
BAB III METODE PENELITIAN 3.1 Ruang Lingkup...
14
BAB III METODE PENELITIAN 3.1 Ruang Lingkup Penelitian Penelitian ini dibatasi pada cakupan permasalahan kemiskinan pada 38 kabupaten/kota di Provinsi Jawa Timur. Penelitian ini bertujuan untuk mengetahui pengaruh dari kebijakan upah minimum terhadap kemiskinan. Selain itu, penulis juga ingin mengetahui pengaruh dari variabel lainnya yakni pendidikan yang diukur dengan Rata-rata Lama Sekolah, dan kesehatan yang diukur dengan Angka Harapan Hidup. Pemilihan tempat dan periode waktu didasarkan pada ketersediaan data dari variabel-variabel yang digunakan dalam penelitian ini. 3.2 Metode Pengumpulan Data Penelitian ini menggunakan data sekunder dengan periode 2010-2017 yang diperoleh dari berbagai data statistik resmi yang kemudian diolah untuk mengetahui nilai dari setiap variabel. Pengumpulan data yang dilakukan melalui proses pencarian data pada website Badan Pusat Statistik, Badan Pusat Statistik Provinsi Jawa Timur, dan Dinas Tenaga Kerja dan Transmigrasi Provinsi Jawa Timur. Kemudian melakukan pencatatan data, pengelompokan data, dan pengolahan data. 23
Transcript of BAB III METODE PENELITIAN 3.1 Ruang Lingkup...

BAB III
METODE PENELITIAN
3.1 Ruang Lingkup Penelitian
Penelitian ini dibatasi pada cakupan permasalahan kemiskinan pada 38
kabupaten/kota di Provinsi Jawa Timur. Penelitian ini bertujuan untuk mengetahui
pengaruh dari kebijakan upah minimum terhadap kemiskinan. Selain itu, penulis
juga ingin mengetahui pengaruh dari variabel lainnya yakni pendidikan yang diukur
dengan Rata-rata Lama Sekolah, dan kesehatan yang diukur dengan Angka Harapan
Hidup. Pemilihan tempat dan periode waktu didasarkan pada ketersediaan data dari
variabel-variabel yang digunakan dalam penelitian ini.
3.2 Metode Pengumpulan Data
Penelitian ini menggunakan data sekunder dengan periode 2010-2017 yang
diperoleh dari berbagai data statistik resmi yang kemudian diolah untuk mengetahui
nilai dari setiap variabel. Pengumpulan data yang dilakukan melalui proses
pencarian data pada website Badan Pusat Statistik, Badan Pusat Statistik Provinsi
Jawa Timur, dan Dinas Tenaga Kerja dan Transmigrasi Provinsi Jawa Timur.
Kemudian melakukan pencatatan data, pengelompokan data, dan pengolahan data.
23

24
3.3 Jenis dan Sumber Data
Data yang digunakan dalam penelitian ini berupa data sekunder yang
berbentuk data panel yang diunduh dari website Badan Pusat Statitika dan BPS
Provinsi Jawa Timur serta Dinas Tenaga Kerja dan Transmigrasi Provinsi Jawa
Timur. Data yang diperoleh dari BPS Provinsi Jawa Timur berupa data persentase
penduduk miskin, Rata-rata Lama Sekolah, dan Angka Harapan Hidup. Sedangkan
data upah minimum diperoleh dari website Dinas Tenaga Kerja dan Transmigrasi
Provinsi Jawa Timur. Variabel yang digunakan dalam penelitian ini adalah tingkat
kemiskinan, Upah Minimum Kabupaten/Kota, pendidikan yang diukur dengan
RLS, dan kesehatan yang diukur dengan AHH.
3.4 Model Penelitian
Model yang digunakan dalam penelitian ini merujuk pada model penelitian
yang telah dilakukukan terdahulu dengan menggunakan regresi data panel, yang
didasarkan pada penelitian Stevans & Sessions (2001) dan Olavarria-Gambi (2003)
dengan melakukan penyesuaian dan metode yang dilakukan di dalam model
tersebut. Penyesuaian variabel dilakukan karena keterbatasan data yang dimiliki
oleh lembaga statistik, maka variabel seperti minimum wage coverage, Tingkat
Partisipasi Angkatan Kerja (tidak ada survei di tahun 2016), pertumbuhan pekerja
tahunan, rumah tangga yang dipimpin perempuan, dan Produk Domestik Regional
Bruto (angka masih menggunakan estimasi) tidak digunakan dalam penelitian ini.
Berikut adalah spesifikasi model yang digunakan untuk menganalisis faktor-faktor
yang diduga mempengaruhi tingkat kemiskinan:

25
POVit = β0 + β1lnMWit + β2EDUCit + β3HEALTHit + εit
Di mana:
POV : Persentase penduduk miskin
MW : Upah Minimum Kabuaten/Kota
EDUC : Pendidikan yang diukur dengan RLS
HEALTH : Kesehatan yang diukur dengan AHH
ln : Notasi dalam bentuk logaritma
β0 : Konstanta
β1, β2, β3 : Koefisien regresi
ε : Error term
i : Kabupaten/Kota
t : Tahun
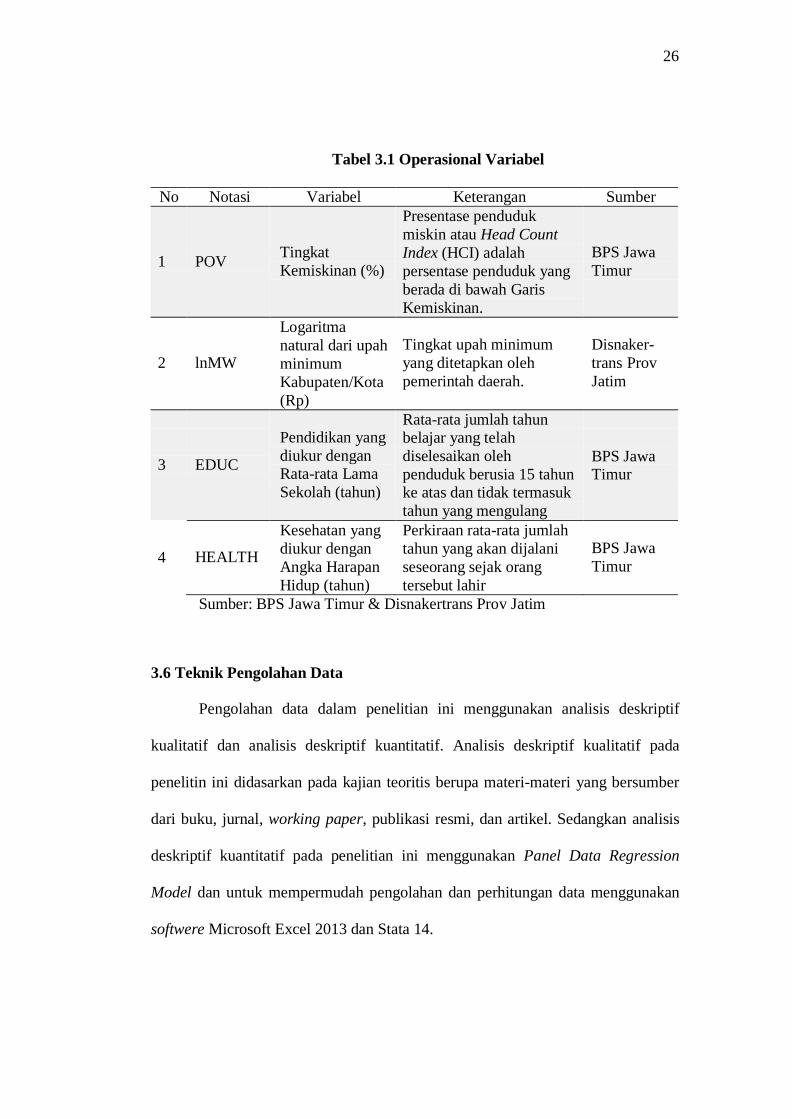
3.5 Operasional Variabel
Pada penelitian ini penulis mennggunakan tingkat kemiskinan sebagai
variabel dependen, sedangkan Upah Minimum Kabupaten/Kota, pendidikan yang
diukur dengan RLS, dan kesehatan yang diukur dengan AHH menjadi variabel
independen. Adapun penjelasan operasional dari variabel dependen dan independen
adalah sebagai berikut:
26
Tabel 3.1 Operasional Variabel
No Notasi Variabel Keterangan Sumber
1
POV
Tingkat
Kemiskinan (%)
Presentase penduduk
miskin atau Head Count
Index (HCI) adalah
persentase penduduk yang
berada di bawah Garis
Kemiskinan.
BPS Jawa
Timur
2
lnMW
Logaritma
natural dari upah
minimum
Kabupaten/Kota
(Rp)
Tingkat upah minimum
yang ditetapkan oleh
pemerintah daerah.
Disnaker-
trans Prov
Jatim
3
EDUC
Pendidikan yang
diukur dengan Rata-rata Lama
Sekolah (tahun)
Rata-rata jumlah tahun belajar yang telah
diselesaikan oleh
penduduk berusia 15 tahun ke atas dan tidak termasuk
tahun yang mengulang
BPS Jawa Timur
4
HEALTH
Kesehatan yang
diukur dengan
Angka Harapan
Hidup (tahun)
Perkiraan rata-rata jumlah
tahun yang akan dijalani
seseorang sejak orang
tersebut lahir
BPS Jawa
Timur
Sumber: BPS Jawa Timur & Disnakertrans Prov Jatim
3.6 Teknik Pengolahan Data
Pengolahan data dalam penelitian ini menggunakan analisis deskriptif
kualitatif dan analisis deskriptif kuantitatif. Analisis deskriptif kualitatif pada
penelitin ini didasarkan pada kajian teoritis berupa materi-materi yang bersumber
dari buku, jurnal, working paper, publikasi resmi, dan artikel. Sedangkan analisis
deskriptif kuantitatif pada penelitian ini menggunakan Panel Data Regression
Model dan untuk mempermudah pengolahan dan perhitungan data menggunakan
softwere Microsoft Excel 2013 dan Stata 14.

27
3.7 Perbandingan Model Regresi
Menurut Gujarati & Porter (2009) terdapat tiga pendekatan yang dapat
digunakan dalam mengestimasi model regresi yang menggunakan data panel yakni
Pooled Least Square, Fixed Effect Model, dan Random Efect Model.
Di mana pendekatan-pendekatan tersebut akan dianalisis untuk menentukan model
regresi yang terbaik.
1. Pooled Least Square
Pendekatan ini merupakan model estimasi yang paling sederhana dengan
menggunakan prinsip Ordinary Least Square (OLS) yaitu dengan cara
meminimalkan jumlah error kuadrat. Pada model ini hanya dilakukan kombinasi
antara data time series dan cross section, serta pendekatan ini tidak memperhatikan
dimensi waktu atau individu, sehingga diasumsikan sifat data sebuah perusahaan
atau wilayah dalam berbagai periode waktu adalah sama.
2. Fixed Effect Model
Pendekatan ini merupakan model estimasi data panel yang berasumsi
perbedaan antar indvidu dapat diakomodasikan oleh perbedaan intersep, tetapi
parameter setiap objek yang ada tidak berubah seiring waktu atau mengabaikan
perbedaan antar waktu. Perbedaan intersep dapat terjadi karena terdapat perbedaan
pada data yang digunakan. Fixed Effect Model dapat dikatakan model terbaik yang
digunakan, ketika jumlah periode waktu lebih panjang jika dibandingkan dengan
jumlah sampel cross section.

28
3. Random Effect Model
Pendekatan ini merupakan model estimasi data panel pada variabel error
yang saling berkorelasi anatar periode waktu pada setiap wilayah. Intersep pada
model ini mewakili nilai rata-rata dari semua nilai intersep cross section serta
intersep tersebut diakomodasi oleh error terms gabungan dari data time series dan
cross section. Random Effect Model dapat dikatakan model terbaik yang digunakan,
ketika jumlah periode waktu lebih pendek jika dibandingkan dengan jumlah sampel
cross section.
3.8 Metode Pengujian
3.8.1 Uji Pemilihan Model
Gujaratai & Porter (2009) menjelaskan tiga pendekatan yang dapat
digunakan dalam mengestimasi model regresi yang menggunakan data panel,
yakni Pooled Least Square, Fixed Effect Model, dan Random Effect Model.
Agar dapat menentukan model regresi yang tepat digunakan dalam penelitian, maka
perlu dilakukannya proses pengujian meliputi uji Chow, uji Hausman, dan Uji
Bruesch-Pagan Lagrangian Multiplier.
3.8.1.1 Uji Chow
Menurut Gujarati & Porter (2009) pengujian ini digunakan untuk
mengetahui antara Pooled Least Square atau Fixed Effect Model yang lebih baik
digunakan dalam penelitian. Dengan hipotesis:

29
H0 : Menggunakan Pooled Least Square
H1 : Menggunakan Fixed Effect Model
Dengan kriteria sebagai berikut:
Apabila nilai (Prob > F) < α maka H0 ditolak, yang artinya Fixed Effect
Model lebih baik digunakan dari pada Pooled Least Square.
Apabila nilai (Prob > F) > α maka H0 tidak dapat ditolak, yang artinya
Poolde Least Square lebih baik digunakan dari pada Fixed Effect Model
3.8.1.2 Uji Hausman
Menurut Gujarati & Porter (2009) pengujian ini digunakan untuk
mengetahui anatara Fixed Effect Model atau Random Effect Model yang lebih baik
digunakan dalam penelitian. Dengan hipotesis:
H0 : Menggunakan Random Effect Model
H1 : Menggunakan Fixed Effect Model
Dengan kriteria sebagai berikut:
Apabila nilai (Prob > Chi2) < α maka H0 ditolak, yang artinya Fixed
Effect Model lebih baik digunakan dari pada Random Effect Model.
Apabila nilai (Prob > Chi2) > α maka H0 tidak dapat ditolak, yang artinya
Random Effect Moel lebih baik digunakan dari pada Fixed Effect Model.

30
3.8.1.3 Uji Breucsh – Pagan Lagrangian Multiplier
Menurut Gujarati & Porter (2009) pengujian ini digunakan untuk
mengetahui antara Random Effect Model atau Pooled Least Square yang lebih baik
digunakan dalam penelitian. Dengan hipotesis:
H0 : Menggunakan Polled Leas Square
H1 : Menggunakan Random Effect Model
Dengan kriteria sebagai berikut:
Apabila nilai (Prob > Chibar) < α maka H0 ditolak, yang artinya Random
Effect Model lebih baik digunakan dari pada Pooled Least Square.
Apabila nilai (Prob > Chibar) > α maka H0 tidak dapat ditolak, yang
artinya Pooled Least Square lebih baik digunakan dari pada
Random Effect Model.
3.8.2 Uji Asumsi Klasik
3.8.2.1 Uji Heteroskedastisitas
Masalah heteroskedastisitas terjadi karena varian dari error terms tidak lagi
konstan. Masalah tersebut berakibat pada nilai standar error yang bervariasi dan
menyebabkan hasil perhitungan uji signifikansi parsial dan simultan menjadi tidak
valid, namun pada faktanya tidak menyebabkan sebuah hasil estimasi menjadi bias
(Gujarati & Porter, 2009). Menurut Wooldridge (2012) masalah heteroskedastisitas
dapat diminimalisir dengan menggunakan robust variance estimate. Jika pada
pemilihan model terbaik didapatkan random effect model, maka masalah
heteroskedastisitas dapat diminimalisir.

31
Kemudian menurut Gujarati & Porter (2009) pada hasil regresi
menggunakan random effect model merupakan estimasi yang dilakukan dengan
Generelize Least Square (GLS) yaitu transformasi variabel sehingga memenuhi
asumsi standar kuadrat terkecil, di mana hasil estimasi dari GLS bersifat
homoskedastis sehingga tidak terdapat masalah heteroskedastisitas. Masalah ini
dapat dideteksi melalui uji Walad Test. Dengan hipotesis yang digunakan pada
pengujian ini adalah:
H0 : Tidak terdapat masalah heterokedastisitas
H1 : Terdapat masalah heteroskedastisitas
Dengan menggunakan kriteria sebagai berikut:
Ketika nilai (Prob > Chi2) < α maka H0 ditolak, hal ini menjelaskan
bahwa dalam model regresi ini terdapat masalah heteroskedastisitas.
Ketika nilai (Prob > Chi2) > α maka H0 tidak dapat ditolak, hal ini
menjelaskan bahwa dalam model regresi ini tidak terdapat masalah
heteroskedastisitas atau data bersifat homoskedastisitas.
3.8.2.2 Uji Autokorelasi
Gujarati & Porter (2009) menjelaskan autokorelasi merupakan masalah
yang diakibatkan adanya hubungan antara error terms, yaitu ketika error terms
pada periode waktu tertentu memiliki hubungan dengan variabel yang ada di
periode waktu lain. Terdapat beberapa aspek yang mengakibatkan masalah ini,
seperti kesalahan dalam penentuan model yang digunakan, terdapat lag waktu
dalam model, serta tidak menggunakan variabel penting dalam model.

32
Masalah ini berakibat pada kriteria yang diestimasi akan menjadi bias,
memiliki varian yang rendah, dan tidak efesien. Jika pemilihan model terbaik
didapatkan random effect model, maka masalah autokolerasi dapat diminimalisir.
Menurut Wooldridge (2012) jika menggunakan random effect model maka dapat
dikatakan tidak terdapat masalah autokorelasi dikarenakan telah menggunakan
Generalized Least Square (GLS). Masalah ini dapat dideteksi dengan melakukan
uji Wooldridge dengan hipotesis:
H0 : Tidak terdapat masalah autokorelasi
H1 : Terdapat masalah autokorelasi
Dengan menggunakan kriteria sebagai berikut:
Ketika nilai (Prob > F) < α maka H0 ditolak, hal ini menjelaskan bahwa
dalam model regresi ini terdapat masalah autokorelasi.
Ketika nilai (Prob > F) > α maka H0 tidak dapat ditolak, hal ini
menjelaskan bahwa dalam model regresi ini tidak terdapat masalah
autokorelasi.
3.8.2.3 Uji Multikolinearitas
Menurut Gujarati & Porter (2009) masalah mutikolinearitas merupakan
masalah yang terjadi ketika terdapat korelasi antara variabel indepeden yang
digunakan dalam model. Tanda-tandanya dapat ditemukan dengan melihat nilai R2
yang besar, akan tetapi variabel independen yang signifikan memiliki pengaruh
yang kecil, atau bahkan tidak memeiliki pengaruh terhadap variabel dependennya.

33
Masalah multikolinearitas dapat diketahui dengan melihat korelasi anatar variabel
independen. Ketika variabel-variabel independen dalam model memiliki koefisien
korelasi lebih dari 0,8 maka dapat dinyatakan dalam model regresi terdapat
masalah multikolinearitas.
Christopher Achen dalam (Gujarati & Porter, 2009) menjelaskan ketika
pada model terdapat masalah multikolinearitas, tidak perlu melakukan uji
perbaikan, karena multikolinearitas tidak melanggar asumsi-asumsi regresi dan
tidak menyebabkan bias pada model, estimasi yang digambarkan akan tetap
konsisten dan standar error akan terestimasi dengan benar.
3.8.3 Uji Statistik
3.8.3.1 Uji Signifikansi Parsial
Uji signifikansi parsial atau uji t dilakukan untuk mengetahui pengaruh
variabel independen secara individual terhadap variabel dependen dalam model.
Pengujian ini dilakukan dengan cara membandingkan nilai Prob.t dengan nilai
signifikansi yang digunakan. Dengan hipotesis:
H0 : Variabel independen tidak memiliki pengaruh signfikan terhadap
variabel dependen
H1 : Variabel independen memiliki pengaruh signifikan terhadap
variabel dependen

34
Dengan menggunakan kriteria sebagai berikut:
Jika nilai Prob.t < α maka H0 ditolak, hal ini menjelaskan bahwa variabel
independen memiliki pengaruh signifikan terhadap variabel
dependennya.
Jika nilai Prob.t > α maka H0 tidak dapat ditolak, hal ini menjelaskan
bahwa variabel independen tidak memiliki pengaruh signifikan terhadap
variabel dependennya.
Menurut StataCorp (2013) apabila hasil estimasi regresi menggunakan
Random Effect Model, maka uji signifikansi parsial dapat dilakukan dengan uji z.
Pada uji ini menggunakan hipotesis yang sama seperti uji t, namun dengan kriteria:
Jika Prob z < α maka H0 ditolak, hal ini menjelaskan bahwa variabel
independen memiliki pengaruh signifikan terhadap variabel
dependennya.
Jika Prob z > α maka H0 tidak dapat ditolak, hal ini menjelaskan bahwa
variabel independen tidak memiliki pengaruh signifikan terhadap
variabel dependennya.
3.8.3.2 Uji Signifikansi Simultan
Uji signifikansi simultan atau uji F ini dilakukan untuk mengetahui
pengaruh dari variabel independen secara keseluruhan terhadap variabel
dependennya. Pengujian ini dilakukan dengan cara membandingkan nilai Prob > F
dengan nilai signifikansi yang digunakan. Dengan hipotesis:

35
H0 : Seluruh variabel independen secara bersama-sama tidak memiliki
pengaruh terhadap variabel dependen
H1 : Seluruh variabel independen secara bersama-sama memiliki
pengaruh terhadap variabel dependen
Dengan kriteria:
Jika nilai Prob F < α maka H0 ditolak, hal ini menjelaskan bahwa seluruh
variabel independen secara bersama-sama memiliki pengaruh terhadap
variabel dependen.
Jika nilai Prob F ≥ α maka H0 tidak dapat ditolak, hal ini menjelaskan bahwa seluruh variabel independen secara bersama-sama tidak memiliki
pengaruh terhadap variabel dependen.
Menurut StataCorp (2013) apabila hasil estimasi regresi menggunakan
Random Effect Model, maka uji signifikansi simultan ini dapat dilakukan dengan
uji Walad Chi-Square. Pada uji ini hipotesis yang digunakan sama dengan uji F,
namun dengan kriteria sebagai berikut:
Jika Prob χ2 < α maka H0 ditolak, hal ini menjelaskan bahwa seluruh
variabel independen secara bersama-sama memiliki pengaruh terhadap
variabel dependen
Jika Prob χ2 > α maka H0 tidak dapat ditolak, hal ini menjelaskan bahwa
seluruh variabel independen secara bersama-sama tidak memiliki
pengaruh terhadap variabel dependen.

36
3.8.3.3 Uji Koefisien Determinasi (R2)
Menurut Gujarati & Porter (2009) koefisien determinasi atau yang biasa
dikenal dengan R-saqured (R2) adalah parameter ringkas yang memberikan
informasi seberapa baik sebuah garis regresi sampel yang sesuai dengan datanya.
R2 merupakan bilangan yang dinyatakan dalam bentuk persen. Persentase tersebut
menjelaskan seberapa besar variabel independen yang digunakan dapat
menjelaskan variabel dependennya. Besaran nilai R2 adalah sekitar kosong hingga
satu. Apabila nilai R-squared mendekati angka satu maka dapat dikatakan model
regresi yang digunakan sangat baik, karena semakin besar variasi variabel
independen yang dapat menjelaskan variabel dependennya.




















