
Klasifikasi Status Gizi Balita Menggunakan Metode Decision ...
59
Klasifikasi Status Gizi Balita Menggunakan Metode Decision Tree C4.5 Oleh: Yanuiarius Basilius 165314047 Program Studi Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta 2020 PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
Transcript of Klasifikasi Status Gizi Balita Menggunakan Metode Decision ...

Klasifikasi Status Gizi Balita Menggunakan
Metode Decision Tree C4.5
Oleh:
Yanuiarius Basilius
165314047
Program Studi Informatika
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Yogyakarta
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

Classification of Toddler Nutrition
Using C4.5 Decision Tree Method
By:
Yanuiarius Basilius
165314047
Informatics Study Program
Faculty of Science And Technology
Sanata Dharma University
Yogyakarta
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

HALAMAN PERSETUJUAN
S KR量PS量
Klasi鯨kasi Status Gizi Ba此a Menggunakan Mctode Dα恵めn Z+臓c4 5
Dosen Pembimbing l ,
」‥.2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

HALAMAN PENGESAHAN
SKR量PS賞
Klas推hasi Status Gizi BaHta Menggunahan Metode Dea寂を説分隊C4 5
D車erse皿ba址ran dan disu s皿oleh:
Yanu鉦i陣S Bas轟競S
1653 14047
Y。g,ak。rta, #. Jh硬a詰2021
F永山tas Sa誼sめれT謙れobgj
Universitas Samata Dh孤ma
Dek狐,
起因Sudi N鳳ngkasiうPh.d.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

viii
ABSTRAK
Gizi sangat dibutuhkan dalam pertumbuhan balita, penting sekali memberi
bayi asupan gizi seimbang pada tahap yang benar agar bayi tumbuh sehat dan
terbiasa dengan pola hidup sehat di masa yang akan datang. Anak usia di bawah
lima tahun merupakan golongan yang rentan terhadap masalah kesehatan dan gizi.
Berdasarkan hasil Riset Kesehatan Dasar (Riskesdas) Kementerian Kesehatan 2018
menunjukkan 17,7% bayi usia di bawah 5 tahun (balita) masih mengalami masalah
gizi. Dalam menentukan status gizi selama ini dilakukan secara manual oleh bidan
atau perawat puskesmas. Sebenarnya dalam menentukan status gizi bisa dilakukan
secara otomatis dengan menggunakan beberapa metode klasifikasi dengan
menginputkan beberapa variabel atau atribut. Salah satu metode tersebut adalah
Decision Tree C4.5. Keluaran sistem adalah hasil prediksi keputusan status gizi
yang diambil dari Puskesmas Kebong, kab. Sintang, Kalimantan Barat. Peneliti
melakukan pengujian pada dataset yang berjumlah 853 data. Klasifikasi dilakukan
untuk menentukan status gizi berdasarkan BB/U, PB/U, dan BB/PB. Atribut yang
digunakan untuk klasifikasi BB/U adalah jenis kelamin, berat badan, dan umur.
Atribut yang digunakan untuk PB/U adalah jenis kelamin, panjang badan atau
tinggi badan, dan umur. Atribut yang digunakan untuk BB/PB adalah jenis kelamin,
berat badan, panjang badan atau tinggi badan, dan umur. Rata-rata akurasi tertinggi
untuk kelas BB/U adalah 90,93% dengan menggunakan 5 folds, untuk kelas PB/U
adalah 78,33% dengan menggunakan 7 folds, dan untuk kelas BB/PB adalah
84,45% dengan menggunakan 7 folds.
Kata kunci: Klasifikasi, Pohon Keputusan, C4.5, Gizi Balita, Penambangan Data,
Pembelajaran Mesin
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ix
ABSTRACT
Nutrition is very needed in the growth of toddlers, it is very important to give
babies a balanced nutrition intake at the right stage so that the baby grows healthy
and gets used to a healthy lifestyle in the future. Children under five years of age
are vulnerable to health and nutrition problems. Based on the results of the 2018
Ministry of Health's Basic Health Research, 17.7% of infants under 5 years of age
(toddlers) still experience nutritional problems. In determining nutritional status,
midwives or public health center nurses have done it manually. Actually,
determining nutritional status can be done automatically by using several
classification methods by entering several variables or attributes. One such method
is the C4.5 Decision Tree. The system output is the prediction of nutritional status
decisions taken from Kebong Public Health Center, Sintang District, West Borneo
Province. Researchers tested the dataset which amounted to 853 data. The
classification is carried out to determine nutritional status based on body
weight/age (BB/U), body length/age (PB/U), and body weight/body length (BB/PB).
The attributes that used for the classification of body weight/age (BB/U) are sex,
body weight and age. The attributes that are used for body length/age (PB/U) are
gender, body length or height, and age. The attributes that are used for body
weight/body length (BB/PB) are gender, body weight, body length or height, and
age. The highest average accuracy for class BB/U is 90.93% using 5 folds, for PB/U
class is 78.33% using 7 folds, and for BB/PB class is 84.45% using 7 folds.
Keywords: Classification, Decision Tree, C4.5, Toddler Nutrition, Data Mining,
Machine Learning
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

x
DAFTAR ISI
JUDUL ................................................................................................................ i
HALAMAN PERSETUJUAN ............................................................................ ii
HALAMAN PENGESAHAN ............................................................................. iii
HALAMAN PERSEMBAHAN .........................................................................iv
PERNYATAAN KEASLIAN KARYA .............................................................vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA
ILMIAH UNTUK KEPENTINGAN AKADEMIS ............................................vii
KATA PENGANTAR ........................................................................................ viii
ABSTRAK .......................................................................................................... ix
ABSTRACT .......................................................................................................... x
DAFTAR ISI ....................................................................................................... xi
DAFTAR TABEL ............................................................................................... xii
DAFRTAR GAMBAR ....................................................................................... xiv
DAFTAR PROGRAM ........................................................................................ xv
BAB I PENDAHULUAN ................................................................................... 1
1.1 Latar Belakang ......................................................................................... 1
1.2 Rumusan Masalah .................................................................................... 3
1.3 Tujuan ....................................................................................................... 3
1.4 Batasan Masalah ....................................................................................... 3
1.5 Sistematika Penulisan ............................................................................... 3
BAB II LANDASAN TEORI ............................................................................. 5
2.1 Data Mining ............................................................................................. 5
2.1.1 Prediksi ............................................................................................. 5
2.1.2 Deskripsi ........................................................................................... 5
2.1.3 Klasifikasi ......................................................................................... 5
2.1.4 Asosiasi ............................................................................................. 6
2.1.5 Estimasi............................................................................................. 6
2.1.6 Pengklusteran .................................................................................... 6
2.2 Tahapan Data Mining ............................................................................... 6
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xi
2.2.1 Pre-Processing ................................................................................. 7
2.2.2 Data Selection ................................................................................... 7
2.2.3 Data Mining ...................................................................................... 8
2.2.4 Evaluation ......................................................................................... 8
2.3 Klasifikasi ................................................................................................. 8
2.4 Algoritma C4.5 ......................................................................................... 9
2.5 Evaluasi .................................................................................................... 10
2.5.1 Confusion Matrix .............................................................................. 10
2.5.2 Cross Validation ............................................................................... 11
2.6 Pemantauan Status Gizi Balita (PSG) ...................................................... 12
BAB III METODE PENELITIAN...................................................................... 13
3.1 Peralatan Penelitian .................................................................................. 13
3.2 Bahasa Pemrograman Python ................................................................... 13
3.3 Data .......................................................................................................... 14
3.4 Alur Penelitian .......................................................................................... 16
3.4.1 Data Cleaning ................................................................................... 16
3.4.2 Seleksi Data ...................................................................................... 16
3.4.3 Pembagian Data ................................................................................ 17
3.4.4 Pemisahan Data ................................................................................ 18
3.4.5 Modeling Decision Tree C4.5 ........................................................... 18
3.4.6 Pengujian .......................................................................................... 23
3.4.7 Akurasi .............................................................................................. 24
3.5 Perancangan GUI ..................................................................................... 25
3.5.1 Halaman Awal .................................................................................. 25
3.5.2 Halaman Klasifikasi Gizi .................................................................. 25
3.5.3 Halaman Setting ................................................................................ 26
3.5.4 Halaman Feature Selection .............................................................. 27
3.5.5 Halaman Dataset .............................................................................. 28
3.5.6 Halaman View Tree........................................................................... 28
BAB IV IMPLEMENTASI DAN ANALISIS .................................................... 30
4.1 Implementasi ............................................................................................ 30
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xii
4.1.1 Preprocessing ................................................................................... 30
4.1.2 Modeling ........................................................................................... 31
4.1.3 Evaluasi............................................................................................. 32
4.2 Pengujian Menggunakan Dataset ............................................................. 35
4.2.1 Pengujian Menggunakan Manual Attribute ...................................... 35
4.2.2 Pengujian Menggunakan Voting Attribute Selection ........................ 36
4.3 Perbandingan Hasil Pengujian .................................................................. 39
4.3.1 BB/U ................................................................................................. 39
4.3.2 PB/U ................................................................................................. 39
4.3.3 BB/PB ............................................................................................... 39
4.4 Analisis ..................................................................................................... 40
BAB V PENUTUP .............................................................................................. 41
5.1 Kesimpulan ............................................................................................... 41
5.2 Saran ......................................................................................................... 42
DAFTAR PUSTAKA ......................................................................................... 43
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiii
DAFTAR TABEL
Tabel 2.1 Confusion Matrix untuk dua kelas ......................................................11
Tabel 3.1 Kelas dan Label ...................................................................................14
Tabel 3.2 Contoh Data dan Keterangan Atribut..................................................15
Tabel 3.3 Atribut yang digunakan tiap kelas ......................................................17
Tabel 3.4 Dataset ................................................................................................19
Tabel 3.5 Data Training ......................................................................................19
Tabel 3.6 Data Testing ........................................................................................19
Tabel 3.7 Perhitungan node 1..............................................................................20
Tabel 3.8 Tabel dataset pada node 2 ...................................................................21
Tabel 3.9 Perhitungan node 2..............................................................................22
Tabel 3.10 Percobaan Decision Tree C4.5 untuk atribut yang dipilih manual ...23
Tabel 3.11 Percobaan Decision Tree C4.5 untuk atribut yang di-voting ............24
Tabel 4.1 Weighted Voting untuk BB/U .............................................................30
Tabel 4.2 Weighted Voting untuk PB/U ..............................................................31
Tabel 4.3 Weigted Voting untuk BB/PB .............................................................31
Tabel 4.4 Hasil percobaan BB/U ........................................................................35
Tabel 4.5 Hasil prcobaan PB/U ...........................................................................46
Tabel 4.6 Hasil percobaan BB/PB ......................................................................46
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiv
DAFTAR GAMBAR
Gambar 2.1 Data Mining ....................................................................................7
Gambar 2.2 Cross Validation ..............................................................................12
Gambar 3.1 Alur penelitian .................................................................................16
Gambar 3.2 Root Node ........................................................................................21
Gambar 3.3 Leaf Node ........................................................................................22
Gambar 3.4 Halaman Awal .................................................................................25
Gambar 3.5 Halaman klasifikasi gizi ..................................................................26
Gambar 3.6 Halaman Setting ..............................................................................27
Gambar 3.7 Halaman feature selection ...............................................................28
Gambar 3.8 Halaman Dataset .............................................................................29
Gambar 3.9 Halaman view tree ...........................................................................29
Gambar 4.1 Matrix kelas PB/U ...........................................................................33
Gambar 4.2 Grafik rata-rata akurasi BB/U .........................................................37
Gambar 4.3 Grafik rata-rata akurasi PB/U ..........................................................38
Gambar 4.4 Grafik rata-rata akurasi BB/PB .......................................................38
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xv
DAFTAR PROGRAM
Program 4.1 Import Klasifikasi ...........................................................................32
Program 4.2 Pemisahan data training dan testing tiap folds ..............................32
Program 4.3 Membangun model klasifikasi .......................................................32
Program 4.4 Klasifikasi data testing ...................................................................32
Program 4.5 Import Cross Validation .................................................................32
Program 4.6 Input Folds .....................................................................................33
Program 4.7 Import dan membangun confusion matrix......................................33
Program 4.8 Menghitung akurasi ........................................................................34
Program 4.9 Rata-rata akurasis ...........................................................................34
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Gizi adalah substansi organik yang dibutuhkan untuk fungsi
normal dari sistem tubuh, pertumbuhan dan pemeliharaan kesehatan.
Penting sekali memberi bayi asupan gizi seimbang pada tahap yang
benar agar bayi tumbuh sehat dan terbiasa dengan pola hidup sehat di
masa yang akan datang. Anak usia di bawah lima tahun merupakan
golongan yang rentan terhadap masalah kesehatan dan gizi, sehingga
masa balita merupakan masa pertumbuhan yang sangat penting dan
perlu perhatian yang serius. Berdasarkan hasil Riset Kesehatan Dasar
(Riskesdas) Kementerian Kesehatan 2018 menunjukkan 17,7% bayi
usia di bawah 5 tahun (balita) masih mengalami masalah gizi. Angka
tersebut terdiri atas balita yang mengalami gizi buruk sebesar 3,9% dan
yang menderita gizi kurang sebesar 13,8%(Kemenkes,2018). Status
gizi balita dapat diukur secara antropometri, indeks antropometri yang
sering digunakan, yaitu: berat badan menurut umur (BB/U), tinggi
badan menurut umur (TB/U), berat badan menurut tinggi badan
(BB/TB). Indeks berat badan berdasarkan umur (BB/U) merupakan
indikator yang paling umum digunakan karena mempunyai kelebihan
yaitu mudah dan lebih cepat dimengerti oleh masyarakat umum.
Standar rujukan yang digunakan untuk penentuan status gizi dengan
antropometri berdasarkan SK Menkes No. 920/Menkes/SK/VIII/2002,
untuk menggunakan rujukan buku World Health Organization-
National Center for Health Statistics (WHO-NCHS) dengan melihat
nilai Z-score.
Dalam menentukan status gizi selama ini dilakukan secara
manual oleh bidan atau perawat puskesmas. Sebenarnya dalam
menentukan status gizi bisa dilakukan secara otomatis dengan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

2
menggunakan beberapa metode klasifikasi dengan menginputkan
beberapa variabel atau atribut. Salah satu metode tersebut adalah
Decision Tree C4.5.
Algoritma C4.5 merupakan algoritma yang digunakan untuk
membentuk pohon keputusan (Decision Tree). Pohon keputusan adalah
model prediksi menggunakan struktur pohon atau struktur berhirarki.
Konsep dari pohon keputusan adalah mengubah data menjadi pohon
keputusan dengan aturan-aturan keputusan. Algoritma C4.5
mempunyai data masukan berupa data testing dan data training, data
training merupakan data contoh yang digunakan untuk membangun
sebuah tree yang telah teruji kebenarannya. Sedangkan data testing
digunakan untuk mengukur sejauh mana klasifikasi berhasil melakukan
klasifikasi dengan benar.
Pada penelitian sebelumnya tentang perbandingan kinerja
algoritma C4.5 dan Naive Bayes untuk klasifikasi penerima beasiswa
oleh Choirul Anam dan Harry Budi Santoso, menyatakan bahwa
algoritma C4.5 mempunyai kinerja yang lebih baik dari Naive Bayes
dengan tingkat akurasi yang didapatkan menggunakan algoritma C4.5
sebesar 96.4%, sedangkan tingkat akurasi dari Naïve Bayes sebesar
95.11% (Anam, Choirul dan Santoso 2018).
Pada penelitian lainnya dilakukan oleh Ulva Febriana, M. Tanzil
Furqon, dan Bayu Rahayudi (2018) tentang klasifikasi penyakit typhoid
fever (TF) dan dengue hemorrhagic fever (DHF) dengan menerapkan
algoritma decision tree C4.5. Disimpulkan dengan menggunakan
pengujian k-folds cross validation didapatkan nilai rata-rata akurasi
tertinggi pada 5-folds dengan akurasi sebesar 91,875% yang
menggunakan data uji sebanyak 32 data dan data latih sebanyak 128
data (Febriana, Farqon, dan Rahayudi 2017).
Dari uraian diatas penulis melakukan penelitian menggunakan
metode Decision Tree C4.5 dalam menentukan status gizi balita.
Diharapkan dengan menerapkan metode Decision Tree C4.5 dapat
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

3
membantu mengklasifikasikan status gizi balita untuk mengetahui
pertumbuhan balita.
1.2. Rumusan Masalah
Berdasarkan latar belakang masalah diatas, maka dapat
disimpulkan rumusan masalah adalah berapa akurasi dari metode
Decision Tree C4.5 dalam mengklasifikasi status gizi balita?
1.3. Tujuan
Tujuan dari penelitian ini adalah untuk mengetahui hasil dari
akurasi Decision Tree C4.5 dalam menentukan status gizi balita.
1.4. Batasan Masalah
Batasan-batasan masalah dalam penulisan proposal tugas akhir
ini antara lain:
1. Parameter yang digunakan adalah jenis kelamin, umur, tinggi
badan dan berat badan.
2. Ambang batas pengkategorian parameter tinggi, berat dan
BMI berdasarkan pada Keputusan Menteri Kesehatan
Republik Indonesia Nomor: 1995/Menkes/SK/XII/2010
tentang standar Antropometri Penilaian Status Gizi anak.
3. Penentuan Status Gizi menggunakan perhitungan berat badan
terhadap umur (BB/U), Panjang badang terhadap umur
(PB/U), dan berat badan terhadap panjang badan (BB/PB).
1.5. Sistematika Penulisan
Bagian ini berisi mengenai sistematika penulisan tugas akhir.
BAB I PENDAHULUAN
Pada bab ini berisi tentang latar belakang masalah, rumusan
masalah, tujuan penelitian, batasan masalah, metodologi penelitian,
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

4
dan sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini, akan dibahas tentang berbagai teori yang
berhubungan dengan status gizi balita, metode decision tree C4.5.
BAB III METODE PENELITIAN
Berisi analisis teori-teori yang digunakan dan bagaimana
menerjemahkannya kedalam system yang akan dibuat dan membahas
tentang perancangan kebutuhan sistem.
BAB IV IMPLEMENTASI DAN ANALISA HASIL
Bab ini membahas Analisa hasil perancangan sistem, dan
pengujian algoritma C4.5.
BAB V PENUTUP
Bab ini berisi kesimpulan dari hasil Analisa dan saran-saran
untuk pengembangan lebih lanjut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

5
BAB II
LANDASAN TEORI
Pada bab ini dijelaskan mengenai teori yang digunakan untuk mendukung
penelitian dalam mengklasifikasi status gizi balita menggunakan decision tree C4.5.
2.1 Data Mining
Data mining adalah proses ekstraksi pola yang menarik dari
sekumpulan data yang berjumlah besar, dengan melakukan penggalian
pola-pola dari data tersebut bertujuan untuk memanipulasi data menjadi
informasi yang lebih berharga (Han dan Kamber, 2006). Terdapat
beberapa istilah lain yang memiliki makna sama dengan data mining,
yaitu Knowledge Discovery in Database (KDD), ekstraksi pengetahuan
(knowledge extraction), Analisa data/pola (data/pattern analysis),
kecerdasan bisnis (business intelligence) dan data archaeology dan data
dredging (Larose, 2005).
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas
yang dapat dilakukan, yaitu (Larose, 2005):
2.1.1 Prediksi
Proses untuk menemukan pola dari data dengan
menggunakan beberapa variabel untuk memprediksikan variabel
lain yang tidak diketahui jenis atau nilainya.
2.1.2 Deskripsi
Proses untuk menemukan suatu karakteristik penting dari
data dalam suatu basis data.
2.1.3 Klasifikasi
Klasifikasi merupakan suatu proses untuk menemukan
model atau fungsi untuk menggambarkan class atau konsep dari
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

6
suatu data.
2.1.4 Asosiasi
Proses ini digunakan untuk menemukan suatu hubungan
yang terdapat pada nilai atribut dari sekumpulan data.
2.1.5 Estimasi
Estimasi hampir sama dengan klasifikasi, tetapi atribut
lebih ke arah numerik daripada kategori. Model dibangun
menggunakan record lengkap yang menyediakan nilai dari atribut
target sebagai nilai prediksi.
2.1.6 Pengklusteran
Pengklusteran merupakan pengelompokan record,
pengamatan, atau memperhatikan dan membentuk kelas objek-
objek yang memiliki kemiripan. Cluster adalah kumpulan record
yang memiliki kemiripan antara satu dengan yang lainnya dan
memiliki ketidakmiripan dengan records dalam kluster lain.
2.2 Tahapan Data Mining
Dalam data mining terdapat beberapa tahapan, rangkain tahap
tersebut dapat di lihat pada Gambar 2.1.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

7
Gambar 2.1 Data Mining
Sumber: https://andyku.wordpress.com/2008/11/21/konsep-data-mining/
2.2.1 Pre-Processing / Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu
dilakukan proses cleaning pada data. Proses cleaning merupakan
langkah membuang duplikasi data, memeriksa data yang
inkonsisten, dan memperbaiki kesalahan pada data.
2.2.2 Data Selection
Pada jumlah data yang cukup besar seringkali tidak
semuanya terpakai, oleh karena itu perlu dilakukan seleksi data
diantaranya adalah seleksi atribut atau sering dikenal dengan
feature selection yang digunakan untuk mengambil atribut yang
sesuai untuk dianalisis. Seleksi data dari sekumpulan data
operasional perlu dilakukan sebelum tahap penggalian informasi
dalam Knowledge Discovery in Database (KDD) dimulai. Seleksi
atribut atau feature selection bisa dilakukan secara manual
dengan memilih atribut-atribut yang akan digunakan dan bisa
juga dilakukan dengan menggunakan weighted voting untuk
menentukan atribut mana saja yang akan digunakan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

8
2.2.3 Data mining
Data mining adalah proses mencari pola atau informasi
menarik dalam data terpilih dengan menggunakan teknik atau
metode tertentu. Teknik, metode, atau algoritma dalam data
mining sangat bervariasi. Pemilihan metode atau algoritma yang
tepat sangat bergantung pada tujuan dan proses Knowledge
Discovery in Database (KDD) secara keseluruhan.
2.2.4 Evaluation
Pola informasi yang dihasilkan dari proses data mining
perlu ditampilkan dalam bentuk yang mudah dimengerti. Tahap
ini merupakan bagian dari proses Knowledge discovery in
database (KDD) yang disebut evaluation. Tahap ini mencakup
pemeriksaan apakah pola atau informasi yang ditemukan
bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2.3 Klasifikasi
Klasifikasi adalah proses menemukan sebuah model atau fungsi
yang mendeskripsikan dan membedakan data ke dalam kelas-kelas,
dengan tujuan menggunakan model dan melakukan prediksi kelas dari
suatu objek dimana label kelas tersebut tidak diketahui. Model tersebut
berasal dari analisis kumpulan data training (objek data dimana label
kelas sudah diketahui) (Han dan Kamber, 2006).
Dalam klasifikasi terdapat bebrapa algoritma yang dapat
digunakan, yaitu: Naïve Bayes, Decision Tree, Backpropagation
Classification, K-Nearest Neighbor Classifiers, dan Pendekatan Sistem
Fuzzy (Han dan Kamber, 2006).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

9
2.4 Algoritma C4.5
Algoritma C4.5 merupakan salah satu algoritma yang cukup
popular karena mampu melakukan klasifikasi dan sekaligus
menunjukkan hubungan antar atribut. Algoritma C4.5 dapat menangani
data numerik dan diskrit, algoritma ini menggunakan rasio perolehan
(Faruz El Said, 2009).
Dalam algoritma C4.5 pemilihan atribut yang baik adalah atribut
yang bisa memisahkan objek menurut kelasnya. Secara heuristik atribut
yang dipilih adalah atribut yang menghasilkan simpul yang paling
”purest” (paling bersih). Ukuran purity dinyatakan dengan tingkat
impurity, dan untuk menghitungnya, dapat dilakukan dengan
menggunakan konsep Entropy, Entropy menyatakan impurity suatu
kumpulan objek (Larose, 2005)
Sebelum memilih atribut sebagai akar, dilakukan perhitungan
nilai entropi seperti pada persamaan (2.1).
𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆) = ∑ −𝑝𝑖 ∗ log2 𝑝𝑖𝑛𝑖=1 -----------------------------(2.1)
Keterangan:
S : Himpunan kasus
n : Jumlah partisi S
pi : Proporsi dari Si Terhadap S
Untuk pemilihan atribut sebagai akar didasarkan pada nilai
tertinggi dari atribut-atribut yang ada. Dalam menghitung gain
digunakan persamaan seperti pada persamaan (2.2).
𝐺𝑎𝑖𝑛 (𝑆, 𝐴) = 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆) − ∑|𝑆𝑖|
|𝑆|𝑛𝑖=1 ∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖) -----(2.2)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

10
Keterangan:
S = Sampel
A = Atribut
n = Jumlah partisi himpunan atribut A
|Si| = Jumlah sampel pada partisi ke -i
|S| = Jumlah sampel dalam S
Untuk menghitung Gain Ratio diperlukan sebuah term baru yang
disebut SplitIn formation. Atribut dengan nilai Gain Ratio tertinggi
dipilih sebagai atribut test untuk simpul, dengan gain adalah
information gain. Pendekatan ini menerapkan normalisasi pada
information gain dengan menggunakan apa yang disebut sebagai
SplitIn formation. SplitIn formation dapat dihitung dengan
menggunakan persamaan seperti pada persamaan (2.3) (Han dan
Kamber 2006).
𝑆𝑝𝑙𝑖𝑡𝐼𝑛𝑓𝑜(𝑆, 𝐴) = − ∑|𝑆𝑖|
|𝑆|𝑣𝑖=1 × log2 (
|𝑆𝑖|
|𝑆|) -------------------(2.3)
Dimana v adalah subset yang dihasilkan dari pemecahan dengan
menggunakan atribut A yang mempunyai sebanyak v nilai. Dalam
algoritma C4.5 pemilihan atribut dilakukan dengan menggunakan
GainRatio. GainRatio dapat dihitung menggunakan persamaan seperti
pada persamaan (2.4).
𝐺𝑎𝑖𝑛𝑅𝑎𝑡𝑖𝑜(𝑆, 𝐴) =𝐺𝑎𝑖𝑛(𝑆,𝐴)
𝑆𝑝𝑙𝑖𝑡𝐼𝑛𝑓𝑜(𝑆,𝐴) ------------------------------(2.4)
2.5 Evaluasi
2.5.1. Confusion Matrix
Confusion matrix digunakan untuk melihat seberapa besar
akurasi yang dihasilkan dari model klasifikasi yang telah
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

11
dibuat untuk memprediksi dan mengklasifikasi kelas dari
data testing. Confusion Matrix dapat dilihat pada Tabel 2.1.
Tabel 2.1 Confusion Matrix untuk dua kelas
Kelas Aktual
Kelas Prediksi
Positif Negatif
Positif True Positif
(TP)
False Positif
(FP)
Negatif False Negatif
(FN)
True Negatif
(TN)
Nilai akurasi dapat dihitung dengan menggunakan rumus
(2.5) yang didefinisikan sebagai berikut:
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 --------------------------(2.5)
TP : Jumlah kelas yang diprediksi sebagai positif dan kelas
aktualnya adalah positif
TN : Jumlah kelas yang diprediksi sebagai negatif dan kelas
aktualnya adalah negatif
FP : Jumlah kelas yang diprediksi sebagai positif tetapi kelas
aktualnya adalah negatif
FN : Jumlah kelas yang diprediksi sebagai negatif tetapi kelas
aktualnya adalah positif
2.5.2. Cross Validation
Cross Validation digunakan untuk mengevaluasi kinerja
model klasifikasi di mana data dipisahkan menjadi dua subset
yaitu data training dan data testing. Model klasifikasi dilatih
menggunakan data training dan selanjutnya akan di validasi
menggunakan data training. Dalam cross validation dataset
dibagi berdasarkan pada ukuran k-folds cross validation.
Misalnya model dilatih menggunakan 3-folds, maka dataset
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

12
dibagi menjadi 3 bagian dengan ukuran yang sama. Dari 3 bagian
tersebut, 2 bagian digunakan sebagai data training dan 1 bagian
digunakan sebagai data testing. Cross Validation dapat dilihat
pada Gambar 2.2.
Gambar 2.2 Cross Validation
2.6 Pemantauan Status Gizi Balita (PSG Balita)
Pemantauan Status Gizi (PSG) merupakan kegiatan pemantauan
perkembangan status gizi balita yang dilaksanakan setiap tahun secara
berkesinambungan untuk memberikan gambaran tentang kondisi status
gizi balita (Kementerian Kesehatan, 2018).
Pelaksanaan PSG bertujuan untuk mengawal upaya perbaikan
gizi masyarakat agar lebih efektif dan efisien, melalui monitoring
perubahan status gizi maupun kinerja program dari waktu ke waktu,
sehingga kita dapat dengan tepat menetapkan upaya tindakan,
perubahan formulasi kebijakan dan perencanaan program (Kementerian
Kesehatan, 2018). Status gizi balita dinilai berdasarkan 3 indeks, yaitu:
1. Berat Badan Menurut Umur (BB/U) adalah berat badan
balita yang dicapai pada umur tertentu.
2. Tinggi Badan Menurut Umur (TB/U) adalah tinggi badan
balita yang dicapai pada umur tertentu.
3. Berat Badan Menurut Tinggi Badan (BB/TB) adalah berat
badan balita yang dibandingkan berdasarkan tinggi badan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

13
BAB III
METODE PENELITIAN
Dalam metodologi penelitian ini akan dibahas lebih rinci mengenai
data dan proses klasifikasi status gizi balita menggunakan decision tree c4.5.
3.1 Peralatan Penelitian
Implementasi pada penelitian ini menggunakan aplikasi yang
dibangun oleh penulis menggunakan bahasa pemrograman python.
Implementasi ini dilakukan dengan menggunakan komputer dengan
spesifikasi sebagai berikut:
1. Perangkat keras
a. Prosesor : Intel Core I3-7020U
b. RAM : 4,00 GB
c. HDD : 500 GB
2. Perangkat Lunak
a. Windows 10 Home 64 Bit Operating System
b. Microsoft Word 2016
c. Microsoft Excel 2016
d. Visual Studio Code
e. Qt Designer
3.2 Bahasa Pemrograman Python
Bahasa pemrograman Python adalah bahasa pemrograman yang
interpreted, high-level, dan general-purpose. Tidak seperti bahasa
pemrograman lain yang susah untuk dibaca dan dipahami, python lebih
menekankan pada keterbacaan kode agar lebih mudah untuk memahami
sintak.
Bahasa pemrograman python sangat powerfull untuk digunakan,
yang membuat python sangat powerfull karena mudah digunakan dan
juga terdapat banyak library yang bisa digunakan. Dalam data mining
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

14
terdapat library seperti Scrapy, BeautifulSoup, Pandas, Numpy, dll.
Dalam pembuatan machine learning terdapat beberapa library seperti
Keras, TensorFlow, ScikitLearn, PyTorch, dll. Dalam pembuatan
webapps terdapat framework yang sangat popular seperti Django dan
Flask.
Salah satu tools dalam data mining dan machine learning yang
dibangun menggunakan python adalah Orange.
3.3 Data
Data yang digunakan pada penelitian ini merupakan data
Pemantauan Status Gizi (PSG) Balita yang diperoleh dari Puskesmas
Kebong, Kecamatan Kelam Permai, Kabupaten Sintang, Kalimantan
Barat tahun 2017. Data disajikan dalam format .xls dengan jumlah data
sebanyak 853. Contoh data dapat dilihat pada Tabel 3.2.
Data PSG Balita ini mempunyai tiga kelas, yaitu kelas berat
badan menurut umur BB/U, tinggi badan menurut umur TB/U, dan
berat badan terhadap tinggi badan BB/TB. Label yang digunakan tiap
kelas dapat dilihat pada Tabel 3.1.
Tabel 3.1 Kelas dan Label
No Kelas Label
1 BB/U Lebih, Baik, Kurang, Buruk
2 TB/U Tinggi, Normal, Pendek, Sangat Pendek
3 BB/TB Gemuk, Normal, Kurus, Sangat Kurus
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

15
Tabel 3.2 Contoh Data dan Keterangan Atribut
No Nama Atribut Keterangan Contoh
1 Nama Nama balita Gisella
2 Tanggal lahir Tgl lahir berupa tanggal, bulan, dan tahun 20/06/2016
3 Js.L/P
Jenis kelamin balita
1 = Laki-laki
2 = Perempuan 1/2
4 Berat B. Berat badan balita 10,5
5 PB / TB Panjang badan/tinggi badan 95
6 Posisi diukur
Penentuan posisi diukur
3 = Diukur telentang
4 = Diukur berdiri 3/4
7 Umur Umur balita 11
8 Proses Perhitungan Umur Untuk menentukan umur balita 37
9 Konversi TB/PB Penentuan TB/PB dari posisi diukur 81,7
10 Klp Umur
pengelompokan umur
1= Umur <24
2 = Umur >=24 1/2
11 Kode Digunakan untuk menentukan standar gizi BB/U 130
12 Kode1 Digunakan untuk menentukan standar gizi PB/U 137
13 Kode2 Digunakan untuk menentukan standar gizi BB/PB 22090
14
Standar Gizi Buruk
BB/U Penentuan standar gizi buruk BB/U 5,3
15 Standar Gizi Baik BB/U Penentuan standar gizi baik BB/U 6 dan 9,3
16
Standar Pendek PB/U
atau TB/U Penentuan standar pendek TB/U 55,3
17
Standar Normal PB/U
atau TB/U Penentuan standar normal TB/U 57,3 dan 65,5
18
Standar Kurus BB/PB
atau BB/PB Penentuan standar kurus BB/PB 4,4
19
Standar Normal BB/PB
atau BB/PB Penentuan standar normal BB/PB 4,7 dan 6,6
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

16
3.4 Alur Penelitian
Langkah-langkah peneltian digambarkan pada skema penelitian yang
digambarkan pada gambar 3.1 berikut.
Gambar 3.1 Alur penelitian
3.4.1. Data Cleaning
Pada penelitian ini data cleaning dilakukan secara manual
dengan menggunakan Excel 2016. Terdapat 5 data yang tidak
lengkap, 3 diantaranya tidak mempunyai label BB/TB, 1 tidak
mempunyai nilai PB/TB, dan 1 lainnya tidak mempunyai nilai
konversi TB/PB. Dengan demikian missing data sebanyak
0,585% dari total data dihilangkan dari dataset.
3.4.2. Seleksi Data
Pada tahap ini seleksi data dilakukan untuk menentukan
atribut yang digunakan untuk klasifikasi (feature selection).
Pemilihan atribut dilakukan secara manual dan dengan
menggunakan weighted voting information gain. Dalam
pemilihan atribut secara manual dipilih atribut Js.L/P, Berat B.,
PB/TB, dan Umur. Atribut tersebut dipilih berdasarkan
rekomendasi dari puskesmas, mereka merekomendasikan atribut
tersebut karena nilai dari masing-masing atribut murni didapatkan
langsung dari pengambilan data terhadap balita, bukan dari hasil
perhitungan lainya. Pada Tabel 3.3 dapat dilihat atribut-atribut
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

17
yang digunakan untuk tiap kelas.
Sementara itu untuk pemilihan atribut menggunakan
information gain penulis menggunakan fitur weighted voting by
information gain yang ada pada aplikasi Rapid Miner Studio versi
9.7. Proses voting ini dilakukan terhadap 3 kelas, yaitu BB/U,
PB/U, dan BB/PB. Untuk tiap atribut pada masing-masing kelas
akan di seleksi. Atribut-atribut yang digunakan adalah atribut
yang tidak bergantung pada atribut lainya, atribut yang
bergantung dari atribut lainnya atau dari turunan atribut lain
dihilangkan dari dataset. Atribut yang digunakan adalah Js.L/P,
Umur, Berat B., PB/TB, Posisi diukur, Tahun Lahir, Bulan Lahir,
dan Tanggal Lahir.
Tabel 3.3 Atribut yang digunakan tiap kelas
No Kelas Atribut Label
1 BB/U Js.L/P, Berat B.,
Umur
Lebih, Baik, Kurang,
Buruk
2 TB/U Js.L/P, PB/TB, Umur Tinggi, Normal,
Pendek, Sangat Pendek
3 BB/PB Js.L/P, Berat B.,
PB/TB, Umur
Gemuk, Normal,
Kurus, Sangat Kurus
3.4.3. Pembagian Data
Setelah data diseleksi maka dilakukan pembagian dataset,
dataset dibagi menjadi data testing dan data training
menggunakan k-folds validation. Jumlah k dipilih oleh user
dimana nilai k adalah 3, 5, 7, dan 9 folds menggunakan masukan
berupa dropdown. Jika nilai k = 3 maka data dibagi menjadi 3
bagian, 2 bagian digunakan untuk data training dan 1 bagian
untuk data testing, dan begitu juga untuk pembagian nilai folds =
5, 7, dan 9 folds.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

18
3.4.4. Pemisahan Data
Pada tahap ini dataset hasil pembagian menggunakan k-
folds cross validation dipisahkan menjadi 2 bagian, bagian
pertama berisi atribut-atribut yang digunakan dan bagian kedua
berisi label, dimana label yang digunakan dibagi menjadi tiga
yaitu, BB/U, PB/U, dan BB/PB. Untuk atribut yang di-voting
berdasarkan information gain kita dapat memilih atribut yang
nantinya digunakan untuk klasifikasi. Kita memilih atribut
dengan memberikan centang pada checkbox untuk atribut yang
akan digunakan.
3.4.5. Modeling Decision Tree C4.5
Setelah dataset dibagi berdasarkan K-Folds maka tiap folds
di-modeling menggunakan metode decision tree c4.5, sehingga
terdapat n model untuk tiap n folds. Metode decision tree c4.5
mengklasifikasikan data dengan cara mencari nilai Entropy,
Information Gain, Split Info, dan Gain Ratio. Pembentukan
pohon diawali dengan mencari nilai Gain Ratio tertinggi untuk
dijadikan root node, selanjutnya untuk leaf node dilakukan secara
rekursif sampai decision tree terbentuk.
Berikut adalah contoh langkah pembentukan tree secara
manual:
1. Siapkan data yang akan digunakan untuk pembentukan model
decision tree c4.5. Disini penulis menggunakan 9 data untuk
klasifikasi kelas BB/U dengan atribut yang digunakan adalah
Js,L/P, Berat B., dan Umur. Data dapat dilihat pada Tabel 3.4.
2. Memisahkan data menjadi data training seperti pada Tabel 3.5
dan data testing seperti pada Tabel 3.6, menggunakan
confusion matrix dengan jumlah 3 folds.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

19
Tabel 3.4 Dataset
Js.L/P Berat B. Umur BB/U
1 8 9 Baik
1 7,8 8 Baik
1 10,1 8 Baik
2 6,1 6 Baik
2 4,6 6 Buruk
2 10 44 Buruk
2 7,3 27 Buruk
2 8,9 17 Buruk
1 8,1 26 Buruk
Tabel 3.5 Data Training
Js.L/P Berat B. Umur BB/U
1 8 9 Baik
1 7,8 8 Baik
1 10,1 8 Baik
2 6,1 6 Baik
2 4,6 6 Buruk
2 10 44 Buruk
Tabel 3.6 Data Testing
Js.L/P Berat B. Umur BB/U
2 7,3 27 Buruk
2 8,9 17 Buruk
1 8,1 26 Buruk
3. Menghitung entropy dengan rumus 2.1, information gain
dengan rumus 2.2, split info dengan rumus 2.3, dan gain ratio
dengan rumus 2.4 untuk tiap atribut. Lalu cari kandidat root
node dengan mencari nilai information gain tertinggi untuk
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
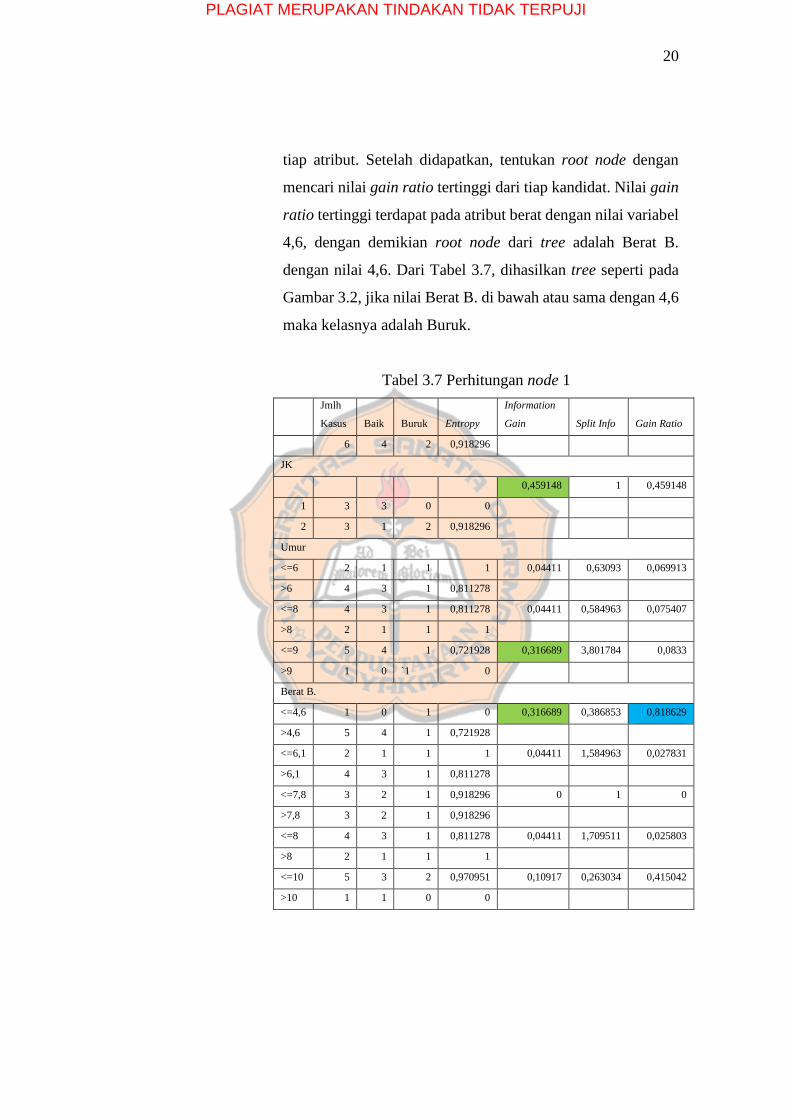
20
tiap atribut. Setelah didapatkan, tentukan root node dengan
mencari nilai gain ratio tertinggi dari tiap kandidat. Nilai gain
ratio tertinggi terdapat pada atribut berat dengan nilai variabel
4,6, dengan demikian root node dari tree adalah Berat B.
dengan nilai 4,6. Dari Tabel 3.7, dihasilkan tree seperti pada
Gambar 3.2, jika nilai Berat B. di bawah atau sama dengan 4,6
maka kelasnya adalah Buruk.
Tabel 3.7 Perhitungan node 1
Jmlh
Kasus Baik Buruk Entropy
Information
Gain Split Info Gain Ratio
6 4 2 0,918296
JK
0,459148 1 0,459148
1 3 3 0 0
2 3 1 2 0,918296
Umur
<=6 2 1 1 1 0,04411 0,63093 0,069913
>6 4 3 1 0,811278
<=8 4 3 1 0,811278 0,04411 0,584963 0,075407
>8 2 1 1 1
<=9 5 4 1 0,721928 0,316689 3,801784 0,0833
>9 1 0 `1 0
Berat B.
<=4,6 1 0 1 0 0,316689 0,386853 0,818629
>4,6 5 4 1 0,721928
<=6,1 2 1 1 1 0,04411 1,584963 0,027831
>6,1 4 3 1 0,811278
<=7,8 3 2 1 0,918296 0 1 0
>7,8 3 2 1 0,918296
<=8 4 3 1 0,811278 0,04411 1,709511 0,025803
>8 2 1 1 1
<=10 5 3 2 0,970951 0,10917 0,263034 0,415042
>10 1 1 0 0
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

21
Gambar 3.2 Root Node
4. Setelah mendapat root node, selanjutnya kita melakukan
pencarian leaf node. Sebelum mencari leaf node, data dengan
nilai Berat B. 4,6 dihapus/dihilangkan dari dataset. Lihat Tabel
3.8.
Tabel 3.8 Tabel dataset pada node 2
Js.L/P Berat B. Umur BB/U
1 8 9 Baik
1 7,8 8 Baik
1 10,1 8 Baik
2 6,1 6 Baik
2 4,6 6 Buruk
2 10 44 Buruk
Setelah dihilangkan kita lanjutkan dengan mencari leaf node,
pencarian leaf node dilakukan dengan mencari nilai information
gain tertinggi. Contoh perhitungan dapat dilihat pada Tabel 3.9.
Nilai information gain tertinggi terdapat pada atribut Umur
dengan nilai 9, dengan demikian leaf node adalah Umur, jika
umur di bawah 9 maka kelasnya adalah Baik dan jika di atas 9
maka kelasnya adalah Buruk. Tree yang dihasilkan dapat dilihat
pada Gambar 3.2.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

22
Tabel 3.9 Perhitungan node 2
Jmlh
Kasus Baik Buruk Entropy
Information
Gain
5 4 1 0,721928
JK
0,321928
1 3 3 0 0
2 2 1 1 1
Umur
<=6 1 1 0 0 0,072906
>6 4 3 1 0,811278
<=8 3 3 0 0 0,321928
>8 2 1 1 1
<=9 4 4 0 0 0,721928
>9 1 0 1 0
Berat B.
<=6,1 1 1 0 0 0,072906
>6,6 4 3 1 0,811278
<=7,8 2 2 0 0 0,170951
>7,8 3 2 1 0,918296
<=8 3 3 0 0 0,321928
>8 2 1 1 1
<=10 4 3 1 0,811278 0,072906
>10 1 1 0 0
Gambar 3.3 Leaf Node
5. Dengan model yang sudah dibuat Gambar 3.3, dari data testing
pada Tabel 3.5, kita bisa menguji atau mengklasifikasikan data
training pada Tabel 3.6.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

23
Pada penelitian ini dilakukan 2 tahap, yaitu tahap pertama
dilakukan untuk atribut yang di pilih secara manual dan tahap
kedua untuk atribut yang di pilih berdasarkan nilai information
gain.
3.4.6. Pengujian
Pada penelitian ini dilakukan 2 tahap pengujian, tahap
pertama dilakukan untuk atribut yang dipilih secara manual dan
tahap kedua untuk atribut yang di seleksi berdasarkan nilai
information gain. Tiap tahap dilakukan dengan menggunakan 3,
5, 7, dan 9 folds. Tiap percobaan dilakukan untuk tiap kelas, yaitu
kelas BB/U, PB/U, dan BB/PB. Percobaan dapat dilihat pada
Tabel 3.10.
Tabel 3.10 Percobaan Decision Tree C4.5 untuk atribut yang
dipilih manual
Percobaan Jumlah Folds
Percobaan ke-1 3-folds
Percobaan ke-2 5-folds
Percobaan ke-3 7-folds
Percobaan ke-4 9-folds
Untuk atribut yang di-voting berdasarkan information gain
dilakukan dengan penyeleksian tiap atribut. Atribut diseleksi
dengan menghapus atau menghilangkan atribut yang mempunyai
nilai information gain terkecil. Penyeleksian atribut dilakukan
untuk tiap kelas BB/U, PB/U, dan BB/PB. Percobaan dapat
dilihat pada Tabel 3.11.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

24
Tabel 3.11 Percobaan Decision Tree C4.5 untuk atribut yang di-
voting
Percobaan Jumlah Atribut Jumlah Folds
Percobaan ke-1 8 Atribut 3-folds
5-folds
7-folds
9-folds
Percobaan ke-2 7 Atribut 3-folds
5-folds
7-folds
9-folds
… … …
Percobaan ke-5 3 Atribut 3-folds
5-folds
7-folds
9-folds
3.4.7. Akurasi
Setelah proses modeling selanjutnya adalah pengujian
akurasi, pengujian akurasi dilakukan dengan menggunakan
confusion matrix. Akurasi didapatkan dengan menjumlahkan data
yang diprediksi benar dibagi dengan jumlah keseluruhan data
prediksi, lalu dikali 100%. Akurasi didapatkan dari tiap model
dalam n folds, kemudian untuk mendapatkan rata-rata akurasi,
nilai akurasi tiap folds dijumlahkan dan dibagi dengan n.
Misalnya jika menggunakan 3 folds, maka akan terdapat 3 model
klasifikasi, lalu tiap model memiliki akurasinya dan untuk
mendapatkan rata-rata akurasi maka ketiga hasil akurasi tersebut
dijumlahkan dan dibagi 3. Sehingga didapatkan rata-rata akurasi
untuk 3 folds.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

25
3.5 Perancangan GUI
3.5.1. Halaman Awal
Pada halaman awal ditampilkan nama aplikasi “Cek Gizi
Balita”, lalu terdapat judul skripsi “Klasifikasi Gizi Balita
Menggunakan Decision Tree C4.5”. Pada halaman ini terdapat
tombol “Start”, tombol ini digunakan untuk memulai aplikasi.
Ketika kita mengklik tombol “Start” maka kita akan diarahkan
pada halaman klasifikasi gizi. Halaman awal dapat dilihat pada
Gambar 3.4.
Gambar 3.4 Halaman Awal
3.5.2. Halaman Klasifikasi Gizi
Pada halaman ini terdapat form untuk memasukkan nama,
umur, jenis kelamin, berat badan, dan tinggi badan. Hasil dari
masukan tersebut nantinya akan diklasifikan untuk menentukan
status gizi dengan mengklik tombol “Cek Gizi”. Maka status gizi
akan ditampilkan pada jendela kecil di sebelah kanan, status gizi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

26
yang ditampilkan yaitu status gizi berdasarkan BB/U, PB/U, dan
BB/PB. Kita juga bisa mengklasifikasikan ketiga status gizi
secara terpisah dengan memilih menu bar File -> Cek Gizi ->
Lalu pilih klasifikasi yang diinginkan. Lalu ada tombol “Setting”
yang digunakan untuk mengatur jumlah folds, dan mengetes
model. Halaman Klasifikasi Gizi dapat dilihat pada Gambar 3.5.
Gambar 3.5 Halaman klasifikasi gizi
3.5.3. Halaman Setting
Pada halaman setting terdapat sebuah tombol “Open File”
yang berfungsi untuk membuka file yang digunakan untuk
klasifikasi (PSG Balita 2017). Lalu terdapat sebuah dropdown
yang digunakan untuk memilih jumlah folds, jumlah folds yang
dapat dipilih yaitu 3, 5, 7, dan 9 folds. Lalu tombol “Test”
digunakan untuk mengetes model pada jumlah folds yang sudah
dipilih, sistem akan menampilkan jumlah folds dan rata-rata
akurasi untuk tiap klasifikasi pada jendela sebelah kanan.
Selanjutnya ada tombol “Print Tree” yang digunakan untuk mem-
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

27
print tree ke format *.PNG, dan tombol “Cek Data” yang
digunakan untuk kembali ke halaman klasifikasi gizi. Halaman
Setting dapat dilihat pada Gambar 3.6.
Gambar 3.6 Halaman Setting
3.5.4. Halaman Feature Selection
Halaman ini dapat diakses melalui menu bar Setting-
>Feature Selection. Pada halaman ini kita dapat memilih atribut
yang ingin digunakan untuk klasifikasi, lalu kita juga bisa
memilih kelas dan jumlah folds yang ingin digunakan. Pada
jendela sebelah kanan sistem akan menampilkan jumlah atribut
yang dipilih, kelas yang digunakan, jumlah folds yang pakai, dan
rata-rata akurasi. Tombol “Cek Model” digunakan untuk
mengecek model klasifikasi dan tombol “Kembali” digunakan
untuk kembali ke halaman klasifikasi gizi. Halaman Feature
Selection dapat dilihat pada Gambar 3.7.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

28
Gambar 3.7 Halaman feature selection
3.5.5. Halaman Dataset
Pada halaman dataset di tampilkan data PSG Balita 2017,
data ditampilkan dalam bentuk tabel. Tombol “Kembali”
digunakan untuk kembali ke halaman klasifikasi gizi. Halaman
Dataset dapat dilihat pada Gambar 3.8.
3.5.6. Halaman View Tree
Pada halaman ini kita dapat melihat tree yang dibentuk,
pada pojok kiri atas terdapat informasi banyak nodes dan banyak
leaves. Halaman ini dapat diakses dengan memilih menu bar file
-> view tree -> pilih kelas yang akan ditampilkan (BB/U, PB/U,
atau BB/PB). Halaman ini di-import dari orange widgets library
yang bernama QWTreeGraph. Halaman ini dapat dilihat pada
Gambar 3.9.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

29
Gambar 3.8 Halaman Dataset
Gambar 3.9 Halaman view tree
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
30
BAB IV
IMPLEMENTASI DAN ANALISIS
4.1. Implementasi
4.1.1. Preprocessing
Data PSG Balita yang didapatkan dari Puskesmas Kebong,
Kecamatan Kelam Permai, Kabupaten Sintang, Kalimantan Barat
tahun 2017 dilakukan proses cleaning dengan menggunakan
excel secara manual. Selanjutnya dilakukan proses selection,
proses ini dilakukan dengan memilih atribut secara manual,
atribut yang dipilih dapat dilihat pada Tabel 3.3, lalu dilakukan
dengan pemilihan atribut berdasarkan voting information gain,
untuk proses voting digunakan software Rapid Miner Studio.
Hasil voting untuk kelas BB/U dapat dilihat pada Tabel 3.4, untuk
kelas PB/U dapat dilihat pada Tabel 3.5, dan untuk kelas BB/PB
dapat dilihat pada Tabel 3.6
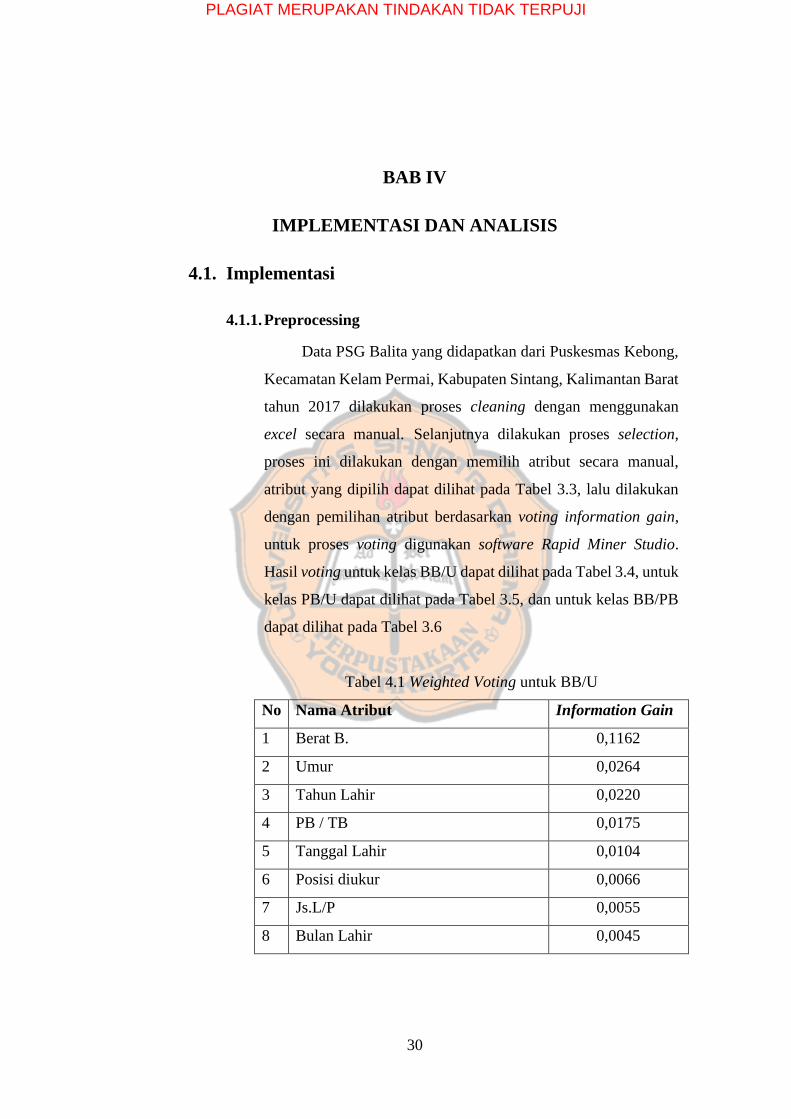
Tabel 4.1 Weighted Voting untuk BB/U
No Nama Atribut Information Gain
1 Berat B. 0,1162
2 Umur 0,0264
3 Tahun Lahir 0,0220
4 PB / TB 0,0175
5 Tanggal Lahir 0,0104
6 Posisi diukur 0,0066
7 Js.L/P 0,0055
8 Bulan Lahir 0,0045
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

31
Tabel 4.2 Weighted Voting untuk PB/U
No Nama Atribut Information Gain
1 PB / TB 0,0451
2 Umur 0,0387
3 Tahun Lahir 0,0372
4 Berat B. 0,0302
5 Posisi diukur 0,0162
6 Tanggal Lahir 0,0114
7 Bulan Lahir 0,0052
8 Js.L/P 0,0039
Tabel 4.3 Weighted Voting untuk BB/PB
No Nama Atribut Information gain
1 Berat B. 0,1110
2 PB / TB 0,0256
3 Umur 0,0119
4 Tahun Lahir 0,0100
5 Js.L/P 0,0060
6 Posisi diukur 0,0054
7 Tanggal Lahir 0,0045
8 Bulan Lahir 0,0045
4.1.2. Modeling
Pada proses data yang telah di bagi menjadi atribut dan
label di-modeling menggunakan decision tree c4.5. Modeling
dilakukan sebanyak n kali sesuai jumlah folds. Model c45 di-
import dari orange library dan menggunakan modul c45 yang di-
import dari github. Disini penulis menggunakan modul c45 dari
github untuk modeling dan menggunakan orange library untuk
menampilkan tree ke halaman view tree. Lihat Program 4.1.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

32
from Orange.classification.tree import TreeLearner
from c45 import C45
Program 4.1 Import Klasifikasi
Setelah kedua library di-import kita memisahkan data training
dan data testing untuk tiap folds. Lihat Program 4.2
X_train, y_train = attr.iloc[train_index,:], label.iloc[train_i ndex]
X_test, y_test = attr.iloc[test_index,:], label.iloc[test _index]
Program 4.2 Pemisahan data training dan testing tiap folds
Setelah dataset dipisah menjadi data training dan data testing
dilakukan pemodelan decision tree c4.5. Lihat Program 4.3
clf = C45()
clf.fit(X_train, y_train)
Program 4.3 Membangun model klasifikasi
Setelah model terbentuk maka selanjutnya adalah
mengklasifikasikan data testing dengan model yang telah
dibentuk sebelumnya. Lihat Program 4.4.
y_predict = clf.predict(X_test)
Program 4.4 Klasifikasi data testing
4.1.3. Evaluasi
Proses evaluasi dilakukan dengan menggunakan cross
validation, data dibagi menjadi n-folds menggunakan library dari
ScikitLearn. Lihat Program 4.5.
from sklearn.model_selection import KFolds, cross_val_score
Program 4.5 Import Cross Validation
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
33
Pembagian data dilakukan dengan mengisi nilai n untuk
parameter n_split. Lihat Program. Lihat Program 4.6.
kf = KFolds(n_splits=n)
Program 4.6 Input Folds
Untuk menghitung akurasi penulis menggunakan confusion
matrix dari library ScikitLearn. Dengan menggunakan fungsi ini
kita memasukkan 3 parameter yaitu y_true (label data testing),
y_pred (label hasil prediksi dari y_train), dan labels(label). Lihat
Program 4.7.
from sklearn.metrics import confusion_matrix
a = confusion_matrix(y_test, y_predict, labels=categories)
Program 4.7 Import dan membangun confusion matrix
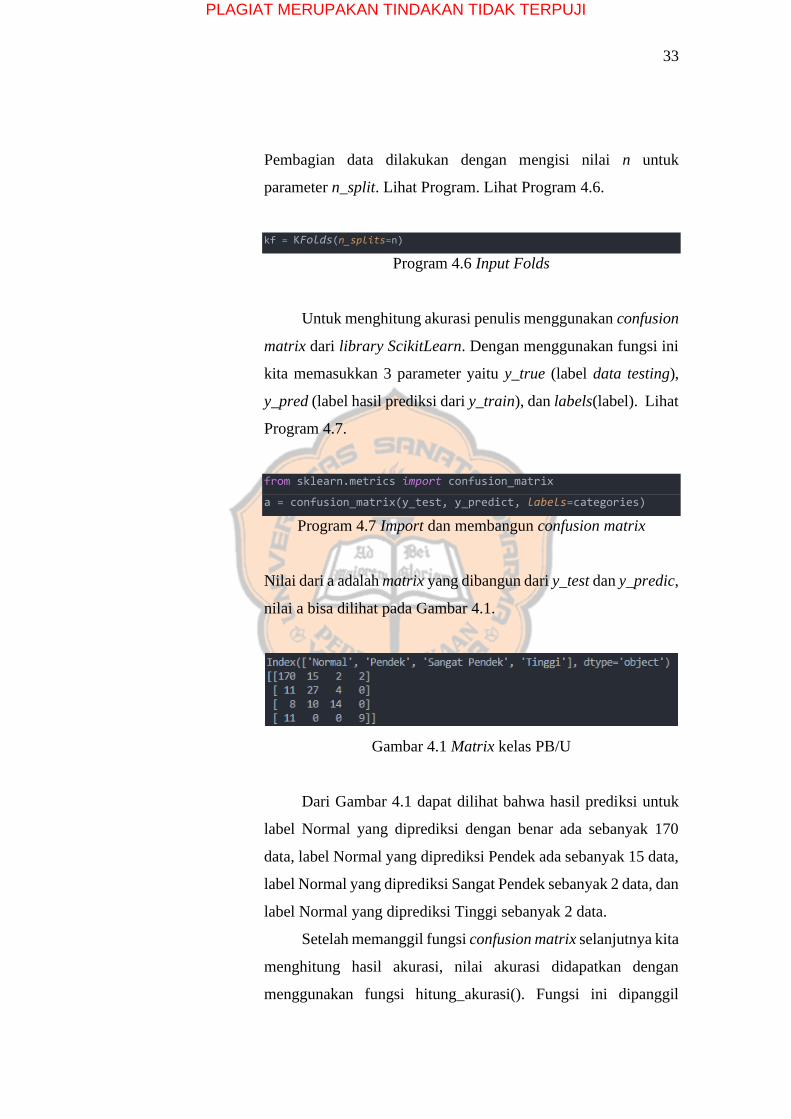
Nilai dari a adalah matrix yang dibangun dari y_test dan y_predic,
nilai a bisa dilihat pada Gambar 4.1.
Gambar 4.1 Matrix kelas PB/U
Dari Gambar 4.1 dapat dilihat bahwa hasil prediksi untuk
label Normal yang diprediksi dengan benar ada sebanyak 170
data, label Normal yang diprediksi Pendek ada sebanyak 15 data,
label Normal yang diprediksi Sangat Pendek sebanyak 2 data, dan
label Normal yang diprediksi Tinggi sebanyak 2 data.
Setelah memanggil fungsi confusion matrix selanjutnya kita
menghitung hasil akurasi, nilai akurasi didapatkan dengan
menggunakan fungsi hitung_akurasi(). Fungsi ini dipanggil
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

34
dengan memasukkan a (confusion matrix) sebagai parameter.
Lihat Program 4.8.
akurasi = hitung_akurasi(a)
def hitung_akurasi(confusion_matrix):
jmlh_data = 0
jmlh_benar = 0
pjg_matrix = len(confusion_matrix)
for i in range(pjg_matrix):
for j in range(pjg_matrix):
jmlh_data += confusion_matrix[i][j]
if i == j:
jmlh_benar += confusion_matrix[i][j]
return (jmlh_benar/jmlh_data)*100
Program 4.8 Menghitung akurasi
Fungsi hitung_akurasi mengembalikan nilai akurasi, nilai
akurasi di sini adalah jumlah benar dibagi jumlah data kemudian
di kali 100. Untuk menghitung akurasi juga bisa dilakukan
dengan memanggil fungsi accuracy_score yang juga merupakan
fungsi yang terdapat dalam library ScikitLearn.
Setelah nilai akurasi didapatkan selanjutnya mencari nilai rata-
rata akurasi, rata-rata akurasi didapatkan dengan menjumlahkan
akurasi tiap n model kemudian dibagi dengan n. Lihat Program
4.9.
sum_akurasi += akurasi
rata_akurasi = sum_akurasi/n
Program 4.9 Rata-rata akurasi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

35
4.2. Pengujian Menggunakan Dataset
4.2.1. Pengujian Menggunakan Manual Attribute Selection
Atribut yang telah dipilih secara manual disini diuji untuk
melihat seberapa besar akurasinya, pengujian dilakukan dengan
menggunakan 3, 5, 7, dan 9 folds. Pengujian ini dilakukan untuk
tiap kelas. Berikut ini adalah hasil uji terhadap atribut yang dipilih
secara manual.
Tabel 4.4 Hasil percobaan BB/U
BB/U
Percobaan
Jumlah
folds
Avg.
Akurasi
1 3 89,52
2 5 90,93
3 7 90,1
4 9 90,1
Pada Tabel 4.4 dapat dilihat bahwa rata-rata akurasi
tertinggi untuk kelas BB/U adalah 90,93% dengan menggunakan
5 folds dan rata-rata akurasi terendah 89,52% dengan
menggunakan 3 folds.
Pada Tabel 4.5 rata-rata akurasi tertinggi untuk kelas PB/U
adalah 78,33% dengan menggunakan 7 folds dan akurasi terendah
75,27% dengan menggunakan 3 folds.
Pada Tabel 4.6 rata-rata akurasi tertinggi untuk kelas
BB/PB adalah 84,45% dengan menggunakan 7 folds dan rata-rata
akurasi terendah adalah 83,27% dengan menggunakan 3 dan 5
folds.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

36
Tabel 4.5 Hasil prcobaan PB/U
PB/U
Percobaan
Jumlah
folds
Avg.
Akurasi
1 3 75,27
2 5 75,96
3 7 78,32
4 9 77,03
Tabel 4.6 Hasil percobaan BB/PB
BB/PB
Percobaan
Jumlah
folds
Avg.
Akurasi
1 3 83,27
2 5 83,27
3 7 84,45
4 9 84,34
4.2.2. Pengujian Menggunakan Voting Attribute Selection
Pengujian ini dilakukan dengan menguji model decision
tree c45 dengan menggunakan atribut yang telah di voting, atribut
keseluruhan berjumlah 8 atribut. Berdasarkan Weighted Voting by
Information Gain Rapid Miner Studio, tiap kelas memiliki urutan
rangking yang berbeda. Percobaan dilakukan untuk tiap kelas,
dimana tiap kelas akan di seleksi atributnya dengan
mengeliminasi atribut satu-persatu dari rangking terbawah.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

37
Penyeleksian atribut dapat dilakukan pada halaman feature
selection. Pengujian ini dilakukan dengan tujuan mencari rata-
rata akurasi tiap folds untuk tiap atribut yang digunakan.
Gambar 4.2 Grafik rata-rata akurasi BB/U
Pada Gambar 4.2 dapat dilihat bahwa untuk kelas BB/U
penyeleksian atribut dari 8 hingga 3 atribut mengalami
peningkatan rata-rata akurasi untuk tiap folds. Rata-rata akurasi
tertinggi adalah 88,69% yaitu ketika menggunakan 7 folds dan 3
atribut. Nilai akurasi paling rendah adalah 81,98% yaitu dengan
menggunakan 3 folds dan 8 atribut.
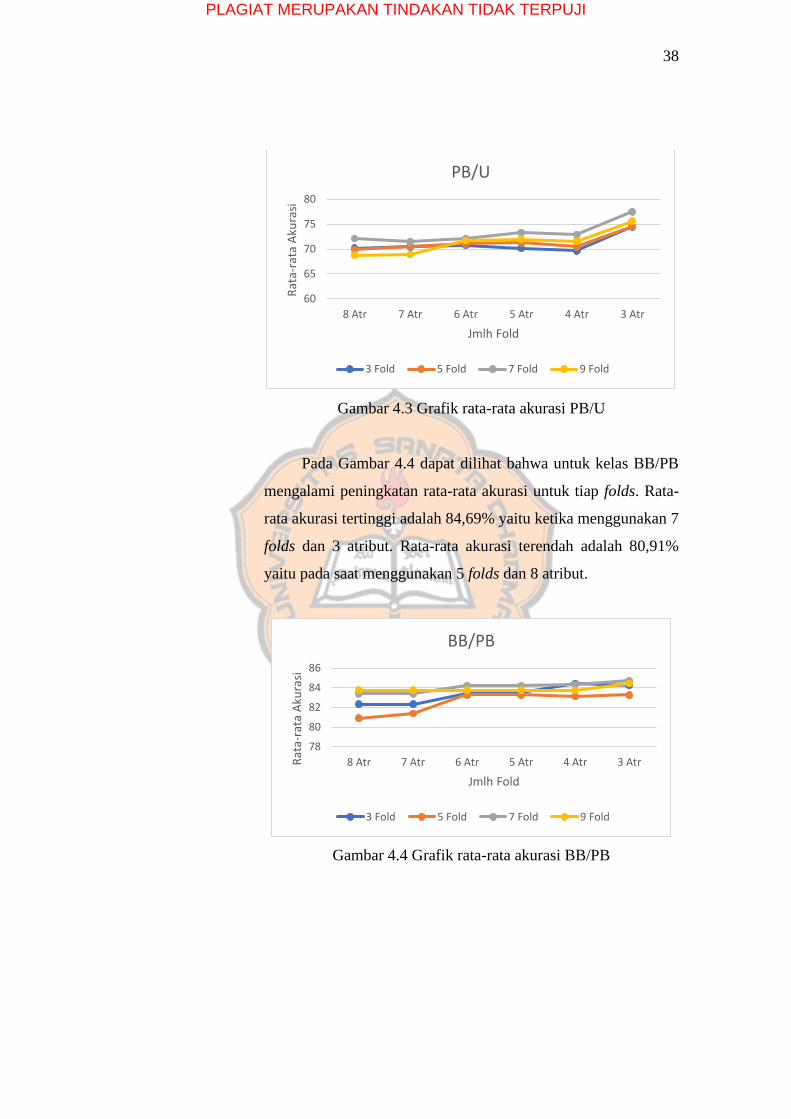
Pada Gambar 4.3 dapat dilihat bahwa untuk kelas PB/U
mengalami peningkatan rata-rata akurasi untuk tiap folds. Nilai
rata-rata akurasi tertinggi adalah 77,5% pada saat menggunakan
7 folds dan 3 atribut. Nilai rata-rata akurasi terendah adalah
68,78% pada saat menggunakan 9 folds dan 8 atribut.
78
80
82
84
86
88
90
8 Atr 7 Atr 6 Atr 5 Atr 4 Atr 3 Atr
Rat
a-ra
ta A
kura
si
Jmlh Fold
BB/U
3 Fold 5 Fold 7 Fold 9 Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
38
Gambar 4.3 Grafik rata-rata akurasi PB/U
Pada Gambar 4.4 dapat dilihat bahwa untuk kelas BB/PB
mengalami peningkatan rata-rata akurasi untuk tiap folds. Rata-
rata akurasi tertinggi adalah 84,69% yaitu ketika menggunakan 7
folds dan 3 atribut. Rata-rata akurasi terendah adalah 80,91%
yaitu pada saat menggunakan 5 folds dan 8 atribut.
Gambar 4.4 Grafik rata-rata akurasi BB/PB
60
65
70
75
80
8 Atr 7 Atr 6 Atr 5 Atr 4 Atr 3 Atr
Rat
a-ra
ta A
kura
si
Jmlh Fold
PB/U
3 Fold 5 Fold 7 Fold 9 Fold
78
80
82
84
86
8 Atr 7 Atr 6 Atr 5 Atr 4 Atr 3 AtrRat
a-ra
ta A
kura
si
Jmlh Fold
BB/PB
3 Fold 5 Fold 7 Fold 9 Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

39
4.3. Perbandingan Hasil Pengujian
4.3.1. BB/U
Pada klasifikasi kelas BB/U dengan menggunakan atribut
yang dipilih secara manual yaitu Js.L/P, Berat B., dan Umur
memiliki nilai rata-rata akurasi tertinggi sebesar 90,93% dengan
menggunakan 5 folds dan rata-rata akurasi terendah 89,52%
dengan menggunakan 3 folds, lihat Tabel 4.4. Sementara itu untuk
atribut yang di-voting hingga tersisa 3 atribut diantaranya Berat
B., Umur, dan Tahun Lahir memiliki nilai rata-rata akurasi
tertinggi sebesar 86,92% menggunakan 9 folds dan terendah
sebesar 85,63% menggunakan 3 folds, lihat Gambar 4.1.
4.3.2. PB/U
Pada klasifikasi kelas PB/U dengan menggunakan atribut
yang dipilih secara manual yaitu Js.L/P, PB/TB, dan Umur
memiliki nilai rata-rata akurasi tertinggi sebesar 78,33% dengan
menggunakan 7 folds dan akurasi terendah 75,27% dengan
menggunakan 3 folds, lihat Tabel 4.5. Sementara itu untuk atribut
yang di-voting hingga tersisa 3 atribut diantaranya PB/TB, Umur,
dan Tahun Lahir memiliki nilai rata-rata akurasi tertinggi sebesar
76,91% menggunakan 7 folds dan terendah sebesar 74,44%
menggunakan 3 folds, lihat Gambar 4.2.
4.3.3. BB/PB
Pada klasifikasi kelas PB/U dengan menggunakan atribut
yang dipilih secara manual yaitu Js.L/P, Berat B., PB/TB, dan
Umur memiliki nilai rata-rata akurasi tertinggi sebesar 84,45%
dengan menggunakan 7 folds dan rata-rata akurasi terendah
83,27% dengan menggunakan 3 dan 5 folds, lihat Tabel 4.6.
Sementara itu untuk atribut yang di-voting hingga tersisa 4 atribut
diantaranya Berat B., PB/TB, Umur, dan Tahun Lahir memiliki
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

40
nilai rata-rata akurasi tertinggi sebesar 84,69% dengan
menggunakan 7 folds dan terendah sebesar 83,26% dengan
menggunakan 5 folds, lihat Gambar 4.3.
4.4. Analisis
Dari hasil pengujian di atas dapat dilihat bahwa decision tree
bekerja dengan baik untuk mengklasifikasikan kelas BB/U, PB/U, dan
BB/PB dengan menggunakan atribut yang dipilih secara manual
maupun dengan menggunakan atribut yang dipilih berdasarkan
weighted voting by information gain.
Rata-rata akurasi yang dihasilkan dipengaruhi oleh jumlah folds
yang digunakan, jumlah atribut yang digunakan, dan pemilihan atribut.
Pemilihan atribut yang tepat akan menghasilkan rata-rata akurasi yang
baik. Dengan demikian sistem yang telah dibangun menggunakan
decision tree c4.5 bekerja dengan baik untuk klasifikasi BB/U, PB/U,
dan BB/PB untuk atribut yang dipilih secara manual.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

41
BAB V
PENUTUP
5.1. Kesimpulan
Berdasarkan hasil penelitian klasifikasi gizi balita menggunakan
metode decision tree c4.5, dapat diambil kesimpulan sebagai berikut.
1. Metode klasifikasi decision tree c4.5 dapat mengklasifikasikan
gizi balita dengan baik.
2. Rata-rata akurasi tertinggi dari klasifikasi gizi balita
menggunakan decision tree c4.5 adalah sebagai berikut.
a. Klasifikasi kelas BB/U dengan menggunakan atribut yang
dipilih secara manual adalah 90,93% dengan menggunakan
5 folds, dan dengan menggunakan atribut yang di voting
adalah 88,69% dengan menggunakan 7 folds dan 3 atribut.
b. Klasifikasi kelas PB/U dengan menggunakan atribut yang
dipilih secara manual adalah 78,33% dengan menggunakan
7 folds, dan dengan menggunakan atribut yang di voting
adalah 77,5% pada saat menggunakan 7 folds dan 3 atribut.
c. Klasifikasi kelas BB/PB dengan menggunakan atribut yang
dipilih secara manual adalah 84,45% dengan menggunakan
7 folds, dan dengan menggunakan atribut yang di voting
adalah 84,69% yaitu ketika menggunakan 7 folds dan 3
atribut.
3. Pemilihan atribut secara manual lebih baik dan efektif jika
dibandingkan dengan atribut yang di-voting.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

42
5.2. Saran
Dari hasil penelitian klasifikasi gizi balita menggunakan metode
decision tree c4.5, penulis memberikan saran sebagai berikut:
1. Perangkat lunak mampu mengimpor data dengan berbagai jenis
lainnya seperti *.cvs, *.dat, *.tab, dll.
2. Pengembangan perangkat lunak dengan metode klasifikasi
lainnya.
3. Perangkat lunak dapat menyimpan hasil uji data tunggal.
4. Pengklasifikasian status gizi balita berdasarkan latar belakang
keluarga.
5. Pengembangan program lebih fleksibel (variabel input tidak
statis).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

43
DAFTAR PUSTAKA
Anam, Choirul dan Santoso. 2018. Perbandingan Kinerja Algoritma C4.5 dan
Naive Bayes untuk Klasifikasi Penerima Beasiswa. Sumber:
https://ejournal.upm.ac.id/index.php/energy/article/view/111
Damayanti. 2018. 4 Ancaman Bahaya yang Dialami Balita dengan Gizi Buruk.
Sumber: https://www.cnnindonesia.com/gaya-hidup/20180125110614-255-
271456/4-ancaman-bahaya-yang-dialami-balita-dengan-gizi-buruk [Diakses
tanggal: 29 November 2019]
Faruz El Said. 2009. Data Mining-Konsep Pohon Keputusan. Sumber:
https://fairuzelsaid.wordpress.com/2009/11/24/data-mining-konsep-pohon-
keputusan/#more-521 [Diakses tanggal: 29 November 2019]
Fayyad, Usama. 1996. Advances in Knowledge Discovery and Data Mining. MIT
Press.
Han, Jiawei dan Kamber, Micheline. 2006. Data Mining: Concept and Techniques
Second Edition, Morgan Kaufmann Publishers.
Kemenkes,2018. Hasil Utama Riset Kesehatan Dasar (Riskesdas) Kementerian
Kesehatan 2018. Sumber:
https://www.depkes.go.id/resources/download/info-
terkini/materi_rakorpop_2018/Hasil%20Riskesdas%202018.pdf [Diakses
tanggal: 22 November 2019]
Larose, Daniel T. 2005. Discovering Knowledge in Data: An Introduction to
Data Mining. John Willey & Sons, Inc.
Quinlan, J.R. (1992). C4.5 Programs for Machine Learning, San Mateo, CA:
Morgan Kaufmann.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

44
Ulva Febriana, M. Tanzil Furqon, dan Bayu Rahayudi. 2017. Klasifikasi Penyakit
Typhoid Fever (TF) Dan Dengue Hemorrhagic Fever (DHF) Dengan
Menerapkan Algoritma Decision Tree C4.5. Sumber:
http://repository.ub.ac.id/id/eprint/1800
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI




















