
PENGAMBILAN POLA KELULUSAN TEPAT WAKTU PADA...
19
i PENGAMBILAN POLA KELULUSAN TEPAT WAKTU PADA MAHASISWA STMIK AMIKOM YOGYAKARTA MENGGUNAKAN DATA MINING ALGORITMA C4.5 Naskah Publikasi diajukan oleh Muchamad Piko Henry Widiarto 04.22.0400 kepada SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER AMIKOM YOGYAKARTA 2011
Transcript of PENGAMBILAN POLA KELULUSAN TEPAT WAKTU PADA...

i
PENGAMBILAN POLA KELULUSAN TEPAT WAKTU PADA
MAHASISWA STMIK AMIKOM YOGYAKARTA
MENGGUNAKAN DATA MINING
ALGORITMA C4.5
Naskah Publikasi
diajukan oleh
Muchamad Piko Henry Widiarto
04.22.0400
kepada
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER
AMIKOM
YOGYAKARTA
2011

ii

iii
PATTERN MAKING ON-TIME GRADUATION ON THE
STUDENT STMIK AMIKOM YOGYAKARTA
USING C4.5 ALGORITM DATA MINING
PENGAMBILAN POLA KELULUSAN TEPAT WAKTU PADA
MAHASISWA STMIK AMIKOM YOGYAKARTA
MENGGUNAKAN DATA MINING
ALGORITMA C4.5
Muchamad Piko Henry Widiarto
Jurusan Sistem Informasi
STMIK AMIKOM YOGYAKARTA
ABSTACT
Progress of sophisticated computer applications have helped performance of big
companies which requires an application that need an application that can perform
calculation of big amounts of data. Data mining is a process of discovering meaningful
connections, patterns, and trends by examining the large collection of data stored in
storage by using pattern recognition techniques such as statistics and mathematics.
Therefore, data mining is indispensable in helping make decisions with the results of data
using one algorithm is applicable.
Purpose of the implementation of the "data mining" of C4.5 algorithm on STMIK
AMIKOM Yogyakarta is help a manager of data management systems of student
graduation improving the quality of education. Due to the frequent occurrence of buildup
of students which not graduate on time according to education level in each period of
graduation.
Therefore, implementation of data mining will help classify the student data which
will then be calculated using the C4.5 algoritm and the patterns are accurate decisions.
Keywords: Data mining, C4.5 Algoritm, Computer System

1
1. Latar Belakang Masalah
STMIK AMIKOM Yogyakarta merupakan salah satu perguruan tinggi yang
sukses menarik banyak mahasiswa disetiap periodenya. Namun ada beberapa hal yang
tidak seimbang antara masuk dan keluarnya mahasiswa yang telah menyelesaikan
studinya. Mahasiswa yang masuk dalam jumlah besar, tetapi mahasiswa yang lulus tepat
waktu sesuai dengan ketentuan jauh sangat kecil dibandingkan masuknya. Sehingga
terjadi penumpukan mahasiswa dalam jumlah tinggi disetiap periode kelulusan.
Oleh karena itu untuk meningkatkan kualitas pada perguruan tinggi STMIK
AMIKOM Yogyakarta, maka haruslah ada filter pada mahasiswa yang mendaftar untuk
masuk. Data mining merupakan salah satu metode yang tepat untuk membentuk pola-
pola yang mungkin memberikan indikasi yang bermanfaat pada data mahasiswa yang
dalam jumlah besar. Pada data mining ini dapat dirumuskan sebuah permasalahan yang
dijadikan sebagai acuan yaitu proses Algoritma C4.5 menentukan mahasiswa yang akan
lulus tepat waktu sesuai dengan ketentuan jenjang pendidikan yang diambil.
2. Landasan Teori
2.1. Data mining
Menurut Gartner Group, data mining adalah suatu proses menemukan hubungan
yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data
yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola
seperti teknik statistik dan matematika (Larose, 2005). Data mining bukanlah suatu
bidang yang sama sekali baru. Salah satu kesulitan untuk mendefinisikan data mining
adalah kenyataan bahwa data mining mewarisi banyak aspek dan teknik dari bidang-
bidang ilmu yang sudah mapan terlebih dulu. Berawal dari beberapa disiplin ilmu, data
mining bertujuan untuk memperbaiki teknik tradisional sehingga bisa menangani:
1. Jumlah data yang sangat besar
2. Dimensi data yang tinggi
3. Data yang heterogen dan berbeda bersifat
2.2. Teknik Data Mining
2.2.1 Klasifikasi
Teknik Klasifikasi dalam data mining dikelompokkan ke dalam Teknik Pohon
Keputusan, Bayesian (Naïve Bayesian dan Bayesian Belief Networks), Jaringan Saraf
Tiruan (Backpropagation), Teknik yang berbasis konsep dari penambangan aturan-
aturan asosiasi, dan teknik lain (k-Nearest Neighboor, algoritma genetik, teknik dengan
pendekatan himpunan rough dan fuzzy.)

2
Setiap teknik memiliki kelebihan dan kekurangannya sendiri. Data dengan profil
tertentu mungkin paling optimal jika diklasifikasi dengan teknik tertentu, atau dengan kata
lain, profil data tertentu dapat mendukung termanfaatkannya kelebihan dari teknik ini.
Gambar 2.2 Pengelompokan Teknik Klasifikasi
Secara umum, Proses Klasifikasi dapat dilakukan dalam dua tahap, yaitu proses
belajar dari data pelatihan dan klasifikasi kasus. Pada proses belajar, Algoritma
Klasifikasi mengolah data training untuk menghasilkan sebuah model. Setelah model diuji
dan dapat diterima, pada tahap klasifikasi, model tersebut digunakan untuk memprediksi
kelas dari kasus baru untuk membantu proses pengambilan keputusan (Han et al.,2001;
Quinlan, 1993).
2.3 Pohon Keputusan
Pohon Keputusan atau Decision Tree merupakan metode klasifikasi dan prediksi
yang sangat kuat dan terkenal. Metode Pohon Keputusan mengubah fakta yang sangat
besar menjadi Pohon Keputusan yang merepresentasikan aturan. Aturan dapat dengan
mudah dipahami dengan bahasa alami. Dan mereka juga dapat diekspresikan dalam
bentuk bahasa database seperti SQL untuk mencari record pada kategori tertentu.
Pohon Keputusan adalah sebuah struktur pohon dimana setiap node pohon
merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian
hasil uji, dan node daun merepresentasikan kelompok kelas tertentu. Level node teratas
dari sebuah Pohon Keputusan adalah node akar yang biasanya berupa atribut yang
paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision
Tree melakukan strategi pencarian secara top-down untuk solusinya.
2.4 Algoritma C4.5
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai
berikut.
1. Pilih atribut sebagai node akar.
2. Buat cabang untuk tiap-tiap nilai.
3. Bagi kasus dalam cabang.

3
4. Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki
kelas yang sama.
Untuk memilih atribut sebagai node akar, didasarkan pada nilai Gain tertinggi dari
atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam
persamaan berikut: Gain(S,A) = Entropy(S) – ∑| |
| |
* Entropy(Si)
Keterangan :
S : himpunan kasus
A : atribut
n : jumlah partisi atribut A
| | : jumlah kasus pada partisi ke-i
| | : jumlah kasus dalam S
Sebelum mendapatkan nilai Gain adalah mencari nilai Entropy. Entropy
digunakan untuk menentukan seberapa informatif sebuah masukan atribut untuk
menghasilkan keluaran atribut. Rumus dasar dari Entropy tersebut adalah sebagai
berikut : Entropy(S) = ∑
Keterangan :
S : himpunan Kasus
A : fitur
n : jumlah partisi S
pi : proporsi dari Si terhadap S
2.5 Java
Java telah mengakomodasi hampir seluruh fitur penting bahasa – bahasa
pemrograman yang ada semenjak perkembangan komputasi modern manusia. Sebagai
sebuah bahasa pemrograman, Java dapat membuat seluruh bentuk aplikasi, desktop,
web dan lainnya, sebagaimana dibuat dengan menggunakan bahasa pemrograman
konvensional yang lain. Java adalah bahasa pemrograman yang berorientasi obyek
(OOP) dan dapat dijalankan pada berbagai platform sistem operasi. Perkembangan Java
tidak hanya terfokus oada satu sistem operasi, tetapi dikembangkan untuk berbagai
sistem operasi dan bersifat open source. Sebagai sebuah peralatan pembangun,
teknologi Java menyediakan banyak tool: compiler, interpreter, penyusun dokumentasi,
paket kelas dan sebagainya.Aplikasi dengan teknologi Java secara umum adalah aplikasi
serba guna yang dapat dijalankan pada seluruh mesin yang memiliki JRE.
Berdasarkan white paper resmi dari SUN, Java memiliki karakteristik:Sederhana
(Simple), Terdistribusi (Distributed), Interpreted, Robust, Secure, Portable, Performance.,
Multithreaded, dan Dynamic.

4
2.6 MySql
MySQL merupakan software yang didistribusikan secara gratis walaupun ada
versi untuk komersial. Barulah sejak versi 3.23.19, MySQL dikategorikan software
berlisensi GPL, yaitu dapat dipakai tanpa biaya untuk kebutuhan apapun. Awalnya,
MySQL hanya dapat berjalan pada sistem operasi UNIX serta variannya. Namun kini,
MySQL dapat diberbagai sistem operasi, termasuk Windows. MySQL menjadi database
server open source yang sangat populer dan merupakan Database Relational (RDMS),
yang mempunyai kemampuan yang sangat cepat untuk menjalankan perintah SQL
dengan multi-thread dan mult-user. Dengan melihat kemampuannya, maka MySQL
dijadikan database server yang handal tambahan feature terus dikembangkan agar lebih
optimal.
3. Analisis dan Perancangan Sistem
3.1 Analisis Sistem
Analisis sistem yang dipaparkan dalam pembahasan ini merupakan gambaran
secara keseluruhan kendala-kendala yang ada dalam aplikasi data mining yang berbasis
algoritma C4.5 pada sistem STMIK AMIKOM Yogyakarta.Dengan adanya sistem yang
masih bersifat manual mengakibatkan proses sistem yang terjadi kurang efektif dan
efisien. Data dari sistem adalah berupa atribut yang dimiliki oleh mahasiswa, nilai atribut,
dan nilai kemungkinannya. Data yang dimaksud adalah data yang mempunyai minimal
dua kolom atribut. Satu kolom sebagai kolom atribut masukan dan satu kolom sebagai
kolom atribut target. Dari setiap kolom terdapat nilai-nilai yang akan dipergunakan untuk
kalkulasi, dan nilai dari setiap atribut harus bersifat diskret.
Ketentuan lain yang harus dipenuhi agar masukan dapat diproses dengan lancar
adalah peletakan kolom target harus berada pada posisi terakhir dari kolom pada tabel
masukan. Sistem akan membaca masukan dengan atribut target berada pada kolom
terakhir dari tabel, maka dari itu selain kolom terakhir sistem akan mengenalinya sebagai
atribut masukan dari sistem.Beberapa komponen variable yang digunakan yaitu :
1 NEM. Variabel nem berisi seluruh kemungkinan nem yang dimiliki oleh
mahasiswa untuk diisi pada proses input program. Nilai yang sudah ditentukan
pada program ini antara lain 0-3.99, 4-6.99, 7-10.
2 Jurusan SMA. Variabel Jurusan SMA berisi seluruh kemungkinan jurusan yang
diambil oleh mahasiswa sebelum masuk perguruan tinggi. Nilai yang sudah
ditentukan pada program berdasarkan hasil pengelompokan survei antara lain
ipa, ips, bahasa, smk.
3 Jurusan Kuliah. Variabel jurusan kuliah beriisi seluruh kemungkinan jurusan
yang akan diambil oleh mahasiswa pada perguruan tinggi STMIK AMIKOM
Yogyakarta. Pengelompokan jurusan kuliah dibagi menjadi 4 berdasarkan

5
ketentuan perguruan tinggi yaitu S1 Teknik Informatika, S1 Sistem Informasi, D3
Teknik Informatika, D3 Manajemen Informatika.
4 Konsentrasi. Variabel konsentrasi berisi data konsentrasi mata kuliah yang akan
dipilih mahasiswa pada saat pertengahan kuliah. Pengelompokan yang ada
berdasarkan ketentuan yang dibuat program adalah jaringan, pemrograman,
multimedia.
5 Ekonomi. Variabel ekonomi adalah variabel yang berisi tentang keadaan
ekonomi mahasiswa.Pilihan yang terdapat pada program ini antara lain
dibedakan menjadi tiga bagian yaitu atas, menengah, dan bawah.
6 Keputusan. Variabel keputusan merupakan data yang berfungsi untuk
menentukan hasil keputusan. Dalam pengelompokan data sudah ditentukan
secara tetap agar tidak terjadi kesalahan dalam perhitungan proses program.
Data keputusan hanya memiliki dua buah nilai yaitu “ya” dan “tidak”.
3.1.1 Analisis Model
Berikut ini adalah penjelasan lebih terperinci mengenai tiap-tiap langkah dalam
pembentukan pohon keputusan dengan menggunakan algoritma C4.5 untuk
menyelesaikan permasalahan dalam tugas akhir ini.Salah satu proses kalkulasi dari
entropy adalah proses kalkulasi nilai entropy TOTAL yaitu dengan jumlah sampel 36
data.
Table 3.1 Tabel Data Informasi
NEM Jur. SMA Jur. Kul. Konsent. Ekonom. Keputusan
0-3.99=7 ipa=17 S1TI=13 Jaringan=21 Atas=9 Ya=21
4-6.99=16 ips=7 S1SI=6 Pemrograman=8 Menengah=18 Tidak=15
7-10=13 bahasa=11 D3TI=3 Multimedia=7 Bawah=9
smk=1 D3MI=14
Table 1
Gain(S,A) = Entropy(S) – ∑| |
| |
* Entropy(Si)
Keterangan :
S : himpunan kasus
A : atribut
n : jumlah partisi atribut A
Si : jumlah kasus pada partisi ke-i
S : jumlah kasus dalam S
Entropy(S) = ∑ pi
Keterangan :
S : himpunan Kasus
A : fitur
n : jumlah partisi S
pi : proporsi dari Si terhadap S
6
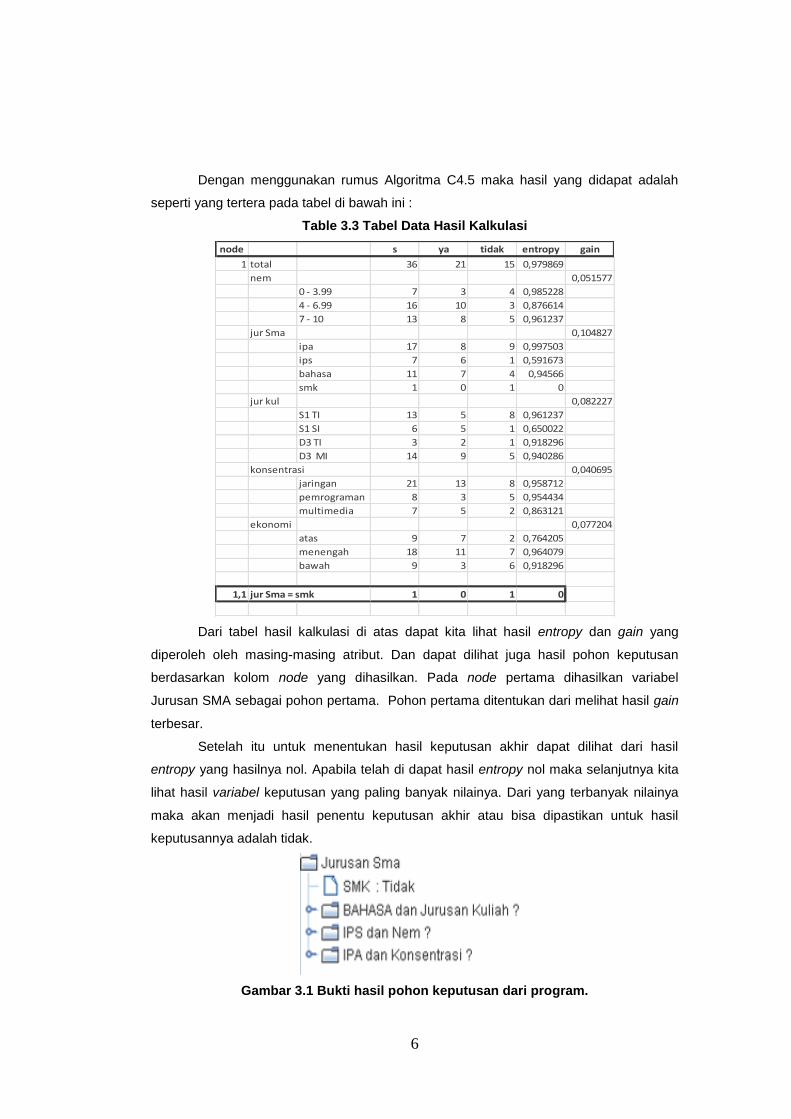
Dengan menggunakan rumus Algoritma C4.5 maka hasil yang didapat adalah
seperti yang tertera pada tabel di bawah ini :
Table 3.3 Tabel Data Hasil Kalkulasi
node s ya tidak entropy gain
1 total 36 21 15 0,979869
nem 0,051577
0 - 3.99 7 3 4 0,985228
4 - 6.99 16 10 3 0,876614
7 - 10 13 8 5 0,961237
jur Sma 0,104827
ipa 17 8 9 0,997503
ips 7 6 1 0,591673
bahasa 11 7 4 0,94566
smk 1 0 1 0
jur kul 0,082227
S1 TI 13 5 8 0,961237
S1 SI 6 5 1 0,650022
D3 TI 3 2 1 0,918296
D3 MI 14 9 5 0,940286
konsentrasi 0,040695
jaringan 21 13 8 0,958712
pemrograman 8 3 5 0,954434
multimedia 7 5 2 0,863121
ekonomi 0,077204
atas 9 7 2 0,764205
menengah 18 11 7 0,964079
bawah 9 3 6 0,918296
1,1 jur Sma = smk 1 0 1 0
Dari tabel hasil kalkulasi di atas dapat kita lihat hasil entropy dan gain yang
diperoleh oleh masing-masing atribut. Dan dapat dilihat juga hasil pohon keputusan
berdasarkan kolom node yang dihasilkan. Pada node pertama dihasilkan variabel
Jurusan SMA sebagai pohon pertama. Pohon pertama ditentukan dari melihat hasil gain
terbesar.
Setelah itu untuk menentukan hasil keputusan akhir dapat dilihat dari hasil
entropy yang hasilnya nol. Apabila telah di dapat hasil entropy nol maka selanjutnya kita
lihat hasil variabel keputusan yang paling banyak nilainya. Dari yang terbanyak nilainya
maka akan menjadi hasil penentu keputusan akhir atau bisa dipastikan untuk hasil
keputusannya adalah tidak.
Gambar 3.1 Bukti hasil pohon keputusan dari program.

7
Gambar pohon keputusan di atas menunjukkan hasil dari perhitungan diatas
dengan hasil dari program yang telah dibuat terbentuklah sebuah pola. Dimulai dari
pohon pertama yaitu jurusan sma, selanjutnya jurusan sma yang bernilai smk langsung
menuju pola dengan keputusan tidak,selanjutnya masing-masing variabel tersebut
mempunyai pola keputusannya masing-masing.
3.2 Perancangan Sistem
3.2.1 Perancangan Alur Sistem
Dalam aplikasi ini, rancangan alur program dituangkan kedalam alur program
(Flowchart) terlebih dahulu. Alur program dalam sistem data mining ini adalah sebagai
berikut :
Gambar 3.2 Flowchart Sistem
3.2.2 Perancangan Use Case Diagram
Use Case diagram adalah suatu bentuk diagram yang menggambarkan
fungsionalitas yang diharapkan dari sebuah sistem dilihat dari perspektif pengguna diluar
sistem.
Gambar 3.3 Use Case Diagram

8
Dari gambar diatas terlihat bahwa ada satu actor yaitu user.User di atas hanya
ada satu yaitu yang berfungsi sebagai admin. User tersebut dapat melakukan aktifitas
memasukkan data, mengubah data, melihat pohon keputusan, menghapus data menguji
atribut identitas, tambah data, hapus data, edit data, dan melihat pohon keputusan.
3.2.3 Perancangan Activity Diagram
Activity Diagram merupakan suatu diagram yang dapat menampilkan secara
detail urutan proses dari aplikasi. Perancangan aplikasi data mining ini dapat
digambarkan dengan menggunakan Activity Diagram sebagai berikut :
Gambar 3.4 Activity Diagram
Dari gambar Activity Diagram diatas dapat dilihat bahwa aplikasi data mining
STMIK AMIKOM Yogyakarta memiliki empat komponen yaitu Proses Pembentukan Pola,
Visualisasi Pohon Keputusan, Pola Keputusan, dan Identitas Mahasiswa.
Saat pertama kali membuka aplikasi, maka user akan langsung masuk ke
halaman utama. Di halaman utama ini, user dapat memilih operasi yang diinginkan.
Dengan memilih operasi proses data, user dapat melakukan penambahan data
keputusan dengan memasukkan nilai-nilai atribut dan nilai kemungkinannya. Dari data
yang telah diinputkan tersebut, kemudian user dapat melakukan pembentukan pohon
keputusan dengan menekan button proses.
Proses kedua dalam aplikasi ini yaitu pohon keputusan. Saat tampil halaman
pohon keputusan, maka user harus menekan button tampilkan untuk memicu
terbentuknya pohon keputusan.
Proses selanjutnya adalah pola keputusan. Pada halaman pola keputusan ini,
user diminta untuk menginputkan atribut-atribut yang dimiliki oleh seorang mahasiswa
untuk dicocokkan dengan pohon keputusan yang telah terbentuk.

9
4. Implementasi dan Pembahasan
4.1 Implementasi Sistem
Implementasi sistem bertujuan untuk memastikan bahwa sistem yang dibangun
dapat bekerja dengan baik dan sesuai yang diharapkan. Sebelum sistem
diimplementasikan dalam kehidupan sehari-hari maka sistem harus dipastikan telah
bebas dari kesalahan. Kesalahan-kesalahan yang mungkin terjadi yaitu penulisan
bahasa, kesalahan tampilan, dan kesalahan proses pada saat dioperasikan. Untuk dapat
mengetahui kesalahan-kesalahan pada sistem yang dibangun maka harus dilakukan
pengujian terhadap sistem tersebut.
4.2 Implementasi Interface
4.2.1 Halaman Utama
Form Halaman Utama adalah halaman yang pertama kali muncul setelah aplikasi
dijalankan.
Gambar 4.1 Halaman Utama
4.2.2 Halaman Proses Pembentukan Pola
Halaman form Proses Pembentukan Pola akan muncul setelah memilih menu
Proses Data. Halaman ini berfungsi untuk melakukan konversi data yang dipilih untuk
membentuk pohon keputusan.

10
Gambar 4.2 Halaman Proses Pembentukan Pola
Pada halaman ini terdapat dua bagian tombol yaitu bagian tombol atas yang
terdiri dari Baru, Ubah, Simpan, Batal, dan Hapus berfungsi untuk mengolah data rule
pada tabel dan yang kedua adalah bagian tombol bawah yang terdiri dari tombol Proses
yang berguna untuk melakukan proses perhitungan menggunakan algoritma C4.5.
Halaman ini membutuhkan beberapa class script program untuk melakukan proses
tesebut. Diantara class itu adalah class fungsi yang berfungsi melakukan perhitungan
dengan menggunakan algoritma C4.5.
4.2.3 Halaman Visualisasi Keputusan
Halaman ini berisi visualisasi pohon keputusan yang dihasilkan dari pengolahan
tabel pada proses pembentukan pola keputusan yang dibuat.
Gambar 4.3 Halaman Visualisasi Keputusan

11
4.2.4 Halaman Identitas Mahasiswa
Pada form ini berfungsi untuk melakukan penambahan dan perubahan data
identitas mahasiswa yang selanjutnya data ini akan berguna untuk diseleksi yang akan
lulus tepat waktu dengan pola keputusan sebagai standar penilainnya. Data Identitas
Mahasiswa ini akan tersimpan pada tabel Mahasiswa.
Gambar 4.4 Halaman Identitas Mahasiswa
4.2.5 Halaman Pola Keputusan
Form ini berfungsi untuk menentukan proses keputusan mahasiswa yang
diprediksi lulus tepat waktu dan yang tidak. Data Mahasiswa diambil dari tabel
Mahasiswa melalui form Tabel Identitas Mahasiswa dengan menekan tombol Cari.
Gambar 4.5 Halaman Pola Keputusan
4.2.6 Form Tabel Identitas Mahasiswa
Form ini muncul setelah menekan tombol Cari pada Halaman Pola Keputusan.
Pada form ini berfungsi untuk mengambil data identitas mahasiwa untuk diperiksa
dengan pola keputusan yang telah terbentuk.

12
Gambar 4.6 Form Tabel Identitas Mahasiswa
4.2.7 Form Konten Bantuan
Form ini berisi mengenai cara penggunaan aplikasi data mining ini.
Gambar 4.7 Halaman Konten Bantuan

13
4.2.8 Halaman Tentang
Halaman ini berisi informasi pembuat.
Gambar 4.8 Halaman Tentang
5. Penutup
5.1 Kesimpulan
Berdasarkan hasil penelitian dan pembahasan yang telah dilakukan dapat
diambil beberapa kesimpulan, antara lain:
1. Data mining dapat digunakan untuk membantu manajemen STMIK AMIKOM
Yogyakarta dalam menentukan keputusan kelulusan mahasiswa tepat pada
waktunya sesuai pola yang terbentuk.
2. Hasil penelitian ini sebagai gambaran bagi mahasiswa STMIK AMIKOM
Yogyakarta implementasi teknik data mining di lapangan.
3. Perancangan pohon keputusan memudahkan dalam proses penalaran
penentuan pola keputusan yang terbentuk.
4. Sistem ini telah memberi kemudahan bagi user untuk menentukan hasil
keputusan yang mudah dimengerti dalam bentuk visualisasi pohon keputusan.
5. Data yang bisa diambil hanya file yang berekstensi *.csv (Comma Delimited).
6. Dalam data mining ada data eksternal pendukung. Di dalam penelitian ini ada
beberapa variabel data atau beberapa field tabel ditambahkan ke dalamnya
seperti status ekonomi, konsentrasi secara spesifik.

14
5.2 Saran
Mengingat keterbatasan yang dimiliki oleh penulis, baik pengetahuan, waktu,
maupun pemikiran, maka penulis dapat memberikan beberapa gambaran sebagai saran
yang dapat dipakai sebagai acuan dalam pengembangan aplikasi ini di masa yang akan
datang, antara lain:
1. Dengan hasil kesimpulan point terakhir, memberikan saran kepada STMIK
AMIKOM Yogyakarta agar menambah variabel pada form pengisian calon
mahasiswa baru berupa range status ekonomi keluarga atau orangtua dan
konsentrasi yang ingin diambil.
2. Untuk membuat hasil pola data mining ini bisa optimal dan real di lapangan
seperti apa yang ada dalam penelitian ini, hendaknya STMIK AMIKOM
Yogyakarta membuat kategori Tugas Akhir atau Skripsi yang akan atau telah
dikerjakan untuk mendukung variabel konsentrasi yang akan diambil.
3. Menyempurnakan segala kekurangan program yang belum diketahui oleh
penulis. Seperti hal menambah variabel-variabel data dari segi sosial dan
psikologi mahasiswa yang analisanya dapat dilakukan pada jenjang magister
maupun doktoral.
4. Memberikan sistem yang baik dalam pembentukan pola keputusan basisdata
yang ada.

15
DAFTAR PUSTAKA
Anonim, 2009. Bab 10 Data mining, diakses dari pada tanggal 3 Maret 2010.
Basuki,A dan Syarif,I , 2003. Decision Tree, diakses dari http://www2.eepis-
its.edu/~basuki/lecture/DecisionTree.pdf, pada 3 Maret 2010.
Firmansyah, K, 2010. Sekilas Data mining, diakses dari
http://kikifirmansyah.blog.upi.edu/2010/02/27/sekilas-data-mining/#more-191,
pada tanggal 15 Maret 2010.
http://repository.usu.ac.id/bitstream/123456789/19859/3/Chapter%20II.pdf
Kusrini, Luthfi,E.T, 2009. Algoritma Data mining. Yogyakarta: Andi.
Larose,D.T, 2005. DiscoveringKnowledge in Data: An Introduction to Data mining. John
Willey & Sons, Inc.
Said,F.L, 2009. BAB I Konsep,Pengertian, Manfaat, dan Tujuan Data mining, diakses
dari http://fairuzelsaid.wordpress.com/2009/10/27/data-mining-1-konsep-
pengertian-manfaat-dan-tujuan-data-mining/, pada tanggal 12 Maret 2010.
Said,F.L, 2009. Data mining – Konsep Pohon Keputusan, diakses dari
http://fairuzelsaid.wordpress.com/2009/11/24/data-mining-konsep-pohon-
keputusan/, pada tanggal 12 Maret 2010.
Shaufiah, 2010. Pengenalan Data mining, diakses dari
http://imeldas.blog.ittelkom.ac.id/blog/files/2010/03/Dami1_Introduction.pdf,
pada 5 Maret 2010.
Turban,E, dkk. 2005. Decicion Support Systems and Intelligent Systems. Yogyakarta:
Andi Offset.

16




















