
Data Mining -...
32
Metode Klasterisasi K-Means Data Mining
Transcript of Data Mining -...

Metode Klasterisasi K-Means
Data Mining

Pokok Pembahasan
1. Konsep Dasar Clustering
2. Tahapan Clustering
3. K-Means Clustering
Algoritma K-Means
Rumus Umum K-Means
4. Case Study

• Klusterisasi Data, atau Data Clustering (atau
Clustering), juga disebut sebagai analisis
klaster, analisis segmentasi, analisis taxonomi,
atau unsupervised classification.
• Metode yang digunakan untuk membangun
grup dari objek-objek, atau klaster-klaster,
dimana objek-objek dalam satu kluster tertentu
memiliki kesamaan ciri yang tinggi dan objek-
objek pada kluster yang berbeda memiliki
kesamaan ciri yang rendah.
Konsep Dasar

• Tujuan dari klasterisasi data adalah
mengelompokkan data yang memiliki
kesamaan ciri dan memisahkan data ke dalam
klaster yang berbeda untuk objek-objek yang
memiliki ciri yang berbeda.
• Berbeda dengan klasifikasi, yang memiliki
kelas yang telah didefinisikan sebelumnya.
Dalam klasterisasi, klaster akan terbentuk
sendiri berdasarkan ciri objek yang dimiliki dan
kriteria pengelompokan yang telah ditentukan.
Konsep Dasar

• Untuk menunjukkan klasterisasi dari
sekumpulan data, suatu kriteria
pengelompokan haruslah ditentukan
sebelumnya secara random.
• Perbedaan kriteria pengelompokan akan
memberikan dampak perbedaan hasil
akhir dari klaster yang terbentuk.
Konsep Dasar

• Dua klaster dengan kriteria berdasarkan “Bagaimana
cara hewan mamalia berkembang biak”.
• Dua klaster dengan kriteria berdasarkan “Keberadaanparu-paru”.
Contoh
Blue shark,
sheep, cat,
dog
Lizard, sparrow,
viper, seagull, gold
fish, frog, red
mullet
Gold fish, red
mullet, blue
shark
Sheep, sparrow,
dog, cat, seagull,
lizard, frog, viper

1. Feature Selection
– Penentuan informasi fitur yang digunakan.
2. Proximity Measure
– Tahap kuantifikasi item kemiripan data.
3. Clustering Criterion
– Penentuan fungsi pembobotan / tipe aturan.
4. Clustering Algorithm
– Metode klaster berdasarkan ukuran kemiripan data dan kriteria
klasterisasi.
5. Validation of the Result
6. Interpretation of the Result
Tahapan Klasterisasi

Proximity Measure
• Kemiripan data memiliki peranan yang sangat
penting dalam proses analisis klaster.
• Pada berbagai literatur tentang clustering,
ukuran kemiripan (similarity measures),
koefisien kemiripan (similarity coefficients),
ukuran ketidakmiripan (dissimilarity measures),
atau jarak (distances) digunakan untuk
mendeskripsikan nilai kuantitatif dari kemiripan
atau ketidakmiripan dari dua titik atau dua
klaster data.

Proximity Measure
• Koefisien kemiripan menunjukkan kekuatan
hubungan antara dua data.
• Semakin banyak kemiripan titik data satu sama
lain, maka semakin besar koefisien kesamaan.
• Misalkan x = (x1, x2, ..., xd) dan y = (y1, y2, ..., yd)
adalah dua titik data pada d dimensi. Maka nilai
koefisien kemiripan antara x dan y adalah
beberapa nilai atribut fungsi s(x,y) = s(x1, x2, ..., xd,
y1, y2, ..., yd).

Proximity Measure
• Pemilihan jarak pada clustering adalah sangat penting, dan pilihan yang
terbaik sering diperoleh melalui pengalaman, kemampuan, pengetahuan.
• Pengukuran Jarak Data :
– Numerik dengan banyak fitur atau dimensi (d) :
- Euclidean Distance : - Minkowski Distance :
- Manhattan Distance : - Mahalanobis Distance :
- Maximum Distance : - Average Distance :
– Kategorikal :
- Simple Matching Distance
2
1
1
2),(
d
j
jjeuclid yxyxd
d
j
jjman yxyxd1
),(
jjdj
yxyxd ..1
max max),(
1,),(
1
1
minkow
ryxyxdrd
j
r
jj
T
mah yxyxyxd 1),(
2
1
1
21),(
d
j
jjave yxd
yxd
yxif
yxifyx
1
0),(
d
j
jjsim yxyxd1
,),(

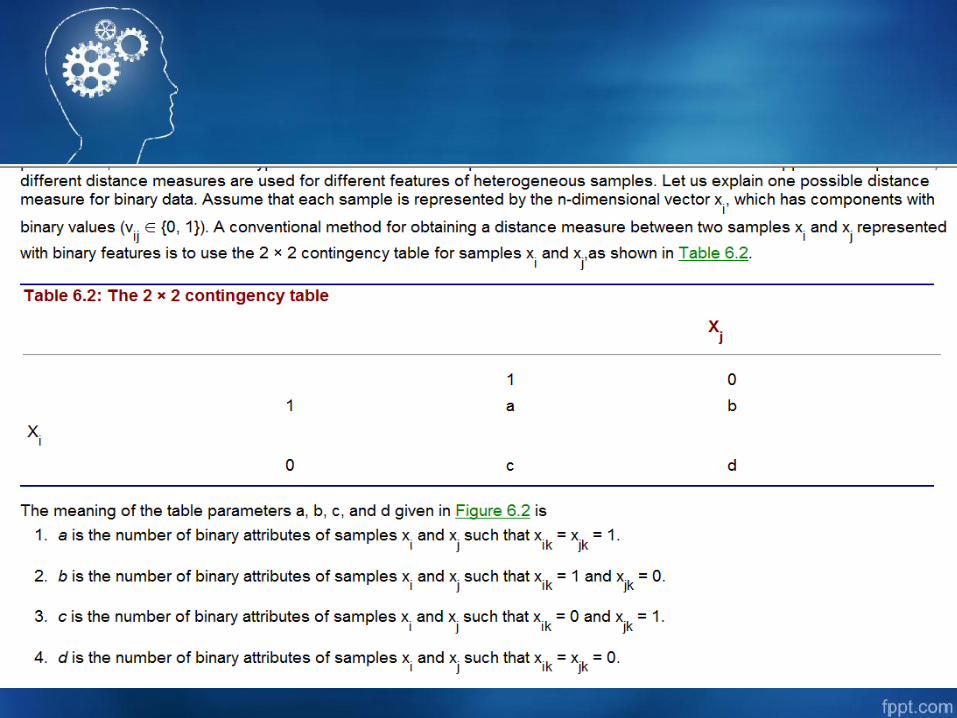

Proximity Measure
• Jika x1=(1,2) dan x2=(2,3). Hitunglah Jarak x1 dan x2 dengan Euclidean!
• Jika Hitunglah Jarak x1 dan x2 dengan Mahalanobis!
(Note : Mahalanobis biasanya digunakan untuk menghitung jarak antar cluster)
– Hitung Mean Corected Matrix
– Hitung Matrik Covarian (Ci)
4.122113221),( 2
12
1222
122
2
1
1
2
2121
d
jjjeuclid xxxxd
0
ix
32
43
21
1x
17
552x
323
342
3
2311
x 36
2
15
2
752
x
00
11
11
3322
3423
32210
1x
21
21
3167
35650
2x
7.07.0
7.07.0
22
22
3
1
00
11
11
011
011
3
11 0
1
0
1
1
1 xxn
CT
42
21
84
42
2
1
21
21
22
11
2
11 0
2
0
2
2
2 xxn
CT

Proximity Measure
• Jika Hitunglah Jarak x1 dan x2 dengan mahalanobis!
– Hitung Matrik Covarian (Ci)
32
43
21
1x
17
552x
7.07.0
7.07.0
22
22
3
1
00
11
11
011
011
3
11 0
1
0
1
1
1 xxn
CT
42
21
84
42
2
1
21
21
22
11
2
11 0
2
0
2
2
2 xxn
CT
24.0
4.08.0
6.18.0
8.04.0
4.04.0
4.04.0
42
21
5
2
7.07.0
7.07.0
5
3
5
111 2
1
2
1211 i
ii
i
ii
n
i
ii CnCnnn
Cnn
group
6.03.0
3.04.1
8.04.0
4.02
44.1
1
8.04.0
4.02
4.0*4.02*8.0
111 Adj

Proximity Measure
• Jika Hitunglah Jarak x1 dan x2 dengan mahalanobis!
– Hitung Mean Different (X1,X2) :
7.42.220
41.16.5
0
4
6.03.0
3.04.104,,),( 21
1
2121
T
mah xxxxxxd
32
43
21
1x
17
552x
6.03.0
3.04.1
8.04.0
4.02
44.1
1
8.04.0
4.02
4.0*4.02*8.0
111 Adj
043362, 21 xx
362
15
2
752
x 32
3
342
3
2311
x
T
mah xxxxxxd 21
1
2121 ),(

K-Means• K-Means termasuk partitioning clustering
yang memisahkan data ke k daerah
bagian yang terpisah.
• K-Means sangat terkenal karena
kemudahan dan kemampuannya untuk
mengklaster data besar dan data outlier
dengan sangat cepat.
• Setiap data harus masuk cluster tertentu.

K-Means• Kelemahan metode ini memungkinkan bagi
setiap data yang termasuk cluster tertentu pada
suatu tahapan proses, pada tahapan berikutnya
berpindah ke cluster yang lain.
• Prinsip utama dari teknik ini adalah menyusun k
buah prototipe/pusat massa (centroid)/rata-rata
(mean) dari sekumpulan data berdimensi n.
• Teknik ini mensyaratkan nilai k sudah diketahui
sebelumnya (a priori)

K-MeansAlgoritma K-Means adalah seperti berikut :1. Tentukan k (jumlah cluster) yang ingin dibentuk
2. Bangkitkan k centroid (titik pusat cluster) awal secara
random
3. Hitung jarak setiap data ke masing-masing centroid.
4. Kelompokkan obyek berdasar jarak minimum
5. Tentukan posisi centroid baru (Ck) untuk semua cluster
dengan cara menghitung nilai rata-rata dari data-data
yang berada pada cluster yang sama.
6. Kembali ke langkah 3 jika posisi centroid baru dan
centroid lama tidak sama
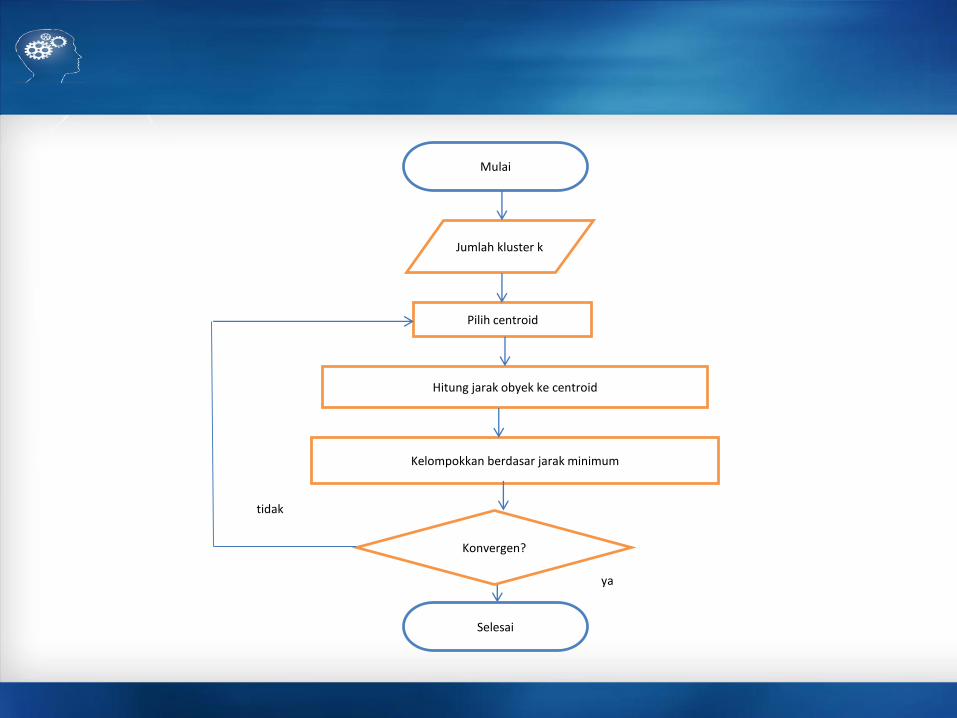
Mulai
Jumlah kluster k
Pilih centroid
Hitung jarak obyek ke centroid
Kelompokkan berdasar jarak minimum
Konvergen?
Selesai
tidak
ya

Rumus Umum K-Means
• Menentukan Centroid (Titik Pusat) setiap kelompok diambil dari nilai rata-
rata (Means) semua nilai data pada setiap fiturnya. Jika M menyatakan
jumlah data pada suatu kelompok, i menyatakan fitur ke-i dalam sebuah
kelompok, berikut rumus untuk menghitung centroid :
• Hitung jarak titik terdekat (Euclidean Distance):
• Pengalokasian keanggotaan titik :
M
j
ji xM
C1
1
p
j
jj xxxxD1
2
1212 ,
lainnya
CxDda
ij
ji,0
)),(min(,1
• Fungsi Objektif :
N
j
K
i
ijji CxDaF1 1
),(
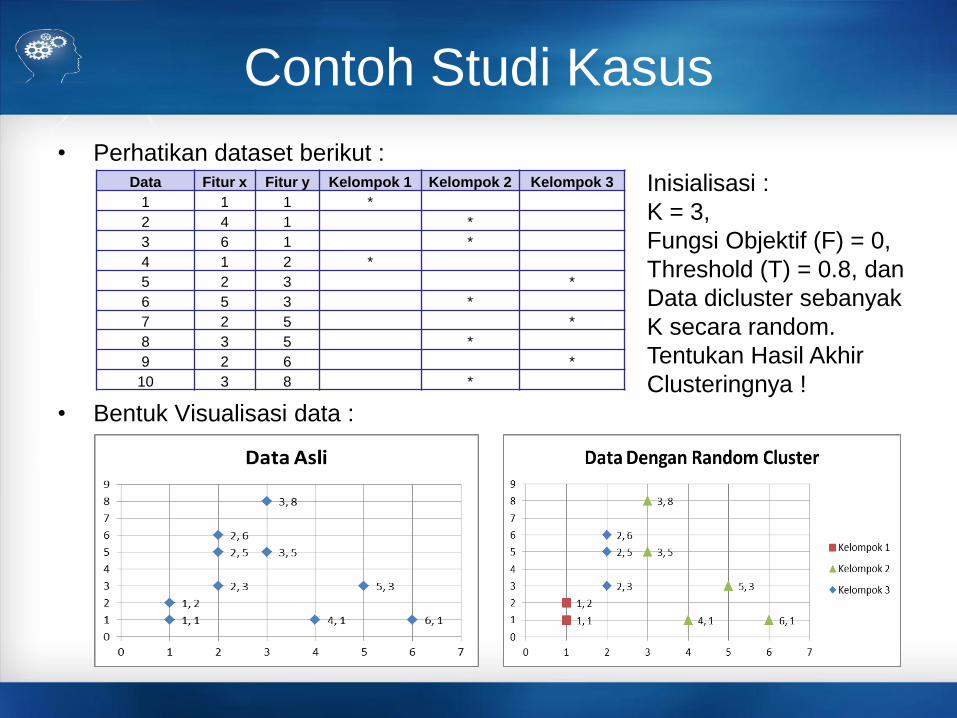
Contoh Studi Kasus
• Perhatikan dataset berikut :
• Bentuk Visualisasi data :
Data Fitur x Fitur y Kelompok 1 Kelompok 2 Kelompok 3
1 1 1 *
2 4 1 *
3 6 1 *
4 1 2 *
5 2 3 *
6 5 3 *
7 2 5 *
8 3 5 *
9 2 6 *
10 3 8 *
Inisialisasi :
K = 3,
Fungsi Objektif (F) = 0,
Threshold (T) = 0.8, dan
Data dicluster sebanyak
K secara random.
Tentukan Hasil Akhir
Clusteringnya !
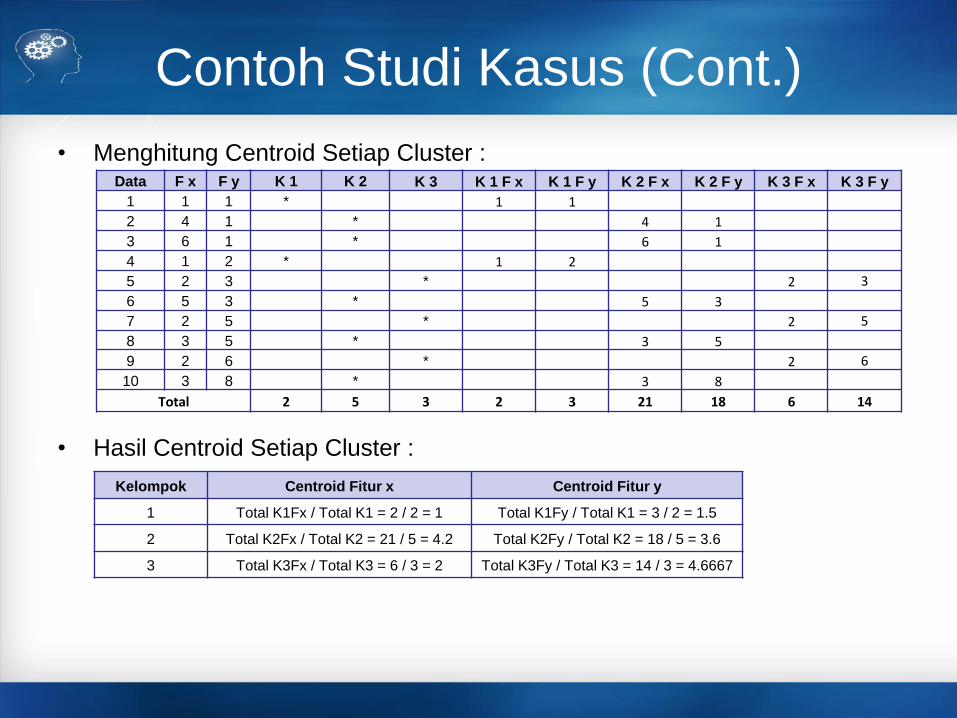
Contoh Studi Kasus (Cont.)
• Menghitung Centroid Setiap Cluster :
• Hasil Centroid Setiap Cluster :
Data F x F y K 1 K 2 K 3 K 1 F x K 1 F y K 2 F x K 2 F y K 3 F x K 3 F y
1 1 1 * 1 1
2 4 1 * 4 1
3 6 1 * 6 1
4 1 2 * 1 2
5 2 3 * 2 3
6 5 3 * 5 3
7 2 5 * 2 5
8 3 5 * 3 5
9 2 6 * 2 6
10 3 8 * 3 8
Total 2 5 3 2 3 21 18 6 14
Kelompok Centroid Fitur x Centroid Fitur y
1 Total K1Fx / Total K1 = 2 / 2 = 1 Total K1Fy / Total K1 = 3 / 2 = 1.5
2 Total K2Fx / Total K2 = 21 / 5 = 4.2 Total K2Fy / Total K2 = 18 / 5 = 3.6
3 Total K3Fx / Total K3 = 6 / 3 = 2 Total K3Fy / Total K3 = 14 / 3 = 4.6667
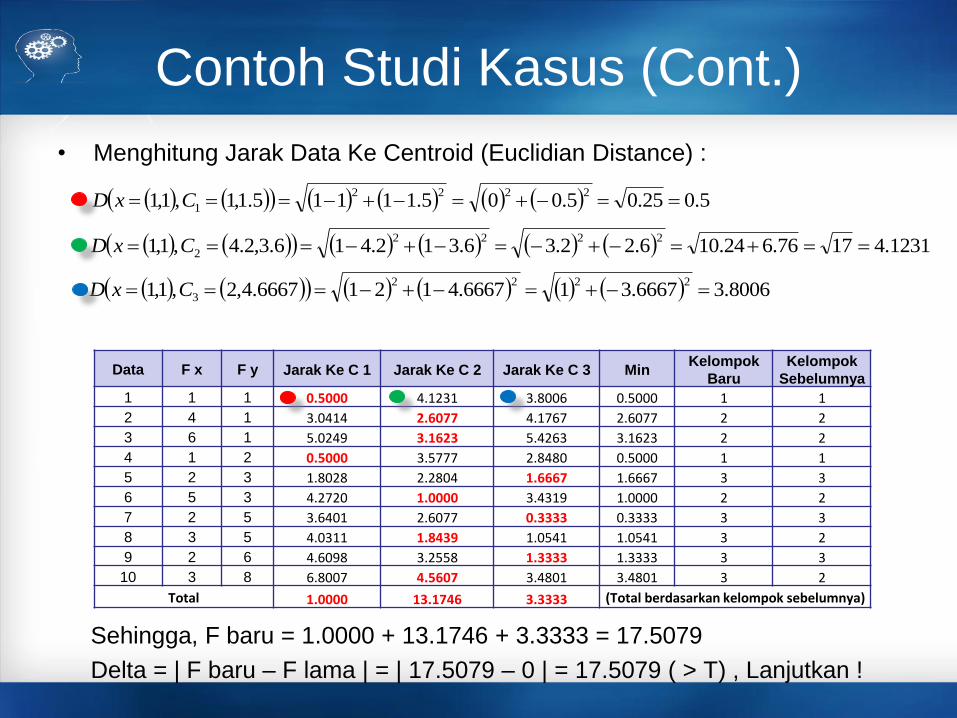
Contoh Studi Kasus (Cont.)
• Menghitung Jarak Data Ke Centroid (Euclidian Distance) :
Sehingga, F baru = 1.0000 + 13.1746 + 3.3333 = 17.5079
Delta = | F baru – F lama | = | 17.5079 – 0 | = 17.5079 ( > T) , Lanjutkan !
Data F x F y Jarak Ke C 1 Jarak Ke C 2 Jarak Ke C 3 MinKelompok
Baru
Kelompok
Sebelumnya
1 1 1 0.5000 4.1231 3.8006 0.5000 1 1
2 4 1 3.0414 2.6077 4.1767 2.6077 2 2
3 6 1 5.0249 3.1623 5.4263 3.1623 2 2
4 1 2 0.5000 3.5777 2.8480 0.5000 1 1
5 2 3 1.8028 2.2804 1.6667 1.6667 3 3
6 5 3 4.2720 1.0000 3.4319 1.0000 2 2
7 2 5 3.6401 2.6077 0.3333 0.3333 3 3
8 3 5 4.0311 1.8439 1.0541 1.0541 3 2
9 2 6 4.6098 3.2558 1.3333 1.3333 3 3
10 3 8 6.8007 4.5607 3.4801 3.4801 3 2
Total 1.0000 13.1746 3.3333 (Total berdasarkan kelompok sebelumnya)
5.025.05.005.11115.1,1,1,12222
1 CxD
1231.41776.624.106.22.36.312.416.3,2.4,1,12222
2 CxD
8006.36667.314.66671214.6667,2,1,12222
3 CxD
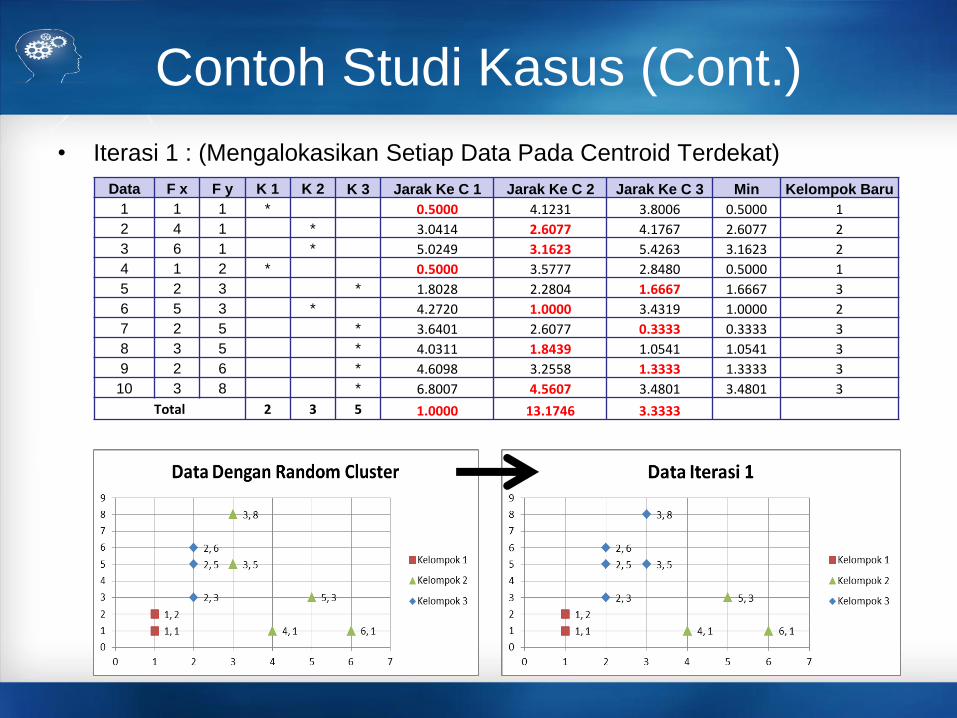
Contoh Studi Kasus (Cont.)
• Iterasi 1 : (Mengalokasikan Setiap Data Pada Centroid Terdekat)
Data F x F y K 1 K 2 K 3 Jarak Ke C 1 Jarak Ke C 2 Jarak Ke C 3 Min Kelompok Baru
1 1 1 * 0.5000 4.1231 3.8006 0.5000 1
2 4 1 * 3.0414 2.6077 4.1767 2.6077 2
3 6 1 * 5.0249 3.1623 5.4263 3.1623 2
4 1 2 * 0.5000 3.5777 2.8480 0.5000 1
5 2 3 * 1.8028 2.2804 1.6667 1.6667 3
6 5 3 * 4.2720 1.0000 3.4319 1.0000 2
7 2 5 * 3.6401 2.6077 0.3333 0.3333 3
8 3 5 * 4.0311 1.8439 1.0541 1.0541 3
9 2 6 * 4.6098 3.2558 1.3333 1.3333 3
10 3 8 * 6.8007 4.5607 3.4801 3.4801 3
Total 2 3 5 1.0000 13.1746 3.3333
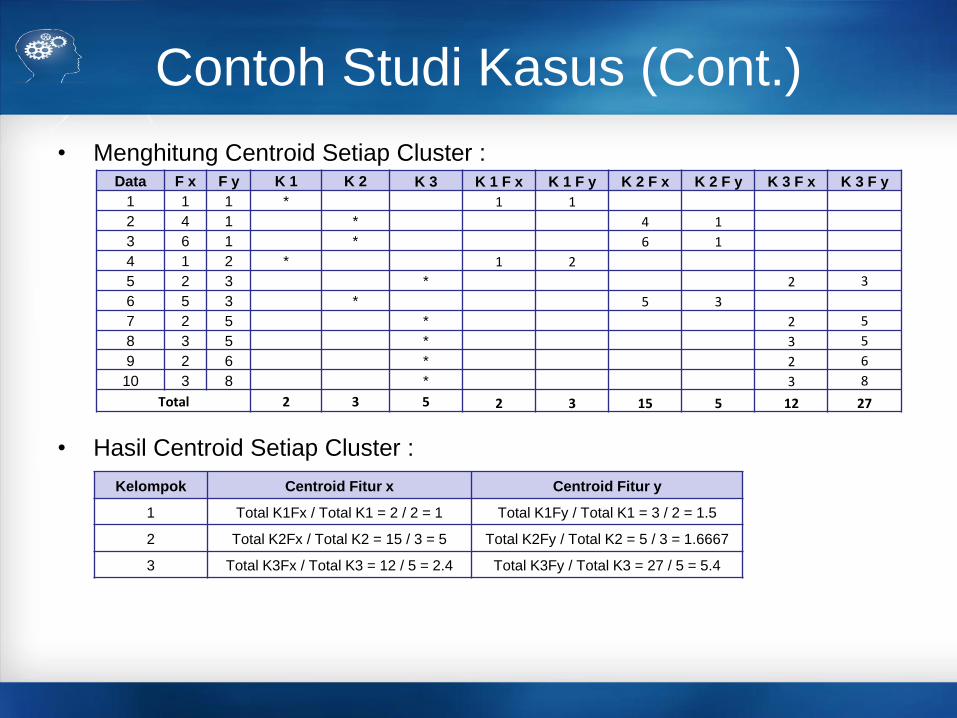
Contoh Studi Kasus (Cont.)
• Menghitung Centroid Setiap Cluster :
• Hasil Centroid Setiap Cluster :
Data F x F y K 1 K 2 K 3 K 1 F x K 1 F y K 2 F x K 2 F y K 3 F x K 3 F y
1 1 1 * 1 1
2 4 1 * 4 1
3 6 1 * 6 1
4 1 2 * 1 2
5 2 3 * 2 3
6 5 3 * 5 3
7 2 5 * 2 5
8 3 5 * 3 5
9 2 6 * 2 6
10 3 8 * 3 8
Total 2 3 5 2 3 15 5 12 27
Kelompok Centroid Fitur x Centroid Fitur y
1 Total K1Fx / Total K1 = 2 / 2 = 1 Total K1Fy / Total K1 = 3 / 2 = 1.5
2 Total K2Fx / Total K2 = 15 / 3 = 5 Total K2Fy / Total K2 = 5 / 3 = 1.6667
3 Total K3Fx / Total K3 = 12 / 5 = 2.4 Total K3Fy / Total K3 = 27 / 5 = 5.4
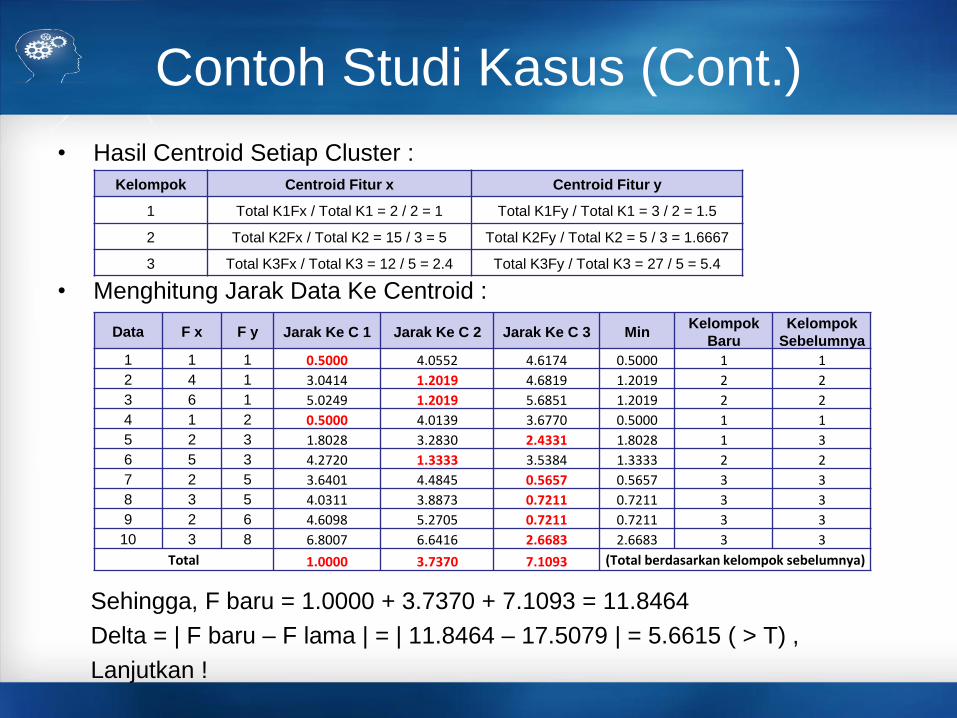
Contoh Studi Kasus (Cont.)
• Hasil Centroid Setiap Cluster :
• Menghitung Jarak Data Ke Centroid :
Sehingga, F baru = 1.0000 + 3.7370 + 7.1093 = 11.8464
Delta = | F baru – F lama | = | 11.8464 – 17.5079 | = 5.6615 ( > T) ,
Lanjutkan !
Data F x F y Jarak Ke C 1 Jarak Ke C 2 Jarak Ke C 3 MinKelompok
Baru
Kelompok
Sebelumnya
1 1 1 0.5000 4.0552 4.6174 0.5000 1 1
2 4 1 3.0414 1.2019 4.6819 1.2019 2 2
3 6 1 5.0249 1.2019 5.6851 1.2019 2 2
4 1 2 0.5000 4.0139 3.6770 0.5000 1 1
5 2 3 1.8028 3.2830 2.4331 1.8028 1 3
6 5 3 4.2720 1.3333 3.5384 1.3333 2 2
7 2 5 3.6401 4.4845 0.5657 0.5657 3 3
8 3 5 4.0311 3.8873 0.7211 0.7211 3 3
9 2 6 4.6098 5.2705 0.7211 0.7211 3 3
10 3 8 6.8007 6.6416 2.6683 2.6683 3 3
Total 1.0000 3.7370 7.1093 (Total berdasarkan kelompok sebelumnya)
Kelompok Centroid Fitur x Centroid Fitur y
1 Total K1Fx / Total K1 = 2 / 2 = 1 Total K1Fy / Total K1 = 3 / 2 = 1.5
2 Total K2Fx / Total K2 = 15 / 3 = 5 Total K2Fy / Total K2 = 5 / 3 = 1.6667
3 Total K3Fx / Total K3 = 12 / 5 = 2.4 Total K3Fy / Total K3 = 27 / 5 = 5.4
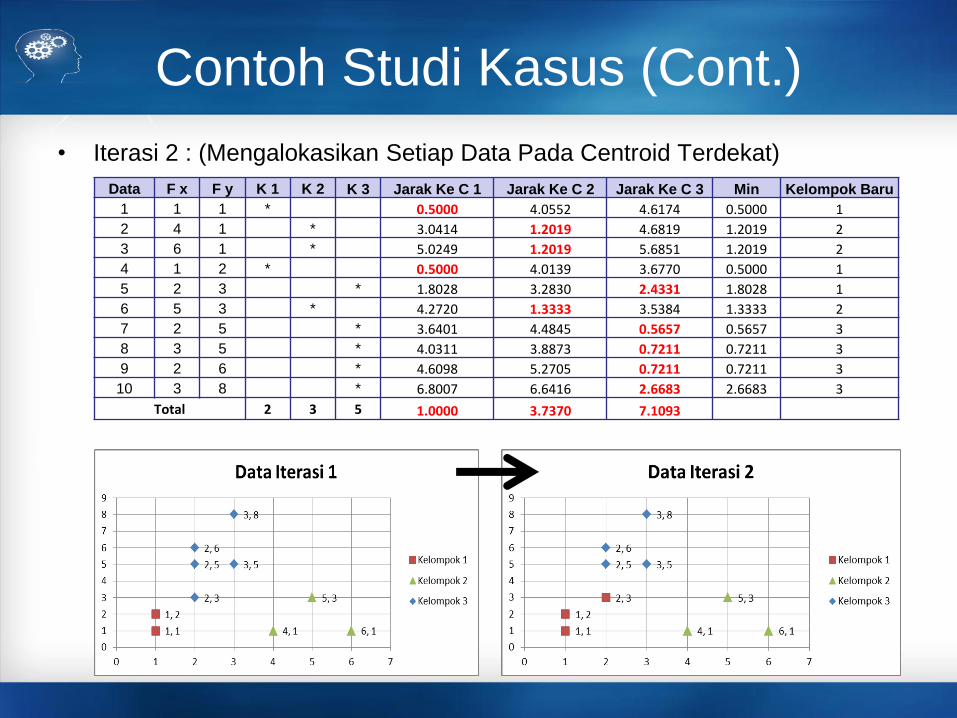
Contoh Studi Kasus (Cont.)
• Iterasi 2 : (Mengalokasikan Setiap Data Pada Centroid Terdekat)
Data F x F y K 1 K 2 K 3 Jarak Ke C 1 Jarak Ke C 2 Jarak Ke C 3 Min Kelompok Baru
1 1 1 * 0.5000 4.0552 4.6174 0.5000 1
2 4 1 * 3.0414 1.2019 4.6819 1.2019 2
3 6 1 * 5.0249 1.2019 5.6851 1.2019 2
4 1 2 * 0.5000 4.0139 3.6770 0.5000 1
5 2 3 * 1.8028 3.2830 2.4331 1.8028 1
6 5 3 * 4.2720 1.3333 3.5384 1.3333 2
7 2 5 * 3.6401 4.4845 0.5657 0.5657 3
8 3 5 * 4.0311 3.8873 0.7211 0.7211 3
9 2 6 * 4.6098 5.2705 0.7211 0.7211 3
10 3 8 * 6.8007 6.6416 2.6683 2.6683 3
Total 2 3 5 1.0000 3.7370 7.1093
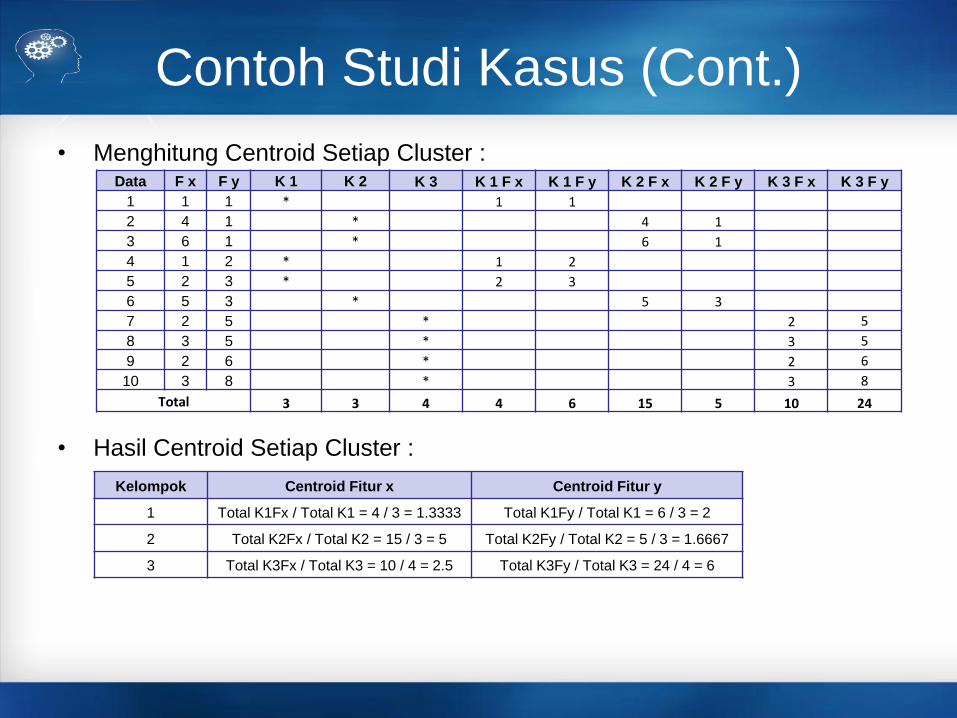
Contoh Studi Kasus (Cont.)
• Menghitung Centroid Setiap Cluster :
• Hasil Centroid Setiap Cluster :
Data F x F y K 1 K 2 K 3 K 1 F x K 1 F y K 2 F x K 2 F y K 3 F x K 3 F y
1 1 1 * 1 1
2 4 1 * 4 1
3 6 1 * 6 1
4 1 2 * 1 2
5 2 3 * 2 3
6 5 3 * 5 3
7 2 5 * 2 5
8 3 5 * 3 5
9 2 6 * 2 6
10 3 8 * 3 8
Total 3 3 4 4 6 15 5 10 24
Kelompok Centroid Fitur x Centroid Fitur y
1 Total K1Fx / Total K1 = 4 / 3 = 1.3333 Total K1Fy / Total K1 = 6 / 3 = 2
2 Total K2Fx / Total K2 = 15 / 3 = 5 Total K2Fy / Total K2 = 5 / 3 = 1.6667
3 Total K3Fx / Total K3 = 10 / 4 = 2.5 Total K3Fy / Total K3 = 24 / 4 = 6
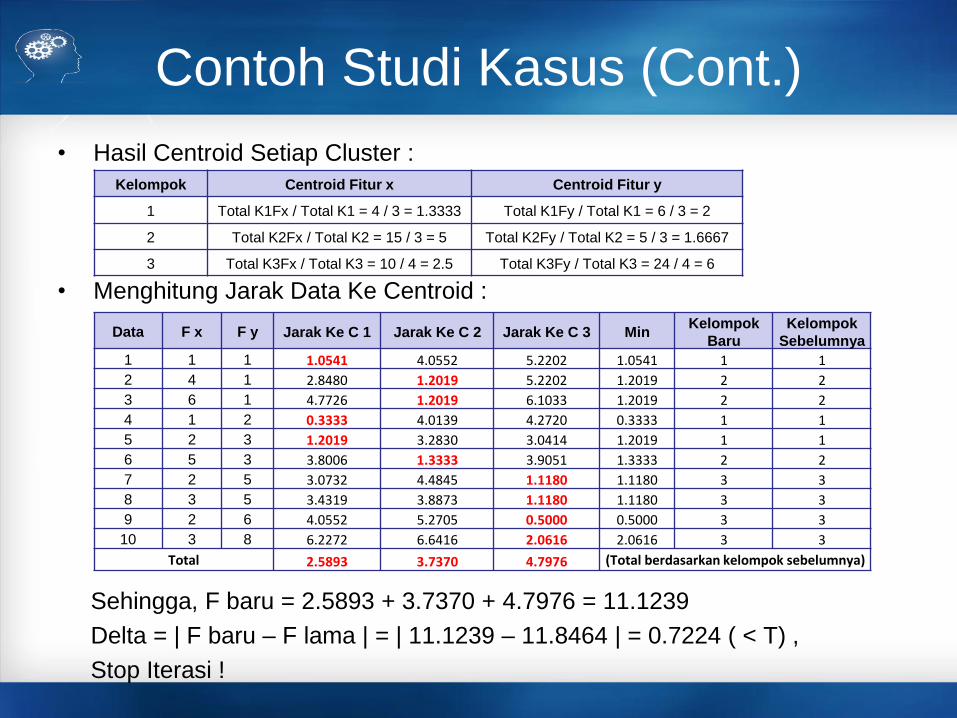
Contoh Studi Kasus (Cont.)
• Hasil Centroid Setiap Cluster :
• Menghitung Jarak Data Ke Centroid :
Sehingga, F baru = 2.5893 + 3.7370 + 4.7976 = 11.1239
Delta = | F baru – F lama | = | 11.1239 – 11.8464 | = 0.7224 ( < T) ,
Stop Iterasi !
Data F x F y Jarak Ke C 1 Jarak Ke C 2 Jarak Ke C 3 MinKelompok
Baru
Kelompok
Sebelumnya
1 1 1 1.0541 4.0552 5.2202 1.0541 1 1
2 4 1 2.8480 1.2019 5.2202 1.2019 2 2
3 6 1 4.7726 1.2019 6.1033 1.2019 2 2
4 1 2 0.3333 4.0139 4.2720 0.3333 1 1
5 2 3 1.2019 3.2830 3.0414 1.2019 1 1
6 5 3 3.8006 1.3333 3.9051 1.3333 2 2
7 2 5 3.0732 4.4845 1.1180 1.1180 3 3
8 3 5 3.4319 3.8873 1.1180 1.1180 3 3
9 2 6 4.0552 5.2705 0.5000 0.5000 3 3
10 3 8 6.2272 6.6416 2.0616 2.0616 3 3
Total 2.5893 3.7370 4.7976 (Total berdasarkan kelompok sebelumnya)
Kelompok Centroid Fitur x Centroid Fitur y
1 Total K1Fx / Total K1 = 4 / 3 = 1.3333 Total K1Fy / Total K1 = 6 / 3 = 2
2 Total K2Fx / Total K2 = 15 / 3 = 5 Total K2Fy / Total K2 = 5 / 3 = 1.6667
3 Total K3Fx / Total K3 = 10 / 4 = 2.5 Total K3Fy / Total K3 = 24 / 4 = 6

Contoh Studi Kasus (Cont.)
• Hasil Akhir Clustering Data :
• Visualisasi Hasil Akhir Clustering :
Data F x F y Kelompok Baru
1 1 1 1
2 4 1 2
3 6 1 2
4 1 2 1
5 2 3 1
6 5 3 2
7 2 5 3
8 3 5 3
9 2 6 3
10 3 8 3

Selesai




















