalah SPSS data editor dan yang ke dua adalah beberapa menu pilihan yang dapat digunakan dalam analisis lebih lanjut yang berkaitan dengan manajemen data. Klik kotak dialog Cancel pada menu pilihan untuk menyembunyikan jendela ini. 2. MENU UTAMA SPSS Beberapa menu utama yang penting dalam SPSS adalah sebagai berikut: File; berisi fasilitas pengelolaan atau manajemen data dan file Transform; digunakan untuk memanipulasi data Analyze; digunakan untuk menganalisis data
Transcript of PRAKTIKUM 1 PENGENALAN SPSS - …suparti.blog.undip.ac.id/files/MODUL-PRAKTIKUM-SPSS-PWK.pdf ·...
PRAKTIKUM 1 PENGENALAN SPSS
1. MEMULAI SPSS
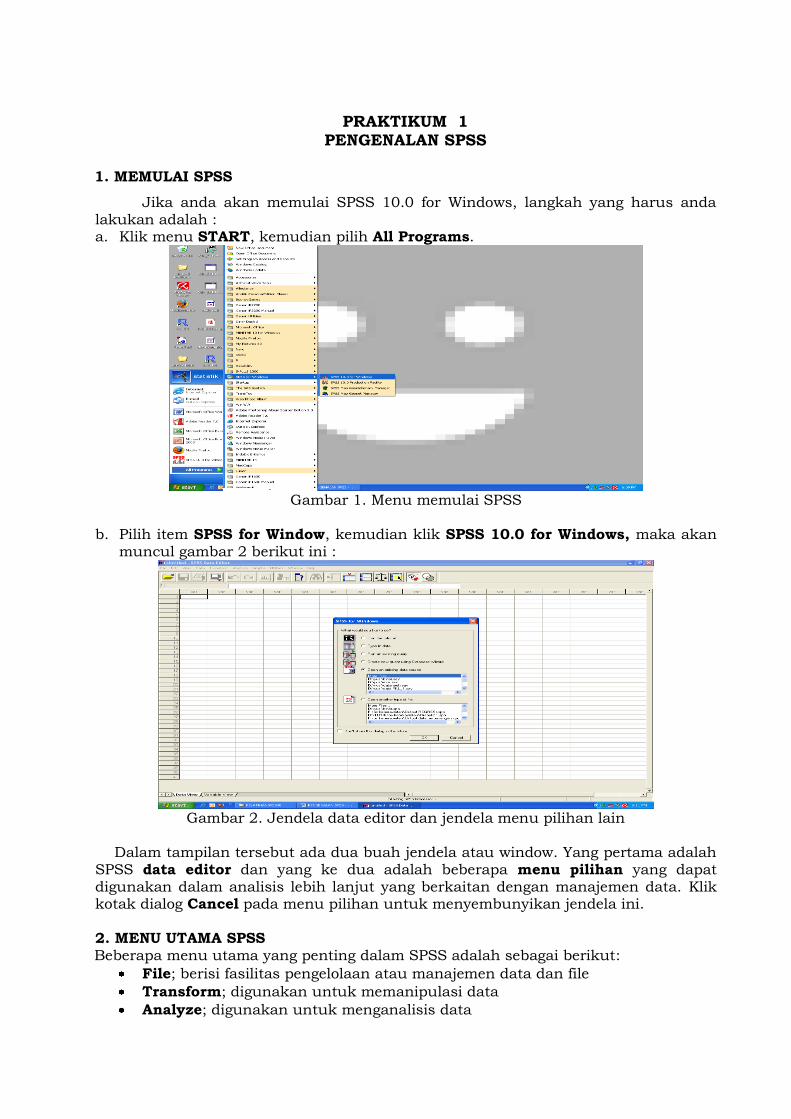
Jika anda akan memulai SPSS 10.0 for Windows, langkah yang harus anda lakukan adalah : a. Klik menu START, kemudian pilih All Programs.
Gambar 1. Menu memulai SPSS
b. Pilih item SPSS for Window, kemudian klik SPSS 10.0 for Windows, maka akan
muncul gambar 2 berikut ini :
Gambar 2. Jendela data editor dan jendela menu pilihan lain
Dalam tampilan tersebut ada dua buah jendela atau window. Yang pertama adalah
SPSS data editor dan yang ke dua adalah beberapa menu pilihan yang dapat digunakan dalam analisis lebih lanjut yang berkaitan dengan manajemen data. Klik kotak dialog Cancel pada menu pilihan untuk menyembunyikan jendela ini. 2. MENU UTAMA SPSS Beberapa menu utama yang penting dalam SPSS adalah sebagai berikut:
File; berisi fasilitas pengelolaan atau manajemen data dan file
Transform; digunakan untuk memanipulasi data
Analyze; digunakan untuk menganalisis data

Graph; digunakan untuk memvisualkan data
Utilities; digunakan berkaitan dengan utilitas dalam SPSS 10.0. Menu-menu tersebut bisa anda lihat pada gambar 3 berikut :
gambar 3. Jendela data editor
3. PENDEFINISIAN VARIABEL
Jika anda bekerja pada Software SPSS maka anda pertama-tama harus mempunyai data yang berada dalam sususan tabel. Cara pemasukan data bisa dilakukan dengan dua cara yaitu memasukkan data terlebih dahulu kemudian mendefinisikan nama variabel atau sebaliknya.
i. Memasukkan data terlebih dahulu kemudian mendefinisikan nama variabel. Untuk dapat memasukkan data maka pada jendela data editor, kotak data view
yang berada pada bagian pojok kiri bawah harus aktif (berwarna putih). Langkah yang harus dilakukan adalah :
a. Dari menu utama data dapat langsung dimasukkan ke dalam sel-selnya seperti terlihat pada gambar 4.
Gambar 4. contoh data
Jika anda memasukkan data pada kolom-kolom data editor, nama variabel yang muncul adalah var00001,var00002, dst. Ini adalah nama variabel default pada SPSS jika kita tidak mendefinisikan nama variabel. Dan untuk variabel dengan type numerik mempunyai default 2 decimal.
b. Berikutnya anda ganti nama variabel dengan nama yang sesuai. Misalnya urutan
nama variabelnya adalah Nama, Kelamin, Umur. Caranya adalah klik Variable view pada pojok kiri bawah data editor sehingga muncul gambar 5 berikut. Gantilah default variabel SPSS dengan nama variabel yang sesuai dan isikan type, desimal ,dll sesuai data.
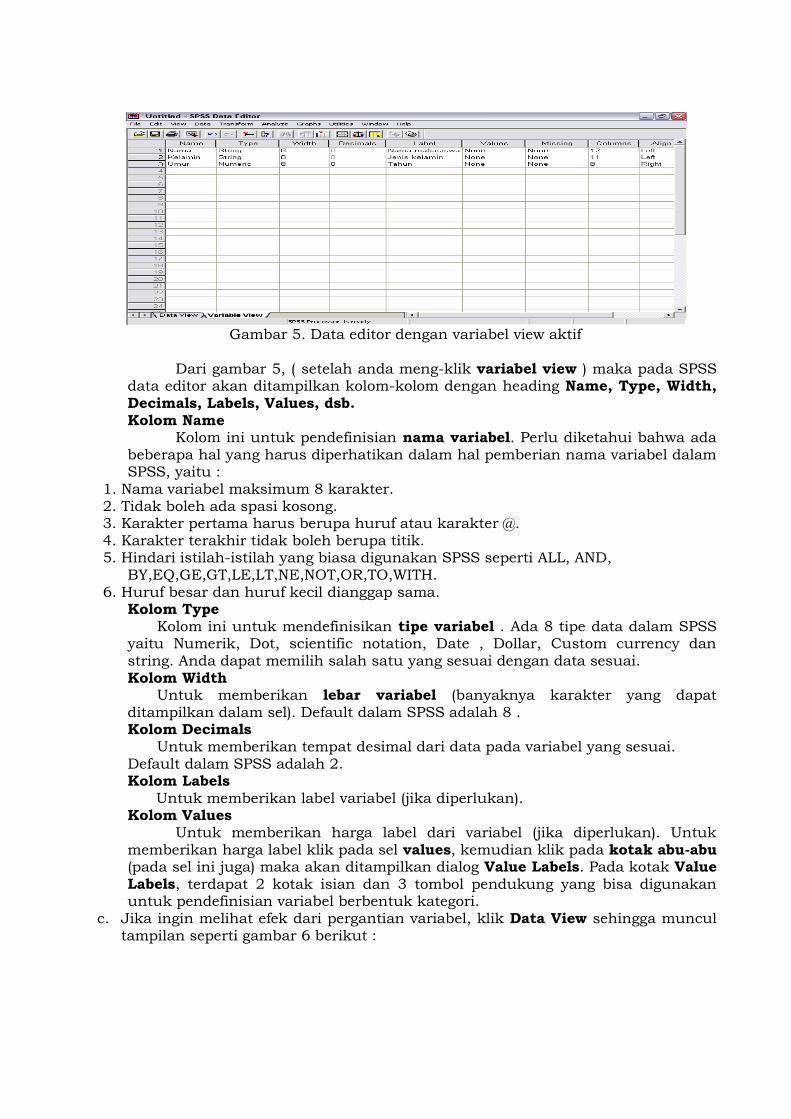
Gambar 5. Data editor dengan variabel view aktif
Dari gambar 5, ( setelah anda meng-klik variabel view ) maka pada SPSS
data editor akan ditampilkan kolom-kolom dengan heading Name, Type, Width, Decimals, Labels, Values, dsb. Kolom Name
Kolom ini untuk pendefinisian nama variabel. Perlu diketahui bahwa ada beberapa hal yang harus diperhatikan dalam hal pemberian nama variabel dalam SPSS, yaitu :
1. Nama variabel maksimum 8 karakter. 2. Tidak boleh ada spasi kosong. 3. Karakter pertama harus berupa huruf atau karakter @. 4. Karakter terakhir tidak boleh berupa titik. 5. Hindari istilah-istilah yang biasa digunakan SPSS seperti ALL, AND,
BY,EQ,GE,GT,LE,LT,NE,NOT,OR,TO,WITH. 6. Huruf besar dan huruf kecil dianggap sama.
Kolom Type Kolom ini untuk mendefinisikan tipe variabel . Ada 8 tipe data dalam SPSS
yaitu Numerik, Dot, scientific notation, Date , Dollar, Custom currency dan string. Anda dapat memilih salah satu yang sesuai dengan data sesuai. Kolom Width
Untuk memberikan lebar variabel (banyaknya karakter yang dapat ditampilkan dalam sel). Default dalam SPSS adalah 8 . Kolom Decimals
Untuk memberikan tempat desimal dari data pada variabel yang sesuai. Default dalam SPSS adalah 2. Kolom Labels
Untuk memberikan label variabel (jika diperlukan). Kolom Values
Untuk memberikan harga label dari variabel (jika diperlukan). Untuk memberikan harga label klik pada sel values, kemudian klik pada kotak abu-abu (pada sel ini juga) maka akan ditampilkan dialog Value Labels. Pada kotak Value Labels, terdapat 2 kotak isian dan 3 tombol pendukung yang bisa digunakan untuk pendefinisian variabel berbentuk kategori.
c. Jika ingin melihat efek dari pergantian variabel, klik Data View sehingga muncul tampilan seperti gambar 6 berikut :

Gambar 6. Tampilan data
ii. Mendefinisikan variabel terlebih dahulu kemudian memasukkan data.
Langkah-langkah yang harus dilakukan adalah sebagai berikut (sebelumnya pilihlah menu File, kemudian New, Data untuk memasukkan /membuat data baru jika sebelum ini anda telah memasukkan data ) : 1. Aktifkan Variable View (di pojok kiri bawah). 2. Isikan nama variabel pada kolom Name seperti tampilan pada gambar 7 di
bawah ini :
Gambar 7. Data editor dengan variabel view aktif
3. Atur kolom Type sesuai kebutuhan dengan mengklik pada sel yang sudah ada
nama variabelnya, pilihlah tipe data, lebar dan banyaknya decimal yang sesuai.
Gambar 8. Type variabel dalam SPSS
4. Klik tombol OK untuk melanjutkan, atau Cancel kalau ingin membatalkan. 5. Setelah pendefinisian dilakukan maka pengisian data dapat dilakukan dengan
mengaktifkan terlebih dahulu Data View seperti pada gambar 9. Selanjutnya isikan datanya seperti data pada gambar 6.

Gambar 9. Tampilan data editor setelah pendefinisian variabel
4. MENYIMPAN DATA Menyimpan dokumen adalah merekam semua dokumen ke dalam disket atau hard disk. Data dalam SPSS mempunyai ekstensi sav (.sav). Sedangkan output dari hasil pengolahan data yang dilakukan oleh SPSS berekstensi spo (.spo).
Adapun langkah-langkah untuk menyimpan adalah sebagai berikut : i. Menyimpan Data
a. Jika file data belum dibuka, maka buka terlebih dahulu file data yang akan disimpan.
b. Kemudian pilih menu File, Save as (bila belum pernah disimpan) atau Save (bila sudah pernah di simpan), sehingga muncul gambar berikut :
Gambar 10. Layar tempat penyimpanan data
c. Pilih tempat untuk menyimpan data dengan cara klik pada kotak
pilihan Save in. d. Jika sudah dapat tempat, pada kotak isian File name, isikan nama file
data tersebut dengan extensi .sav (ekstensi .sav boleh tidak diketikkan pada nama file. Meskipun kita tidak mengetik ekstensi .sav, secara otomatis dalam penyimpanan data ekstensi .sav akan muncul sendiri).
e. Bila pemberian nama sudah benar, kemudian klik tombol Save. ii. Menyimpan Output (Hasil)
a. Jika file output belum dibuka, maka buka terlebih dahulu file output yang akan disimpan.
b. Kemudian pilih menu File, Save as (bila belum pernah disimpan) atau Save (bila sudah pernah di simpan), sehingga muncul gambar 9.

c. Pilih tempat untuk menyimpan output dengan cara klik pada kotak pilihan Save in.
d. Jika sudah dapat tempat, pada kotak isian File name, isikan nama file output tersebut dengan extensi .spo (ekstensi .spo boleh tidak diketikkan pada nama file output).
e. Bila pemberian nama sudah benar, kemudian klik tombol Save.
5. MEMANGGIL/MEMBUKA DATA/OUTPUT Membuka atau memanggil data maupun hasil pengolahan data (output),
berarti membuka kembali dokumen yang telah pernah disimpan. Hal ini dilakukan untuk mengadakan perbaikan atau untuk dianalisis hasil pengolahan datanya. i. Memanggil/Membuka Data
Langkah-langkah untuk memanggil/membuka data adalah :
a. Klik icon Open atau pilih menu File, Open, Data, maka muncul
Gambar 11.Layar tempat data tersimpan
b. Tentukan folder (file) yang akan dibuka pada kotak isian Look in. c. Klik nama file yang akan dibuka, kemudian klik tombol Open di sebelah
kanan kotak isian File name. ii. Memanggil/Membuka Hasil (Output)
Langkah-langkah untuk memanggil/membuka hasil (output) adalah : a. Pilih menu File Open Output, maka muncul layar gambar 10.: b. Tentukan folder (file) yang akan dibuka pada kotak isian Look in.. c. Klik nama file yang akan dibuka, kemudian klik tombol Open di sebelah
kanan kotak isian File name. 6. MENGAKHIRI SPSS
Sebagaimana pada perangkat lunak yang lainnya, untuk mengakhiri kerja dari suatu perangkat lunak tersebut dilakukan dengan mengaktifkan menu File, kemudian pilih Exit. Cara lain bisa dilakukan yaitu dengan menekan gambar X (silang/cross) yang ada di baris Title Bar kanan atas.
TUGAS :
Buatlah sebuah file data 15 orang mahasiswa yang berisi Nomor Urut, Nama, Jenis Kelamin, Nilai Satatistika I dan II seperti dibawah ini.
No Urut Nama Mahasiswa Jenis Kelamin
Nilai Statistika I
Nilai Statistika II
1 Toni 1 65 45
2 Ratu 2 58 67
3 Erma 2 79 34
4 Sani 2 80 89
5 Marta 2 90 90
6 Diah 2 77 65
7 Yani 1 70 91
8 Sari 2 85 80
9 Emi 2 64 54
10 Boni 1 82 47
11 Edward 1 86 70
12 Jodi 2 63 45
13 Wida 2 71 60
14 Dodo 1 87 66
15 Tri 1 60 54
Petunjuk : Buatlah file data dengan pendefinisian variabel berikut :
Data Nama Variabel
Type Label Value label
Nomor urut nomor numerik nomor urut
Nama mahasiswa
nama string nama mahasiswa
Jenis kelamin seks numerik Jenis kelamin 1:”laki-laki” 2:”Perempuan”
Nilai Statistik I Stat1 numerik Nilai statistik I
Nilai Statistik II Stat2 numerik Nilai Statistik II
Untuk memberi label dan value label pada data Jenis Kelamin, dapat dilakukan langkah-langkah :
1. Pada sel di bawah Label isi dengan “Jenis Kelamin” 2. Klik pada sel di bawah Values dan klik pada kotak abu-abu selanjutnya akan
muncul Value Labels dialog. 3. Pada kotak Value isi dengan angka 1 . 4. Pada kotak Value Label isi dengan “Laki-laki” 5. Klik tombol Add 6. Lanjutkan proses dengan mengisi angka 2 pada kotak Value. 7. Padakotak Value Label isi dengan “Perempuan” 8. Klik tombol Add 9. Proses sudah selesai, klik OK
Setelah selesai, simpan data anda dengan nama PRAK_01.sav. DATA VIEW:

VARIABLE VIEW:
PRAKTIKUM 2 STATISTIKA DESKRIPTIF
Anda dapat menampilkan karakteristik nilai-nilai data anda yang paling sederhana yaitu menampilkan deskripsi data anda seperti mean, standart deviasi, varian, nilai tengah (median), modus,minimum, maximum, dll.
Contoh kasusnya : ingin diketahui deskripsi data dari variabel stat1 dan stat2 pada data di praktikum 1. Langkah pengolahan dengan SPSS :
a. Buka file data PRAK_01.sav b. Klik Analyze c. Sorot Descriptive Statistics d. Klik Frequencies.

e. Pindahkan variabel yang akan diolah dari kolom kiri ke kolom kanan dengan
cara mengeblok variabel yang akan diolah kemudian klik tanda panah.
f. Klik pada opsi statistics, berilah tanda chek (V) pada pilihan yang anda
perlukan. Untuk keseragaman beri tanda (V) dalam mean, median, mode, std deviasi, variance,minimum dan maximum.
g. Klik continue . h. Untuk membuat histogram klik opsi chart , tandai (o) pada histograms dan
beri tanda (V) pada With normal curve
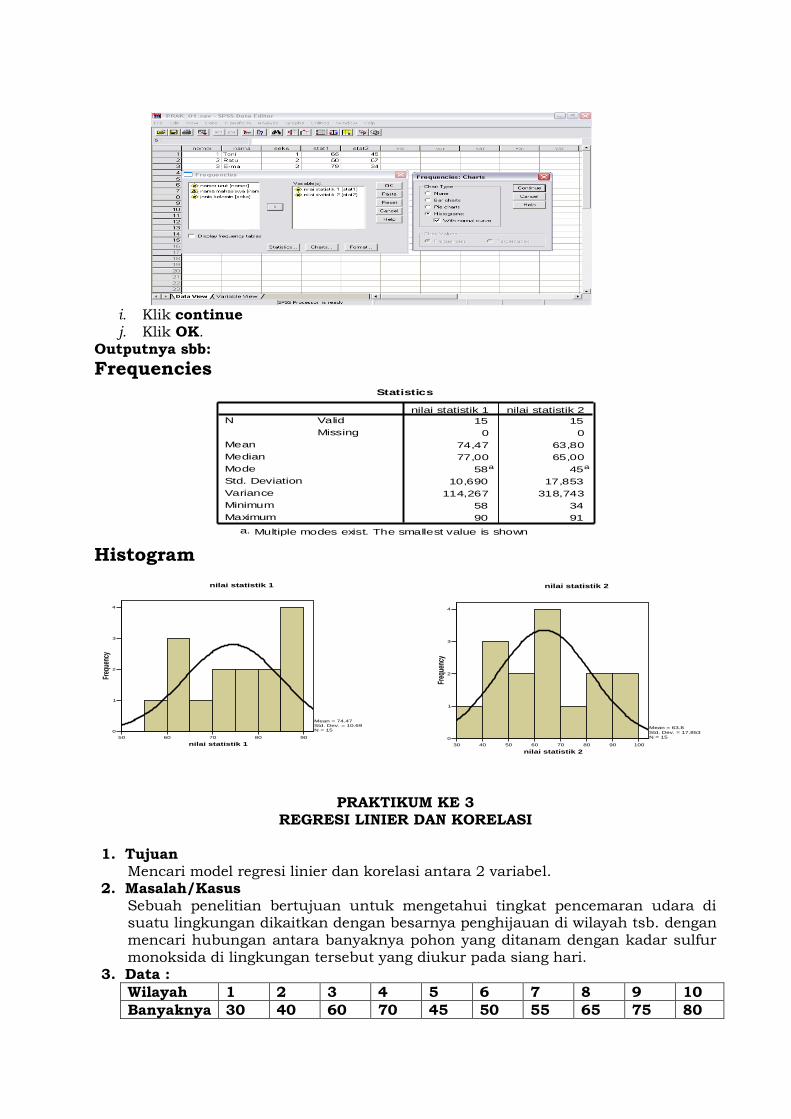
i. Klik continue j. Klik OK.
Outputnya sbb:
Frequencies Statistics
15 15
0 0
74,47 63,80
77,00 65,00
58a 45a
10,690 17,853
114,267 318,743
58 34
90 91
Valid
Missing
N
Mean
Median
Mode
Std. Deviation
Variance
Minimum
Maximum
nilai statistik 1 nilai statistik 2
Multiple modes exist. The smallest value is showna.
Histogram
50 60 70 80 90
nilai statistik 1
0
1
2
3
4
Freq
uenc
y
Mean = 74.47Std. Dev. = 10.69N = 15
nilai statistik 1
30 40 50 60 70 80 90 100
nilai statistik 2
0
1
2
3
4
Freq
uenc
y
Mean = 63.8Std. Dev. = 17.853N = 15
nilai statistik 2
PRAKTIKUM KE 3
REGRESI LINIER DAN KORELASI 1. Tujuan
Mencari model regresi linier dan korelasi antara 2 variabel. 2. Masalah/Kasus
Sebuah penelitian bertujuan untuk mengetahui tingkat pencemaran udara di suatu lingkungan dikaitkan dengan besarnya penghijauan di wilayah tsb. dengan mencari hubungan antara banyaknya pohon yang ditanam dengan kadar sulfur monoksida di lingkungan tersebut yang diukur pada siang hari.
3. Data :
Wilayah 1 2 3 4 5 6 7 8 9 10
Banyaknya 30 40 60 70 45 50 55 65 75 80
pohon
Kadar sulphur monoksida
0.96 0.74 0.63 0.55 0.76 0.70 0.69 0.57 0.53 0.50
a. Apakah ada korelasi antara besarnya kadar sulphur monoksida di udara dengan banyaknnya tanaman hijau disekitar?
b. Carilah model yang sesuai antara banyaknya tanaman dan besarnya kadar sulphur monoksida di udara sekitar.
c. Lakukan uji kecocokan model tsb
4. Pengolahan Dengan SPSS
a. Buat File data SPSS
b. Pilih menu Analyze Regression Curve Estimation
Sehingga muncul layar :

Pindahkan variable sulfur ke kotak Dependent(s) dan variable pohon ke kotak Variabel, beri tanda V di kotak Model Linier dan kotak Display ANOVA table.
Hasil (Output) Dari SPSS
Linear
Model Summary
R R Square
Adjusted R
Square
Std. Error of the
Estimate
.965 .931 .923 .038
The independent variable is variabel x.
ANOVA
Sum of Squares df Mean Square F Sig.
Regression .161 1 .161 108.625 .000
Residual .012 8 .001
Total .172 9
The independent variable is variabel x.
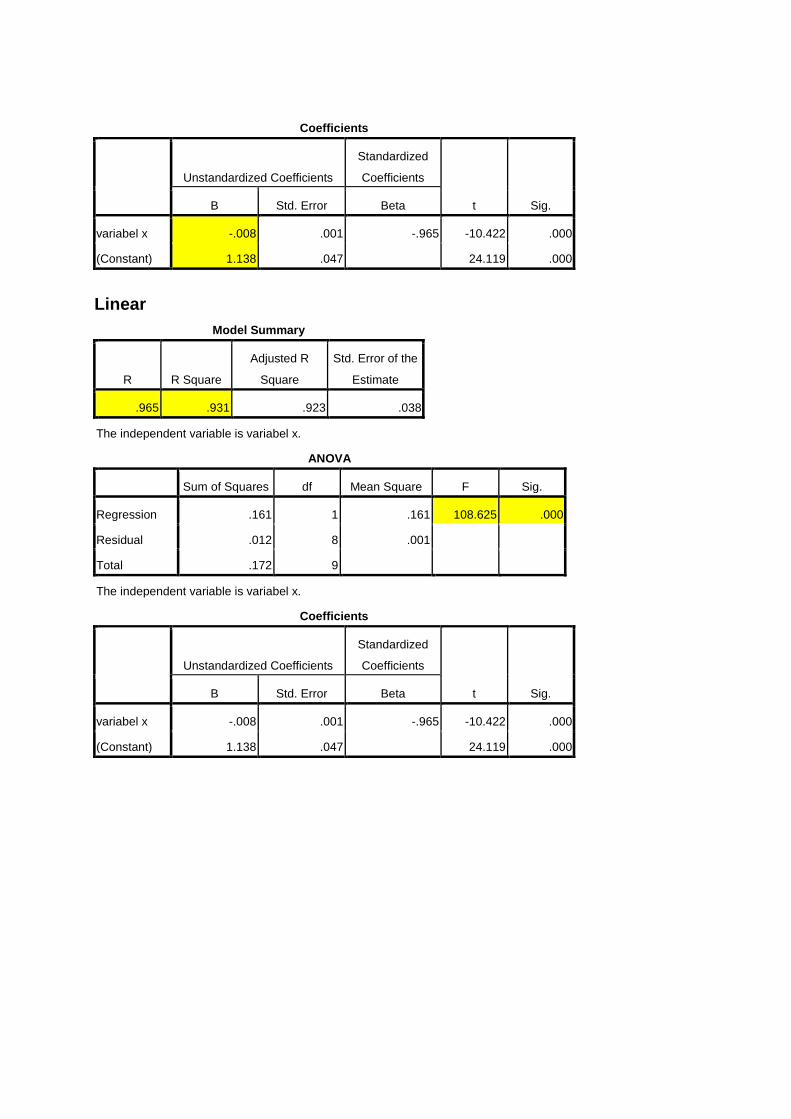
Coefficients
Unstandardized Coefficients
Standardized
Coefficients
t Sig. B Std. Error Beta
variabel x -.008 .001 -.965 -10.422 .000
(Constant) 1.138 .047 24.119 .000
Linear
Model Summary
R R Square
Adjusted R
Square
Std. Error of the
Estimate
.965 .931 .923 .038
The independent variable is variabel x.
ANOVA
Sum of Squares df Mean Square F Sig.
Regression .161 1 .161 108.625 .000
Residual .012 8 .001
Total .172 9
The independent variable is variabel x.
Coefficients
Unstandardized Coefficients
Standardized
Coefficients
t Sig. B Std. Error Beta
variabel x -.008 .001 -.965 -10.422 .000
(Constant) 1.138 .047 24.119 .000

Untuk Uji Korelasi : Pengolahan data : Pilih menu Analyze Correlate bivariate
Pindahkan kedua viariabel ke kotak variables Beri tanda V pada kotak Pearson beri bulatan (0) pada two tailed OK

Output :
Correlations
variabel x variabel y
variabel x Pearson Correlation 1 -.965**
Sig. (2-tailed) .000
N 10 10
variabel y Pearson Correlation -.965** 1
Sig. (2-tailed) .000
N 10 10
**. Correlation is significant at the 0.01 level (2-tailed).
PRAKTIKUM 4
UJI CHI KUADRAT
Tujuan Menguji apakah tingkat kebisingan antara desa dan kota berbeda secara signifikan.
Masalah/Kasus Kebisingan suatu wilayah bisa diakibatkan banyaknya kendaraan bermotor dan banyaknya pabrik.
Suatu penelitian untuk mengetahui tingkat kebisingan antara wilayah kota dan desa melalui
persepsi masyarakat. Dari data 200 responden masyarakat kota ternyata diperoleh 100 orang
merasa bising sedangkan dari 150 responden masyarakat desa 40 orang yang merasa bising.
Apakah ada perbedaan yang signifikan antara proporsi penduduk kota dan desa tentang kebisingan
terjadi. Gunakan taraf nyata 5 %.
MEMBUAT FILE DATA :

Buatlah nama-nama variabel sesuai dengan nama variabel yang ada di permasalahan
ditambah 1 variabel jumlah, kemudian isilah data sesuai yang ada di permasalahan
Misalnya bising dan daerah. Berilah nama label dan value label pada masing-masing
variabel tersebut. Misalnya value label untuk tingkat kebisingan, 1 : bising, 2 : tidak bising
dan value label untuk daerah, 1 : kota , 2 : desa
Setelah membuat file data lakukan pengolahan data.
LANGKAH-LANGKAH PENGOLAHAN DATA :
Dari menu utama SPSS, pilih menu Data, kemudian pilih Weight Cases, pilih Weight
cases by, isilah dengan variabel jumlah
Tekan OK,
Klik Analyze,
Pilih Descriptive Statistics,
Klik Crosstabs,
Isilah Row(s), Colum(s) dengan masing-masing variabel,
Klik Statistics, beri tanda (V) pada hal-hal yang ingin diketahui (Chi-square)
Klik Continue,
Klik Cells, beri tanda (V) pada hal-hal yang ingin diketahui (observed dan expected)

Klik Continue,
Klik OK
Lakukan analisa output yang diperoleh.
Output :
Crosstabs
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
Tingkat kebisingan * Daerah 350 100.0% 0 .0% 350 100.0%
Tingkat kebisingan * Daerah Crosstabulation
Daerah
Total Kota Desa
Tingkat kebisingan Bising Count 100 40 140
Expected Count 80.0 60.0 140.0
Tidak bising Count 100 110 210
Expected Count 120.0 90.0 210.0
Total Count 200 150 350
Expected Count 200.0 150.0 350.0
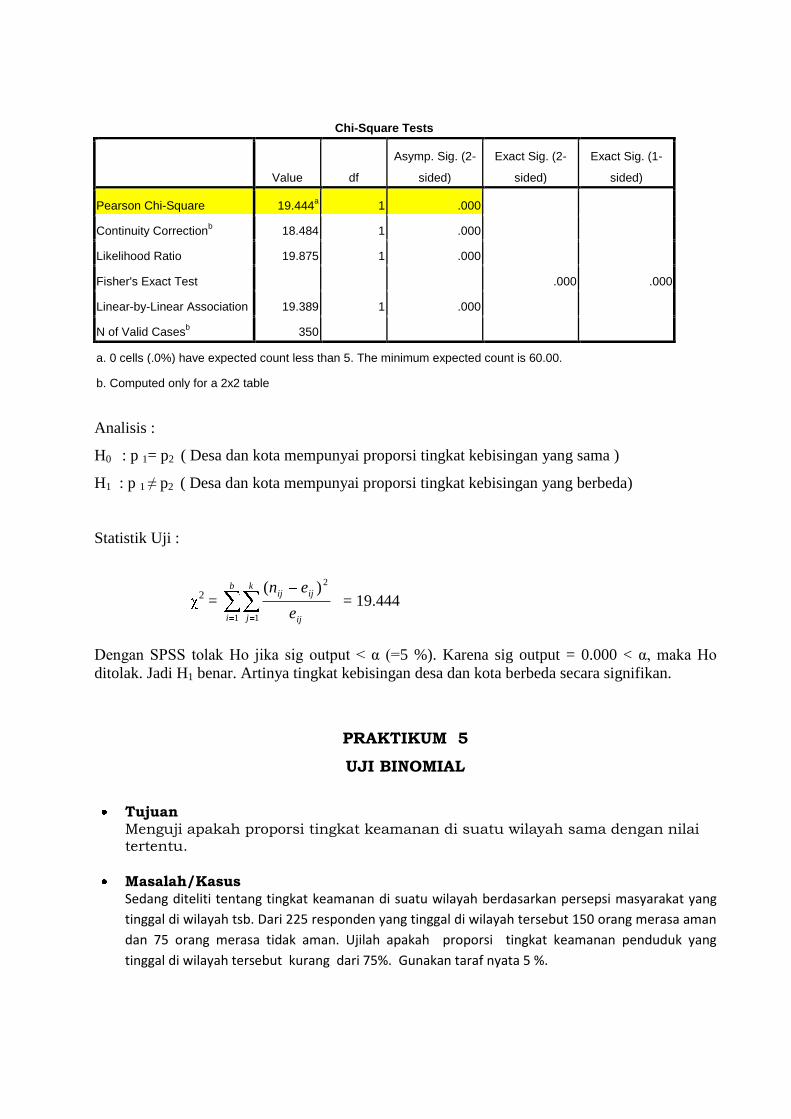
Chi-Square Tests
Value df
Asymp. Sig. (2-
sided)
Exact Sig. (2-
sided)
Exact Sig. (1-
sided)
Pearson Chi-Square 19.444a 1 .000
Continuity Correctionb 18.484 1 .000
Likelihood Ratio 19.875 1 .000
Fisher's Exact Test .000 .000
Linear-by-Linear Association 19.389 1 .000
N of Valid Casesb 350
a. 0 cells (.0%) have expected count less than 5. The minimum expected count is 60.00.
b. Computed only for a 2x2 table
Analisis :
H0 : p 1= p2 ( Desa dan kota mempunyai proporsi tingkat kebisingan yang sama )
H1 : p 1 ≠ p2 ( Desa dan kota mempunyai proporsi tingkat kebisingan yang berbeda)
Statistik Uji :
2 =
b
i
k
j ij
ijij
e
en
1 1
2)( = 19.444
Dengan SPSS tolak Ho jika sig output < α (=5 %). Karena sig output = 0.000 < α, maka Ho
ditolak. Jadi H1 benar. Artinya tingkat kebisingan desa dan kota berbeda secara signifikan.
PRAKTIKUM 5
UJI BINOMIAL
Tujuan Menguji apakah proporsi tingkat keamanan di suatu wilayah sama dengan nilai tertentu.
Masalah/Kasus Sedang diteliti tentang tingkat keamanan di suatu wilayah berdasarkan persepsi masyarakat yang
tinggal di wilayah tsb. Dari 225 responden yang tinggal di wilayah tersebut 150 orang merasa aman
dan 75 orang merasa tidak aman. Ujilah apakah proporsi tingkat keamanan penduduk yang
tinggal di wilayah tersebut kurang dari 75%. Gunakan taraf nyata 5 %.
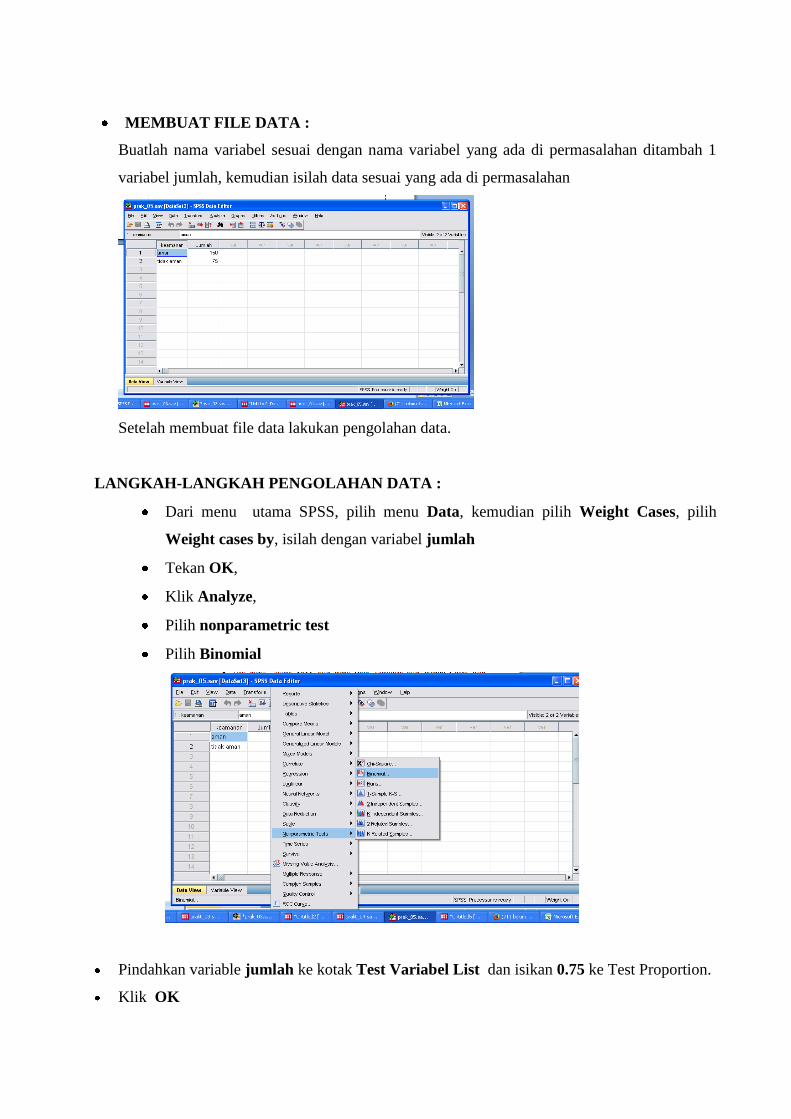
MEMBUAT FILE DATA :
Buatlah nama variabel sesuai dengan nama variabel yang ada di permasalahan ditambah 1
variabel jumlah, kemudian isilah data sesuai yang ada di permasalahan
Setelah membuat file data lakukan pengolahan data.
LANGKAH-LANGKAH PENGOLAHAN DATA :
Dari menu utama SPSS, pilih menu Data, kemudian pilih Weight Cases, pilih
Weight cases by, isilah dengan variabel jumlah
Tekan OK,
Klik Analyze,
Pilih nonparametric test
Pilih Binomial
Pindahkan variable jumlah ke kotak Test Variabel List dan isikan 0.75 ke Test Proportion.
Klik OK
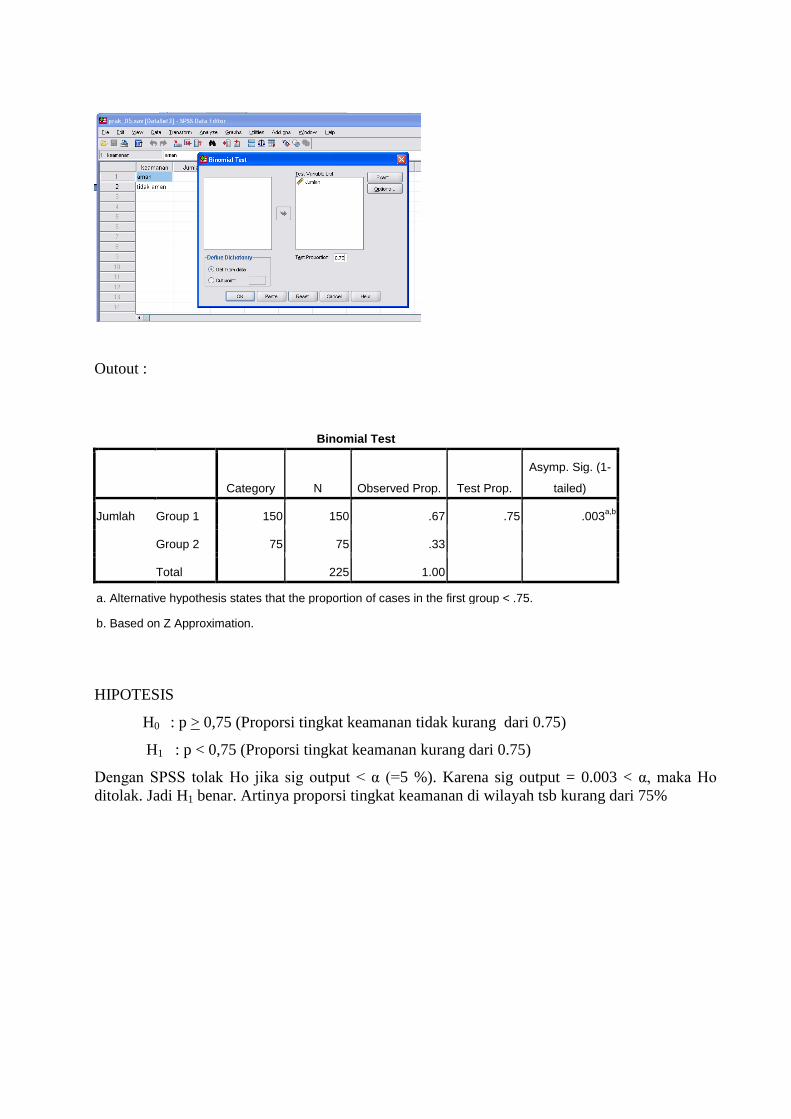
Outout :
Binomial Test
Category N Observed Prop. Test Prop.
Asymp. Sig. (1-
tailed)
Jumlah Group 1 150 150 .67 .75 .003a,b
Group 2 75 75 .33
Total 225 1.00
a. Alternative hypothesis states that the proportion of cases in the first group < .75.
b. Based on Z Approximation.
HIPOTESIS
H0 : p > 0,75 (Proporsi tingkat keamanan tidak kurang dari 0.75)
H1 : p < 0,75 (Proporsi tingkat keamanan kurang dari 0.75)
Dengan SPSS tolak Ho jika sig output < α (=5 %). Karena sig output = 0.003 < α, maka Ho
ditolak. Jadi H1 benar. Artinya proporsi tingkat keamanan di wilayah tsb kurang dari 75%