BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · data dalam mencocokkan kata yang diucapkan...
18
BAB II TINJAUAN PUSTAKA 2.1 State Of The Art Suara dapat menjadi ciri khas dari setiap individu yang dapat membedakan antara individu satu dengan yang lainnya. Perbedaan tersebut terletak pada karakteristik suara yang dihasilkan oleh masing – masing individu tersebut. Tapitidak semua pendengaran manusia mampu membedakan suara dari masing-masing individu yang dikenalnya. Kepekaan telinga juga memiliki berbagai keterbatasan dan sensitif terhadap suara. Oleh karena itu dibutuhkan suatu sistem untuk mengenali suara manusia tersebut sehingga dapat hasilnya akan tertuju tepat kepada individu yang dimaksud. Sistem untuk mengenali suara manusia tersebut biasa dikenal dengan nama identifikasi suara, sistem ini bisa membedakan antara suara individu yang satu dengan individu yang lainnya berdasarkan perbedaan karakteristik suara dari masing – masing indivdu yang bisa dicari dengan beberapa metode ekstraksi ciri. Darshan Mandalia (2011) pernah membuat suatu sistem jaringan saraf tiruan untuk identifikasi suara dengan metode ekstraksi ciri MFCC menggunakan perangkat lunak MATLAB. Sistem ini juga menggunakan metode Vector Quantization untuk clustering suara yang sudah direkam sebelumnya. Secara garis besar cara kerja sistem identifikasi suara ini adalah pertama – tama sistem akan merekam suara yang akan diidentifikasi, lalu suara hasil rekama tersebut akan mengalami proses Silence Detection dan Windowing, setelahnya suara hasil rekaman tersebut dikonversikan ke dalam domain frekuensi dilanjukan dengan mengkonversinya ke dalam domain Mel Frequency Cepstrum. Setelah melalui proses tersebut, suara rekaman akan digambarkan dalam Overlapping Triangle Window yang nantinya akan mendapatkan nilai energy dari setiap window, selanjutnya akan mendapatkan nilai DCT (Discrete Cosine Transform) dari Spectrum Energy, dan didapatkan nilai MSE (Mean Square Error) dari suara rekaman yang pertama. Untuk mencocokkanya, diperlukan suara rekaman kedua yang mengalami proses sama dengan rekaman suara pertama dan nilai MSE dari kedua suara ini akan dicocokkan, apabila nilai MSEnya kurang dari 1,5
Transcript of BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · data dalam mencocokkan kata yang diucapkan...

BAB II
TINJAUAN PUSTAKA
2.1 State Of The Art
Suara dapat menjadi ciri khas dari setiap individu yang dapat membedakan
antara individu satu dengan yang lainnya. Perbedaan tersebut terletak pada
karakteristik suara yang dihasilkan oleh masing – masing individu tersebut. Tapitidak
semua pendengaran manusia mampu membedakan suara dari masing-masing individu
yang dikenalnya. Kepekaan telinga juga memiliki berbagai keterbatasan dan sensitif
terhadap suara. Oleh karena itu dibutuhkan suatu sistem untuk mengenali suara
manusia tersebut sehingga dapat hasilnya akan tertuju tepat kepada individu yang
dimaksud. Sistem untuk mengenali suara manusia tersebut biasa dikenal dengan nama
identifikasi suara, sistem ini bisa membedakan antara suara individu yang satu dengan
individu yang lainnya berdasarkan perbedaan karakteristik suara dari masing – masing
indivdu yang bisa dicari dengan beberapa metode ekstraksi ciri.
Darshan Mandalia (2011) pernah membuat suatu sistem jaringan saraf tiruan
untuk identifikasi suara dengan metode ekstraksi ciri MFCC menggunakan perangkat
lunak MATLAB. Sistem ini juga menggunakan metode Vector Quantization untuk
clustering suara yang sudah direkam sebelumnya. Secara garis besar cara kerja sistem
identifikasi suara ini adalah pertama – tama sistem akan merekam suara yang akan
diidentifikasi, lalu suara hasil rekama tersebut akan mengalami proses Silence
Detection dan Windowing, setelahnya suara hasil rekaman tersebut dikonversikan ke
dalam domain frekuensi dilanjukan dengan mengkonversinya ke dalam domain Mel
Frequency Cepstrum. Setelah melalui proses tersebut, suara rekaman akan
digambarkan dalam Overlapping Triangle Window yang nantinya akan mendapatkan
nilai energy dari setiap window, selanjutnya akan mendapatkan nilai DCT (Discrete
Cosine Transform) dari Spectrum Energy, dan didapatkan nilai MSE (Mean Square
Error) dari suara rekaman yang pertama. Untuk mencocokkanya, diperlukan suara
rekaman kedua yang mengalami proses sama dengan rekaman suara pertama dan nilai
MSE dari kedua suara ini akan dicocokkan, apabila nilai MSEnya kurang dari 1,5

makan kedua rekaman suara tersebut berasal dari orang yang sama, sebaliknya apabila
nilai MSE dari kedua rekaman suara ini melebihi 1,5 maka kemungkinan kedua
rekaman suara itu bukan berasal dari suara orang yang sama. Faktor – faktor yang bisa
mempengaruhi proses identifikasi suara menggunakan sistem jaringan saraf tiruan ini
antara lain yaitu kondisi kesehatan individu yang suaranya dijadikan sampel, kondisi
lingkungan tempat pengambilan sampel, dan kondisi perangkat keras yang digunakan
dalam pengambilan sampel suara.
Pada penelitian oleh Ghulam M. tahun 2009, yang mengambil kasus
pengenalan digit terisolasi yang menggunakan kombinasi metode MFCC dan HMM
dalam bahasa Bangia, sistem mampu mengenali digit bilangan yang digunakan dengan
tingkat keberhasilan mencapai 90%. Sedangkan, untuk studi kasus yang sama pada
penelitian oleh M. Chandrasekar yang mengdopsi metode MFCC dalam mengekstrak
fitur suara, kemudian dikenali dengan Back Propagation Network diperoleh nilai
akurasi yang lebih kecil yaitu 80,95%. Dalam pengenalan kata berkelanjutan
(continuous) dengan kosa kata berukuran besar oleh Corneliu O. dan Inger Gavat,
digunakan Hidden Markov Model sebagai recognizer dan 3 macam metode algoritma
ekstraksi fitur yaitu MFCC, LPC, dan PLP. Dari ketiga metode ekstraksi fitur tersebut,
MFCC menghasilkan tingkat akurasi tertinggi dengan persentase 90,41%. Sedangkan
metode LPC memiliki persentase keberhasilan 63,55% sementara PLP sebesar 75,78%.
Pada penelitian ini akan membahas dan membuat suatu aplikasi identifikasi
suara yang bisa mengidentifikasi, menyocokkan suara dari individu yang berbeda –
beda. Untuk membuat aplikasi identifikasi suara ini menggunakan metode MFCC (Mel
Frequency Cepstral Coefficients) sebagai metode esktraksi cirinya dan 2 metode
pengenalan (recognition) yaitu Hidden Markov Model dan Vector Quantization.
Jaringan saraf tiruan untuk identifikasi suara ini akan dibuat dengan menggunakan
perangkat lunak MATLAB.

2.2 Suara
Menurut Muhammad Nuh Al-Azhar (2011) suara dihasilkan melalui proses
Generation dan Filtering. Pada proses Generation, suara pertama kali diproduksi
melalui bergetarnya pita suara yang berada di larynx untuk menghasilkan bunyi
periodik. Bunyi periodik yang bersifat konstan tersebut kemudian difilterisasi melalui
vocal tract (juga disebut dengan istilah resonator suara atau articulator) yang terdiri
dari lidah, gigi, bibir, langit-langit mulut dan lain-lain sehingga bunyi tersebut dapat
menjadi bunyi keluaran berupa bunyi vokal dan atau bunyi konsonan yang membentuk
kata-kata yang memiliki arti yang nantinya dapat dianalisa untuk identifikasi suara.
Untuk dapat diidentifikasi, ada beberapa karakteristik suara yang dapat
dijadikan parameter untuk membedakan antara orang yang satu dengan yang lainnya.
Menurut Nilsson dan Ejnarsson (2002), sinyal suara dan karakteristiknya dapat
direpresentasikan ke dalam dua domain yang berbeda, yaitu domain waktu dan domain
frekuensi. Sinyal suara merupakan sinyal yang bervariasi lambat sebagai fungsi waktu,
dalam hal ini ketika diamati pada durasi yang sangat pendek (5 sampai 100 m)
karakteristiknya masih stasioner. Tetapi apabila diamati dalam durasi yang lebih
panjang (> 1/5 detik) karakteristik sinyalnya berubah untuk merefleksikan suara yang
keluar dari pembicara.

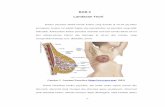
Gambar 2.1 Human Vocal Tract
Sumber: http://www.dukemagazine.duke.edu/issues/050608/images/050608-lg-figure1purves.jpg
2.2.1 Komponen Suara
Suara terdiri dari beberapa komponen, yaitu pitch, formant dan spectrogram
yang dapat digunakan untuk mengidentifikasi karakteristik suara seseorang untuk
kepentingan voice recognition.
a. Pitch
Frekuensi getar dari pita suara yang juga disebut dengan istilah frekwensi
fundamental (dasar) dengan notasi F0. Masing-masing orang memiliki
pitch yang khas (habitual pitch) yang sangat dipengaruhi oleh aspek
fisiologis larynx manusia. Pada kondisi pembicaraan normal, level habitual
pitch berkisar pada 50 s/d 250 Hz untuk laki-laki dan 120 s/d 500 Hz untuk
perempuan. Frekuensi F0 ini berubah secara konstan dan memberikan
informasi linguistik seseorang seperti perbedaan intonasi dan emosi.
Analisa pitch dapat digunakan untuk melakukan voice recognition terhadap
suara seseorang, yaitu melalui analisa statistik terhadap minimum pitch,
maximum pitch dan mean pitch.

b. Formant adalah frekwensi-frekwensi resonansi dari filter, yaitu vocal tract
(articulator) yang meneruskan dan memfilter bunyi periodik dari getarnya
pita suara (vocal cord) menjadi bunyi keluaran berupa kata-kata yang
memiliki makna. Secara umum, frekuensi-frekuensi formant bersifat tidak
terbatas, namun untuk identifikasi suara seseorang, paling tidak ada 3 (tiga)
formant yang dianalisa, yaitu Formant 1 (F1), Formant 2 (F2) dan Formant
3 (F3)
c. Spectogram
Spectrogram merupakan representasi spectral yang bervariasi terhadap
waktu yang menunjukkan tingkat density (intensitas energi) spektral.
Dengan kata lain spectrogram adalah bentuk visualisasi dari masing-
masing nilai formant yang dilengkapi dengan level energi yang bervariasi
terhadap waktu. Level energy ini dikenal dengan istilah formant bandwidth.
Nantinya pada kasus-kasus yang bersifat pemalsuan suara dengan teknik
pitch shift atau si subyek berusaha untuk menghilangkan karakter suara
aslinya, maka formant bandiwidth dapat digunakan untuk memetakan atau
mengidentifikasi suara aslinya. Spectrogram membentuk pola umum yang
khas dalam pengucapan kata dan pola khusus masing-masing formant
dalam pengucapan suku kata, sehingga spectrogram juga digunakan untuk
melakukan analisa identifkasi suara seseorang. Jika durasi rekaman suara
unknown lumayan panjang, maka analisa spectrogram juga dapat
digunakan untuk mempercepat pemilihan pengucapan kata-kata yang akan
dianalisa dalam rangka untuk mendapatkan jumlah minimal 20 kata untuk
dapat menunjukkan ke-identik-an suara unknown dengan known
(pembanding).
2.3 Pengenalan Ucapan
Pengenalan ucapan dalam istilah bahasa Inggrisnya Automatic Speech
Recognition (ASR) adalah suatu pengembangan teknik dan sistem yang

memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan.
Teknologi ini memungkinkan suatu perangkat untuk mengenali dan memahami kata
yang diucapkan dengan cara digitalisasi kata dan mencocokkan sinyal digital tersebut
dengan suatu pola tertentu yang tersimpan dalam suatu perangkat. Kata-kata yang
diucapkan diubah bentuknya menjadi sinyal digital dengan cara mengubah gelombang
suara menjadi sekumpulan angka yang kemudian disesuaikan dengan kode-kode
tertentu untuk mengidentifikasikan kata-kata tersebut. Hasil dari identifikasi kata yang
diucapkan dapat ditampilkan dalam bentuk tulisan atau dapat dibaca oleh perangkat
teknologi sebagai sebuah komando untuk melakukan suatu pekerjaan, misalnya
penekanan tombol pada telepon genggam yang dilakukan secara otomatis dengan
komando suara alat pengenal ucapan, yang sering disebut dengan speech recognizer,
membutuhkan sampel kata sebenarnya yang diucapkan dari pengguna. Sampel kata
akan didigitalisasi, disimpan dalam komputer dan kemudian digunakan sebagai basis
data dalam mencocokkan kata yang diucapkan selanjutnya.
2.4 Digitalisasi Suara
Digitalisasi adalah suatu proses mengubah bentuk informasi analogberupa teks,
suara (audio) , gambar, dan video menjadi informasi digital berupa kode biner tunggal
0 dan 1. Informasi digital dalam bentuk 0 atau 1 disebut bit dan rangkaian dari banyak
0 dan 1 disebut byte yang membentuk suatu informasi informasi. Tujuan Digitalisasi
adalah untuk mendapatkan efisiensi dan optimalisasi dalam banyak hal antara lain
efisiensi dan optimalisasi tempat penyimpanan, keamanan dari berbagai bentuk
bencana, untuk meningkatkan resolusi, gambar dan suara lebih stabil.
Proses Digitalisasi informasi analog terbagi menjadi 3 bagian yaitu :
a. Sampling
Pada dasarnya semua suara audio baik vocal atau bunyi tertentu merupakan
suatu bentuk dari getaran. Ini menandakan semua audio memiliki bentuk
gelombangnya masing-masing. Umumnya bentuk dari gelombang dari

suara tersebut disebut sinyal analog. Teknik sampling memungkinkan
sinyal analog ini diubah menjadi bit-bit sinyal digital. Pada proses
sampling, dilakukan suatu pencuplikan dari bentuk sinyal analog tersebut,
pencuplikan dilakukan pada bagian-bagian sinyal analog dengan sinyal-
sinyal sampling. Teori Shannon menyatakan frekuensi sinyal sampling
paling kecil adalah 2 kali frekuensi sinyal analog yang akan disampling.
Setelah dilakukannya proses sampling maka akan didapatkan sinyal analog-
diskrit yang menyerupai sinyal aslinya namun hanya diambil diskrit-
diskritnya saja.
b. Kuantisasi
Kuantisasi adalah proses perbandingan level-level tiap diskrit sinyal hasil
sampling dengan tetapan level tertentu. Level-level ini adalah tetapan
angka-angka yang dijadikan menjadi bilangan biner. Sinyal-sinyal diskrit
yang ada akan disesuaikan levelnya dengan tetapan yang ada. Jika lebih
kecil akan dinaikkan dan jika lebih besar akan diturunkan. Tetapan level
yang ada tergantung pada resolusi dari alat karena tetapan level merupakan
kombinasi bilangan biner, oleh karena itu apabila bitnya lebih besar maka
kombinasinya akan lebih banyak dan tetapannya juga akan lebih banyak.
Level kuantisasi yang dapat dirumuskan :
𝑀 = 2𝑁……………………………………………………...…. (2.1)
Dimana : M = level kuantisasi dan N = Jumlah bit pengkodean
Gambar 2.2 Gambaran Proses Kuantisasi

c. Kompresi
Kompresi adalah proses pengubahan sekumpulan data menjadi suatu
bentuk kode untuk menghemat kebutuhan tempat penyimpanan dan waktu
untuk transmisi data. Saat ini terdapat berbagai tipe algoritma kompresi,
antara lain: Huffman, LIFO, ZHUF, LZ77 dan variannya (LZ78, LZW,
GZIP), Dynamic Markov Compression (DMC), Block-Sorting
Lossless, Run- Length, Shannon-Fano, Arithmetic, PPM (Prediction by
Partial Matching), Burrows-Wheeler Block Sorting, dan Half Byte.
Berdasarkan tipe peta kode yang digunakan untuk mengubah pesan awal
menjadi sekumpulan codeword, metode kompresi terbagi menjadi dua
kelompok, yaitu Metode Statik, metode ini menggunakan peta kode yang
selalu sama. Metode ini membutuhkan dua fase. Fase
pertama untuk menghitung probabilitas kemunculan tiap simbol/karakter
dan menentukan peta kodenya, dan fase kedua untuk mengubah pesan
menjadi kumpulan kode yang akan ditransmisikan. Sedangkan Metode
Dinamik menggunakan peta kode yang dapat berubah dari waktu ke waktu.
Metode ini disebut adaptif karena peta kode mampu beradaptasi terhadap
perubahan karakteristik isi file selama proses kompresi berlangsung.
Metode ini bersifat onepass, karena hanya diperlukan satu kali pembacaan
terhadap isi file.
2.5 Jaringan Saraf Tiruan
Jaringan Saraf Tiruan (JST) dalam Bahasa Inggris disebut Artificial Neural
Network (ANN), atau juga disebut Simulated Neural Network (SNN), atau umumnya
hanya disebut Neural Network (NN), adalah jaringan dari sekelompok unit pemroses
kecil yang dimodelkan berdasarkan jaringan saraf manusia. JST merupakan sistem
adaptif yang dapat mengubah strukturnya untuk memecahkan masalah berdasarkan
informasi eksternal maupun internal yang mengalir melalui jaringan tersebut. Saat ini
bidang kecerdasan buatan dalam usahanya menirukan intelegensi manusia, belum

mengadakan pendekatan dalam bentuk fisiknya melainkan dari sisi yang lain. Pertama-
tama diadakan studi mengenai teori dasar mekanisme proses terjadinya intelegensi.
Bidang ini disebut ‘Cognitive Science’. Dari teori dasar ini dibuatlah suatu model untuk
disimulasikan pada komputer, dan dalam perkembangannya yang lebih lanjut dikenal
berbagai sistem kecerdasan buatan yang salah satunya adalah jaringan saraf tiruan.
Dibandingkan dengan bidang ilmu yang lain, jaringan saraf tiruan relatif masih baru.
Sejumlah literatur menganggap bahwa konsep jaringan saraf tiruan bermula pada
makalah Waffen McCulloch dan Walter Pitts pada tahun 1943. Dalam makalah
tersebut mereka mencoba untuk memformulasikan model matematis sel-sel otak.
Metode yang dikembangkan berdasarkan sistem saraf biologi ini, merupakan suatu
langkah maju dalam industri komputer.
Menurut Hecht-Nielsend (1988) mendefinisikan sistem saraf buatan sebagai
suatu struktur pemroses informasi yang terdistribusi dan bekerja secara paralel, yang
terdiri atas elemen pemroses yang memiliki memori lokal dan beroperasi dengan
informasi lokal yang diinterkoneksi bersama dengan alur sinyal searah yang disebut
koneksi. Setiap elemen pemroses memiliki koneksi keluaran tunggal yang bercabang
(fan out) ke sejumlah koneksi kolateral yang diinginkan. Setiap koneksi membawa
sinyal yang sama dari keluaran elemen pemroses tersebut. Keluaran dari elemen
pemroses tersebut dapat merupakan sebarang jenis persamaan matematis yang
diinginkan. Seluruh proses yang berlangsung pada setiap elemen pemroses harus
benar-benar dilakukan secara lokal, yaitu keluaran hanya bergantung pada nilai
masukan pada saat itu yang diperoleh melalui koneksi dan nilai yang tersimpan dalam
memori lokal.
Aplikasi Identifikasi Suara adalah salah satu contoh dari JST. Aplikasi
Identifikasi Suara berfungsi untuk mengenali suara atau bunyi seperti halnya
fingerprint recognition (identifikasi pola sidik jari pada setiap orang), retinal scan
(identifikasi berdasarkan pola pembuluh darah pada retina mata), face recognition
(pengenalan seseorang berdasarkan raut dan ekspresi seseorang dengan kunci utama
pada letak mata dan mulut). Suatu Aplikasi Identifikasi Suara mempunyai keakuratan

yang berbeda-beda dalam mengenali atau mengidentifikasi suara tergantung dari
beberapa faktor seperti metode ekstraksi ciri, metode recognition, noise, dan lain-lain.
Keakuratan unjuk kerja Aplikasi Identifikasi Suara dapat dicari dengan menggunakan
persamaan sederhana, yaitu
% 𝑃𝑒𝑛𝑔𝑒𝑛𝑎𝑙𝑎𝑛 =𝐽𝑢𝑚𝑙𝑎ℎ 𝑠𝑎𝑚𝑝𝑒𝑙 𝑦𝑎𝑛𝑔 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖
𝐽𝑢𝑚𝑙𝑎ℎ 𝑠𝑎𝑚𝑝𝑒𝑙 𝑝𝑎𝑑𝑎 𝑑𝑎𝑡𝑎𝑏𝑎𝑠𝑒 𝑥 100% …………………….…. (2.2)
2.6 Mel Frequency Cepstrum Coefficient (MFCC)
Ekstraksi fitur pada ASR (Automatic Speech Recognition) merupakan proses
perhitungan urutan dari fitur vektor yang mampu merepresentasikan sinyal wicara yang
ada secara optimal (Dave, 2013). Fitur yang biasa digunakan adalah cepstral
coefficient. MFCC merupakan metode ekstraksi fitur yang menghitung koefisien
cepstral yang didasarkan pada variasi dari frekuensi kritis pada telinga manusia. Filter
dipetakan secara linear pada frekuensi rendah (< 1 kHz) dan logaritmik pada frekuensi
tinggi (> 1kHz) untuk mendapatkan karakteristik suara yang penting (Vibha, 2009).
Adapun tahapan-tahapan dalam MFCC adalah sebagai berikut.
a. Frame Blocking
Tahap ini sinyal suara analog dibagi menjadi beberapa frame yang terdiri
dari N sample, masing-masing frame dipisahkan oleh M, dengan M adalah
banyaknya pergeseran antar frame (M<N). Frame pertama berisi sampel N
pertama. Frame kedua dimulai M sampel setelah permulaan frame pertama,
sehingga frame kedua ini overlap terhadap frame pertama sebanyak N-M
sample. Selanjutnya, frame ketiga akan dimulai M sampel setelah frame
kedua. Proses ini berlanjut sampai seluruh suara tercakup dalam frame.
Hasil dari proses ini adalah matriks dengan N baris dan beberapa kolom
sinyal X[N]. Proses ini ditunjukkan pada dibawah, Sn adalah nilai sampel
yang dihasilkan dan n adalah urutan sampel yang akan diproses

Gambar 2.3 Frame Blocking
Sumber :Aria (2013)
b. Windowing
Proses framing dapat menyebabkan terjadinya kebocoran spektral yaitu
sinyal yang baru memiliki frekuensi yang berbeda dengan sinyal aslinya.
Efek ini dapat terjadi karena rendahnya jumlah sampling rate ataupun
karena proses frame blocking dimana menyebabkan sinyal menjadi
discontinue. Untuk mengurangi kemungkinan terjadinya kebocoran
spektral ini maka hasil dari proses framing harus melewati proses
windowing. Konsep windowing adalah meruncingkan sinyal ke angka nol
pada permulaan dan akhir setiap frame. Proses ini dilakukan dengan
mengalikan antar frame dengan jenis window yang digunakan. Jika window
didefinisikan sebagai ( ), , dengan adalah jumlah sampel dalam tiap frame,
maka proses windowing ini dapat dituliskan dalam persamaan berikut.:
𝑦(𝑛) = 𝑥(𝑛)𝑤(𝑛), 0 ≤ 𝑛 ≤ 𝑁 − 1 ………………………..……. (2.3)
dengan
𝑦(𝑛) = sinyal hasil windowing sampel ke-𝑛
𝑥(𝑛) = nilai sampel ke-𝑛
𝑤(𝑛) = nilai window ke-𝑛
𝑁 = jumlah sampel dalam frame
Penelitian suara banyak menggunakan window hamming karena
kesederhanaan formulanya dan nilai kerja window. Dengan pertimbangan
tersebut, maka penggunaan window Hamming cukup beralasan.

Persamaan window Hamming adalah :
𝑤(𝑛) = 0.54 − 0.46 𝑐𝑜𝑠2𝜋𝑛
𝑁−1 …………………………….....…. (2.4)
dengan
𝑛 = 0,1,…,N-1
c. Fast Fourier Transform
Tahapan selanjutnya ialah mengubah setiap frame yang terdiri dari N
samples dari domain waktu ke dalam domain frekuensi. Output dari proses
ini disebut dengan nama spektrum atau periodogram. Sinyal dalam domain
frekuensi dapat diproses dengan lebih mudah dibandingkan data pada
domain waktu, karena pada domain frekuensi, amplitudo suara tidak terlalu
berpengaruh. Fast Fourier Transform (FFT) adalah algoritma yang
mengimplementasikan Discrete Fourier Transform (DFT) yang
dioperasikan pada sebuah sinyal waktu diskrit yang terdiri dari sampel
menggunakan persamaan berikut.
𝑅𝑒𝑎𝑙𝑋[𝑘] = ∑ 𝑥[𝑖]. cos (2𝜋𝑘𝑖
𝑁)𝑁−1
𝑖=0 ……………………….…. (2.5)
𝐼𝑚𝑎𝑗𝑖𝑛𝑒𝑟𝑋[𝑘] = − ∑ 𝑥[𝑖]. sin (2𝜋𝑘𝑖
𝑁)𝑁−1
𝑖=0 …………………...... (2.6)
dengan
𝑁 = jumlah data
𝑘 = 0,1,2, … ,𝑁
2
𝑥(𝑖) = data pada titik ke-𝑖
Proses selanjutnya adalah menghitung nilai magnitude dari FFT.
Persamaan yang digunakan adalah persamaan berikut :
|𝑋[𝑘]| = √(𝑅𝑒𝑎𝑙𝑋[𝑘])2 + (𝐼𝑚𝑎𝑗𝑖𝑛𝑒𝑟𝑋[𝑘])2 …................….. (2.7)
d. Mel-Frequency Wrapping
Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara
ternyata tidak hanya bersifat linear. Penerimaan sinyal suara untuk

frekuensi rendah (<1k Hz) bersifat linear, dan untuk frekuensi tinggi (>1k
Hz) bersifat logaritmik. Jadi, untuk setiap nada dengan frekuensi
sesungguhnya , sebuah pola diukur dalam sebuah skala yang disebut “mel”
(berasal dari Melody). Skala ini didefinisikan oleh Stanley Smith, John
Volkman dan Edwin Newman sebagai :𝐹𝑚𝑒𝑙 =
{2595 × 𝑙𝑜𝑔10 (1 +
𝐹𝐻𝑧
700) , 𝐹𝐻𝑧 > 1000
𝐹𝐻𝑧, 𝐹𝐻𝑧 < 1000 …………………….…. (2.8)
Sebuah pendekatan untuk simulasi spektrum dalam skala mel adalah
dengan menggunakan filter bank yang diletakkan secara seragam dalam
skala mel seperti yang ditunjukkan pada gambar di bawah ini dimana setiap
frame yang diperoleh dari tahapan sebelumnya difilter menggunakan M
filter segitiga sama tinggi dengan tinggi satu.
Gambar 2.4 Mel-spaced Filter Blank
Sumber:http://izanami.tl.fukuokau.ac.jp/SLPL/HMM/HTKBook/img159.gif
Bila spektrum F[N] adalah masukan proses ini, maka keluarannya adalah
spektrum M[N[ yaitu spektrum F[N] termodifikasi yang berisi power output
dari filter-filter ini. Koefisien spektrum mel dinyatakan dengan K. Dalam
mel-frequency wrapping, sinyal hasil FFT dikelompokkan ke dalam berkas
filter triangular ini. Proses pengelompokan tersebut adalah setiap nilai FFT
dikalikan terhadap gain filter yang bersesuaian dan hasilnya dijumlahkan.
Maka setiap kelompok mengandung sejumlah bobot energi sinyal
sebagaimana dinyatakan sebagai seperti ditunjukkan pada gambar diatas.

Proses wrapping terhadap sinyal dalam domain frekuensi dilakukan
menggunakan persamaan berikut.
𝑋𝑖 = 𝑙𝑜𝑔10(∑ 𝑋(𝑘). 𝐻𝑖(𝑘)𝑁−1𝑘=0 ) …......................……………… .. (2.9)
dengan
𝑋𝑖 = nilai frequency wrapping pada filter𝑖 = 1, 2, … , 𝑛(jumlah filter)
𝑋𝑛 = nilai magnitude frekuensi pada 𝑘 frekuensi
𝑋𝑖(𝑘) = nilai tinggi filter𝑖 segitiga dan 𝑘 frekuensi, dengan 𝑘 =
0,1, … , 𝑁 − 1 (jumlah magnitude frekuensi)
e. Cepstrum
Cepstrum adalah sebutan kebalikan untuk spectrum. Cepstrum biasa
digunakan untuk mendapatkan informasi dari suatu sinyal suara yang
diucapkan oleh manusia. Pada tahap terakhir pada MFCC ini, spektrum log
mel akan dikonversi menjadi domain waktu menggunakan DCT
menggunakan persamaan berikut.
𝑐𝑗 = ∑ 𝑋𝑖𝑀𝑖=1 . cos (
𝑗(𝑖−1)
2.
𝜋
𝑀) …......................…………….. .. (2.10)
dengan
𝐶𝑖 = nilai koefisien 𝐶𝑘𝑒𝑗
𝑗 = 1,2,… jumlah koefisien yang diharapkan
𝑋𝑖 = nilai 𝑋 hasil mel-frequeny wrapping pada frekuensi 𝑖 =
1,2, … , 𝑛(jumlah wrapping)
𝑀= jumlah filter
Hasil dari proses ini dinamakan Mel-Frequency Cepstrum Coefficients
(MFCC).
2.7 Hidden Markov Model
Hidden Markov Model (HMM) merupakan model stokastik dimana suatu
sistem yang dimodelkan diasumsikan sebagai markov proses dengan kondisi yang

tidak terobservasi. Suatu HMM dapat dianggap sebagai jaringan Bayesian dinamis
yang sederhana (Simplest Dynamic Bayesian Network) (Prasetyo, 2010).
HMM adalah sebuah model statistik dari sebuah sistem yang diasumsikan
sebuah proses Markov dengan parameter yang tak diketahui, dan tantangannya adalah
menentukan parameter-parameter tersembunyi (hidden) dari parameter-parameter
yang dapat diamati (Lestary, 2010). Setiap kondisi memiliki distribusi kemungkinan
disetiap output yang berbeda. Oleh karena itu urutan langkah yang dibuat oleh HMM
memberikan suatu informasi tentang urutan dari keadaan. Sifat hidden atau
tersembunyi berarti bahwa kondisi langkah yang dilewati model tersebut. Walaupun
parameter model diketahui, model tersebut tetap tersembunyi. HMM dapat digunakan
untuk aplikasi dibidang temporal pattern recognition seperti pengenalan suara, tulisan,
gesture, bioinformatika, kompresi kalimat, computer vision, ekonomi, finansial, dan
pengenalan not balok.
HMM adalah finite state machine stokastik yang akan menghasilkan barisan
simbol-simbol observasi. Setiap state yang ada memiliki fungsi probabilitas yang
berfungsi untuk mengenerate simbol observasi. Dalam HMM, hanya urutan observasi
saja yang dapat teramati, sedangan urutan statenya tersembunyi. Secara umum (Adami,
2010), HMM terdiri atas elemen-elemen berikut :
1. Himpunan nilai output observasi𝑂 = {𝑜1, 𝑜2, … , 𝑜𝑀}, dimana 𝑀adalah
jumlah simbol observasi.
2. Himpunanstate𝛺 = {1,2, … , 𝑁}. Dimana 𝑁 menyatakan jumlah state yang
terdapat pada HMM.
3. Himpunan probabilitas transisi antar state. Pada dasarnya, diasumsikan
bahwa state berikutnya tergantung pada state pada saat ini. Asumsi ini
menyebabkan proses perhitungan menjadi lebih mudah dan efisien untuk
dilakukan.Probabilitas transaksi dapat dinyatakan dengan sebuah matriks
A= {𝑎𝑖𝑗} , dimana 𝑎𝑖𝑗adalah probabilitas transaksi dari state 𝑖ke state 𝑗.
Sebagai contoh :

𝑎𝑖𝑗 = 𝑃(𝑠𝑡 = 𝑗|𝑠𝑡−1 = 𝑖), 1 ≤ 𝑖, 𝑗 ≤ 𝑁 …....…………….. .. (2.11)
dimana𝑠𝑡 merupakan state pada waktu ke-𝑡.
4. Himpunan probabilitas output 𝐵 = {𝑏𝑖(𝑘)}pada setiap state. Yang juga
disebut probabilitas emisi, 𝑏𝑖(𝑘)adalahprobabilitas dari simbol output 𝑜𝑘
pada state 𝑖 yang didefinisikan sebagai
𝑏𝑖(𝑘) = 𝑃(𝑣𝑡 = 𝑜𝑘|𝑠𝑡 = 𝑖) …....……………………………... (2.12)
dimana 𝑣𝑡adalah simbol observasi pada waktu ke-𝑡.
5. Himpunan state awal𝜋 = {𝜋𝑖}, dimana 𝜋𝑖adalah probabilitas state 𝑖
menjadi state awal pada urutan state HMM.
Gambar 2.5 Parameter Probabilistik pada Hidden Markov Model
Sumber:http://www.google.com/imgres?imgurl=http://en.academic.ru/pictures/enwiki/72/Hidden
MarkovModel.png
Penjelasan :
x = kondisi
y = observasi yang mungkin
a = kemungkinan keadaan transisi
b = kemungkinan output
2.8 Vector Quantization

Menurut Kusumadewi (2003), Vector Quantization adalah suatu metode untuk
melakukan pembelajaran pada lapisan kompetitif yang terawasi. Suatu lapisan
kompetitif akan secara otomatis belajar untuk mengklasifikasikan vektor-vektor input.
Kelas-kelas yang didapatkan sebagai hasil dari lapisan kompetitif ini hanya tergantung
pada jarak antara vektor-vektor input. Jika 2 vektor input mendekati sama, maka
lapisan kompetitif akan meletakkan kedua vektor input tersebut kedalam kelas yang
sama.
Teknik VQ terdiri dari mengekstraksi sebagian kecil vektor corak sebagai
contoh untuk menandai karakter spesifik pembicara agar lebih efisien. Dengan
penggunaan corak data suara pelatihan yang diklustering untuk membentuk suatu
codebook untuk masing-masing pembicara. Dalam langkah pengenalan, data dari
pembicara yang diuji dibandingkan kepada codebook dari tiap pembicaradan
mengukurperbedaannya. Perbedaan ini kemudian digunakan untuk membuat
keputusan pengenalan suara dari pembicara tersebut.
Gambar 2.6 Vektor Sebelum Mengalami Proses Vector Quantization
Gambar 2.7 Vektor Setelah Proses Vector Quantization

2.8.1 Arsitektur Vector Quantization
Menurut Putro (2011), arsitektur VQ sama halnya dengan SOM (Self
Organizing Map), VQ juga terdiri dari 2 lapisan, input (x) dan output (y), dimana antara
lapisannya dihubungkan oleh bobot tertentu yang sering disebut sebagai vektor
pewakil. Informasi yang diberikan ke jaringan pada saat pembelajaran bukan hanya
vektor data saja melainkan informasi kelas dari data juga ikut dimasukkan.
Gambar 2.8 Arsitektur Vector Quantization
Sumber: (Azizi, 2013)
Ketika hasil pemrosesan jaringan memberikan hasil klasifikasi yang sama
dengan informasi kelas yang diberikan di awal, maka vektor pewakil akan disesuaikan
agar lebih dekat dengan vektor masukan. Sebaliknya ketika hasil klasifikasi tidak sama
dengan informasi kelas yang diberikan di awal, maka vektor pewakil akan disesuaikan
agar menjauhi vektor masukan.




















