
BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id BAB II.pdf · mengetahui pola angin dan kondisi cuaca di...
14
5 BAB II TINJAUAN PUSTAKA Hal-hal yang dipaparkan pada Bab Tinjauan Pustaka adalah penelaahan kepustakaan yang mendasari proses perancangan dan pembuatan aplikasi meliputi data mining, Customer Relationship Management, segmentasi pelanggan, Metode DBSCAN, teori pengukuran jarak dan uji validitas cluster. 2.1 State of the Art Penelitian tentang data mining untuk CRM, khususnya untuk proses segmentasi pelanggan, serta Model RFM dan Metode DBSCAN telah beberapa kali dilakukan sebelumnya. Ching-Hsue Cheng menggunakan teknik data mining untuk menemukan pola dan trend dari data konsumen dalam kaitannya dengan Konsep CRM. Proses clustering dilakukan terhadap data konsumen C-company, yaitu perusahaan yang bergerak di bidang industri elektronik. Proses clustering didahului dengan mendefinisikan skala dari Atribut RFM. Atribut inilah yang digunakan sebagai input dalam proses clustering yang dilakukan dengan Algoritma K-Means (Cheng, 2009). Luh Putu Dian Shavitri Handayani sebelumnya melakukan proses segmentasi pelanggan menggunakan Metode Jaringan Syaraf Tiruan ART 2 dan Model RFM untuk mengetahui pelanggan potensial pada Perusahaan Retail UD. Fenny. Proses clustering dilakukan dengan membentuk beberapa cluster dan dicari jumlah cluster optimalnya dengan menggunakan Indeks Validitas Silhouette. Hasil rata-rata keseluruhan nilai indeks validitas tiap cluster mendekati 1, yang mana artinya Metode Jaringan Syaraf Tiruan ART 2 telah dapat melakukan proses segmentasi dengan baik (Luh Putu, 2012). Penelitian lain dilakukan oleh Zakrzewska, D. untuk menerapkan konsep data mining dalam proses segmentasi pelanggan (customer segmentation) pada sebuah bank. Penelitian ini membandingkan tiga algoritma clustering dalam hal high dimensionality data with noise yaitu DBSCAN, K-Means, dan Two-phase Clustering (Zakrzewska, 2005).
Transcript of BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id BAB II.pdf · mengetahui pola angin dan kondisi cuaca di...

5
BAB II
TINJAUAN PUSTAKA
Hal-hal yang dipaparkan pada Bab Tinjauan Pustaka adalah penelaahan
kepustakaan yang mendasari proses perancangan dan pembuatan aplikasi meliputi data
mining, Customer Relationship Management, segmentasi pelanggan, Metode
DBSCAN, teori pengukuran jarak dan uji validitas cluster.
2.1 State of the Art
Penelitian tentang data mining untuk CRM, khususnya untuk proses segmentasi
pelanggan, serta Model RFM dan Metode DBSCAN telah beberapa kali dilakukan
sebelumnya. Ching-Hsue Cheng menggunakan teknik data mining untuk menemukan
pola dan trend dari data konsumen dalam kaitannya dengan Konsep CRM. Proses
clustering dilakukan terhadap data konsumen C-company, yaitu perusahaan yang
bergerak di bidang industri elektronik. Proses clustering didahului dengan
mendefinisikan skala dari Atribut RFM. Atribut inilah yang digunakan sebagai input
dalam proses clustering yang dilakukan dengan Algoritma K-Means (Cheng, 2009).
Luh Putu Dian Shavitri Handayani sebelumnya melakukan proses segmentasi
pelanggan menggunakan Metode Jaringan Syaraf Tiruan ART 2 dan Model RFM untuk
mengetahui pelanggan potensial pada Perusahaan Retail UD. Fenny. Proses clustering
dilakukan dengan membentuk beberapa cluster dan dicari jumlah cluster optimalnya
dengan menggunakan Indeks Validitas Silhouette. Hasil rata-rata keseluruhan nilai
indeks validitas tiap cluster mendekati 1, yang mana artinya Metode Jaringan Syaraf
Tiruan ART 2 telah dapat melakukan proses segmentasi dengan baik (Luh Putu, 2012).
Penelitian lain dilakukan oleh Zakrzewska, D. untuk menerapkan konsep data
mining dalam proses segmentasi pelanggan (customer segmentation) pada sebuah bank.
Penelitian ini membandingkan tiga algoritma clustering dalam hal high dimensionality
data with noise yaitu DBSCAN, K-Means, dan Two-phase Clustering (Zakrzewska,
2005).

6
2.2 Data Mining
Data mining secara sederhana merujuk pada ekstraksi atau pertambangan
pengetahuan dari sejumlah besar data. Data mining juga dikatakan sebagai kegiatan
menemukan pattern yang unik dari data dalam jumlah besar, data dapat disimpan
dalam database, data warehouse, atau penyimpanan informasi yang lain. Data mining
berkaitan dengan bidang ilmu-ilmu lain seperti database system, data warehousing,
statistic, machine learning, information retrieval, dan komputasi tingkat tinggi. Data
mining selain itu didukung oleh ilmu lain seperti neural network, pengenalan pola,
spatial data analysis, image database, signal processing (Han, 2006). Data mining
adalah langkah dalam KDD (Knowledge Discovery in Database) yang terdiri dari
penerapan analisis data dan penemuan algoritma untuk menghasilkan daftar pola atau
model tertentu terhadap data yang dianalisa (Fayyad, 1996). Gambar 2.1 menunjukkan
data mining sebagai bagian dari KDD.
Gambar 2.1 Hubungan KDD dengan proses data mining (Fayyad, 1996)
Data mining banyak diterapkan untuk memecahkan masalah kepentingan
intelektual, ekonomi, dan bisnis. Data mining dapat dibagi kedalam enam tugas, yaitu
sebagai berikut (Berry & Linoff, 2004):
1. Klasifikasi
Klasifikasi terdiri dari tindakan pengujian pada fitur baru dan
mengelompokkannya ke dalam salah satu dari sekumpulan kelas yang telah
diidentifikasi.

7
2. Estimasi
Estimasi berhubungan dengan nilai kontinyu, jika terdapat beberapa input data,
estimasi akan bekerja dengan nilai dari beberapa variabel kontinyu yang tidak
diketahui seperti pendapatan, tinggi atau credit card balance.
3. Prediksi
Prediksi adalah tugas yang sama seperti pada klasifikasi dan estimasi
perbedaannya prediksi mengelompokkan berdasarkan beberapa prediksi yang
berkaitan dengan waktu mendatang atau perkiraan waktu mendatang.
4. Afinitas
Tugas dari afinitas didefinisikan sebagai tindakan untuk mengelompokkan hal
mana yang akan dikelompokkan ke dalam kelompok yang sama.
5. Clustering
Tugas dalam clustering yaitu mensegmentasi populasi heterogen ke dalam sub
grup homogen atau clusters. Perbedaan dengan klasifikasi adalah pada
clustering tidak ditentukan target pengelompokkan.
6. Deskripsi dan Penentuan Profil
Sebuah deskripsi yang baik seringkali memberikan penjelasan yang baik juga
sehingga proses deskripsi dan penentuan profil ini sangat berguna untuk
mengetahui pengetahuan yang terdapat pada database yang rumit.
Tiga tugas pertama merupakan contoh data mining yang terawasi (supervised
learning), di mana tujuannya adalah untuk menemukan nilai dari variabel target
tertentu. Afinitas dan clustering adalah tugas tidak diawasi (unsupervised learning),
tujuannya adalah untuk menggungkap pengetahuan yang ada, sedangkan profiling
adalah tugas deskriptif yang mungkin akan baik diawasi atau tidak diawasi.
2.3 Profil Aston Inn Tuban
Archipelago International atau yang sebelumnya dikenal sebagai Aston
International adalah sebuah Hotel Management Chain di Asia Tenggara dan
merupakan yang terbesar di Indonesia. Aston International memasuki pasar Asia
Tenggara sejak tahun 1997 dan saat ini telah memiliki portfolio yang terdiri lebih dari

8
100 properti yang terdiri dari hotel, condotel, resort, serviced apartment dan boutique
villa resort yang mana 86 diantaranya telah beroperasi dan 100 lebih lainnya sedang
dalam proses pengembangan. Aston Inn Tuban merupakan satu dari sekian banyak
cabang Aston International yang ada di Bali (David Ling, 2012).
2.4 Customer Relationship Management (CRM)
Pelanggan adalah aset yang paling penting dari sebuah organisasi. Prospek
bisnis tanpa memuaskan pelanggan yang loyal dan mengembangkan hubungan yang
baik terhadap perusahaan adalah hal yang tidak mungkin. Perusahaan untuk itu harus
merencanakan dan menggunakan strategi yang tepat dalam pelayanan pelanggan. CRM
(Customer Relationship Management) adalah strategi untuk membangun, mengelola,
dan memperkuat hubungan perusahaan dengan pelanggan yang loyal agar dapat
tercipta hubungan yang tahan lama. CRM harus merupakan pendekatan customer-
centric berdasarkan pandangan pelanggan. Ruang lingkup penanganan pelanggan
dalam CRM harus bersifat personal karena setiap pelanggan merupakan entitas yang
unik. Upaya tersebut dilakukan untuk mengidentifikasi dan memahami perbedaan
kebutuhan, prefensi dan perilaku dari tiap pelanggan yang berbeda-beda (Tsiptsis &
Chorianopoulus, 2009).
Pengembangan bisnis dengan memusatkan pada hubungan terhadap pelanggan
merupakan perubahan yang revolusioner untuk kebanyakan perusahaan. Perusahaan
kini telah merubah tujuan dalam pemahaman pelanggan secara individual menjadi
melihat nilai yang dimiliki tiap pelanggan sehingga pihak perusahaan mengetahui
pelanggan mana yang memiliki nilai yang tinggi dan layak dijadikan investasi dan
dipertahankan dan pelanggan mana yang memiliki nilai yang rendah (Berry & Linoff,
2004).
Diperkirakan dalam riset American Management Association bahwa untuk
menarik pelanggan baru membutuhkan biaya lima kali lebih banyak dibandingkan
mempertahankan pelanggan yang telah ada. (Kotler, 1994; Peppers & Rogers, 1996)
Perusahaan dapat mempersingkat daur penjualan dan meningkatkan loyalitas
pelanggan untuk membangun hubungan yang dekat dengan pelanggan sehingga

9
kemudian dapat mendatangkan keuntungan. Penerapan CRM yang baik membantu
perusahaan tetap menjaga pelanggan yang telah ada dan menarik pelanggan baru
(Peppard, 2000).
Perusahaan harus mampu menganalisa berbagai nilai yang terdapat pada
masing-masing pelanggan dan mampu mempertahankan loyalitas pelanggan dalam
waktu yang lama untuk memberikan keuntungan yang maksimal dengan
memanfaatkan CRM sebagai strategi bisnis.
2.5 Data Mining dalam Kerangka Kerja CRM
Data mining dapat menyediakan pandangan dari segi pelanggan yang
merupakan elemen penting dalam membangun CRM yang efektif. Hal ini dapat
meningkatkan interaksi dengan pelanggan sehingga memaksimalkan tingkat kepuasan
pelanggan serta dapat memberikan keuntungan melalui analisis pada data. Hal ini dapat
mendukung manajemen pelanggan secara individual dan mengoptimalkan semua life
cycle pelanggan mulai dari akuisisi dan membentuk hubungan yang kuat untuk
mencegah pengurangan pelanggan. Bagian pemasaran berusaha untuk mendapatkan
pangsa pasar yang lebih besar dan mendapatkan pangsa pelanggan yang lebih besar.
Bagian pemasaran memiliki tanggung jawab untuk mendapatkan, mengembangkan dan
menjaga pelanggan. Aktivitas pemasaran yang dapat didukung dengan data mining
secara spesifik meliputi topik berikut (Tsiptsis & Chorianopoulos, 2009):
1. Segmentasi Pelanggan
Segmentasi pelanggan adalah proses untuk membagi pelanggan ke dalam
kelompok homogen yang unik dalam rangka pengembangan strategi pasar yang
berbeda berdasarkan karakteristiknya. Banyak perbedaan tipe yang terdapat
dalam segmentasi pelanggan berdasarkan kriteria dan atribut yang spesifik
untuk segmentasi
2. Pemasaran Langsung
Bagian pemasaran menggunakan pemasaran langsung untuk
mengkomunikasikan pesan kepada pelanggan menggunakan surat, internet, e-
mail, dan telepon (tele marketing) untuk mengarahkan pelanggan untuk

10
membeli produk yang ditawarkan. Metode tersebut secara lebih spesifik
digunakan untuk mendapatkan pelanggan yang potensial.
3. Asosiasi
Data mining dan asosiasi model dapat digunakan untuk mengidentifikasikan
hubungan antara produk yang biasanya dibeli secara bersamaan. Hal ini
digunakan untuk mengetahui produk mana yang dapat dijual secara bersamaan.
Hubungan data mining dan CRM dalam perusahaan perhotelan yaitu dapat
membantu untuk mengidentifikasi sifat pelanggan dalam bertransaksi,
mempertahankan pelanggan dan memberi kepuasan terhadap pelanggan,
meningkatkan rasio konsumsi barang, merancang transportasi barang yang baik
dan aturan pendistribusian serta mengurangi biaya bisnis (Han, 2006).
2.6 Model RFM
Model RFM membagi data kedalam tiga aspek dimensi variabel yaitu Recency
(R), Frequency (F), Monetary (M). Deskripsi lengkap dari RFM adalah sebagai berikut
(Hughes, 1994):
1. Recency adalah interval waktu antara transaksi terakhir yang dilakukan
pelanggan dengan waktu sekarang atau selama periode tertentu. Interval waktu
yang semakin dekat antara waktu terakhir melakukan transaksi dengan waktu
sekarang atau akhir periode yang ditetapkan maka semakin besar nilai dari
Recency.
2. Frequency didefinisikan sebagai jumlah kali transaksi yang dilakukan
pelanggan sampai waktu sekarang atau periode yang ditentukan. Jumlah kali
transaksi pelanggan (rutin melakukan pembelian) yang semakin banyak,
semakin tinggi nilai Frequency-nya.
3. Monetary memiliki definisi sebagai jumlah biaya yang dikeluarkan pelanggan
dalam setiap transaksi sampai waktu sekarang atau dalam periode tertentu.
Jumlah biaya yang dikeluarkan semakin banyak, maka semakin besar nilai
Monetary-nya.
11
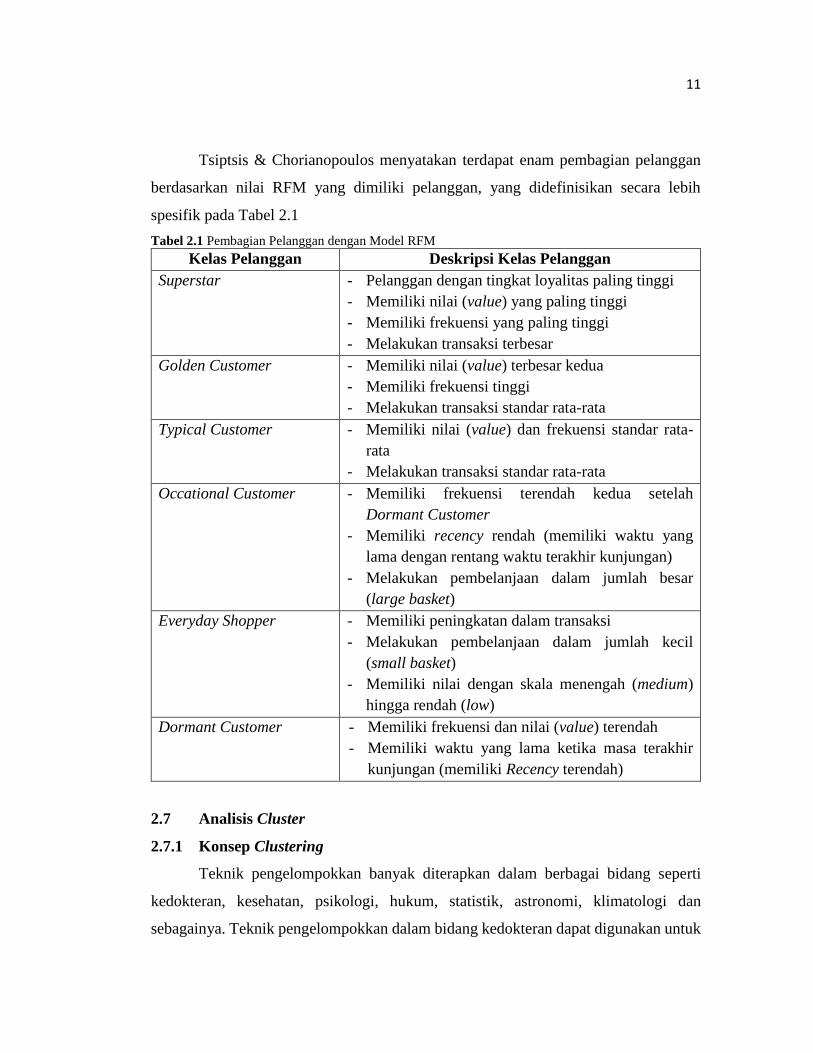
Tsiptsis & Chorianopoulos menyatakan terdapat enam pembagian pelanggan
berdasarkan nilai RFM yang dimiliki pelanggan, yang didefinisikan secara lebih
spesifik pada Tabel 2.1
Tabel 2.1 Pembagian Pelanggan dengan Model RFM
Kelas Pelanggan Deskripsi Kelas Pelanggan
Superstar - Pelanggan dengan tingkat loyalitas paling tinggi
- Memiliki nilai (value) yang paling tinggi
- Memiliki frekuensi yang paling tinggi
- Melakukan transaksi terbesar
Golden Customer - Memiliki nilai (value) terbesar kedua
- Memiliki frekuensi tinggi
- Melakukan transaksi standar rata-rata
Typical Customer - Memiliki nilai (value) dan frekuensi standar rata-
rata
- Melakukan transaksi standar rata-rata
Occational Customer - Memiliki frekuensi terendah kedua setelah
Dormant Customer
- Memiliki recency rendah (memiliki waktu yang
lama dengan rentang waktu terakhir kunjungan)
- Melakukan pembelanjaan dalam jumlah besar
(large basket)
Everyday Shopper - Memiliki peningkatan dalam transaksi
- Melakukan pembelanjaan dalam jumlah kecil
(small basket)
- Memiliki nilai dengan skala menengah (medium)
hingga rendah (low)
Dormant Customer - Memiliki frekuensi dan nilai (value) terendah
- Memiliki waktu yang lama ketika masa terakhir
kunjungan (memiliki Recency terendah)
2.7 Analisis Cluster
2.7.1 Konsep Clustering
Teknik pengelompokkan banyak diterapkan dalam berbagai bidang seperti
kedokteran, kesehatan, psikologi, hukum, statistik, astronomi, klimatologi dan
sebagainya. Teknik pengelompokkan dalam bidang kedokteran dapat digunakan untuk

12
mengelompokkan jenis-jenis penyakit berbahaya berdasarkan karakteristik/sifat-sifat
penyakit pasien. Teknik pengelompokkan dalam bidang kesehatan dapat digunakan
untuk mengelompokkan jenis-jenis makanan berdasarkan kandungan kalori, vitamin
dan protein. Teknik pengelompokkan dalam bidang klimatologi dapat digunakan untuk
mengetahui pola angin dan kondisi cuaca di udara sehingga bisa diketahui wilayah-
wilayah yang rentan terhadap cuaca buruk (Eko Prasetyo, 2014).
Analisis cluster adalah pekerjaan mengelompokkan data (objek) yang
didasarkan hanya pada informasi yang ditemukan dalam data yang menggambarkan
hubungan antara objek-objek tersebut (Tan, 2006). Tujuan dari analisis cluster adalah
agar objek-objek yang bergabung dalam sebuah kelompok merupakan objek yang
mirip atau berhubungan satu sama lain dan berbeda dengan objek dalam kelompok
yang lain. Data yang masuk pada Proses Clustering tidak mempunyai label kelas
seperti pada klasifikasi tetapi dikelompokkan berdasarkan karakteristiknya. Masing-
masing cluster setelah itu diberi label sesuai hasil karakteristik kelompok masing-
masing. Clustering karena alasan tersebut disebut juga sebagai unsupervised learning
(Eko Prasetyo, 2014).
2.7.2 Tujuan Clustering
Tujuan clustering data dapat dibedakan menjadi dua yaitu pengelompokan
untuk pemahaman dan pengelompokan untuk penggunaan. Tujuan pemahaman adalah
untuk membuat kelompok yang terbentuk dapat menangkap struktur alami data. Proses
pengelompokan dalam tujuan pemahaman biasanya hanya sebagai proses awal untuk
kemudian dilanjutkan dengan pekerjaan inti seperti peringkasan atau summarization,
pelabelan kelas pada setiap kelompok, dan sebagainya. Tujuan yang digunakan untuk
pengelompokan biasanya adalah mencari prototype kelompok yang paling
representative terhadap data dan memberikan abstraksi dari setiap objek data dalam
kelompok di mana sebuah data terletak di dalamnya (Eko Prasetyo, 2014).

13
2.7.3 Jenis-jenis Clustering
Metode yang dikembangkan oleh para ahli sudah sangat banyak. Masing-
masing metode mempunyai karakter, kelebihan dan kekurangan masing-masing.
Clustering dapat dibedakan menurut struktur kelompok, keanggotaan data dalam
kelompok dan kekompakan data dalam kelompok.
Metode Clustering menurut strukturnya dibagi menjadi dua yaitu
pengelompokan hirarki dan partitioning. Pengelompokan hirarki memiliki aturan satu
data tunggal bisa dianggap sebagai sebuah kelompok, dua atau lebih kelompok kecil
dapat bergabung menjadi satu kelompok besar dan begitu seterusnya hingga semua
data dapat bergabung menjadi satu kelompok. Metode Clustering Hirarki merupakan
satu-satunya metode yang masuk ke dalam kategori pengelompokan hirarki. Metode
Clustering Partitioning membagi set data ke dalam sejumlah kelompok yang tidak
tumpang tindih (overlap) antara satu kelompok dengan kelompok yang lain artinya
setiap data hanya menjadi anggota satu kelompok. Metode seperti K-Means dan
DBSCAN masuk dalam kategori pengelompokan partitioning.
Metode Clustering menurut keanggotaan dalam kelompok dibagi menjadi dua,
yaitu eksklusif dan tumpang-tindih. Metode tersebut termasuk kategori eksklusif jika
sebuah data hanya menjadi anggota satu kelompok dan tidak menjadi anggota
kelompok yang lain. Metode Clustering yang masuk dalam kategori ini adalah K-
Means dan DBSCAN sedangkan yang masuk kategori tumpang-tindih adalah Metode
Clustering yang membolehkan sebuah data menjadi anggota di lebih dari satu
kelompok, misalnya Fuzzy C-Means.
Metode Clustering menurut kategori kekompakan terbagi menjadi dua yaitu
komplet dan parsial. Semua data bisa dikatakan kompak menjadi satu kelompok jika
semua data bisa bergabung menjadi satu (dalam konteks penyekatan) namun jika ada
sedikit data yang tidak ikut bergabung dalam kelompok mayoritas data tersebut
dikatakan mempunyai perilaku menyimpang. Data yang menyimpang ini dikenal
dengan sebutan noise. Metode yang tangguh untuk mendeteksi noise ini adalah
DBSCAN (Eko Prasetyo, 2014).

14
2.7.4 Density-Based Spatial Clustering of Application with Noise (DBSCAN).
Density-Based Spatial Clustering of Application with Noise (DBSCAN)
merupakan sebuah Metode Clustering yang membangun area berdasarkan kepadatan
yang terkoneksi (density-connected). Setiap objek dari sebuah radius area (cluster)
harus mengandung setidaknya sejumlah minimum data. Semua objek yang tidak
termasuk di dalam cluster akan dianggap sebagai noise. Istilah yang terdapat di dalam
algoritma DBSCAN adalah sebagai berikut:
1. Minpts adalah banyak poin minimal di dalam suatu cluster
2. Eps adalah nilai untuk jarak antar poin yang menjadi dasar pembentukan
neighborhood dari suatu titik item
3. Neighborhood yang terletak di dalam suatu radius ∈ disebut ∈ - neighborhood
dari objek data
4. Jika ∈ - neighborhood dari suatu objek berisi paling sedikit suatu angka yang
minimum (Minpts dari suatu objek), objek tersebut disebut sebagai core object.
5. Directly density-reachable, titik poin dikatakan directly density-reachable dari
titik yang lain jika jarak di antara mereka tidak lebih dari nilai Epsilon (∈).
Gambar 2.2 menggambarkan kasus directly density-reachable.
Gambar 2.2 Directly Density-Reachable
Directly density-reachable merupakan pasangan simetris dari core point
walaupun begitu secara umum directly density-reachable bisa asimetris jika
mengandung satu core point dan satu border point. (Aster, M, 1996) Gambar
2.3 menggambarkan kasus asimetris.

15
Gambar 2.3 Kasus Asimetris
Directly density-reachable asimetris mungkin terjadi jika mengandung satu
core point dan satu border point.
6. Density reachable adalah dua titik yang dihubungkan oleh rantai yang hanya
terdiri dari titik-titik yang directly density-reachable dari titik sebelumnya.
Gambar 2.4 menggambarkan kasus density reachable.
Gambar 2.4 Density Reachable
Gambar 2.4 menggambarkan titik yang density reachable. Density reachable
adalah dua titik yang dihubungkan oleh rantai yang hanya terdiri dari titik-titik
yang directly density-reachable dari titik sebelumnya.
7. Density connected, dikatakan demikian jika ada sebuah objek o elemen D
sehingga p dan q keduanya density-reachable dari o dengan memperhatikan
Eps dan Minpts. Gambar 2.5 menggambarkan kasus density connected.

16
Gambar 2.5 Density Connected
Gambar 2.5 menunjukkan kasus density connected, dikatakan demikian jika ada
sebuah objek o elemen D sehingga p dan q keduanya density-reachable dari o
dengan memperhatikan Eps dan Minpts.
Berikut merupakan algoritma dari Metode DBSCAN:
1. Pilih poin p secara acak.
2. Inisialisasi nilai minpts dan eps
3. Ambil semua poin yang density reachable terhadap p.
4. Jika p adalah core point maka cluster terbentuk.
5. Jika p adalah border point, tidak ada yang merupakan hubungan density-
reachable dari p dan DBSCAN mengunjungi poin selanjutnya dari database.
6. Lanjutkan sampai semua poin telah diproses. Hasil yang didapatkan tidak
tergantung dari urutan proses yang diambil.
7. Hitung jarak, apakah masih memenuhi epsilon. Perhitungan menggunakan
Jarak Eucledian sebagai berikut:
𝐸(𝑥, 𝑦) = √∑ (𝑋𝑖 − 𝑌𝑖)2𝑛𝑖=0 ....................................................................... (2.1)
8. Jika titik yang memenuhi epsilon lebih dari Minpts maka cluster terbentuk.
9. Setelah didapat titik jarak yang paling besar, titik itu dijadikan core point.

17
Ringkasan karakteristik Metode DBSCAN dapat dipaparkan sebagai berikut
(Mumtaz, 2008):
1. DBSCAN tidak perlu mengetahui jumlah data secara sesukanya seperti pada
K-Means. Hal ini memberikan keuntungan karena umumnya bentuk dan jumlah
kelompok yang sebaiknya diberikan pada data berdimensi tinggi tidak bisa
diketahui dengan cara analisis visual data.
2. DBSCAN dapat menemukan bentuk kelompok sembarang, bahkan kelompok
berbentuk melingkar yang tidak bisa ditangani K-Means. Hal ini dapat
disesuaikan dengan menentukan nilai MinPts.
3. DBSCAN bisa mengenali derau (noise) dengan baik.
4. Metode DBSCAN hanya membutuhkan dua parameter yang kebanyakan tidak
sensitif terhadap urutan data dalam database tetapi penentuan parameter
Epsilon hanya mudah diberikan ketika melihat data spasial dua dimensi. Data
berdimensi tinggi, nilai Epsilon yang tepat sangat sulit ditentukan.
5. Metode DBSCAN hanya memberikan hasil kelompok yang baik jika
menggunakan Jarak Euclidian tetapi tidak berguna untuk data berdimensi tinggi.
6. Metode DBSCAN tidak dapat memberikan hasil yang baik untuk data yang
mempunyai kelompok kepadatan yang berbeda. Hal ini karena DBSCAN hanya
memandang proses pengelompokan berdasarkan radius epsilon sehingga ketika
ada dua kelompok atau lebih yang mempunyai kepadatan yang berbeda,
DBSCAN tidak bisa memberikan hasil yang baik.
2.8 Validasi Cluster
Evaluasi dari model yang digunakan dilakukan dengan melakukan Proses
Mining pada data set dalam periode satu tahun. Proses Clustering diuji coba dengan
berbagai nilai parameter dari Algoritma Clustering. Hasil clustering diuji tingkat
validitasnya menggunakan Indeks Validitas Silhouette untuk menentukan jumlah
cluster yang terbaik. Proses yang dilakukan dalam validasi cluster untuk menentukan
jumlah cluster optimal adalah sebagai berikut:

18
1. Tentukan jumlah jarak antara core point dengan semua titik yang berada pada
cluster yang sama
2. Hitung nilai rata-rata jarak core point dengan semua titik pada cluster yang
sama a(i) = (i = objek ke 1, 2, 3,…, n)
3. Hitung jumlah jarak antara core point dengan semua titik pada cluster yang
berbeda
4. Hitung nilai rata-rata jarak antara core point dengan semua titik pada cluster
yang berbeda b(i) = (i = cluster ke 1, 2, 3, …, n)
5. Cari nilai minimum b(i)
6. Hitung nilai Indeks Validitas Silhouette tiap titik (Si) dengan rumus
S(i) = (𝑏(𝑖)−𝑎(𝑖))
max{𝑎(𝑖),𝑏(𝑖)} ................................................................................... (2.2)
7. Hitung nilai rata-rata Indeks Validitas Silhouette dengan rumus
GSu = 1
𝑛∑ 𝑠(𝑖)𝑛𝑖=1 ........................................................................................ (2.3)
8. Cluster dengan nilai GSu tertinggi merupakan cluster optimal.




















