
BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id · Algorithm” membahas tentang penggunaan dua...
42
10 BAB II TINJAUAN PUSTAKA 2.1 State Of The Art Pada penelitian Laetitia Jourdan, Clarisse Dhaenens, El-Ghazali Talbi yang berjudul “A Genetic Algorithm for Feature Selection in Data Mining for Genetic” dilakukan penyelesaian masalah seleksi fitur dengan menggunakan algoritma genetik dan menggunakan algoritma K-Means untuk clustering dalam menemukan fitur genetik dan faktor lingkungan yang terlibat dalam penyakit multifaktorial seperti obesitas dan diabetes. Hasil penelitian ini didapatkan bahwa algoritma genetik berhasil memilih fitur menarik dan K-Means dapat memasangkan kelas individu sesuai dengan fitur. Penelitian yang dilakukan oleh Kyoung-jae Kim dan Hyunchul Ahn dalam “A recommender system using GA K-Means clustering in an online shopping market” membahas tentang penggunaan algoritma clustering Algoritma Genetik dan K-Means untuk segmentasi pasar. Penelitian dilakukan dengan mengambil studi kasus dunia nyata, yaitu pada perdagangan elektronik dan menemukan bahwa penggabungan antara Algoritma Genetik dan K-Means mengakibatkan segmentasi yang lebih baik dari algoritma clustering tradisional sederhana, seperti K-Means dan SOM (Self Organizing Map). Pada penelitian Hsiang-Hsi Liu, Chorng-Shyong Ong yang berjudul “Variable selection in clustering for marketing segmentation using genetic
Transcript of BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id · Algorithm” membahas tentang penggunaan dua...

10
BAB II
TINJAUAN PUSTAKA
2.1 State Of The Art
Pada penelitian Laetitia Jourdan, Clarisse Dhaenens, El-Ghazali Talbi
yang berjudul “A Genetic Algorithm for Feature Selection in Data Mining for
Genetic” dilakukan penyelesaian masalah seleksi fitur dengan menggunakan
algoritma genetik dan menggunakan algoritma K-Means untuk clustering dalam
menemukan fitur genetik dan faktor lingkungan yang terlibat dalam penyakit
multifaktorial seperti obesitas dan diabetes. Hasil penelitian ini didapatkan bahwa
algoritma genetik berhasil memilih fitur menarik dan K-Means dapat
memasangkan kelas individu sesuai dengan fitur.
Penelitian yang dilakukan oleh Kyoung-jae Kim dan Hyunchul Ahn dalam
“A recommender system using GA K-Means clustering in an online shopping
market” membahas tentang penggunaan algoritma clustering Algoritma Genetik
dan K-Means untuk segmentasi pasar. Penelitian dilakukan dengan mengambil
studi kasus dunia nyata, yaitu pada perdagangan elektronik dan menemukan
bahwa penggabungan antara Algoritma Genetik dan K-Means mengakibatkan
segmentasi yang lebih baik dari algoritma clustering tradisional sederhana, seperti
K-Means dan SOM (Self Organizing Map).
Pada penelitian Hsiang-Hsi Liu, Chorng-Shyong Ong yang berjudul
“Variable selection in clustering for marketing segmentation using genetic

11
algorithms” dijelaskan mengenai algoritma genetik yang digunakan pada proses
clustering untuk pemilihan variabel yang mengambil studi kasus segmentasi
pemasaran. Hasil dari penelitian menunjukkan bahwa seleksi variabel melalui
algoritma genetik lebih efektif dan dapat menemukan solusi optimum dengan
akurasi dari model diklasifikasikan meningkat secara dramatis setelah clustering.
Penelitian oleh Jihoon Yang and Vasant Honavar yang berjudul “Feature
Subset Selection Using A Genetic Algorithm” menunjukkan bahwa algoritma
genetik menawarkan sebuah pendekatan menarik untuk memecahkan masalah
feature subset selection dalam pembelajaran induktif mengenai klasifikasi pola
jaringan saraf (neural network). Pendekatan berbasis Algoritma Genetik dalam
pemilihan fitur digunakan untuk mengidentifikasi subset yang relevan terhadap
data, sehingga tidak terjadi kelimpahan atribut yang berlebihan namun tidak
relevan atau tidak berguna.
Penelitian oleh Rouhollah Maghsoudi, dkk yang berjudul “Representing
the New Model for Improving K-Means Clustering Algorithm based on Genetic
Algorithm” membahas tentang K-Means yang merupakan teknik pengelompokan
digabungkan dengan metode optimasi algoritma genetik untuk meningkatkan
prosedur klasifikasi. Dalam penelitian ini, dilakukan pendefinisian representasi
string kromosom serta penggabungan K-Means dan Algoritma Genetik bersama-
sama. Mengamati simulasi yang terjadi, hasilnya menunjukkan bahwa
penggabungan K-Means dan algoritma genetik memberikan hasil pengukuran
yang lebih baik dan lebih efisien dibandingkan dengan K-Means saja.

12
Penelitian oleh Oyelade, O. J yang berjudul “Application of K-Means
Clustering algorithm for prediction of Students’ Academic Performance”
membahas tentang penggunaan algoritma cluster K-Means dan dikombinasikan
dengan model deterministik pada dataset sekolah swasta dengan 9 program studi
dan didapatkan hasil bahwa algoritma clustering ini berfungsi sebagai tolok ukur
yang baik untuk memantau perkembangan kinerja siswa dalam institusi.
Penelitian oleh Chauhan, Yogita, Vaibhav Chaurasia dan Chetan Agarwal
yang berjudul “A Survey Of K-Means And GA-KM The Hybrid Clustering
Algorithm” membahas tentang penggunaan dua algoritma klasterisasi, yaitu K-
Means dan algoritma hybrid GA-KM (Genetic Algorithm dan K-Means).
Penggabungan GA-KM untuk mendapatkan jumlah cluster yang optimal dimana
dapat diterapkan untuk berbagai jenis data seperti dataset genom, dataset numerik.
Hasil penelitian menyimpulkan GA-KM lebih baik dibandingkan K-Means.
Penelitian oleh Agus Widodo dan Purhadi yang berjudul “Perbandingan
Metode Fuzzy C-Means Clustering Dan Fuzzy C-Shell Clustering (Studi Kasus:
Kabupaten/Kota Di Pulau Jawa Berdasarkan Variabel Pembentuk Indeks
Pembangunan Manusia)”, ditemukan hasil dengan pembandingan berdasarkan
fungsi objektif, indeks validitas dan waktu komputasinya, didapatkan bahwa
metode Fuzzy C-Means merupakan metode terbaik untuk digunakan dengan
jumlah kelompok yang optimum adalah enam kelompok.

13
Penelitian yang dilakukan oleh Sarita Budiyani Purnamasari dkk.
melanjutkan penelitian Agus Widodo dan Purhadi yang berjudul “Pemilihan
Cluster Optimum Pada Fuzzy C-Means (Studi Kasus: Kabupaten/Kota Di Pulau
Jawa Berdasarkan Variabel Pembentuk Indeks Pembangunan Manusia)” yang
membahas penggunaan Index Xie Beni untuk menemukan cluster terbaik dari
cluster lain yang sudah ditemukan dengan metode Fuzzy C-Means.
Penelitian oleh Annas Syaiful Rizal dan R.B Fajriya Hakim melanjutkan
penelitian Sarita Budiyani Purnamasari dkk. dengan judul penelitian “Metode K-
Means Cluster dan Fuzzy C-Means Cluster (Studi Kasus: Indeks Pembangunan
Manusia di Kawasan Indonesia Timur tahun 2012)”, mendapatkan hasil yang
menunjukkan pengelompokkan dengan Fuzzy C-Means mendapatkan hasil yang
lebih baik jika dibandingkan K-Means karena Fuzzy C-Means menghasilkan rasio
Sw/Sb yang lebih kecil dibandingkan metode K Means.
Berdasarkan beberapa penelitian yang telah dilakukan, maka dalam
penelitian ini diusulkan pendekatan baru yang dapat dilihat pada Gambar 2.1,
dimana dalam penentuan kompetensi mahasiswa digunakan algoritma genetik
untuk pemilihan fitur dan metode Fuzzy C-Means untuk proses clustering.

14
Gambar 2.1 Pendekatan Baru

15
2.2 Kompetensi
Menurut Wibowo (2007), kompetensi adalah suatu kemampuan untuk
melaksanakan atau melakukan suatu pekerjaan yang dilandasi atas
keterampilan dan pengetahuan serta didukung oleh sikap kerja yang dituntut
oleh pekerjaan tersebut. Kompetensi merupakan landasan dasar karakteristik
orang dan mengindikasikan cara berperilaku atau berpikir, menyamakan situasi,
dan mendukung untuk periode waktu cukup lama. Kompetensi berpengaruh
positif terhadap kinerja karyawan pada suatu perusahaan (Posuma, 2013).
2.3 Clustering
Clustering adalah suatu metode pengelompokan berdasarkan ukuran
kedekatan (kemiripan). Klasterisasi (clustering) merupakan proses
mengelompokkan atau menggolongkan obyek berdasarkan informasi yang
diperoleh dari data yang menjelaskan hubungan antar objek dengan prinsip untuk
memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan
kesamaan antar kelas/cluster (Kim, 2008).
Metode clustering secara umum dapat dibagi menjadi dua yaitu
hierarchical clustering dan partitional clustering. Pada hierarchical clustering,
data dikelompokkan melalui suatu bagan yang berupa hirarki, dimana terdapat
penggabungan dua grup yang terdekat disetiap iterasinya ataupun pembagian dari
seluruh set data kedalam klaster-klaster. Prosedur yang digunakan dalam metode
hierarki adalah prosedur pautan tunggal (single linkage), pautan lengkap
(complete linkage), dan pautan rata-rata (average linkage). Sedangkan pada

16
partitional clustering, data dikelompokkan ke dalam sejumlah klaster tanpa
adanya struktur hirarki antara satu dengan yang lainnya.
Pada metode partitional clustering setiap klaster memiliki titik pusat
klaster (centroid) dan secara umum metode ini memiliki tujuan yaitu
meminimumkan jarak dari seluruh data ke pusat klaster masing-masing.
a. Hirarchical clustering method
Pada kasus untuk jumlah kelompok belum ditentukan terlebih dulu,
contoh data-data hasil survey kuisioner
b. Non Hirarchical clustering method
Jumlah kelompok telah ditentukan terlebih dahulu. Salah satu contoh
metode yang digunakan adalah algoritma K-Means.
Berikut ini merupakan contoh data yang akan dilakukan proses klasterisasi
(pengelompokkan):
Gambar 2.2 Data Sebelum Klasterisasi
Jika data dilakukan clustering (pengelompokkan) berdasarkan warna, maka
pengelompokkannya seperti yang terlihat pada gambar 2.2 berikut:

17
Gambar 2.3 Pengelompokan berdasarkan kesamaan warna
Jika data dilakukan clustering (pengelompokkan) berdasarkan bentuk, maka
pengelompokannya dapat dilihat seperti gambar 2.3 berikut:
Gambar 2.4 Pengelompokan berdasarkan kesamaan bentuk
Selain dengan menggunakan similaritas (kesamaan) berdasarkan bentuk
dan warna, clustering juga bisa dilakukan dengan menggunakan similaritas
berdasarkan jarak, artinya data yang memiliki jarak berdekatan akan membentuk
satu cluster.
2.4 Validity Cluster
Terdapat beberapa metode cluster validity, yaitu:
1. Korelasi

18
Menggunakan 2 jenis matriks, yaitu proximity matrix dan incidence matrix
a. Proximity matrix adalah matriks yang berisi jarak antar obyek
b. Incidence matrix adalah matriks biner yang mengindikasikan
keanggotaan klaster
I. 0 jika anggota dari klaster yang berbeda
II. 1 jika anggota dari klaster yang sama
2. Cohession dan Separation
Cohession merupakan cluster validity yang menghitung varian intra klaster
(WSS).
…………………………… 1)
Sedangkan Separation merupakan cluster validity yang menghitung varian
inter klaster(BSS)
………………………………… 2)
3. Silhouette Coefficient
Menggunakan gabungan kedua prinsip dasar dari cohesion dan separation
…………………………….……… 3)
dimana:
a = rata-rata jarak ke obyek satu klaster
b = minimal rata-rata jarak ke obyek berbeda klaster
4. Dunn Index
Memiliki dasar pemikiran bahwa klaster yang baik adalah yang memiliki
diameter yang kecil dan jarak yang besar terhadap klaster lainnya.

19
…………………. 4)
dimana:
a. d(ci, cj) adalah jarak terhadap klaster lain
b. diam(ck) adalah jarak terhadap sesama klaster
5. Davies-Bouldin Index
Memiliki prinsip dasar dalam menghitung similarity antar klaster
……………………………….. 5)
dimana nilai
…….……………………………………….. 6)
a. si adalah rata-rata jarak obyek seluruh klaster i dengan pusatnya
b. dij adalah jarak pusat klaster i dan pusat klaster j
2.5 Feature Selection
Feature selection atau Feature reduction adalah suatu kegiatan yang
umumnya bisa dilakukan secara preprocessing dan bertujuan untuk memilih fitur
yang berpengaruh dan mengesampingkan fitur yang tidak berpengaruh dalam
suatu kegiatan pemodelan atau penganalisaan data. Ada banyak alternatif yang
bisa digunakan dan harus dicoba-coba untuk mencari yang cocok. Secara garis
besar ada dua kelompok besar dalam pelaksanaan feature selection, yaitu ranking
selection dan subset selection.
Pemilihan fitur merupakan kegiatan yang termasuk ke dalam
preprocessing yang bertujuan untuk memilih fitur yang berpengaruh dan

20
mengesampingkan fitur yang tidak berpengaruh dalam suatu kegiatan pemodelan
atau penganalisaan data. Terdapat banyak alternatif yang dapat digunakan dan
juga dilakukan proses mencoba-coba untuk mencari fitur yang cocok (Laetitia,
2001).
2.5.1 Ranking Selection
Ranking selection secara khusus memberikan ranking pada setiap fitur
yang ada dan mengesampingkan fitur yang tidak memenuhi standar tertentu.
Ranking selection menentukan tingkat ranking secara independent antara satu
fitur dengan fitur yang lainnya. Fitur yang mempunyai ranking tinggi akan
digunakan dan yang fitur yang mempunyai ranking rendah akan dikesampingkan.
Ranking selection ini biasanya menggunakan beberapa cara dalam memberikan
nilai ranking pada setiap fitur misalnya regression, correlation, mutual
information dan lain-lain.
2.5.2 Subset Selection
Subset selection adalah metode selection yang mencari suatu set dari fitur
yang dianggap sebagai optimal feature. Ada tiga jenis metode yang bisa
digunakan yaitu selection dengan tipe wrapper, selection dengan tipe filter dan
selection dengan tipe embedded.
a. Feature Selection Tipe Wrapper
Feature selection tipe wrapper ini melakukan feature selection dengan
melakukan pemilihan bersamaan dengan pelaksanaan pemodelan.
Selection tipe ini menggunakan suatu criterion yang memanfaatkan

21
classification rate dari metode pengklasifikasian/pemodelan yang
digunakan. Untuk mengurangi computational cost, proses pemilihan
umumnya dilakukan dengan memanfaatkan classification rate dari metode
pengklasifikasian/pemodelan untuk pemodelan dengan nilai terendah.
Untuk tipe wrapper, perlu untuk terlebih dahulu melakukan feature subset
selection sebelum menentukan subset mana yang merupakan subset
dengan ranking terbaik. Feature subset selection dapat dilakukan dengan
memanfaatkan metode-metode, seperti metode sequential forward
selection (dari satu fitur menjadi banyak fitur), sequential backward
selection (dari banyak fitur menjadi satu fitur), sequential floating
selection (dapat dari mana saja), GA, Greedy Search, Hill Climbing,
Simulated Annealing, dan lain-lain.
b. Feature Selection Tipe Filter
Feature selection dengan tipe filter hampir sama dengan selection tipe
wrapper dengan menggunakan intrinsic statistical properties dari data.
Tipe filter berbeda dari tipe wrapper dalam hal pengkajian fitur yang tidak
dilakukan bersamaan dengan pemodelan yang dilakukan. Selection ini
dilakukan dengan memanfaatkan salah satu dari beberapa jenis filter yang
ada. Sebagai contoh, Individual Merit-Base Feature Selection dengan
selection criterion: Fisher Criterion, Bhattacharyya, Mahalanobis
Distance atau Divergence, Kullback-Leibler Distance, Entropy dan lain-
lain. Metode filter ini memilih umumnya dilakukan pada tahapan
preprocessing dan mempunyai computational cost yang rendah.
c. Feature Selection Tipe Embedded

22
Feature selection jenis ini memanfaatkan suatu learning machine dalam
proses feature selection. Dalam sistem selection ini, fitur secara natural
dihilangkan, apabila learning machine menganggap fitur tersebut tidak
begitu berpengaruh. Beberapa learning machine yang bisa digunakan
antara lain Decision Trees, Random Forests dan lain-lain.
2.6 Algoritma Fuzzy C-Means
Fuzzy C-Means Clustering (FCM) merupakan model pengelompokan fuzzy
sehingga data dapat menjadi anggota dari semua kelas atau cluster terbentuk
dengan derajat atau tingkat keanggotaan yang berbeda antara 0 hingga 1. Tingkat
keberadaan data dalam suatu cluster ditentukan oleh derajat keanggotaannya.
Konsep dasar Fuzzy C-Means adalah pertama kali melakukan penentuan pusat
cluster yang akan menandai lokasi rata-rata untuk tiap-tiap kelas/cluster.
Algoritma ini termasuk dalam metode pengelompokan fuzzy sehingga data dapat
menjadi anggota dari semua kelas atau cluster terbentuk dengan derajat atau
tingkat keanggotaan yang berbeda antara 0 hingga 1 (Sukim, 2011).
Pada kondisi awal, pusat cluster ini masih belum akurat. Tiap-tiap data
memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara memperbaiki
pusat cluster dan nilai keanggotaan tiap-tiap data secara berulang, maka dapat
dilihat bahwa pusat cluster akan menuju lokasi yang tepat. Perulangan ini
didasarkan pada minimasi fungsi obyektif yang menggambarkan jarak dari titik
data yang diberikan ke pusat dari klaster yang terboboti oleh derajat keanggotaan
titik data dari himpunan fuzzy tersebut. Algoritma Fuzzy C-Means pertama kali

23
diperkenalkan oleh Dunn (1974), kemudian dikembangkan oleh Bezdek (1981),
kemudian direvisi oleh Rouben (1982), Trauwert (1985), Goth dan Geva (1989),
Gu dan Gubuisson (1990), Xie dan Beni (1991). Namun, algoritma FCM dari
Bezdek yang paling banyak digunakan.
Fuzzy C-Means adalah salah satu teknik pengelompokkan data yang mana
keberadaan tiap titik data dalam suatu kelompok (cluster) ditentukan oleh derajat
keanggotan. Berbeda dengan K-Means clustering, dimana suatu objek hanya akan
menjadi anggota satu cluster, dalam Fuzzy C-Means setiap objek dapat menjadi
anggota dari beberapa cluster. Batas-batas dalam K-Means adalah tegas (hard)
sedangkan dalam Fuzzy C-Means adalah soft. Fuzzy C-Means bersifat sederhana,
mudah diimplementasikan, memiliki kemampuan untuk melakukan
pengelompokan data yang besar, lebih kokoh terhadap data outlier. Algoritma
Fuzzy C-Means adalah sebagai berikut:
1. Pemasukan data yang akan di cluster X, berupa matriks berukuran n x m
dengan:
n = jumlah sample data
m = atribut setiap data
Xij = data sample ke-i (i = 1,2,…,n), atribut ke-j (j = 1,2,…,m)
2. Menentukan:
a. Jumlah cluster = c;
b. Pangkat = w;
c. Maksimum iterasi = MaxIter;

24
d. Error terkecil yang diharapkan = ;
e. Fungsi obyektif awal = P0 = 0;
f. Iterasi awal = t=1;
3. Membangkitkan nilai acak μik, i=1,2,…,n; k=1,2,…,c; sebagai elemen-
elemen matriks partisi awal u. μik adalah derajat keanggotaan yang
merujuk pada seberapa besar kemungkinan suatu data bisa menjadi
anggota ke dalam suatu cluster. Posisi dan nilai matriks dibangun secara
random. Dimana nilai keanggotaan terletak pada interval 0 sampai dengan
1. Pada posisi awal matriks partisi U masih belum akurat begitu juga pusat
clusternya. Sehingga kecendrungan data untuk masuk suatu cluster juga
belum akurat.
Selanjutnya menghitung jumlah setiap kolom (atribut)
………………………………..…...……. 7)
Qj adalah jumlah nilai derajat keanggotaan perkolom = 1 dengan
j=1,2,…m
Selanjutnya dilakukan perhitungan sebagai berikut:
………………………………………..…..…. 8)
4. Menghitung pusat Cluster ke-k: Vkj ,dengan k=1,2,…c; dan j=1,2,…m.
….……………………..…….. 9)
5. Menghitung fungsi obyektif pada iterasi ke-t, Pt.

25
Fungsi obyektif digunakan sebagai syarat perulangan untuk mendapatkan
pusat cluster yang tepat. Sehingga diperoleh kecendrungan data untuk
masuk ke cluster mana pada langkah akhir.
….. 10)
6. Menghitung perubahan matriks partisi:
………………...…..… 11)
dengan: i=1,2,…n;dan k=1,2,..c.
7. Mengecek kondisi berhenti:
Jika:
(|Pt – Pt-1| < ζ) ………………………………..…. 12)
atau
(t>maxIter) ……….………………………….……13)
maka berhenti;
Jika tidak: t=t+1, dilakukan pengulangan langkah ke-4.

26
Gambar 2.5 Algoritma Fuzzy C-Means
2.7 Algoritma Genetik
Algoritma genetik pertama kali diperkenalkan oleh John Holland dalam
bukunya yang berjudul "Adaption in Natural and Artificial Systems", dan oleh De
Jong dalam bukunya “Adaption of behavior of a Class of Genetic Adaptive
Systems”, yang keduanya diterbitkan pada tahun 1975 yang merupakan dasar dari
algoritma genetik. (Davis, 1991)

27
Algoritma Genetik sebagai cabang dari Algoritma Evolusi merupakan
metode adaptive yang biasa digunakan untuk memecahkan suatu pencarian nilai
dalam sebuah masalah optimasi. Algoritma ini didasarkan pada proses genetik
yang ada dalam makhluk hidup, yaitu perkembangan generasi dalam sebuah
populasi yang alami. secara lambat laun mengikuti prinsip seleksi alam dan “siapa
yang kuat, dia yang bertahan (survive)”. Dengan meniru teori evolusi ini,
Algoritma Genetik dapat digunakan untuk mencari solusi permasalahan-
permasalahan yang ada dalam dunia nyata.
Konsep dasar algoritma genetik sebenarnya dirancang untuk
mensimulasikan proses-proses dalam sistem alam yang diperlukan untuk evolusi,
khusunya teori evolusi alam yang dicetuskan oleh Charles Darwin, yaitu survival
of the fittest. Menurut teori ini, di alam terjadi persaingan antara individu-individu
untuk memperebutkan sumber daya lain yang langka sehingga makhluk yang kuat
mendominasi makhluk yang lemah. (Rouhollah, 2011)
Algoritma Genetik merupakan analogi secara langsung dan kebiasaan yang
alami yaitu seleksi alam. Algoritma ini bekerja dengan sebuah populasi yang
terdiri dari individu-individu. yang masing-masing individu mempresentasikan
sebuah solusi yang mungkin bagi persoalan yang ada. Dalam kaitan ini, individu
dilambangkan dengan sebuah nilai fitness yang akan digunakan untuk mencari
solusi terbaik dan persoalan yang ada.

28
Pertahanan yang tinggi dan individu memberikan kesempatan untuk
melakukan reproduksi melalui perkawinan silang dengan individu yang lain
dalam populasi tersebut. Individu baru yang dihasilkan dalam hal ini dinamakan
keturunan. yang membawa beberapa sifat dari induknya. Sedangkan individu
dalam populasi yang tidak terseleksi dalam reproduksi akan mati dengan
sendirinya. Dengan jalan ini beberapa generasi dengan karakteristik yang bagus
akan bermunculan dalam populasi tersebut, untuk kemudian dicampur dan ditukar
dengan karakter yang lain. Dengan mengawinkan semakin banyak individu, maka
akan semakin banyak kemungkinan terbaik yang dapat diperoleh.
Sebelum Algoritma Genetik dapat dijalankan, maka sebuah kode yang
sesuai (representatif) untuk persoalan harus dirancang. Untuk ini maka titik solusi
dalam ruang permasalahan dikodekan dalam bentuk kromosom/string yang terdiri
atas komponen genetik terkecil yaitu gen. Dengan teori evolusi dan teori genetika,
di dalam penerapan Algoritma Genetik akan melibatkan beberapa operator, yaitu:
a. Operasi Evolusi yang melibatkan proses seleksi (selection) di dalamnya.
b. Operasi Genetik yang melibatkan operator pindah silang (crossover) dan
mutasi (mutation).
Untuk memeriksa hasil optimasi. kita membutuhkan fungsi fitness, yang
menandakan gambaran hasil atau solusi yang sudah dikodekan. Selama berjalan,
induk harus digunakan untuk reproduksi, pindah silang dan mutasi untuk

29
menciptakan keturunan baru. Jika Algoritma Genetik didesain secara baik,
populasi akan mengalami konvergensi dan akan didapatkan sebuah solusi yang
optimum.
Hal-hal yang dilakukan dalam algoritma genetik: (Basuki, 2003)
a. Mendefinisikan individu, dimana individu menyatakan salah satu solusi
(penyelesaian) yang mungkin dan permasalahan yang diangkat.
b. Mendefinisikan nilai fitness. yang merupakan ukuran baik-tidaknya
sebuah individu atau baik-tidaknya solusi yang didapatkan.
c. Menentukan proses pembangkitan populasi awal. Hal ini biasanya
dilakukan dengan menggunakan pembangkitan acak seperti random-walk.
d. Menentukan proses seleksi yang akan digunakan.
Menentukan proses perkawinan silang (cross-over) dan mutasi gen yang
akan digunakan.
2.8 Konsep Individu
Individu menyatakan salah satu solusi yang mungkin. Individu bisa
dikatakan sama dengan kromosom, yang merupakan kumpulan gen. Gen ini bisa
biner, float, dan kombinatorial. Beberapa definisi penting yang perlu diperhatikan
dalam mendefinisikan individu untuk membangun penyelesaian permasalahan
dengan algoritma genetik adalah sebagai berikut: (Basuki, 2003)
a. Genotype (Gen)
Sebuah nilai yang menyatakan satuan dasar yang membentuk suatu arti
tertentu dalam satu kesatuan gen yang dinamakan kromosom. Dalam

30
algoritma genetik, gen ini bisa berupa nilai biner, float. integer maupun
karakter, atau kombinatorial.
b. Allele
Nilai dan gen.
c. Kromosom
Gabungan gen-gen yang membentuk nilai tertentu.
d. Individu
Individu menyatakan satu nilai atau keadaan yang menyatakan salah satu
solusi yang mungkin dan permasalahan yang diangkat
e. Populasi
Sekumpulan individu yang akan diproses bersama dalam satu siklus proses
evolusi.
f. Generasi
Generasi menyatakan satu siklus proses evolusi atau satu iterasi di dalam
algoritma genetik.
2.9 Siklus Algoritma Genetik
Algoritma ini ditemukan di Universitas Michigan, Amerika Serikta oleh
John Holland (1975) melalui sebuah penelitian dan dipopulerkan oleh salah satu
muridnya, David Goldberg (1989).

31
Gambar 2.6 Siklus Algoritma Genetik yang diperkenalkan oleh David Goldberg
David Goldberg memperkenalkan siklus algoritma genetik yang di
gambarkan seperti gambar 2.5 Siklus dimulai dari membuat populasi awal secara
acak, kemudian setiap individu dihitung nilai fitness nya. Proses berikutnya adalah
menyelesi individu terbaik, kemudian dilakukan cross over dan dilanjutkan oleh
proses mutasi sehingga terbentuk populasi baru. Selanjutnya populasi baru ini
mengalami siklus yang sama dengan populasi sebelumnya. Proses ini berlangsung
terus hingga generasi ke –n.
Gambar 2.7 Siklus Algoritma Genetik Zbigniew Michalewics
Reproduksi:
Reproduksi:

32
Gambar 2.7 menunjukkan siklus algoritma genetik yang diperkenalkan
oleh Zbigniew Michalewics. Siklus ini merupakan perbaikan dari siklus algoritma
genetik David Goldberg yang dilakukan oleh Zbigniew Michalewicz dengan
menambahkan satu proses elitisme dan membalik proses reproduksi terlebih
dahulu, kemudian dilanjutkan dengan proses seleksi. Adapun gambaran algoritma
genetik adalah sebagai berikut :
Gambar 2.8 Algoritma Genetik
Gambar 2.8 menggambarkan siklus algoritma genetic. Inisialisasi populasi
awal dilakukan dengan membangkitkan sejumlah kromosom (sesuai dengan
ukuran populasi) untuk dijadikan anggota populasi awal. Populasi itu sendiri
terdiri dari sejumlah kromosom yang merepresentasikan solusi yang diinginkan.
Tahap evaluasi nilai fitnes dimana setiap kromosom pada populasi dihitung nilai
fitnessnya berdasarkan fungsi fitness. Nilai fitness suatu kromosom
menggambarkan kualitas kromosom dalam populasi tersebut. Proses ini akan
mengevaluasi setiap populasi dengan menghitung nilai fitness setiap kromosom

33
dan mengevaluasinya sampai terpenuhi kriteria berhenti. Pembentukan kromosom
baru melalui proses seleksi, yaitu memilih sejumlah kromosom yang akan
menjadi kromosom calon parent, selanjutnya tahap crossover yang
mengkombinasikan dua kromosom parent (induk) berdasar nilai probabilitas
crossovernya untuk menghasilkan offspring. Tahap mutasi mengubah sejumlah
gen berdasar nilai probabilitas mutasinya untuk menghasilkan kromosom baru.
Sehingga terjadi update Generasi, yaitu membaharui kromosom yang terdapat
dalam populasi.
2.10 Teknik Encoding/Decoding Gen dan Individu
Encoding (pengkodean) berguna untuk mengkodekan nilai gen-gen
pembentuk individu. Nilai-nilai gen ini diperoleh secara acak. Ada 3 pengkodean
yang paling umum digunakan, yaitu:
1. Pengkodean bilangan real
Nilai gen berada dalam interval [0 1].
Contoh:
3 variabel (x1,x2,x3) dikodekan ke dalam individu yang terdiri dari 3 gen.
x1 x2 x3
0,2431 0,9846 0,5642
g1 g2 g3
2. Pengkodean diskrit desimal
Nilai gen berupa bilangan bulat dalam interval [0 9].

34
Contoh:
3 Variabel (x1, x2, x3) dikodekan ke dalam individu yang terdiri dari 9
gen, tiap-tiap variabel dikodekan ke dalam 3 gen.
5 2 9 5 4 8 0 2 0
g1 g2 g3 g4 g5 g6 g7 g8 g9
3. Pengkodean Biner
Nilai gen berupa bilangan biner 0 atau 1.
3 Variabel (x1, x2, x3) dikodekan ke dalam individu yang terdiri dari 9
gen, tiap-tiap variabel dikodekan ke dalam 3 gen.
1 1 0 1 0 0 0 1 0
g1 g2 g3 g4 g5 g6 g7 g8 g9
Decoding (pengkodean) berguna untuk mengkodekan gen-gen pembentuk
individu agar nilainya tidak melebihi range yang telah ditentukan dan sekaligus
menjadi nilai variabel yang akan dicari sebagai solusi permasalahan. Jika nilai
variabel x yang telah dikodekan tersebut range-nya dirubah menjadi [ra rb], yaitu
XX3
X
X XX

35
rb=batas bawah, ra = batas atas, maka cara untuk mengubah nilai-nilai variabel di
atas hingga berada dalam range yang baru [rb ra], disebut Decoding
(pengkodean).
1. Pendekodean Bilangan real :
X = rb + (ra - rb) g ……………………………………...….. 14)
2. Pendekodean Diskrit Desimal :
X = rb + (ra - rb) (g1 x 10-1 + g2 x 10-2 +.......+ gn x 10-n) ….. 15)
3. Pendekodean Biner :
X = rb + (ra - rb) (g1 x 2-1 + g2 x 2-2 +.......+ gn x 2-n) ……… 16)
Dengan catatan bahwa N adalah jumlah gen dalam individu.
2.11 Membangkitkan Populasi Awal
Sebelum membangkitkan populasi awal, terlebih dahulu kita harus
menentukan jumlah individu dalam populasi tersebut. Misalnya jumlah individu
tersebut N. Setelah itu, baru kita membangkitkan populasi awal yang mempunyai
N individu secara random. Membangkitkan populasi awal adalah proses
membangkitkan sejumlah individu secara acak atau melalui prosedur tertentu.
Ukuran untuk populasi tergantung pada masalah yang akan diselesaikan dan jenis
operator genetik yang akan diimplementasikan. Setelah ukuran populasi
ditentukan, kemudian dilakukan pembangkitan populasi awal. Syarat- syarat yang
harus dipenuhi untuk menunjukkan suatu solusi harus benar-benar diperhatikan
dalam pembangkitan setiap individunya. Teknik dalam pembangkitan populasi
awal ini ada beberapa cara, diantaranya adalah sebagai berikut:
1. Random Generator

36
Inti dan cara ini adalah melibatkan pembangkitan bilangan random
untuk nilai setiap gen sesuai dengan representasi kromosom yang
digunakan.
2. Pendekatan Tertentu (Memasukkan Nilai Tertentu ke dalam gen
Cara ini adalah dengan memasukkan nilai tertentu ke dalam gen dan
populasi awal yang dibentuk.
3. Permutasi Gen
Salah satu cara permutasi gen dalam pembangkitan populasi awal
adalah penggunaan permutasi Josephus dalam permasalahan
kombinatorial seperti TSP.
Dalam proses inisialisasi populasi ditentukan variabel-variabel apa saja
yang akan dioptimasi, lalu ditentukan bentuk kromosomnya, dan ditentukan
berapa jumlah kromosom dalam suatu populasinya. Agar algoritma genetik dapat
dijalankan berdasarkan teori evolusi, maka tiap solusi harus dipresentasikan dalam
suatu kode yang sesuai dengan persoalan. Kode yang digunakan harus dapat
mewakili seluruh ruangan persoalan. Pada algoritma genetik persoalan
diasumsikan sebagai sebuah kromosom yang terdiri dari beberapa gen. Populasi
adalah himpunan kromosom, populasi tersebut yang nantinya akan digunakan
oleh algoritma genetik untuk memulai melakukan optimasi.
Ada banyak jenis kromosom yang dapat digunakan dalam proses
Algoritma Genetik, misalnya kromosom biner (kromosom yang disusun dari gen
gen yang bernilai 0 dan 1) , kromosom float (kromosom yang disusun dari gen-

37
gen dengan nilai pecahan dan bilangan integer juga termasuk), kromosom string
(kromosom yang disusun dari gen-gen yang bernilai string atau simbol). Berikut
adalah penjelasan dari masing-masing kromosom:
1. Kromosom Biner
Bentuk ini adalah bentuk standart yang sering digunakan, tetapi jarak
antar batasannya harus sama, bentuk biner ini nantinya akan dirubah
menjadi bilangan integer lalu diubah lagi menjadi bentuk bilangan
float. Untuk menentukan panjang bilangan integer ditentukan dengan
suatu rumusan.
2. Kromosom Float
Bentuk ini bisa digunakan apabila batasanya meiliki selisih yang tidak
sama, bentuk ini lebih simpel dan lebih mudah dipahami oleh orang
awam.
2.12 Nilai Fitness
Nilai fitness adalah nilai yang menyatakan baik tidaknya suatu solusi
(individu). Nilai fitness ini yang dijadikan acuan dalam mencapai nilai optimal
dalam algoritma genetik. Algoritma genetik bertujuan mencari individu dengan
nilai fitness yang paling tinggi. (Basuki, 2003)
Nilai fitness menyatakan nilai dari fungsi tujuan. Tujuan dari algoritma
genetik adalah memaksimalkan nilai fitness. Jika yang dicari nilai maksimal,
maka nilai fitness adalah nilai dari fungsi itu sendiri. Tetapi jika yang dibutuhkan

38
adalah nilai minimal, maka nilai fitness merupakan invers dari nilai fungsi itu
sendiri. Proses invers dapat dilakukan dengan cara berikut.
Fitness = C — f(x) atau Fitness = .................... 17)
C adalah konstanta dan adalah bilangan kecil yang ditentukan untuk
menghindari agar tidak terjadi pembagian oleh nol dan x adalah individu.
2.13 Elitisme
Elitisme adalah prosedur untuk meng-copy individu yang mempunyai nilai
fitness tertinggi sebanyak satu (bila jumlah individu dalam suatu populasi adalah
ganjil) atau dua (bila jumlah individu dalam suatu populasi adalah genap). Hal ini
dilakukan agar individu ini tidak mengalami kerusakan (nilai fitness-nya
menurun) selama proses pindah silang maupun mutasi. Misalnya pada contoh
sebelumnya, maka individu ke-4 dibuat copy-nya sebanyak satu, kemudian
disimpan dalam variabel temporer_individu.
temporer_individu =111, 111;
2.14 Seleksi
Kadang kala suatu fungsi tertentu dapat menyebabkan setiap individu
mempunyai nilai fitness hampir sama. Hal ini bisa berakibat buruk pada saat
dilakukan proses seleksi untuk memilih orangtua karena dapat menyebabkan
optimum lokal. Gambar 2.8 menggambarkan bagaimana terjadinya optimum
lokal.
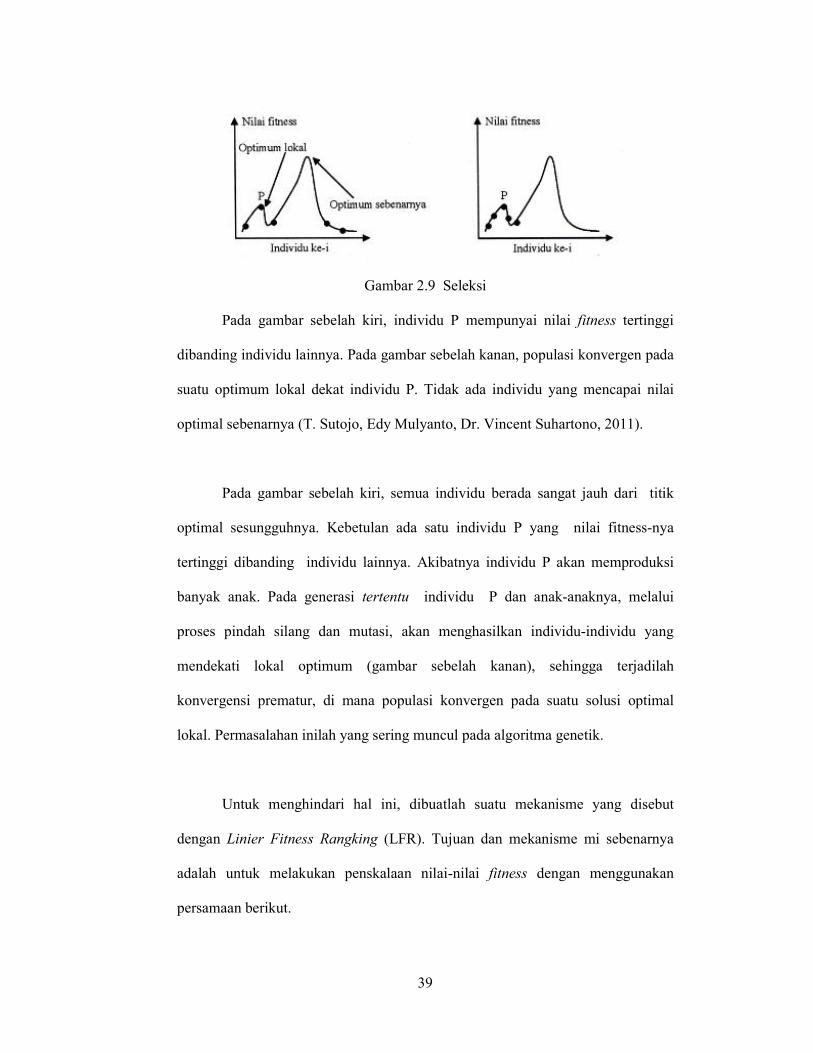
39
Gambar 2.9 Seleksi
Pada gambar sebelah kiri, individu P mempunyai nilai fitness tertinggi
dibanding individu lainnya. Pada gambar sebelah kanan, populasi konvergen pada
suatu optimum lokal dekat individu P. Tidak ada individu yang mencapai nilai
optimal sebenarnya (T. Sutojo, Edy Mulyanto, Dr. Vincent Suhartono, 2011).
Pada gambar sebelah kiri, semua individu berada sangat jauh dari titik
optimal sesungguhnya. Kebetulan ada satu individu P yang nilai fitness-nya
tertinggi dibanding individu lainnya. Akibatnya individu P akan memproduksi
banyak anak. Pada generasi tertentu individu P dan anak-anaknya, melalui
proses pindah silang dan mutasi, akan menghasilkan individu-individu yang
mendekati lokal optimum (gambar sebelah kanan), sehingga terjadilah
konvergensi prematur, di mana populasi konvergen pada suatu solusi optimal
lokal. Permasalahan inilah yang sering muncul pada algoritma genetik.
Untuk menghindari hal ini, dibuatlah suatu mekanisme yang disebut
dengan Linier Fitness Rangking (LFR). Tujuan dan mekanisme mi sebenarnya
adalah untuk melakukan penskalaan nilai-nilai fitness dengan menggunakan
persamaan berikut.

40
LFR(i) =fmax –(fmax - fmin) ................................................. 18)
Dengan catatan bahwa:
LFR(i) = nilai LFR individu ke-i
N = jumlah individu dalam populasi
R(i) = rangking individu ke-i setelah diurutkan dan nilai fitness terbesar hingga
terkecil
fmax = nilai fitness tertinggi
fmin = nilai fitness terendah
Seleksi digunakan untuk memilih individu-individu mana saja yang akan
dipilih untuk proses kawin silang dan mutasi. Seleksi digunakan untuk
mendapatkan calon induk yang baik. Induk yang baik akan menghasilkan
keturunan yang baik. Semakin tinggi nilai fitness suatu individu semakin besar
kemungkinannya untuk terpilih (Basuki, 2003).
Langkah pertama yang dilakukan dalam seleksi ini adalah pencarian nilai
fitness. Nilai fitness ini yang nantinya akan digunakan pada tahap-tahap seleksi
berikutnya. Masing-masing individu dalam wadah seleksi akan menerima
probabilitas reproduksi yang tergantung pada nilai obyektif dirinya sendiri
terhadap nilai obyektif dan semua individu dalam wadah seleksi tersebut.
Terdapat beberapa metode seleksi, seperti roullete dan turnamen.
Setelah mengetahui jenis representasi yang dibutuhkan maka
pembangkitan generasi awal (parent) dapat dilakukan. Langkah pertama yang

41
dilakukan dalam seleksi ini adalah pencarian nilai fitness. Masing-masing individu
dalam suatu wadah seleksi akan menerima probabilitas reproduksi yang
tergannuig pada nilai objektif dirinya sendiri terhadap nilai objektif dan semua
individu dalam wadah seleksi tersebut. Metode-metode seleksi yang bisa
digunakan untuk memilih individu atau kromosom sebagai orang tua. yaitu:
1. Roulette Wheel Selection
Dalam metode mi, kromosom-kromosom yang ada dalam populasi
ditempatkan ke dalam roda yang disebut “roulette wheel”. Setiap
kromosom menempati potongan roda dengan ukuran yang proposional
dengan nilai fitness cost yang dimilikinya. Putaran dilakukan sebanyak n
kali, dan pada setiap putaran, kromosom yang berada di bawah penanda
roda dipilih sebagai parent untuk generasi berikutnya. Metode mi
merupakan metode yang digunakan oleh Holland pada Algoritma Genetik
yang dikembangkan olehnya. Kelemahan utama metode ini adalah bila
terdapat satu krornosom yang merniliki fItness cost yang tinggi seka1i,
sebagai contoh 90% dari keseluruhan roda, maka kromosom-kromosom
lainnya hanya menempati 10% dari keseluruhan roda. Akibatnya. setiap
putaran roda kemungkinan besar menghasilkan kromosom yang sama
sehingga populasi baru hanya dihuni oleh kromosom yang sama. Kondisi
mi disebut sebagai konvergensi dini (“premature convergence”).
2. Elitism
Metode ini diperkenalkan oleh Kenneth De Jong. Dalam metode ini
beberapa gen terbaik dan setiap generasi diambil dan disimpan. Tujuan
metode ini adalah mencegah hilangnya gen-gen terbaik karena tidak

42
terpilih untuk tuelakukan crossover atati mutasi. Banyak penelitian yang
menernukan bahwa metode ini meningkatkan kinerja Algoritina Genetik
secara signifikan.
3. Rank Selection
Metode ini merupakan alternatif untuk mencegah terjadinya konvergensi
dini yang terlalu cepat. Dalam metode ini kromosom-kromosom dalam
populasi dirangking berdasarkan fitness cost yang dimiliki. Pemilihan
kromosorn tidak didasarkan pada nilai fitness cost, namun didasarkan pada
nilai ranking yang diberikan. Hal ini bertujuan untuk mengurangi
perbedaan nilai yang besar seperti yang dapat terjadi pada metode Roulette
Wheel Selection.
4. Tournament Selection
Dalam metode ini 2 buah kromosom dipililih secara acak dari populasi.
Sebuah angka r dipilih secara acak dari angka-angka di antara 0 dan 1.
Sebuah parameter k ditentukan (rnisalnya k = 0,75). Jika r < k, maka
kromosom dengan fitness cost yang lebih baik dipilih. dan jika sebaliknya.
kromosorn dengan fitness cost yang lebih rendah yang dipilih. Kedua
kromosom tersebut kemudian dikembalikan ke populasi dan dapat dipilih
lagi.
5. Steady-State Selection
Dalam metode ini hanya sebagian kecil kromosom dan populasi yang
diganti dalam setiap generasi. Biasanya kromosom-kromosom yang
memiliki fitness cost rendah diganti dengan kromosom-kromosom baru
hasil crossover dan mutasi dari kromosom-kromosom dengan fitness cost

43
yang tinggi. Metode ini sering digunakan dalam rule-based system dimana
proses pembelajaran memiliki peran penting dari semua anggota populasi
secara bersama-sama (tidak secara individual) memecahkan masalah yang
ada.
2.15 Crossover
Crossover (perkawinan silang) bertujuan menambah keanekaragaman string
dalam populasi dengan penyilangan antar-string yang diperoleh dari sebelumnya.
Sebuah individu yang mengarah pada solusi optimal bisa diperoleh melalui
proses pindah silang, dengan catatan bahwa pindah silang hanya bisa dilakukan
jika sebuah bilangan random r dalam interval [0 1] yang dibangkitkan nilainya
lebih kecil dari probabilitas tertentu prob, dengan kata lain: r < prob. Biasanya
nilai prob diset mendekati 1. Cara yang paling sederhana untuk melakukan
pindah silang adalah pindah silang satu titik potong. Posisi titik potong dilakukan
secara random. Berdasarkan tipe data dan nilai gen, ada beberapa cara untuk
melakukan pindah silang, yaitu:
a. Gen bertipe data biner
Pindah silang melibatkan dua buah individu sebagai orangtua dan akan
menghasilkan dua anak sebagai individu baru. Prinsip dan pindah silang ini
adalah menentukan posisi titik potong T (posisi gen) secara random, yang
dipakai sebagai acuan untuk menukar gen-gen orangtua sehingga dihasilkan
gen-gen anak. Jika bilangan random yang dibangkitkan r lebih kecil daripada
probabilitas pindah silang p ( r < p), maka proses pindah silang dikerjakan.

44
Contoh
Misalkan ditentukan p = 0,8
Pindah silang satu titik potong:
Pindah silang dua titik potong:
Pindah silang tiga titik potong:
b. Gen bertipe data Real
Untuk gen bertipe real cara pindah silangnya mengikuti persamaan berikut.

45
x1‘(T)=r * x1(T) + (r - l).x2(T)
x2’ (T) = r* x2(T)+ (r - 1).x1(T)
T adalah posisi gen yang mengalami mutasi r adalah bilangan random [0 1].
Contoh
Pindah silang satu titik :
Pindah silang dua titik potong :
c. Gen bertipe data Permutasi
Bila tipe data dan gen adalah permutasi (contohnya pada Travels Salesman
Problem) kita bisa gunakan metode Partial-Mapped CrossOver (PMX).
Metode ini diciptakan ole Goldberg dan Lingle dengan langkah-langkah
berikut.

46
a. Tentukan dua posisi (P1 dan P2) pada individu secara random. Substring
yang berada dalam dua posisi ini disebut daerah pemetaan.
b. Tukar dua substring antar dua induk untuk menghasilkan proto-child
c. Di antara daerah dua pemetaan, tentukan hubungannya.
d. Mengacu pada hubungan pemetaan tadi, tentukan individu keturunannya.
Contoh
a. Tentukan dua posisi (P1 dan P2) pada individu secara random
b. Tukar dua substring antar dua induk untuk menghasilkan photo-child
c. Di antara daerah dua pemetaan, tentukan hubungannya.

47
d. Mengacu pada hubungan pemetaan tadi, tentukan individu keturunannya.
2.16 Mutasi
Operator berikutnya pada algoritma genetik adalah mutasi gen. Operator ini
berperan untuk menggantikan gen yang hilang dan populasi akibat proses seleksi
yang meniungkinkan munculnya kembali gen yang tidak muncul pada inisialisasi
populasi. Kromosom anak dimutasi dengan menambahkan nilai random yang
sangat kecil (ukuran langkah mutasi), dengan probabilitas yang rendah. Peluang
mutasi didefinisikan sebagai persentasi dan jumlah total gen pada populasi yang
mengalami mutasi. Peluang mutasi mengendalikan banyaknya gen baru yang akan
dimunculkan untuk dievaluasi. Jika peluang mutasi terlalu kecil, banyak gen yang
mungkin berguna tidak pernah dievaluasi. Tetapi bila peluang mutasi ini terlalu
besar, maka akan terlalu banyak gangguan acak, sehingga anak akan kehilangan
kemiripan dari induknya, dan juga algoritma kehilangan kemampuan untuk
belajar dari histori pencarian.
Mutasi merupakan proses mengubah nilai dari satu atau beberapa gen dalam
suatu kromosom. Operasi crossover yang dilakukan pada kromosom dengan
tujuan untuk memperoleh kromosom-kromosom baru sebagai kandidat solusi
pada generasi mendatang denga fitness yang lebih baik, dan lama-kelamaan
menuju solusi optimum yang diinginkan. Akan tetapi, untuk mencapai hal ini,

48
penekanan selektif juga memegang peranan yang penting. Jika dalam proses
pemilihan kromosom-kromosom cenderung pada kromosom yang memiliki
fitness yang tinggi saja, konvergensi premature, yaitu mencapai solusi yang
optimal lokal sangat mudah terjadi. Untuk menghindari konvergensi premature
tersebut dan tetap menjaga perbedaan (diversity) kromosom-kromosom dalam
populasi, selain melakukan penekanan selektif yang lebih efisien, operator mutasi
juga dapat digunakan. Proses mutasi dalam sistem biologi berlangsung dengan
mengubah isi allele gen pada suatu locus dengan allele yang lain. Proses mutasi
ini bersifat acak sehingga tidak selalu menjamin bahwa setelah proses mutasi akan
diperoleh kromosom dengan fitness yang lebih baik.
Mutasi dilakukan untuk semua gen yang terdapat pada individu, jika
bilangan random yang dibangkitkan lebih kecil dan probabilitas mutasi p yang
ditentukan. Biasanya p diset = 1/N, di mana N adalah jumlah gen dalam individu.
Untuk kode biner, mutasi dilakukan dengan cara membalik nilai bit 0 menjadi bit
1, sebaliknya bit 1 diubah menjadi bit 0. Operator mutasi merupakan operasi yang
menyangkut satu kromosom tertentu. Beberapa cara operasi mutasi diterapkan
dalam algoritma genetik antara lain:
Gen bertipe data biner

49
Gen betipe data real
2.17 Evaluasi Fitness dengan Objective Function
Objective function digunakan untuk mencari lokasi nilai terbaik pada tiap
cluster terhadap masing-masing fitur. Adapun persamaan objective function
sebagai berikut:
,
dimana m adalah bilangan real yang lebih besar dari 1, uij adalah derajat
keanggotaan dari xi di klaster j, xi adalah dimensi data yang diukur, cj adalah pusat
dimensi cluster, dan ||*|| adalah setiap aturan yang mengungkapkan kesamaan
antara pusat dan data diukur. Partisi Fuzzy dilakukan melalui optimasi berulang
dari objective function yang ditunjukkan di atas, dengan update keanggotaan uij
dan pusat cluster cj oleh:
,
Iterasi ini akan berhenti ketika , di mana kriteria
terminasi antara 0 dan 1, sedangkan k adalah langkah-langkah iterasi. Prosedur ini
konvergen ke minimum lokal atau titik Jm.
Algoritma in iterdiri dari langkah-langkah berikut:

50
1. Inisialisasi U=[uij] matriks, U(0)
2. Pada k-langkah: menghitung pusat vektor C(k) =[cj] denganU(k)
3. Update U(k), U(k +1)
4. Jika ||U(k +1) -U(k) || < kemudian berhenti; jika tidak kembali ke
langkah 2.
2.18 Metode Kuesioner
Kuesioner merupakan daftar pertanyaan yang akan digunakan oleh periset
untuk memperoleh data dari sumbernya secara langsung melalui proses
komunikasi atau dengan mengajukan pertanyaan (Hendri, 2009). Metode
kuesioner terbagi menjadi 4 (empat), yaitu:
a. Kuesioner terstruktur yang terbuka
Tingkat struktur dalam kuesioner adalah tingkat standarisasi yang
diterapkan pada suatu kuesioner. Pada kuesioner terstruktur yang terbuka
dimana pertanyaan-pertanyaan diajukan dengan susunan kata-kata dan
urutan yang sama kepada semua responden ketika mengumpulkan data.

51
b. Kuesioner tak terstruktur yang terbuka
Kuesioner tak terstruktur yang terbuka dimana tujuan studi adalah jelas
tetapi respon atau jawaban atas pertanyaan yang diajukan bersifat terbuka
dimana subjek berbicara dengan bebas mengenai pertanyaan yang
diajukan.
c. Kuesioner tidak terstruktur yang tersamar
Kuesioner tidak terstruktur yang tersamar berlandaskan pada riset
motivasi. Para periset telah mencoba untuk mengatasi keengganan
responden untuk membahas perasaan mereka dengan cara
mengembangkan teknik-teknik yang terlepas dari masalah kepedulian dan
keinginan untuk membuka diri.
d. Kuesioner terstruktur yang tersamar
Kuesioner ini dikembangkan sebagai cara untuk menggabungkan
keunggulan dari penyamaran dalam mengungkapkan motif dan sikap
dibawah sadar dengan keunggulan struktur pengkodean serta tabulasi
jawaban (Hendri, 2009).




















