
KLASIFIKASI SENTIMEN TERHADAP TOKOH …i KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA TWITTER...
61
i KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA TWITTER MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR SKRIPSI Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika Oleh : Adres Kusumawardhana 155314008 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA YOGYAKARTA 2019 PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
Transcript of KLASIFIKASI SENTIMEN TERHADAP TOKOH …i KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA TWITTER...

i
KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA
TWITTER MENGGUNAKAN ALGORITMA
K-NEAREST NEIGHBOR
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh
Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Adres Kusumawardhana
155314008
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2019
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ii
SENTIMENT CLASSIFICATION OF THE PUBLIC FIGURE ON
TWITTER USING K-NEAREST NEIGHBOR ALGORITHM
A THESIS
Presented as Partitial Fulfillment of Requirments to Obtain Sarjana Komputer
Degree in Informatics Engineering Department
By :
Adres Kusumawardhana
155314008
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2019
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

iii
HALAMAN PESETUJUAN PEMBIMBING
SKRIPSI
KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA
TWITTER MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR
Oleh :
Adres Kusumawardhana
155314008
Telah Disetujui oleh :
Pembimbing,
Robertus Adi Nugroho, S.T., M.Eng. Tanggal.…………
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

iv
HALAMAN PENGESAHAN
KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA
TWITTER MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR
Diperoleh dan ditulis oleh :
ADRES KUSUMAWARDHANA
NIM : 155314008
Telah dipertahankan di depan Penguji pada tanggal…………...
Susunan Panitia Penguji
Nama Lengkap Tanda Tangan
Ketua : Puspaningtyas Sanjoyo Adi, S.T., M.T. ……………...
Sekretaris : Drs. Haris Sriwindono, M.Kom, Ph.D. ……………...
Anggota : Robertus Adi Nugroho S.T., M.Eng. ……………...
Yogyakarta, ……………………………
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

v
HALAMAN MOTO
“ nggak selesai-selesai kuliahnya, cepet selesaiin habis itu kerja jangan lupa
kasih uang ke ibuk” – ibuk. 2019
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

vi
HALAMAN PERSEMBAHAN
“Tuhan Yang Maha Esa”
“Órangtua”
“Setiap Orang yang Selalu Bertanya Kapan Lulus”
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

vii
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa di dalam skripsi yang saya
tulis ini tidak memuat karya atau bagian dari orang lain, kecuali yang telah
disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah
Yogyakarta, 31 Juli 2019.
Penulis
Adres Kusumawardhana
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, sata mahasiswa Universitas Sanata Dharma:
Nama : Adres Kusumawardhana
NIM : 155314008
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah yang berjudul :
KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA
TWITTER MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan
data mendistribusikan secara terbatas , dan mempublikasikannya di internet atau
media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya
maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya
sebagai penulis.
Demikian pernyataan ini saya buat sebenarnya
Yogyakarta, 31 Juli 2019
Yang menyatakan,
Adres Kusumawardhana
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ix
ABSTRAK
Keberadaan twitter telah banyak digunakan masyarakat luas untuk menulis suatu
opini terhadap semua hal yang ada, salah satunya membicarakan tentang tokoh-
tokoh publik tertentu. Tokoh yang dinilai merupakan tokoh yang dianggap layak
untuk dipilih sebagai pemimpin suatu negara terutama di Indonesia. Oleh karena
itu, penelitian ini mencoba untuk menganalisis twitter berbahasa Indonesia yang
memiliki opini tentang tokoh-tokoh publik di Indonesia. Pada penelitian ini terdiri
dari beberapa tahap. Tahap pertama adalah proses pre-processing yang terdiri dari
proses case folding, tokenisasi, stemming, normalisasi kata, dan stopword
removal. Selanjutnya pada tahap kedua adalah dengan melakukan pembobotan
kata menggunakan metode TF-IDF. Pada tahap terakhir yaitu melakukan
klasifikasi dengan metode klasifikasi tweet yang berisi tentang pihak tertentu.
Metode klasifikasi yang dilakukan dalam penelitian ini adalah K-Nearest
Neighbor. Hasil yang diperoleh dari analisis sentimen terhadap tokoh publik
menggunakan algoritma K-Nearest Neighbor memperoleh akurasi tertinggi ketika
menggunakan 20-fold dengan jumlah tetangga nilai k=1 sebesar 68,3%.
Kata kunci : klasifikasi, tf-idf, K-Nearest Neighbor.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

x
ABSTRACT
The existence of Twitter has been widely used by the public to write an opinion
on all things that exist, one of which is talking about certain public figures. Those
who are being talked are public figures who are considered worthy to be elected
as the leader of a country especially in Indonesia. Therefore, this research
attempts to analyze Indonesian-language Twitter which has opinions on public
figures in Indonesia. This research consists of several stages. The first stage is pre-
processing process consisting of case folding, tokenisasi, stemming, normalisasi
kata, and stopword removal. The second stage is word weighting using TF-IDF
method. Finally, the last step is doing the classification using Tweet classification
that contains certain parties. The classification method used in this research is K-
Nearest Neighbor. The sentiment analysis toward public figures using K-Nearest
Neighbor algorithm results the highest accuracy when using 20-fold with the
number of neighboring k=1 at 68,3%.
Key words: classification, tf-idf, K-Nearest Neighbor.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xi
KATA PENGANTAR
Puji dan syukur penilis panjatkan kepada Tuhan Yang Maha Esa atas
penyertaannya dalam penyususnan skripsi ini sehingga dapat berjalan dengan
baik dan lancar.
Skripsi merupakan salah satu syarat mahasiswa untuk mendapatkan gelar
Sarjana pada Teknik Informatika, Fakultas Sains dan Teknologi, Universitas
Sanata Dharma Yogyakarta.
Berkat bimbingan serta dukungan oleh beberapa pihak yang selalu
mendukung untuk menyelesaikan skripsi. Pada kesempatanan ini dengan segenap
kerendahan hati penulis menyampaikan rasa terimakasih kepada :
1. Tuhan Yang Maha Esa yang telah memberikan berkat dan rahmat kepada
penulis
2. Bapak Jentot Suyono dan Ibu Suharti, Saudara Saka Adhi Yudha, Saudari
Mega Kusumawardhani yang selalu memberi bantuan, motivasi dan doa
sehingga memberikan semangat dalam menyelesaikan penelitian ini.
3. Bapak Robertus Adi Nugroho selaku pembimbing tugas akhir yang sudah
bersedia meluangkan waktu dan tenaga untuk memberikan arahan,
masukan serta motivasi kepada penulis
4. Seluruh Dosen Teknik Informatika Universitas Sanata Dharma yang telah
mendidikan dan memberi ilmu pengetahuan yang digunakan dalam
penulisan tugas akhir ini.
5. Elizabeth Tisna Lea Desika yang menemani pengerjaan penelitian,
memberikan semangat dan motivasi dalam mengerjakan penelitian ini
6. Teman – teman “Tempe Benguk” yang selalu menghibur dalam
pengerjaan penelitian ini.
7. Saudara Jery Feridano, Saudara Vincentius Bayu yang telah meluangkan
waktu dan tenaga untuk membantu menemani penulis bertukar pikiran.
8. Saudari Natalia Ambarwati, Saudari Anindya Sabrina, Saudara Kevin,
Saudara Peter, Saudara Bima, Saudari Maria, Saudari Giska, Saudari Ruth,
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xii
Saudari Yerni, Saudari Uni, Saudari El, Saudari Ventya, Saudara Jovi,
Saudara Bagas, Saudara Tubagus, Saudara Tinus, Saudara Peter yang
memberi semangat dalam mengerjakan penelitian ini didalam Ruang
Akses Mahasiswa (RAM).
9. Teman – teman dari seluruh mahasiswa Teknik Informatika Universitas
Sanata Dharma yang telah berdinamika selama dalam perkuliah.
Yogyakarta, 31 Juli 2019
Adres Kusumawardhana
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiii
DAFTAR ISI
KLASIFIKASI SENTIMEN TERHADAP TOKOH PUBLIK PADA TWITTER
MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR ........................... i
SENTIMENT CLASSIFICATION OF THE PUBLIC FIGURE ON TWITTER
USING K-NEAREST NEIGHBOR ALGORITHM ............................................. ii
HALAMAN PESETUJUAN PEMBIMBING ..................................................... iii
HALAMAN PENGESAHAN .............................................................................. iv
HALAMAN MOTO ............................................................................................. v
HALAMAN PERSEMBAHAN .......................................................................... vi
PERNYATAAN KEASLIAN KARYA ............................................................. vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS .......................................................... viii
ABSTRAK ........................................................................................................... ix
ABSTRACT .......................................................................................................... x
KATA PENGANTAR ......................................................................................... xi
DAFTAR ISI ...................................................................................................... xiii
DAFTAR GAMBAR .......................................................................................... xv
DAFTAR TABEL .............................................................................................. xvi
BAB I PENDAHULUAN ..................................................................................... 1
1.1 Latar Belakang ....................................................................................... 1
1.2 Rumusan Masalah .................................................................................. 2
1.3 Tujuan Penelitian .................................................................................... 2
1.4 Manfaat Penelitian .................................................................................. 3
1.5 Batasan Penelitian .................................................................................. 3
1.6 Metodologi Penelitian ............................................................................ 3
1.7 Sistematika Penulisan ............................................................................. 4
BAB II LANDASAN TEORI .............................................................................. 5
2.1. Text Mining ............................................................................................. 5
2.1.1. Pre-processing ................................................................................. 5
2.2 . Pembobotan TF-IDF ........................................................................... 11
2.3 . K-Fold Cross Validation .................................................................... 12
2.4 K-Nearest Neighbor ............................................................................. 12
2.5 Confusion Matiks .................................................................................. 14
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiv
BAB III METODE PENELITIAN...................................................................... 16
3.1 Pengumpulan Data .................................................................................... 16
3.2 Deskripsi Sistem ................................................................................... 16
3.3 Spesifikasi ............................................................................................ 17
3.3.1. Hardware ....................................................................................... 17
3.3.2. Software ........................................................................................ 17
3.4 Tahapan Penelitian ............................................................................... 17
3.4.1 Studi Pustaka ................................................................................. 17
3.4.2 Pengumpulan Data ........................................................................ 17
3.4.3 Perancangan Sistem ...................................................................... 18
3.4.4 Evaluasi dan Analisis Hasil Penelitian .......................................... 18
3.5 Desain Interface .................................................................................... 18
3.6 Gambaran Umum Sistem ..................................................................... 19
3.6.1. Data ............................................................................................... 19
3.6.2. Pre-processing .............................................................................. 19
3.6.3 Pembobotan TF-IDF ..................................................................... 25
3.6.4 K-Nearest Neighbor ...................................................................... 29
3.6.5 Penghitungan Akurasi ................................................................... 29
BAB IV HASIL DAN ANALISA HASIL ........................................................ 31
4.1 Hasil & Analisis ................................................................................... 31
4.1.1 Pengujian Perbandingan Hasil Akurasi K-Nearest Neighbor Secara
Manual dengan Hasil Akurasi K-Nearest Neighbor Menggunakan Perangkat
Lunak ....................................................................................................... 32
4.1.2 Dataset ........................................................................................... 33
BAB V PENUTUP .............................................................................................. 36
5.1 Kesimpulan ........................................................................................... 36
5.2 Saran ..................................................................................................... 36
DAFTAR PUSTAKA ......................................................................................... 37
LAMPIRAN ........................................................................................................ 38
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xv
DAFTAR GAMBAR
Gambar 2.1 Hasil Tokenisasi……………………………………………………………...7
Gambar 2.2 Hasil Stemming……………………………………………………………....7
Gambar 2.3 K-Fold Validation dengan K sebesar 3……………………………………..13
Gambar 2.4 Model Klasifikasi K-Nearest Neighbor…….……………………………….14
Gambar 3.1 Contoh Data Tweet……………………………………………….………....16
Gambar 3.2 Desian Interface……………………………………………………………..18
Gambar 3.3 Gambaran Umum Sistem…………………………………………………...19
Gambar 3.4 Kumpulan Data……………………………………………………………...19
Gambar 3.5 Hasil Proses Case Folding………………………………………….……….20
Gambar 3.6 Proses Hasil Tokenisasi……………………………………………………..21
Gambar 3.7 Hasil Tokenisasi…………………………………………………………….22
Gambar 3.8 Proses Hasil Stemming……………………………………………………...22
Gambar 3.9 Hasil Stemming……………………………………………………………...23
Gambar 3.10 Proses Hasil Normalisasi Kata…………………………………………….23
Gambar 3.11 Contoh Hasil Normalisasi Kata………………………………………...….24
Gambar 3.12 Proses Hasil Stopword Removal…………………………………………..24
Gambar 3.13 Contoh Hasil Stopword Removal……………………………………….....25
Gambar 3.14 Proses Perhitungan Term Frequency………………………………………25
Gambar 3.15 Contoh Term Frequency………………………………………...………...26
Gambar 3.16 Proses Perhitungan Document Frequency…………………………………26
Gambar 3.17 Contoh Hasil Document Frequency……………………………………….26
Gambar 3.18 Proses Perhitungan Inverse Document Frequency………………………...27
Gambar 3.19 Contoh Hasil Inverse Document Frequency………………………………27
Gambar 3.20 Proses Perhitungan Bobot (Weight) ………………………………………28
Gambar 3.21 Contoh Hasil Bobot (Weight) ……………………………………………..28
Gambar 3.22 Hasil Confusion Matrix………………………………………...………….30
Gambar 4.1 Hasil akurasi sistem………………………………………...………………..33
Gambar 4.2 Hasil tampilan percobaan………………………………………...…………34
Gambar 4.3 Akurasi 10-fold………………………………………...…………………....34
Gambar 4.4 Akurasi 20-fold………………………………………...……………………35
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xvi
DAFTAR TABEL
Tabel 2.1 Aturan Awalan yang Tidak Diizinkan……………………………………..8
Tabel 2.2 Aturan Pelurusan Kata Dasar………………………………………...……...9
Tabel 2.3 Hasil Stopword Removal………………………………………...………...12
Tabel 2.4 Tabel Confusion Matrix………………………………………...………….15
Tabel 3.1 Contoh Prediksi Confusion Matrix………………………………………..30
Tabel 4.1 Tabel Perrhitungan Manual TF-IDF……………………………………...39
Tabel 4.2 Uji Coba 1-Fold………………………………………...…………………...40
Tabel 4.3 Jarak Urut 1-Fold………………………………………...………………….40
Tabel 4.4 Perhitungan Manual 2-Fold………………………………………...……....41
Tabel 4.5 Jarak urut 2-Fold………………………………………...………………….41
Tabel 4.5 Perhitungan Manual 3-Fold………………………………………...………42
Tabel 4.6 Jarak Urut 3-Fold………………………………………...………………….42
Tabel 4.7 Perhitungan Manual 4-Fold………………………………………...………43
Tabel 4.8 Jarak urut 4-Fold………………………………………...…………………..43
Tabel 4.9 Perhitungan Manual 5-Fold………………………………………...………44
Tabel 4.10 Jarak Urut 5-Fold………………………………………...………………...44
Tabel 4.11 Confusion Matrik 1………………………………………...……………...45
Tabel 4.12 Confusion Matrik 2………………………………………...……………...45
Tabel 4.13 Confusion Matrik 3………………………………………...……………...45
Tabel 4.14 Confusion Matrik 4………………………………………...……………...45
Tabel 4.15 Confusion Matrik 5………………………………………...……………...45
Tabel 4.16 Akurasi Total………………………………………...…………………….45
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Indonesia merupakan negara yang menganut sistem demokrasi. Hal ini
ditandai dengan adanya pemilihan umum untuk menentukan presiden dan wakil
presiden. Pada umumnya pemilihan umum diadakan secara periodik. Terdapat
pasangan yang ingin maju dalam pemilihan umum sebagai calon presiden, tentu
akan menumbuhkan opini-opini dari masyarakat. Dengan berbagai opini, kritik
dan saran yang disampaikan melalu media sosial. Dalam perkembangan teknologi
terdapat berbagai macam media sosial. Salah satu media sosial yang digunakan
adalah twitter.
Twitter merupakan salah satu alat komunikasi yang popular dikalangan
pengguna internet. Twitter memiliki layanan media sosial yang memungkinkan
penggunanya untuk mempublikasikan pesan pendek yang didalamnya dapat
berisikan opini, kritik dengan batasan karakter terbatas (kurang dari 140 karakter).
Tweet merupakan pesan singkat yang berada dalam twitter. Tweet yang
seringkali digunakan untuk mengungkapkan komentar dapat disertai dengan
emosi penulis. Emosi ini dapat berisi positif dan negatif. Emosi positif dapat
berisikan rasa senang, bangga, cinta serta perasaan yang menguntungkan. Emosi
negatif dapat berisikan rasa marah, sedih, menghujat, atau perasaan yang
merugikan. Pengenalan emosi dapat dilakukan dengan analisis sentimen. Analisis
sentimen merupakan pengelompokan polaritas dari teks yang ada dalam suatu
dokumen pada kasus ini merupakan tweet, dengan pendapat yang dikemukakan
tersebut merupakan pendapat bersifat negatif atau positif.
Dalam sebuah penelitian implementasi algoritma K-Nearest Neighbor dalam
pengklasifikasian follower twitter yang menggunakan Bahasa Indonesia (Rivki,
Bachtiar, 2017). Penelitian tersebut bertujuan untuk membantu memudahkan
pengguna twitter untuk melakukan promosi dengan tweet promosi terhadap
follower yang sudah diklasifikasikan. Dalam penelitian ini dapat diketahui bahwa
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

2
algoritma K-Nearest Neighbordengan akurasi 68% dari data uji mulai bertahap
mulai dari 25, 50, hingga 100 data latih.
Penelitian terkait juga pernah dilakukan terhadap K-Nearest Neighbor untuk
rekomendasi keminatan studi (Anshori, 2018). Pada penelitian tersebut bertujuan
untuk membantu mengklasifikasikan dengan mempunyai 5(lima) peminatan,
karena dalam masalahnya sering kali mahasiswa tidak sesuai peminatannya yang
sesuai dengan bakat, keinginan serta nilai mata kuliah wajib yang sudah ditempuh.
Pengujian tersebut dilakukan dengan membandingkan hasil keminatan yang sudah
diverifikasi oleh akademik dengan hasil yang diperoleh dari perhitungan sistem
berdasarkan 30 data uji dengan hasil yang paling optimal adalah menggunakan
dengan nilai K bernilai 10. Pada penilitain tersebut juga memiliki hasil akurasi
76,66%
Peneliti tertarik untuk mengambil topik ini dengan tujuan untuk mengetahui
berapa presentase yang diperoleh dalam tweet bersifat positif dan negatif
berdasarkan data yang sudah diteliti dari penelitian sebelumnya dengan judul
Analisis Sentimen Terhadap Tokoh Publik Pada Twitter(Pamungkas, Taufik,
2018) dengan menggunakan algoritma K-Nearest Neighbor.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang dikemukan diatas, permasalahan yang
dibahas dalam penelitian ini, yaitu :
1. Bagaimana pendekatan K-Nearest Neighbor mampu mengklasifikasikan
komentar di Twitter?
2. Bagaimana tingkat akurasi klasifikasi twitter menggunakan metode K-
Nearest Neighbor?
1.3 Tujuan Penelitian
Tujuan yang ingin dicapai dari penelitian ini adalah sebagai berikut :
1. Untuk membuat sistem yang mampu mengklasifikasi tweet menggunakan
K-Nearest Neighbor.
2. Untuk mengetahui hasil akurasi klasifikasi sentimen dengan K-Nearest
Neighbor.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

3
1.4 Manfaat Penelitian
Dapat membantu masyarakat untuk menganalisis komentar dalam tweet untuk
mendapatkan klasifikasi menggunakan K-Nearest Neighbor.
1.5 Batasan Penelitian
1. Tweet yang digunakan hanya tweet berbahasa Indonesia.
2. Tweet yang digunakan hanya tweet berupa text, tidak mengandung gambar,
emoji, hashtag
3. Data yang dikumpulkan dengan format .xls
4. Data yang digunakan dari penelitian sebelumnya dengan judul analisis
sentimen dan klasifikasi kategori terhadap tokoh publik pada twitter.
1.6 Metodologi Penelitian
Langkah – langkah yang digunakan untuk melakukan penelitian ini adalah
sebagai berikut :
1. Studi Pustaka
Penggunaan studi pustaka untuk penelitian ini adalah untuk mencari dan
memperlajari sumber-sumber mengenai metode K-Nearest Neighbor untuk
pengklasifikasian data teks.
2. Observasi
Melakukan pencarian data dari penelitian sebelumnya dan dari berbagai
tweet pada twitter.
3. Antarmuka
Penggunaan antarmuka pada penelitian ini adalah untuk mempermudah
dalam melakukan demo kla terhadap tokoh publik menggunakan
klasifikasi K-Nearest Neighbor.
4. Pengujian
Penggunaan pengujian dalam penelitian ini adalah untuk mengukur
ketepatan dalam akurasi klasifikasi menggunakan metode K-Nearest
Neighbor.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

4
1.7 Sistematika Penulisan
Laporan ini disusun secara sistematika yang tersusun dari beberapa bab,
diantaranya sebagai berikut :
BAB I : Pendahuluan
Bab ini berisikan latar belakang yang menguraikan tentang konsep dasar
pembuatan penelitian, yang diuraikan tentang rumusan masalah, tujuan penelitian,
manfaat penelitian, batasan penelitian, metodologi penelitian dan sistematika
penelitian.
BAB II : Landasan Teori
Bab ini berisikan tentang teori-teori yang digunakan untuk penelitian tersusun
dari analisis sentimen, text mining, pre-processing, Pembobotan TF-IDF,
Klasifikasi K-Nearest Neighbor, Euclidean Distance, K-Fold Validation.
BAB III : Metodologi Penelitian
Pada bab ini berisikan tentang metode, langkah-langkah dan desain proses
analisis, klasifikasi serta identifikasi.
BAB IV : Hasil dan Analisa Hasil
Pada bab berisikan tentang implementasi dan hasil dari perancangan yang
telah dibuat.
BAB V : Penutup
Pada bab ini berisikan kesimpulan dan saran untuk pengembangan lebih
lanjut
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

5
BAB II
LANDASAN TEORI
2.1. Text Mining
Text mining adalah ilmu yang bertujuan untuk memproses teks agar menjadi
informasi yang diperoleh dari peramalan pola dan kecenderungan melalui pola
statistik (Jiawei, et al., 2012). Text mining bertujuan untuk menganalisis
pendapat, sentimen, evaluasi, sikap, sehingga dapat diketahui informasi bagi
pengguna. Text mining mencoba untuk mengekstrak infomasi yang berguna dari
sumber data melalui identifikasi dan eksplorasi dari suatu pola menarik. Text
mining biasanya digunakan pada masalah klasifikasi, klastering, pemerolehan
informasi dan information extraction (Nugroho, 2016). Dalam kasus ini untuk
data tweet yang memiliki jumlah data yang banyak, sulit untuk menganalisis
sentimen didalamnya. Disini peran yang dilakukan untuk secara otomatis dapat
mengolah kata dan mengetahui sentimen dari kumpulan tweet. Pada text mining
tahap pertama untuk mengolah kata untuk dapat diproses ke tahap selanjutnya
sebagai berikut :
2.1.1. Pre-processing
Pre-processing merupakan tahapan awal dan tahap paling penting dari proses
text mining untuk mengubah data sesuai dengan format yang akan dibutuhkan
dalam proses selanjutnya. Pre-processing dilakukan untuk mendapatkan data yang
akurat. Dalam pre-processing teks, ada beberapa langkah seperti Case Folding,
Tokenisasi, Stopword Removal, Stemming. (Sharma, Agrawal, Lalit, & Garg,
2017). Tujuan dari pre-processing adalah untuk mengurangi noise dari tweet
supaya diperoleh kata-kata yang hanya memiliki arti penting dalam sebuah tweet.
Tahapan yang dilakukan di pre-processing adalah :
2.1.1.1. Case Folding
Case Folding merupakan tahapan awal dari pre-processing yang bertujuan
untuk mengubah kata-kata yang didapat menjadi format yang sama. Pada tahapan
ini dilakukan dengan mengubah kata menjadi huruf kecil atau lower case.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

6
Contoh proses Case Folding :
Kalimat awal
Hati Ini gemetar melihat kinerja untuk membangun
bangsa
Hasil dari proses case folding
hati ini gemetar melihat kinerja untuk membangun bangsa
2.1.1.2. Tokenisasi
Tokenisasi merupakan proses memisahkan setiap kata menjadi pecahan-
pecahan kecil dan bertujuan untuk menghilangkan whitespace. Pada tahap ini
terkadang disertai langkah untuk membuang karakter tertentu seperti tanda baca,
emoji, url.
Contoh proses Tokenisasi :
Kalimat awal
hati ini gemetar melihat kinerja untuk membangun
bangsa
Hasil dari proses Tokenisasi (Gambar 2.1).
hati ini gemetar melihat kinerja untuk membangun bangsa
Gambar 2.4 Hasil Tokenisasi
2.1.1.3. Stemming
Stemming merupakan proses menyederhanakan kata yang berisi imbuhan
untuk mencari kata dasar dari hasil kata dari hasil proses tokenisasi (Gambar 2.2).
hati ini gemetar lihat kinerja untuk bangun bangsa
Gambar 5.2 Hasil Stemming
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

7
Rule stemming berdasarkan dari algoritma memiliki tahap-tahap sebagai
berikut (Nazief dan Adriani, 2007) :
1) Pertama cari kata yang akan distem dnari kamus kata dasar. Jika
ditemukan kata tersebut maka dapat diasumsikan merupakan root
word. Algoritma berhenti. Jika tidak ditemukan masuk ke langkah ke
b
2) Menghilangkan Inflection Suffixes bila ada dalam kata. Inflection
Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika
berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini
diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”,
atau “-nya”), jika ada.
3) Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata
ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke
langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata
tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata
tersebut ditemukan dalam kamus maka algoritma berhenti.
Jika tidak ditemukan maka lakukan langkah 3b.
b.Akhiran yang dihapus (“-i”, “-an” atau “-kan”)
dikembalikan, lanjut ke langkah 4.
4) Pada langkah ke 4 terdapat 3 iterasi
a. Iterasi berhenti jika :
1. Ditemukan kombinasi akhiran yang tidak diizinkan
berdasarkan awalan (Tabel 2.1).
Tabel 2.4 Aturan Awalan yang Tidak Diizinkan
Awalan Awalan yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
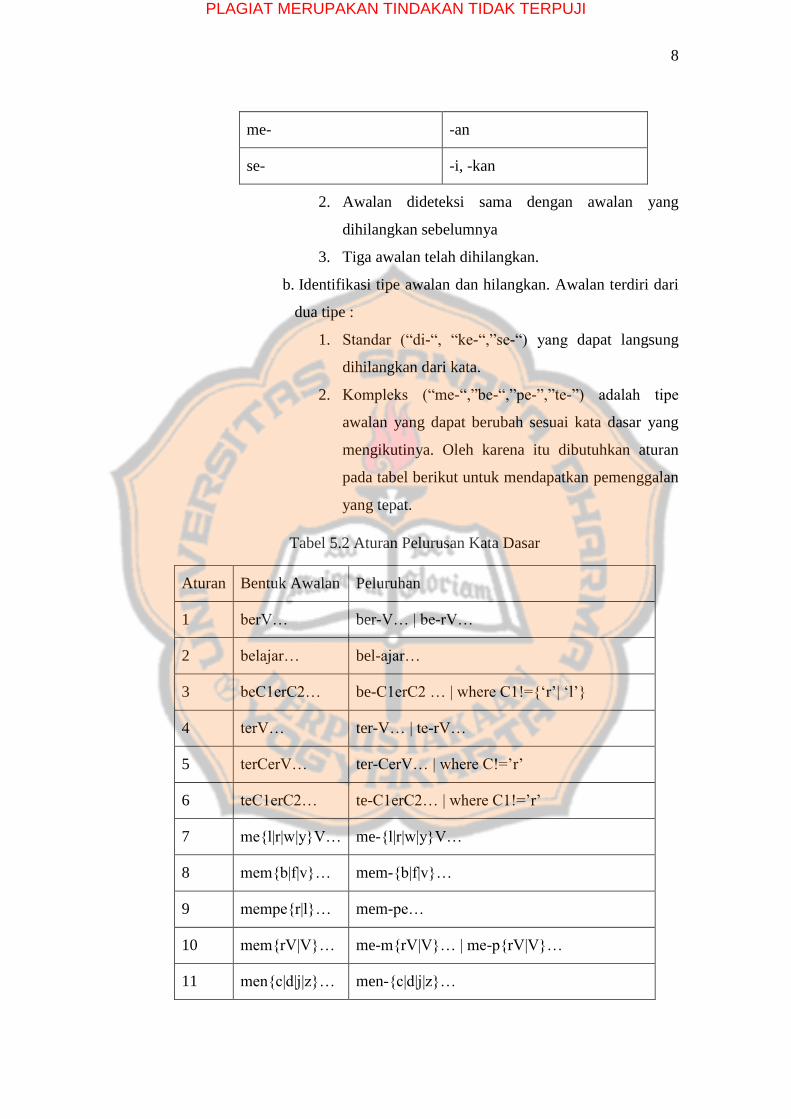
8
me- -an
se- -i, -kan
2. Awalan dideteksi sama dengan awalan yang
dihilangkan sebelumnya
3. Tiga awalan telah dihilangkan.
b. Identifikasi tipe awalan dan hilangkan. Awalan terdiri dari
dua tipe :
1. Standar (“di-“, “ke-“,”se-“) yang dapat langsung
dihilangkan dari kata.
2. Kompleks (“me-“,”be-“,”pe-”,”te-”) adalah tipe
awalan yang dapat berubah sesuai kata dasar yang
mengikutinya. Oleh karena itu dibutuhkan aturan
pada tabel berikut untuk mendapatkan pemenggalan
yang tepat.
Tabel 5.2 Aturan Pelurusan Kata Dasar
Aturan Bentuk Awalan Peluruhan
1 berV… ber-V… | be-rV…
2 belajar… bel-ajar…
3 beC1erC2… be-C1erC2 … | where C1!={„r‟| „l‟}
4 terV… ter-V… | te-rV…
5 terCerV… ter-CerV… | where C!=‟r‟
6 teC1erC2… te-C1erC2… | where C1!=‟r‟
7 me{l|r|w|y}V… me-{l|r|w|y}V…
8 mem{b|f|v}… mem-{b|f|v}…
9 mempe{r|l}… mem-pe…
10 mem{rV|V}… me-m{rV|V}… | me-p{rV|V}…
11 men{c|d|j|z}… men-{c|d|j|z}…
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
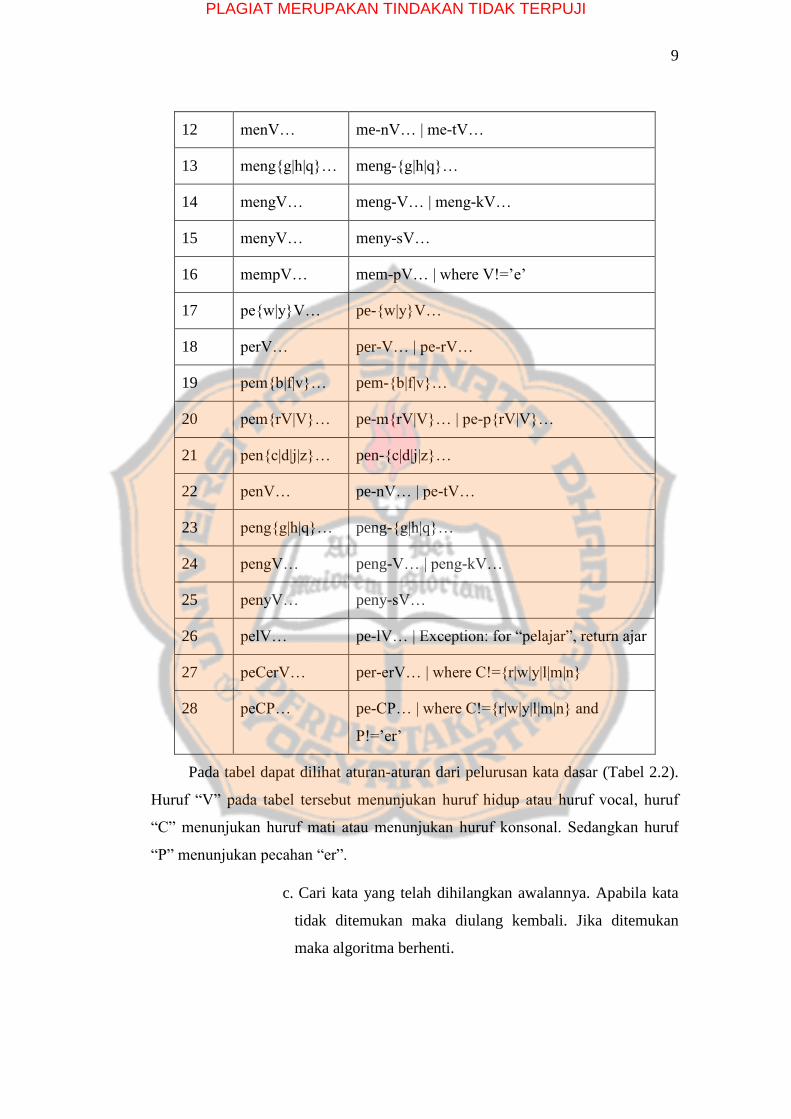
9
12 menV… me-nV… | me-tV…
13 meng{g|h|q}… meng-{g|h|q}…
14 mengV… meng-V… | meng-kV…
15 menyV… meny-sV…
16 mempV… mem-pV… | where V!=‟e‟
17 pe{w|y}V… pe-{w|y}V…
18 perV… per-V… | pe-rV…
19 pem{b|f|v}… pem-{b|f|v}…
20 pem{rV|V}… pe-m{rV|V}… | pe-p{rV|V}…
21 pen{c|d|j|z}… pen-{c|d|j|z}…
22 penV… pe-nV… | pe-tV…
23 peng{g|h|q}… peng-{g|h|q}…
24 pengV… peng-V… | peng-kV…
25 penyV… peny-sV…
26 pelV… pe-lV… | Exception: for “pelajar”, return ajar
27 peCerV… per-erV… | where C!={r|w|y|l|m|n}
28 peCP… pe-CP… | where C!={r|w|y|l|m|n} and
P!=‟er‟
Pada tabel dapat dilihat aturan-aturan dari pelurusan kata dasar (Tabel 2.2).
Huruf “V” pada tabel tersebut menunjukan huruf hidup atau huruf vocal, huruf
“C” menunjukan huruf mati atau menunjukan huruf konsonal. Sedangkan huruf
“P” menunjukan pecahan “er”.
c. Cari kata yang telah dihilangkan awalannya. Apabila kata
tidak ditemukan maka diulang kembali. Jika ditemukan
maka algoritma berhenti.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

10
5) Setelah langkah 4 kata belum ditemukan, maka proses recording
dilakukan dengan mengacu pada aturan tabel.
6) Jika semua sudah dilakukan tetapi tidak ditemukan kata dasar maka
diasumsikan sebaagai kata dasar.
Untuk menambah aturan keterbatasan algoritma diatas, maka ditambahkan
aturan untuk reduplikasi (Agusta, 2009) yaitu :
a. Jika kedua kata yang dihubungkan oleh kata penghubung adalah
kata yang sama dengan root word adalah bentuk tunggalnya.
Contoh : buku-buku maka kata dasarnya adalah buku.
b. Untuk kata bolak-balik , berbalas-balsan. Untuk mendapatkan rot
word, keduanya dipisah dan diartikan satu persatu, contoh untuk
berbalas – balasan, menjadi berbalas dan balasan root word
berbalas sama yaitu balas. Sebaliknya untuk bolak-balik memiliki
root word yang berbeda maka root word adalah bolak-balik
2.1.1.4. Normalisasi Kata
Normalisasi kata merupakan proses untuk mengurangi huruf berturut-turut
dari suatu kata. Normalisasi teks pada tahapan ini merupakan pengubahan kata
yang sebelumnya memiliki karakter huruf yang berturut-turut untuk membaca
kamus untuk menghilangkan karakter berlebih dari kata awal.
Contoh proses Normalisasi kata :
Akuuuuuu
Oleeehhhh
Hasil dari nomalisasi kata :
Aku
Oleh
2.1.1.5. Stopword Removal
Stopword merupakan proses menghilangkan kata umum yang sering muncul
tetapi tidak memliki arti penting dan tidak digunakan. Pada proses ini kata umum
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

11
akan dihapus untuk mengurangi jumlah kata yang disimpan oleh sistem
(Manning, 2009). Contoh stopword adalah dia, mereka, bapak, di, kenapa, apa,
mereka dan sebagainya.
Sebelum melakukan proses stopword removal dilakukan, harus memiliki
kamus yang didalamnya berisi kata-kata yang termasuk dalam stopword (stoplist).
Jika suatu kata didalamnya terdapat dalam stoplist maka kata tersebut akan
dihapus sehingga hanya tersisa kata-kata yang memiliki arti penting serta
mengurangi daftar untuk selanjutnya ke tahap pembobotan kata.
Kalimat awal
hati ini gemetar lihat kinerja untuk bangun bangsa
Hasil dari proses stopword removal (Tabel 2.3) :
Tabel 2.6 Hasil Stopword Removal
hati - gemetar lihat kinerja - bangun bangsa
2.3 . Pembobotan TF-IDF
Term Frequency-Inverse Document Frequency (TF-IDF) adalah metode yang
digunakan untuk memberikan bobot pada setiap kata yang telah diekstraksi.
Model pembobotan dari TF-IDF (1.1) merupakan model integrase dari model term
frequency dan inverse document frequency. Term frequency (TF) adalah proses
untuk menghitung jumlah kemunculan term dalam suatu dokumen. Inverse
document frequency (IDF) berfungsi mengurangi bobot suatu term jika
kemunculannya banyak tersebar di seluruh koleksi dokumen (rahmadya, 2014).
Tahapan pembobotan dengan TF-IDF adalah:
Wdt = tfdt * IDFt (1.1)
Dimana :
d = dokumen ke-d
t = kata ke-t dari kata kunci
W = bobot dokumen ke-d tehadap kata ke-t
tf = Banyaknya kata yang muncul dalam dokumen
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

12
IDF = nilai idf dari hasil
IDF = log D/dft (1.2)
D = Total dokumen
df = banyaknya dokumen yang muncul berdasarkan kata kunci
2.4 . K-Fold Cross Validation
Cross Validation merupakan salah satu teknik untuk memvalidasi keakuratan
suatu model yang akan dibangun berdasarkan dataset tertentu. Proses dari
pembagian data menjadi dua, data untuk pembangunan suatu model disebut
dengan data training, dan data untuk memvalidasi model disebut dengan data
testing (Gambar 2.3).
Cross validation yang sering dipakai adalah 5-fold cross validation dan 10-
fold cross validation. Dalam cross validation, nilai k harus ditentukan untuk
proses dan pembagian model data training dan data testing dari cross validation
selanjutnya.
Data Training
Data Testing
Gambar 2.6 K-Fold Validation dengan K sebesar 3
2.5 K-Nearest Neighbor
K-Nearest Neighbor adalah metode untuk melakukan klasifikasi, algoritma
ini sering digunakan untuk melakukan klasifikasi teks dan data. Inti dari metode
ini melakukan klasifikasi terhadap objek yang berdasar dari data yang jaraknya
paling dekat dengan objek tersebut atau sering disebut dengan neighborhood.
Supervised learning merupakan suatu pembelajaran dimana output yang
diharapkan telah diketahui sebelumnya. Data yang sudah ada akan menjadi
patokan untuk data yang akan masuk.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

13
Tujuan dari algorima ini adalah untuk mengklasifikasikan objek berdasarkan
atribut dan data latih. Apabila dari algoritma tersebut diberikan titik query, maka
akan muncul data latih yang paling dekat dengan data baru. Klasifikasi akan
didapat dengan hasil voting terbanyak diantara klasifikasi dari k obyek. Algoritma
KNN menggunakan klasifikasi ketetanggaan (neighborhood) dimana akan menjadi
nilai prediksi dari query instance.
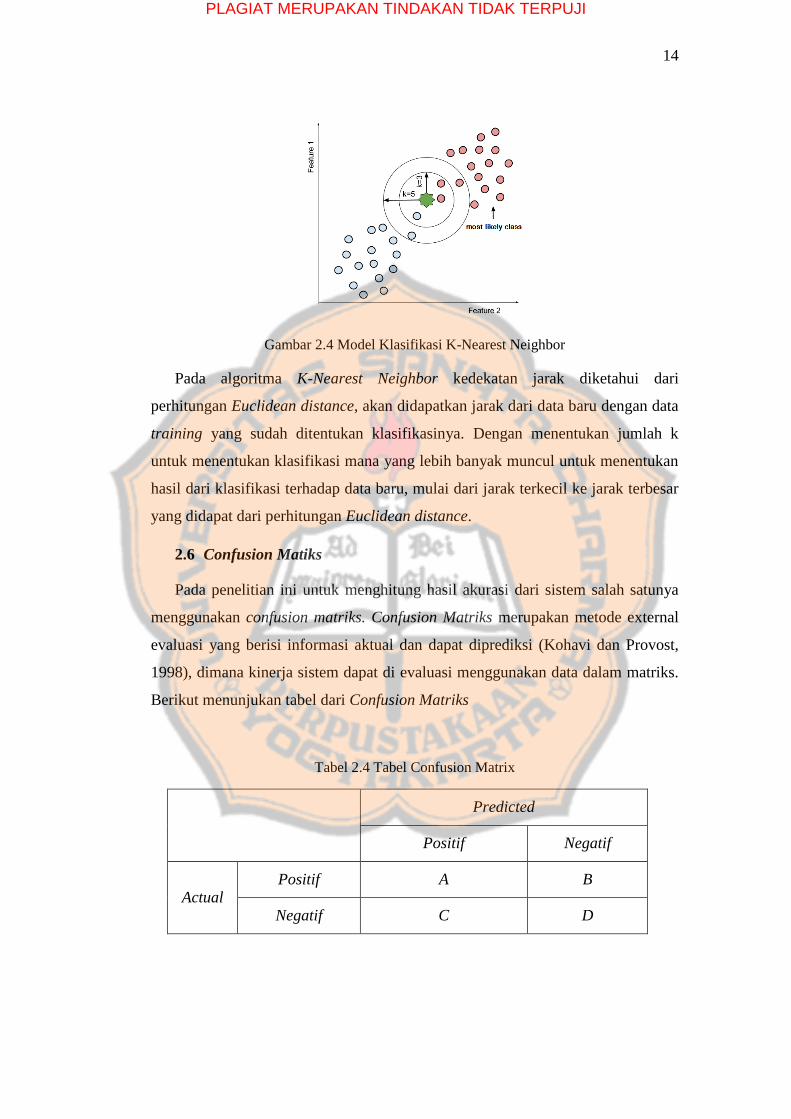
Algoritma KNN bekerja dengan menghitung jarak terdekat dari query
instance ke sampel data latih untuk menentukan klasifikasi (Gambar 2.4). Dengan
adanya data sampel yang dijadikan sebagai ruang dimensi akan menentukan
keberadaan dari data sampel tersebut. Ruang dibagi menjadi bagian-bagian
berdasarkan traning sampel, sebuah titik akan ditandai. Jika titik tersebut
berdekatan dengan k buah tetangga maka akan masuk dalam kelas tersebut.
Metode untuk mencari jarak terdekat menggunakan Euclidean Distance yaitu
untuk perhitungan jarak terdekat. Perhitungan tersebut bertujuan untuk
menentukan kemiripan yang dihitung dengan kemiripan data yang muncul dalam
teks. Kemudian teks yang akan diuji dibandingkan dengan masing-masing sampel
data asli.
Perhitungan jarak menggunakan Euclidean Distance :
d(A,B) =√ (A1 – B1)2 + (A2 – B2)
2 + .. … + |Ai – Bi|
2 (1.3)
dimana :
d(A,B) = jarak dokumen A ke dokumen B
Ai = kata ke i di dokumen A
Bi = kata ke i di dokumen B
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
14
Gambar 2.4 Model Klasifikasi K-Nearest Neighbor
Pada algoritma K-Nearest Neighbor kedekatan jarak diketahui dari
perhitungan Euclidean distance, akan didapatkan jarak dari data baru dengan data
training yang sudah ditentukan klasifikasinya. Dengan menentukan jumlah k
untuk menentukan klasifikasi mana yang lebih banyak muncul untuk menentukan
hasil dari klasifikasi terhadap data baru, mulai dari jarak terkecil ke jarak terbesar
yang didapat dari perhitungan Euclidean distance.
2.6 Confusion Matiks
Pada penelitian ini untuk menghitung hasil akurasi dari sistem salah satunya
menggunakan confusion matriks. Confusion Matriks merupakan metode external
evaluasi yang berisi informasi aktual dan dapat diprediksi (Kohavi dan Provost,
1998), dimana kinerja sistem dapat di evaluasi menggunakan data dalam matriks.
Berikut menunjukan tabel dari Confusion Matriks
Tabel 2.4 Tabel Confusion Matrix
Predicted
Positif Negatif
Actual Positif A B
Negatif C D
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

15
Keterangan :
A : Jumlah prediksi benar dan aktual benar
B : Jumlah prediksi salah dan aktual benar
C : Jumlah prediksi benar dan aktual salah
D : Jumlah Prediksi salah dan aktual salah
Perhitungan akurasi dirumuskan sebagai berikut :
Confusion Matriks =
(1.4)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

16
BAB III
METODE PENELITIAN
3.1 Pengumpulan Data
Pada penelitian ini, data yang diperoleh merupakan tweet dari twitter dengan
Bahasa Indonesia. Tweet berasal dari kombinasi tokoh-tokoh publik. Data diambil
dari penelitian sebelumnya dengan judul analisis sentimen terhadap tokoh publik
(Pamungkas, Taufik, 2018). Data yang diambil 1000 tweet, dimana orang-orang
menulis status terhadap tokoh-tokoh publik yang sering dibicarakan dalam twitter.
Data diperoleh dari penelitian sebelumnya untuk mendapatkan hasil dari
klasifikasi oleh ahli bahasa pada kasus yang sama mengenai analisis sentimen.
Tweet diambil antara label positif dan label negatif seimbang. Kalimat-kalimat
pada tweet tidak mengandung gambar. Kemudian data tweet digunakan sebagai
input pada sistem untuk diolah.
2018-12-09 11:05:09< >AdiSibarani2101 : RT @PowerEmak: @jokowi
Ikut bahagia dan bangga pak. Smoga senantiasa diberi nikmat bahagia ya pak.
Dan keluarga saya juga bisa bahagia
2018-12-09 10:23:02 <>NajmaKhumairoh : @jokowi @muhammadiyah
@MRomahurmuziy Bangga saya punya pemimpin seperti pak @jokowi
2018-12-09 10:23:02 <> Yulianto260776 : @jokowi Rakyat Indonesia 260jt bisa
membiayai kalo pimpinannya cerdas gak bego!
Gambar 3.1 Contoh Data Tweet
3.2 Deskripsi Sistem
Dalam perancangan sistem untuk melakukan analisis sentimen dengan
menggunakan metode klasifikasi K-NN dengan melakukan input dari data yang
sudah didapat dari twitter, yang berupa data training dan data testing, kemudian
masuk ke proses pre-processing hingga proses klasifikasi yang akan
menghasilkan sentimen positif atau negatif.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

17
3.3 Spesifikasi
Untuk proses mendukung pembuatan sistem digunakan software dan
hardware sebagai berikut :
3.3.1. Hardware
a) Processor : Intel ® Core ™ i5-8250U CPU @ 2.8GHz
b) Memory : 8 Gb
c) Harddisk : 1 TB
3.3.2. Software
a) Sistem Operasi : Windows 10 64-bit
b) Aplikasi : Netbeans
3.4 Tahapan Penelitian
3.4.1 Studi Pustaka
Pada studi pustaka ini penulis mencantumkan beberapa teori-teori yang
terkait dengan penelitian yang dilakukan, meliputi analisis sentimen,
preprocessing text, pembobotan kata, algoritma knn, Euclidean distance. Penulis
mencari literatur sebagai referensi untuk mendukung proses penelitian ini.
Literatur yang digunakan berasal dari jurnal ilmiah, karya ilmiah dan buku.
3.4.2 Pengumpulan Data
Data yang digunakan pada penelitian ini menggunakan tweet berbahasa
Indonesia yang ditulis oleh pengguna twitter, data diperoleh dari penelitian
sebelumnya dengan judul analisis sentimen terhadap tokoh publik pada twitter,
dari data yang memuat tentang beberapa tokoh politik Indonesia yang sering
dibicarakan dalam twitter. Dengan adanya data dari penelitian sebelumnya
mempermudah untuk memvalidasi hasil pelabelan dari suatu tweet yang bersifat
positif atau negatif.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

18
3.4.3 Perancangan Sistem
Pada tahap ini, akan dirancang suatu sistem yang dimulai dengan
perancangan interface dan pembuatan alat uji untuk menguji K-Nearest Neighbor
untuk mengelompokan tweet serta mendapatkan akurasi dari sistem.
3.4.4 Evaluasi dan Analisis Hasil Penelitian
Pada tahap pengujian, dilakukan analisis dari hasil luaran dari sistem yang
telah dibuat. Tujuan dari untuk menjawab rumusan masalah yang telah dipaparkan
dibab sebelumnya. Pada tahap analisis ini menjelaskan bagaimana implementasi
algoritma K-Nearest Neighbor dalam melakukan pelabelan dari suatu tweet yang
bersifat positif maupun negatif. Evaluasi dilakukan dengan jumlah K atau
tertangga terdekat untuk mengetahui pengaruh pada hasil akurasi pada setiap hasil
prediksi serta kesimpulan akhir dari hasil prediksi.
3.5 Desain Interface
Perangkat lunak ini memiliki satu tampilan antarmuka, yaitu halaman awal
(Gambar 3.2). Halaman awal berisikan tombol browse yang digunakan untuk
memilih file berekstensi .xls dari direktori komputer. Pada kolom K-Fold untuk
memasukan berapa fold yang diinginkan. Pada kolom jumlah tetangga digunakan
untuk menentukan jumlah tetangga yang akan dipilih. Pada tombol proses untuk
digunakan memproses data yang telah dimasukkan untuk menghasilkan akurasi.
Kolom akurasi menampilkan hasil akurasi.
Gambar 3.2 Desian Interface
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

19
3.6 Gambaran Umum Sistem
Gambar 3.3 Gambaran Umum Sistem
Sistem ini digunakan untuk mengetahui tingkat akurasi dari algoritma K-
Nearest Neighbor. Langkah pertama yaitu pengumpulan data sebagai input untuk
sistem. Langkah kedua adalah langkah preprocessing yang terdiri dari Case
Folding, Tokenisasi, Stemming, Normalisasi kata, Stopword Removal dan
pembobotan kata dengan TF-IDF.
3.6.1. Data
Data yang digunakan merupakan data dengan format .xls diambil dari
penelitian sebelumnya. Tweet diambil dengan keyword tokoh publik
Indonesia yang didalamnya terdapat label positif dan negatif, masing –
masing berjumlah 500 tweet. Berikut kumpulan data dan contoh data tweet.
Gambar 3.4 Kumpulan Data
3.6.2. Pre-processing
Pada tahap awal untuk proses klasifikasi menggunakan algoritma k-
nearest neighbor adalah proses preprocessing. Pada tahap ini data mentah
yang berupa teks kumpulan tweet akan menjadi data yang akan masuk dalam
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

20
proses TF-IDF yang nanti setiap kata akan memiliki bobot, sehingga dapat
diproses ketahap selanjutnya.
3.6.2.1 Case folding
Case Folding merupakan tahapan awal dari pre-processing yang
bertujuan untuk mengubah kata-kata yang didapat menjadi format yang
sama. Pada tahapan ini dilakukan dengan mengubah kata menjadi huruf
kecil atau lower case. Berikut merupakan implementasi proses case
folding
Pada tahap ini setelah pengumpulan data didapat, sistem akan
mengubah seluruh kalimat menjadi huruf kecil.
Langkah – langkah case folding :
1. Baca tiap baris pada file text sebagai satu kesatuan dokumen
2. Dokumen yang terdiri dari huruf besar akan di ubah menjadi huruf
kecil.
3. Dokumen disimpan dengan hasil seluruh huruf menjadi huruf kecil
seluruhnya.
Pada langkah – langkah diatas, dapat diimplementasikan pada
kasus klasifikasi ini pada saat pengambilan data yang masih mentah
yang diambil dari twitter berupa tweet. Data ini akan digunakan
sebagai sampel dari proses awal pada tahap pre-processing.
Berikut contoh case folding terhadap tweet :
ketua adalah pemimpin
berprinsip dan cakap
dlm menentukan
pilihan..gerindra
menang!!prabowo
presiden!!
Gambar 3.5 Hasil Proses Case Folding
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

21
3.6.2.2 Tokenisasi
Tokenisasi merupakan tahap sistem akan memotong dokumen
menjadi potongan-potongan kecil menjadi satu kata yang disebut token
serta dilakukan untuk menghilangkan karakter seperti tanda baca. Berikut
merupakan implementasi proses tokenisasi :
Langkah – langkah tokenisasi :
1. Baca tiap dokumen pada file yang merupakan satu tweet.
2. Dari hasil baca tiap tweet ambil masing-masing token pada setiap
kalimat dengan bantuan spasi dijadikan patokan untuk pemisah token
satu dengan yang lain.
3. Simpan hasil dari setiap tweet yang berupa dari token penyusun setiap
kalimat.
Langkah hapus noise :
1. Menghapus username : menghapus kata yang berawalan tanda “@”
misal @gunawan..
2. Menghapus url : menghapus kalimat yang mengandung “www”, “http”
“https”.
3. Menghapus tanda baca, karakter selain huruf, angka.
4. Mengapus kata yang ada dalam tweet seperti tanggal, retweet,
translation, hour, hours, ago.
5. Menghapus kata yang mengandung hashtag misalnya
“#hariantikorupsi”
Berikut contoh tokenizing terhadap tweet :
Gambar 3.6 Proses Hasil Tokenisasi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

22
Gambar 3.7 Hasil Tokenisasi
3.6.2.3 Stemming
Pada tahap ini, setelah proses tokenisasi, hasil token-token untuk
kemudian masuk kedalam proses stemming (Gambar 3.9). Proses ini
dilakukan untuk mengembalikan kata menjadi kata dasar (root word)
dengan cara menghilangkan awalan dan akhiran. Berikut implementasi
stemming :
1. Baca tiap token dari masing-masing dokumen untuk dicocokan dengan
kamus kata dasar.
2. Hasil dari token yang cocok dengan kamus kata dasar yang sudah ada
maka bisa disimpulkan bahwa token tersebut adalah kata dasar.
3. Jika token yang didapat tidak cocok dengan kamus kata dasar, token
dihapus sesuai aturan akhiran dan awalan pada token.
4. Jika pada langkah ke 3 token tidak ditemukan kata dasarnya maka
anggap token tersebut sebagai kata dasar.
Contoh data tweet yang mengalami proses stemming (Gambar 3.8).
Gambar 3.8 Proses Hasil Stemming
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

23
Gambar 3.9 Hasil Stemming
3.6.2.4 Normalisasi Kata
Setelah data melewati proses stemming, langkah selanjutnya adalah
tahap normalisasi kata. Normalisasi dilakukan untuk menghilangkan huruf
yang muncul secara berturut-turut(Gambar 3.11). Berikut implementasi
normalisasi kata :
1. Baca hasil token dari proses stemming dengan kata pada kamus
dari normalisasi
2. Jika hasil token sama dengan kamus maka sudah termasuk kata
normalisasi
3. Jika token memiliki karakter huruf yang melebihi akan dihapus
dan dicari pada kamus normalisasi.
Contoh hasil normalisasi kata (Gambar 3.10).
Gambar 3.10 Proses Hasil Normalisasi Kata
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

24
Gambar 3.11 Contoh Hasil Normalisasi Kata
3.6.2.5 Stopword Removal
Setelah mengalami proses normalisai kata, kemudian token dari
masing-masing tweet diolah melalui proses stopword. Didalam hasil
stopword(Gambar 3.13). Kata-kata yang tidak memiliki arti penting akan
dibuang. Berikut implementasi stopword :
1. Baca tiap token hasil proses normalisasi kata dari setiap dokumen
tweet dengan kata pada kamus dari stopword.
2. Hapus token yang termasuk dalam kamus stoplist.
3. Jika hasil token sama dengan kata yang berada pada stoplist, maka kata
tersebut dibuang.
4. Jika tidak maka kata tetap disimpan.
Contoh hasil proses stopword (Gambar 3.12)
Gambar 3.12 Proses Hasil Stopword Removal
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

25
Gambar 3.13 Contoh Hasil Stopword Removal
3.6.3 Pembobotan TF-IDF
Tahap selanjutnya setelah pre-processing adalah tahap pembobotan
menggunakan tf-idf, dimana pada tahap ini akan menghitung bobot tweet
dihitung dari setiap kata kemudian mengalikan dengan idf. Berikut adalah
implementasi dari pembobotan tf-idf.
Langkah – langkah proses pembobotan tf-idf :
1. Hitung nilai tf dari masing-masing kata.
2. Hitung nilai idf dari masing-masing kata.
3. Hitung bobot dari dari tf dikalikan dengan idf.
4. Ulangi langkah 1 – 3 untuk setiap tweet.
Berikut contoh proses pembobotan kata :
a. Menghitung term frequency
Gambar 3.14 Proses Perhitungan Term Frequency
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
26
Gambar 3.15 Contoh Term Frequency
Pada perhitungan term frequency dihitung dengan menambahkan kata
yang sesuai dengan kata-kata dari setiap tweet untuk ditambahkan jumlah
muncul kata disetiap dokumen. Term Frequency bertujuan untuk
memperhatikan apakah suatu kata ada atau tidak disuatu dokumen, jika kata
tersebut ada dalam suatu dokumen makan akan diberi nilai satu dan bertambah
jika dalam suatu dokumen memiliki lebih dari satu kata muncul.
b. Menghitung document frequency
Gambar 3.16 Proses Perhitungan Document Frequency
Gambar 3.17 Contoh Hasil Document Frequency
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

27
Pada proses perhitungan document frequency adalah melakukan
perhitungan jumlah dokumen yang mengandung suatu term. Dimana jika
suatu term ada di suatu dokumen maka document frequency akan bertambah
satu sampai dokumen terakhir untuk mengetahui jumlah seluruh document
frequency
c. Menghitung inverse document frequency
Gambar 3.18 Proses Perhitungan Inverse Document Frequency
Gambar 3.19 Contoh Hasil Inverse Document Frequency
Pada Proses perhitungan Inverse Document Frequency (idf) dengan
menggunakan persamaan :
IDF = log D/dft
Inverse Document Frequency merupakan sebuah perhitungan dari suatu kata
yang muncul dari dokumen yang bersangkutan. Jumlah dokumen (D) di bagi
dengan jumlah document frequency (DF) atau jumlah kemunculan kata dalam
suatu dokumen.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
28
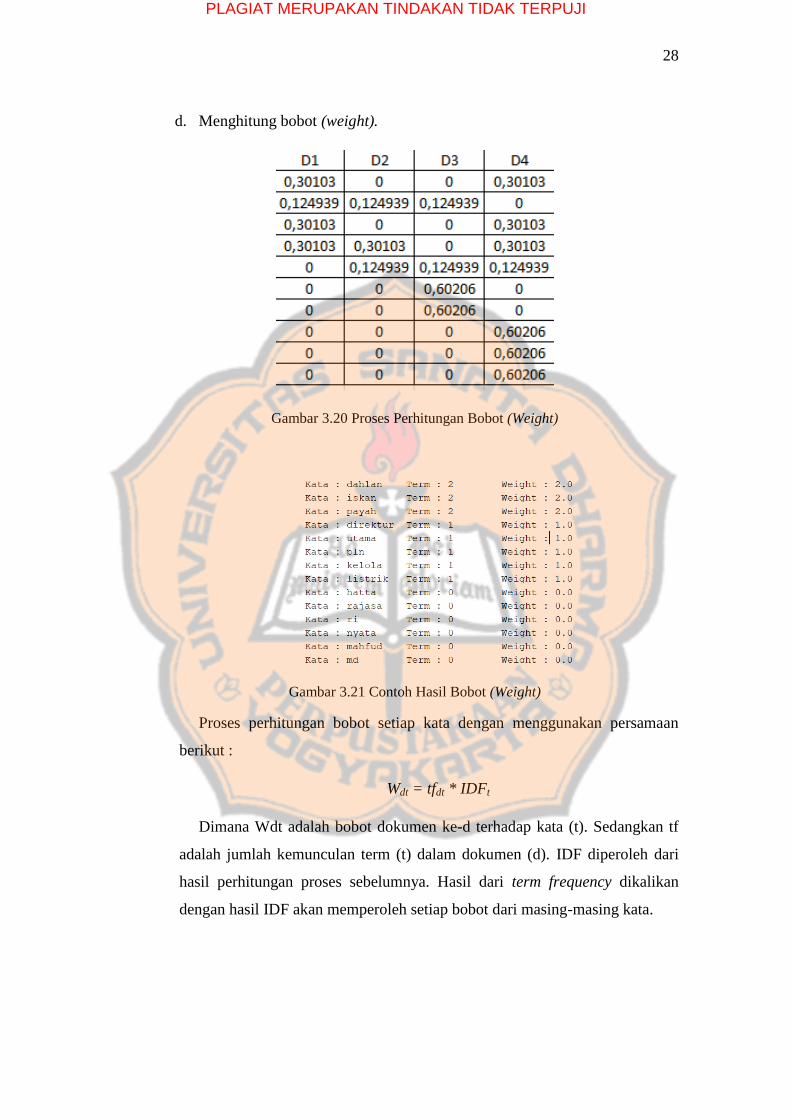
d. Menghitung bobot (weight).
Gambar 3.20 Proses Perhitungan Bobot (Weight)
Gambar 3.21 Contoh Hasil Bobot (Weight)
Proses perhitungan bobot setiap kata dengan menggunakan persamaan
berikut :
Wdt = tfdt * IDFt
Dimana Wdt adalah bobot dokumen ke-d terhadap kata (t). Sedangkan tf
adalah jumlah kemunculan term (t) dalam dokumen (d). IDF diperoleh dari
hasil perhitungan proses sebelumnya. Hasil dari term frequency dikalikan
dengan hasil IDF akan memperoleh setiap bobot dari masing-masing kata.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

29
3.6.4 K-Nearest Neighbor
Setelah didapatkan bobot masing-masing tweet dan vector dari masing-
masing masing tweet. Metode ini mengambil k-tetangga terdekat dan
dilakukan menggunakan mekanisme voting. Jauh dekat dari suatu tetangga
dihitunga dengan penghitungan jara antar tweet. Penghitungan jarak yang
digunakan menggunakan Euclidean distance.
1. Menentukan parameter K (jumlah tetangga paling dekat).
2. Menghitung kuadrat jarak Euclidean masing-masing obyek terhadap
data sampel yang diberikan.
3. Mengurutkan objek-objek tersebut ke dalam kelompok yang memiliki
jarak Euclidean terkecil.
4. Mengumpulkan kategori Y (klasifikasi K-Nearest Neighbor.
5. Dengan menggunakan kategori mayoritas, maka dapat diprediksikan
nilai query instance yang telah dihitung.
3.6.5 Penghitungan Akurasi
Pada penelitian ini penghitungan akurasi adalah hasil yang diprediksi oleh
sistem akan dibandingkan dengan label aktual dari setiap tweet. Kecocokan
dari setiap perbandingkan yang akan mempengaruhi hasil akurasi dari sistem.
Setelah perhitungan K-Nearest Neighbor dilakukan maka pengujian akurasi
dilakukan untuk mengetahui keakuratan hasil klasifikasi. Pada pengujian
akurasi dilakukan menggunakan confusion matriks. Confusion matriks
digunakan untuk mengetahui seberapa besar keberhasilan sistem dalam
melakukan klasifikasi. Confusion matriks mempermudah perhitungan akurasi
dalam melihat suatu permodelan antara class aktual dan presiksi.
Berikut langkah – langkah uji akurasi :
1. Baca label aktual tweet.
2. Baca label tweet hasil dari prediksi sistem.
3. Bandingkan menggunakan tabel confusion matriks.
4. Hitung akurasi dengan cara membagi tweet benar dibagi dengan seluruh
data dikalikan dengan 100%. Menghitung akurasi menggunakan rumus
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

30
Perbandingan contoh hasil prediksi dan aktual (Tabel 3.1)
Tabel 3.1 Contoh Prediksi Confusion Matrix
Prediksi Aktual
Tweet 1 Positif Positif
Tweet 2 Positif Negatif
Tweet 3 Positif Positif
Tweet 4 Positif Positif
Tweet 5 Positif Positif
Tweet 6 Negatif Positif
Tweet 7 Negatif Positif
Tweet 8 Negatif Positif
Tweet 9 Negatif Positif
Tweet 10 Negatif Negatif
Gambar 3.22 Hasil Confusion Matrix
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

31
BAB IV
HASIL DAN ANALISA HASIL
4.1 Hasil & Analisis
Pada penelitian ini, data yang digunakan berupa tweet sebanyak 1000 data
dari masing – masing label adalah 500 label positif dan 500 label negatif. Proses
pertama dilakukan adalah preprocessing. Preprocessing dilakukan dengan tahap
case folding dengan tujuan untuk membuat semua huruf menjadi huruf kecil dan
tokenisasi adalah untuk memisahkan kata dengan menggunakan white space
sebagai patokan untuk memisahkan tiap kata serta menghilangkan tanda baca.
Stemming adalah tahap untuk mengembalikan kata menjadi kata dasar(root word)
dengan menghilangkan kata awalan dan akhiran. Tahap selanjutnya adalah
normalisasi kata, normalisai kata digunakan untuk menghilankgan duplikasi dari
huruf yang berada dalam kata tersebut. Stopword removal dengan tahap ini
bertujuan untuk menghilangkan kata yang tidak begitu memiliki arti penting
diambil dari kamus kata tidak penting. Setelah tahap preprocessing dilakukan
diperoleh kata-kata penting dari masing - masing tweet. Dilakukan pembobotan
kata menggunakan TF-IDF. Pembobotan ini bertujuan untuk menghitung bobot
dari setiap kata dengan cara menghitung frekuensi kemunculan kata dari setiap
tweet dan dikalikan idf untuk mengetahui bobot dari masing-masing kata. Setelah
proses pembobotan, dilakukan proses untuk menghitung jarak dari tweet satu
dengan tweet yang lain untuk digunakan dalam proses pencarian tweet mana yang
berdekat kemudian dilakukan perankingan sesuai K yang telah di tentukan
menggunakan K = 1,3,5,7 diambil mayoritas label yang muncul. Setelah
perankingan dilakukan didapatkan label prediksi yang dilakukan oleh sistem.
Untuk menghitung akurasi sistem dilakukan perhitungan jumlah data diprediksi
benar dibagi dengan jumlah data kemudian dikalikan dengan 100%. Sistem akan
dikatakan tepat jika nilai akurasi didapatkan tinggi dan sebaliknya jika nilai
akurasi didapatkan rendah maka sistem kurang tepat untuk melakukan klasifikasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

32
Berikut adalah langkah – langkah percobaan yang dilakukan
1) Data tweet 1000
2) Tahap preprocessing
3) Pembagian data testing dan training untuk fold validation.
4) Menghitung jarak menggunakan Euclidean distance
5) Perangkingan dari metode K-Nearest Neighbor.
4.1.1 Pengujian Perbandingan Hasil Akurasi K-Nearest Neighbor
Secara Manual dengan Hasil Akurasi K-Nearest Neighbor
Menggunakan Perangkat Lunak
4.1.1.1 Hasil Akurasi K Nearest Neighbor Secara Manual
Pengujian hasil akurasi secara manual menggunakan 10 data dari
1000 data tweet. Proses penghitungan dilakukan dengan
menggunakan Microsoft Excel yang diambil setelah proses
pembobotan TF-IDF. Dalam penghitungan akurasi manual
menggunakan algoritma K-Nearest Neighbor ditetapkan jumlah
tetangga terdekat 1 menggunakan K-Fold 5. Hasil uji secara
manual dapat dilihat pada lampiran.
4.1.1.2 Hasil Akurasi K-Nearest Neighbor Secara Sistem
Pengujian hasil akurasi menggunakan sistem menggunakan 10 data
dari 1000 data tweet. Proses penghitungan dilakukan dengan
memasukkan file .xls kedalam sistem, Dalam penghitungan akurasi
manual menggunakan algoritma K-Nearest Neighbor ditetapkan
jumlah tetangga terdekat 1 menggunakan K-Fold 5.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

33
Gambar 4.1 Hasil akurasi sistem
4.1.1.3 Evaluasi Hasil Prediksi Secara Manual Dan
Sistem
Hasil yang diperoleh dari perhitungan manual sama dengan hasil
dari sistem. Oleh karena itu dapat disimpulkan bahwa sistem dapat
berjalan dengan baik sesuai dengan yang diharapkan penulis.
4.1.2 Dataset
Penelitian ini menggunakan 1000 data tweet yang diambil dari twitter,
pada pengujian dilakukan untuk mencari akurasi tertinggi dengan
menggunakan K-Nearest Neighbor menggunakan 10-fold dengan
menggunakan jumlah tertangga terdekat sebesar 1,3,5,7. Gambar dibawah
ini terkhusus menampilkan hasil percobaan dataset.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

34
Gambar 4.2 Hasil tampilan percobaan
Gambar 4.3 Akurasi 10-fold
Dari gambar 4. Bisa dilihat akurasi tertinggi dari 10-fold yaitu 67,5%
dengan nilai K=1.
67.5
62.7
57.6
54.4
50
55
60
65
70
1 3 5 7
Pre
sen
tase
K-tetangga terdekat
Akurasi 10-fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
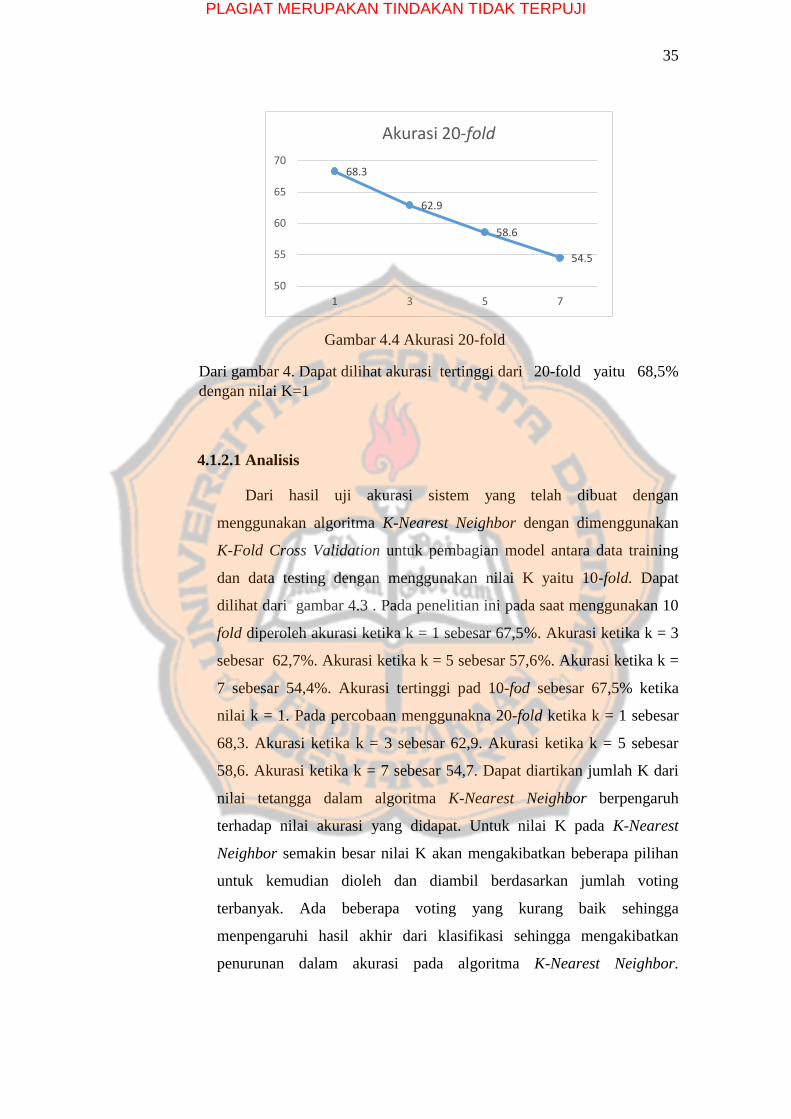
35
Gambar 4.4 Akurasi 20-fold
Dari gambar 4. Dapat dilihat akurasi tertinggi dari 20-fold yaitu 68,5%
dengan nilai K=1
4.1.2.1 Analisis
Dari hasil uji akurasi sistem yang telah dibuat dengan
menggunakan algoritma K-Nearest Neighbor dengan dimenggunakan
K-Fold Cross Validation untuk pembagian model antara data training
dan data testing dengan menggunakan nilai K yaitu 10-fold. Dapat
dilihat dari gambar 4.3 . Pada penelitian ini pada saat menggunakan 10
fold diperoleh akurasi ketika k = 1 sebesar 67,5%. Akurasi ketika k = 3
sebesar 62,7%. Akurasi ketika k = 5 sebesar 57,6%. Akurasi ketika k =
7 sebesar 54,4%. Akurasi tertinggi pad 10-fod sebesar 67,5% ketika
nilai k = 1. Pada percobaan menggunakna 20-fold ketika k = 1 sebesar
68,3. Akurasi ketika k = 3 sebesar 62,9. Akurasi ketika k = 5 sebesar
58,6. Akurasi ketika k = 7 sebesar 54,7. Dapat diartikan jumlah K dari
nilai tetangga dalam algoritma K-Nearest Neighbor berpengaruh
terhadap nilai akurasi yang didapat. Untuk nilai K pada K-Nearest
Neighbor semakin besar nilai K akan mengakibatkan beberapa pilihan
untuk kemudian dioleh dan diambil berdasarkan jumlah voting
terbanyak. Ada beberapa voting yang kurang baik sehingga
menpengaruhi hasil akhir dari klasifikasi sehingga mengakibatkan
penurunan dalam akurasi pada algoritma K-Nearest Neighbor.
68.3
62.9
58.6
54.5
50
55
60
65
70
1 3 5 7
Akurasi 20-fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

36
BAB V
PENUTUP
5.1 Kesimpulan
Berdasarkan hasil penelitian, klasifikasi terhadap tokoh publik pada twitter
menggunakan algoritma k-nearest neighbor dengan menggunakan 1000 data
diperoleh kesimpulan sebagai berikut :
1) Pengujian klasifikasi sentimen terhadap tokoh publik pada twitter
menggunakan algoritma K-Nearest Neighbor. Berdasarkan hasil
percobaan, didapatkan akurasi tertinggi pada dataset menggunakan
metode evaluasi 10-fold validation dengan pembagian dataset
seimbang antara jumlah label postif dan label negatif,
menghasikan akurasi terbaik sebesar 67,5%.
2) Pengujian klasifikasi sentimen terhadap tokoh publik pada twitter
menggunakan algoritma K-Nearest Neighbor. Berdasarkan hasil
percobaan, didapatkan akurasi tertinggi pada dataset menggunakan
metode evaluasi 20-fold cross validation dengan pembagian
dataset seimbang antara jumlah label postif dan label negatif,
menghasikan akurasi terbaik sebesar 68,3%
3) Dari hasil ini dapat disimpulkan bahawa sistem mampu melakukan
klasifikasi dengan tingkat akurasi yang kurang baik.
5.2 Saran
Berikut saran yang dapat membatu untuk penelitian agar lebih baik dan
berkembang :
1) Kamus bahasa dalam bahasa Indonesia cukup banyak dapat
ditambahkan kamus untuk penambahan dari kata dasar dan kamus
bahasa slang.
2) Sistem tidak hanya dapat menerima data mengunakan file yang
berekstensi .xls.
3) Data dapat diambil secara otomatis dari twitter.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

37
DAFTAR PUSTAKA
Aliandu, P. 2012, Analisis Sentimen Tweet Berbahasa Indonesia di Twitter, Tesis,
Program Studi S2 Ilmu Komputer, Fakultas Matematika Dan Ilmu
Pengetahuan Alam, Universitas Gadjah Mada, Yogyakarta.
Darma, I. M. 2017. Penerapan Sentimen Analisis Acara Televisi Pada Twitter
Menggunakan Support Vector Machine dan Algoritma Genetika. Jurnal
Pengembangan Teknologi Informasi dan Ilmu Komputer , 998-1007.
Haryanto, D. J., Muflikhah, L., Fauzi, M. A. Analisis Sentimen Review Barang
Berbahasa Indonesia Dengan Metode Support Vector Machine Dan Query
Expansion. Jurnal Pengembangan Teknologi Informasi dan Ilmu
Komputer. Vol. 2, No.9, September 2018. 2909-2916.
Hidayatullah, A. F., Azhari S.N. 2014. Analisis Sentimen Dan Klasifikasi
Kategori Terhadap Tokoh Publik Pada Twitter. Jurnal Jurusan Teknik
Informatika Fakultas Teknologi Industri, Universitas Islam Indonesia,
Agustus 2014.
Hirzani1, F. A., Maharani W., Bijaksana, Moch. A. 2015. Analisis Sentimen
Review Produk Menggunakan Pendekatan Berbasis Kamus. e-Proceeding
of Engineering. Vol.2, No.2, Agustus 2015
Rivki, M., Bachtiar, A. M. 2017. Implementasi Algoritma K-Nearest Neighbor
Dalam Pengklasifikasian Follower Twitter Yang Menggunakan Bahasa
Indonesia. Jurnal Sistem Informasi (Journal of Information Systems),
Universitas Komputer Indonesia
Salam, A., Zeniarja J., Khasanah R. S. U. Analisis Sentimen Data Komentar
Sosial Media Facebook Dengan K-Nearest Neighbor (Studi Kasus Pada
Akun Jasa Ekspedisi Barang J&T Ekspress Indonesia. Jurnal Program
Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Dian
Nuswantoro.
Sendhy, R. W., Sendi N., Umi R. 2017.Perbandingan Euclidean Distance Dengan
Canberra Distance Pada Face Recognition. Jurnal Fakultas Ilmu
Komputer, Universitas Dian Nuswantoro Semarang.
Sianipar, R., Setiawan, E. B. 2015 Pendeteksian Kekuatan Sentimen Pada Teks
Tweet Berbahasa Indonesia Menggunakan Sentistrength. e-Proceeding of
Engineering. Vol.2, No.3, Desember 2015.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

38
LAMPIRAN
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
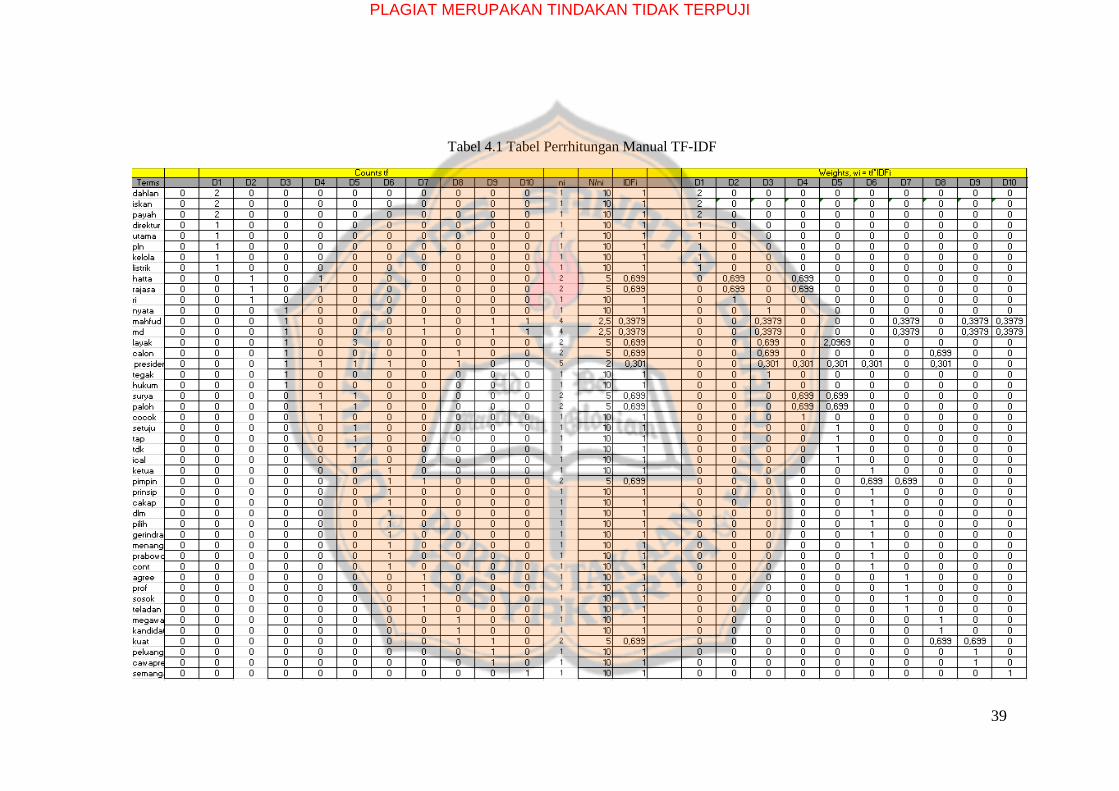
39
Tabel 4.1 Tabel Perrhitungan Manual TF-IDF
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
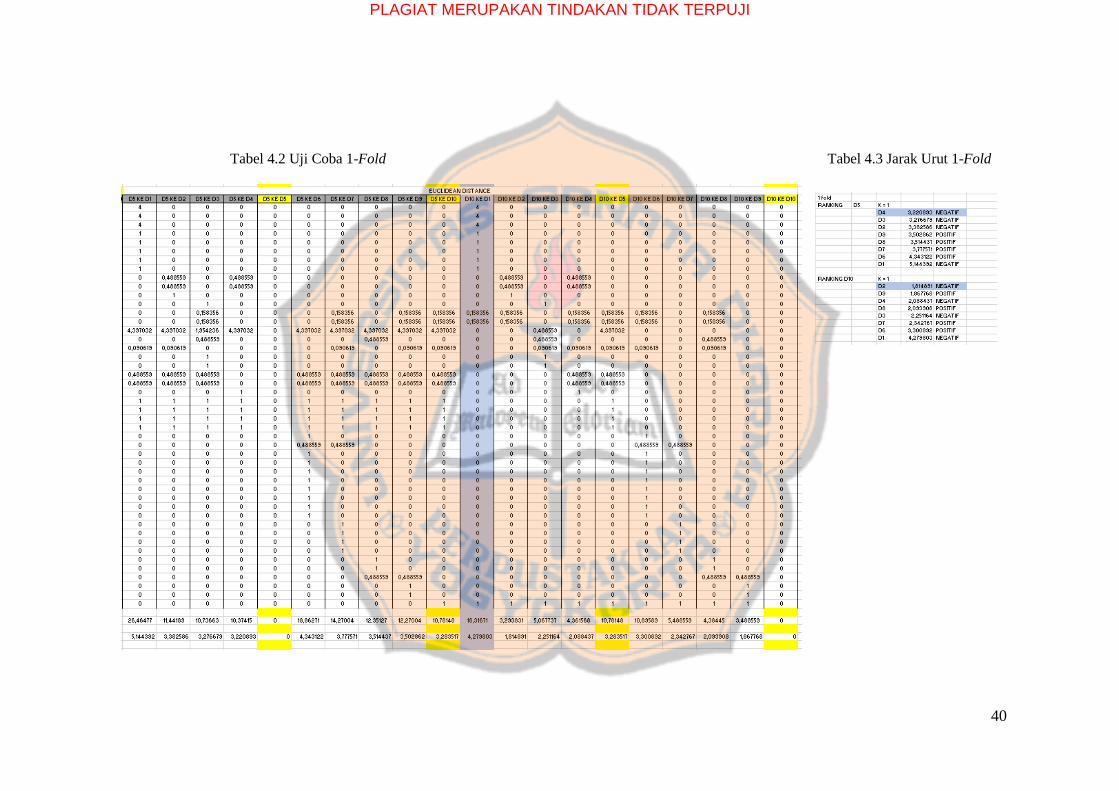
40
Tabel 4.2 Uji Coba 1-Fold Tabel 4.3 Jarak Urut 1-Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
41
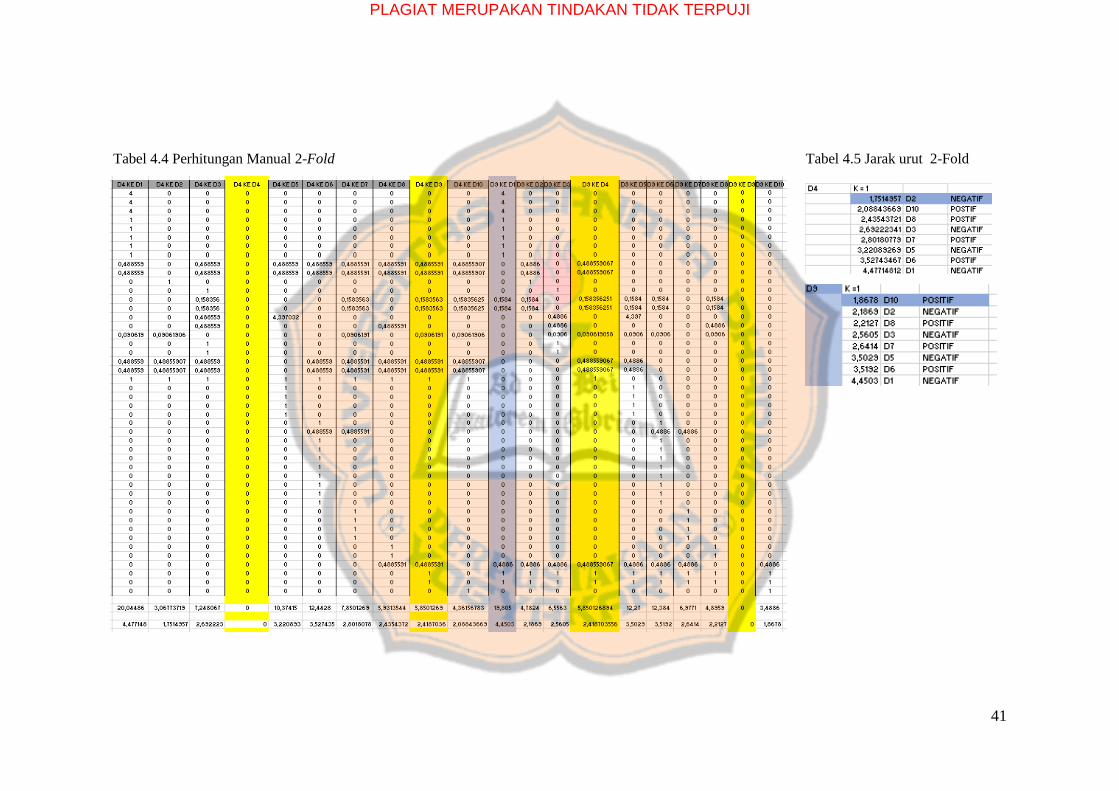
Tabel 4.4 Perhitungan Manual 2-Fold Tabel 4.5 Jarak urut 2-Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
42
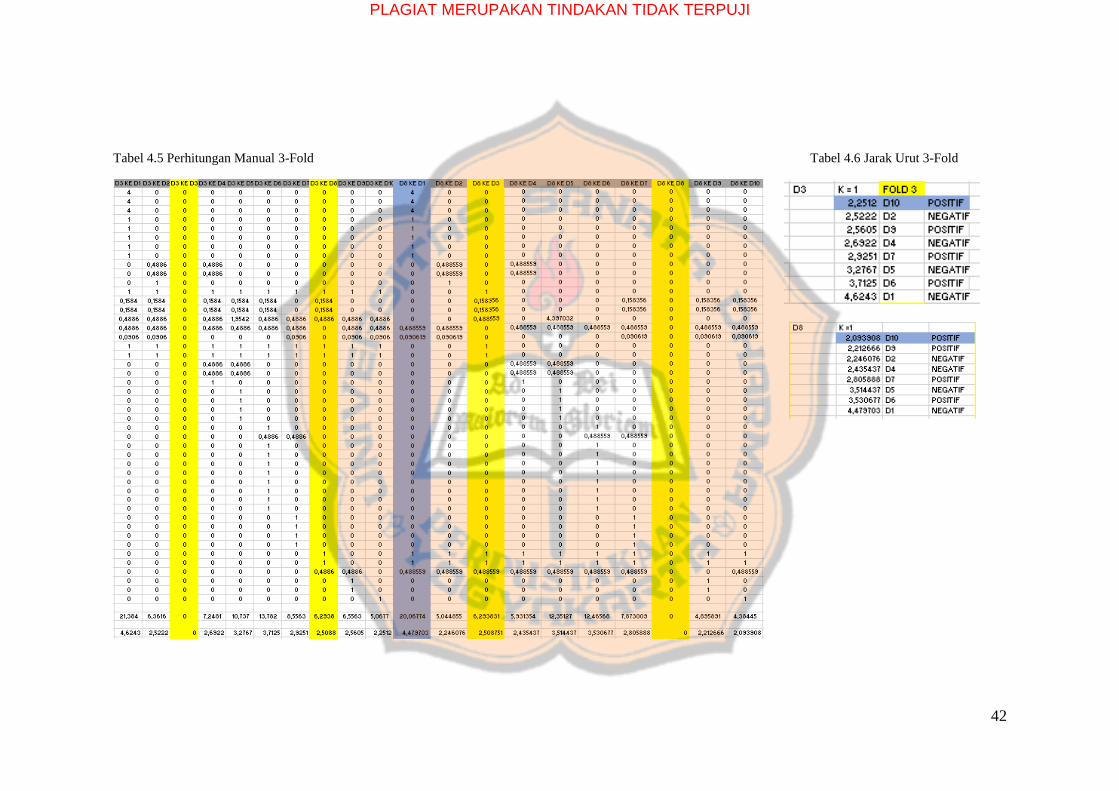
Tabel 4.5 Perhitungan Manual 3-Fold Tabel 4.6 Jarak Urut 3-Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
43
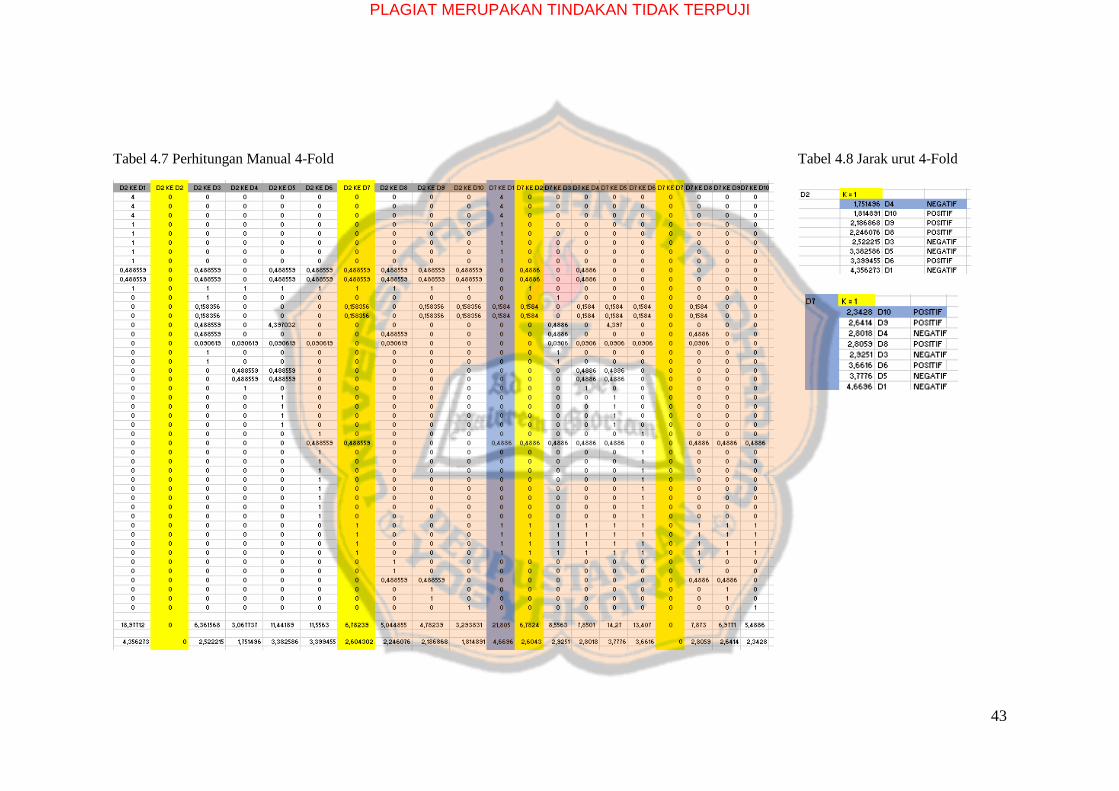
Tabel 4.7 Perhitungan Manual 4-Fold Tabel 4.8 Jarak urut 4-Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
44
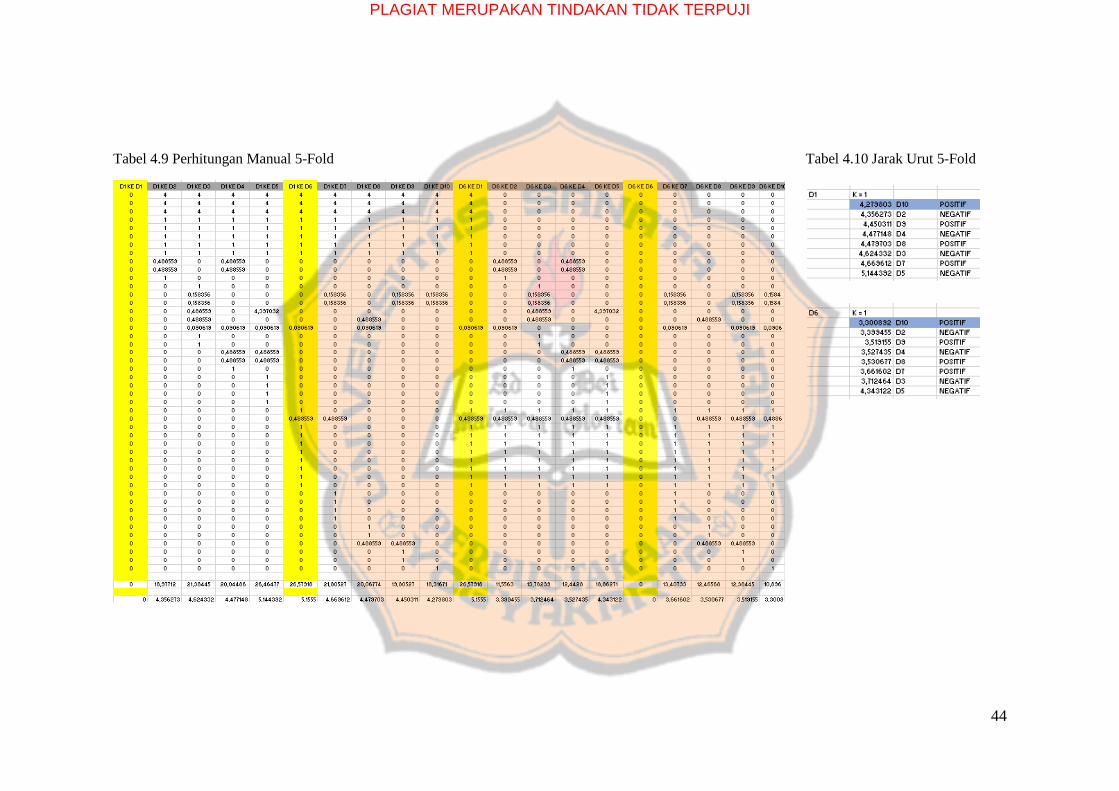
Tabel 4.9 Perhitungan Manual 5-Fold Tabel 4.10 Jarak Urut 5-Fold
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

45
Tabel 4.11 Confusion Matrik 1 Tabel 4.12 Confusion Matrik 2 Tabel 4.13 Confusion Matrik 3
Tabel 4.14 Confusion Matrik 4 Tabel 4.15 Confusion Matrik 5 Tabel 4.16 Akurasi Total
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI




















