
(MMS-4411) BIOSTATISTIKA DAN...
63
BAHAN AJAR (MMS-4411) BIOSTATISTIKA DAN EPIDEMIOLOGI Disusun oleh: Dr. Danardono, MPH. JURUSAN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS GADJAH MADA 2006
Transcript of (MMS-4411) BIOSTATISTIKA DAN...

BAHAN AJAR
(MMS-4411)BIOSTATISTIKA DAN EPIDEMIOLOGI
Disusun oleh:Dr. Danardono, MPH.
JURUSAN MATEMATIKAFAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS GADJAH MADA2006

ii

Daftar Isi
1 Pendahuluan 11.1 Biostatistika dan Epidemiologi . . . . . . . . . . . . . . . . . . . 11.2 Profesi Biostatistisi dan Epidemiolog . . . . . . . . . . . . . . .. 2
2 Desain Penelitian 32.1 Penelitian dalam bidang ilmu hayati, kedokteran, dan epidemiologi 32.2 Penelitian observasional . . . . . . . . . . . . . . . . . . . . . . 52.3 PenelitianCross-sectional dan Longitudinal. . . . . . . . . . . . 52.4 PenelitianFollow-up . . . . . . . . . . . . . . . . . . . . . . . . 52.5 PenelitianCase-control. . . . . . . . . . . . . . . . . . . . . . . 52.6 Penelitian klinis . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.7 Model Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Statistik dan Ukuran dalam Epidemiologi 93.1 Prevalensi dan insidensi . . . . . . . . . . . . . . . . . . . . . . . 9
3.1.1 Faktor-faktor yang berpengaruh terhadap nilai prevalensi . 103.1.2 Model untuk Prevalensi . . . . . . . . . . . . . . . . . . 11
3.2 Model untuk Insidensi . . . . . . . . . . . . . . . . . . . . . . . 123.3 Ukuran untuk Pengaruh Faktor . . . . . . . . . . . . . . . . . . . 15
3.3.1 Tabel Kontingensi2 × 2 . . . . . . . . . . . . . . . . . . 173.4 Perancuan (Confounder) . . . . . . . . . . . . . . . . . . . . . . 19
4 Uji Diagnostik 234.1 Sensitivitas, Spesifisitas dan Nilai Prediksi . . . . . . . .. . . . . 234.2 Kurva ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5 Regresi Logistik 295.1 Model dan Estimasi Parameter . . . . . . . . . . . . . . . . . . . 305.2 Interpretasi Parameter Model . . . . . . . . . . . . . . . . . . . . 31
iii

iv Daftar Isi
6 Regresi Poisson 336.1 Model dan Estimasi Parameter . . . . . . . . . . . . . . . . . . . 336.2 Interpretasi Parameter Model . . . . . . . . . . . . . . . . . . . . 34
7 Analisis Data Longitudinal 397.1 Data longitudinal . . . . . . . . . . . . . . . . . . . . . . . . . . 397.2 Prinsip Pemodelan . . . . . . . . . . . . . . . . . . . . . . . . . 407.3 Model Linear Umum untuk data longitudinal . . . . . . . . . . . 437.4 Model Parametrik untuk Struktur Kovariansi . . . . . . . . . .. . 43
8 Analisis Data Survival 478.1 Fungsi Survival dan Hazard . . . . . . . . . . . . . . . . . . . . . 478.2 Kaplan-Meier danLife Table . . . . . . . . . . . . . . . . . . . . 488.3 Model Regresi data survival . . . . . . . . . . . . . . . . . . . . 52
9 Ringkasan Metode 57

1Pendahuluan
1.1 Biostatistika dan Epidemiologi
Biostatistika adalah statistika yang diterapkan pada ilmu hayati, kedokteran danepidemiologi. Armitage and Colton (1998) mendefinisikan Biostatistika lebihsempit lagi, yaitu metode statistika dalam kedokteran dan ilmu kesehatan, ataudikenal juga sebagaimedical statistics. Sedangkan ilmu statistika dalam bidangbiologi, lingkungan dan pertanian sering disebut biometrika (biometrics).
Definisi Epidemiologi menurut (Last, 1995) adalah
The study of distribution and determinants of health-related states orevents in specified population, and the application of this study tocontrol of health problems.
MMS-4411 mempunyai penekanan agar lulusan bisa bertindak sepertilayaknya konsultan dalam bidang Biostatistika. Untuk itu, materi yang diberikantidak hanya berupa metode saja namun juga aspek komunikasi,konsultasi danpengetahuan terkait seperti epidemiologi dan terminologidalam bidang kese-hatan. Matakuliah ini diharapkan akan membuka wawasan lanjut mahasiswakarena banyak pengembangan teori statistika yang berawal dari permasalahandalam bidang Biostatistika dan Epidemiologi. Selain itu melalui matakuliah inimahasiswa diharapkan untuk mulai berpikir dan bertindak bukan hanya sebagaistatistisi saja, tapi juga sebagai orang yang mempelajari bidang lain dan dengansudut pandang yang berbeda dari seorang statistisi.
Matakuliah ini dapat diambil setelah mahasiswa mengetahuidan memahamidasar serta teknik metode statistik secara umum dan mampu melakukan analisisstatistik dengan beberapa metode tertentu. Matakuliah MMS-4411 diharapkandapat mendukung kompetensi lulusan program studi statistika, khususnya untuklulusan yang mempunyai minat dan konsentrasi pada bidang Biostatistika.
1

2 1.2. Profesi Biostatistisi dan Epidemiolog
1.2 Profesi Biostatistisi dan Epidemiolog
Profesi biostatistisi dan epidemiolog banyak diperlukan di bidang-bidang sepertitersebut di bawah ini,
• Lembaga penelitian
• Akademik atau lembaga pendidikan
• Lembaga pemerintah bidang kesehatan atau rumah sakit
• Industri obat dan farmasi
• Konsultan
Di Indonesia profesi seperti tersebut belum sepopuler profesi seperti dokter,apoteker atau dosen, namun di negara maju dan di negara ASEANseperti Singa-pura profesi ini sudah cukup dikenal. Lembaga penelitian asing yang melakukanpenelitian di bidang penyakit tropis biasanya juga membutuhkan tenaga biostatis-tisi dan epidemiolog lokal. Perencanaan aspek kesehatan, termasuk di dalamnyaasuransi kesehatan dan kematian, yang baik dan terukur akansangat memerlukanahli di bidang biostatistik dan epidemiologi.

2Desain Penelitian
2.1 Penelitian dalam bidang ilmu hayati, kedokter-an, dan epidemiologi
Menurut Kleinbaum, Kupper and Morgenstern (1982), ada 4 kata kunci tujuanpenelitian di bidang epidemiologi, yaitu:describe, explain, predict dancontrol.Selengkapnya dapat dijelaskan sebagai berikut:
1. Mendeskripsikanstatus kesehatan populasi dengan cara melakukan enu-merasi kejadian sakit, menghitung frekuensi relatif dan mendapatkan ke-cenderungan atau trend penyakit;
2. Menjelaskanpenyebab penyakit dengan cara menentukan faktor yang men-jadi sebab dari suatu penyakit tertentu dan cara transmisinya;
3. Melakukan prediksikejadian sakit dan distribusi status kesehatan dalam po-pulasi;
4. Melakukan pengendalianpenyebaran penyakit dalam populasi denganpencegahan kejadian sakit, penyembuhan kasus sakit, menambah lamahidup bersama dengan suatu penyakit, atau meningkatkan status kesehatan-nya
Penelitian dalam bidang kedokteran dan epidemiologi secara garis besarsama dengan penelitian lain, seperti misalnya bidang pertanian, biologi dan ilmurekayasa (teknik). Namun karena penelitian ini banyak melibatkan manusia seba-gai subyek, maka banyak teknik atau metode yang dapat diterapkan pada bidanglain yang tidak dapat diterapkan dalam bidang ini karena permasalahan etika. Mi-salnya, kita tidak mungkin memberikan perlakuan yang jelasmembahayakan sub-yek penelitian.
3

4 2.1. Penelitian dalam bidang ilmu hayati, kedokteran, dan epidemiologi
populasi
A B
sampel data
Gambar 2.1: Skema penelitian secara umum dimulai dari pendefinisian popula-si dan unit populasi, tahap A: pengambilan unit sampel dari populasi; tahap B:pengambilan informasi dari sampel.
Gambar 2.1 merepresentasikan skema penelitian secara umum. Suatu peneli-tian dimulai dengan mendefinisikan populasi untuk mana kesimpulan atau hasildari penelitian akan dikenakan. Pada tahap ini unit populasi dan variabel peneli-tian harus ditentukan. Unit populasi adalah bagian terkecil dari populasi yangakan digunakan dalam pengambilan sampel. Sedangkan variabel adalah karakter-istik atau informasi yang ingin diperoleh dari unit tersebut.
Bagian A pada Gambar 2.1 adalah bagian pengambilan sampel atau penyam-pelan. Tujuan utama penyampelan adalah untuk mendapatkan wakil yang repre-sentatif dari populasi, tanpa harus melihat atau meneliti keseluruhan anggota po-pulasi. Pengambilan sampel dapat dilakukan secara non-random ataupun random.Pengambilan sampel non-random biasanya lebih mudah dibandingkan denganpengambilan sampel random. Namun, pengambilan random menjamin obyek-tivitas dan sampel yang representatif, dan banyak analisisstatistik yang disusunberdasarkan asumsi sampel random. Dikenal beberapa macam metode pengam-bilan sampel random yang pada hakekatnya bertujuan untuk mengatasi hetero-genitas populasi, seperti misalnya: sampel random sederhana, stratifikasi, kluster,sistematik, dan lainnya.
Setelah sampel diperoleh dilanjutkan dengan tahap pengambilan informasidari unit sampel berdasarkan variabel penelitian yang telah ditentukan (bagian Bpada Gambar 2.1). Cara pengambilan informasi dapat dilakukan dengan penguku-ran, pencacahan, wawancara, dan sebagainya. Jenis penelitian dapat dibedakandari apakah ada perlakuan, manipulasi, intervensi atau tindakan yang dinenakan

2.2. Penelitian observasional 5
pada unit penelitian sebelum dilakukan tahap B atau tidak. Selain itu, elemenutama yang selalu menyertai penelitian adalah waktu. Penelitian juga dapatdibedakan berdasarkan saat pelaksanaan tahap A maupun B. Lebih jelasnya jenis-jenis penelitian tersebut akan diterangkan pada bagian-bagian selanjutnya setelahbagian ini.
2.2 Penelitian observasional
Dalam penelitian jenis ini tidak dilakukan manipulasi atauperlakuan pada faktor-faktor yang diteliti. Data diperoleh apa adanya dari populasi. Dalam penelitianini, tidak dilakukan manipulasi, perlakuan ataupun intervensi pada tahap B.
2.3 PenelitianCross-sectional dan Longitudinal
Dalam penelitian ini, sampel atau data hanya dikumpulkan pada satu titik wak-tu tertentu saja. Jenis penelitian ini dikontraskan denganpenelitian longitudinal,yaitu penelitian yang dilakukan dalam periode tertentu. Dalam prakteknya peneli-tian longitudinal dicirikan dengan dikumpulkannya beberapa pengukuran atau ob-servasi untuk satu unit sampel, sedangkan penelitiancross-sectionaldicirikan de-ngan satu pengukuran atau observasi untuk satu unit.
2.4 PenelitianFollow-up
Sering juga disebut penelitian prospektif. Dalam penelitian ini subyek diikuti se-lama jangka waktu tertentu atau sampai suatu kejadian (event), nilai pengukuranatauend-pointtertentu diperoleh. PenelitianFollow-updapat berupa observasion-al maupun eksperimental.
2.5 PenelitianCase-control
Penelitian case-controlmerupakan salah satu contoh penelitian retrospektif.Penelitian retrospektif yaitu jenis penelitian yang berawal dari suatueventatauend-point. Unit sampel yang memilikieventatauend-pointtersebut kemudianditeliti. Penelitiancase-controldimulai dari unit yang mendapatkan kasus (pe-nyakit misalnya), kemudian dipilih sekelompok pembandingatau kontrol (yaituunit yang tidak mendapatkan atau mempunyai kasus). Faktor atau variabel penje-las yang lain juga dikumpulkan untuk masing-masing kasus dan kontrol.

6 2.6. Penelitian klinis
2.6 Penelitian klinis
Penelitian klinis (clinical trial ) menurut (Chow, 2000, hal 110) adalah
” ... an experiment performed by a health care organization or profes-sional to evaluate the effect of an intervention or treatment against acontrol in a clinical environment. It is a prospective studyto identifyoutcome measures that are influenced by the intervention. A clini-cal trial is designed to maintain health, prevent diseases,or treat dis-eased subjects. The safety, efficacy, pharmacological, pharmacokinet-ic, quality-of-life, health economics, or biochemical effects are mea-sured in a clinical trial.”
Tahapan penelitian klinis (Le, 2003):
• Fase I: Memfokuskan pada keamanan obat baru, fase ini adalahuji cobapertama obat pada manusia setelah sukses dengan uji coba pada binatang
• Fase II: Uji coba skala kecil untuk menilai efektivitas obatdan lebih fokuskepada keamanannya
• Fase III: Uji coba klinis lebih lanjut untuk menilai efektivitasnya sebelumdidaftarkan pada pihak yang berwenang
• Fase IV: Penelitian setelah obat dipasarkan untuk memberikan informasiyang lebih detail tentang efektivitas obat dan keamanannya
2.7 Model Statistik
Dalam terminologi dan notasi statistika, variabel sering dituliskan dengan hurufX untuk variabel penjelas, variabel independen, faktor; danY untuk variabel de-penden atau variabel respon. Dalam Epidemiologi dikenal juga istilah variabelpaparan (exposure) dan perancu (confounder) yang termasuk dalam kelompokX,danoutcomeyang termasuk dalam kelompokY .
Umumnya setiap penelitian bertujuan untuk mencari tahu apakahX menye-babkanY , atau seberapa besar pengaruhX terhadapY . Model statistik, sepertimisalnya model regresi sederhana
E(Y | X) = β0 + β1X (2.1)
merupakan representasi untuk mencapai tujuan itu.

2.7. Model Statistik 7
Statistisi memikirkan model seperti (2.1) sebagai suatu ”pembangkit data”(data generating-process). Realisasi dari model itu adalah data yang diperoleh(sering dituliskan sebagai huruf kecilx dany). Apabila model dan estimasi pa-rameternya dinyatakan cukup tepat untuk menjelaskan data,dapat dilakukan infe-rensi atau pengambilan kesimpulan dari model tersebut. Termasuk dalam inferen-si itu adalah penggunaan model untuk prediksi dan kausalitas.
Perlu diperhatikan bahwa sangat mungkin terdapat lebih dari satu model yangcukup tepat untuk menjelaskan suatu set data. Untuk itu harus diingat pendap-at yang mengatakan bahwa ada banyak model yang baik tapi pilihlah satu yangberguna. Dikaitkan dengan penelitian di bidang Epidemiologi dan kedokteran,model yang berguna di sini adalah model yang terdiri dari variabel yang ni-lainya dapat atau mudah dimodifikasi dalam praktek dan modelyang sesederhanamungkin.
Desain penelitian, atau cara memperoleh data penelitian, sangat mempen-garuhi asumsi model statistik yang pada akhirnya mempengaruhi penjelasan daninterpretasi dari hubunganX denganY . Ambil contoh model sederhana seperti(2.1). Misalkan untuk mendapatkanx (realisasi dari variabelX) digunakan caraobservasi tanpa perlakuan pada unit sampel (penelitian observasional) maka mo-del ini kurang kuat untuk menjelaskan kausalitasX terhadapY . Namun bilaxdiperoleh dengan kaidah desain eksperimental maka model dapat digunakan un-tuk menjelaskan hubungan kausal1.
1Meskipun demikian, sekarang ini berkembang penelitian untuk mengembangkan metodestatistik untuk data penelitian observasional yang dapat digunakan untuk analisis kausalitas

8 2.7. Model Statistik

3Statistik dan Ukuran dalam
Epidemiologi
3.1 Prevalensi dan insidensi
Definisi sehat menurut WHO adalah:health is a state of complete physical, men-tal, and social well-being and not merely the absence of disease or infirmity. De-finisi ini cukup sulit direalisasikan terutama pada definisidan ukuranwell-being.Definisi yang lebih praktis yang banyak digunakan oleh epidemiolog adalah ”ada”atau ”tidak ada” penyakit1.
Ukuran paling dasar yang sering digunakan untuk melihat besarnya perma-salahan adalah banyaknya kejadian atau frekuensi kejadian(sakit, meninggal,dsb.). Namun ukuran ini sangat bergantung pada besar populasi dan lama peri-ode pengamatan. Ukuran yang tidak bergantung pada besar populasi dan lamaperiode pengamatan yang banyak digunakan adalah prevalensi (prevalence) daninsidensi (incidence)
Prevalensi adalah banyaknya subyek yang mengalami kejadian tertentu ataumenderita penyakit tertentu pada suatu waktu tertentuPrevalensi dirumuskan sebagai:
P =d
N(3.1)
d: banyaknya subyek yang mengalami kejadian tertentu atau menderitapenyakit tertentu pada suatu waktu tertentu
N : banyaknya subyek pada suatu waktu tersebut
1Meskipun demikian penelitian dalam bidang Biostatistika dan Epidemiologi saat ini mengarahpada pengukuran hal-hal yang lebihsoftdaripada hanya sakit dan tidak sakit sepertiwell-beingdanquality of life, dan seterusnya.
9

10 3.1. Prevalensi dan insidensi
Insidensi adalah banyaknya subyek yang mengalam kejadian baru atau menda-patkan penyakit baru dalam suatu interval waktu tertentu. Jenis ukuran in-sidensi yang sering dipakai adalah Insidensi Kumulatif (IK) dan tingkat in-sidensi (incidence rate).IK dirumuskan sebagai:
IK =d
N0
(3.2)
d: banyaknya subyek yang mengalami kejadian tertentu atau menderitapenyakit tertentu dalam suatu interval waktu tertentu
N0: banyaknya subyek yang belum mengalami kejadian tertentu ataumenderita penyakit tertentu pada awal interval waktu tersebut
Jenis insidensi yang lain berdasarkan pada pengertian tingkat (rate), yaitubanyaknya perubahan kuantitatif yang terjadi terkait dengan waktu.Insidensi (Incidence rate) dirumuskan sebagai:
I =d
NT(3.3)
d: banyaknya subyek yang mengalami kejadian tertentu atau menderitapenyakit tertentu dalam suatu interval waktu tertentu
NT : Total waktu subyek yang belum mengalami kejadian tertentuataumenderita penyakit tertentu dalam interval waktu tersebut(sering jugadisebut sebagaiperson-timeataurisk-time)
Istilah lain yang sering digunakan untuk insidensi adalahperson-time in-cidence rate, instantaneous incidence rate, force of morbidity, incidence-density, hazard)
3.1.1 Faktor-faktor yang berpengaruh terhadap nilaiprevalensi
Prevalensi sangat dipengaruhi oleh banyak faktor yang tidak berhubungan lang-sung dengan penyebab penyakit, misalnya in-migrasi dan out-migrasi dan per-baikan cara diagnosis (lihat Gambar 3.1). Oleh karena itu prevalensi tidak dian-jurkan untuk menunjukkan kausalitas. Tapi prevalensi sangat membantu untukmenunjukkan besarnya masalah kesehatan.
Prevalensi dan insidensi saling berkaitan, secara umum hubungannya dapatditunjukkan sebagai berikut:
Bila prevalensi kecil dan tidak berubah menurut waktu
prevalensi≈ insidensi× durasi (3.4)

3.1. Prevalensi dan insidensi 11
naik karena turun karena
durasi penyakit yg panjangpasien hidup lamainsidensi meningkatin-migrasi kasusout-migrasi penduduk sehatin-migrasi orang yg rentanmeningkatnya diagnosis
durasi penyakit yg pendekpasien hidup singkatinsidensi menurunin-migrasi penduduk sehatout-migrasi kasusout-migrasi orang yg rentanmeningkatnya kesembuhan
Gambar 3.1: Faktor-faktor yang mempengaruhi prevalensi terobservasi
S
G
π
1 − π
Gambar 3.2: Model Bernoulli
3.1.2 Model untuk Prevalensi
Dasar analisis untuk prevalensi adalah Model Bernoulli (Lihat Gambar 3.2) yangmempunyai asumsi sebagai berikut :
• tiap usaha (trial ) menghasilkan satu dari dua hasil yang mungkin, dina-makan sukses (S) dan gagal (G);
• peluang sukses,P (S) = π dan peluang gagalP (G) = 1 − π
• usaha-usaha tersebut independen
Fungsi probabilitas Bernoulli adalah
P (X = x; π) = πx(1 − π)1−x,
denganπ adalah probabilitas sukses danx = 0, 1 (gagal, sukses). Dalam konteksEpidemiologi, sukses misalnya terkena penyakit tertentu atau meninggal.

12 3.2. Model untuk Insidensi
Untuk melakukan inferensi berdasarkan model ini dapat digunakan fungsilikelihoodberdasarkan data yang diperoleh.Contoh 1:Dari n = 10 orang diketahui outcome sukses (S) dan gagal (G) SSGSGGGSGG(misalnya sukses adalah terkena penyakit tertentu dan gagal adalah tidak terkenapenyakit tertentu). Seberapa mungkin data ini berasal darimodel binomial dengan(i) π = 0,1; (ii) π = 0,5?Jawab:
(i) π = 0,1:
L(π | data) = ππ(1 − π)π(1 − π)(1 − π)(1 − π)π(1 − π)(1 − π)
= 0,14 × 0,96
= 5,31× 10−5
(ii) π = 0,5
L(π | data) = ππ(1 − π)π(1 − π)(1 − π)(1 − π)π(1 − π)(1 − π)
= 0,54 × 0,56
= 9,77× 10−4
Terlihat bahwa likelihood untukπ = 0,5 lebih besar daripadaπ = 0,1 sehinggadapat disimpulkan bahwa data lebih mungkin berasal dari model Bernoulli denganπ = 0,5 daripadaπ = 0,1 (Lihat Gambar 3.3).
Nilai maksimum likelihood untuk data ini diperoleh padaπ = 0,4 (Gambar3.4). Nilai inilah yang sebenarnya paling didukung oleh data. Cara seperti inidikenal dalam Statistika sebagai cara untuk mencari estimator dengan MetodeMaximum Likelihood.
3.2 Model untuk Insidensi
Model untuk insidensi kumulatif pada prinsipnya sama seperti prevalensi, yaituberdasarkan pada model Bernoulli. Di sini akan dibahas modeluntuk insidensi,khususnyaincidence rate(3.3).
Pada bagian sebelumnya, prevalensi dapat dipandang sebagai eksperimenBernoulli, dengan sukses adalah kejadian yang menjadi perhatian, seperti sakitdan lainnya. Model ini dapat dikembangkan untuk insidensi.Dalam insiden-si, khususnyaincidence rate(3.3), seorang individu diamati dalam suatu periodewaktu tertentu. yang dapat dibagi dalam beberapa interval.Misalnya, seseorang

3.2. Model untuk Insidensi 13
0.0 0.2 0.4 0.6 0.8 1.0
0.00
000.
0004
0.00
080.
0012
π
Like
lihoo
d
L(0.1)
L(0.5)
Gambar 3.3: Fungsilikelihooduntuk data biner SSGSGGGSGG denganπ = 0,1danπ = 0,5
0.0 0.2 0.4 0.6 0.8 1.0
0.00
000.
0004
0.00
080.
0012
π
Like
lihoo
d
0.00119
Gambar 3.4:Maksimum Likelihooduntuk data biner SSGSGGGSGG adalah padaπ = 0,4

14 3.2. Model untuk Insidensi
1 3 5
π1
M
H
1− π1
π2
M
H
1− π2
π3
M
H
1− π3
Gambar 3.5: Insidensi sebagai satu urutan beberapa model probabilitas biner, de-ngan sukses M (mati) dan gagal H (hidup)
yang diamati selama 3 tahun dapat dibagi menjadi 3 satu tahuninterval waktupengamatan.
Pada Gambar 3.5 seseorang diamati sampai M (meninggal) yangjuga meru-pakan titik akhir (end-point) pengamatan, selama 3 tahun. Apabila dalam 3 tahuntersebut probabilitas meninggal sama, misalnyaπ, maka model yang dapat digu-nakan adalah Bernoulli seperti yang telah dibahas di muka. Namun apabila dalamsetiap interval waktu probabilitas meninggal berbeda, misalnyaπ1, π2, π3 sepertiterlihat pada Gambar, maka probabilitas M untuk tiap akhir interval akan berbedadan merupakan probabilitas bersyarat.
Sebagai contoh pada Gambar 3.6 diketahui nilaiπ1, π2, π3. Probabilitasmeninggal pada akhir tahun pertama adalah 0,3. Probabilitas meninggal padaakhir tahun kedua merupakan probabilitas bersyarat, karena untuk meninggal pa-da akhir tahun kedua individu ini harus hidup pada akhir tahun pertama, sehing-ga probabilitasnya adalah 0,7× 0,2 = 0,14. Demikian pula untuk probabilitasmeninggal pada akhir tahun ketiga, 0,7× 0,8× 0,1= 0,056.
Selanjutnya, untuk interval yang semakin sempit, probabilitas kondisional(untuk M) menjadi semakin kecil pula, dan konvergen kehazard rate(force ofmortality)
λ = limh→0
P (t ≤ T < t + h | T ≥ t)
h(3.5)
Likelihood untukλ dapat diturunkan dari likelihood binomial dengan meng-anggap bahwa probabilitas sukses adalahλh denganh kecil,
L(λ) = λD exp(−λY ) (3.6)

3.3. Ukuran untuk Pengaruh Faktor 15
1 3 5
0,3M
H
0,7
0,2M
H
0,8
0,1M
H
0,9
Gambar 3.6: Contoh satu urutan beberapa model probabilitas biner dan penghi-tungan probabilitas bersyarat)
denganD adalah banyaknya kejadian,Y adalah total waktu observasi.Log-likelihood untukλ
ℓ(λ) = D log(λ) − λY (3.7)
Persamaan (3.6) dan (3.7) adalah fungsi likelihood dan log-likelihood untukdistribusi Poisson. Dapat dengan mudah ditunjukkan bahwa penduga untukλadalahλ = D/Y .
Contoh 2:Misalkan ada 7 observasi dengan total waktu observasi 500 orang-tahun (person-years). Log-likelihood untukλ
ℓ(λ) = 7 log(λ) − 500λ
Nilai maksimum untuk fungsi Log-likelihood ini diperoleh padaλ = 0,014 (Gam-bar 3.7)
3.3 Ukuran untuk Pengaruh Faktor
Bagian di muka membahas statistik dan ukuran tanpa memandangadanya fak-tor atau variabel yang mempengaruhi statistik atau ukuran tersebut. Dengan katalain dalam notasi statistika di muka, sementara hanya dilihat variabelY saja tan-pa melihat adanyaX (variabel independen, penjelas, paparan). Dalam bagianini akan dibahas statistik dan ukuran yang melibatkan pengaruh faktor. Ukuran

16 3.3. Ukuran untuk Pengaruh Faktor
0.005 0.010 0.015 0.020 0.025 0.030
−39
.5−
38.5
−37
.5
λ
log
likel
ihoo
d
Gambar 3.7: Log-likelihood untukλ dan nilai maksimumnya
ini, seperti yang akan dijelaskan lebih lanjut, sangat bergantung pada pada desainpenelitian yag digunakan.
Beberapa ukuran yang dapat digunakan untuk melihat faktor resiko di-antaranya:
• Selisih resiko (risk difference)
• Rasio resiko (risk ratio)
• Odds ratio
Misalkanπ1 adalah probabilitas atau resiko untuk subyek yang terpapardanπ2
untuk subyek yang tidak terpapar. Sebagai contoh,π1 adalah probabilitas subyekterkena kanker paru jika diketahui subyek merokok, danπ1 adalah probabilitassubyek terkena kanker paru jika diketahui subyek tidak merokok. Selisih resiko,rasio resiko danodds ratioakan dijelaskan berdasarkanπ1 danπ2 di atas.
Selisih resiko Didefinisikan sebagaiRD = π1 − π2 yaitu selisih antara duaprobabilitasπ1 danπ2. Karenaπ1 = RD+π2, selisih resiko mengukur perubahanpada skala aditif. JikaRD > 0, paparan berkaitan dengan kenaikan probabilitasterkena penyakit. Sebaliknya jikaRD < 0, paparan berkaitan dengan penurunanprobabilitas terkena penyakit; dan jikaRD = 0, paparan tidak berkaitan denganpenyakit tersebut.
Rasio resiko didefinisikan sebagai rasio antara dua probabilitas,RR = π1/π2.Karenaπ1 = RRπ2, rasio resiko mengukur perubahan pada skala multiplikatif.JikaRR > 1, paparan berkaitan dengan kenaikan probabilitas terkena penyakit.

3.3. Ukuran untuk Pengaruh Faktor 17
Tabel 3.1: Notasi untuk frekuensi terobservasi (observed frequencies) dalam tabelkontingensi2 × 2
YX 1 2
1 n11 n12 n1•
2 n21 n22 n2•
n•1 n•2 n
JikaRR < 1, paparan berkaitan dengan penurunan probabilitas terkenapenyakit;dan jikaRR = 1, paparan tidak berkaitan dengan penyakit tersebut.
Oddsmerupakan representasi alternatif untuk probabilitas. Untuk probabilitasπ 6= 1, oddsω didefinisikan sebagai
ω =π
1 − π.
Meskipun probabilitas danoddsmerepresentasikan informasi yang sama, ni-lai rentangω tidak sama denganπ, yaitu 0 ≤ π ≤ 1 sedangkanω > 0. Biladidefinisikanω1 = π1/(1 − π1) danω2 = π2/(1 − π2), Odds ratioadalah rasioantara dua oddsω1 danω2
OR =ω1
ω2
=π1(1 − π2)
π2(1 − π1). (3.8)
Odds ratiomirip dengan rasio resikoRR dalam hal perubahannya yang diukursecara multiplikatif. Interpretasi nilaiOR juga ekivalen denganRR.
3.3.1 Tabel Kontingensi2 × 2
Dalam tabel kontingensi2 × 2, terdapat dua variabel, misalnyaX danY yangmasing-masing memiliki dua kategori. Tabel kontingensi2 × 2 merupakan klasi-fikasi silang atau frekuensi yang diperoleh dari kategori-kategori variabelX danY . Data yang diperoleh adalah seperti pada Tabel 3.1. Pada tabel tersebut,ni• = ni1 + ni2, i = 1, 2; n•j = n1j + n2j, j = 1, 2 dan n =
∑i
∑j nij.
Untuk desain penelitiancohort, prospekstif ataufollow-up, diasumsikanbahwa probabilitas marginalX adalah tetap, dengan menganggap bahwaXadalah variabel penjelas atau variabel paparan (exposure) danY adalah respon(Tabel 3.2), denganπj|i adalah probabilitas bersyarat. Untuk menyederhanakanpenulisanπ1|1 ditulis sebagaiπ1 saja, sedangkanπ1|2 ditulis sebagaiπ2.
Estimasi titik untukRD berdasarkan data seperti Tabel 3.1 adalah
RD = π1 − π2 (3.9)

18 3.3. Ukuran untuk Pengaruh Faktor
Tabel 3.2: Model probabilitas untuk desain penelitiancohort, prospektif ataufollow-up
YX 1 2
1 π1|1 π2|1 12 π1|2 π2|2 1
denganπ1 = n11/n1• danπ2 = n21/n2•. Estimator ini mempunyai galat standar(standard error)
σ(π1 − π2) =
[π1(1 − π1)
n1
+π2(1 − π2)
n2
]1/2
. (3.10)
Interval konfidensi(1 − α)100% untukπ1 − π2
(π1 − π2) ± Zα/2σ(π1 − π2), (3.11)
σ(π1 − π2) sama sepertiσ(π1 − π2) denganπi digantiπi.Estimasi titik untuk RR
RR =π1
π2
(3.12)
galat standar (standard error) untuk log RR
σ(log RR
)=
(1 − π1
π1n1
+1 − π2
π2n2
)1/2
(3.13)
Interval konfidensi(1 − α)100% untuk log RR
log RR± Zα/2σ(log RR
)(3.14)
Estimasi titik untuk OR
OR =n11n22
n12n21
(3.15)
alternatifnya, untuk menghindari masalah bila adanij = 0
OR =(n11 + 0,5)(n22 + 0,5)(n12 + 0,5)(n21 + 0,5)
(3.16)
galat standar (standard error) untuk log OR
σ(log OR
)=
(1
n11
+1
n12
+1
n21
+1
n22
)1/2
(3.17)

3.4. Perancuan (Confounder) 19
Tabel 3.3: DataBedsores studyMeninggal hidup Total
Bedsore 79 745 824tidak Bedsore 286 8.290 8.576Total 365 9.035 9.400
F
E
D
F
E
D
F
E
D
Gambar 3.8: Variabel F adalah perancu antara D (variabel respon) dengan E (vari-abel paparan). Tanda→ pengaruh satu arah;↔ pengaruh dua arah
Interval konfidensi(1 − α)100% untuk log OR
log OR± Zα/2σ(log OR
)(3.18)
Tabel2 × 2 dapat dikembangkan dan diperluas untuk tabel yang lebih umumb × k, maupun variabel yang lebih dari dua.
3.4 Perancuan (Confounder)
Variable perancu adalah variabel yang memenuhi dua kondisi:
• merupakan faktor resiko
• mempunyai hubungan dengan variabel paparan tapi bukan merupakan kon-sekuensi dari variabel paparan
Secara konseptual perancuan dapat digambarkan seperti pada Gambar 3.8 dan3.9. Pada gambar pertama variabel F mempengaruhi baik variabel D maupun E,sedangkan pada gambar kedua F tidak mempengaruhi D dan E sekaligus.
Contoh 3:Manula yang mengalami kecelakaan, seperti terjatuh, seringkali menjadi tidak

20 3.4. Perancuan (Confounder)
F
E
D
F
E
D
F
E
D
F
E
D
Gambar 3.9: Variabel F bukan perancu antara D dengan E (variabel respon) de-ngan E (variabel paparan). Tanda→ pengaruh satu arah;↔ pengaruh dua arah
dapat bangun dan bergerak dalam waktu lama. Hal ini dapat mengakibatkanbed-sores, yaitu luka pada kulit yang dapat berlanjut ke otot dan tulang dan dapatberakibat fatal. Diperoleh data seperti pada Tabel 3.3. Rasio resiko dari data iniadalah
RR =79/824
286/8576= 2,9
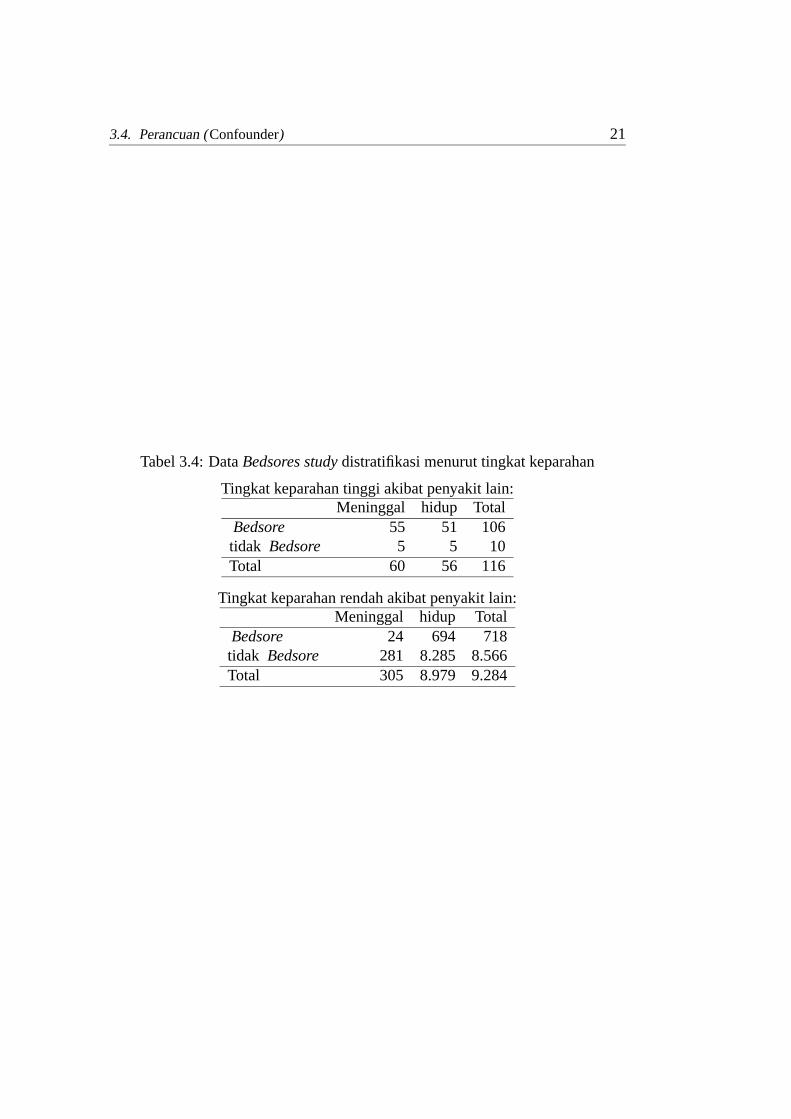
Nilai RR tersebut cukup tinggi menunjukkan bahwabedsoremungkin dapatmengakibatkan kematian. Untuk melihat apakah ada variabelperancu pada da-ta ini diperoleh data seperti pada Tabel 3.4. Data distratifikasi menurut tingkatkeparahan penyakit lain.
Dari stratifikasi ini diperoleh RR untuk masing-masing tingkat adalah
RR =55/106
5/10= 1,04
untuk tingkat keparahan tinggi dan
RR =24/718
281/8566= 1,02
untuk tingkat keparahan rendah. Dari hasil stratifikasi initerlihat bahwabedsoretidak terlalu berpengaruh terhadap kematian karena nilai RRcukup dekat dengansatu. Artinya bahwa tingkat keparahan merupakan variabel perancu dalam hu-bungan antarabedsoredengan kematian.
3.4. Perancuan (Confounder) 21
Tabel 3.4: DataBedsores studydistratifikasi menurut tingkat keparahan
Tingkat keparahan tinggi akibat penyakit lain:Meninggal hidup Total
Bedsore 55 51 106tidak Bedsore 5 5 10Total 60 56 116
Tingkat keparahan rendah akibat penyakit lain:Meninggal hidup Total
Bedsore 24 694 718tidak Bedsore 281 8.285 8.566Total 305 8.979 9.284

22 3.4. Perancuan (Confounder)

4Uji Diagnostik
4.1 Sensitivitas, Spesifisitas dan Nilai Prediksi
Untuk menentukan sakit atau tidaknya seseorang diperlukandiagnosa yang tepat.Dapat dikatakan diagnosis adalah langkah awal yang pentingdalam pengobatan.Kesalahan diagnosa dapat berakibat kesalahan pengobatan dan tidak mustahil be-rakibat fatal. Diagnosa juga merupakan tahap yang penting dalam program pre-ventif penyakit. Dalam hal ini diagnosa sering disebut sebagaiscreening.
Dalam diagnosa ataupunscreeningdigunakan suatu prosedur atau tes untukmelihat apakah seseorang menderita penyakit tertentu atautidak. Kegiatan diag-nostik dapat dipandang sebagai peristiwa-peristiwa probabilitas sebagai berikut:T+ : diagnosa atauscreeningmenunjukkan tes positifT− : diagnosa atauscreeningmenunjukkan tes negatifD+ : kenyataannya positif ada penyakitD− : kenyataannya tidak ada penyakit (negatif)
Baik atau tidaknya suatu prosedur atau tes diagnostik dapat dilihat berdasarkanprobabilitas-probabilitas bersyarat di bawah ini:
Sensitivitas (sensitivity): Sens= P (T+ | D+)
Specifisitas (sensitivity): Spec= P (T− | D−)
Nilai Prediksi + (Predictive Value+): PV+ = P (D+ | T+)
Nilai Prediksi - (Predictive Value-): PV− = P (D− | T−)
Suatu alat yang ideal seharusnya mempunyai nilai sensitivitas dan spesifisi-tas yang cukup tinggi (mendekati 1). Namun pada prakteknya nilai sensitivitasdan spesifisitas tidak dapat diestimasi, karena memerlukanpengetahuan apakahkenyataannya seseorang menderita penyakit atau tidak. Sedangkan jika sudahdiketahui ada tidaknya suatu penyakit tentu saja tidak lagidiperlukan adanya tes
23

24 4.1. Sensitivitas, Spesifisitas dan Nilai Prediksi
Tabel 4.1: Hasilcytological testT− T+ Total
D− 23.362 362 23.724D+ 225 154 379
diagnostik! Nilai sensitivitas dan spesifisitas hanya dapat diestimasi dengan caradibandingkan dengan tes lain yang dianggap paling tepat (gold standar test).
Dalam praktek yang ingin diketahui melalui suatu prosedur diagnostik adalah,apakah suatu tes yang diketahui positif akan dapat memprediksi adanya suatu pe-nyakit, yaitu PV+ prosedur diagnostik tersebut; dan juga PV- dari prosedur diag-nostik tersebut.
Nilai prediksi+ dapat diturunkan menggunakan Teorema Bayes:
PV+ = P (D+ | T+)
=P (D+ ∩ T+)
P (T+)
=P (D+)P (T+ | D+)
P (D+)P (T+ | D+) + P (D−)P (T+ | D−)
=Prevalence× Sensitivity
prev.× sens.+ (1 − prev.) × (1 − spec.).
Demikian pula untuk Nilai prediksi−,
PV− = P (D− | T−)
=P (D− ∩ T−)
P (T−)
=P (D−)P (T− | D−)
P (D−)P (T− | D−) + P (D+)P (T− | D+)
=(1 − Prevalence) × Specificity
(1 − prev.) × spec.+ prev.× (1 − sens.)
Contoh 1:Suatu tes sitologi (cytological test) dilakukan untukscreeningkanker rahim padawanita. Diperoleh data 24.103 wanita yang terdiri atas 379 wanita yang diketahuisudah menderita kanker rahim (dengan tes yang dianggap sebagai gold standar).Diperoleh data seperti pada Tabel 4.1. Hitungsensitivitydanspecificitytes terse-but!Jawab:

4.2. Kurva ROC 25
Tabel 4.2: NilaiPV+ danPV- untuk berbagai nilai prevalensiprevalensi PV+ PV-
0,0010 0,0264 0,9990,0157 0,3015 0,9900,0500 0,5876 0,9690,1000 0,7505 0,9370,5000 0,9644 0,624
sens =154
379= 0,406
= 40,6%
spec =23.362
23.724= 0,985
= 98,5%
Hasil estimasisensdanspectersebut dapat diinterpretasikan sebagai berikut:
• Jika tes digunakan untuk wanita yang tidak menderita kankerrahim, teshampir pasti akan negatif (specificity= 98,5% cukup besar)
• Jika tes digunakan untuk wanita yang menderita kanker rahim, peluangtidak terdeteksi besar (sensitivity= 40,6 % rendah;false negatif59,4%)
Untuk menghitungPV+ danPV− diperlukan prevalensi. Table 4.2 menya-jikan PV+ dan PV− untuk berbagai nilai prevalensi denganspec=98,5% dansens=40,6%. Terlihat bahwaPV+ danPV− nilainya terpengaruh oleh prevalensi,semakin besar prevalensiPV+ akan semakin besar sedangkanPV− akan semakinkecil.
4.2 Kurva ROC
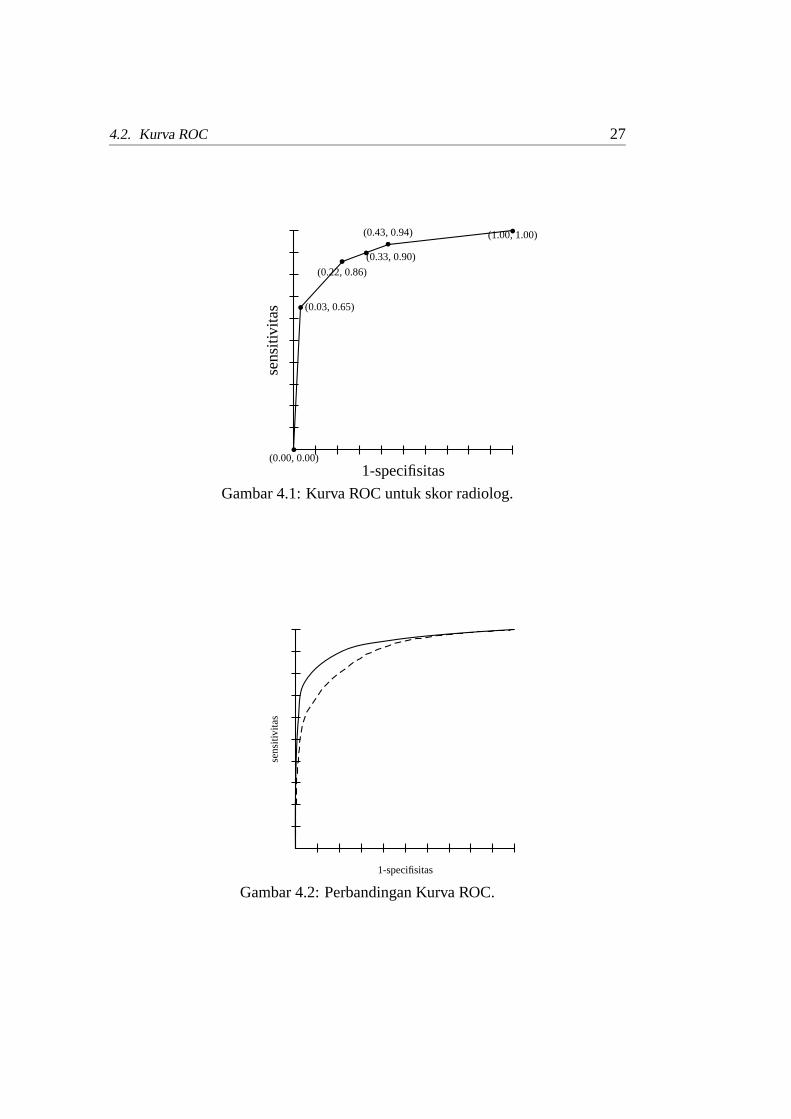
Kurva ROC (receiver operating characteristic) digunakan bila respon diagnosis(emphscreening test) lebih dari dua jenis respon atau respon bilangan kontinu.
Kurva ini menghubungkan nilaisensitivitasdengan 1-specifisitas. Area dibawah kurva ROC dapat digunakan untuk menilai keakuratan suatu diagnosis.Contoh 2:Diketahui probabilitas skor CTimage (computed tomographic image) untuk

26 4.2. Kurva ROC
Tabel 4.3: Skor dari radiolog untuk hasilCT imagepasien syarafStatus Skor dari radiolog∗
Penyakit (D) (1) (2) (3) (4) (5)Normal (D−) 0,303 0,055 0,055 0,101 0,018 0,532Abnormal (D+) 0,028 0,018 0,018 0,101 0,303 0,468
∗(1) hampir pasti normal; (2) mungkin normal; (3) tidak dapatditentukan (4) mungkin abnormal; (5) hampir pasti abnormal
Tabel 4.4:SensitivitasdanSpecifisitasberdasarkan beberapa kriteria tes positifKriteria tes positif sensitivitas spesifitas1-spesifitas
1≤ skor 1,00 0,00 1,002≤ skor 0,94 0,57 0,433≤ skor 0,90 0,67 0,334≤ skor 0,86 0,78 0,225≤ skor 0,65 0,97 0,035 < skor 0,00 1,00 0,00
pasien syaraf oleh seorang radiolog adalah seperti pada Tabel 4.3. Dari tabel terse-but dapat ditentukan beberapa kriteria tes positif berdasarkan nilai skor radiolog.Nilai sensitivitas, spesifisitas dan 1− spesifisitas dapat dihitung berdasarkan krite-ria tersebut seperti pada Tabel 4.4. Plot antara sensitivitas dengan 1− spesifisitasadalah kurva ROC untuk skor radiolog ini (Gambar 4.1).
Kurva ROC dapat digunakan untuk membandingkan beberapa prosedur diag-nostik. Prosedur yang paling baik adalah yang mempunyai luas area di bawahkurva ROC yang paling besar. Sebagai contoh pada Gambar 4.2,prosedur diag-nostik yang lebih baik adalah yang berupa kurva ROC garis penuh.
4.2. Kurva ROC 27
b
b
b
b
b
b
(1.00, 1.00)(0.43, 0.94)
(0.33, 0.90)
(0.22, 0.86)
(0.00, 0.00)
(0.03, 0.65)
1-specifisitas
sens
itivi
tas
Gambar 4.1: Kurva ROC untuk skor radiolog.
1-specifisitas
sens
itivi
tas
Gambar 4.2: Perbandingan Kurva ROC.

28 4.2. Kurva ROC

5Regresi Logistik
Pada bagian 3.3.1 dipelajari analisis untuk tabel2 × 2. Dalam tabel2 × 2 inibaik responY maupun variabel penjelas atau faktorX hanya terdiri atas dua je-nis kategori. Penelitian dalam bidang kesehatan maupun Epidemiologi biasanyamempunyai lebih dari satu variabel penjelas atau faktorX. Untuk data penelitiansemacam ini dapat digunakan regresi logistik.
Contoh 1:Diperoleh data tentang hubungan antara penyakit jantung koroner dengan tekananpekerjaan seperti pada Tabel 5.1.
Rasio resiko untuk tekanan pekerjaan adalah
RR =97/404
200/1609
= 1,932
dengan interval konfidensi 95% (1,5554 – 2.3987)Esimasi rasio resiko ini juga dapat dihitung dengan model regresi logistik
sederhana (satu variabel) yang dibahas pada bagian selanjutnya.
Tabel 5.1: Data studi tentang hubungan penyakit jantung koroner dengan tekananpekerjaan
Tertekan krn. Penyakit jantung koronerPekerjaan Ya Tidak TotalYa 97 307 404Tidak 200 1409 1609
29

30 5.1. Model dan Estimasi Parameter
5.1 Model dan Estimasi Parameter
MisalkanYi adalah variabel random Bernoulli untuk individui, distribusi proba-bilitasYI adalah
P (Yi = yi) = πyi
i (1 − πi)1−yi , yi = 0, 1 (5.1)
Setiap individui mempunyai karakteristik berupa kovariatxi yang mempengaruhiπi dalam bentuk
πi =1
1 + exp(−(β0 + β1xi))(5.2)
Fungsi sepertiπi dalam persamaan (5.2) dinamakan fungsi logistik. Untuk ko-variat atau variabel penjelas yang lebih dari satu, fungsi untuk πi dapat diperluasmenjadi
πi =1
1 + e−Z, atau πi =
eZ
1 + eZ(5.3)
denganZ = β0 + β1x1 + β1x1 + · · · + βp adalah fungsi linear darip variabelpenjelas.
Model (5.3) dapat dituliskan sebagai kombinasi linear darivariabel penjelasseperti halnya pada model linear sebagai berikut
logπi
1 − πi
= β0 + β1x1i + β2x2i + · · · + βpxpi (5.4)
atau
logit(π) = β0 + β1x1i + β2x2i + · · · + βpxpi (5.5)
denganx1i, x2i, . . . , xpi adalah variabel penjelas, faktor atau kovariat; danβ0 +β1x1 + β1x1 + · · · + βp adalah parameter model.
Estimasi untukβ = (β0, β1, . . . , βp) dapat diperoleh dengan MLE untukfungsi likelihood berikut ini
L(β) =n∏
i=1
P (Yi = yi)
=[exp(β0 + β1x1i + β2x2i + · · · + βpi)]
yi
1 + exp(β0 + β1x1i + β2x2i + · · · + βpi)(5.6)
Program statistika seperti R, SPSS, Epi-Info, STATA menyediakan fasilitas untukestimasiβ dan kesalahan standarnyaSE(β).

5.2. Interpretasi Parameter Model 31
5.2 Interpretasi Parameter Model
Untuk model regresi logistik sederhana (5.2)
logit(πi) = β0 + β1xi
dengan
xi =
{0 i tdk terpapar
1 i terpapar
dapat dituliskan
πi
1 − πi
= exp [β0 + β1xi]
atau
oddsxi= exp [β0 + β1xi]
Sehingga
OR =odds1odds0
=eβ0+β1
eβ0
= eβ1
Atau dapat disimpulkan bahwa eksponen dari parameter modelregresi logistikadalah OR. Interpretasi ini dapat diperluaas untuk model regresi logistik gandadan untuk variabel penjelas kontinu bukan kategori seperticontoh di atas. Untukvariabel kontinu, kenaikan m-unit untuk satu variabel penjelasX, misalnyaX =x + m dibandingkan denganX = x mempunyai OR sama denganemβ1 .
Estimasi titik dan interval konfidensi(1 − α)100% untuk OR:
OR = exp(β)
exp(β ± Zα/2SE(β))
Contoh 2: :Dengan menggunakan paket statistik R dapat diestimasi RD, RR maupun RD
dari data Contoh 1 di muka. Digunakan fungsi glm (Generalized Linear Model)dengan fungsi penghubung (link function) logit dan distribusi Binomial1
1Regresi logistik sebenarnya merupakan bagian dari model yang lebih umum lagi yang dina-makan GLM (Generalized Linear Model)

32 5.2. Interpretasi Parameter Model
> m<-glm(D˜E,family=binomial(link=logit), data=dt)> round(ci.logistik(m),digits=3)
coef.p s.err L U ecoef.p eL eU(Intercept) -1.952 0.076 -2.100 -1.804 0.142 0.122 0.165 E0.800 0.139 0.528 1.072 2.226 1.696 2.922
Fungsici.logistik bukan fungsi standar bawaan R, fungsi ini adalah fungsibuatan untuk menghitungeβ dan interval konfidensi dari hasil estimasi parametermodel regresi logistik.
Diperoleh interval konfidensi untuk OR 2,226 (1,696 – 2,922), yang samadengan hasil yang diperoleh dengan analisis tabel2 × 2 di muka.
Untuk menghitung RR dan RD digunakan estimasi probabilitasπ(x) dari mo-del regresi yang diperoleh. Probabilitas mendapatkan penyakit jantung untuk in-dividu yang terpaparP (yi = 1 | xi = 1) adalah
> predict(m,newdata=data.frame(E=1),type="response")[1] 0.240099
yang merupakan estimasi untukP (yi = 1 | xi = 1), dan
predict(m,newdata=data.frame(E=0),type="response")[1] 0.1243008
yang merupakan estimasi untukP (yi = 1 | xi = 0).Regresi Logistik dapat digunakan untuk menghitung RR, RD, OR dalam de-
sain penelitiancohortataufollow-up. Namun hanya dapat valid digunakan untukmenghitung OR desaincase-control.

6Regresi Poisson
6.1 Model dan Estimasi Parameter
Distribusi Poisson biasanya digunakan untuk memodelkan cacah kejadian dalamsuatu unit interval waktu, atau daerah tertentu. Distribusi probabilitas Poissonadalah
P (X = x) =θxe−θ
x!, x = 0, 1, 2, . . . (6.1)
yang mempunyai mean dan variansi sama yaituθUntuk menyelidiki infeksi pada suatu populasi organisme tertentu, sering tidak
mungkin untuk meneliti tiap-tiap individu. Organisme tersebut dibagi dalamkelompok-kelompok dan kelompok tersebut dianggap sebagaiunit.N = banyaknya organismen = banyaknya kelompokm = banyaknya organisme tiap kelompok,N = nm (dengan menganggapm samauntuk tiap kelompok)MisalnyaX adalah banyaknya organisme yang tidak terinfeksi, variabel randomX kemungkinan besar dapat dimodelkan dengan Poisson,
Data yang dapat dianalisis dengan regresi Poisson berupayi banyaknya obser-vasi cacah pada uniti; si ukuran tiap uniti; dan karakteristik tiap unit (kovariat)xi, i = 1, 2, . . . , n.
Model regresi Poisson dapat dituliskan sebagai berikut:
E(Yi | Xi) = µi = siλ(xi) (6.2)
= si exp(β0 + β1xi), atau
log µi = log si + β0 + β1xi (6.3)
denganλ(xi) dinamakan resiko uniti.
33

34 6.2. Interpretasi Parameter Model
Ukuran unitsi dapat berupa: banyaknya anggota populasi, interval waktu,luasan,exposure timedan sebagainya.
Dengan asumsiYi berdistribusi Poisson, diperoleh fungsi likelihood:
L(β) =n∏
i=1
P (Yi = yi) (6.4)
=n∏
i=1
[siλ(xi)]yi exp[−siλ(xi)]
yi!(6.5)
Dapat digunakan beberapa program statistika seperti R, STATA, SAS untuk esti-masiβ dan kesalahan standarnya SE(β).
6.2 Interpretasi Parameter Model
:Untuk model regresi Poisson sederhana
log µi = log si + β0 + β1xi
dengan
xi =
{0 i tdk terpapar
1 i terpapar
Dapat dihitung RR untuk unit yang terpapar sebagai berikut
RR =E(Yi | Xi = 1)
E(Yi | Xi = 0)(6.6)
=si exp(β0 + β1)
si exp(β0)(6.7)
= eβ1 (6.8)
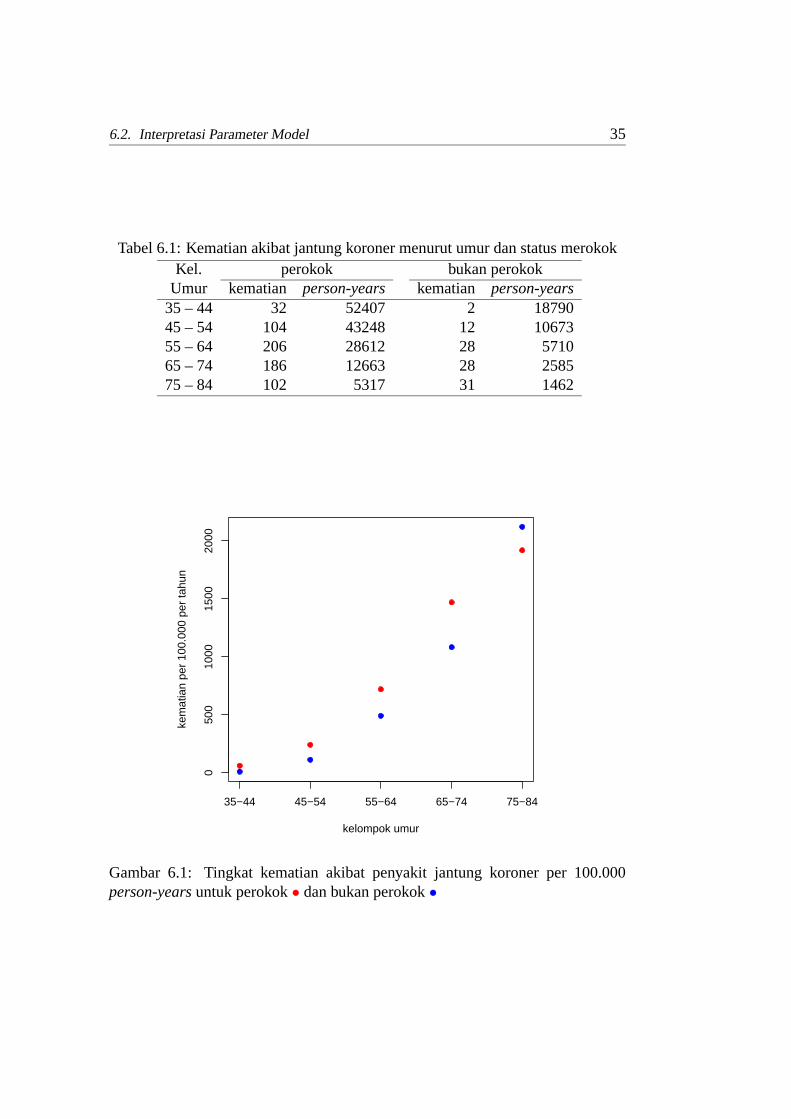
Contoh 1:Data diperoleh dari studi awal tentang akibat buruk merokokbagi kesehatan padatahun 1951. Kematian akibat penyakit jantung koroner dikategorikan menurutumur dan status merokok (Tabel 6.1).
Dapat dilihat pada Gambar 6.1 bahwa tingkat kematian untuk perokok lebihtinggi dibandingkan dengan tingkat kematian bukan perokok, kecuali untukkelompok usia lanjut.
Untuk menganalisis data ini dapat digunakan regresi Poisson. Ada dua alter-natif model yang dapat dicocokkan.
6.2. Interpretasi Parameter Model 35
Tabel 6.1: Kematian akibat jantung koroner menurut umur danstatus merokokKel. perokok bukan perokok
Umur kematian person-years kematian person-years35 – 44 32 52407 2 1879045 – 54 104 43248 12 1067355 – 64 206 28612 28 571065 – 74 186 12663 28 258575 – 84 102 5317 31 1462
050
010
0015
0020
00
kelompok umur
kem
atia
n pe
r 10
0.00
0 pe
r ta
hun
35−44 45−54 55−64 65−74 75−84
Gambar 6.1: Tingkat kematian akibat penyakit jantung koroner per 100.000person-yearsuntuk perokok• dan bukan perokok•

36 6.2. Interpretasi Parameter Model
Tabel 6.2: Estimasi parameter model (6.9)Parameter Estimasi SE RR Int-konf. 95% RR
β0 -10,79 0,450β1 1,44 0,372 4,22 2,04 – 8,76β2 2,37 0,207 10,77 7,16 –16,18β3 -0,19 0,027 0,82 0,78 – 0,87β4 -0,30 0,097 0,74 0,61 – 0,89
Model yang pertama menganggap kelompok usia sebagai variabel kontinu,sehingga dapat dimodelkan pula kuadrat dari umur dan interaksinya dengan sta-tus merokok. Asumsi ini masuk akal karena usia seperti terlihat pada Gambar6.1 menampilkan bentuk kuadratik dan bersilangan pada usialanjut yang menun-jukkan adanya interaksi.
log µi = log(si) + β1x1i + β2x2i + β3x1i × x2i + β4x21i, i = 1, . . . , 10 (6.9)
dengan
• µi : mean dari kematian
• si: person-years
• x1i: perokok atau bukan;
• x2i: usia1, 2, 3, 4, 5 ;
• x1i × x2i: interaksi (hasil kali) antarax1i denganx2i;
• x21i: kuadrat umur
Untuk model ini diperoleh estimasi seperti pada Tabel 6.2.Model kedua membuat variabel-variabel boneka (dummy) untuk kelompok
umur seperti biasa dengan interaksi variabel-variabel tersebut dengan statusmerokok.
log µi = log(si) + β1x1i + β2x2i + β3x3i + β4x4i + β5x5i +
β6x1ix2i + β7x1ix3i + β8x1ix4i + β9x1ix5i
i = 1, 2, . . . , 10 (6.10)
dengan
• µi : mean dari kematian

6.2. Interpretasi Parameter Model 37
Tabel 6.3: Estimasi parameter model (6.10)Parameter Estimasi SE RR Int-konf 95% RR
β0 -9,15 0,71 0,00 0,00 – 0,00β1 1,75 0,73 5,74 1,37 – 23,94β2 2,36 0,76 10,56 2,36 – 47,20β3 3,83 0,73 46,07 10,97 –193,39β4 4,62 0,73 101,76 24,24 –427,18β5 5,29 0,73 199,21 47,68 –832,36β6 -0,99 0,79 0,37 0,08 – 1,75β7 -1,36 0,76 0,26 0,06 – 1,13β8 -1,44 0,76 0,24 0,05 – 1,04β9 -1,85 0,76 0,16 0,04 – 0,70
• si: person-years
• x1i: perokok atau bukan;
• xki, k = 2, 3, . . . , 5: kelompok umur35 − 44, 45 − 54, . . ., 75 − 84
• x1ixki, h = 2, 3, . . . , 5: interaksi (hasil kali) antarax1i dengan kelompokumurxki
Untuk model kedua ini diperoleh estimasi seperti pada Tabel6.3.Model (6.9) memiliki lebih sedikit parameter dibandingkanmodel (6.10) dan
kecocokan yang lebih baik dilihat dari nilai AIC (Akaike Information Criterion)yaitu nilai AIC 66,70, lebih kecil dibanding model (6.10) yaitu 75.06794. Namunmemberi nilai numerik pada variabel kelompok umur terkadang dapat menye-satkan, karena pengubahan skala pengukuran dari interval ke rasio1.
1Apabila umur sebenarnya dari individu diketahui, lebih baik digunakan nilai variabel inidalam model

38 6.2. Interpretasi Parameter Model

7Analisis Data Longitudinal
7.1 Data longitudinal
Banyak penelitian dalam bidang kedokteran, kesehatan dan epidemiologi yangmenggunakan desain pengumpulan data longitudinal. Yang dimaksud dengan datalongitudinal adalah
• Individu (subyek, unit sampel) diamati dalam suatu periodewaktu tertentulebih dari satu kali
• Pengukuran berulang pada suatu individu (subyek, unit sampel)
Data longitudinal mempunyai kelebihan dibandingkan data yang hanyadikumpulkan satu kali saja (cross-sectional). Keuntungan ini dapat diilustrasikanseperti pada Gambar 7.1. Akan lebih mudah melihat informasibahwa kemam-puan membaca semakin naik atau semakin menurun seiring dengan umur bilaindividu diamati lebih dari satu kali.
Jenis data yang berkaitan dengan data longitudinal:
• Data Panel
• Data Survival, Antar Kejadian (Event History)
• Data Runtun Waktu
Beberapa keuntungan menggunakan data longitudinal:
• Dapat digunakan untuk mengetahui pola perubahan
• Setiap individu dapat menjadi kontrol bagi dirinya sendiri
• Dapat membedakan efek dari umur dengan efek dari cohort maupun efekdari periode
39

40 7.2. Prinsip Pemodelan
Umur
Kem
ampu
anM
emba
ca
b
b
b
b
b
b
b
b
b
b
Umur
Kem
ampu
anM
emba
ca
b
b
b
b
b
b
b
b
b
b
Gambar 7.1: Data longitudinal
• Memungkinkan untuk meneliti kausalitas
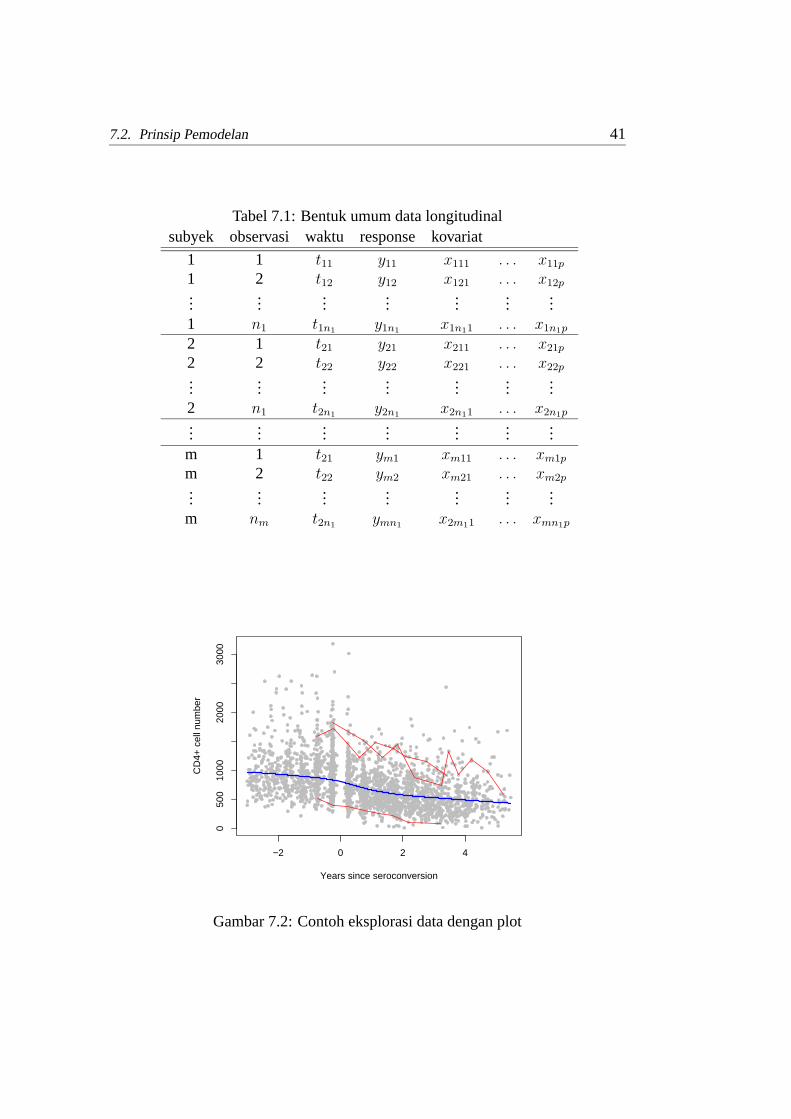
Secara umum data longitudinal mempunyaisetupseperti pada Tabel 7.1.Seperti halnya semua metode statistika, sebelum melakukananalisis kita per-
lu melakkan eksplorasi data. Prinsip eksplorasi data longitudinal di antaranyaadalah:
• tampilkan sebanyak mungkin data mentah daripada hanya ringkasannya
• tonjolkan pola atau ringkasannya
• identifikasilah baik polacross-sectionalmaupun longitudinal
• identifikasilah individu atau observasi yang tidak biasa (outliers)
Sebagai contoh, Gambar 7.2 adalah plot antara banyaknya selCD4+ denganwaktu sejakzeroconversionuntuk penderita AIDS. Dalam plot itu selain plot un-tuk keseluruhan individu, plot unutuk beberapa individu juga ditampilkan, disertaiplot untuk rata-rata keseluruhan individu (menggunakan fungsi penghalusan non-parametrik yang dinamakanlowess). Terlihat bahwa banyaknya sel CD4+ menu-run sejak pertama kali pasien AIDS didiagnosis menderita penyakit tersebut.
7.2 Prinsip Pemodelan
Seperti halnya model regresi biasa, permasalahan ilmiah diformulasikan sebagaimodel regresi yang terdiri dari variabel respon dan variabel penjelas. Dua halpenting yang perlu diperhatikan, secara alamiah dalam datalongitudinal terda-pat variabel yang berubah sepanjang waktu (time-varying expl. variables) dan
7.2. Prinsip Pemodelan 41
Tabel 7.1: Bentuk umum data longitudinalsubyek observasi waktu response kovariat
1 1 t11 y11 x111 . . . x11p
1 2 t12 y12 x121 . . . x12p...
......
......
......
1 n1 t1n1y1n1
x1n11 . . . x1n1p
2 1 t21 y21 x211 . . . x21p
2 2 t22 y22 x221 . . . x22p...
......
......
......
2 n1 t2n1y2n1
x2n11 . . . x2n1p
......
......
......
...m 1 t21 ym1 xm11 . . . xm1p
m 2 t22 ym2 xm21 . . . xm2p...
......
......
......
m nm t2n1ymn1
x2m11 . . . xmn1p
−2 0 2 4
050
010
0020
0030
00
Years since seroconversion
CD
4+ c
ell n
umbe
r
Gambar 7.2: Contoh eksplorasi data dengan plot

42 7.2. Prinsip Pemodelan
korelasi (asosiasi) karena pengukuran berulang pada individu yang sama, atau ob-servasi berulang. Dua hal ini harus dimasukkan dalam pemodelan.
Notasi yang digunakan dalam analisis data longitudinal
• Individu: i = 1, . . . ,m
• Observasi pada individui: jh = 1, . . . , ni
• Total observasi:N =∑m
i=1 ni
• Waktu observasi aktual:tij
• Variabel respon:variabel random respon observasiYij yij
Yi = (Yi1, . . . , Yini) yi = (yi1, . . . , yini
)Y = (Y1, . . . ,Ym) y = (y1, . . . ,ym)
• Variabel penjelas:xij = (xij1, . . . , xijp)
T , vektor berukuranp × 1Xi = (xi1, . . . , xini
), matriks berukuranni × p
• MeanYi untuk individui: E(Yi) = µi
• VariansiYi ; Matriks Kovariansini × ni untuk individui:
Var(Yi) =
vi11 . . . vi1ni
. . . vijk . . .vini1 . . . vinini
denganvijk = Cov(Yij, Yik)
Ada beberapa pendekatan pemodelan yang dikenal selama ini,yaitu:
• Model linear umum
• Model marginal (marginal, population average)
• Model efek random (random effects; subject specific)
• Model transisi (transition)

7.3. Model Linear Umum untuk data longitudinal 43
7.3 Model Linear Umum untuk data longitudinal
• Merupakan Perluasan dari model linear (Anava, regresi, anacova) denganbentuk variansi yang lebih umum
• Estimasi parameter menggunakan least-squares atau MLE atau perluasan-nya
• Untuk respon (Y) kontinu
Data observasiyij merupakan realisasi dari variabel randomYij,
Yij = µij + Ui + Zij
dimanaµij = E(Yij),Ui ∼ N(0, v2) independen dgnZij ∼ N(0, τ 2)danY ∼ MV N(Xβ, σ2V)
σ2V adalah blok diagonal matriks yang terdiri atasn× n blok σ2V0 (matriksvariansi vektor observasi pada suatu subyek).
Bentuk korelasi antar dua observasi pada satu subyek
• Korelasi UniformV0 = (1 − ρ)I + ρI
• Korelasi Eksponensial
vjk = σ2 exp(−φ(| tj − tk |))
denganvjk = Cov(Yij, Yik)
7.4 Model Parametrik untuk Struktur Kovariansi
Data observasi:yi = (yi1, . . . , yini
), i = 1, . . . , ni adalah vektor observasi untuk subyeki danti = (ti1, . . . , tini
) adalah waktu observasi;yi merupakan realisasi dari
Yi ∼ MV N(Xiβ, σ2Vi(ti,α))
denganβ danα adalah parameter yang tidak diketahui nilainya dengan dimensip danq.

44 7.4. Model Parametrik untuk Struktur Kovariansi
Dapat juga ditulis sbg.:
Y ∼ MV N(Xβ, σ2V(t,α))
Variogram dari suatu proses stokastikY (t)
λ(u) =1
2E
[(Y (t) − Y (t − u))2
], u ≥ 0
Untuk suatu proses stasionerY (t), jika ρ(u) adalah korelasi antaraY (t) denganY (t − u) danσ2 = VarY (t), maka
λ(u) = σ2(1 − ρ(u)), u ≥ 0
Sumber variansi random:
• Efek Random (random effects)
• Korelasi serial (serial correlation))
• galat pengukuran (measurement error)
Model:Y = Xβ + ǫ
denganǫ ∼ MV N(0, V (t,α))
Dengan asumsi aditif untuk komponen sumber variansi efek random, korelasiserial dan galat pengukuran:
ǫij = dTijUi + Wi(tij) + Zij
denganǫij adalah galat dari individui pengukuran (observasi) ke-j; Zij adalahN i.i.d berdistribusiN(0, τ 2); Ui adalahm kumpulani.i.d dari random vektorN(0, G) denganr elemen ;dij adalah vektor variabel independen denganr el-emen untuk tiap individui; Wi(tij m i.i.d adalah proses Gaussian dengan meannol, variansiσ2 dan fungsi korelasiρ(u).
Model:Y = Xβ + ǫ
denganǫ ∼ MV N(0, V (t,α))
Dengan asumsi aditif untuk komponen sumber variansi efek random, korelasiserial dan galat pengukuran:
ǫij = dTijUi︸ ︷︷ ︸
efek random
+ Wi(tij)︸ ︷︷ ︸korelasi serial
+ Zij︸︷︷︸galat pengukuran

7.4. Model Parametrik untuk Struktur Kovariansi 45
Estimasi menggunakanWeighted Least-squaresEstimasi parameterβ menggunakan bobot matriks simetrisW adalahβW
yang meminimumkan(y − Xβ)TW(y − Xβ)
HasilnyaβW = (XTWX)−1XTWy
danVar(βW ) = σ2
[(XTWX)−1XTW
]V
[(WX(XTWX)−1
]
Estimasi menggunakanMaximum LikelihoodParameter:β, σ2 danV0
Fungsi log-likelihood
ℓ(β, σ2,V0) = −1
2
[nm log σ2 + m log | V0 | +σ−2(y − Xβ)TV−1(y − Xβ)
]
(7.1)Estimasi untukβ dengan diketahuiV0
β(V0) = (XTV−1X)−1XTV−1y (7.2)
Fungsi log-likelihood (7.1) menjadi
ℓ(β(V0), σ2,V0) = −
1
2
[nm log σ2 + m log | V0 | +σ−2RSS(V0)
](7.3)
dengan RSS(V0) = (y − Xβ(V0))TV−1(y − Xβ(V0))
Parameter:β, σ2 danV0
Turunkan (7.3) keσ2, diperoleh estimasiσ2
σ2(V0) = RSS(V0)/nm (7.4)
Substitusikan (7.2), (7.3) dan (7.4) ke (7.1)
ℓr(V0) = ℓ(β(V0), σ2(V0),V0)
≈ −1
2[n log RSSV0 + log | V0 |] (7.5)
Akhirnya diperoleh estimasi untukV0, danβ = β(V0) danσ2 = σ2(V0)

46 7.4. Model Parametrik untuk Struktur Kovariansi

8Analisis Data Survival
8.1 Fungsi Survival dan Hazard
Fungsi Survival adalah probabilitas satu individu hidup (tinggal dalam suatusta-tus) lebih lama daripadat
S(t) = P (T > t) (8.1)
S(t) adalah fungsinon-increasingterhadap waktut dengan sifat
S(t) =
{1 untuk t = 0
0 untuk t = ∞
Fungsi survivalS(t) mempunyai hubungan dengan distribusi kumulatifF (t)sebagai berikut
S(t) = 1 − F (t)
Penduga untukS(t) bila data tidak tersensor
S(t) =s
N(8.2)
dimanas adalah banyaknya individu yang masih hidup lebih lama darit ; Nadalah total banyaknya individu
FungsiHazardmenunjukkan tingkat (rate) terjadinya suatueventyang dide-finisikan sebagai
h(t) = lim∆t→0
P (t ≤ T < t + ∆t | T ≥ t)
∆t
Tidak seperti probabilitas yang nilainya antara 0 sampai dengan 1, fungsi hazarddapat bernilai berapa saja asalkan non-negative,h(t) ≥ 0. Gambar 8.2, 8.3, 8.4dan 8.5 adalah contoh beberapa macam fungsi hazard.
47

48 8.2. Kaplan-Meier danLife Table
0.0 0.5 1.0 1.5 2.0
0.0
0.2
0.4
0.6
0.8
1.0
t
S(t
)
Gambar 8.1: Grafik dua fungsi survival
Hubunganh(t), S(t) danf(t)
h(t) =f(t)
S(t)
FungsiHazardKumulatif
H(t) =
∫ t
0
h(x)dx
HubunganH(t) denganS(t)
H(t) = − log S(t)
8.2 Kaplan-Meier dan Life Table
Kaplan-Meier merupakan estimator non-parametrik untukS(t) (sering disebut ju-ga sebagai Product-Limit estimator)
S(t) =
{1 jika t < t1∏
ti≤t(1 − di
Yi
) jika ti ≤ t

8.2. Kaplan-Meier danLife Table 49
0.0 0.5 1.0 1.5 2.0
01
23
45
t
h(t)
Gambar 8.2: Fungsi hazard konstan
0.0 0.5 1.0 1.5 2.0
01
23
45
t
h(t)
Gambar 8.3: Fungsi hazard naik
50 8.2. Kaplan-Meier danLife Table
0.0 0.5 1.0 1.5 2.0
01
23
45
t
h(t)
Gambar 8.4: Fungsi hazard naik-turun
0.0 0.5 1.0 1.5 2.0
01
23
45
t
h(t)
Gambar 8.5: Fungsi hazardbathtub

8.3. Membandingkan Distribusi Survival 51
dimanadi adalah banyaknyaeventdanYi adalah banyaknya individu yang bere-siko (number at risk)
Variansi dari KM estimator (Greenwood’s formula)
var[S(t)] = S(t)2∑
ti≤t
di
Yi(Yi − di)
Alternatif:
var[S(t)] = S(t)2 [1 − S(t)]
Y (t)
Nelson-Aalen merupakan estimator untuk fungsi hazard kumulatif:
H(t) =
{0 jika t < t1∑
ti≤tdi
Yi
jika ti ≤ t
dengan variansi
Var(H(t)) =∑
ti≤t
di
Y 2i
8.3 Membandingkan Distribusi Survival
Membandingkan dua populasi yang masing-masing mempunyai fungsi survivalS1(t) danS2(t).
Hipotesis nol:H0 : S1(t) = S2(t)
Hipotesis alternatif:H1 : S1(t) > S2(t)H1 : S1(t) < S2(t)H1 : S1(t) 6= S2(t)Metode Non-parametrik
Untuk data tidak tersensor dapat digunakan
• Wilcoxon (1945)
• Mann-Whitney (1947)
• Sign test (1977)
Untuk data tersensor

52 8.4. Model Regresi data survival
• Gehan’s generalized Wilcoxon test (1965)
• the Cox-Mantel test (Cox 1959, 1972; Mantel, 1966)
• the logrank test (1972)
• Peto and Peto’s generalized Wilcoxon test (1972)
• Cox’s F-test (1964)
• Gehan’s generalized Wilcoxon test (1965)
• the Cox-Mantel test (Cox 1959, 1972; Mantel, 1966)
• the logrank test (1972)
• Peto and Peto’s generalized Wilcoxon test (1972)
• Cox’s F-test (1964)
Log-rank Test
Berdasarkanobserveddanexpectedevent pada setiapevent-time
Untuk 2 grupStatistik penguji:
χ2 =(O1 − E1)
2
E1
+(O2 − E2)
2
E2
denganχ2 ∼Chi-square(df=1)Contoh:grup 1: 23, 16+, 18+, 20+, 24+
grup 2: 15, 18, 19, 19, 20
H0 : S1(t) = S2(t)H1 : S1(t) 6= S2(t)
8.4 Model Regresi data survival
Model Regresi Parametrik
• AFT (accelerated failure-time model)
• model linear dalam log durasi (lama antar kejadian)

8.4. Model Regresi data survival 53
• model hazard proporsional
• Representasi fungsi hazard AFT
h(t | X) = h0(exp(Xβ)t) exp(Xβ)
denganX adalah matriks (n × p) dari variabel penjelas;βT = (β1 . . . βp)adalah vektor (p × 1) parameter regresi.
• Representasilog Tlog T = µ + Xα + σǫ
denganαT = (α1 . . . αp) danµ adalah parameter regresi;ǫ adalah sukuerror berdistribusi tertentu danσ > 0 adalah suatu parameter skala.
Model AFT dapat ditulis sebagai fungsi hazard atau survival
H(t | x) = H0(exp(xβ)t), untuk semuat
atau
S(t | x) = S0(exp(xβ)t), untuk semuat
denganH0 adalah baseline fungsi hazard kumulatif danS0 baseline fungsisurvival
Hazard ProporsionalMisalkan ada dua orang yang masing-masing mempunyai hazardλ1 = 0, 1
danλ2 = 0, 3
hazard ratio:λ2
λ1
= 0,30,1
= 3Misalkan ada dua orang yang masing-masing mempunyai hazardλ1 = 0, 1
danλ2 = 0, 3
hazard ratio:λ2
λ1
= 0,30,1
= 3
konstant, independen terhadap waktuCox’s regression model atau Cox’s proportional hazards (Cox;1972,1975):
h(t | x) = h0(t)ψ(x,β)

54 8.4. Model Regresi data survival
denganx = (x1, . . . , xp) adalah vektor kovariat (variabel independen) danβ′ =(β1, . . . , βp) adalah parameter dari model regresi
Cox’s regression model atau Cox’s proportional hazards (Cox;1972,1975):
h(t | x) = h0(t)ψ(x, β)
fungsi hazardbergantung padax =
baseline hazardtdk bergantung pdx × fungsi kovariat
Cox’s regression model atau Cox’s proportional hazards (Cox;1972,1975):
h(t | x) = h0(t)ψ(x, β)
fungsi hazardbergantung padax =
baseline hazardtdk bergantung pdx × fungsi kovariat
Bentuk fungsional dariψ(x, β)
• ψ(x, β) = exp(xβ)
• ψ(x, β) = exp(1 + xβ)
• ψ(x, β) = log(1 + exp(xβ))
Model:
h(t | x) = h0(t) exp(xβ)
Misalkan:
x =
{0 placebo
1 obat baru
Hazard ratio:
h(t | x = 1)
h(t | x = 0)=
h0(t) exp(1 × β)
h0(t) exp(0 × β)
Model:
h(t | x) = h0(t) exp(xβ)
Hazard ratio:
h(t | x = 1)
h(t | x = 0)=
h0(t) exp(1 × β)
h0(t) exp(0 × β)
= exp(β)

8.4. Model Regresi data survival 55
Hazard ratio:
h(t | x = 1)
h(t | x = 0)=
h0(t) exp(1 × β)
h0(t) exp(0 × β)
= exp(β)
jika β = 0 ⇒ obat baru dan placebo sama efeknyajika β < 0 ⇒ obat baru memberikan efek yang lebih baik daripada placebo (resiko
kematian lebih rendah)jika β > 0 ⇒ obat baru memberikan efek yang lebih buruk daripada placebo (resiko
kematian lebih tinggi)Secara umum nilai estimasiβ dapat digunakan untuk mengidentifikasi faktor resiko
(risk factors, prognostic factors) yang berkaitan dengan variabel dependentime-to-eventT .
Dapat dituliskan dalamH(t | x) atauS(t | x)
H(t | x) = H0(t) exp(xβ)
S(t | x) = S0(t)exp(xβ)
denganH0 adalahbaselinehazard kumulatif danS0 adalahbaselinesurvival

56 8.4. Model Regresi data survival

9Ringkasan Metode
Metode statistik yang dapat digunakan sebagai alat analisis dalam penelitiandi bidangkedokteran, ilmu hayati dan epidemiologi dapat diringkas seperti Tabel 9.1.
Tentu saja masih banyak metode lain yang tidak disebutkan dalam ringkasan. Misal-nya metode-metode nonparametrik padanan metode parametrik di atas. Selain itu, masihbanyak masalah yang memerlukan pengembangan metode baru atau modifikasimetode.Misalnya beberapa desain seperticase-cohort, case-controlmemerlukan modifikasi me-tode regresi logistik dan regresi Cox.
57

58
Tabel 9.1: Ringkasan MetodeRespon Variabel penjelas MetodeKontinu Biner t-test, z-test
Nominal, 2 kategoriatau lebih
ANAVA
Ordinal ANAVAKontinu Regresi GandaNominal dan kontinu Analisis KovariansiKategorik dan kontinu Regresi Ganda
Biner Kategorik Tabel kontingensiRegresi Logistik
Kontinu Regresi Logistik,probit ataumodel dose-response
Kategorik dan kontinu Regresi LogistikNominal, 2kategori
Nominal Tabel kontingensi
atau lebih Kategorik dan kontinu Regresi LogistikNominal
Ordinal Kategorik dan kontinu Regresi LogistikOrdinal
Cacah Kategorik Model Log-linear,Regresi Poisson
Kategorik dan kontinu Regresi PoissonDurasi (survival) Biner Log-rank test
Kategorik dan kontinu Survival analysisResponberkorelasi
Kategorik dan kontinu Generalized EstimatingequationMultilevels modelAnalisis DataLongitudinalAnalisis Data Panel

Daftar Pustaka
Armitage, P. and Colton, T. (1998).Encyclopedia of Biostatistics, John Wiley & Sons,Inc.
Chow, S.-C. (2000).Encyclopedia of Biopharmaceutical Statistics., Marcel Dekker, NewYork.
Kleinbaum, D. G., Kupper, L. L. and Morgenstern, H. (1982).Epidemiologic Research:Principles and Quantitative Methods., Wadsworth, Inc.
Last, J. (1995).A Dictionary of Epidemiology, 3rd edn, Oxford University Press.
Le, C. T. (2003).Introductory Biostatistics, John Wiley & Sons, Inc.
59




















