
ANALISIS PENGELOMPOKAN OBJEK DENGAN METODE … · Clustering dan Diskriminan Linear untuk Kasus Dua...
35
ANALISIS PENGELOMPOKAN OBJEK DENGAN METODE SINGLE LINKAGE CLUSTERING DAN DISKRIMINAN LINEAR UNTUK KASUS DUA KELOMPOK MELINDA DEPARTEMEN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2006
Transcript of ANALISIS PENGELOMPOKAN OBJEK DENGAN METODE … · Clustering dan Diskriminan Linear untuk Kasus Dua...

ANALISIS PENGELOMPOKAN OBJEK DENGAN METODE SINGLE LINKAGE CLUSTERING
DAN DISKRIMINAN LINEAR UNTUK KASUS DUA KELOMPOK
MELINDA
DEPARTEMEN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR BOGOR
2006

ANALISIS PENGELOMPOKAN OBJEK DENGAN METODE SINGLE LINKAGE CLUSTERING
DAN DISKRIMINAN LINEAR UNTUK KASUS DUA KELOMPOK
MELINDA
Skripsi Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Sains pada Departemen Matematika
DEPARTEMEN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR BOGOR
2006

ABSTRAK
MELINDA. Analisis Pengelompokan Objek dengan Metode Single Linkage Clustering dan Diskriminan Linear untuk Kasus Dua Kelompok. Dibimbing oleh MUHAMMAD NUR AIDI dan RETNO BUDIARTI.
Banyak keragaman yang dapat dijumpai pada kehidupan ini sehingga pengelompokan suatu objek yang relatif homogen selalu menjadi permasalahan yang menarik. Analisis cluster merupakan teknik multivariat yang tujuan utamanya mengelompokkan objek-objek berdasarkan kesamaan karakteristik di antara objek-objek tersebut. Ciri pengelompokan yang baik, pertama terdapat kesamaan yang tinggi antar anggota dalam satu kelompok. Kedua, antar kelompok yang satu dengan kelompok lainnya memiliki perbedaan yang tinggi.
Terdapat beberapa metode dalam analisis cluster, salah satu diantaranya adalah metode hierarki yang akan mengelompokkan objek-objek secara bertingkat. Metode agglomeratif merupakan metode hierarki yang sering dipakai untuk suatu data metrik. Metode ini secara algoritma akan mengelompokkan objek-objek berdasarkan tingkat kesamaan antar objek-objek dari yang terdekat sampai akhirnya semua objek berada dalam sebuah kelompok. Jarak antara suatu kelompok terhadap kelompok lainnya dihitung sebagai jarak minimum antara anggota kelompok pertama dengan anggota kelompok lainnya, metode pengukuran ini disebut sebagai single linkage clustering merupakan metode yang paling sederhana.
Kevalidan hasil pengelompokan dengan metode yang digunakan perlu agar tidak terjadi kesalahan (misklasifikasi) yang cukup besar terutama pada saat menentukan strategi dari tujuan dilakukannya analisis cluster. Analisis diskriminan merupakan metode yang dapat digunakan untuk menguji kevalidan hasil dari metode yang digunakan pada analisis cluster dan juga merupakan analisis lanjutan untuk menentukan fungsi setiap kelompok yang terbentuk (fungsi diskriminan). Dari fungsi diskriminan dapat dengan mudah menentukan kelompok untuk suatu objek baru. Fungsi ini dapat diperoleh dari persamaan yang akan meminimumkan nilai expected cost of misclassification (ECM).
Pengelompokan tujuh belas kabupaten/kota di Jawa Barat berdasarkan tiga indikator sosial ekonomi pada tahun 2002, yaitu upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan ekonomi ke dalam dua kelompok menghasilkan fungsi diskriminan 321 5153,00993,20694,6 xxxy ++= . Fungsi diskriminan yang diperoleh mempunyai ketepatan mengklasifikasikan kasus sebesar 94,12%. Maka, fungsi ini dapat digunakan untuk mengelompokkan sebuah kabupaten/kota berdasarkan ketiga indikator tersebut ke dalam kelompok dengan tingkat sosial ekonomi menengah ke bawah atau menengah ke atas.

Judul Skripsi : Analisis Pengelompokan Objek dengan Metode Single Linkage
Clustering dan Diskriminan Linear untuk Kasus Dua Kelompok Nama : Melinda NIM : G54101010
Menyetujui:
Pembimbing I Pembimbing II
Dr. Ir. Muhammad Nur Aidi, MS. Ir. Retno Budiarti, MS. NIP. 131842408 NIP. 131842409
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS. NIP. 131473999
Tanggal Lulus : 27 September 2006

PRAKATA
Alhamdulillah, puji dan syukur penulis panjatkan kepada Allah SWT atas segala limpahan rahmatNya sehingga karya ilmiah ini berhasil diselesaikan. Shalawat dan salam semoga tercurah kepada Rasulullah SAW.
Selama menyusun karya ilmiah, penulis banyak mendapatkan bimbingan dan bantuan dari berbagai pihak. Dalam kesempatan ini, penulis mengucapkan terima kasih kepada Bapak Dr. Ir. Muhammad Nur Aidi, MS., dan Ibu Ir. Retno Budiarti, MS. selaku pembimbing serta Bapak Dr. Ir. I Gusti Putu Purnaba, DEA. selaku penguji. Ungkapan terima kasih juga disampaikan kepada kedua orang tua dan seluruh keluarga tercinta atas do’a dan kasih sayangnya. Selain itu, penulis juga menghaturkan terima kasih kepada seluruh staf dan dosen Departemen Matematika IPB. Terima kasih kepada semua teman Matematika 38, kost-an Al-Mardhiyah, dan semua pihak yang telah membantu kelancaran karya ilmiah ini atas do’a, perhatian, dan dukungan yang diberikan.
Semoga karya ilmiah ini bermanfaat dalam bidang ilmu pengetahuan.
Bogor, September 2006
Melinda

RIWAYAT HIDUP
Penulis dilahirkan di Sumedang, 20 Oktober 1983 sebagai anak pertama dari 3 bersaudara dari pasangan Iman Arfiman dan Euis Suharyati.
Pada tahun 1995 penulis menyelesaikan sekolah di SDN Gudang Kopi 2 Sumedang dan tahun 1998 penulis menyelesaikan sekolahnya di SMPN 8 Sumedang. Pada tahun sama, penulis melanjutkan sekolah ke SMUN 2 Sumedang dan lulus pada tahun 2001. Pada tahun tersebut penulis diterima di IPB Departemen Matematika melalui jalur USMI.
Selama perkuliahan, penulis terlibat sebagai pengurus Himpro Departemen Matematika (GUMATIKA) dan TKA Al-Fikri. Selain itu penulis pernah bekerja sebagai staf administrasi pada Yayasan Kirana Indonesia.

DAFTAR ISI
Halaman
DAFTAR TABEL......................................................................................................................... viii
DAFTAR GAMBAR .................................................................................................................... viii
DAFTAR LAMPIRAN..................................................................................................................viii PENDAHULUAN
Latar Belakang .......................................................................................................................1 Tujuan .............................................................................................................. 1
LANDASAN TEORI ................................................................................................. 1 METODE DAN PEMBAHASAN
Analisis Cluster .......................................................................................................................5 Analisis Diskriminan ..............................................................................................................7 Contoh Kasus .........................................................................................................................11
SIMPULAN ..................................................................................................................................14
DAFTAR PUSTAKA ....................................................................................................................15 LAMPIRAN...................................................................................................................................16

DAFTAR TABEL
Halaman
1 Pengelompokan objek berdasarkan jumlah kelompok yang diinginkan.................................... 6 2 Upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju
pertumbuhan ekonomi (LPE) 14 kabupaten/kota di Jawa Barat pada tahun 2002 ....................11 3 Upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju
pertumbuhan ekonomi (LPE) Kab. Sumedang, Kab. Bogor, dan Kab. Purwakarta pada tahun 2002 .................................................................................................................................13
4 Nilai diskriminan masing-masing kabupaten/kota.....................................................................14
DAFTAR GAMBAR
Halaman
1 Jarak antar kelompok untuk single linkage clustering .............................................................. 5 2 Contoh Dendogram .................................................................................................................. 6
DAFTAR LAMPIRAN
Halaman
1 ANALISIS CLUSTER
1.1 Nilai standarisasi upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan ekonomi (LPE) pada tahun 2002........................16
1.2 Matriks jarak euclid antar kabupaten/kota ( matriks kasamaan).....................................17 1.3 Tabel tahap agglomeratif dengan single linkage clustering ...........................................19 1.4 Tabel anggota kelompok untuk 4, 3, dan 2 pengelompokan ..........................................20 1.5 Gambar dendogram single linkage clustering untuk jarak antar kabupaten/kota ...........21 1.6 Diagram pencar UMK, tingkat pengangguran, dan LPE................................................22
2 ANALISIS DISKRIMINAN 2.1 Nilai standarisasi upah minimum kabupaten/kota (UMK), persentase tingkat
pengangguran, dan laju pertumbuhan ekonomi (LPE) kelompok pertama dan kelompok kedua .............................................................................................................23
2.2 Hasil uji beda vektor rataan antar kelompok ..................................................................24 2.3 Hasil uji asumsi kenormalan variabel UMK, tingkat pengangguran, dan LPE ..............25 2.4 Hasil uji asumsi kehomogenan matriks kovarian kelompok pertama dengan
kelompok kedua LPE .....................................................................................................27

PENDAHULUAN Latar Belakang
Banyak keragaman yang dapat dijumpai pada kehidupan ini sehingga pengelompokan suatu objek yang relatif homogen selalu menjadi permasalahan yang menarik. Salah satu alasan pengelompokan adalah untuk memperoleh contoh data yang dapat mewakili populasi atau dapat menggambarkan karakteristik objek dalam populasi yang dikelompokkan.
Analisis cluster merupakan teknik multivariat yang tujuan utamanya mengelompokkan objek-objek berdasarkan kesamaan karakteristik di antara objek-objek tersebut. Analisis ini dapat bermanfaat dan diterapkan pada berbagai bidang ilmu, seperti : geografi, psikologi, biologi, manajemen dan lain sebagainya. Objek yang diamati dapat berupa produk (barang dan jasa), benda (tumbuhan atau lainnya) serta orang (responden, konsumen atau yang lain).
Ciri pengelompokan yang baik, pertama terdapat kesamaan yang tinggi antar anggota dalam satu kelompok (intra kelompok). Kedua, antar kelompok yang satu dengan kelompok lainnya (inter kelompok) memiliki perbedaan yang tinggi. Salah satu metode analisis cluster adalah dengan metode
hierarki. Metode hierarki yang banyak dipakai untuk suatu data metrik adalah metode agglomeratif. Adapun, setelah diperoleh hasil pengelompokan perlu dilakukan validasi dengan membandingkan hasil yang diperoleh terhadap metode lainnya ataupun dapat dilakukan suatu analisis lanjutan seperti analisis diskriminan. Analisis diskriminan selain itu berguna untuk memperoleh fungsi yang dapat menunjukkan perbedaan (diskriminasi) antar kelompok.
Pada tulisan ini akan dibahas proses pengelompokan objek secara agglomeratif dengan menggunakan metode paling sederhana yaitu, single linkage clustering serta menguraikan analisis diskriminan untuk mengevaluasi objek pada kasus dua kelompok. Contoh pengolahan data pada tulisan ini menggunakan software SPSS. Tujuan
Tujuan dari penulisan ini adalah menguraikan dan mempelajari proses pengelompokan suatu objek dengan menggunakan single linkage clustering. Serta bagaimana proses mengevalusi suatu objek pada kelompok yang terbentuk dengan analisis diskriminan.
LANDASAN TEORI
Berikut ini beberapa pokok bahasan
berupa definisi dan teorema yang dijadikan landasan dalam penyusunan tulisan ini. Definisi 1 (Analisis Cluster) Analisis cluster merupakan alat untuk membangun kelompok-kelompok (cluster) dari objek data multivariat.
(Härdle & Simar 2003) Definisi 2 (Analisis Diskriminan) Analisis diskriminan merupakan metode dan alat yang digunakan untuk membedakan antar kelompok serta berguna untuk menentukan proses mengalokasikan objek baru ke dalam kelompok.
(Härdle & Simar 2003) Definisi 3 (Single Linkage Clustering) Single linkage clustering mendefinisikan bahwa jarak antar kelompok merupakan jarak terdekat dari anggota kelompok pertama dengan anggota kelompok lainnya.
(Hair, Anderson, Tatham, & Black 1998)
Definisi 4 (Ruang Contoh) Ruang contoh adalah himpunan dari semua kemungkinan hasil suatu percobaan, dinotasikan Ω .
(Hogg & Craig 1995) Definisi 5 (Peubah Acak) Peubah acak X adalah suatu fungsi yang memetakan masing-masing elemen pada ruang contoh tepat satu ke bilangan real, dinotasikan X: R→Ω .
(Hogg & Craig 1995) Definisi 6 (Jarak Euclid) Jarak euclid untuk n objek dapat didefinisikan,
2...
222
211 ⎟
⎠⎞⎜
⎝⎛ −++⎟
⎠⎞⎜
⎝⎛ −+⎟
⎠⎞⎜
⎝⎛ −= jkxikxjxixjxixdij
dimana: i, j= 1, 2, ..., n dij = jarak euclid antara objek ke-i dengan objek ke-j xik = objek ke-i untuk variabel ke-k xjk = objek ke-j untuk variabel ke-k
(Johnson & Wichern 1998)

Definisi 7 ( Rataan) Misalkan x1, x2, ..., xn, objek pengamatan, rataannya
n
n
iix
µ∑== 1
dimana: µ = rataan untuk n objek pengamatan xi = objek pengamatan ke-i n = jumlah objek yang diamati
(Moore 1994) Definisi 8 (Ragam) Ragam untuk n objek pengamatan x1, x2, ..., xn didefinisikan sebagai
( )1
1
2
2
−
∑=
µ−
=n
n
iix
S
dimana: S2 = ragam untuk n objek pengamatan
S = 2S = simpangan baku untuk n objek pengamatan µ = rataan untuk n objek pengamatan xi = objek pengamatan ke-i
(Moore 1994) Definisi 9 (Koefisien Korelasi) Korelasi antara variabel xl dan xk,
⎟⎟⎠
⎞⎜⎜⎝
⎛ µ−∑ ⎟⎟
⎠
⎞⎜⎜⎝
⎛ µ−−
== k
kikn
i l
lillk S
xS
xn
r11
1
dimana: rlk = korelasi antara variabel ke-l dan ke-k Sl = simpangan baku untuk variabel ke-l Sk = simpangan baku untuk variabel ke-k
lµ = rataan untuk variabel ke-l
kµ = rataan untuk variabel ke-k xil = objek ke i untuk variabel ke-l xik = objek ke i untuk variabel ke-k
(Moore 1994) Definisi 10 (Kovarian) Kovarian antara variabel xl dan xk,
( ) kllkkl SSrx,x =cov dimana: cov(xl ,xk) = kovarian antara variabel ke-l dan ke-k rlk = korelasi antara variabel ke-l dan ke-k Sl = simpangan baku untuk variabel ke-l Sk = simpangan baku untuk variabel ke-k
(Hogg & Craig 1995)
Definisi 11 (z-skor) Suatu pengamatan x dari suatu populasi yang mempunyai nilai tengah µ dan simpangan baku S, mempunyai nilai z yang didefinisikan sebagai
Sx µ−
=z
(Walpole 1995) Definisi 12 (Fungsi Kepekatan Peluang) Misalkan X peubah acak dengan ruang contoh Ω berdimensi satu, terdiri dari sebuah interval atau gabungan interval. Fungsi f(x) non negatif maka
( )∫ =Ω
1dxxf
Fungsi peluang P(R), Ω⊂R , dapat ditulis P(R) = Pr(X∈R) = ( )∫
RX dxxf
X disebut peubah acak kontinu dan fX(x) disebut fungsi kepekatan peluang bagi X.
(Hogg & Craig 1995) Definisi 13 (Fungsi Likelihood) Misalkan ( )θ,xf fungsi kepekatan peluang dengan parameter θ , fungsi likelihood adalah ( ) ( ) ( ) ( ).,,, 321 θθθθ xfxfxfL K=
(Hogg & Craig 1995) Definisi 14 (Aturan Diskriminan
Maksimum Likelihood) Aturan maksimum likelihood untuk mengalokasikan sebuah objek x ke salah satu kelompok Πg, dimana g = 1, 2,…,ng adalah mengalokasikan x ke kelompok yang memberikan likelihood terbesar ke x.
(Mardia, Kent & Bibby 1989) Definisi 15 (Peluang Suatu Kejadian) Peluang suatu kejadian A adalah jumlah peluang semua titik contoh dalam A. Apabila suatu percobaan mempunyai N hasil percobaan yang berbeda dan masing-masing mempunyai kemungkinan yang sama untuk terjadi, dan bila tepat n di antara hasil percobaan itu menyusun kejadian A, maka peluang kejadian A adalah
( )NnAP =
(Walpole 1995) Definisi 16 (Peluang Bersyarat) Peluang bersyarat B, bila A diketahui dilambangkan dengan P(B|A), didefinisikan sebagai

( ) ( )( )AP
BAPA|BP ∩= jika P(A) > 0
(Walpole 1995) Definisi 17 (Distribusi Multinormal) Misalkan X = [X1, X2, ..., Xk]' vektor acak kontinu memiliki fungsi kepekatan peluang fX(x), X berdistribusi normal dengan vektor rataan µ dan matriks kovarian Σ > 0. X ~ Nk( µ , Σ ),
( ) ( ) ( )⎥⎦⎤
⎢⎣⎡ −−−= −− µxΣµxΣx 1'
21exp2 2/k
Xf π
(Härdle & Simar 2003)
Definisi 18 (Distribusi Khi-kuadrat) Fungsi kepekatan peluang untuk peubah acak kontinu X berdistribusi khi-kuadrat dengan derajat bebas r, X~ 2
rχ ,
( )( )
212222
1 xrrX ex
rxf −−
Γ= , ∞<< x0 .
dimana:
( ) ∫=αΓ∞
−−α
0
1 dyey y , 0>α .
(Hogg & Craig 1995)
Definisi 19 (Distribusi F) Misalkan X1 dan X2 peubah acak bebas masing-masing berdistribusi khi-kuadrat dengan derajat bebas r1 dan r2. Fungsí kepekatan peluang bersama untuk X1 dan X2 berdistribusi F,
( )
( ) ( ) ( )( ) 2/21122
2121
12/2121
2121
22/2/1
,
xxrrrr
XX
exxrr
xxf
+−−−+ΓΓ
=
.x,x ∞<<∞<< 21 00 (Hogg & Craig 1995)
Definisi 20 (Modus) Modus segugus pengamatan adalah nilai tengah yang terjadi paling sering atau yang mempunyai frekuensi paling tinggi.
(Walpole 1995) Definisi 21 (Skewness) Skewness adalah nilai ukuran kecondongan grafik. Nilai skewness = (rataan-modus)/simpangan baku
(Santoso 2000) Definisi 22 (Kurtosis) Kurtosis menunjukkan tinggi rendahnya atau runcing datarnya bentuk kurva model normal
atau distribusi normal. Koefisien kurtosis a4 dirumuskan
( )2244 / mma =
dimana: ( )
nxx
mr
ir
∑ −= , r = 0, 1, 2, ...
mr = momen ke r xi = objek pengamatan ke-i x = rataan variabel untuk n objek pengamatan
(Sudjana 2000) Uji beda 2 vektor rataan (T2 Hotelling) H0: 21 µµ = H1: 21 µµ ≠ T2 Hotelling didefinisikan,
( ) ( ) ( )211
gabungan2121
212 ' µµΣµµ −−+
= −
nnnnT
( )( )1,
21
212211
2~ −−+−−+−+
knnkFknn
knnT
dimana: n1 = jumlah anggota kelompok pertama n2 = jumlah anggota kelompok kedua k = banyaknya variabel bebas H0 diterima jika: ( )
( )1,2
21
21211
2−−+≤
−−+−+
knnkFTknn
knn
(Mardia, Kent & Bibby 1989)
Uji Kenormalan Multivariat (Skewness dan Kurtosis) Misalkan X = [X1, X2, ..., Xk]' vektor acak dan Σ matriks kovarian untuk contoh,
( )( ) ''n
n
iii HHDxxxxΣ u=−−
−= ∑
=111
dimana: H = (h1, h2, ..., hk) matriks ortogonal Du = diag(u1, u2, ..., uk) Skewness dan kurtosis untuk contoh data, didefinisikan
( )∑ ∑= =
−
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−=k
r
n
irrirk nyyu
kb
1
2
1
323
11
dan
( )∑∑==
− −=n
iiri
k
rrk yyu
nkb
1
4
1
22
1
dimana: r = 1, 2, ..., k i = 1, 2, ..., n
i'rri xhy =
∑=
=k
irir y
ny
1
1

Data pengamatan tidak berdistribusi normal , jika
2,16 αχ≥⎟
⎠⎞
⎜⎝⎛
kkbnk
Tes kurtosis menolak normality, jika
( ) 2221
324 αzbnk
k ≥−⎟⎠⎞
⎜⎝⎛
(Srivastava 2002)
Uji kehomogenan kovarian (Uji Box’s M) H0: gn... ΣΣΣ === 21
H1: ji ΣΣ ≠ , i ≠ j. Box’s M dirumuskan sebagai berikut,
( ) uu ΣΣ 1log1 −∑ −γ= ggnM ,
dimana:
( )( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛∑
−−
−−+−+
−=γgnngk
kk
g
11
11161321
2
ΣΣgn
nu −=
gg
gug n
nΣΣ
1−=
Box’s M mempunyai distribusi khi-kuadrat asimtotik dengan derajat bebas
( )( )1121
−+ gkk .
dimana: g = 1, 2, ..., ng. ng = jumlah objek dalam kelompok ke-g Σ = matriks kovarian gabungan
gΣ = matriks kovarian kelompok ke-g
H0 diterima jika ( )( )2211 −+≤
gnkkM χ
(Mardia, Kent & Bibby 1989) Teorema Neyman-Pearson Misalkan X1, X2,..., Xn, dimana n bilangan bulat positif, merupakan contoh acak kontinu dari fungsi kepekatan peluang ( )θ;xf . Maka fungsi kepekatan peluang bagi X1, X2,..., Xn adalah ( ) ( ) ( ) ( )θθθθ ;;;,,,; 2121 nn xfxfxfxxxL KK =
Misalkan θ' dan θ" nilai tetap nyata bagi θ sehingga ",': θθθθ ==Ω , dan k bilangan positif. Misalkan C himpunan bagian dari ruang contoh Ω dan C* komplemen dari C sehingga,
(a) ( )( ) k
xxxLxxxL
n
n ≤,,,;",,,;'
21
21
K
K
θθ
,
dimana (x1, x2, ...., xn) ∈C.
(b) ( )( ) k
xxxLxxxL
n
n ≥,,,;",,,;'
21
21
K
K
θθ
,
dimana (x1, x2, ...., xn) ∈C*. (c) ( )[ ]021 H*;,,,Pr CXXX n ∈= Kα Maka C daerah kritis terbaik dengan ukuran α untuk menguji hipotesis H0: θ = θ' dan H1: θ = θ". Bukti: Jika α ukuran daerah kritis C, dan terdapat daerah kritis lainnya berukuran α yaitu A. Maka,
( )∫ ∫ nnRdxdxxxxL LKL 121 ,,,;θ dinotasikan
oleh ( )∫R L θ . Akan ditunjukkan bahwa, ( ) ( )∫ ∫ ≥−C A LL 0"" θθ .
Jika C gabungan dari irisan C∩A dan C∩A* dan A gabungan A∩C dan A ∩C*, maka
( ) ( )∫−∫ AC LL "" θθ ( ) ( ) ( ) ( )∫ ∫ ∫ ∫−−+= ∩ ∩ ∩ ∩AC AC CA CA LLLL * * """" θθθθ( ) ( )∫−∫= ∩∩ ** "" CAAC LL θθ (1)
Karena ( ) ( ) ( )'1" θθ LkL ≥ pada setiap titik di C, dan setiap titik di C∩A*, maka
( ) ( )∫ ∫≥∩ ∩* * '1"AC AC Lk
L θθ (2)
Tetapi, ( ) ( ) ( )'1" θθ LkL ≤ pada setiap titik di C*, dan setiap titik di A∩C*, maka
( ) ( )∫ ∫≤∩ ∩* * '1"CA CA Lk
L θθ (3)
Dari persamaan (2) dan (3) dapat diperoleh suatu pertidaksamaan berikut,
( ) ( ) ( ) ( )∫ ∫ ∫−≥∫−∩ ∩ ∩∩* * ** '1'1""AC AC CACA Lk
Lk
LL θθθθ
dan dari persamaan (1), diperoleh
( ) ( ) ( ) ( )∫ ∫ ∫−≥∫− ∩ ∩C AC CAA Lk
Lk
LL * * '1'1"" θθθθ (4)
Sehingga, ( ) ( )∫−∫ ∩∩ ** '' CAAC LL θθ ( ) ( ) ( ) ( )∫−∫ ∫−∫+= ∩∩ ∩∩ ** '''' CAAC CAAC LLLL θθθθ
( ) ( )∫ ∫−= C A LL '' θθ .0=α−α=
Jika hasil disubstitusi ke persamaan (4), diperoleh
( ) ( ) .0"" ≥∫−∫ AC θLθL (Hogg & Craig 1995)
METODE DAN PEMBAHASAN
Analisis Cluster
Proses pengelompokan melalui analisis cluster dapat dibagi ke dalam enam tahap:
Tahap pertama, memilih ataupun mengambil data yang akan digunakan sebagai objek pada analisis cluster. Misalkan, terdapat suatu data dengan n objek dan memiliki k variabel. Matriks data:
⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
nknn
k
xxx
xxxx
LLL
MOMM
MOMM
MOMM
MM
LLL
21
22
11211
Tahap kedua, memperhatikan apakah nilai
variabel dari data mempunyai perbedaan yang besar. Jika terdapat perbedaan maka data harus dibakukan dengan mengubahnya ke nilai z.
( )l
lilil S
x µ−=z
dimana: zil = nilai z untuk objek ke-i variabel ke-l xil = objek ke-i variabel ke-l
lµ = rataan untuk semua nilai variabel ke-l Sl = simpangan baku untuk variabel ke-l
Tahap ketiga, apabila data yang diambil berupa contoh maka harus diasumsikan bahwa contoh yang diambil benar-benar mewakili populasi yang ada. Asumsi lainnya yaitu, kemungkinan adanya korelasi antar variabel bebas sebaiknya tidak ada jika ada harus tidak besar (angka korelasi tidak mencapai 0,90). Asumsi ini harus dipenuhi agar hasil analisis yang diperoleh representatif, menggambarkan karakteristik dari populasi.
Tahap keempat, memilih algoritma pengelompokan yang akan dipakai. Metode hierarki tepat digunakan untuk suatu data metrik. Metode hierarki dengan menggunakan metode agglomeratif, mengalokasikan objek-objek yang terpisah ke suatu kelompok menurut tingkatan kesamaan sehingga akhirnya semua objek berada dalam satu kelompok. Jika ng menunjukkan banyaknya kelompok, maka nng ≤ . Algoritma agglomeratif untuk n objek :
Langkah pertama, membentuk matriks jarak simetri berukuran n x n,
⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
==
nnnn
n
ij
ddd
dddd
d
LLL
MOMM
MOMM
MOMM
MM
LLL
21
22
11211
D
dimana: i = 1, 2, ..., n j = 1, 2, ..., n dij jarak antara objek ke-i dan ke-j menunjukkan tingkat kesamaan atau ketidaksamaan antara n objek. Jarak antar objek tersebut menggunakan persamaan jarak euclid. Langkah kedua, menentukan pasangan objek yang memiliki kesamaan paling besar, misalkan jarak objek U dan V paling minimum (dUV = mindij). Langkah ketiga, menggabungkan objek U dan V sebagai kelompok baru (UV). Membentuk kembali matriks baru berukuran (n-1)x(n-1) dengan menghapus baris dan kolom yang bersesuaian dengan objek U dan V dan menambah sebuah baris dan kolom yang terdiri dari elemen jarak antara kelompok (UV) dengan objek lain. Misalkan terdapat objek lain W, fungsi jarak antara kelompok (UV) dengan objek W yang didefinisikan oleh metode single linkage clustering adalah
( ) VWUWVWUWWUV ddddd −−+=21
21
21 (5)
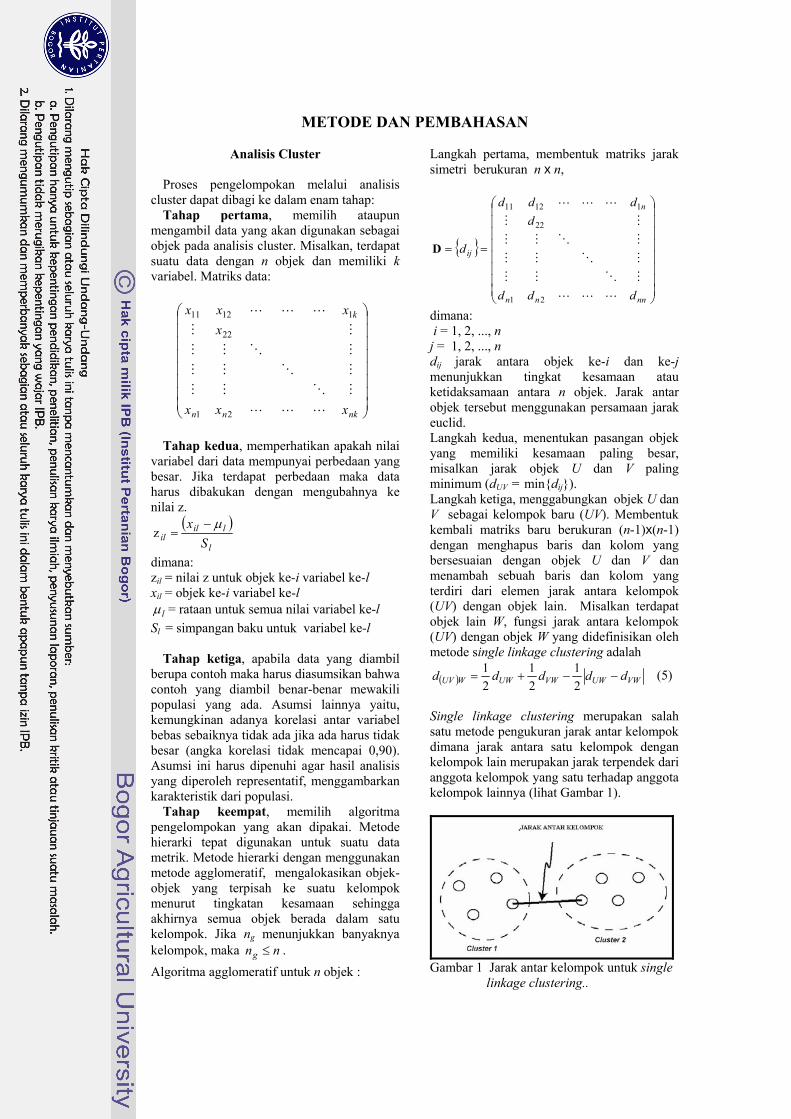
Single linkage clustering merupakan salah satu metode pengukuran jarak antar kelompok dimana jarak antara satu kelompok dengan kelompok lain merupakan jarak terpendek dari anggota kelompok yang satu terhadap anggota kelompok lainnya (lihat Gambar 1).
Gambar 1 Jarak antar kelompok untuk single linkage clustering..

Jarak minimum di antara jarak U ke W dengan jarak V ke W, dinotasikan sebagai d(UV)W = min dUW, dVW (6) Maka dapat ditunjukkan bahwa,
d(UV)W = VWUWVWUW dddd −−+21
21
21
= min dUW, dVW Bukti : Misalkan dUW > dVW,
VWUWVWUW dddd −=− substitusi ke persamaan (5), diperoleh d(UV)W = dVW (7) Misalkan dUW < dVW,
UWVWVWUW dddd −=− substitusi ke persamaan (5), diperoleh d(UV)W = dUW (8) Dari (7) dan (8) diperoleh bahwa d(UV)W = min dUW, dVW. Selanjutnya, ulangi langkah-langkah di atas sampai terbentuk satu kelompok yang terdiri dari semua objek yang dikelompokkan. Namun, pengelompokan dapat pula dihentikan pada saat mindij ≤ do, dimana do nilai batas jarak intra kelompok yang sudah ditentukan.
Tahapan metode hierarki ini dapat ditampilkan sebagai graf ataupun diagram pohon seperti gambar 2. Graf hierarki disebut juga dendogram.
Gambar 2 Contoh Dendogram.
Pada dendogram di atas terlihat jelas
adanya tingkatan yang menunjukkan tahap pengelompokan. Jika dilihat pada Gambar 2, proses agglomeratif berjalan ke arah kanan menghasilkan beberapa kelompok sampai akhirnya semua objek bergabung menjadi satu kelompok. Jarak antar objek untuk setiap tahap pengelompokan secara hieraki akan semakin membesar atau jauh. Semakin besar jarak antar objek menunjukkan semakin besar perbedaan antar objek tersebut.
Dendogram dapat berfungsi untuk menunjukkan anggota kelompok yang sesuai dengan jumlah kelompok yang diinginkan.
Berdasarkan Gambar 2, dapat ditunjukkan anggota yang terdapat pada setiap kelompok berdasarkan jumlah kelompok yang diinginkan seperti yang ditampilkan pada Tabel 1.
Penentuan berapa jumlah kelompok biasanya berdasarkan pada tujuan dari dilakukannya proses analisis cluster (penelitian). Dalam hal ini, tidak ada ketentuan khusus berapa jumlah cluster yang ideal harus dibentuk. Adapun penentuan dari anggota untuk setiap kelompok berdasarkan pada tingkat kesamaan, dengan memperhatikan jarak antar objek. Setiap objek dalam satu kelompok harus memiliki tingkat kesamaan yang besar dan memiliki tingkat perbedaan yang jauh dengan kelompok lainnya. Dengan memperhatikan hal ini maka jumlah pengelompokan optimal dari Gambar 2 sebanyak tiga kelompok, dimana anggota kelompok pertama terdiri dari objek 6, 12, 1, 8, 5, dan 3. Sedangkan kelompok kedua terdiri dari objek 11, 2, 4, 13, 7, dan 9, serta objek 10 sebagai anggota kelompok ketiga. Tabel 1 Pengelompokan objek berdasarkan jumlah kelompok yang diinginkan.
Jumlah kelompok Objek
4 3 2 1 2 1 1 2 3 2 2 3 2 1 1 4 3 2 2 5 2 1 1 6 1 1 1 7 3 2 2 8 2 1 1 9 3 2 2
10 4 3 1/2 11 3 2 2 12 1 1 1 13 3 2 2
Tahap kelima, setelah kelompok terbentuk
maka tahap selanjutnya menginterpretasikan kelompok yang terbentuk, yaitu memberi nama spesifik untuk menggambarkan objek yang terdapat dalam kelompok tersebut. Pemberian nama terhadap kelompok sama halnya dengan penentuan jumlah kelompok yaitu, berdasarkan pada tujuan dilakukan analisis cluster.
Tahap keenam, melakukan profiling kelompok dan validasi. Profiling adalah menjelaskan karakteristik setiap kelompok berdasarkan variabel yang membentuk

kelompok. Pada saat profiling ditentukan persentase atas jumlah objek yang membentuk kelompok serta melihat perbedaan komposisi yang mencolok antar anggota kelompok. Perbedaan komposisi dapat dijelaskan secara lanjut melalui analisis diskriminan. Dari analisis diskriminan dapat ditemukan fungsi untuk kelompok yang terbentuk. Selain itu, dari fungsi yang dibuat dapat mempermudah pengelompokan objek yang baru. Kevalidan dari hasil dapat dilakukan dengan menggunakan analisis diskriminan. Apabila hasil dari evalusi objek terhadap diskriminan diperoleh nilai ketepatan lebih dari 50% maka dapat dikatakan bahwa model diskriminan yang diperoleh valid dan hasil dari pengelompokan analisis cluster juga valid.
Analisis Diskriminan
Analisis diskriminan digunakan sebagai
metode dan alat untuk memisahkan objek-objek ke dalam kelompok secara tepat atau mengevaluasi apakah objek-objek yang telah dikelompokkan sudah tepat atau belum berada dalam kelompok yang diduga, dari fungsi diskriminan yang dicari. Fungsi diskriminan dapat berguna pula untuk mengalokasikan objek baru ke dalam kelompok yang sudah terbentuk sebelumnya saat analisis cluster. Dari fungsi diskriminan yang diperoleh, maka dapat diketahui hubungan antara variabel-variabel bebas yang bersifat metrik terhadap variabel terkait (kelompok) yang bersifat kategori. Fungsi diskriminan yang bersifat linear secara umum dituliskan,
kk x...xxy λλλ +++= 2211 dimana: y = nilai diskriminan (variabel terkait)
kλ = nilai pembobot diskriminan untuk variabel ke-k xk = variabel bebas ke-k
Asumsi yang diambil pada analisis
diskriminan untuk memperoleh fungsi diskriminan linear yaitu: matriks kovarian dari semua variabel bebas dalam setiap kelompok sama (homogen). Apabila kehomogenan matriks kovarian tidak terpenuhi, akan menyebabkan fungsi atau model yang diperoleh menunjukkan hubungan yang kurang tepat antara variabel bebas dengan variabel terkait. Variabel bebas boleh diasumsikan atau tidak berdistribusi normal, namun akan lebih baik apabila diasumsikan berdistribusi normal sehingga dapat diperoleh
fungsi diskriminan yang memiliki ketepatan mengelompokkan lebih baik.
Sebelum melakukan analisis diskriminan lanjutan, dilakukan terlebih dahulu uji asumsi. Salah satu uji asumsi terhadap kenormalan data adalah dengan menggunakan statistik skewness dan kurtosis. Sedangkan untuk menguji asumsi kehomogenan matriks kovarian salah satunya dengan uji Box’s M. Selain melakukan kedua uji asumsi dapat pula diuji beda 2 vektor rataan salah satunya dengan menggunakan T2 Hotelling yang berguna untuk melihat apakah terdapat perbedaan yang nyata antara kelompok yang terbentuk dari masing-masing variabel bebas.
Misalkan terdapat kelompok Πg, g = 1, 2, ..., ng dan x sebagai objek yang akan dialokasikan ke salah satu kelompok sedangkan x0 merupakan objek baru. Aturan diskriminan, memisahkan ruang contoh Ω menjadi Rg sehingga jika gR∈x , x diidentifikasikan sebagai anggota dari kelompok Πg dengan aturan diskriminan maksimum likelihood. Aturan maksimum likelihood mengalokasikan x ke Πg, dimana
( ) ( ) ( )xxx gg
gg LfL maks* == (9)
Sehingga diperoleh bahwa, ( ) ( )hg
ngLLR ghgg
≠
=>= ,,,2,1untuk: Kxxx
Jika Lg(x) = Lh(x), g ≠ h maka x dapat dialokasikan ke salah satu kelompok baik Πg atau Πh karena peluang mengelompokkan x misklasifikasi ke salah satu kelompok baik ke Πg atau Πh adalah P(Lg(x) = Lh(x), g ≠ h| Πg) = 0.
Misalkan g = 2, f1(x) dan f2(x) masing-masing merupakan fungsi kepekatan peluang vektor acak X berdistribusi normal untuk kelompok Π1 dan Π2, ruang contoh Ω = R1∪R2. Setiap objek hanya boleh dikelompokkan ke dalam salah satu dari kedua kelompok.
Pada saat pengelompokan akan mungkin menemukan kesalahan pengelompokan (misklasifikasi). Peluang mengelompokkan sebuah objek x yang terdiri dari peubah acak kontinu yang berasal dari Π1 ke Π2, dapat dihitung sebagai peluang bersyarat P(2|1) sebagai berikut, ( ) ( ) ( )∫=∈=
2 112 .|1|2 R dfΠRPP xxX (10) Hal sama, peluang mengelompokkan sebuah objek yang berasal dari Π2 ke Π1 adalah ( ) ( ) ( )∫=∈=
1 221 .|2|1 R dfΠRPP xxX (11)

Peluang pengelompokan objek-objek secara tepat atau tidak tepat dapat dirumuskan sebagai hasil kali peluang prior dengan peluang bersyarat : P(objek tepat dikelompokkan sebagai Π1) = P(objek berasal dari Π1 dan tepat diklasifikasikan sebagai Π1) = ( ) ( ) ( ) 1111 11 p|PP|RP =∈ ΠΠX (12)
P(objek tidak tepat dikelompokkan sebagai Π1) = P(objek berasal dari Π2 dan tidak tepat diklasifikasikan sebagai Π1) = ( ) ( ) ( ) 2221 21 p|PP|RP =∈ ΠΠX (13)
P(objek tepat dikelompokkan sebagai Π2) = P(objek berasal dari Π2 dan tepat diklasifikasikan sebagai Π2) = ( ) ( ) ( ) 2222 22 p|PP|RP =∈ ΠΠX (14)
P(objek tidak tepat dikelompokkan sebagai Π2) = P(objek berasal dari Π1 dan tidak tepat diklasifikasikan sebagai Π2) = ( ) ( ) ( ) 1112 12 p|PP|RP =∈ ΠΠX (15) Jumlah misklasifikasi objek pada setiap
kelompok dapat ditampilkan berupa tabel berikut Kelompok yang diduga Π1 Π2
Π1 n1c n1m
= n1-n1c Kelompok seharusnya Π2
n2m = n2-n2c
n2c
Ketepatan prediksi pengelompokan secara
tepat = 100%21
21 ×++
nnnn cc
Besar misklasifikasi pengelompokan
= 100%21
21 ×++
nnnn mm
dimana: n1c = jumlah objek Π1 tepat dikelompokkan sebagai anggota Π1 n1m = jumlah objek Π1 misklasifikasi sebagai anggota Π2 n2c = jumlah objek Π2 tepat dikelompokkan sebagai anggota Π2 n2m = jumlah objek Π2 misklasifikasi sebagai anggota Π1 n1 = n1c + n1m n2 = n2c + n2m
Misklasifikasi akan membuat biaya sebesar C(i | j). Matriks biaya tersebut : Kelompok yang diduga Π1 Π2
Π1 0 C(2|1) Kelompok seharusnya Π2 C(1|2) 0
Biaya sebesar nol terjadi apabila pengelompokan tepat, C(1|2) ketika objek dari Π2 tidak tepat dikelompokkan sebagai Π1, dan C(2|1) ketika objek dari Π1 tidak tepat dikelompokkan sebagai Π2.
Biaya yang diduga akibat misklasifikasi dirumuskan sebagai nilai expected cost of misclassification (ECM) yaitu,
( ) ( ) ( ) ( ) 21 21211212 p|P|Cp|P|CECM += (16)
Dengan mensubstitusi persamaan (10) dan (11) ke persamaan (16) diperoleh,
( ) ( ) ( ) ( )∫+∫=12 2211 2|11|2 RR dfpCdfpCECM xxxx
karena Ω = R1 ∪ R2 , dimana ( ) ( ) ( ) 1
1 211
Ω1 =∫ ∫+=∫
R Rdfdfdf xxxxxx
maka ECM dapat ditulis, ( ) ( )[ ] ( ) ( )( ) ( ) ( ) ( )[ ] ( ) 11122
2211
1|21|22|1
2|111|2
1
11
pCdfpCfpC
dfpCdfpCECM
R
RR
+∫ −=
∫+∫−=
xxx
xxxx (17)
p1, p2 , C(1/2), C(2|1) nilainya diketahui dan non negatif. f1(x) dan f2(x) juga diketahui dan bernilai non negatif untuk semua nilai x. Pengelompokan dikatakan tepat apabila ECM minimum atau kecil. ECM bernilai minimum apabila memenuhi aturan berikut :
( )( )
( )( ) ⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛≥=
1
2
2
11 1|2
2|1:pp
CC
ffR
xxx (18)
( )( )
( )( ) ⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛<=
1
2
2
12 1|2
2|1:pp
CC
ffR
xxx (19)

Lemma Neyman-Pearson Bukti persamaan (18) dan (19): Misalkan X = [X1, X2, ..., Xk]′ vektor acak, dan ( )x1φ dan ( )x2φ fungsi kontinu. Misalkan
21~~ RR ∪ ruang contoh vektor acak X dan 1
~R dan 2~R disjoint. Misalkan R1∪R2 ruang contoh X,
dimana R1=x| ( ) ( )xx 21 φ≥φ dan R2=x| ( ) ( )xx 21 φ<φ . Jika diberikan bahwa,
( ) ( ) xxxx ddI RR ∫ φ+∫ φ=21
~ 2~ 1~ , ( ) ( ) xxxx ddI RR ∫ φ+∫ φ=
21 21 maka selisih keduanya
( ) ( ) ( ) ( ) xxxxxxxx ddddII RRRR ∫ φ−∫ φ−∫ φ+∫ φ=−2121
~ 2~ 121~ .
Jika ( ) ( )21111~~ RRRRR ∩∪∩= , ( ) ( )22122
~~ RRRRR ∩∪∩= , ( ) ( )21111~~~ RRRRR ∩∪∩= ,
( ) ( )22122~~~ RRRRR ∩∪∩=
Maka selisih dapat ditulis ( ) ( ) ( ) ( ) ( ) ( )( ) ( ) xxxx
xxxxxxxxxxxx
dd
ddddddII
RRRR
RRRRRRRRRRRR
∫ φ−∫ φ−
∫ φ−∫ φ−∫ φ+∫ φ+∫ φ+∫ φ=−
∩∩
∩∩∩∩∩∩
2212
211122122111
~ 2~ 2
~ 1~ 1~ 2~ 2~ 1~ 1~
( ) ( ) ( ) ( ) xxxxxxxx dddd RRRRRRRR ∫ φ−∫ φ+∫ φ−∫ φ= ∩∩∩∩ 21121221~ 1~ 2~ 2~ 1
( ) ( )[ ] ( ) ( )[ ] xxxxxx dd RRRR ∫ φ−φ+∫ φ−φ= ∩∩ 1221~ 12~ 21
Karena ( ) 121~ RRR ⊂∩ dan ( ) ( )xx 21 φ≥φ dalam R1 mengakibatkan ( ) ( )[ ] 0
21~ 21 ≥∫ φ−φ∩ xxx dRR .
Sedangkan untuk ( ) 212~ RRR ⊂∩ dan ( ) ( )xx 21 φ<φ dalam R2 mengakibatkan
( ) ( )[ ] 012
~ 12 ≥∫ φ−φ∩ xxx dRR . Sehingga, 0~≥− II . Jika ( ) ( ) ( )xx 111 1|2 fpC=φ dan
( ) ( ) ( )xx 222 2|1 fpC=φ , maka persamaan (17) bernilai minimum untuk II ~≥ apabila memilih R1
dimana x memenuhi pertidaksamaan berikut
( ) ( ) ( ) ( )[ ] 01221 1121 ≤− xx fp|Cfp|C ( )( )
( )( ) ⎟⎟
⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛≥⇔
1
2
2
1
1|22|1
pp
CC
ff
xx
untuk R2 = R1* komplemen dari R1 apabila x memenuhi pertidaksamaan berikut ( ) ( ) ( ) ( )[ ] 01221 1121 >− xx fp|Cfp|C
( )( )
( )( ) ⎟⎟
⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛<⇔
1
2
2
1
1|22|1
pp
CC
ff
xx
Terbukti.ٱ Dari kedua persamaan diatas (18) dan (19) dapat diperoleh ECM untuk beberapa kasus khusus. Untuk p2/p1 = 1 (nilai peluang sama)
( )( )
( )( )
( )( )
( )( )12
211221
2
12
2
11 |C
|Cff
:R|C|C
ff
:R <≥xx
x x
Untuk C(1|2)/C(2|1) = 1 (biaya akibat kesalahan pengelompokan sama)
( )( )
( )( ) 1
2
2
12
1
2
2
11 p
pff
:Rpp
ff
:R <≥xx
xx
Untuk p2/p1 = C(1|2)/C(2|1) =1 atau p2/p1 = 1/(C(1|2)/C(2|1)) (nilai peluang sama dan biaya akibat kesalahan pengelompokan sama)
( )( )
( )( ) 11
2
12
2
11 <≥
xx
xx
ff
:Rff
:R
Jika x0 sebagai objek baru yang ingin dikelompokkan sedangkan nilai peluang dan biaya akibat kesalahan tidak diketahui maka x0 dikelompokkan ke Π1, jika ( ) ( ) 121 ≥00 xx f/f ⇔ ( ) ( )00 xx 21 ff ≥ x0 dikelompokkan ke Π2, jika
( ) ( ) 121 <00 xx f/f ⇔ ( ) ( )00 xx 21 ff <
Kasus kelompok normal dan nilai 1µ , 2µ , dan Σ = Σ1 = Σ2 diketahui
Misalkan fg(x) fungsi kepekatan normal dengan vektor rataan gµ dan matriks kovarian Σ dimana g = 1, 2. Maka fungsi kepekatan normal bersama, dimana Πg ~ Nk( gµ ,Σ) adalah

( )( )
( ) ( )⎥⎦⎤
⎢⎣⎡ −−−
π= −
iikgf µxΣµxΣ
x 12/12/
'21exp
2
1 (20)
Dari persamaan (20), jika 1µ , 2µ dan Σ = Σ1 = Σ2 nilainya sudah diketahui. Maka, hasil
substitusi terhadap persamaan (18) dan (19) akan diperoleh persamaan ECM sebagai berikut :
( ) ( ) ( ) ( ) ( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛≥⎥⎦
⎤−−+⎢⎣⎡ −−− −−
1
22
121
111 1|2
)2|1('21'
21exp:
pp
CCR µxΣµxµxΣµx (21)
( ) ( ) ( ) ( ) ( ) ⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛<⎥⎦
⎤−−−+⎢⎣⎡ −−−−
12
1|2)2|1(
21'22
11
1'121exp:2 p
pCCR µxΣµxµxΣµx (22)
Sehingga, x0 sebagai objek baru dialokasikan ke Π1 jika
( ) ( ) ( ) ( )( ) ⎥
⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛≥+−−− −−
1
221
1210
121 1|2
2|1ln'21'
pp
CCµµΣµµxΣµµ (23)
x0 dialokasikan ke Π2 jika selainnya.
( ) ( ) ( ) ( ) ( ) ( ) ( )211
211
2121
211
1 '21''
21'
21 µµΣµµxΣµµµxΣµxµxΣµx +−−−=−−+−−− −−−− (24)
Bukti persamaan (24):
( ) ( ) ( ) ( )21
211
1 21
21 µxΣµxµxΣµx −−+−−− −− ''
( )( )[ ( )( )]21
21
11
11
21 µxΣµΣxµxΣµΣx −−−−−−= −−−− '' ''
[ ]21'
21'
2211
11'
1111'
11 ''''
21 µΣµxΣµµΣxxΣxµΣµµΣxxΣµxΣx −−−−−−−− −++−+−−−=
( ) ( )[ ]( ) ( ) ( )21
121
121
211
21211'
1
'21'
''2221
µµΣµµxΣµµ
µµΣµµµΣxxΣµ
+−−−=
+−−−=
−−
−−−
Terbukti.ٱ Kasus kelompok normal dan nilai 1µ , 2µ , dan Σ = Σ1 = Σ2 belum diketahui
Misalkan X= [X1, X2, ...., Xk ]' vektor acak, jumlah objek pada Π1 sebanyak n1 dan jumlah objek pada Π2 sebanyak n2, dengan n1+ n2 – 2 ≥ k. Dan jika dari persamaan (21) dan (22)
1µ , 2µ dan Σ1 , Σ2 nilainya belum diketahui. Matriks data adalah
( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
′
′′
=×
11
12
11
1
x
xx
X
n
Mkn1
(25)
( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
′
′′
=×
22
22
21
2
x
xx
X
n
Mkn2
(26)
dimana: X1 = matriks yang berisi nilai objek untuk kelompok pertama (Π1) X2 = matriks yang berisi nilai objek untuk kelompok kedua (Π2)
'1 1
x n = vektor yang berisi nilai objek ke-n1 pada kelompok 1
'2 2
x n = vektor yang berisi nilai objek ke-n2 pada kelompok 2 Dari matriks data, rataan dan mariks kovarian dihitung dengan rumus
( )∑=×
=1
11
11
1 n
ii
k nxx1 (27)
( )( )( )∑
=×−−
−=
1
111
1 11 n
iii
kk'
n 111 xxxxΣ (28)
( )∑=×
=2
12
21
1 n
ii
k nxx2 (29)
( )( )( )∑
=×−−
−=
2
122
2 11 n
iii
kk'
n 222 xxxxΣ (30)
dimana: 1x = vektor yang terdiri dari nilai rataan
variabel Π1

2x = vektor yang terdiri dari nilai rataan variabel Π2 Σ1 = matriks kovarian Π1 Σ2 = matriks kovarian Π2 Dengan asumsi yang sama dimana Σ = Σ1 = Σ2, matriks kovarian Σgabungan adalah gabungan matriks kovarian Σ1 dan Σ2,
( ) ( )
( ) ( ) 2
1
Σ
ΣΣ
⎥⎦
⎤⎢⎣
⎡−+−
−
+⎥⎦
⎤⎢⎣
⎡−+−
−=
111
111
21
2
21
1gabungan
nnn
nnn
(31)
Substitusi 1x untuk 1µ , 2x untuk 2µ , gabunganΣ untuk Σ ke dalam persamaan (23), x0 sebagai objek baru dialokasikan ke Π1 jika ( )
( ) ( )
( )( ) ⎥
⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛≥
+−
−−
−
−
1
2
211
gabungan21
01
gabungan21
1|22|1ln
'21
'
pp
CC
xxΣxx
xΣxx
(32)
x0 dialokasikan ke Π2 jika selainnya.
Jika ( )( ) 1
1|22|1
1
2 =⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛pp
CC ,maka persamaan
(32) menjadi
( )
( ) ( ) 0'21
'
211
gabungan21
01
gabungan21
≥+−
−−
−
−
xxΣxx
xΣxx (33)
Misalkan dari persamaan (32) didefinisikan nilai diskriminan objek sebagai berikut
( ) x'axΣxx 21 ˆ'y =−= −1gabungan (34)
Maka selanjutnya x0 dievaluasi dengan nilai tengah antara nilai diskriminan Π1 dan Π2,
( ) ( )2121 xxΣxx +−= −1gabungan2
1 'm
( )21 yy +=21 (35)
dimana: ( ) 1x'axΣxx ˆ'y =−= −
11
gabungan211
( ) 2221 x'axΣxx ˆ'y =−= −1gabungan2
1y = nilai diskriminan untuk kelompok pertama
2y = nilai diskriminan untuk kelompok kedua
Aturan minimum ECM untuk dua kelompok normal, yaitu alokasikan x0 ke Π1 jika mˆy ≥= x'a0 , dan x0 dialokasikan ke Π2 jika mˆy <= x'a0 .
Tabel 2 Upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan ekonomi (LPE) 14 kabupaten/kota di Jawa Barat pada tahun 2002.
i Kota/Kabupaten UMK % Tingkat Pengangguran LPE 1 Kab. Sukabumi Rp281.000 6,15 3,78 2 Kab. Cianjur Rp310.000 7,29 3,23 3 Kab. Bandung Rp470.500 12,49 5,16 4 Kab. Garut Rp385.000 6,82 3,89 5 Kab. Tasikmalaya Rp290.000 7,99 2,36 6 Kab. Ciamis Rp283.500 4,53 3,32 7 Kab. Kuningan Rp281.000 8,24 2,8 8 Kab. Cirebon Rp487.827 11,87 4,83 9 Kab. Majalengka Rp315.000 6,25 4,34 10 Kab. Subang Rp350.000 4,33 4,11 11 Kab. Karawang Rp530.015 13,02 6,04 12 Kab. Bekasi Rp575.000 12,81 5,58 13 Kota Bogor Rp576.169 9,88 4,73 14 Kota Bandung Rp471.000 10,06 5,41 Rataan Rp400429,3571 8,6950 4,2557 Standar Deviasi Rp113791,6172 3,0184 1,0979
Sumber: Badan Pusat Statistik Propinsi Jawa Barat, 2003.

Contoh Kasus
Tabel 2 menyajikan data 14 kabupaten/kota di Jawa Barat yang terdiri dari tiga variabel bebas, yaitu upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan ekonomi (LPE) masing-masing kabupaten/kota. Tujuan yang ingin diperoleh adalah mengelompokkan keempatbelas kabupaten/kota kedalam dua kelompok sehingga dapat dibedakan kelompok dengan tingkat sosial ekonomi menengah ke bawah dan menengah ke atas diukur berdasarkan ketiga variabel bebas tersebut. Analisis Cluster Diketahui: n =14 objek
k = 3 variabel bebas Misalkan: x1 = upah minimum kabupaten/kota (Rupiah) x2 = tingkat pengangguran (persen) x3 = laju pertumbuhan ekonomi
Tahap kedua, standarisasi data dapat dilihat pada Lampiran 1.1.
Nilai z UMK Kabupaten Sukabumi:
0495,16172,113791
3571,400429281000
1
11111 −=
−=
−=
Sxx
z
Nilai z tingkat pengangguran Kabupaten Sukabumi:
8432,00184,3
6950,815,6
2
21212 −=
−=
−=
Sxx
z
Nilai z LPE Sukabumi:
4333,00979,1
2557,478,3
3
31313 −=
−=
−=
Sxx
z
Tahap ketiga, asumsi bahwa contoh yang
diambil mewakili populasi yang ada, dan korelasi antara variabel bebas tidak besar.
Tahap keempat, membuat matriks jarak antar objek (Lampiran 1.2). Jarak antara Kabupaten Sukabumi dengan Kabupaten Cianjur sebesar 0,677 merupakan hasil perhitungan sebagai berikut:
2
23132
22122
211112 zzzzzzd −+−+−=
677,0
29342,04333,024655,08432,027947,00495,112
=
+−++−++−=d
Pada matriks kesamaan, jarak terkecil antar objek sebesar 0,395 yaitu jarak antara Kabupaten Bandung dengan Kabupaten Cirebon. mindij= d38 = dA = 0,395 Berikutnya membentuk matriks baru dengan menghilangkan baris dan kolom Kabupaten Bandung dan Kabupaten Cirebon, kemudian menambah baris dan kolom baru yang terdiri dari elemen jarak antara Kabupaten Bandung dan Kabupaten Cirebon dengan kabupaten/kota lainnya dengan menggunakan rumus jarak single linkage clustering. Sehingga terbentuk matriks berukuran 13× 13. Tahap agglomeratif dapat dilihat pada Lampiran 1.3 dan dendogram pada Lampiran 1.5, sedangkan Lampiran 1.6 memperlihatkan diagram pencar data.
Pada langkah kesepuluh agglomeratif Kabupaten Bandung dan Kabupaten Cirebon dikelompokkan dengan Kota Bandung, seperti pada Lampiran 1.3 dengan koefisien jaraknya antara lain,
( ) ( ) ( ) ( ) ( )14814314814314 21
21
21 ddddd A −−+=
( ) ( ) ( )813,0
813,0837,021813,0
21837,0
21
14
=
−−+=Ad
Cara kedua:
( ) ( ) 813,0
;0,8130,837min,min 1481431
=
== ddd A
Hasil pengelompokan dapat dilihat pada Lampiran 1.4. Diperoleh hasil pengelompokan kabupaten/kota ke dalam dua kelompok , kelompok pertama terdiri dari, Kab.Sukabumi, Kab.Cianjur, Kab.Garut, Kab.Tasikmalaya, Kab.Ciamis, Kab.Kuningan, Kab.Majalengka, dan Kab.Subang. Kelompok kedua terdiri dari Kab.Bandung, Kab.Cirebon, Kab.Karawang, Kab.Bekasi, Kota Bogor dan Kota Bandung.
Tahap kelima, UMK dan LPE setiap kabupaten/kota pada kelompok pertama seperti pada Tabel 2 berada di bawah rata-rata keempatbelas kabupaten/kota, kecuali tingkat pengangguran. Kelompok pertama dapat dikatakan kelompok dengan tingkat sosial ekonomi menengah ke bawah. Sedangkan untuk kelompok kedua sebaliknya.
Tahap keenam, profiling, menguji kevalidan pengelompokan, dan mengetahui hubungan antara UMK, tingkat pengangguran, dan LPE dengan tingkat sosial ekonomi suatu kabupaten/kota menengah ke atas atau menengah ke bawah dilakukan melalui analisis diskriminan. Analisis Diskriminan Misalkan, terdapat tiga kabupaten sebagai objek baru yang ingin dievaluasi, yaitu Kab. Sumedang yang diduga termasuk ke dalam kelompok pertama, sedangkan Kab. Bogor, dan Kab. Purwakarta diduga termasuk kelompok kedua. Tabel 3 menampilkan data ketiga kabupaten tersebut. Standarisasi untuk data yang telah ditambahkan objek baru dapat dilihat pada Lampiran 2.1.
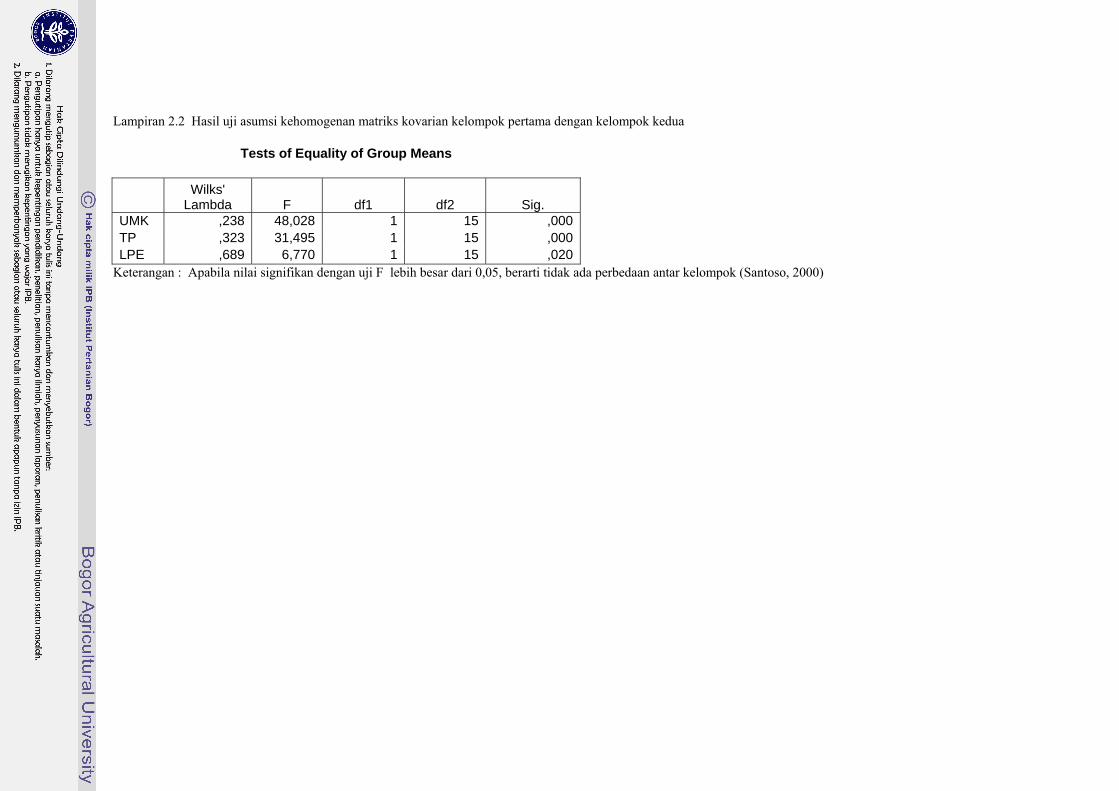
Hasil uji beda rataan dapat dilihat pada Lampiran 2.2, menunjukkan bahwa terdapat
perbedaan antara kelompok pertama dengan kelompok kedua. Besar kecilnya UMK, tingkat pengangguran, dan LPE mempengaruhi tingkat sosial ekonomi suatu kabupaten/kota. Pada Lampiran 2.2 ditunjukkan pula nilai F untuk ketiga variabel. UMK memiliki nilai F paling besar sehingga dapat dikatakan bahwa variabel ini paling besar mempengaruhi tingkat sosial ekonomi masyarakat suatu kabupaten/kota dibandingkan dengan pengaruh tingkat pengangguran. Sementara LPE pengaruhnya paling kecil.
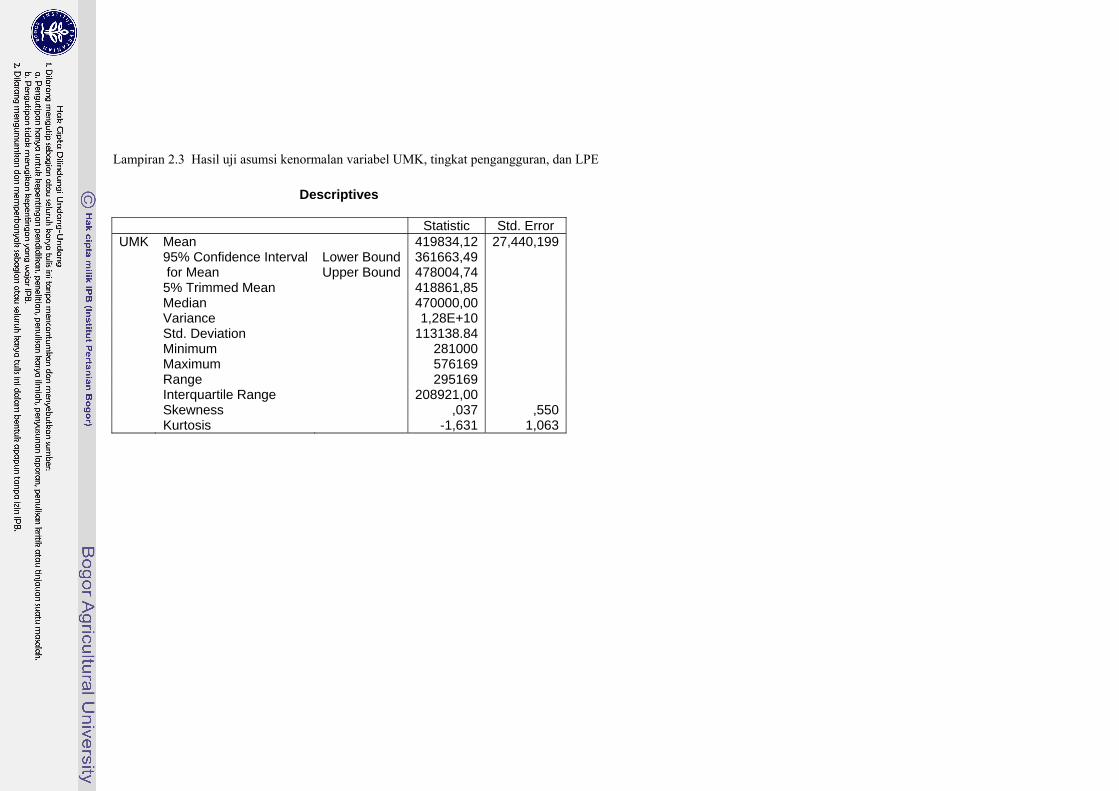
Pada Lampiran 2.3 diperoleh bahwa data berdistribusi normal dengan melihat rasio skewness dan kurtosis diantara 2 dan -2. Lampiran 2.4 matriks kovarian kelompok cenderung homogen.
Tabel 3 Upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju
pertumbuhan ekonomi (LPE) Kab. Sumedang, Kab. Bogor, dan Kab. Purwakarta pada tahun 2002.
i Kota/Kabupaten UMK % Tingkat Pengangguran LPE 1 Kab. Sumedang Rp470.000 9,25 4,08 2 Kab. Bogor Rp576.169 9,69 2,93 3 Kab. Purwakarta Rp485.000 9,29 3,02
Sumber: Badan Pusat Statistik Propinsi Jawa Barat, 2003.
Apabila asumsi telah terpenuhi, maka dapat dicari fungsi diskriminan. Dengan asumsi lain
bahwa: ( )( ) 1
1|22|1
1
2 =⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛pp
CC
Diketahui : n1 = 9, n2 = 8 Vektor rataan kelompok pertama dan kelompok kedua,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
=5101,07528,07984,0
1x ,⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
5738,08469,08982,0
2x
Matriks kovarian kelompok pertama,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−=
3797,01054,11664,01054,13622,01120,0
1664,01120,03146,0
1Σ
Matriks kovarian kelompok kedua,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−
−−=
1410,14062,00400,04062,07951,00057,00400,00057,01845,0
2Σ
Matriks kovarian gabungan ,
21gabungan 157
158 ΣΣΣ +=
Invers matriks kovarian gabungan,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−−
=−
4482,13089,03302,03089,08795,13374,03302,03374,01063,4
1gabunganΣ
Fungsi diskriminan adalah [ ] xΣxxxa 1
gabungan21−−== ''ˆy
[ ]⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−−
=
3
2
1
4482,13089,03302,03089,08795,13374,03302,03374,01063,4
0893,15997,16967,1xxx
321 5153,00993,20694,6 xxx ++=
Nilai diskriminan kelompok pertama,
[ ] 5253,75101,07528,07984,0
0893,15997,16967,1'ˆ 11 =⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
== xay
Nilai diskriminan kelompok kedua,
[ ] 6891,65738,08469,08982,0
0893,15997,16967,1x'a 22 −=⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡==y
Nilai tengah antara 1y dan 2y ,
( ) ( ) 4181,06891,65253,721yy
21ˆ 21 =−=+=m
Selanjutnya evaluasi objek dengan
menghitung nilai diskriminan, y dari masing-masing kabupaten/kota, Tabel 4 berikut menampilkan hasil perhitungan nilai y untuk masing-masing kabupaten/kota. Dari Tabel 4 dapat diperkirakan terdapat satu misklasifikasi kabupaten/kota, Kab. Sumedang mempunyai nilai y > m = 0,4181 maka seharusnya kabupaten ini dikelompokkan ke kelompok kedua.
Ketepatan pengklasifikasian dari fungsi diskriminan yang diperoleh adalah
%12,94%10017
88=×
+
Maka, hasil pengelompokan dapat dikatakan valid dengan fungsi diskriminan berikut,
321 5153,00993,20694,6ˆ xxxy ++= . Begitu pula hasil pengelompokan melalui
analisis cluster valid karena setiap anggota tepat dikelompokkan sebagai kelompoknya. Berdasarkan Tabel 4 diperoleh bahwa dari ketujuhbelas kabupaten/kota di Jawa Barat 47,06% berada pada tingkat sosial ekonomi menengah ke bawah.
Tabel 4 Nilai diskriminan masing-masing
kabupaten/kota. Kabupaten/Kota y
Kelompok 1 Kab.Sukabumi -9,6476 Kab.Cianjur -7,4806 Kab.Garut -3,5019 Kab.Tasikmalaya -8,4329 Kab.Ciamis -10,9765 Kab.Kuningan -8,5133 Kab.Majalengka -7,4789 Kab.Subang -7,1843 Kab. Sumedang* 3,0131 Kelompok 2 Kab.Bandung 6,0423 Kab.Cirebon 6,3383 Kab.Karawang 10,0629 Kab.Bekasi 12,0948 Kota Bogor 9,5030 Kota Bandung 4,3247 Kab. Bogor 8,4957 Kab. Purwakarta 3,3411
SIMPULAN
Secara umum, analisis cluster
mengelompokkan objek-objek yang memiliki kemiripan, dan setiap anggota kelompok akan berbeda dengan anggota kelompok yang lain. Salah satu cara mengukur tingkat kemiripannya yaitu dengan menghitung jarak antar objek dengan jarak euclid.
Metode agglomeratif akan mengelompokkan dua atau lebih kelompok dari yang memiliki kesamaan terdekat secara bertingkat sampai akhirnya diperoleh hanya satu kelompok. Setiap tahap algoritma agglomeratif jarak antar kelompok akan
semakin membesar. Semakin besar jarak antar kelompok menunjukkan semakin jauh tingkat kesamaan antar kelompok tersebut. Penentuan objek yang akan dikelompokkan sangat bergantung pada pendefinisian jarak antar kelompok. Single linkage clustering merupakan teknik agglomeratif yang paling sederhana untuk menentukan jarak antar kelompok dimana jarak antar kelompok sama dengan jarak terpendek antara anggota kelompok yang satu dengan anggota kelompok lainnya.

Analisis diskriminan dapat digunakan untuk menguji kevalidan hasil analisis cluster karena hasil dapat berbeda berdasarkan metode yang dipilih pada analisis tersebut. Uji kevalidan dilakukan setelah menemukan fungsi diskriminan. Apabila fungsi kepekatan untuk kedua kelompok diketahui maka fungsi diskriminan dapat diperoleh melalui proses meminimumkan nilai expected cost of misclassification (ECM).
Dari hasil analisis diskriminan, pengelompokan tujuh belas kabupaten/kota di Jawa Barat berdasarkan tiga indikator sosial ekonomi pada tahun 2002, yaitu upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan
ekonomi ke dalam dua kelompok diperoleh fungsi 321 5153,00993,20694,6 xxxy ++= . Ketepatan pengklasifikasian kasus fungsi adalah sebesar 94,12%. Maka, fungsi ini dapat dianggap valid untuk mengelompokkan sebuah kabupaten/kota berdasarkan ketiga indikator tersebut ke dalam kelompok dengan tingkat sosial ekonomi menengah ke bawah atau menengah ke atas. Dengan membandingkan hasil pengelompokan analisis cluster dengan analisis diskriminan, hasil yang diperoleh melalui analisis cluster dapat dikatakan sudah tepat.
DAFTAR PUSTAKA
Badan Pusat Statistik Propinsi Jawa Barat.
2003. Indikator Sosial Ekonomi Masyarakat Jawa Barat Tahun 2002. Bandung: BPS.
Hair JF, Anderson RE, Tatham RL &
Black WC. 1998. Multivariate Data Analysis with Reading. Edisi ke-5. New Jersey: Prentice-Hall International.
Härdle, Wolfgang & Simar L. 2003. Applied
Multivariate Statistical Analysis. Berlin: Springer-Verlag.
Hogg RV & Craigg AT. 1995. Introduction
to Mathematical Statistics. Edisi ke-5. New Jersey: Prentice Hall.
Johnson RA & Dean WW. 1998. Applied
Multivariate Stastistical Analysis. Edisi ke-4. Canada: Prentice-Hall Internasional.
Johnston RJ. 1976. Classification in
Geography. Concepts and Techniques in Modern Geography No. 6.
Karson MJ. 1983. Multivariate Statistical
Method. Edisi ke-1. The Lowa State University Press.
Mardia KV, Kent JT & Bibby JM. 1989. Multivariate Analysis. London: Academic Press.
Moore DS. 1994. The Basic Practice of Statistics. New York: W. H. Freeman and Company.
Santoso S. 2000. Buku Latihan SPSS Statistik
Parametrik. Jakarta: Elex Media Komputindo.
Santoso S. 2002. Buku Latihan SPSS Statistik
Multivariat. Jakarta: Elex Media Komputindo.
Srivastava MS. 2002. Methods of
Multivariate Statistics. Canada: A. John Wiley & Sons, Inc.
Stewart J. 2001. Kalkulus. Edisi ke-4.
Jakarta: Erlangga. Sudjana. 1996. Metoda Statistika. Edisi ke-6.
Bandung: Tarsito. Walpole RE. 1995. Pengantar Statistika.
Edisi ke-3. Jakarta: Gramedia Pustaka Utama.
Lampiran 1 Analisis Cluster Lampiran 1.1 Nilai standarisasi upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan ekonomi (LPE) pada tahun 2002
i Kabupaten/Kota z_UMK z_Tingkat Pengangguran z_LPE 1 Kab. Sukabumi -1,0495 -0,8432 -0,4333 2 Kab. Cianjur -0,7947 -0,4655 -0,9342 3 Kab. Bandung 0,6158 1,2573 0,8236 4 Kab. Garut -0,1356 -0,6212 -0,3331 5 Kab. Tasikmalaya -0,9705 -0,2336 -1,7266 6 Kab. Ciamis -1,0276 -1,3799 -0,8523 7 Kab. Kuningan -1,0495 -0,1507 -1,3259 8 Kab. Cirebon 0,7681 1,0519 0,5231 9 Kab. Majalengka -0,7508 -0,8100 0,0768
10 Kab. Subang -0,4432 -1,4461 -0,1327 11 Kab. Karawang 1,1388 1,4329 1,6251 12 Kab. Bekasi 1,5341 1,3633 1,2062 13 Kota Bogor 1,5444 0,3926 0,4320 14 Kota Bandung 0,6202 0,4522 1,0513
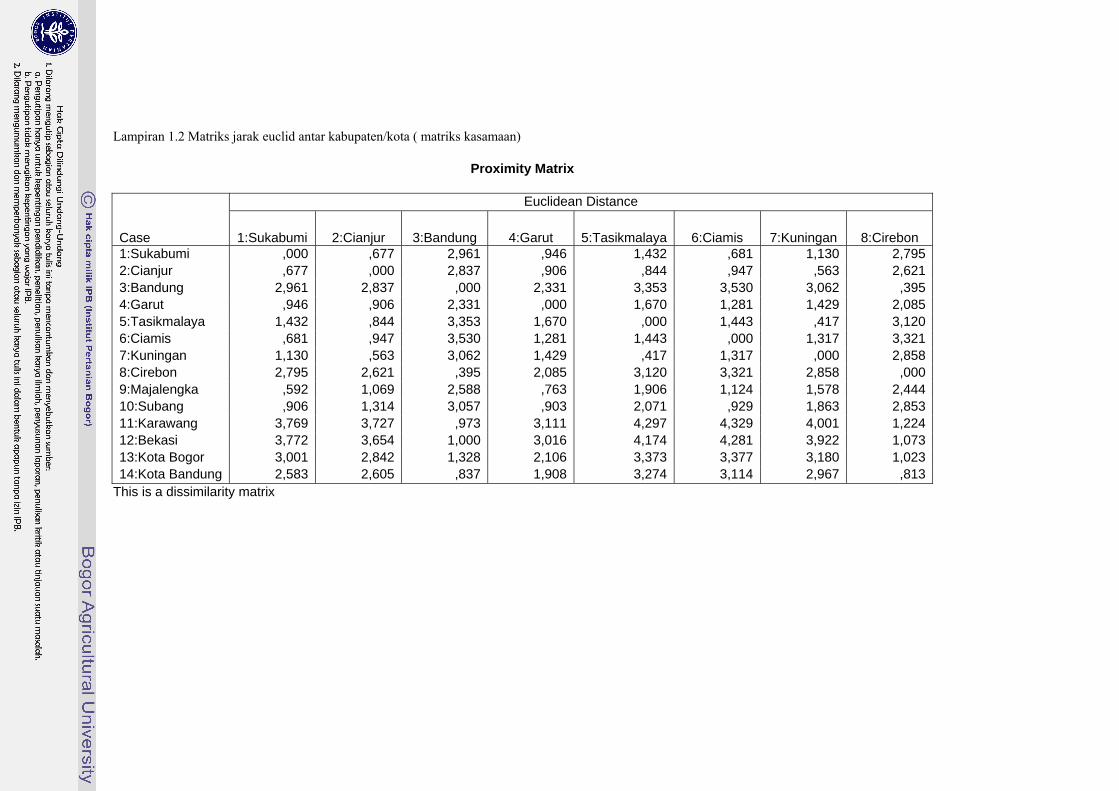
Lampiran 1.2 Matriks jarak euclid antar kabupaten/kota ( matriks kasamaan)
Proximity Matrix
Euclidean Distance
Case 1:Sukabumi 2:Cianjur 3:Bandung 4:Garut 5:Tasikmalaya 6:Ciamis 7:Kuningan 8:Cirebon 1:Sukabumi ,000 ,677 2,961 ,946 1,432 ,681 1,130 2,7952:Cianjur ,677 ,000 2,837 ,906 ,844 ,947 ,563 2,6213:Bandung 2,961 2,837 ,000 2,331 3,353 3,530 3,062 ,3954:Garut ,946 ,906 2,331 ,000 1,670 1,281 1,429 2,0855:Tasikmalaya 1,432 ,844 3,353 1,670 ,000 1,443 ,417 3,1206:Ciamis ,681 ,947 3,530 1,281 1,443 ,000 1,317 3,3217:Kuningan 1,130 ,563 3,062 1,429 ,417 1,317 ,000 2,8588:Cirebon 2,795 2,621 ,395 2,085 3,120 3,321 2,858 ,0009:Majalengka ,592 1,069 2,588 ,763 1,906 1,124 1,578 2,44410:Subang ,906 1,314 3,057 ,903 2,071 ,929 1,863 2,85311:Karawang 3,769 3,727 ,973 3,111 4,297 4,329 4,001 1,22412:Bekasi 3,772 3,654 1,000 3,016 4,174 4,281 3,922 1,07313:Kota Bogor 3,001 2,842 1,328 2,106 3,373 3,377 3,180 1,02314:Kota Bandung 2,583 2,605 ,837 1,908 3,274 3,114 2,967 ,813
This is a dissimilarity matrix
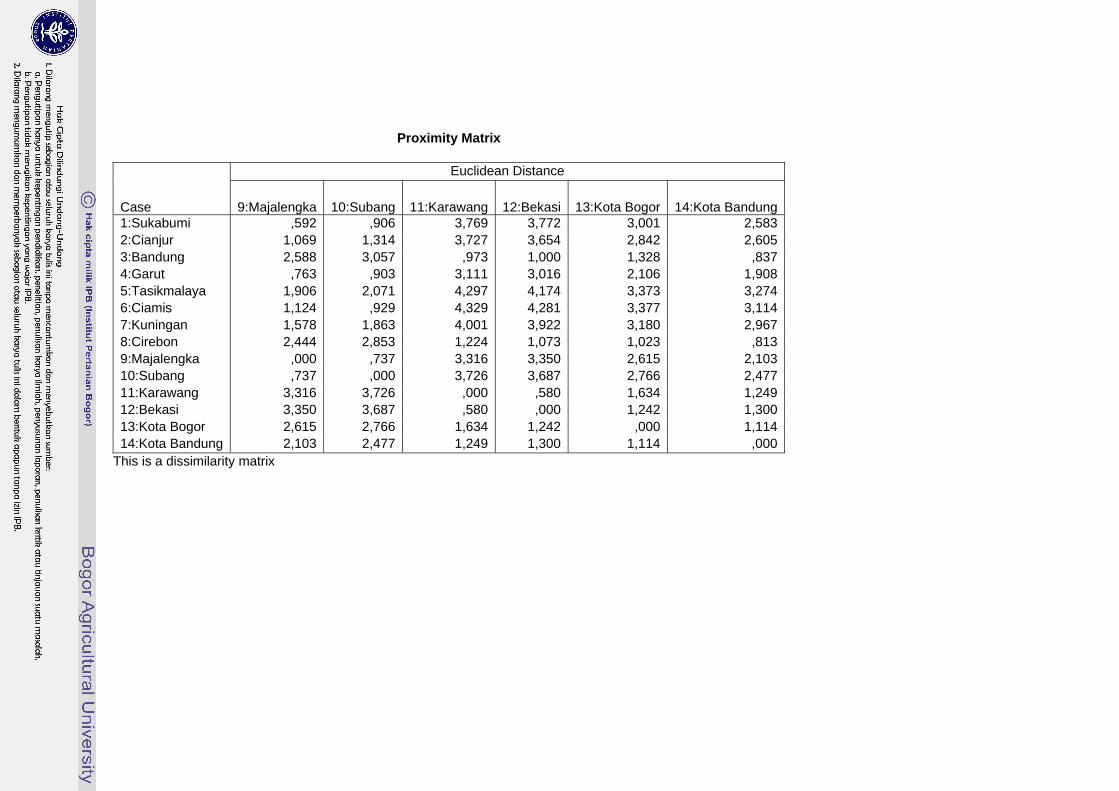
Proximity Matrix
Euclidean Distance
Case 9:Majalengka 10:Subang 11:Karawang 12:Bekasi 13:Kota Bogor 14:Kota Bandung1:Sukabumi ,592 ,906 3,769 3,772 3,001 2,5832:Cianjur 1,069 1,314 3,727 3,654 2,842 2,6053:Bandung 2,588 3,057 ,973 1,000 1,328 ,8374:Garut ,763 ,903 3,111 3,016 2,106 1,9085:Tasikmalaya 1,906 2,071 4,297 4,174 3,373 3,2746:Ciamis 1,124 ,929 4,329 4,281 3,377 3,1147:Kuningan 1,578 1,863 4,001 3,922 3,180 2,9678:Cirebon 2,444 2,853 1,224 1,073 1,023 ,8139:Majalengka ,000 ,737 3,316 3,350 2,615 2,10310:Subang ,737 ,000 3,726 3,687 2,766 2,47711:Karawang 3,316 3,726 ,000 ,580 1,634 1,24912:Bekasi 3,350 3,687 ,580 ,000 1,242 1,30013:Kota Bogor 2,615 2,766 1,634 1,242 ,000 1,11414:Kota Bandung 2,103 2,477 1,249 1,300 1,114 ,000
This is a dissimilarity matrix
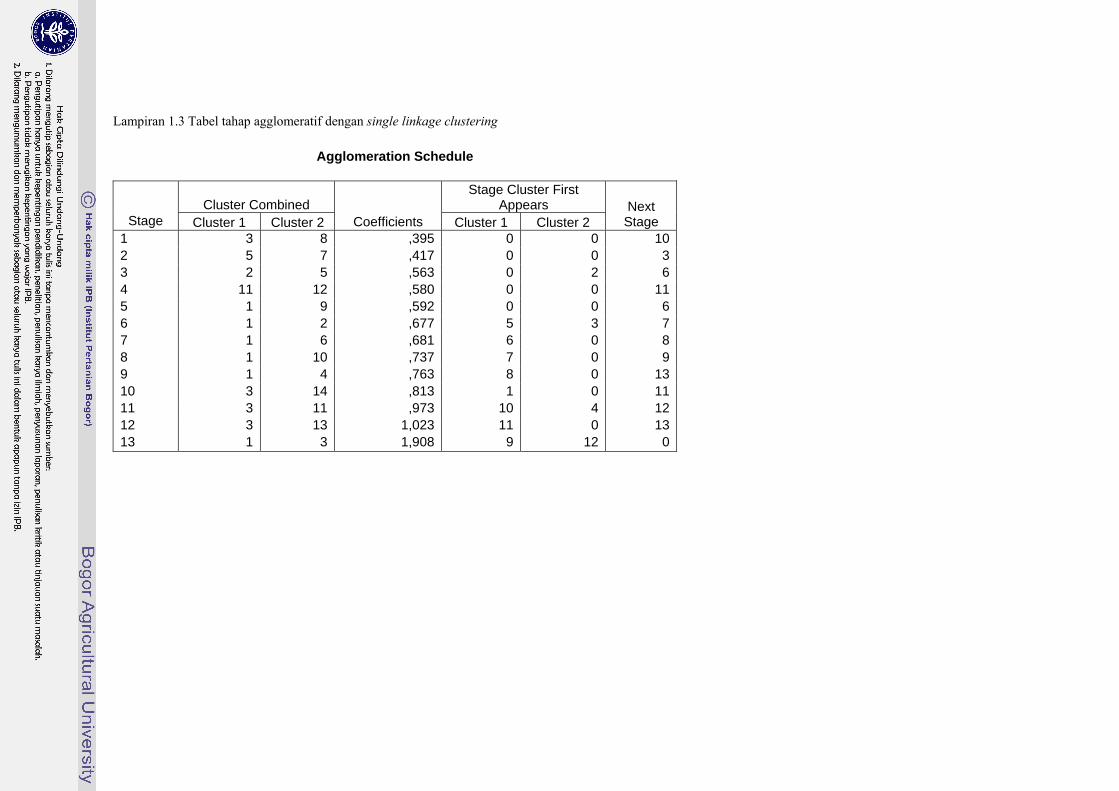
Lampiran 1.3 Tabel tahap agglomeratif dengan single linkage clustering
Agglomeration Schedule
Cluster Combined
Stage Cluster First Appears
Stage Cluster 1 Cluster 2 Coefficients Cluster 1 Cluster 2 Next
Stage 1 3 8 ,395 0 0 102 5 7 ,417 0 0 33 2 5 ,563 0 2 64 11 12 ,580 0 0 115 1 9 ,592 0 0 66 1 2 ,677 5 3 77 1 6 ,681 6 0 88 1 10 ,737 7 0 99 1 4 ,763 8 0 1310 3 14 ,813 1 0 1111 3 11 ,973 10 4 1212 3 13 1,023 11 0 1313 1 3 1,908 9 12 0
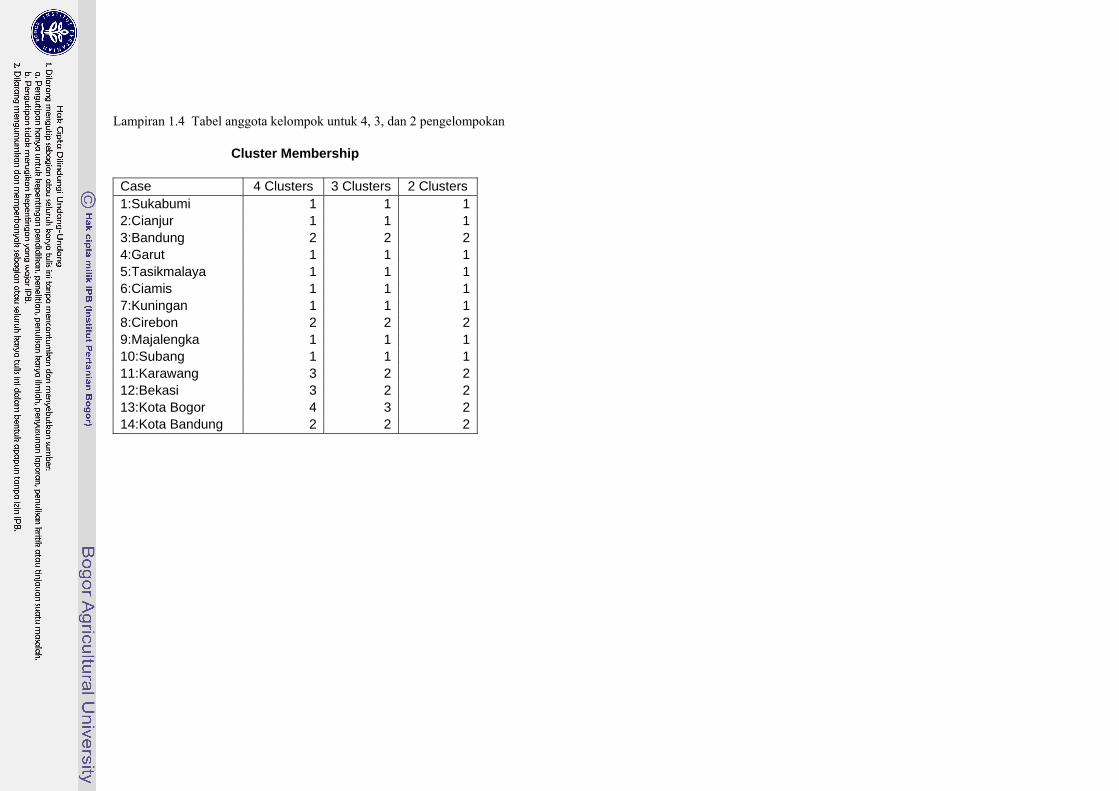
Lampiran 1.4 Tabel anggota kelompok untuk 4, 3, dan 2 pengelompokan
Cluster Membership
Case 4 Clusters 3 Clusters 2 Clusters 1:Sukabumi 1 1 12:Cianjur 1 1 13:Bandung 2 2 24:Garut 1 1 15:Tasikmalaya 1 1 16:Ciamis 1 1 17:Kuningan 1 1 18:Cirebon 2 2 29:Majalengka 1 1 110:Subang 1 1 111:Karawang 3 2 212:Bekasi 3 2 213:Kota Bogor 4 3 214:Kota Bandung 2 2 2
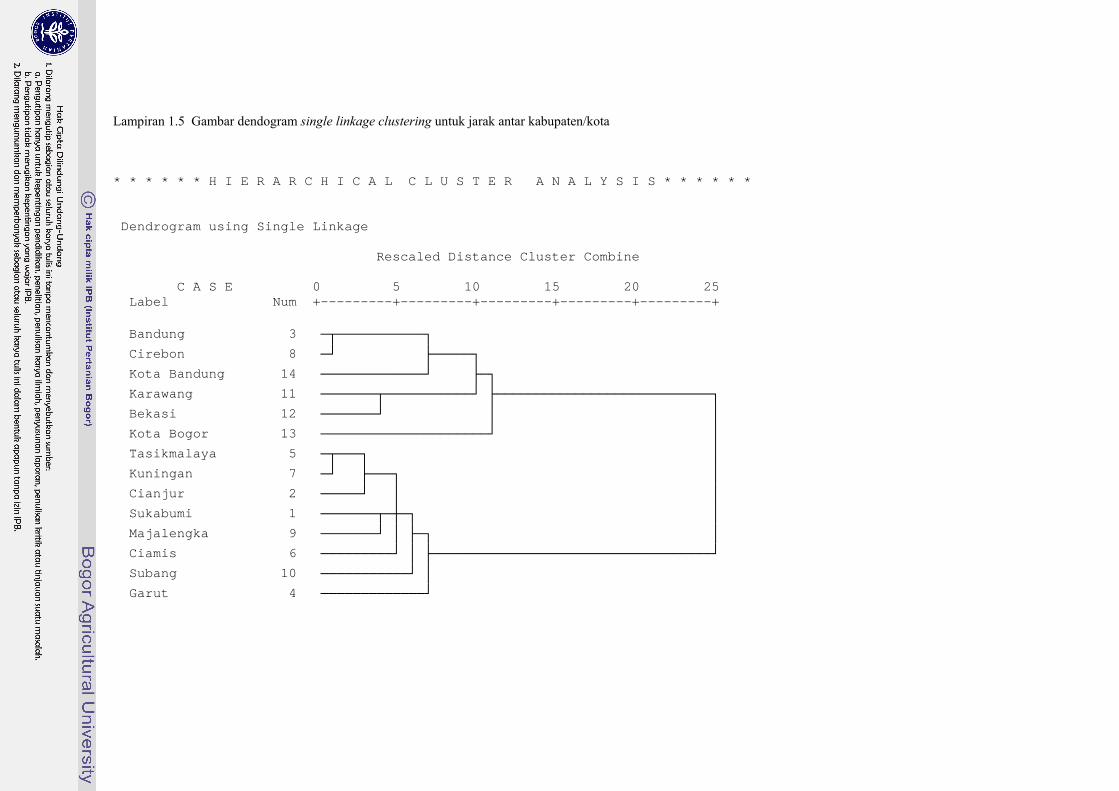
Lampiran 1.5 Gambar dendogram single linkage clustering untuk jarak antar kabupaten/kota * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * Dendrogram using Single Linkage Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ Bandung 3 òûòòòòòòòòòòòø Cirebon 8 ò÷ ùòòòòòø Kota Bandung 14 òòòòòòòòòòòòò÷ ùòø Karawang 11 òòòòòòòûòòòòòòòòòòò÷ ùòòòòòòòòòòòòòòòòòòòòòòòòòòòø Bekasi 12 òòòòòòò÷ ó ó Kota Bogor 13 òòòòòòòòòòòòòòòòòòòòò÷ ó Tasikmalaya 5 òûòòòø ó Kuningan 7 ò÷ ùòòòø ó Cianjur 2 òòòòò÷ ó ó Sukabumi 1 òòòòòòòûòôòø ó Majalengka 9 òòòòòòò÷ ó ùòø ó Ciamis 6 òòòòòòòòò÷ ó ùòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòò÷ Subang 10 òòòòòòòòòòò÷ ó Garut 4 òòòòòòòòòòòòò÷

Lampiran 1.6 Diagram pencar UMK, tingkat pengangguran, dan LPE
714
300000
12
400000
6
500000
10
600000
5
TP LPE8 46 34

Lampiran 2 Analisis Diskriminan Lampiran 2.1 Nilai standarisasi upah minimum kabupaten/kota (UMK), persentase tingkat pengangguran, dan laju pertumbuhan ekonomi (LPE) kelompok pertama dan kelompok kedua
Kabupaten/Kota z_UMK z_Tingkat Pengangguran z_LPE Kelompok dengan tingkat sosial ekonomi menengah ke bawah Kab. Sukabumi -1,22711 -0,97611 -0,29231 Kab. Cianjur -0,97079 -0,55953 -0,80317 Kab. Garut -0,30789 -0,73128 -0,19014 Kab. Tasikmalaya -1,14756 -0,30373 -1,61125 Kab. Ciamis -1,20502 -1,5681 -0,71957 Kab. Kuningan -1,22711 -0,21238 -1,20256 Kab. Majalengka -0,9266 -0,93957 0,22784 Kab. Subang -0,61724 -1,64118 0,01421 Kab. Sumedang* 0,4434 0,1567 -0,01366 Rataan -0,7984 -0,7528 -0,5101 Standar Deviasi 0,5609 0,6018 0,6162 Kelompok dengan tingkat sosial ekonomi menengah ke atas Kab. Bandung 0,44782 1,34067 0,98948 Kab. Cirebon 0,60097 1,11411 0,68296 Kab. Karawang 0,97386 1,53435 1,80685 Kab. Bekasi 1,37146 1,45761 1,37959 Kota Bogor 1,3818 0,38692 0,59008 Kota Bandung 0,45224 0,45269 1,22169 Kab. Bogor* 1,3818 0,31749 -1,08182 Kab. Purwakarta* 0,57598 0,17132 -0,99822 Rataan 0,8982 0,8469 0,5738 Standar Deviasi 0,4295 0,5688 1,0682
Lampiran 2.2 Hasil uji asumsi kehomogenan matriks kovarian kelompok pertama dengan kelompok kedua
Tests of Equality of Group Means
Wilks'
Lambda F df1 df2 Sig. UMK ,238 48,028 1 15 ,000TP ,323 31,495 1 15 ,000LPE ,689 6,770 1 15 ,020
Keterangan : Apabila nilai signifikan dengan uji F lebih besar dari 0,05, berarti tidak ada perbedaan antar kelompok (Santoso, 2000)
Lampiran 2.3 Hasil uji asumsi kenormalan variabel UMK, tingkat pengangguran, dan LPE
Descriptives
Statistic Std. Error UMK Mean 419834,12 27,440,199 95% Confidence Interval Lower Bound 361663,49 for Mean Upper Bound 478004,74 5% Trimmed Mean 418861,85 Median 470000,00 Variance 1,28E+10 Std. Deviation 113138.84 Minimum 281000 Maximum 576169 Range 295169 Interquartile Range 208921,00 Skewness ,037 ,550 Kurtosis -1,631 1,063

Descriptives Statistic Std. ErrorTP Mean 88,212 ,66371 95% Confidence Interval Lower Bound 74,142 for Mean Upper Bound 102,282 5% Trimmed Mean 88,374 Median 92,500 Variance 7,489 Std. Deviation 273,655 Minimum 4,33 Maximum 13,02 Range 8,69 Interquartile Range 44,300 Skewness ,004 ,550 Kurtosis -,899 1,063LPE Mean 40,947 ,26112 95% Confidence Interval Lower Bound 35,412 for Mean Upper Bound 46,483 5% Trimmed Mean 40,830 Median 40,800 Variance 1,159 Std. Deviation 107,662 Minimum 2,36 Maximum 6,04 Range 3,68 Interquartile Range 18,700 Skewness ,195 ,550 Kurtosis -,953 1,063
Keterangan : Data dikatakan berdistribusi normal apabila nilai rasio skewness dan nilai rasio kurtosis berada di antara nilai -2 dan 2. Rasio skewness adalah nilai skewness/standar error skewness. Rasio kurtosis adalah nilai kurtosis/standar error kurtosis (Santoso, 2000)

Lampiran 2.4 Hasil uji asumsi kehomogenan matriks kovarian kelompok pertama dengan kelompok kedua
Test Results Box's M 15,310 F Approx. 1,986 df1 6 df2 1,555,544 Sig. ,065
Tests null hypothesis of equal population covariance matrices. Keterangan : Matriks kovarian dikatakan homogen apabila nilai signifikan pada tabel diatas lebih besar dari 0,05 (Santoso, 2000)




















