
BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · Dari tiga defenisi sistem ... jumlah atribut...
16
11 BAB II TINJAUAN PUSTAKA 2.1 Sistem Pendukung Keputusan Sistem pendukung keputusan pertama kali diperkenalkan pada tahun 1970 oleh Michael S. Scott dengan istilah management decision systemyang merupakan suatu sistem berbasi computer yang membantu pengambilan keputusan dengan memanfaatkan data dan model-model untuk menyelesaikan masalah-masalah yang tidak terstruktur. (Turban, 2005) Menurut Surbakti (2002), sistem pendukung keputusan mendayagunakan resources individu-individu secara intelek dengan kemampuan komputer untuk meningkatkan kualitas keputusan. Menurut Maryan Alavi dan H. Albert Napler, sistem pendukung keputusan merupakan suatu kumpulan prosedur pemrosesan data dan informasi yang berorientasi pada penggunaan model untuk menghasilkan berbagai jawaban yang dapat membantu manajemen dalam pengambilan keputusan.Sistem ini harus sederhana, mudah dan adaptif. Dari tiga defenisi sistem pendukung keputusan diatas dapat ditarik kesimpulan bahwa sistem pendukung keputusan adalah sebuah sistem berbasis komputer yang dapat melakukan bantuan dalam pengambilan keputusan untuk memecahkan suatu masalah dengan memanfaatkan data dan model tertentu. 2.2 Karakteristik dan Nilai Guna Sistem Pendukung Keputusan Berikut karakteristik sistem pendukung keputusan menurut Turban : 1. Sistem pendukung keputusan dirancang untuk membantu pengambil keputusan dalam memcahkan masalah yang sifatnya semi terstruktur ataupun tidak terstruktur. 2. Dalam proses pengolahannya, sistem pendukung keputusan mengombina- sikan penggunaan model-model analisis dengan teknik pemasukan data konvensional serta fungsi-fungsi pencari informasi.
Transcript of BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · Dari tiga defenisi sistem ... jumlah atribut...

11
BAB II
TINJAUAN PUSTAKA
2.1 Sistem Pendukung Keputusan
Sistem pendukung keputusan pertama kali diperkenalkan pada tahun 1970
oleh Michael S. Scott dengan istilah management decision systemyang merupakan
suatu sistem berbasi computer yang membantu pengambilan keputusan dengan
memanfaatkan data dan model-model untuk menyelesaikan masalah-masalah
yang tidak terstruktur. (Turban, 2005)
Menurut Surbakti (2002), sistem pendukung keputusan mendayagunakan
resources individu-individu secara intelek dengan kemampuan komputer untuk
meningkatkan kualitas keputusan.
Menurut Maryan Alavi dan H. Albert Napler, sistem pendukung keputusan
merupakan suatu kumpulan prosedur pemrosesan data dan informasi yang
berorientasi pada penggunaan model untuk menghasilkan berbagai jawaban yang
dapat membantu manajemen dalam pengambilan keputusan.Sistem ini harus
sederhana, mudah dan adaptif.
Dari tiga defenisi sistem pendukung keputusan diatas dapat ditarik
kesimpulan bahwa sistem pendukung keputusan adalah sebuah sistem berbasis
komputer yang dapat melakukan bantuan dalam pengambilan keputusan untuk
memecahkan suatu masalah dengan memanfaatkan data dan model tertentu.
2.2 Karakteristik dan Nilai Guna Sistem Pendukung Keputusan
Berikut karakteristik sistem pendukung keputusan menurut Turban :
1. Sistem pendukung keputusan dirancang untuk membantu pengambil
keputusan dalam memcahkan masalah yang sifatnya semi terstruktur
ataupun tidak terstruktur.
2. Dalam proses pengolahannya, sistem pendukung keputusan mengombina-
sikan penggunaan model-model analisis dengan teknik pemasukan data
konvensional serta fungsi-fungsi pencari informasi.

12
3. Sistem pendukung keputusan dirancang sedemikian rupa sehingga dapat
digunakan dengan mudah oleh orang-orang yang tidak memiliki dasar
kemampuan tinggi. Oleh karena itu pendekatan yang digunakan biasanya
model interaktif.
4. Sistem pendukung keputusan dirancang dengan menekankan pada aspek
fleksibelitas serta kemampuan adaptasi yang tinggi. Sehinggan mudah
disesuaikan dengan berbagai perubahan lingkungan yang terjadi dan
kebutuhan pemakai.
Dengan berbagai karakter diatas, sistem pendukung keputusan dapat
memberikan berbagai manfaat atau keuntungan bagi pemakainya. Berikut
keuntungannya :
a. Memperluas kemampuan pengambil keputusan dalam memproses data.
b. Menyediakan bukti tambahan untuk memberikan pembenaran sehingga
dapat memperkuat posisi pengambil keputusan.
c. Menghemat waktu dalam pengambilan keputusan.
2.3 Case Based Reasoning (CBR)
Case BasedReasoning (CBR) merupakan sebuah metode yang digunakan
untuk menyelesaikan permasalahan dengan memanfaatkan kejadian kejadian lama
sebagai solusi dari kasus yang baru dengan melihat tingkat kemiripanya.
Menurut Aamodt dan Plaza (1994) Case-Based Reasoning adalah suatu
pendekatan untuk menyelesaikan suatu permasalahan (problem solving)
berdasarkan solusi dari permasalahan sebelumnya. Case-based Reasoning ini
merupakan suatu paradigma pemecahan masalah yang banyak mendapat
pengakuan yang pada dasarnya berbeda dari pendekatan utama AI lainnya. Suatu
masalah baru dipecahkan dengan menemukan kasus yang serupa di masa lampau,
dan menggunakannya kembali pada situasi masalah yang baru. Perbedaan lain
dari CBR yang tidak kalah penting adalah CBR juga merupakan suatu pendekatan
ke arah incremental yaitu pembelajaran yang terus menerus. Dalam Case-Based
Reasoning ada empat tahapan yang meliputi:
1. Retrieve

13
Mendapatkan kembali kasus yang paling relevan (similar) dengan
kasus yang baru.Tahap retrieval ini dimulai dengan menggambarkan
sebagian masalah, dan diakhiri jika ditemukan kecocokan terhadap
masalah sebelumnya yang tingkat kecocokannya paling tinggi.Bagian ini
mengacu pada segi identifikasi, kecocokan awal, pencarian dan pemilihan
serta eksekusi.
2. Reuse
Memodelkan/menggunakan kembali pengetahuan dan informasi
kasus lama berdasarkan bobot kemiripan yang paling relevan ke dalam
kasus yang baru, sehingga menghasilkan usulan solusi dimana mungkin
diperlukan suatu adaptasi dengan masalah yang baru tersebut.
3. Revise
Meninjau kembali solusi yang diusulkan kemudian mengetesnya
pada kasus nyata (simulasi) dan jika diperlukan memperbaiki solusi
tersebut agar cocok dengan kasus yang baru.
4. Retain
Mengintegrasikan kasus baru yang telah berhasil mendapatkan
solusi agar dapat digunakan oleh kasus-kasus selanjutnya yang mirip
dengan kasus tersebut, tetapi Jika solusi baru tersebut gagal, maka
menjelaskan kegagalannya, memperbaiki solusi yang digunakan, dan
mengujinya lagi.
Empat proses masing-masing melibatkan sejumlah langkah-langkah spesifik, yang
dijelaskan pada Gambar 2.1

14
Gambar 2.1Tahapan Proses dalam Case Based Reasoning
(A. Aamodt & E. Plaza, 1994)
Pada saat terjadi permasalahan baru, pertama-tama sistem melakukan
proses retrieve. Proses retrieve melakukan dua langkah pemrosesan, yaitu
pengenalan masalah dan pencarian persamaan masalah pada database. Setelah
proses retrieve selesai dilakukan, selanjutnya sistem melakukan proses reuse. Di
dalam proses reuse, sistem menggunakan informasi permasalahan sebelumnya
yang memiliki kesamaan untuk menyelesaikan permasalahan yang baru. Pada
proses reuse dilakukan penyalinan, penyeleksian, dan melengkapi informasi yang
digunakan. Selanjutnya pada proses revise, informasi tersebut dikalkulasi,
dievaluasi, dan diperbaiki kembali untuk mengatasi kesalahan-kesalahan yang
terjadi pada permasalahan baru.
Pada proses terakhir, sistem melakukan proses retain. Proses retain
mengindeks, mengintegrasi, dan mengekstrak solusi yang baru tersebut kedalam
database. Selanjutnya, solusi baru itu disimpan di dalam basis pengetahuan
(knowledgebase) untuk menyelesaikan permasalahan yang akan datang. Tentunya,
permasalahan yang memiliki kesamaan.

15
2.4 Nearest Neighbor
Nearest Neighbor adalah pendekatan untuk mencari kasus dengan
menghitung kedekatan antara kasus baru dengan kasus lama, yaitu berdasarkan
pada pencocokan bobot dari sejumlah fitur yang ada.Misalkan diinginkan untuk
mencari solusi terhadap seorang pasien baru dengan menggunakan solusi dari
pasien terdahulu. Untuk mencari kasus pasien mana yang akan digunakan maka
dihitung kedekatan kasus pasien baru dengan semua kasus pasien lama. Kasus
pasien lama dengan kedekatan terbesar-lah yang akan diambil solusinya untuk
digunakan pada kasus pasien baru.
Gambar 2.2 Ilustrasi Kedekatan Kasus
Seperti tampak pada Gambar 2, terdapat dua pasien lama A dan B. Ketika
ada pasien Baru, maka solusi yang akan diambil adalah solusi dari pasien terdekat
dari pasien Baru. Seandainya d1 adalah kedekatan antara pasien Baru dan pasien
A, sedangkan d2 adalah kedekatan antara pasien Baru dengan pasien B. Karena d2
lebih dekat dari d1 maka solusi dari pasien B lah yang akan digunakan untuk
memberikan solusi pasien Baru.
Adapun rumus untuk melakukan penghitungan kedekatan antara dua kasus
adalah sebagai berikut:
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 𝑇, 𝑆 = 𝑓 𝑇𝑖 ,𝑆𝑖 ∗ 𝑊𝑖𝑛
𝑖=1
𝑊𝑖…………………………………….(2.1)
dengan
T : kasus baru
S : kasus yagn ada dalam penyimpanan
n : jumlah atribut dalam masing-masing kasus

16
i : atribut individu antara 1 s/d n
f : fungsi similarity atribut i antara kasus T dan kasus S
w : bobot yang diberikan pada atribut ke i
Kedekatan biasanya berada pada nilai antara 0 s/d 1. Nilai 0 artinya kedua
kasus mutlak tidak mirip, sebaliknya untuk nilai 1 kasus mirip dengan
mutlak.Untuk memudahkan pemahaman diberikan kasus kemungkinan seorang
nasabah bank akan bermasalah dalam pembayarannya atau tidak, seperti tampak
pada Tabel 2.1.
Tabel 2.1 Tabel Kasus
No Jenis
Kelamin
Pendidikan Agama Bermasalah
1 L S1 Islam Ya
2 P SMA Kristen Tidak
3 L SMA Islam Ya
Atribut Bermasalah merupakan atribut tujuan. Bobot antara satu atribut
dengan atribut yang lain pada atribut bukan tujuan dapat didefinisikan dengan
nilai berbeda. Sebagai contoh didefinisikan bobot untuk masing-masing atribut
seperti tampak pada Tabel 2.2.
Tabel 2.2 Definisi Bobot Atribut
Atribut Bobot
Jenis Kelamin 0.5
Pendidikan 1
Agama 0.75
Kedekatan antara nilai-nilai dalam atribut juga perlu didefinikan. Sebagai
contoh dalam pembahasan ini, kedekatan nilai Atribut Jenis kelamin ditunjukkan
pada Tabel 2.3, kedekatan nilai Atribut Pendidikan ditunjukkan pada Tabel 2.4
dan kedekatan nilai Atribut Agama ditunjukkan pada Tabel 2.5.

17
Tabel 2.3Kedekatan Atribut Jenis Kelamin
Nilai 1 Nilai 2 Kedekatan
L L 1
P P 1
L P 0.5
P L 0.5
Tabel 2.4 Kedekatan Nilai Atribut Pendidikan
Nilai 1 Nilai 2 Kedekatan
S1 S1 1
SMA SMA 1
S1 SMA 0.4
SMA S1 0.4
Tabel 2.5 Kedekatan Nilai Atribut Agama
Nilai 1 Nilai 2 Kedekatan
Islam Islam 1
Kristen Kristen 1
Islam Kristen 0.75
Kristen Islam 0.75
Misalkan ada kasus nasabah baru dengan nilai atribut:
Jenis Kelamin : L
Pendidikan : SMA
Agama : Kristen
Dengan menggunakan tabel 2.2, tabel 2.3, tabel 2.4, dan tabel 2.5 maka
untuk kasus yang baru dapat dihitung kedekatanya dengan masing – masing kasus
yang ada pada tabel 2.1 :
a. Menghitung kedekatan kasus baru dengan kasus no 1
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑡𝑦 = 1 ∗ 0.5 + 0.4 ∗ 1 + 0.75 ∗ 0.75
0.5 + 1 + 0.75=
1.4625
2.25= 0.625

18
b. Menghitung kedekatan kasus baru dengan kasus no 2
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑡𝑦 = 0.5 ∗ 0.5 + 1 ∗ 1 + 0.75 ∗ 0.75
0.5 + 1 + 0.75=
1.8125
2.25= 0.8
c. Menghitung kedekatan kasus baru dengan kasus no 3
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑡𝑦 = 1 ∗ 0.5 + 1 ∗ 1 + 0.75 ∗ 0.75
0.5 + 1 + 0.75=
2.0625
2.25= 0.9
Dari langkah a, b dan c dapat diketahui bahwa nilai tertinggi adalah kasus
3.Berarti kasus yang terdekat dengan kasus baru adalah kasus 3. Maka klasifikasi
dari kasus 3 yang akan digunakan untuk memprediksi kasus baru. Yaitu
kemungkinan nasabah baru akan Tidak Bermasalah.
2.5 System Development Life Cycle (SDLC)
System Development Life Cycle (SDLC) adalah sebuah model konseptual
yang digunakan dalam pengelolaan projek yang menggambarkan tahapan-tahapan
yang dilibatkan dalam projek pengembangan sistem informasi dari studi
kelayakan awal sampai maintenance dari aplikasi.
2.6 Metode Pengembangan Waterfall
Model waterfall adalah proses pengembangan perangkat lunak tradisional
yang umum digunakan dalam proyek – proyek perangkat lunak yang paling
pembangunan. Ini adalah model sekuensial, sehingga penyelesaian satu set
kegiatan menyebabkan dimulainya aktivitas berikutnya. Hal ini disebut waterfall
karena proses mengalir secara sistematis dari satu tahap ke tahap lainnya dalam
model ke bawah. Membentuk kerangka kerja untuk pengembangan perangkat
lunak.Beberapa varian darimodelada, setiap label yang berbeda menggunakan
untuk setiap tahap.Secara umum, bagaimanapun, model ini dianggap memiliki
enam tahap yang berbeda seperti yang ditunjukkan pada model proses perangkat
lunak merupakan deskripsi sederhana dari proses perangkat lunak yang
menyajikan suatu pandangan dari proses tersebut(Sommerville, 2011).Model
proses mencakup kegiatan yang merupakan bagian dari proses perangkat lunak,
19
produk perangkat lunak, dan peran orang yang terlibat dalam rekayasa perangkat
lunak. Model waterfall memiliki tahapan - tahapan dalam proses nya, setiap
tahapan tersebut harus diselesaikan sebelum berlanjut ke tahap berikutnya.
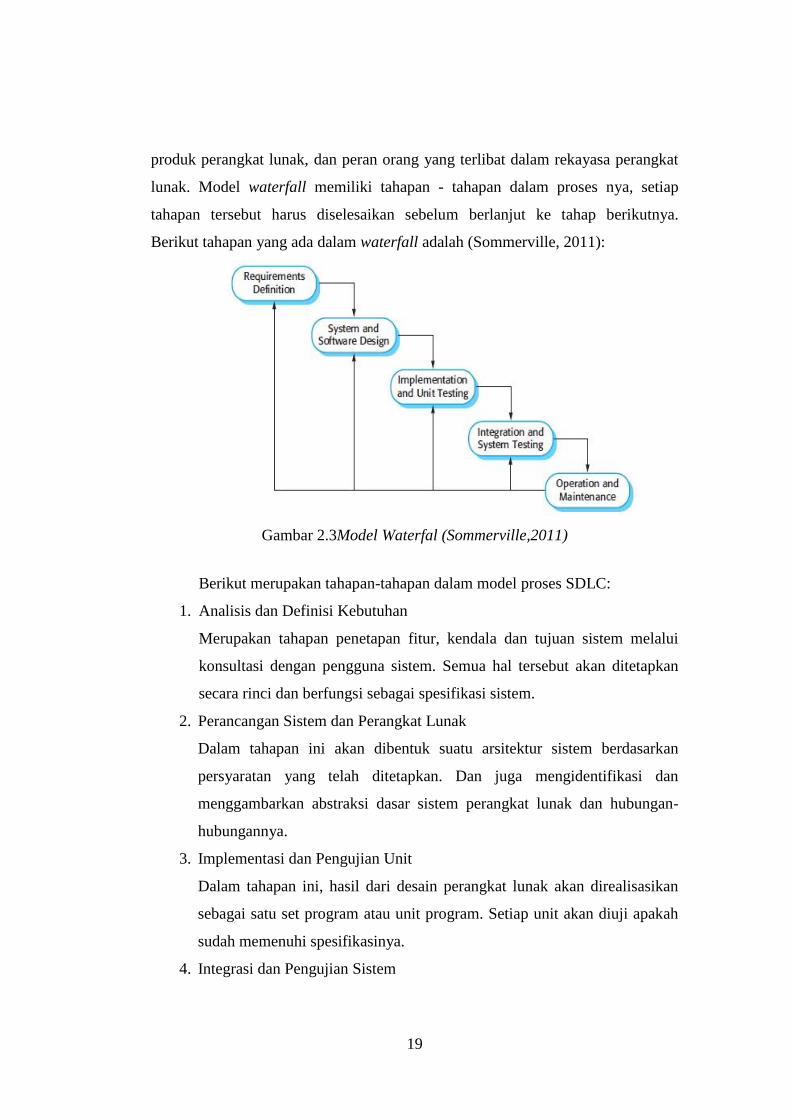
Berikut tahapan yang ada dalam waterfall adalah (Sommerville, 2011):
Gambar 2.3Model Waterfal (Sommerville,2011)
Berikut merupakan tahapan-tahapan dalam model proses SDLC:
1. Analisis dan Definisi Kebutuhan
Merupakan tahapan penetapan fitur, kendala dan tujuan sistem melalui
konsultasi dengan pengguna sistem. Semua hal tersebut akan ditetapkan
secara rinci dan berfungsi sebagai spesifikasi sistem.
2. Perancangan Sistem dan Perangkat Lunak
Dalam tahapan ini akan dibentuk suatu arsitektur sistem berdasarkan
persyaratan yang telah ditetapkan. Dan juga mengidentifikasi dan
menggambarkan abstraksi dasar sistem perangkat lunak dan hubungan-
hubungannya.
3. Implementasi dan Pengujian Unit
Dalam tahapan ini, hasil dari desain perangkat lunak akan direalisasikan
sebagai satu set program atau unit program. Setiap unit akan diuji apakah
sudah memenuhi spesifikasinya.
4. Integrasi dan Pengujian Sistem

20
Dalam tahapan ini, setiap unit program akan diintegrasikan satu sama lain
dan diuji sebagai satu sistem yang utuh untuk memastikan sistem sudah
memenuhi persyaratan yang ada. Setelah itu sistem akan dikirim ke
pengguna sistem.
5. Operasi dan Pemeliharaan
Dalam tahapan ini, sistem diinstal dan mulai digunakan. Selain itu juga
memperbaiki error yang tidak ditemukan pada tahap pembuatan. Dalam
tahap ini juga dilakukan pengembangan sistem seperti penambahan fitur
dan fungsi baru.
2.7 Normalisasi
2.7.1 Definisi Normalisasi
Proses normalisasi adalah proses pengelompokan data elemen menjadi
tabel-tabel yang menunjukkan entity dan relasinya. Normalisasi merupakan
sebuah teknik dalam logical desain sebuah basis data atau database, teknik
pengelompokkan atribut dari suatu relasi sehingga membentuk struktur relasi yang
baik (tanpa redudansi). Pada proses normalisasi dilakukan pengujian pada
beberapa kondisi apakah ada kesulitan pada saat menambah/menyisipkan,
menghapus, mengubah dan mengakses pada suatu basis data. Bila terdapat
kesulitan pada pengujian tersebut maka perlu dipecahkan relasi pada beberapa
tabel lagi atau dengan kata lain perancangan basis data belum optimal. Tujuan dari
normalisasi yaitu :
a. Menghilangkan kerangkapan data,
b. Mengurangi kompleksitas, dan
c. Mempermudah pemodifikasian data.
Sebuah tabel dikatakan baik (efisien) atau normal jika memenuhi 3 kriteria sbb:
1. Jika ada dekomposisi (penguraian) tabel, maka dekomposisinya harus
dijamin aman (Lossless-Join Decomposition). Artinya, setelah tabel
tersebut diuraikan / didekomposisi menjadi tabel-tabel baru, tabel-tabel
baru tersebut bisa menghasilkan tabel semula dengan sama persis.
2. Terpeliharanya ketergantungan fungsional pada saat perubahan data
(Dependency Preservation).

21
3. Tidak melanggar Boyce-Codd Normal Form (BCNF)
Jika kriteria ketiga (BCNF) tidak dapat terpenuhi, maka paling tidak tabel tersebut
tidak melanggar Bentuk Normal tahap ketiga (3rd Normal Form atau 3NF). Tabel
2.1 merupakan yang akan dilakukan proses normalisasi.
Tabel 2. 6 Tabel Unnormal
PNo PName ENo EName Jcode ChgHr Hrs
1 Alpha 101 John Doe NE $65 20
105 Jane Vo SA $80 15
110 Bob Lund CP $60 40
2 Beta 101 John Doe NE $65 20
108 Jeb Lee NE $65 15
106 Sara Lee SA $80 20
3 Omega 102 Beth Reed PM $125 20
105 Jane Vone SA $80 10
2.7.2 Bentuk – Bentuk Normalisasi
1. Bentuk Normal Tahap Pertama (1st Normal Form atau 1NF)
Suatu relasi dikatakan sudah memenuhi bentuk normal ke satu
(1NF) bila data bersifat atomic yaitu setiap irisan baris dan kolom hanya
mempunyai satu nilai data. Tabel 2.6 dapat diubah menjadi bentuk normal
tahap pertama (1NF) dengan menambahkan PNo dan PName di setiap
baris sehingga akan terbentuk tabel 2.7
Tabel 2. 7 Tabel 1NF
PNo Pname ENo Ename Jcode ChgHr Hrs
1 Alpha 101 John Doe NE $65 20
1 Alpha 105 Jane Vo SA $80 15
1 Alpha 110 Bob Lund CP $60 40
2 Beta 101 John Doe NE $65 20
22
2 Beta 108 Jeb Lee NE $65 15
2 Beta 106 Sara Lee SA $80 20
3 Omega 102 Beth Reed PM $125 20
3 Omega 105 Jane Vone SA $80 10
2. Bentuk Normal Tahap Kedua (2st Normal Form atau 2NF)
Bentuk normal kedua yaitu dengan melakukan dekomposisi tabel
2.7 menjadi beberapa relasi dengan mencari kandidat primary key. Syarat
bentuk normal tahap kedua yaitu sudah memenuhi dalam bentuk normal
kesatu (1NF), semua atribut bukan kunci hanya boleh tergantung
(functional dependency) pada atribut kunci. Jika ada ketergantungan
parsial maka atribut tersebut harus dipisah pada tabel yang lain. Perlu ada
tabel penghubung ataupun kehadiran foreign key bagi atribut-atribut yang
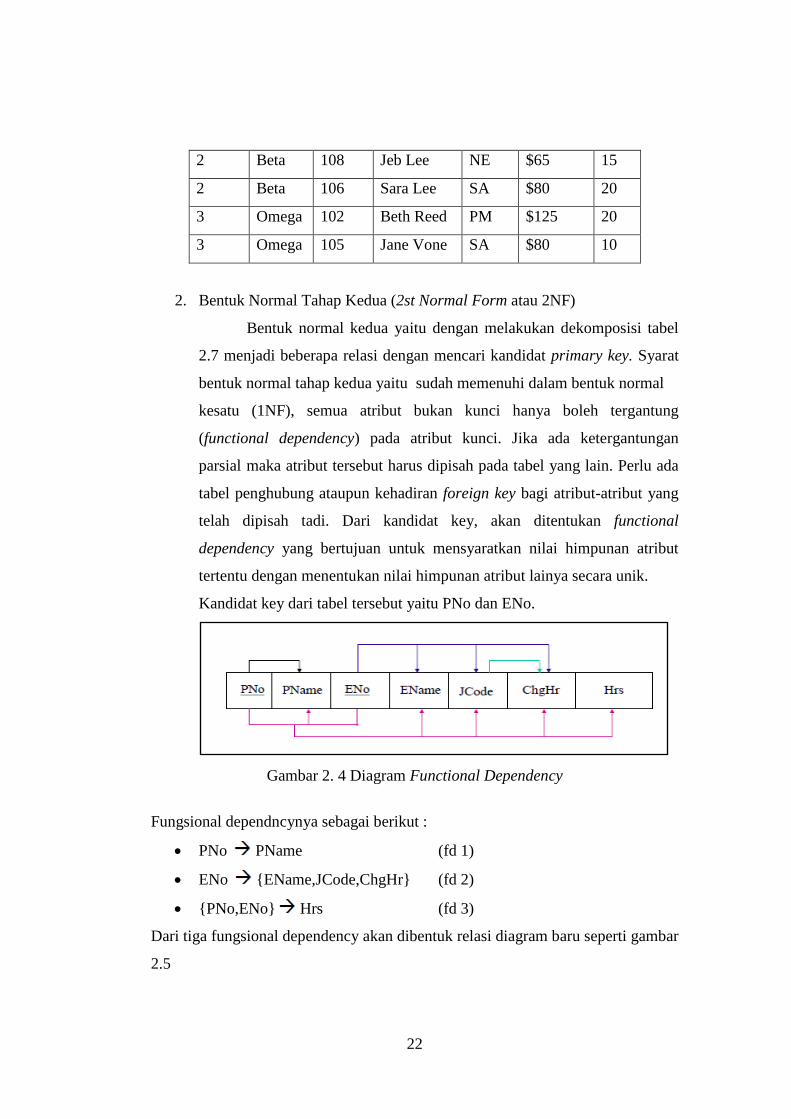
telah dipisah tadi. Dari kandidat key, akan ditentukan functional
dependency yang bertujuan untuk mensyaratkan nilai himpunan atribut
tertentu dengan menentukan nilai himpunan atribut lainya secara unik.
Kandidat key dari tabel tersebut yaitu PNo dan ENo.
Gambar 2. 4 Diagram Functional Dependency
Fungsional dependncynya sebagai berikut :
PNo PName (fd 1)
ENo {EName,JCode,ChgHr} (fd 2)
{PNo,ENo} Hrs (fd 3)
Dari tiga fungsional dependency akan dibentuk relasi diagram baru seperti gambar
2.5

23
Gambar 2. 5 Digram 2NF
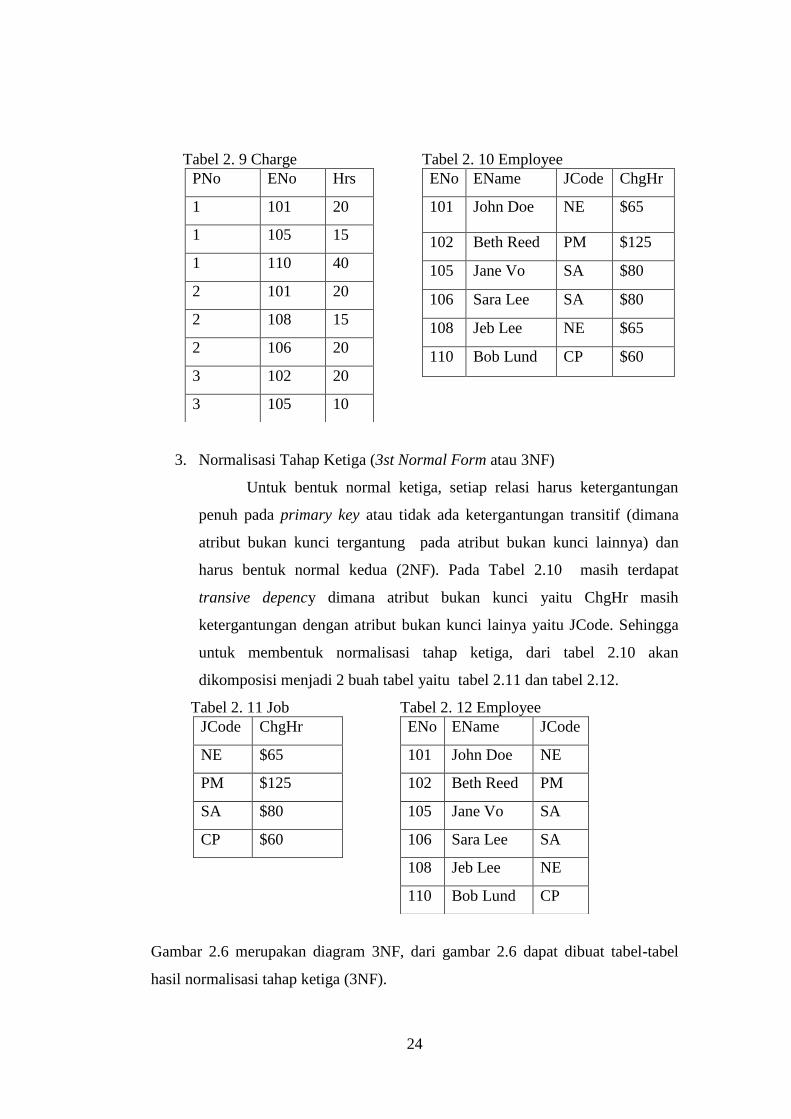
Dari gambar 2.5 akan dibentuk tiga buah tabel 2NF yaitu tabel Project, Charge,
dan Employee sebagai berikut
Tabel 2. 8 Project
PNo PName
1 Alpha
2 Beta
3 Omega
24
Tabel 2. 9 Charge
PNo ENo Hrs
1 101 20
1 105 15
1 110 40
2 101 20
2 108 15
2 106 20
3 102 20
3 105 10
Tabel 2. 10 Employee
ENo EName JCode ChgHr
101 John Doe NE $65
102 Beth Reed PM $125
105 Jane Vo SA $80
106 Sara Lee SA $80
108 Jeb Lee NE $65
110 Bob Lund CP $60
3. Normalisasi Tahap Ketiga (3st Normal Form atau 3NF)
Untuk bentuk normal ketiga, setiap relasi harus ketergantungan
penuh pada primary key atau tidak ada ketergantungan transitif (dimana
atribut bukan kunci tergantung pada atribut bukan kunci lainnya) dan
harus bentuk normal kedua (2NF). Pada Tabel 2.10 masih terdapat
transive depency dimana atribut bukan kunci yaitu ChgHr masih
ketergantungan dengan atribut bukan kunci lainya yaitu JCode. Sehingga
untuk membentuk normalisasi tahap ketiga, dari tabel 2.10 akan
dikomposisi menjadi 2 buah tabel yaitu tabel 2.11 dan tabel 2.12.
Tabel 2. 11 Job
JCode ChgHr
NE $65
PM $125
SA $80
CP $60
Tabel 2. 12 Employee
ENo EName JCode
101 John Doe NE
102 Beth Reed PM
105 Jane Vo SA
106 Sara Lee SA
108 Jeb Lee NE
110 Bob Lund CP
Gambar 2.6 merupakan diagram 3NF, dari gambar 2.6 dapat dibuat tabel-tabel
hasil normalisasi tahap ketiga (3NF).

25
Gambar 2. 6 Diagram 3NF
Dari hasil normalisasi tahap ketiga (3NF), terbentuk 4 buah tabel yaitu tabel 2.8
Projetct, tabel 2.9 Charge, tabel 2.11 Job, dan tabel 2.12 Employee.
2.7 Tinjauan Studi
Terdapat beberapa penilitian yang pernah dilakukan dengan menggunakan
Case Base Reasoning sebagai metode sistem pendukung keputusan diantaranya :
a. Pembangunan Aplikasi Trevel Recommender Dengan Metode Case
Base Reasoning (Uung Ungkawa, Dewi Rosmala, Fanny Aryanti,
2013).Pada penelitian ini diimplementasikan metode CBR untuk
membantu perekomendasian wisata. .Kasus-kasus yang dipergunakan
dalam sistem diperoleh dari beberapa sumber data real tentang objek
wisata di Jawa Barat. Sistem akan memberikan keluaran berupa jenis
objek wisata yang direkomendasikan serta perkiraan biaya akomodasi
yang didasarkan pada kemiripan kasus baru dengan pengetahuan yang
dimiliki sistem. Berdasarkan pengujian Aplikasi Travel Recommender
dapat memberikan rekomendasi wisata berdasarkan rencana wisata
sebelumnya dengan tingkat keberhasilan 60% dan kegagalan 40%.

26
b. Sistem Berbasis Kasus Untuk Diagnosis Penyakit Melalui Hasil
Pemeriksaan Laboratorium (Lusiana Indriasari Sagita, Sri
Kusumadewi, 2009). Penelitian ini bertujuan membuat suatu sistem
berbasis kasus untuk diagnosis penyakit melalui hasil pemeriksaan
laboratorium dengan menggunakan model penalaran Case Based
Reasoning (CBR). Sistem berbasis kasus untuk diagnosis penyakit melalui
pemeriksaan laboratorium merupakan sistem yang dapat menentukan
suatu keputusan mengenai diagnosis penyakit melalui hasil pemeriksaan
laboratorium dengan menggunakan metode CBR. Selain diagnosis
penyakit, sistem akan memberikan informasi penyebab tinggi rendahnya
suatu nilai penyakit, sistem akan memberikan informasi penyebab tinggi
rendahnya suatu nilai pemeriksaan dan solusi terapinya. Dengan aplikasi
ini diharapkan dapat memberikan manfaat yang lebih untuk melakukan
diagnosis penyakit dan proses rekam medik pasien.
c. Sistem Pakar Menentukan Kerusakan Televisi Dengan Metode Case
Based Reasoning (Nur Hidayah, 2015). Penelitian ini bertujuan
membuat sistem ini semoga dapat membantu masyarakat dalam
mendiagnosa kerusakan televisi mereka . Dalam hal ini mereka tidak
perlu repot-repot untuk memanggil reparasi atau membawaketempat
reparasi televisi. Disini penulis memberikan solusu-solusinya untuk
menyelesaikan masalahmasalah yang timbul pada televisi yang sering
muncul. Dalam penelitian ini peulis juga memberikan cara perawatan –
perwawan Televisi. Dengan menggunakan metode Case Based Reasoning
dapat diterapkan dalam pembuatan aplikasi sistem pakar mendeteksi
kerusakan Televisi sehingga membantu masyarakat awam dalam
memperbaiki kerusakan Televisi.




















