1. SEM dan LISREL (Seri LISREL bag.1) » pengertian teknologi informasi, teknologi komunikasi,...
41
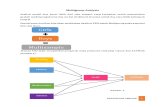
SEM dan LISREL (Seri LISREL bag.1) Tulisan kali ini merupakan pengantar untuk seri tulisan yang akan membahas mengenai aplikasi Program LISREL. Sebagai suatu pengantar, pada bagian ini akan diberikan konsep-konsep dasar yang berguna untuk mengikuti pembahasan pada tulisan berikutnya. 1. Konsep Stuctural Equation Modelling (SEM) Dalam penelitian, kita seringkali menganalisis hubungan atau pengaruh antar variabel. Tetapi, seringkali juga dalam penelitian (terutama dalam penelitian ilmu sosial) kita berhadapan dengan variabel yang tidak bisa diukur secara langsung (misalnya kinerja karyawan, kepribadian dan lainnya), dan memerlukan beberapa indikator untuk pengukurannya. Variabel yang tidak bisa diukur ini dinamakan dengan konstruk laten/variabel laten/variabel unobserved, sedangkan indikator sebagai variabel terukur dinamakan sebagai variabel manifest/variabel observed. Misalnya di bidang manajemen keuangan, kita ingin menganalisis pengaruh efektivitas penggunaan dana terhadap kinerja keuangan. Kedua variabel tersebut (efektivitas penggunaan dana dan kinerja keuangan) adalah variabel yang tidak terukur. Oleh karenanya kita membutuhkan indikator untuk merepresentasikan kedua variabel tersebut. Jika secara teori efektivitas penggunaan dana tercermin melalui nilai-nilai ARTO, ITO, WCTO, FATO dan TATA, sedangkan kinerja keuangan, tercermin melalui nilai-nilai ROA dan ROE, kita dapat menggambarkan diagram hubungan tersebut sebagai berikut: Keterangan: ARTO = penjualan/rata-rata piutang ITO = HPP/rata-rata persediaan WCTO = penjualan/rata-rata modal kerja FATO = penjualan/aktiva tetap TATA = penjualan/total aktiva ROA = penerimaan setelah pajak/total aktiva ROE = penerimaan setelah pajak/modal sendiri
Transcript of 1. SEM dan LISREL (Seri LISREL bag.1) » pengertian teknologi informasi, teknologi komunikasi,...

SEM dan LISREL (Seri LISREL bag.1)
Tulisan kali ini merupakan pengantar untuk seri tulisan yang akan membahas mengenai aplikasi Program LISREL. Sebagai suatu pengantar, pada bagian ini akan diberikan konsep-konsep dasar yang berguna untuk mengikuti pembahasan pada tulisan berikutnya.
1. Konsep Stuctural Equation Modelling (SEM)
Dalam penelitian, kita seringkali menganalisis hubungan atau pengaruh antar variabel. Tetapi, seringkali juga dalam penelitian (terutama dalam penelitian ilmu sosial) kita berhadapan dengan variabel yang tidak bisa diukur secara langsung (misalnya kinerja karyawan, kepribadian dan lainnya), dan memerlukan beberapa indikator untuk pengukurannya. Variabel yang tidak bisa diukur ini dinamakan dengan konstruk laten/variabel laten/variabel unobserved, sedangkan indikator sebagai variabel terukur dinamakan sebagai variabel manifest/variabel observed.
Misalnya di bidang manajemen keuangan, kita ingin menganalisis pengaruh efektivitas penggunaan dana terhadap kinerja keuangan. Kedua variabel tersebut (efektivitas penggunaan dana dan kinerja keuangan) adalah variabel yang tidak terukur. Oleh karenanya kita membutuhkan indikator untuk merepresentasikan kedua variabel tersebut.
Jika secara teori efektivitas penggunaan dana tercermin melalui nilai-nilai ARTO, ITO, WCTO, FATO dan TATA, sedangkan kinerja keuangan, tercermin melalui nilai-nilai ROA dan ROE, kita dapat menggambarkan diagram hubungan tersebut sebagai berikut:
Keterangan:
ARTO = penjualan/rata-rata piutang ITO = HPP/rata-rata persediaan WCTO = penjualan/rata-rata modal kerja FATO = penjualan/aktiva tetap TATA = penjualan/total aktiva ROA = penerimaan setelah pajak/total aktiva ROE = penerimaan setelah pajak/modal sendiri EFEKTIF = Efektivitas penggunaan dana KINERJA = Kinerja keuangan e = error
Pada dasarnya diagram diatas sama dengan regresi sederhana biasa yang melihat pengaruh satu variabel independen terhadap variabel dependen. Namun perbedaannya adalah variabel-variabel tersebut adalah variabel unobserved yang diukur dengan berbagai indikator. Oleh karena itu, teknik regresi biasa tidak dapat digunakan untuk mengestimasi model tersebut.
Selain itu, dari diagram tersebut terlihat bahwa, di setiap pengukuran indikator pasti terdapat kesalahan yang dinamakan dengan kesalahan pengukuran (measurement error). Selain itu juga terdapat kesalahan struktural (error yang diperlihatkan pada variabel dependent) sebagai akibat tidak masuknya semua variabel yang mempengaruhi variabel dependen (kinerja keuangan) ke dalam model. Ini dinamakan dengan kesalahan struktural (structural error).

SEM memungkinkan kita untuk menguji hubungan antara variabel laten (antara efektivitas penggunaan dana dengan kinerja keuangan) sehingga kita dapat menguji teori. Selain itu, secara simultan, SEM juga menguji indikator-indikatornya sehingga kita dapat menilai kualitas pengukuran. Dengan demikian kita dapat menentukan apakah efektivitas penggunaan dana berpengaruh terhadap ARTO (misalnya), seberapa besar pengaruhnya dan seberapa baik ARTO dapat dijadikan indikator untuk variabel efektivitas penggunaan dana.
2. Beberapa Definisi dan Konsep Terkait
1. Variabel eksogen: adalah variabel yang nilainya tidak dipengaruhi/ditentukan oleh variabel lain di dalam model; setiap variabel eksogen selalu variabel independen
2. Variabel endogen: adalah variabel yang nilainya dipengaruhi/ditentukan oleh variabel lain di dalam model. Dikenal juga dengan istilah variabel dependen
3. Konstruk Laten/Variabel Laten/Variabel Unobserved: adalah variabel yang tidak dapat diukur secara langsung dan memerlukan beberapa indikator atau proksi untuk mengukurnya.
4. Indikator/Variabel Manifest/Variabel Observed: adalah variabel yang nilainya dapat diukur secara langsung. Indikator ini dapat dibagi atas dua kelompok:
1. Indikator Reflektif/Indikator Efek: adalah indikator yang dianggap dipengaruhi oleh konstruk laten, atau indikator yang dianggap merefleksikan/merepresentasikan konstruk laten. LISREL dan beberapa program SEM yang lain hanya dapat menggunakan indikator reflektif ini.
2. Indikator Formatif: adalah indikator yang dianggap mempengaruhi konstruk laten. Indikator formatif ini hanya dapat digunakan dengan metode Partial Least Square (PLS).
Perbedaan antara indikator formatif dan indikator reflektif digambarkan dalam diagram berikut:
5. Path Diagram: adalah representasi grafis mengenai bagaimana beberapa variabel pada suatu model berhubungan satu sama lain, yang memberikan suatu pandangan menyeluruh mengenai struktur model.
3. LISREL (Linear Structural Relationship)
Pentingnya SEM sebagai alat statistik dalam penelitian (khususnya dibidang ilmu sosial) menyebabkan berkembangnya berbagai software SEM, seperti LISREL, AMOS, ROMANO, SEPATH dan LISCOMP. Namun demikian, diantara software yang ada tersebut, LISREL (Linerar Structural RELationship) merupakan program SEM yang paling banyak digunakan. Hal ini disebabkan, selain kemampuan LISREL dalam mengestimasi berbagai masalah SEM (yang seringkali tidak mungkin dilakukan program lain), tampilan LISREL juga paling informatif dalam menyajikan hasil-hasil statistik.
Sayangnya, untuk ukuran Indonesia, harga software LISREL relatif mahal. Untuk versi terakhir (LISREL Versi 8.8 for Windows) harganya US$ 495 ditambah ongkos kirim US$ 20. Dengan kurs 9.130 (hari ini tanggal 14 Juli 2008), kita harus merogoh kocek sekitar Rp 4,7 juta. SSI (Scientific Software International) sebagai perusahaan yang mengeluarkan produk LISREL juga menyediakan versi rental (sewa) untuk program ini. Untuk sewa selama 6 bulan dikenakan biaya US$ 75 (sekitar Rp 685 ribu), dan untuk 12 bulan dengan sewa US$ 130 (sekitar Rp 1,2 juta).
Masih terlalu mahal ? Jangan kuatir. Tersedia juga LISREL student edition. Versi ini gratis dan bukan versi trial (jadi tidak memiliki limit waktu pemakaian), namun demikian yang namanya gratis yang tetap ada batasannya. Batasannya adalah:

Analisis-analisis statistik dasar dan manipulasi data dibatasi maksimum 20 variabel
Model SEM dibatasi maksimum 15 variabel observed
Pemodelan multilevel dibatasi maksimum 15 variabel
Model GLM dibatasi dibatasi maksimum 20 variabel
Hanya dapat mengimpor data ASCII, tab-delimited, comma-delimited dan SPSS
Yah cukup lumayan. Meskipun ada batasannya, untuk kepentingan pengolahan data penelitian pada level rendah-menengah sudah sangat memadai.
Input Data untuk LISREL (Seri LISREL bag.2)
Dalam operasinya, Program LISREL membutuhkan input data dan input file (perintah). Untuk menyiapkan input data, LISREL menyediakan program PRELIS dan untuk menyiapkan input file, LISREL menyediakan program SIMPLIS sebagai bahasa perintah.
Pada dasarnya selain menggunakan PRELIS, input data untuk LISREL juga dapat ditulis dengan text documen. Demikian juga untuk input file, selain melalui SIMPLIS juga dapat disiapkan melalui bahasa LISREL itu

sendiri. Namun demikian, alternatif tersebut tidak dianjurkan karena relatif sulit untuk dioperasionalkan. Oleh karenanya, pada seri LISREL bagian kedua ini hanya akan diuraikan tahapan-tahapan persiapan input data dengan PRELIS, dan pada seri tulisan LISREL bagian ketiga akan dibahas tahapan-tahapan input file (perintah) dengan SIMPLIS.
1. MENYIAPKAN INPUT DATA (Program PRELIS)
PRELIS adalah program suplemen dari paket program LISREL 8. PRELIS dapat menyimpan data mentah yang sebelumnya disimpan pada berbagai macam program seperti SPSS, EXCEL, SAS, data text, dan berbagai program pengolah angka lainnya. LISREL hanya dapat menjalankan model dari data mentah yang disimpan dalam PRELIS atau text document. Sehingga setiap data mentah yang disimpan pada program yang lain harus disimpan terlebih dahulu kedalam PRELIS. Selain untuk menyimpan data, PRELIS juga dapat digunakan untuk melakukan manipulasi data dan manajemen data serta memberikan deskripsi awal dari data
Sayangnya, pada student edition, program PRELIS dari LISREL hanya dapat mengenali data yang berformat SPSS (*.sav), Comma Delimited Data (*.csv), Tab Delimited Data (*.txt) dan Free Format Data (*.dat, *.raw)
Tapi jangan kuatir. Anda tetap dapat mengetik data di program Excel. Kemudian, sewaktu menyimpan data tersebut, simpanlah dengan “Save As” ke format CSV (Comma Delimited) atau ke Text (Tab Delimited). Dengan cara seperti ini, meskipun kita mengetik dengan Excel, kita bisa dapatkan file data yang berformat CSV atau TEXT yang bisa diolah Program PRELIS.
Pada bagian berikut ini akan kita bahas cara menyiapkan/menginput data yang berasal dari SPSS maupun yang berformat *.csv dan *.txt
2. MENYIMPAN DATA
2.1. File dari SPSS
Buka program LISREL, kemudian klik File dan klik Import Data. Akan muncul kotak dialog Open.
Tampilan 1. Kotak Dialog Open
Pada Look in, pilih folder tempat data disimpan. Pada Files of Type pilih SPSS for Windows (*.sav). Pada File Name pilih nama file (dalam contoh, nama file adalah latihan lisrel1). Kemudian klik Open.
Akan muncul tampilan Save As berikut. Isikan pada File Name nama file untuk menyimpan data PRELIS. Dalam contoh dibawah, kita beri nama lisrel1. Setelah itu klik Save.
Tampilan 2. Kotak Dialog Save As

Secara langsung file data SPSS kita akan tersimpan dalam bentuk file PRELIS dengan nama lisrel1.psf, dan akan tampil di layar seperti berikut: (keterangan: contoh data kita terdiri dari 6 variabel yaitu AGE (umur), SEX (jenis kelamin), RAS (suku), WORK (jenis pekerjaan), INC (pendapatan) dan EDC (pendidikan).
Tampilan 3. Hasil Prelis
2.2. File Data dengan Format Comma Delimited Data (*.csv), Tab Delimited Data (*.txt)
Seperti yang telah dikemukakan sebelumnya, setelah mengetik data dengan Program Excel, anda bisa menyimpan ke format *.csv atau *.txt. Untuk mengimpor data dengan format ini ke PRELIS, tahapannya sebagai berikut: (Catatan: dalam mengetik data di Excel, nama variabel tempatkan pada baris pertama setiap variabel)
Buka program LISREL, kemudian klik File dan klik Import Data. Akan muncul kotak dialog Open, seperti tampilan 1 sebelumnya.

Dari tampilan 1 tersebut, pada Look in, pilih folder tempat data disimpan. Pada Files of Type pilih Comma Delimited Data (*.csv). Pada File Name pilih nama file. Kemudian klik Open.
Akan muncul tampilan Save As seperti pada tampilan 2 sebelumnya. Isikan pada File Name nama file untuk menyimpan data PRELIS. Setelah itu klik Save.
Setelah mengklik Save, akan muncul tampilan berikut yang meminta kita memasukkan jumlah variabel. Dalam kasus kita, jumlah variabelnya 6. Setelah itu klik OK.
Tampilan 4. Input Jumlah Variabel
Setelah mengklik OK, maka secara langsung file data yang berformat *.csv tadi, akan tersimpan dalam bentuk file PRELIS dengan format *. psf, dan akan tampil di layar seperti pada tampilan 3 sebelumnya. Untuk file data dengan format *.txt, caranya juga sama dengan format *.csv. Hanya pada pilihan Files of Type pada tampilan 1 diambil pilihan Tab Delimited Data (*.txt)
2.1.2. Menentukan Jenis Data
Jenis data dalam LISREL umumnya dibagi 2 yaitu dari continous dan data ordinal. Data dikatakan continous jika memiliki kategori lebih dari 15. Sebaliknya, dikatakan data ordinal. Untuk menentukan jenis data klik Data kemudian Define Variables, maka akan muncul tampilan
Tampilan 5. Definisi Variabel
Setelah itu klik nama variabel dan klik Variable Type, akan muncul kotak dialog berikut:
Tampilan 6. Jenis Variabel

Tentukan jenis data. Jika seluruh data akan diperlakukan sama, klik Apply to all.
3. MEMBUAT MATRIKS COVARIANCE DAN CORRELATIONS
Input data pada LISREL dapat berupa data mentah maupun matriks covariance dan matriks korelasi. Jika ingin mempublikasikan hasil penelitian pada jurnal ilmiah, kita tidak mungkin menyediakan data mentah. Solusinya adalah dengan memberikan data matriks covariance atau matriks korelasi.
3.1. Membuat Matriks Covariance
Setelah data mentah disimpan dalam PRELIS, klik Statistics dan klik Output Options pada bagian Statistics. Akan muncul kotak dialog berikut:
Tampilan 7. Covariance Matrix
Pada moment matrix pilih covariances, klik save to file, kemudian tulis nama file untuk menyimpan matriks kovarians tersebut. Kemudian klik OK. Dalam contoh diatas data disimpan pada partisi hardisk D dengan nama file data1.cov
Data matriks kovarians akan tersimpan dalam format text documen. File tersebut dapat dibuka dengan program Notepad (bagian program Windows).
3.2. Membuat Matriks korelasi
Matriks korelasi dibagi dua yaitu :

1. Matriks korelasi continous yang dihasilkan dari data continous. Untuk jenis ini PRELIS akan menghasilkan matriks korelasinya dalam bentuk Pearson’s Correlation.
2. Matriks korelasi ordinal yang dihasilkan dari data ordinal. Untuk jenis ini PRELIS akan menghasilkan matriks korelasinya dalam bentuk Polychoric Correlation.
Dalam LISREL, data yang memiliki kategori lebih dari 15 dikategorikan sebagai data continous, sebaliknya jika kurang dari 15 secara otomatis dikategorikan sebagai data ordinal. Kita dapat merubah data ordinal/interval menjadi continous, tetapi tidak sebaliknya.
Terdapat empat jenis matriks korelasi untuk data ordinal
1. Polychoric: matriks korelasi yang seluruh variabel memiliki skala ordinal dan juga diperlakukan sebagai ordinal
2. Tetrachoric: matriks korelasi dimana seluruh variabel memiliki skala dichotomous (variabel dummy; 1 dan 0)
3. Polyserial: matriks korelasi dimana variabel memiliki skala ordinal dan juga skala interval, yang diperlakukan sebagai ordinal.
4. Biserial: matriks korelasi dimana variabel memiliki skala interval (continuos) dan juga skala dichotomous.
Untuk membuat matrik korelasi adalah sebagai berikut:
Setelah data mentah disimpan dalam PRELIS, klik Output Options pada bagian Statistics. Akan muncul tampilan berikut:
Tampilan 8. Correlations Matrix
Pada moment matrix pilih Correlations, klik save to file, kemudian tulis nama file untuk menyimpan matriks korelasi tersebut. Kemudian klik OK. Dalam contoh diatas data disimpan pada partisi hardisk D dengan nama file data2.cor
Data matriks korelasi akan tersimpan dalam format text documen. File tersebut dapat dibuka dengan program Notepad (bagian program Windows).
3.3. Membuat Asymtotic Covariance Matrix
Asymtotic Covariance Matrix merupakan perhitungan matriks varians dan kovarians yang dihitung berdasarkan data yang berdistribusi tidak normal. Matriks ini umumnya digunakan untuk metode Weigthed Least

Square (WLS). Selain itu, asymptotic covariance matrix juga digunakan bersamaan dengan penggunaan polychoric matrix. Untuk membuat Asymtotic Covariance Matrix adalah sebagai berikut:
Setelah data mentah disimpan dalam PRELIS, klik Output Options pada bagian Statistics. Akan muncul tampilan berikut:
Tampilan 9. Asymptotic Covariance Matrix
Klik Save to file pada Asymptotic Covariance Matrix, kemudian tulis nama file tempat penyimpanan di bawahnya. Kemudian klik OK. Dalam contoh diatas data disimpan pada partisi hardisk D dengan nama file data3.acm
Data matriks asymtotic covariance akan tersimpan dalam format text document. File tersebut dapat dibuka dengan program Notepad (bagian program Windows), namun demikian nilainya tidak dapat dibaca dengan Notepad. Tetapi file tersebut tetap memiliki nilai dan dapat dipergunakan untuk analisis.
Input Perintah pada LISREL (Seri LISREL bag.3)
Jika pada seri kedua tulisan LISREL kita sudah membahas dasar-dasar input data dengan PRELIS, maka pada seri ketiga ini akan dibahas tahapan-tahapan input file (perintah) dengan SIMPLIS.
MENYIAPKAN INPUT FILE/PERINTAH (Program/Bahasa SIMPLIS)
Buka program LISREL, kemudian klik File dan klik New. Akan muncul tampilan berikut:
Kemudian klik SIMPLIS Project, dan klik OK. Akan muncul kotak dialog Save As.

Pada Save in, pilih folder tempat data disimpan. Pada Save of Type pilih SIMPLIS Project (*.spj). Pada File Name pilih nama file. Kemudian klik Save. Akan muncul tampilan kosong berikut tempat untuk menginput/menulis perintah
STRUKTUR PENULISAN PERINTAH PADA PROGRAM SIMPLIS
Syntax dan aturan-aturan yang sering digunakan dalam input file SIMPLIS sebagai berikut: (syntax lainnya selain yang diberikan di bawah ini, akan diberikan bersamaan dengan contoh aplikasi pada seri-seri tulisan berikutnya mengenai LISREL)
1. Baris Judul
Baris pertama pada input file dapat digunakan sebagai baris judul. Setiap keterangan pada baris pertama akan diperlakukan sebagai baris judul kecuali LISREL menemukan dua hal berikut:

Baris yang dimulai dengan kata Observed Variables atau Labels yang merupakan baris perintah pertama dalam input file SIMPLIS
Baris yang dua karakter (huruf) pertamanya dimulai dengan DA, Da, dA atau da, yang merupakan baris perintah pertama dalam input file SIMPLIS
2. Variabel Observed
Setelah baris judul, baris selanjutnya adalah observed variables, yang merupakan variabel yang memiliki nilai pada input data.
Baris ini harus dilakukan jika input data adalah matriks kovarians atau matriks korelasi atau data mentah yang disimpan dalam file text.
Baris ini tidak diharuskan jika input data menggunakan data mentah yang disimpan dalam program PRELIS.
Penulisan observed variables dengan memberikan spasi antar variabel. Contoh: Observed Variables X1 X2 X3 Y1 Y2
3. Data
Setelah baris observed variables, baris selanjutnya adalah penjelasan unuk input data. Dalam LISREL input data dapat berupa data mentah, Matriks kovarians, Matriks kovarias dan means, Matriks korelasi,Matriks korelasi dan standar deviasi, Matriks korelasi, standar deviasi dan means. Pada seluruh macam format input data tersebut, asymptotic covariance matrix juga dapat ditambahkan pada input data.
Untuk membaca data, perintahnya adalah sebagai berikut:
Untuk Data mentah
Raw Data from file ‘nama file’
Matriks kovarians
Covariance Matrix from file ‘nama file’
Matriks kovarians dan means
Covariance Matrix from file ‘nama file’
Means from file ‘nama file’
Matriks korelasi
Correlations Matrix from file ‘nama file’
Matriks korelasi dan standar deviasi
Correlations Matrix from file ‘nama file’
Standard Deviations from file ‘nama file’
Matriks korelasi, standar deviasi dan means
Aplikasi LISREL untuk Regresi (Seri LISREL bag.4)

Tulisan seri keempat dari LISREL ini akan membahas aplikasi sederhana pada persoalan regresi berganda. Misalkan, kita punya data mentah dari 474 pekerja/karyawan yang mencakup variabel-variabel sebagai berikut: (Untuk latihan,silakan ambil datanya disini. Tapi data tersebut dalam bentuk word, rubah dulu ke Excel atau SPSS ya. Maklum, WordPress tidak mendukung file data Excel dan SPSS)
X1 = pendidikan dalam tahun pendidikan formal
X2 = masa kerja pada pekerjaan (perusahaan) sekarang dalam bulan
X3 = masa kerja sebelum pekerjaan (perusahaan) sekarang dalam bulan
Y1 = Gaji sekarang (dalam Juta Rp)
Y2 = Gaji awal bekerja (dalam Juta Rp)
Setelah data yang Anda ambil tersebut dirubah ke SPSS atau Excel, kemudian simpan ke dalam format PRELIS (lihat tahapannya pada tulisan Seri 2), dengan nama kerja1.psf, pada folder D:\blog. Kemudian, kita buat file perintah dengan nama file kerja2.psf (lihat tahapannya pada tulisan Seri 3).
Misalnya kita ingin menganalisis pengaruh pendidikan (X1), masa kerja sekarang (X2) dan masa kerja sebelumnya (X3) terhadap gaji sekarang (Y1), maka pada halaman perintah, kita ketikkan perintah-perintahnya seperti tampilan berikut.
Baris pertama dari perintah tersebut adalah judul dari output kita. Baris kedua adalah perintah agar LISREL membaca data mentah kerja1.psf di folder D:\blog. Baris ketiga adalah baris hubungan, yang memerintahkan LISREL untuk mencari hubungan. Baris keempat adalah bentuk hubungan yang akan kita cari. Baris kelima adalah perintah agar LISREL menghasilkan path diagram. Baris keenam untuk menyatakan seluruh persamaan telah dituliskan.
Setelah mengetikkan semua perintah tersebut, langkah selanjutnya adalah memerintahkan LISREL untuk mengolah hasilnya. Caranya? Perhatikan di bagian atas layar ada icon orang sedang berlari dan tulisan L. Klik icon tersebut. Maka kita akan mendapatkan hasil perhitungan LISREL.
Sesuai dengan perintah kita, LISREL akan menghasilkan dua output. Output pertama dengan nama file kerja2.out, seperti tampilan di bawah ini.

Sebagian output pertama tersebut kita kutipkan disini.
Perhitungan pertama yang ditampilkan LISREL adalah kovarians matriks yang diikuti oleh nilai rata-rata hitung masing-masing variable sebagai berikut:
Koefisien regresi ditunjukkan dengan angka-angka pada baris pertama. Di bawah koefisien regresi (dalam tanda kurung) adalah estimasi standar error yang mengukur ketepatan dari estimasi parameter. Di bawah standar error adalah nilai t-hitung, yang diuji dengan nilai t-tabel untuk menarik kesimpulan mengenai signifikansi koefisien regresi. Jika nilai t-hitung > t-tabel dapat ditarik kesimpulan adanya pengaruh yang signifikan antar variable.Nilai t-tabel pada α = 5% dan df=470 adalah 1,97. dan nilai t-tabel pada α = 1% dan df=470 adalah 2,59. Berdasarkan hal tersebut, variable X1 berpengaruh signifikan terhadap Y1 pada level 1%, variable X3 berpengaruh signifikan terhadap Y1 pada level 5 %, sedangkan X2 tidak berpengaruh terhadap Y1.Angka konstantanya adalah sebesar -2,79. (catatan: jika dalam perintah SIMPLIS tidak ditambahkan kata constant, LISREL tidak akan memunculkan nilai ini). Secara matematis ini berarti nilai Y1 ketika nilai X1, X2 dan X3 sama dengan 0. (catatan: secara teori empirik, penafsiran konstanta tidak selalu seperti hal tersebut).Dalam estimasi persamaan regresi juga dimunculkan nilai error variance dan R2.

Output LISREL juga menampilkan kovarians matriks antara variable-variabel independent. Kovarians antara variable X1 dan X3 adalah -76,14 dengan standar error 14,35 dan nilai t adalah -5,30 (signifikan pada level 1%). Sebagai catatan: kovarians antar variable independent yang standardized adalah nilai korelasi.
Dengan cara pembacaan yang sama, terlihat bahwa kovarians antara X2 dan X3 tidak signifikan, demikian juga antara X1 dan X2.
Varians X1 adalah sebesar 8,32 dengan standar error 0,54 dan nilai t adalah 15,33 (membandingkan dengan nilai t table, angka ini signifikan pada level 1 %). Varians X2 adalah sebesar 101,22 dengan standar error 6,60 dan nilai t adalah 15,33 (signifikan pada level 1 %).
Berikutnya, output LISREL juga menampilkan kovarians matriks variable laten. Namun demikian, karena variable kita adalah variable observed bukan variable laten, maka tampilan ini dapat diartikan sebagai kovarians antara semua variable yang dianalisis.
Selain output yang dijelaskan diatas, masih terdapat beberapa output lainnya dari LISREL. Namun demikian output-output tersebut belum terkait dengan contoh kita pada bagian ini, dan akan dibahas pada contoh-contoh pada tulisan seri berikutnya:
Selanjutnya, output kedua yang dihasilkan LISREL dari perintah path diagram diberikan sebagai berikut:

Tampilan path diagram diatas menampilkan nilai estimasi unstandarized. Angka ini sama dengan output teks sebelumnya. Sedangkan angka pada panah dua arah yang menghubungan antar variabel independen adalah nilai kovarians antara variabel independent tersebut.
Perhatikan pada menu bagian atas. Pada menu model ada dua pilihan yaitu Structural Model (seperti yang terlihat pada tampilan diatas) dan Mean Model (yang bisa kita pilih dengan mengklik panah disamping menu tersebut). Jika kita pilih Mean Model, maka angka-angka yang ada pada diagram tersebut akan berganti dengan angka mean model.
Demikian juga, pada menu bagian atas terdapat menu Estimates. Terdapat beberapa pilihan pada menu Estimates yaitu Estimates (seperti yang terlihat pada tampilan), Standarized Solution (menghasilkan estimasi standarisasi), Conceptual Diagram (menghasilkan konsep diagram tanpa angka), T-Values (mengeluarkan nilai t-hitung), Modification Indices (indeks modifikasi) dan Expected Change (perubahan yang diharapkan).
Sebagaimana halnya pada menu Model, ketika kita merubah pilihan pada Menu Estimates ini, maka angka-angka pada diagram juga akan berubah. Misalnya, pada menu Estimates kita pilih T-values, maka akan muncul tampilan seperti berikut, yang menampilkan nilai t untuk estimasi masing-masing parameter. Hubungan yang signifikan (default LISREL adalah sebesar 5%) ditampilkan dengan warna hitam, sedangkan yang tidak signifikan ditampilkan dengan warna merah.

Aplikasi LISREL untuk Path Analysis (Seri LISREL bag.5)
Pada tulisan seri kelima ini, kita akan mencoba mengaplikasikan program LISREL untuk Path Analysis. Untuk dapat mengikuti pembahasan pada tulisan ini, Anda diharapkan sudah membaca tulisan-tulisan seri LISREL sebelumnya yang ada pada blog ini (Seri 1, Seri 2, Seri 3 dan Seri 4)
Analisis jalur (Path Analysis) merupakan teknik statistik yang digunakan untuk menguji hubungan kausal antara dua atau lebih variabel. Analisis jalur berbeda dengan teknik analisis regresi lainnya, dimana pada analisis jalur memungkinkan pengujian dengan menggunakan variabel mediating/intervening/perantara (misalnya X→ Y → Z)
Dengan menggunakan data pekerja seperti pada tulisan seri LISREL bagian 4 sebelumnya, misalnya kita membentuk model sebagai berikut:
Y1 = X1 X2 X3 Y2
Y2 = X1 X3
Yang berarti bahwa gaji sekarang (Y1) selain dipengaruhi oleh pendidikan (X1), masa kerja sekarang (X2), masa kerja sebelumnya (X3), juga dipengaruhi oleh gaji awal bekerja (Y2). Gaji awal bekerja (Y2) itu sendiri juga dipengaruhi oleh pendidikan (X1) dan masa kerja sebelumnya (X3).
Input untuk menjalankan persamaan tersebut adalah sebagai berikut:
Catatan: perintah Option: SS, digunakan untuk menampilkan nilai standardized hubungan antar variable. Jika perintah ini tidak digunakan, maka yang akan ditampilkan hanya nilai unstandarized (tetapi nilai standardized tetap bias dilihat pada path diagram). Option: EF digunakan untuk menampilkan effect decomposition (komposisi pengaruh).
Dengan input tersebut, LISREL menghasilkan estimasi regresi unstandarized berikut:
Dari output tersebut terlihat bahwa semua variabel pada taraf 1 % berpengaruh signifikan, baik terhadap Y1 maupun Y2.
Selanjutnya, output covariance matrix untuk independent variables dan latent variables diberikan sebagai berikut. Interpretasinya sama dengan kasus sebelumnya.

Model memiliki fit yang sangat baik karena memiliki nilai probabilitas yang tidak signifikan (p-value = 0,12 Chi-Square = 2,41 dengan df = 1). Catatan: model yang fit seharusnya memiliki nilai p yang tidak signifikan (lebih besar dari 0,05). Penjelasan lebih lanjut mengenai model fit ini lihat pada bab khusus mengenai model fit.
Berdasarkan perintah Option: SS, LISREL memberikan output sebagai berikut:
Output BETA adalah output LISREL yang berupa matriks hubungan antara sesame variable endogen. Bagian kolom adalah variable endogen independent dan bagian baris adalah variable endogen dependent. Dari output tersebut diketahui nilai standardized pengaruh antara Y2 terhadap Y1 adalah 0,81.
Output GAMMA adalah output LISREL yang berupa matriks pengaruh (standardized) antara variable eksogen (independent) terhadap variable endogen (dependen). Bagian kolom adalah variable eksogen (independent) dan bagian baris adalah variable endogen (dependent).

Output diatas adalah matrik korelasi antara variable yang dianalisis. Output ini hanya akan ditampilkan jika ada perintah Option: SS
Output PSI menampilkan output mengenai measurement error (perhatikan hanya untuk variable endogen) dimana error telah distandarisasi. Y1 memiliki measureme
nt error 0,19 dan Y2 sebesar 0,55.
Karena variable-variabel yang dianalisis adalah variable observed dan tidak latent, maka output di atas adalah output gabungan sebelumnya yaitu output BETA dan GAMMA.
Selanjutnya, berdasarkan perintah Option: EF, LISREL memberikan output berikut:
Output diatas memberikan pengaruh total antara variable eksogen terhadap variable endogen. Pengaruh total ini merupakan penjumlahan dari pengaruh langsung (lihat output estimasi regresi unstandarized sebelumnya) dengan pengaruh tidak langsung (lihat output di bawah ini). Misalnya pengaruh total X1 terhadap Y1 sebesar 0,40. Ini adalah penjumlahan dari pengaruh langsung X1 terhadap Y1 sebesar 0,067 dengan pengaruh tidak langsung X1 terhadap Y1 sebesar 0,33.
Pengaruh total X2 terhadap Y1 sama dengan pengaruh langsungnya. Karena hubungan X2 dan Y1 adalah langsung dan tidak memiliki hubungan tidak langsung.

Output diatas memberikan pengaruh
Aplikasi LISREL pada Model Pengukuran & Analisis Faktor (Seri LISREL bag.6)
Tulisan ini merupakan seri ke 6 dari seri LISREL yang akan membahas mengenai aplikasi LISREL pada Model Pengukuran dan Analisis Faktor. Silakan baca dulu seri 1 – 5 dari tulisan LISREL yang ada pada blog ini.
Untuk mengukur suatu variabel/faktor, kita memerlukan indikator-indikator yang membentuk variabel tersebut. Misalnya untuk mengukur tingkat ketampanan seseorang, maka indikatornya misalnya panjang hidung, warna kulit dan lain sebagainya. Nah, pemodelan yang ditujukan untuk mengukur dimensi-dimensi yang membentuk sebuah faktor atau variabel tersebut disebut Measurement Model atau Model Pengukuran. Measurement model berkaitan dengan sebuah faktor. Karenanya, analisis yang dilakukan sebenarnya sama dengan analisis faktor, dalam konteks apakah indikator yang digunakan dapat mengkonfirmasi faktor.
Sebagai latihan, misalnya kita ingin meneliti mengenai persepsi nasabah terhadap kualitas pelayanan suatu bank (Untuk latihan, silakan ambil datanya disini. Tapi file ini masih dalam word, Anda harus rubah dulu ke Excel atau SPSS. Selanjutnya simpan dalam format PRELIS). Diambil sebanyak 101 responden nasabah bank tersebut. Untuk mengukur persepsi terhadap kualitas pelayanan bank tersebut dikembangkan dua dimensi kualitas pelayanan yaitu dimensi fisik dan dimensi non-fisik. Untuk dimensi fisik digunakan tiga indikator pengukuran dan untuk dimensi non-fisik dikembangkan lima indikator pengukuran. Indikator-indikator tersebut ditanyakan kepada responden dengan menggunakan pengukuran skala likert 1-5, yaitu sangat tidak setuju = 1, tidak setuju = 2, setuju = 3, tidak setuju = 4 dan sangat tidak setuju = 5. Rincian indikator sebagai berikut:
Indikator Persepsi Kualitas Pelayanan Dimensi Kualitas Pelayanan
Fasilitas ATM di Bank ini terjamin keamanannya. Fisik

X1
X2
Memarkir kendaraan di Bank ini terjamin keamanannya
X3
Ruangan tunggu di Bank ini cukup memadai untuk menampung nasabah yang ada
X4
Keakuratan dan keterandalan pelayanan bank ini tidak sesuai dengan yang dijanjikan.
NonFisik
X5
Bantuan pelayanan yang diberikan sangat lambat jika saya ada masalah yang berkaitan dengan bank ini
X6
Kemampuan pegawai bank sangat rendah dalam mengatasi masalah saya yang berkaitan dengan bank ini
X7
Bank ini tidak memiliki kepedulian dan perhatian personal yang tinggi kepada saya
Penulisan input pada LISREL untuk menjalankan model tersebut adalah sebagai berikut:

Perhatikan, pada baris ketiga kita sebutkan nama variabel laten (unobserved variable), yang menunjukkan dua dimensi kualitas pelayanan yang akan diukur. Perhatikan penulisan persamaan pada baris keempat dan kelima yang berbeda dengan contoh-contoh sebelumnya (pada tulisan seri 3,4,5), karena adanya variabel laten. Indikator berada di sebelah kiri tanda sama dengan, sedangkan variabel laten di sebelah kanan. Perhatikan juga penulisan tanda strip (-) diantara indikator, yang berarti “sampai dengan”. Penulisan baris kelima (demikian juga untuk baris keenam) sebenarnya adalah ringkasan dari:
X1 = FISIK
X2 = FISIK
X3 = FISIK
Yang berarti variabel laten FISIK berpengaruh terhadap indikator X1, X2 dan X3.
Perhatikan penulisan perintah path diagram yang diikuti dengan kata-kata tv=10. Perintah ini meminta LISREL untuk menguji (menandai) output path diagram dengan tingkat signifikansi 10%. (Jika tidak dituliskan, default LISREL adalah 5%).
Input tersebut akan memberikan estimasi mengenai hubungan antara indikator dengan variabel laten, atau dengan kata lain, kita ingin menguji validitas indikator dalam merefleksikan variabel laten (unobserved).

Dengan menggunakan α = 10%, nilai t-tabel df=99 adalah 1,66. Ini berarti dari output diatas dapat diketahui bahwa yang tidak signifikan adalah indicator X2 yang merupakan indicator FISIK dan X4 sebagai indicator NONFISIK. Kedua indicator itu juga memberikan nilai R2 paling kecil. Nilai R2 pada masing-masing persamaan, biasanya diinterpretasikan sebagai reliabilitas indicator. Sebaliknya, indicator-indikator lainnya terbukti cukup baik dalam merepresentasikan variable laten.
Dari output juga dapat disimpulkan bahwa dari ketiga indicator FISIK, indicator X3 merupakan indicator yang paling reliable, sedangkan dari lima empat indicator NONFISIK, indicator X7 yang paling reliable.
Model memiliki fit yang sangat baik karena memiliki nilai probabilitas yang tidak signifikan (p-value = 0,60 Chi-Square = 11,08 dengan df = 13). Catatan: model yang fit seharusnya memiliki nilai p yang tidak signifikan (lebih besar dari 0,05).
Karena model pengukuran di atas memiliki fit yang sangat baik, maka kita dapat menggunakan nilai estimasi (loading) sebagai koefisien validitas. Dengan demikian, karena X3 memiliki nilai loading yang paling besar (sebesar 0,43 bandingkan dengan X1 sebesar 0,28 dan X2 sebesar 0,022), maka dapat disimpulkan bahwa X3 merupakan indikator yang paling valid dari indikator variabel FISIK. Sedangkan untuk variabel NONFISIK adalah indikator X7.
Dua variable independent (eksogen) secara default LISREL diasumsikan saling berkorelasi, maka output LISREL juga menampilkan nilai korelasinya. Nilai korelasi antara FISIK dan NONFISIK adalah -0,82 dengan standar error 0,35 dan nilai t= -2,31 (signifikan pada α = 5%).
Informasi korelasi dan standar error ini berguna untuk mengetahui apakah sebenarnya model cocok menggunakan satu variable laten saja atau dua variable laten. Dengan kata lain, kita dapat membuktikan apakah dari tujuh indicator tersebut, sebaiknya dipecah dalam dua dimensi (FISIK dan NONFISIK) atau menjadi satu dimensi saja.

Karena korelasinya cukup kuat, maka dapat kita simpulkan sebaiknya model menggunakan satu dimensi saja.
Output path diagram yang menampilkan koefisien estimasi dari kasus kita sebagai berikut:
Output path diagram yang menampilkan nilai t dari kasus kita sebagai berikut:

Modifikasi Model Pengukuran & Analisis Faktor (Seri LISREL bag.7)
Tulisan ini merupakan seri ketujuh dari tulisan seri LISREL yang ada pada blog ini. Jika pada seri keenam kita membahas mengenai model pengukuran dan analisis faktor, pada seri ketujuh ini juga masih membahas hal yang sama, tetapi lebih ditekankan pada teknik modifikasi model dalam analisis faktor jika model fit tidak baik
Misalnya, kita punya data hipotetik dengan dua faktor, yaitu FAKTOR1 dan FAKTOR2. Asumsikan masing-masing faktor tersebut akan diukur melalui tiga indikator. FAKTOR1 diukur melalui indikator X1, X2 dan X3 dan FAKTOR2 diukur melalui X4, X5 dan X6. Indikator-indikator itu sendiri merupakan respon dari responden yang diukur dengan skala likert 1-5. (Silakan ambil datanya disini. Tapi data tersebut masih dalam bentuk word. Rubah dulu ke bentuk SPSS atau Excel, kemudian simpan dalam format PRELIS)
Secara konseptual, model tersebut dapat digambarkan sebagai berikut:

Input untuk model tersebut dapat ditulis dalam LISREL sebagai berikut:
Ada tambahan dua elemen baru dalam baris perintah yaitu:
Number of Decimals = 3
Yang memerintahkan LISREL untuk menampilkan output dengan tiga desimal di belakang koma (default LISREL dua desimal).
Wide Print
Yang memerintahkan LISREL untuk menampilkan output dengan 132 karakter perbaris (default LISREL 80 karakter)

Print Residuals
Yang memerintahkan LISREL untuk menampilkan residual
Dengan perintah-perintah tersebut diatas, LISREL menghasilkan persamaan pengukuran sebagai berikut:
Seluruh indicator tersebut signifikan pada taraf 1% atau 5%. Seluruh error variance juga signifikan pada tarf 1% atau 5%, dengan R2 berkisar antara 0,121 sampai 0,863. Tetapi jika dilihat dari goodness of fit, ternyata model tidak fit. Chi-Square sebesar 65,821 dengan derajat bebas 8 dan nilai p yang signifikan, mengindikasikan model tidak fit. Dalam konteks ini, ada dua alternatif. Melakukan penelitian ulang atau memodifikasi model. Tentu saja pilihan yang lebih logis adalah memodifikasi model, asal terdapat justifikasi teori yang kuat untuk modifikasi model tersebut.
Perintah Print residual dalam input kita sebelumnya dapat memberikan kita informasi mengenai penyebab tidak fitnya model. Output-output LISREL di bawah ini dapat digunakan sebagai pemandu untuk menganalisis penyebab tidak fitnya model.

Output dengan judul Covariance Matrix secara statistik juga dikenal dengan istilah Sample Covariance Matrix (yang merupakan tampilan default dari LISREL). Output dengan judul Fitted Covariance Matrix merupakan estimasi program dalam memprediksi covariance matrix model penelitian yang diajukan. Pengurangan Covariance Matrix dengan Fitted Covariance Matrix menghasilkan output Fitted Residuals.
Suatu model dikatakan fit jika matriks residualnya (Fitted Residuals) adalah nol (mendekati nol). Sedangkan model dikatakan memiliki fit yang sangat buruk apabila matriks residualnya sangat besar.
Berdasarkan hal tersebut, terlihat bahwa residual kovarians yang terbesar adalah antara X1 dan X4 yaitu 0,338, sehingga diperoleh kesimpulan bahwa X1 dan X4 inilah yang menjadi penyebab tidak fitnya model.
Namun demikian, informasi residual ini perlu ditanggapi secara hati-hati karena nilai residual tersebut adalah unstandarized, yang mungkin nilai-nilainya dipengaruhi oleh bedanya pengukuran. Jika indicator-indikator dalam model kita memiliki perbedaan dalam skala pengukurannya, sebaiknya menggunakan Standarized Residual yang juga ditampilkan dalam output LISREL sebagai berikut:
Dari output diatas terlihat bahwa berdasarkan standarized residual, sebenarnya yang memiliki residual terbesar adalah X5 dan X6.

Lalu apa yang harus dilakukan ? Dalam konteks ini LISREL memberikan output modification index yang merupakan salah satu alternatif terbaik untuk modifikasi model.
Output LISREL menyarankan dua tipe modifikasi yang dapat dilakukan:
Tipe 1.
1. Menambah path (jalur) dari FAKTOR2 ke indikator X3. Dengan kata lain, X3 selain merupakan indikator FAKTOR1 juga merupakan indikator indikator FAKTOR2. Modifikasi ini akan menurunkan nilai Chi-Square sebesar 13,0 dan menghasilkan estimasi baru menjadi 0,48
2. Menambah path (jalur) dari FAKTOR1 ke indikator X4. Dengan kata lain, X4 selain merupakan indikator FAKTOR2 juga merupakan indikator indikator FAKTOR1. Modifikasi ini akan menurunkan nilai Chi-Square sebesar 27,7 dan menghasilkan estimasi baru menjadi 0,65
Tipe 2.
1. Memberikan hubungan antara dua error indikator X2 dan X1, akan menghasilkan penurunan nilai Chi-Square sebesar 13,0 dan menghasilkan kovarians baru sebesar 0,26
2. Memberikan hubungan antara dua error indikator X4 dan X1, akan menghasilkan penurunan nilai Chi-Square sebesar 10,0 dan menghasilkan kovarians baru sebesar 0,25
3. Memberikan hubungan antara dua error indikator X6 dan X1, akan menghasilkan penurunan nilai Chi-Square sebesar 17,7 dan menghasilkan kovarians baru sebesar -0,24
4. Memberikan hubungan antara dua error indikator X6 dan X3, akan menghasilkan penurunan nilai Chi-Square sebesar 10,8 dan menghasilkan kovarians baru sebesar 0,17
5. Memberikan hubungan antara dua error indikator X6 dan X5, akan menghasilkan penurunan nilai Chi-Square sebesar 27,7 dan menghasilkan kovarians baru sebesar 3,23
Modification indices dan perubahan yang diharapkan (Expected Change) juga divisualisasikan oleh LISREL dalam bentuk path diagram berikut:

Berikut ini diberikan cara mengoperasikan LISREL untuk memodifikasi model. Contoh untuk modifikasi tipe 1a dari kasus kita diatas. Inputnya dapat ditulis:

Nah, setelah mengetikan perintah tersebut di LISREL, coba di run untuk melihat hasilnya. Apakah modelnya sudah fit? Jika belum, coba lagi dengan tipe modifikasi lain yang disarankan LISREL. Selamat mencoba.
Aplikasi LISREL pada Model Persamaan Struktural (Seri LISREL bag.8)

Tulisan ini merupakan seri terakhir (seri kedelapan) dari seri yang membahas mengenai aplikasi-aplikasi dasar dari LISREL. Tentunya, untuk mendalami lebih jauh mengenai LISREL, kita harus membaca buku-buku mengenai LISREL dengan bahasan-bahasan yang lebih lanjut. Meskipun demikian, sebagai tulisan yang mengantarkan kepada pemahaman awal, harapannya ini bisa membantu.
Ok. Pada tulisan ini kita akan fokuskan pada aplikasi LISREL untuk Structural Equation Model (SEM). SEM secara statistik adalah generasi kedua dari teknik analisis multivariate, yang memungkinkan peneliti untuk menguji hubungan antara variabel yang kompleks baik recursive maupun non-recursive untuk memperoleh gambaran menyeluruh mengenai keseluruhan model.
Misalnya kita ingin melakukan penelitian mengenai keyakinan masyarakat terhadap partai politik di Indonesia. Untuk itu diambil sampel sebanyak 150 orang. Jawaban responden kita skor dengan skala Likert.
Misalnya lagi, kita punya kerangka teori bahwa keyakinan terhadap partai politik (PARTAI) ditentukan oleh keyakinannya terhadap keberhasilan program partai (PROGRAM) dan keyakinannya terhadap kemampuan pengurus partai (PENGURUS). Keyakinannya terhadap kemampuan pengurus partai juga mempengaruhi keyakinannya terhadap keberhasilan program partai.
Selanjutnya untuk mengukur keyakinan terhadap partai politik digunakan dua indikator (X5 dan X6), untuk mengukur keyakinan terhadap keberhasilan program partai digunakan dua indikator (X3 dan X4) sedangkan untuk mengukur keyakinan terhadap kemampuan pengurus partai dengan indikator X1 dan X2
Model grafisnya dari kerangka teori kita adalah sebagai berikut:
Setelah melakukan penelitian, dan data sudah diinput. Ubah file data ke dalam format prelis dan misalnya kita tempatkan di folder D:/blog dengan nama file partai.psf. Selanjutnya, tuliskan input perintah pada program LISREL (SIMPLIS) sebagai berikut

Setelah dirun dengan LISREL kita akan mendapatkan hasil output grafik dan output dalam bentuk teks. Sebagian output grafik (yaitu grafik dengan koefisien estimasi) ditampilkan di bawah ini. Sedangkan output teks kita tampilkan utuh. (Catatan: Tetapi tidak diinterpretasikan disini. Sebagai bahan latihan silakan interpretasikan sendiri mengacu pada tulisan-tulisan seri LISREL sebelumnya)