
BAB 2 LANDASAN TEORI Data Mining - thesis.binus.ac.idthesis.binus.ac.id/Doc/Bab2/2012-2-00627-SI...
21
7 BAB 2 LANDASAN TEORI 2.1. Data Mining 2.1.1. Pengertian Data Mining Menurut Han, Jiawei (2011, p36), data mining adalah proses menemukan pola yang menarik, dan pengetahuan dari data yang berjumlah besar. Sedangkan menurut Dunston dan Yager (2008, p188), data mining adalah proses pencarian melalui data dengan jumlah yang besar, dalam sebuah usaha untuk menemukan pola, tren, dan hubungan. Menurut Keating dan Berry (2008), data mining adalah sebuah cara untuk mendapatkan kecerdasan pasar dari data dengan jumlah yang besar. Sedangkan menurut Liu, Sandra S. dan Chen, Jie (2009), data mining adalah proses pencarian pola tersembunyi dari berbagai database. Berdasarkan beberapa pengertian di atas, dapat disimpulkan bahwa data mining adalah suatu proses analisis untuk menggali informasi yang tersembunyi dengan menggunakan statistik dan artificial intelligence di dalam suatu database dengan ukuran sangat besar, sehingga ditemukan suatu pola dari data yang sebelumnya tidak diketahui, dan pola tersebut direpresentasikan dengan grafik komputer agar mudah dimengerti. 2.1.2. Tahap Penemuan Knowledge pada Data Mining (KDD) Data mining adalah sebuah langkah dalam proses mencari pola-pola yang terdapat dalam setiap informasi. Langkah-langkah tersebut akan dijelaskan pada gambar 2.1 (Han, 2011, p6).
Transcript of BAB 2 LANDASAN TEORI Data Mining - thesis.binus.ac.idthesis.binus.ac.id/Doc/Bab2/2012-2-00627-SI...

7
BAB 2
LANDASAN TEORI
2.1. Data Mining
2.1.1. Pengertian Data Mining
Menurut Han, Jiawei (2011, p36), data mining adalah proses menemukan
pola yang menarik, dan pengetahuan dari data yang berjumlah besar. Sedangkan
menurut Dunston dan Yager (2008, p188), data mining adalah proses pencarian
melalui data dengan jumlah yang besar, dalam sebuah usaha untuk menemukan pola,
tren, dan hubungan.
Menurut Keating dan Berry (2008), data mining adalah sebuah cara untuk
mendapatkan kecerdasan pasar dari data dengan jumlah yang besar. Sedangkan
menurut Liu, Sandra S. dan Chen, Jie (2009), data mining adalah proses pencarian
pola tersembunyi dari berbagai database.
Berdasarkan beberapa pengertian di atas, dapat disimpulkan bahwa data
mining adalah suatu proses analisis untuk menggali informasi yang tersembunyi
dengan menggunakan statistik dan artificial intelligence di dalam suatu database
dengan ukuran sangat besar, sehingga ditemukan suatu pola dari data yang
sebelumnya tidak diketahui, dan pola tersebut direpresentasikan dengan grafik
komputer agar mudah dimengerti.
2.1.2. Tahap Penemuan Knowledge pada Data Mining (KDD)
Data mining adalah sebuah langkah dalam proses mencari pola-pola yang
terdapat dalam setiap informasi. Langkah-langkah tersebut akan dijelaskan pada
gambar 2.1 (Han, 2011, p6).
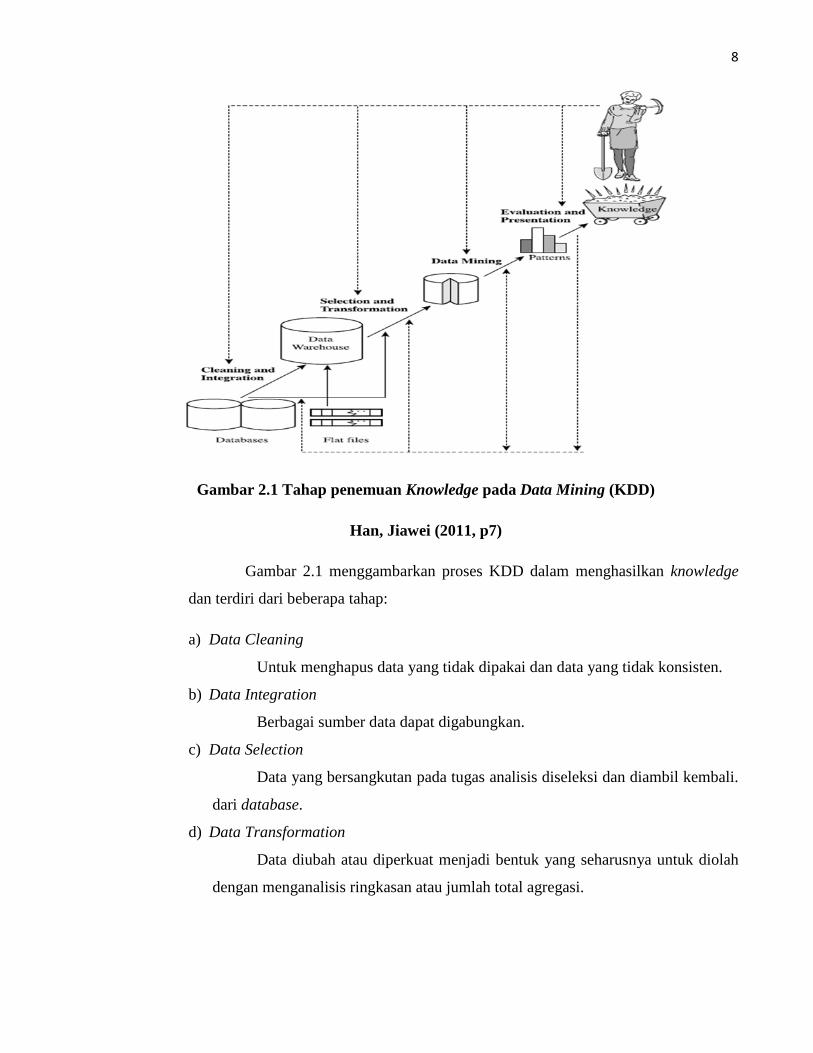
8
Gambar 2.1 Tahap penemuan Knowledge pada Data Mining (KDD)
Han, Jiawei (2011, p7)
Gambar 2.1 menggambarkan proses KDD dalam menghasilkan knowledge
dan terdiri dari beberapa tahap:
a) Data Cleaning
Untuk menghapus data yang tidak dipakai dan data yang tidak konsisten.
b) Data Integration
Berbagai sumber data dapat digabungkan.
c) Data Selection
Data yang bersangkutan pada tugas analisis diseleksi dan diambil kembali.
dari database.
d) Data Transformation
Data diubah atau diperkuat menjadi bentuk yang seharusnya untuk diolah
dengan menganalisis ringkasan atau jumlah total agregasi.

9
e) Data Mining
Sebuah proses penting di mana metode intelijen diterapkan dengan tujuan
untuk megolah pola-pola data.
f) Pattern Evaluation
Untuk mengidentifikasi pola-pola menarik yang menjelaskan mengenai
ukuran dasar pengetahuan yang ada.
g) Knowledge Presentation
Visualisasi dan teknik representasi knowledge digunakan untuk
menyajikan knowledge yang telah diolah untuk pengguna.
2.1.3. Metode-Metode Data Mining
2.1.3.1. Mining Frequent Patterns, Association, Correlations
Frequent pattern adalah pola yang sering muncul dalam kumpulan
data. Misalnya, satu set item seperti susu dan roti yang sering muncul
bersama-sama dalam satu set data transaksi adalah frequent itemset. Sebuah
subsequence, seperti membeli pertama kali sebuah PC, lalu kamera digital,
dan kemudian memory card. Jika sequence tersebut sering terjadi dalam
history pada database belanja, maka pola tersebut adalah frequent pattern.
Menemukan frequent pattern adalah peranan penting dalam mining
association, correlation, dan hubungan menarik lainnya antara data. Selain
itu, membantu dalam classification data, clustering, dan lainnya. Frequent
itemset mining kemungkinan untuk menemukan asosiasi dan korelasi dari
banyak item dari banyaknya transaksi. Dengan banyaknya data yang
terkumpul, banyak industri yang mulai tertarik pada pola mining tersebut
dari database mereka.
Penemuan hubungan korelasi yang menarik antara jumlah besar,
catatan transaksi bisnis, dapat membantu bisnis seperti dalam proses
pengambilan keputusan untuk desain katalog, lintas pemasaran, dan analisis
tingkah laku pelanggan. Assosciation rule mining yang biasanya disebut juga
market basket analysis adalah teknik mining untuk menemukan aturan
asosisatif antara suatu kombinasi item. Contoh aturan asosisatif dari analisa
pembelian di suatu pasar swalayan adalah bisa diketahui berapa besar

10
kemungkinan seorang pelanggan membelli roti bersamaan dengan susu.
Dengan pengetahuan tersebut, pemilik pasar swalayan dapat mengatur
penempatan barangnya atau merancang kampanye pemasaran dengan
memakai kupon diskon untuk kombinasi barang tertentu. Penting tidaknya
suatu aturan asosiatif dapat diketahui dengan dua parameter, support yaitu
presentase kombinasi item tersebut dalam database dan confidence yaitu
kuatnya hubungan antar item dalam aturan asosisatif.
2.1.3.2. Classification
Menurut Han, Jiawei (p327), classification adalah satu bentuk
analisis data yang menghasilkan model untuk mendeskripsikan kelas data
yang penting. Classification memprediksi kategori (discrete, unordered) ke
dalam label class. Classification merupakan proses untuk menemukan model
atau fungsi yang menjelaskan atau membedakan konsep atau class data,
dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang
labelnya tidak diketahui. Model itu sendiri bisa berupa if-then-rules, decision
tree, formula matematis atau neural network. Sebagai contoh, kita dapat
membangun model klasifikasi untuk mengkategorikan aplikasi pinjaman
bank, aman atau berisik. Analisa tersebut dapat membantu memberikan
pemahaman yang lebih baik dari data pada umumnya. Classification memiliki
berbagai aplikasi yaitu, deteksi penipuan, pemasaran target, prediksi kinerja,
manufaktur, dan diagnosa medis.
2.1.3.2.1. Decision Tree
Decision tree adalah salah satu metode classification
yang paling populer karena mudah untuk diinterpretasi oleh
manusia. Decision tree menggunakan model seperti struktur
pohon.
Menurut Austin, Peter C.; Tu, Jack V.; Ho, Jennifer E.;
Levy, Daniel; Lee, Douglas S dalam data mining dan machine
learning fields, peningkatan untuk classical classfication trees
yang telah dikembangkan. Banyak metode yang melibatkan

11
aggreagting classification melalui sebuah rangkaian
classification trees.
Pembangunan decision tree tidak memerlukan
pengaturan domain knowledge atau parameter, karena itu cocok
untuk eksplorasi penemuan pengetahuan. Decision tree dapat
menangani data multidimensi. Perwakilan dari pengetahuan yang
diperoleh dalam bentuk pohon memudahkan untuk dipelajari dan
dipahami. Decision tree memiliki akurasi yang baik. Namun,
keberhasilan penggunaannya tergantung pada data yang ada.
Aplikasi klasifikasi decision tree telah digunakan dalam banyak
area, seperti kedokteran, manufaktur dan produksi, analisis
keuangan, astronomi, dan biologi molekuler. Untuk menetukan
proses pembangunan decision tree, diperlukan adanya atribute
selection measure, yaitu suatu metode untuk memilih kriteria
pemisahan yang terbaik yang memisahkan partisi data yang
diberikan, kelas-label ke dalam class individu.
Atribute selection measure memberikan peringkat untuk
setiap atribut. Jika atribut yang terpisah adalah continues-valued
atau jika kita dibatasi ke dalam binary trees, maka subset yang
membelah juga harus ditentukan sebagai bagian dari kriteria
pemisahan. Node pohon diciptakan untuk partisi yang dilabeli
dengan kriteria pembagian, cabang yang tumbuh untuk setiap hasil
dari kinerja. Tiga selection measures attribute yang populer
adalah information gain, gain ratio, dan gain index.
2.1.3.2.2. Naive Bayes
Naive bayes didasarkan pada teorema bayes probabilitas
posterior. Ini mengasumsikan bahwa kelas-kemerdekaan-
kondisional efek dari nilai atribut pada kelas tertentu tidak
tergantung pada nilai dari atribut lainnya. Naive bayesian classifier,
atau classifier bayesian sederhana, bekerja sebagai berikut:

12
a) Misalkan D pelatihan set tuple dan label class yang
terkait. Seperti biasa, setiap tuple diwakili oleh atribut
vektor, X = (x₁ , x₂ , ...., xn) menggambarkan n pengukuran
yang dilakukan pada tuple dari n atribut, masing-masing, A₁
, A₂ , ... , An
P(Ci � X) > P(Cj �X) for 1 ≤ j ≤ m, j ≠ i,
P(Ci|X) =
b) Misalkan ada kelas m, C₁ , C₂ , ... , Cm. Mengingat tuple, X,
classifier akan memprediksi bahwa X milik class memiliki
probabilitas posterior tertinggi, dikondisikan pada X.
Artinya, naive bayesian classifier memprediksi bahwa tuple
X milik class Cᵢ jika dan hanya jika
c) P(X) adalah konstan untuk semua kelas, hanya
P = P(X|C�)P(C�) perlu dimaksimalkan. Jika probabilitas
sebelum class tidak diketahui, maka umumnya diasumsikan
bahwa class yang sama mungkin, yaitu, P (C1) = P (C2)
=…= P (Cm), dan dengan demikian kami akan
memaksimalkan P (X|C�). Jika tidak, kita memaksimalkan
P(X|C�)P(C�). Perhatikan bahwa probabilitas sebelum
class dapat dihitung dengan P(C�) = |C���|/|D|, dimana
|C���| adalah jumlah tuple pelatihan class Cᵢ di D.
d) Mengingat data set dengan banyak atribut, akan sangat
komputasi mahal untuk menghitung P(X|C�). Untuk
mengurangi perhitungan dalam mengevaluasi P(X|C�)
naive asumsi independensi kelas kondisional yang dibuat.
Hal ini mengandaikan bahwa nilai-nilai atribut yang
kondisional independen satu sama lain, mengingat label
class tuple (yaitu, bahwa tidak ada hubungan
ketergantungan antara atribut). Dengan demikian, (Rumus)

13
= P(x₁|Ci ) x P (x₂|Ci) x P(x₂|Ci) x ... x P(Xn|Ci)
Kita dapat dengan mudah memperkirakan probabilitas
P(x₁|C₁),P(x₂|C�),...,P(Xn|C₁) dari tuple pelatihan. Ingat
bahwa di sini xk mengacu pada nilai atribut Ak untuk tuple
X. Untuk setiap atribut, kita melihat apakah atribut kategori
atau kontinu-dihargai. Misalnya, untuk menghitung
P(X|C�), kita pertimbangkan hal-hal berikut:
a) Untuk memprediksi class label dari X,P(X│C�)P(C�)
dievaluasi untuk setiap class Cᵢ .Classifier
(penggolong) memprediksikan bahwa class label dari
tuple X adalah class Cᵢ dan hanya berlaku jika
P(X│C�)P(C�) > P(X│Cj)P(Cj) for 1 < j < m,j ≠i.
Dengan kata lain, class label yang diprediksikan adalah
class Cᵢ yang nilai maksimumnya adalah
P(X│C�)P(C�).
b) Berbagai penelitian empiris dari classifier (penggolong)
ini dibandingkan kepada decision tree dan neural
network classifiers telah menemukan bahwa itu dapat
dibandingkan dalam beberapa domain. Dalam teori,
bayesian classifiers memiliki tingkat kesalahan
minimum dalam perbandingan pada classifiers lainnya.
Bagaimanapun juga, pada kenyataannya hal ini tidak
selalu menjadi kasus, karena ketidakakuratan dalam
asumsi yang dibuat untuk fungsinya, seperti class-
conditional independence, dan kurangnya kemungkinan
data (probability data) yang tersedia

14
c) Bayesian classifiers juga berguna karena mereka
menyediakan pembenaran teoritis untuk classifiers lain
yang tidak menggunakan teori Bayes secara eksplisit.
Sebagai contoh, berdasarkan asumsi tertentu, dapat
dilihat bahwa banyak neural network dan curve-fitting
algoritma menghasilkan posteriori hipotesis maksimal,
seperti halnya naive bayesian classifier.
2.1.3.3. Clustering
Clustering adalah proses pengelompokan kumpulan data menjadi
beberapa kelompok sehingga objek di dalam satu kelompok memiliki
banyak kesamaan dan memiliki banyak perbedaan dengan objek di
kelompok lain. Perbedaan dan persamaannya biasanya berdaasarkan nilai
atribut dari objek tersebut dan dapat juga berupa perhitungan jarak.
Clustering sendiri juga disebut unsupervised classification, karena clustering
lebih bersifat untuk dipelajarai dengan diperhatikan. Cluster analysis
merupakan proses partisi satu set objek data ke dalam himpunan bagian.
Setiap himpunan bagian adalah cluster, sehingga objek yang ada di dalam
cluster mirip satu sama dengan lainnya, dan mempunyai perbedaan dengan
objek dari cluster yang lain. Partisi tidak dilakukan dengan manual algoritma
clustering. Oleh karena itu, clustering sangat berguna dan bisa menemukan
grup yang tidak dikenal dalam data.
Cluster analysis banyak digunakan dalam berbagai aplikasi seperti
Business Intelligence, Image Pattern Recognition, Web Search, Biology, dan
Security. Di dalam business intelligence, clustering bisa mengatur banyak
customer ke dalam banyak grup. Contohnya pengelompokan customer ke
dalam beberapa cluster dengan persamaan karakteristik yang kuat.
Clustering juga dikenal sebagai data segmentation, karena clustering
mempartisi banyak data set ke dalam banyak grup berdasarkan
persamaannya. Clustering juga bisa sebagai outlier detection, di mana
outlier bisa menjadi menarik daripada kasus yang biasa. Aplikasinya adalah
Outlier Detection, untuk mendeteksi card fraud dan memonitori aktivitas

15
kriminal dalam e-commerce. Contohnya adalah pengecualian dalam
transaksi kartu kredit.
2.1.3.3.1. Konsep Dasar Clustering
Proses clustering akan menghasilkan cluster yang baik
apabila:
a) Tingkat kesamaan yang tinggi dalam satu kelas.
b) Tingkat kesamaan yang rendah antar kelas.
Kesamaan yang dimaksud merupakan pengukuran secara
numerik terhadap dua buah objek. Nilai kesamaan ini akan
semakin tinggi apabila memiliki kemiripan yang tinggi. Perbedaan
kualitas hasil clustering tergantung pada metode yang dipakai.
Tipe data pada clustering:
a) Variabel berskala interval.
b) Variabel biner.
c) Variabel nominal, ordinal, dan rasio.
d) Variabel dengan tipe lainnya.
Meotde clustering juga harus dapat mengukur
kemampuannya dalam usaha untuk menemukan suatu pola
tersembunyi pada data yang tersedia. Dalam mengukur nilai
kesamaan ini, ada beberapa metode yang dapat dipakai. Salah satu
metodenya adalah Weighted Euclidean Distance. Dalam meotde
ini, dua buah poin dapat dihitung jaraknya bila diketahui nilai dari
masing-masing atribut pada kedua poin tersebut, berikut
rumusnya:
Keterangan :
N = Jumlah record data

16
K = Urutan field data
r = 2
k = Bobot field yang diberikan user
2.1.3.3.2. Persyaratan untuk Clustering
Syarat untuk melakukan analisa clustering:
a) Scalability
Mampu menangani data dalam jumlah yang besar.
Karena database yang besar berisi lebih dari jutaan objek,
bukan hanya ratusan objek. Maka dari itu diperlukan algoritma
dengan clustering yang scalable.
b) Ability to deal with different types of attributes
Banyak algoritma clustering yang hanya dibuat untuk
menganalisa data bersifat numerik. Namun sekarang ini,
aplikasi data mining harus dapat menangani berbagai macam
bentuk data seperti biner, data nominal, data ordinal, ataupun
campuran.
c) Discovery of clusters with arbitrary shape
Banyak algoritma clustering yang menggunakan
euclidean atau manhattan. Namun, hasil dari metode tersebut
bukan hanya berbentuk bulat seperti pada contoh. Hasil dapat
berbentuk aneh dan tidak sama antara satu dengan yang lain.
Maka dari itu diperlukan kemampuan untuk menganalisa
cluster dengan bentuk apapun.
d) Requirements for domain knowledge to determain input
parameters
Banyak algoritma clustering yang mengharuskan
pengguna untuk memasukan parameter tertentu, seperti jumlah
cluster. Hasil clustering bergantung pada parameter yang
ditentukan. Terkadang parameter sulit untuk menentukan,
terutama pada data yang memiliki dimensi tinggi. Hal ini

17
menyulitkan pengguna serta kualitas clustering yang yang
dicapaipun tidak terkontrol.
e) Ablity to deal with noisy data
Pada kenyataannya, data pasti ada yang rusak, error,
tidak dimengerti, ataupun menghilang. Beberapa algoritma
clustering sangat sensitif terhadap data yang rusak, sehingga
menyebabkan cluster dengan kualitas yang rendah. Maka dari
itu, diperlukan clustering yang mampu menagani data yang
rusak.
f) Incremental clustering and insensitivity to input order
Data yang dimasukan dapat menyebabkan cluster
menjadi berubah total. Hal ini dapat terjadi karena tidak
sensitifnya algoritma clustering yang dipakai. Maka dari itu
diperlukan algoritma yang tidak senssitif terhadap urutan input
data.
g) Capability of clustering high-dimentionallity data
Sebuah kelompok data dapat berisi banyak dimensi
ataupun atribut. Kebanyakan algoritma clustering hanya
mampu menangani kelompok data dengan dimensi sedikit.
Maka dari itu, diperlukan algoritma clustering yang mampu
menangani data dengan dimensi yang berjumlah banyak.
h) Constraint based clustering
Pada kenyataannya, membuat clustering tentu saja
memiliki beberapa pembatas ataupun syarat tertentu. Hal ini
menajadi tugas yang menantang, karena diperlukan
kemampuan yang tinggi untuk mengelompokan data, dengan
kendala dan perilaku tertentu.
i) Interpretability and usability
Pengguna tentu saja menginginkan hasil clustering
mudah ditafsirkan, dimengerti, dan bermanfaat. Hal ini berarti
clustering perlu ditandai dengan beberapa syarat, sesuai

18
kemauan user, dan tentu saja hal itu memengaruhi pemilihan
metode clustering yang akan digunakan.
2.1.3.3.3. Tipe Clustering
Berikut ini merupakan tipe clustering yang umum
digunakan, antara lain:
a) Partitional Clustering
Metode yang paling sederhana dan paling mendasar
dari analisis partisi cluster, yang mengatur objek dari suatu
himpunan ke dalam beberapa kelompok eksklusif atau cluster.
Intinya adalah memisahkan data per kelompok dengan
kelompok lainnya.
Metode yang paling sering digunakan dalam
partitional clustering adalah metode K-Means. Algoritma K-
Means mendefinisikan centroid dari cluster menjadi rata-rata
point dari cluster tersebut. Ini hasil dari langkah-langkah dalam
melakukan metode K-Means. Langkah-langkah melakukan
metode K-Means:
a) Tentukan jumlah cluster yang akan dibuat.
b) Masukan elemen yang akan di-cluster secara acak ke
masing-masing cluster.
c) Hitung centroid (titik tengah) pada setiap cluster.
d) Ukur jarak antara satu titik ke titik tengah pada masing-
masing cluster.
e) Masukan titik ke centroid terdekat.
f) Ulangi sampai cluster benar-benar tersusun dengan baik.
b) Hierarchical Clustering
Pengelompokan data berdasarkan hierarkinya.
Langkah-langkah melakukan hierarchical clustering:
a) Identifikasi item dengan jarak terdekat.
b) Gabungkan item itu ke dalam satu cluster.
c) Hitung jarak antar cluster.

19
d) Ulangi dari awal, sampai semua terhubung.
c) Density-Based
Metode partitioning dan hierarchical adalah dirancang
untuk menemukan spherical-shaped cluster. Metode tersebut
memiliki kesulitan untuk menemukan cluster berbentuk
sembarang seperti bentuk “S” dan cluster ouval. Untuk hal
tersebut dengan menggunakan metode di atas, kemungkinan
besar tidak akurat, di mana kebisingan atau outlier termasuk
dalam cluster. Untuk menemukan cluster berbentuk
sembarang, sebagai alternatif, kita dapat memodelkan cluster
ke dalam beberapa bagian dalam data space, yang dipisahkan
dari bagian yang jarang. Ini adalah strategi utama di balik
kepadatan metode berbasis clustering, yang dapat menemukan
cluster berebentuk nonspherical.
d) Grid-Based
Metode clustering yang dibahas sejauh ini adalah
metode yang mempartisi set dari objek dengan distribusi objek
di embedding space. Pendekatan clustering Grid-Based
menggunakan grid multiresolusi struktur data. Ini membagi
objek space ke dalam jumlah yang terbatas dari struktur grid, di
mana operasi untuk clustering dilakukan. Keuntungan dari
pendekatan ini adalah waktu proses yang cepat, yang biasanya
tergantung dari jumlah objek data, namun tergantung pada
jumlah sel dalam setiap dimensi, dalam quantized space.
2.1.3.3.4. Penggunaan Metode Clustering
Clustering banyak digunakan pada berbagai bidang
aplikasi seperti:
a) Business Intelligence
b) Image pattern recognition
c) Web search

20
d) Biology
e) Security
f) Economy
Contoh aplikasi data mining yang menggunakan teknik
clustering:
a) Business Intelligence
Clustering dapat digunakan untuk mengorganisir
pelanggan dalam jumlah besar ke dalam kelompok yang
memiliki banyak persamaan. Hal ini membantu dalam
proses CRM.
b) Web search
Clustering digunakan pada saat pencarian
menggunakan keyword. Karena sangat banyaknya
jumalah website yang ada, clustering dapat digunakan
untuk mengorganisir hasil pencarian ke dalam beberapa
kelompok, yang menyajikan hasil yang lebih mudah
ditelusuri.
c) Marketing
Untuk mengelompokan customer yang memiliki
keunikan dan mengembangkan program target
marketing terhadap beberapa customer tersebut.

21
2.1.4. Holdout Method
Gambar 2.2 Holdout Method
Han, Jiawei (2011, p370)
Menurut Han, Jiawei (2011, p370), holdout method adalah data yang
diberikan secara acak dibagi menjadi dua set independen, yaitu training set dan test
set. Biasanya, dua pertiga dari data yang dialokasikan untuk training set, dan sisanya,
sepertiga dialokasikan untuk test set. Training set digunakan untuk menurunkan
model. Akurasi model tersebut kemudian diperkirakan dengan test set. Perkiraan
pesimis karena hanya sebagian dari data awal yang digunakan untuk menurunkan
model.
2.2. Pasar Modal
2.2.1. Saham
2.2.1.1. Pengertian Saham
Saham adalah sertifikat yang menunjukkan bukti kepemilikan suatu
perusahaan, dan pemegang saham memiliki hak klaim atas penghasilan dan
aktiva perusahaan.
2.2.1.2. Jenis Saham
a) Saham Biasa
Merupakan jenis efek yang paling sering dipergunakan oleh
emiten untuk memperoleh dana dari masyarakat dan juga merupakan

22
jenis yang paling populer di Pasar Modal. Jenis ini memiliki
karakteristik seperti:
a) Hak klaim terakhir atas aktiva perusahaan jika perusahaan
dilikuidasi.
b) Hak suara proporsional pada pemilihan direksi serta keputusan lain
yang ditetapkan pada Rapat Umum Pemegang Saham.
c) Dividen, jika perusahaan memperoleh laba dan disetujui di dalam
Rapat Umum Pemegang Saham.
d) Hak memesan efek terlebih dahulu, sebelum efek tersebut
ditawarkan kepada masyarakat.
b) Saham Preferen
Memiliki karakteristik sebagai berikut:
a) Pembayaran dividen dalam jumlah yang tetap.
b) Hak klaim lebih dahulu dibanding saham biasa, jika perusahaan
dilikuidasi.
c) Dapat dikonversikan menjadi saham biasa.
2.2.1.3. Manfaat Investasi Saham
a) Dividen
Dividen adalah bagian keuntungan perusahaan yang dibagikan
kepada pemegang saham. Jumlah dividen yang akan dibagikan
diusulkan oleh Dewan Direksi dan disetujui di dalam Rapat Umum
Pemegang Saham. Dividen terbagi menjadi dua, yaitu:
b) Dividen Tunai
Jika emiten membagikan dividen kepada para pemegang saham
dalam bentuk sejumlah uang untuk setiap saham yang dimiliki.
c) Dividen Saham
Jika emiten membagikan dividen kepada para pemegang saham
dalam bentuk saham baru perusahaan tersebut, yang pada akhirnya
akan meningkatkan jumlah saham yang dimiliki pemegang saham.

23
d) Capital Gain
Investor dapat menikmati capital gain, jika harga jual melebihi
harga beli saham tersebut.
2.2.1.4. Risiko Investasi Saham
Berikut ini adalah risiko investasi pada saham:
a) Tidak ada pembagian dividen
Jika emiten tidak dapat membukukan laba pada tahun berjalan
atau Rapat Umum Pemegang Saham memutuskan untuk tidak
membagikan dividen kepada pemegang saham karena laba yang
diperoleh akan digunakan untuk ekspansi perusahaan.
b) Capital Loss
Investor akan mengalami capital loss, jika harga beli saham
besar dari harga jual.
c) Risiko Likuidasi
Jika emiten bangkrut atau dilikuidasi, para pemegang saham
memiliki hak klaim terakhir terhadap aktiva perusahaan, setelah
seluruh kewajiban emiten dibayar.
d) Saham delisting dari Bursa
Karena beberpa alasan tertentu, saham dapat dihapus
pencatatannya (delisting) di Bursa, sehingga pada akhirnya saham
tersebut tidak dapat diperdagangkan.
2.2.2. Obligasi
2.2.2.1. Pengertian Obligasi
Obligasi adalah sertifikat yang berisi kontrak antara investor dan
perusahaan, yang menyatakan bahwa investor/pemegang obligasi telah
meminjam sejumlah uang kepada perusahaan. Perusahaan yang menerbitkan
obligasi mempunyai kewajiban untuk membayar bunga secara regular sesuai
dengan jangka waktu yang telah ditetapkan, serta pokok pinjaman pada saat
jatuh tempo.

24
2.2.2.2. Manfaat Investasi Obligasi
Berikut ini manfaat dari obligasi:
a) Bunga
Bunga dibayar secara regular sampai jatuh tempo dan
ditetapkan dalam presentase dari nilai nominal.
b) Capital Gain
Sebelum jatuh tempo, biasanya obligasi diperdagangkan di
Pasar Sekunder, sehingga investor mempunyai kesempatan
untuk memperoleh capital gain. Capital gain juga dapat
diperoleh jika investor membeli Obligasi dengan diskon, yaitu
dengan nilai lebih rendah dari nilai nominalnya.
c) Hak Klaim Pertama
Jika emiten bangkrut atau dilikuidasi, pemegang obligasi
sebagai kreditur memiliki Hak Klaim Pertama atas aktiva
perusahaan.
d) Jika memiliki obligasi konversi
Investor dapat mengkonversikan obligasi menjadi saham
pada harga yang telah ditetapkan, dan kemudian berhak untuk
memperoleh manfaat atas saham.
2.2.2.3. Risiko Investasi Obligasi
Berikut ini merupakan risiko investasi pada obligasi:
a) Gagal bayar (default)
Kegagalan dari emiten untuk melakukan pembayaran bunga
serta hutang pokok pada waktu yang telah ditetapkan, atau
kegiatan emiten untuk memenuhi ketentuan lain yang
ditetapkan dalam kontrak Obligasi.

25
b) Capital Loss
Obligasi yang dijual sebelum jatu tempo dengan harga yang
lebih rendah dari harga belinya.
c) Callability
Sebelum jatuh tempo, emiten mempunyai hak untuk
membeli kembali Obligasi yang telah diterbitkan.
2.2.3. Derivatif
Derivatif terdiri dari efek yang diturunkan dari instrumen efek lain yang
disebut “underlying” . Ada beberapa macam instrument derivatif di Indonesia, seperti
Bukti Right, Waran, dan Kontrak Berjangka. Derivatif merupakan instrumen yang
sangat berisiko jika tidak dipergunakan secara hati-hati.
2.2.3.1. Bukti Right
2.2.3.1.1. Pengertian Bukti Right
Sesuai dengan undang-undang Pasar Modal, Bukti Right
didefinisikan sebagai hak memesan efek terlebih dahulu pada
harga yang telah ditetapkan selama periode tertentu. Bukti Right
diterbitkan pada penawaran umum terbatas (Right Issue), dimana
saham baru ditawarkan pertama kali kepada pemegang saham
lama. Bukti Right juga dapat diperdagangkan di Pasar Sekunder
selama periode tertentu.
2.2.3.1.2. Manfaat Investasi Bukti Right
Berikut ini beberapa manfaat Bukti Right:
a) Investor memiliki hak istimewa untuk membeli
saham baru pada harga yang telah ditetapkan dengan
menukarkan Bukti Right yang dimilikinya. Hal ini
memungkinkan investor untuk memperoleh
keuntungan dengan membeli saham baru dengan
harga yang lebih murah.

26
b) Bukti Right dapat diperdagangkan pada Pasar
Sekunder, sehingga investor dapat menikmati Capital
Gain, ketika harga jual dari Bukti Right tersebut lebih
besar dari harga belinya.
2.2.3.1.3. Risiko Investasi Bukti Right
Berikut ini merupakan risiko dari memiliki Bukti Right:
a) Jika harga saham pada periode pelaksanaan jatuh dan
menjadi lebih rendah dari harga pelaksanaan, maka
investor tidak akan mengkonversikan Bukti Right
tersebut, sementara itu investor akan mengalami
kerugian atas harga beli Right.
b) Bukti Right dapat diperdagangkan pada pasar
sekunder, sehingga investor dapat mengalami
kerugian (Capital Loss), ketika harga jual dari Bukti
Right tersebut lebih rendah dari harga belinya.
2.2.3.2. Waran
2.2.3.2.1. Pengertian Waran
Waran biasanya melekat sebagai daya tarik (sweetener)
pada penawaran umum saham ataupun obligasi. Biasanya harga
pelaksanaan lebih rendah dari pada harga pasar saham. Setelah
saham ataupun obligasi tersebut tercatat di bursa, waran dapat
diperdagangkan secara terpisah.
2.2.3.2.2. Manfaat Investasi Waran
Berikut ini merupakan manfaat dari memiliki Waran:
a) Pemilik waran memiliki hak untuk membeli saham
baru perusahaan dengan harga yang lebih rendah dari
harga saham tersebut di Pasar Sekunder dengan cara
menukarkan waran yang dimilikinya ketika harga

27
saham perusahaan tersebut melebihi harga
pelaksanaan.
b) Apabila waran diperdagangkan di Bursa, maka
pemilik waran mempunyai kesempatan untuk
memperoleh keuntungan (capital gain) yaitu apabila
harga jual waran tersebut lebih besar dari harga beli.
2.3. Kerangka Pikir
Latar Belakang
Studi literatur dan lain-lain
Identifikasi Masalah
Identifikasi kebutuhan informasi
Gambar 2.3 Kerangka Pikir Penelitian
Evaluasi classification dengan menggunakan metode classification
Visualisasi grafik
Penerapan Data Mining pada Targeted
Marketing




















